– columns user_id, post_id – uniqueness validation (nobody can give 2 likes to one post) • what if someone send two requests to „like” something to our app?
(?, ?)”, user_id, post_id); rescue DatabaseException::ForeignKeyViolation end • not bad? – on fail, sql statement rollbacks whole transaction – it can't be nicely fixed – you have to sacrifice – something (best case requires you to use a SAVEPOINT) • and with assumption you don't delete records
approximate result, so you would like to pick a sample of data, fast – pick first N rows – make a select with random value, sort by it and then get first N rows – use something like WHERE random() < 0.1
pages – if you request 0.01 sample, you get at least 0.01% of the table – in our case much more (136 instead of 10) – advantage: very fast! • just pick random pages from 736, in our case 1 page was enough – with x as (select * from test tablesample system ( 0.01 )) select * from x order by random() limit 10;
more flexible data • history – 9.2 – added json column, text but with validation – 9.3 – added very basic extraction functions • '{"a":1,"b":2}'::json->'b' – 9.4 – jsonb type, more querying functions, indexing – 9.5 – updating functions, more indexing
within it the right value? – '{"a":1, "b":2}'::jsonb @> '{"b":2}'::jsonb • Does the key/element string exist within the JSON value? – '{"a":1, "b":2}'::jsonb ? 'b' • Do any of these key/element strings exist? – '{"a":1, "b":2, "c":3}'::jsonb ?| array['b', 'c'] • Do all of these key/element strings exist? – '["a", "b"]'::jsonb ?& array['a', 'b'] • Returns the number of elements in the outermost JSON array. – json_array_length(json) • Returns set of keys in the outermost JSON object. – json_object_keys(json)
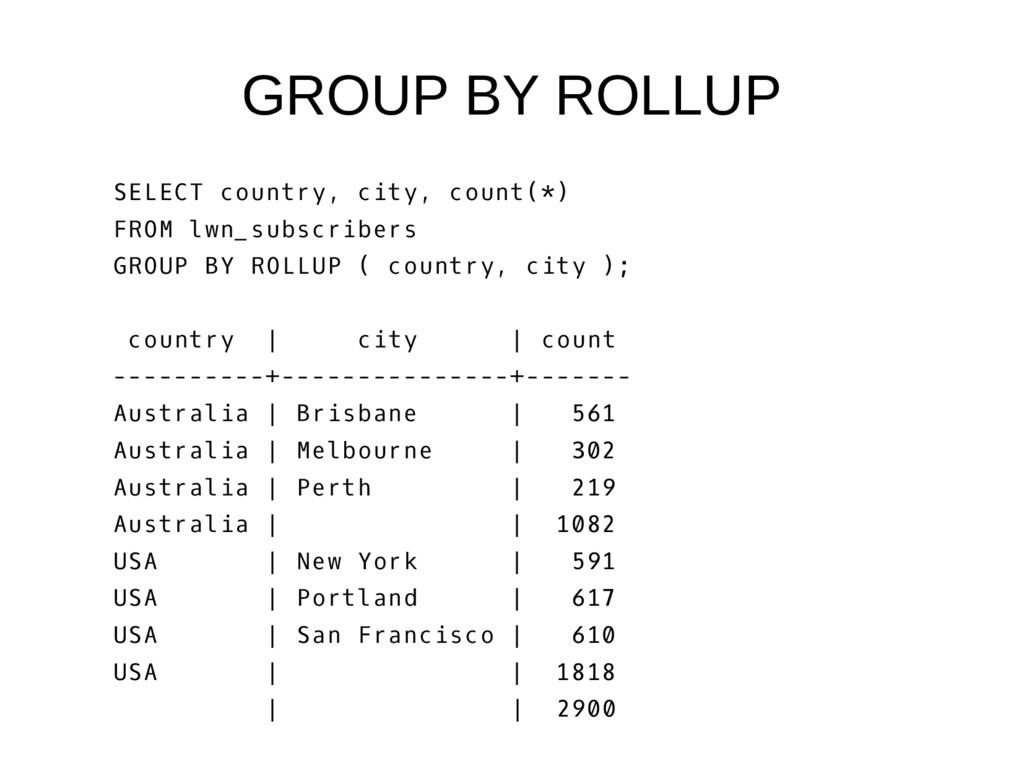
BY ROLLUP ( country, city ); country | city | count ----------+---------------+------- Australia | Brisbane | 561 Australia | Melbourne | 302 Australia | Perth | 219 Australia | | 1082 USA | New York | 591 USA | Portland | 617 USA | San Francisco | 610 USA | | 1818 | | 2900
audit – logs • special index for special case • like a B-tree – but leaf represents a range instead of one row – and in the range, data is found sequentially – less use of data storage
bleeding-edge software • Old way – compilation, adding external package sources, etc… • New way – Install docker – docker run -it jberkus/postgres95-test
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![JSON updates (9.5) • merging – '["a", "b"]'::jsonb || '["c",](https://files.speakerdeck.com/presentations/ff3f6c63ba3d4ed6a25c7d999f7f377d/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}