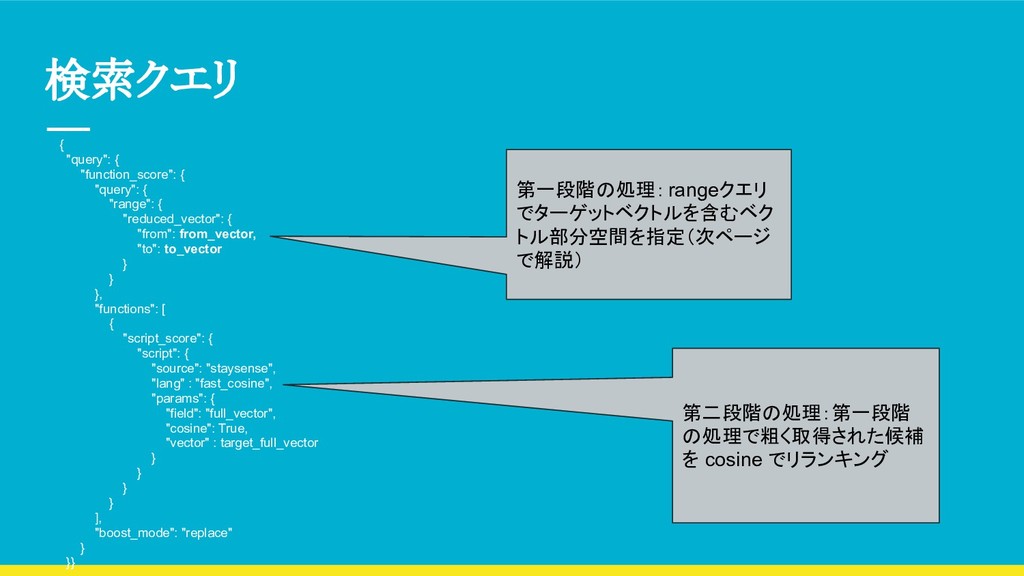
"reduced_vector": ",".join([str(x) for x in vector8]), "full_vector": base64.b64encode(np.array(vector200). astype(np.dtype('>f8'))).decode("utf-8"), })
[element -2.5 for element in vector] to_vector = [element + 2.5 for element in vector] return ",".join([str(x) for x in from_vector]), ",".join([str(x) for x in to_vector]) 下限ベクトル(入 力ベクトルの要 素から定数を引 いたもの) 上限ベクトル(入 力ベクトルの要 素に定数を足し たもの)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}