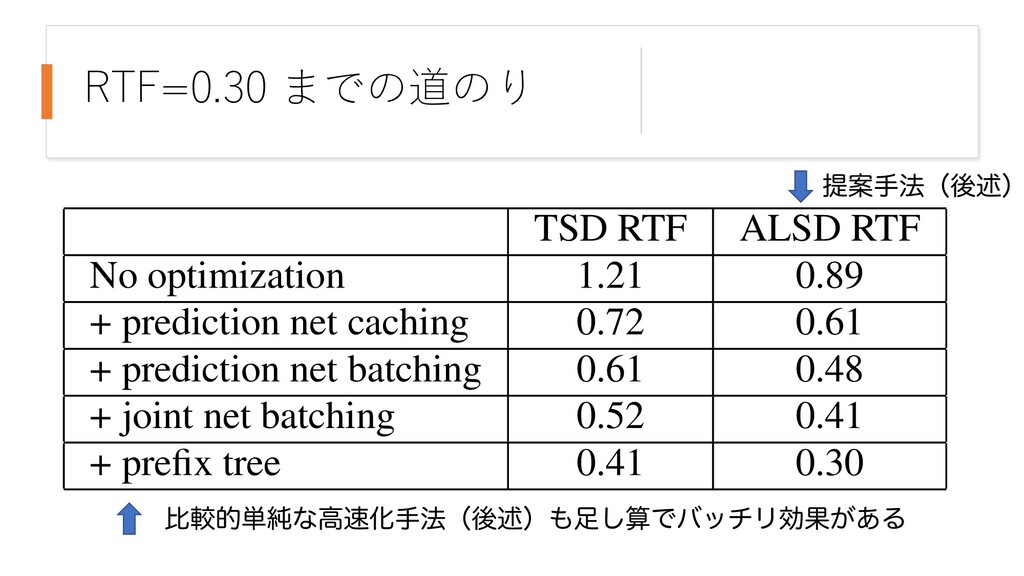
for both time and alignment- ength synchronous decoding for the same CallHome WER of 0.9%. The timing runs are measured on a 28-core Intel Xeon .3GHz processor. TSD RTF ALSD RTF No optimization 1.21 0.89 + prediction net caching 0.72 0.61 + prediction net batching 0.61 0.48 + joint net batching 0.52 0.41 + prefix tree 0.41 0.30 ఏҊख๏ʢޙड़ʣ ൺֱత୯७ͳߴԽख๏ʢޙड़ʣ͠ࢉͰόονϦޮՌ͕͋Δ
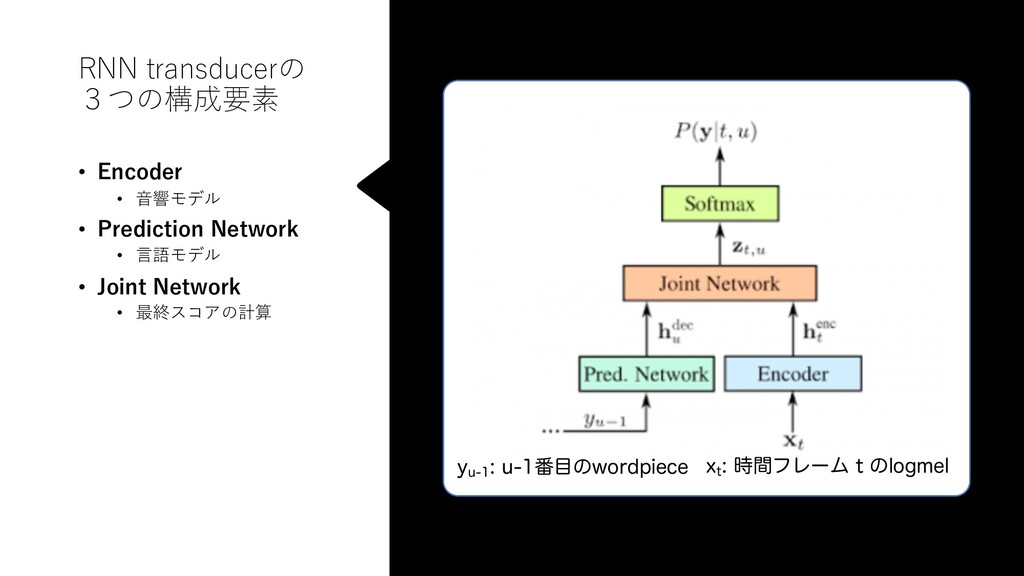
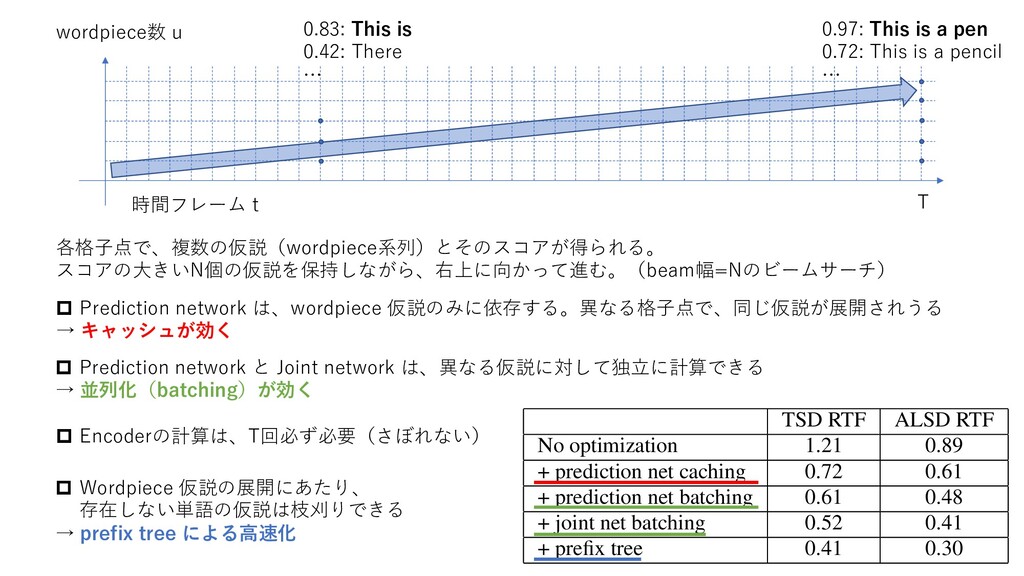
Additionally, we employ ata perturbation/augmentation techniques: speed rbation in the range 0.9-1.1 [18], sequence noise ere we add with probability 0.4 and weight 0.4 the one or two random training utterances to the current e, and spectral augmentation as described in [1]. hieve the best possible word error rates, we trained M parameters RNN-T with the following architec- 2], the encoder network has 8 bidirectional LSTM cells per layer per direction with pyramidal sub- nput [5, 6] by a factor of 4 after the first and second 2 each). The prediction network has an embedding and 2 unidirectional LSTM layers with 1024 cells utputs of the encoder and prediction networks are jected to a common dimension of size 512. The esponds to 182 word piece units (plus BLANK) ex- -step byte-pair encoding [20]. was trained in PyTorch to minimize the RNN-T or 50 epochs on 8 V100 GPUs using Nesterov- hronous SGD with a batchsize of 256 utterances. hase both batchsize and learning rate are linearly and 0.02 over the first 2 epochs. The training • Batching of prediction network evaluations. First, we find y’s in the beam that are not in the prediction cache. Seco we make a single call to the Prediction function with entire batch. Lastly, we add the (y, gu) pairs to the cache • Batching of joint network evaluations. We group the (ht, pairs for all hypotheses within the beam into a single ba and make a single joint network and softmax function cal • Word prefix trees. Instead of iterating over all possible ou symbols, we restrict the hypothesis expansion only to succ sor BPE units from a given node in the prefix tree. The effect of these optimization techniques on the overall r time factor (RTF) is shown in Table 2 for both time and alignm length synchronous decoding for the same CallHome WER 10.9%. The timing runs are measured on a 28-core Intel X 2.3GHz processor. TSD RTF ALSD RTF No optimization 1.21 0.89 + prediction net caching 0.72 0.61 + prediction net batching 0.61 0.48 + joint net batching 0.52 0.41 + prefix tree 0.41 0.30 時間フレーム t wordpiece数 u 各格⼦点で、複数の仮説(wordpiece系列)とそのスコアが得られる。 スコアの⼤きいN個の仮説を保持しながら、右上に向かって進む。(beam幅=Nのビームサーチ) T 0.97: This is a pen 0.72: This is a pencil … 0.83: This is 0.42: There … p Encoderの計算は、T回必ず必要(さぼれない) p Prediction network は、wordpiece 仮説のみに依存する。異なる格⼦点で、同じ仮説が展開されうる → キャッシュが効く p Prediction network と Joint network は、異なる仮説に対して独⽴に計算できる → 並列化(batching)が効く p Wordpiece 仮説の展開にあたり、 存在しない単語の仮説は枝刈りできる → prefix tree による⾼速化
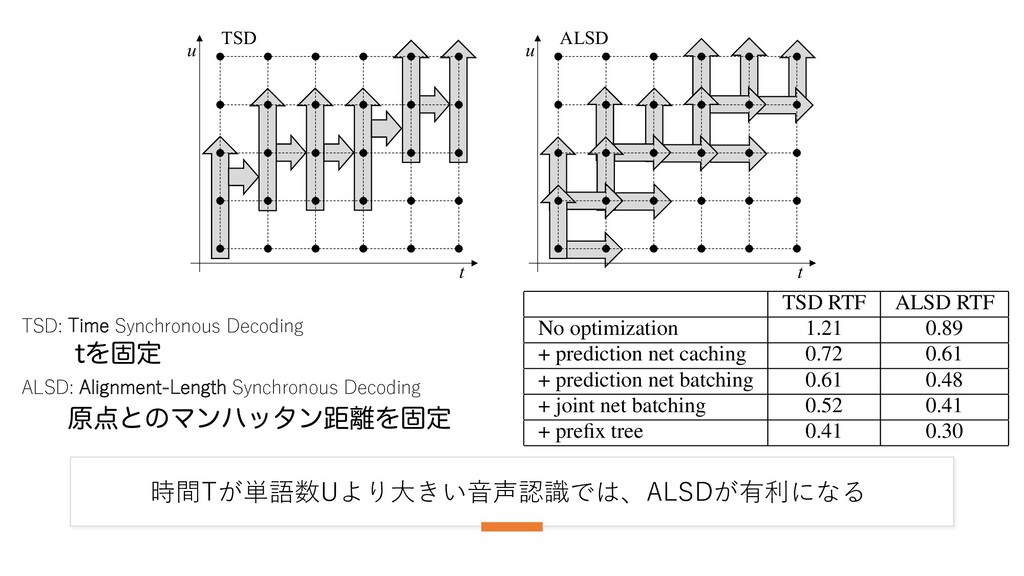
t u TSD ALSD Fig. 1. Comparison between time synchronous (left) and alignment- length synchronous (right) search spaces. Comparing the two algorithms whose search spaces are illus- trated in Figure 1, it is clear that TSD has a complexity of T ⇤ max sym exp whereas ALSD runs in T + Umax steps. Since, for our experimental setting, Umax < T and max sym exp 4, we expect ALSD to perform fewer operations and consequently be faster than TSD for the same accuracy (even though ALSD requires a System Battenberg et al. ( Hadian et al. (201 Xiong et al. (2017 Han et al. (2017) This system Table 1. Word e tems for the Swit LMs trained on e networks apply d matrices [21] wi Finally, the learn 12 epochs. The r the Switchboard which compares as shown in Table 時間Tが単語数Uより⼤きい⾳声認識では、ALSDが有利になる one or two random training utterances to the current e, and spectral augmentation as described in [1]. hieve the best possible word error rates, we trained M parameters RNN-T with the following architec- 2], the encoder network has 8 bidirectional LSTM cells per layer per direction with pyramidal sub- nput [5, 6] by a factor of 4 after the first and second 2 each). The prediction network has an embedding and 2 unidirectional LSTM layers with 1024 cells utputs of the encoder and prediction networks are jected to a common dimension of size 512. The esponds to 182 word piece units (plus BLANK) ex- -step byte-pair encoding [20]. was trained in PyTorch to minimize the RNN-T or 50 epochs on 8 V100 GPUs using Nesterov- hronous SGD with a batchsize of 256 utterances. hase both batchsize and learning rate are linearly and 0.02 over the first 2 epochs. The training ndomly grouped into buckets such that the input bucket differ by at most 10 frames. The buck- in ascending length order for the first 8 epochs y shuffled after that. Both encoder and prediction t pairs for all hypotheses within the beam into a single ba and make a single joint network and softmax function cal • Word prefix trees. Instead of iterating over all possible ou symbols, we restrict the hypothesis expansion only to succ sor BPE units from a given node in the prefix tree. The effect of these optimization techniques on the overall r time factor (RTF) is shown in Table 2 for both time and alignm length synchronous decoding for the same CallHome WER 10.9%. The timing runs are measured on a 28-core Intel X 2.3GHz processor. TSD RTF ALSD RTF No optimization 1.21 0.89 + prediction net caching 0.72 0.61 + prediction net batching 0.61 0.48 + joint net batching 0.52 0.41 + prefix tree 0.41 0.30 Table 2. Effect of optimization techniques on the overall real-t factor for the two decoding algorithms. UΛݻఆ ݪͱͷϚϯϋολϯڑΛݻఆ
RNN-T 8.5 16.4 Hadian et al. (2018) [22] TDNN-LSTM LF-MMI 7.3 14.2 Xiong et al. (2017) [23] BLSTM (hybrid) 6.3 12.0 Han et al. (2017) [24] CNN-BLSTM (hybrid) 5.6 10.7 This system RNN-T 6.2 10.9 Table 1. Word error rate comparison with other single-model sys- tems for the Switchboard 2000 hours task. [23] and [24] use RNN LMs trained on external data sources whereas our model does not. networks apply dropout and drop-connect to the hidden-to-hidden
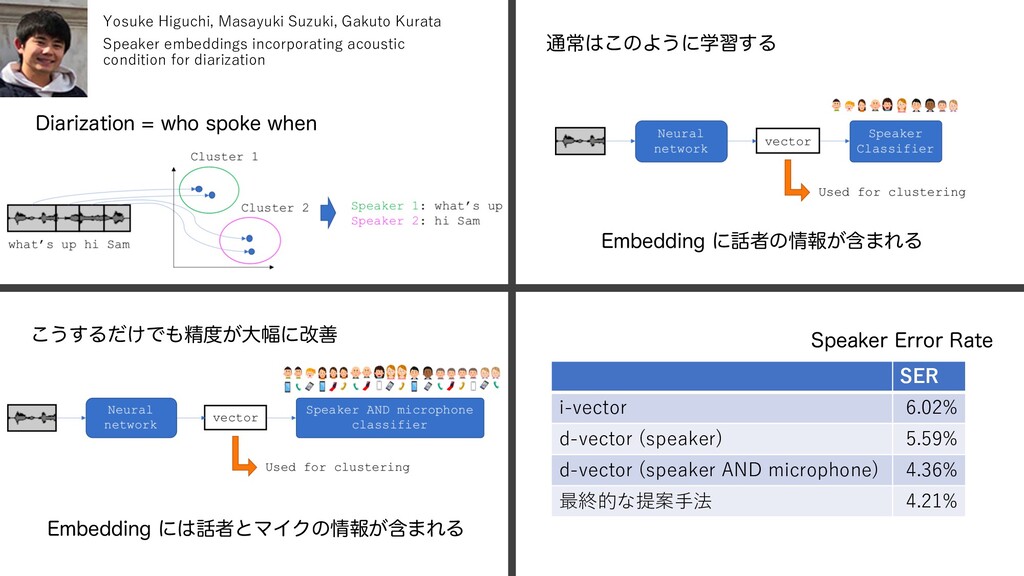
Gakuto Kurata Speaker embeddings incorporating acoustic condition for diarization Shintaro Ando, Masayuki Suzuki, Nobuyasu Itoh, Gakuto Kurata, Nobuaki Minematsu Converting written language to spoken language with neural machine translation for language modeling
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![- System Type SWB CH Battenberg et al. (2017) [11]](https://files.speakerdeck.com/presentations/a06ef1bec1cf49a7bd02e58b79b6abf1/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![ASR system [Akita+’10] ontaneous style. NMT Texts in written language](https://files.speakerdeck.com/presentations/a06ef1bec1cf49a7bd02e58b79b6abf1/slide_11.jpg){kind=link}