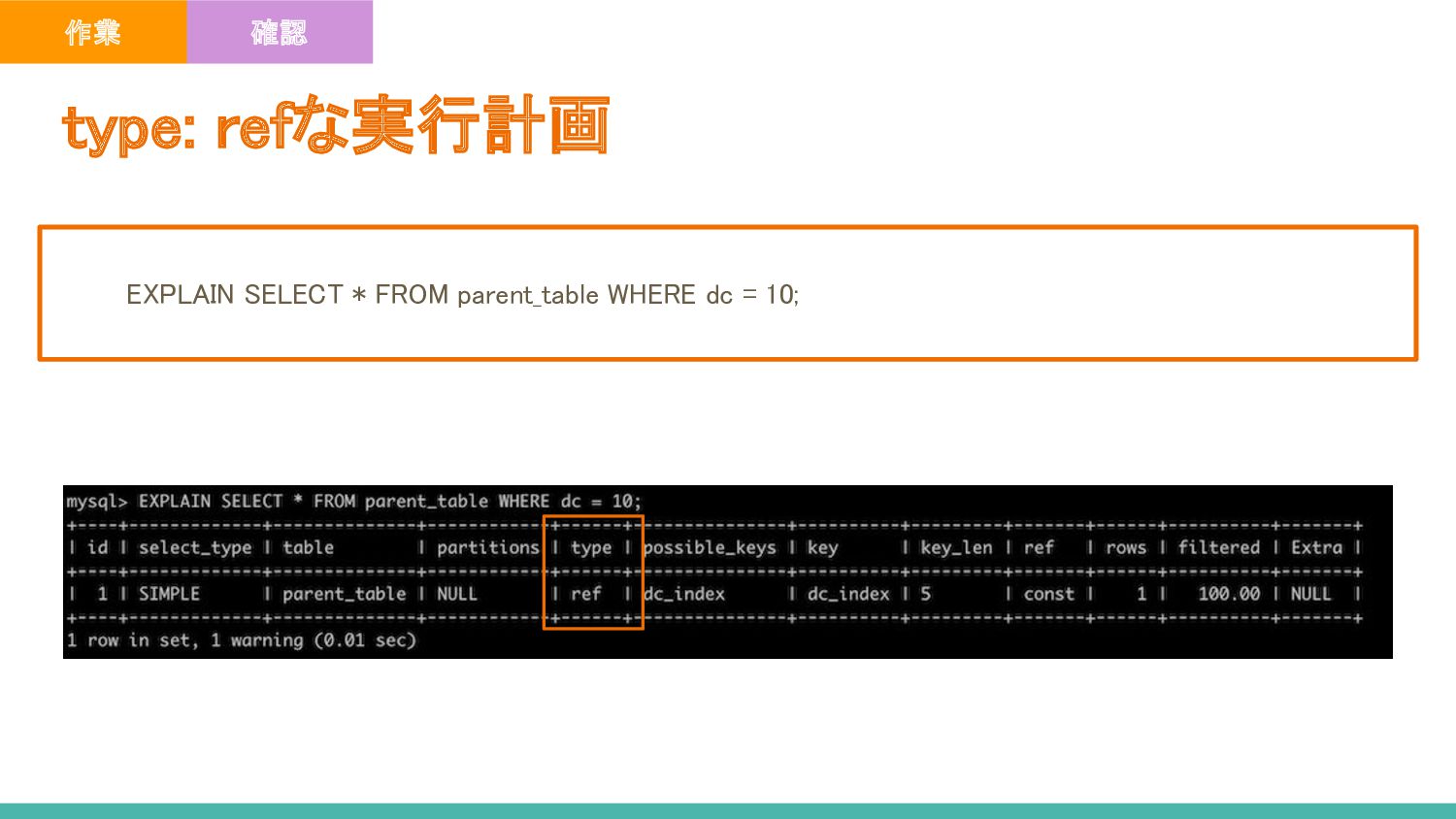
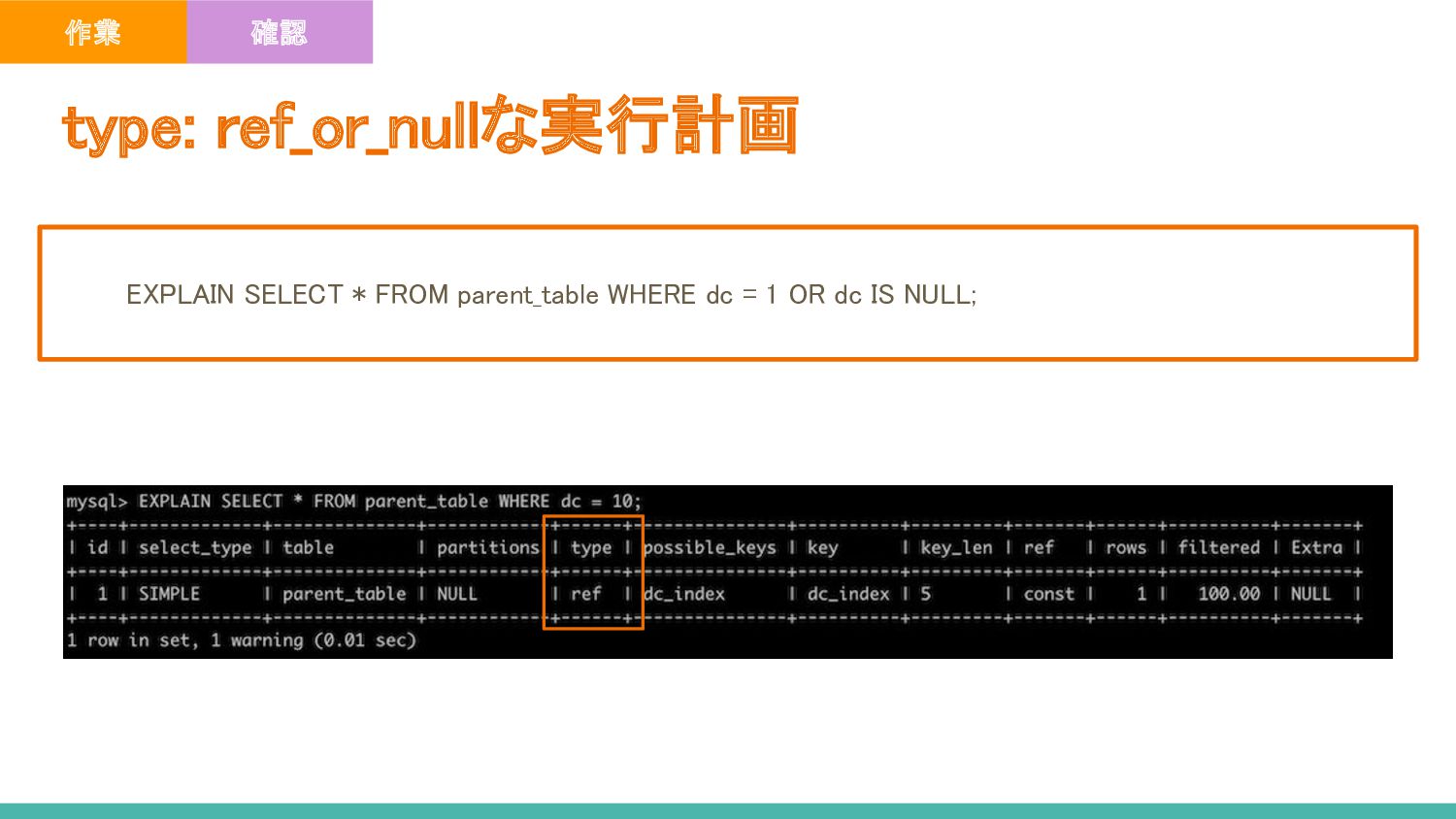
IS NULLと IS NOT NULLの検索にはインデックスを使える - prent_tableのdc_indexからカラムdcの値が1の箇所、dcの値がNULLの箇所を読み込み、行を取得している - 注意点 - レコード数が少ない場合はテーブルの全件スキャンが行われる場合がある type: ref_or_nullな実行計画 ポイント
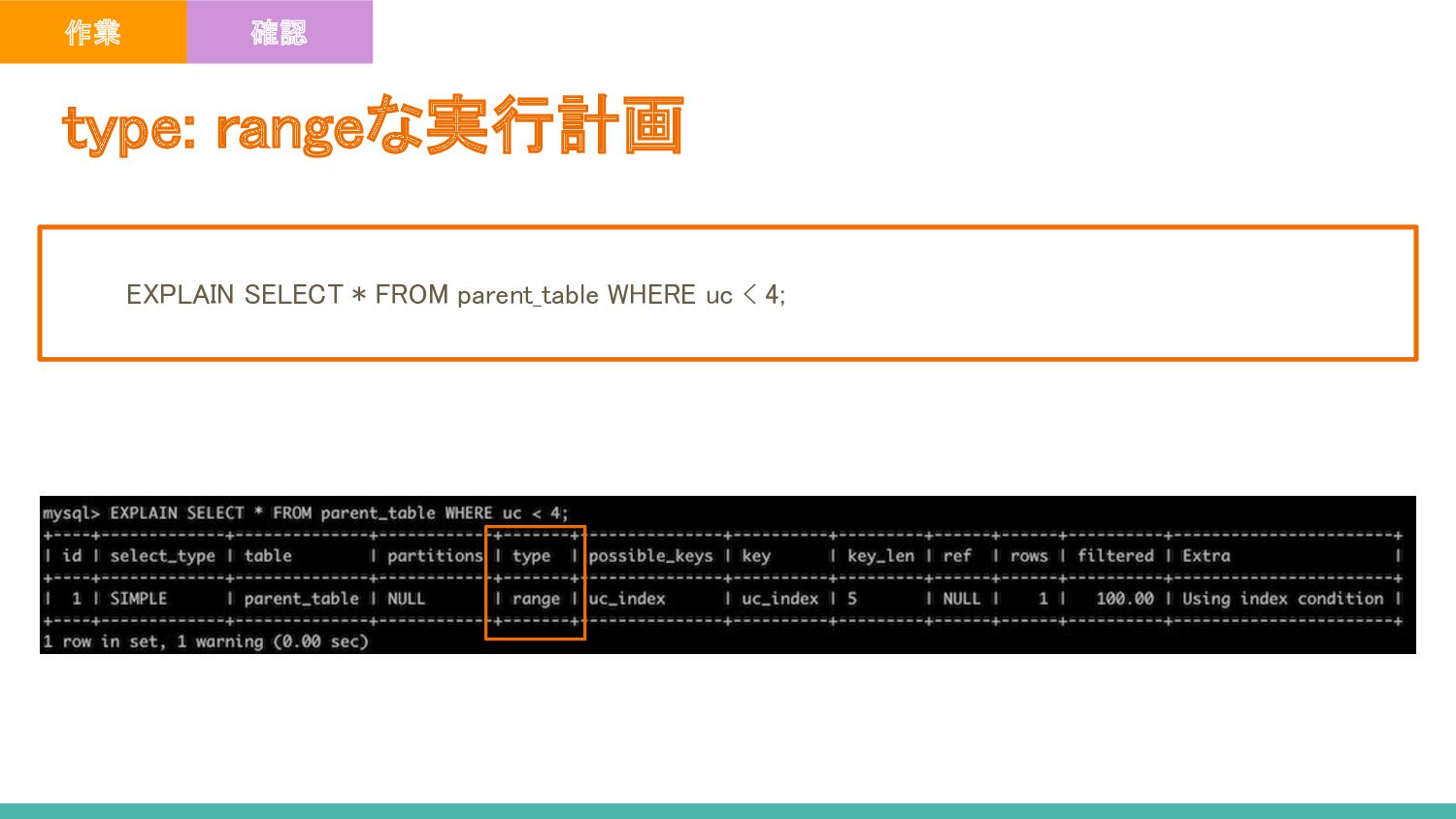
インデックスが有効でないカラムへの条件適用が必要な時(今回の例の nc < 4 の部分) - インデックスが貼られているカラムへのtype:rangeでの読み取り時 - その他の例 - SELECT dc FROM parent_table_copy WHERE dc IN (1, 4, 7); - type : rangeで範囲読み込みしてるためMySQLサーバでフィルタリングしなくても問題なさそうだがダメらしい Extra: Using where ポイント
上記例のケース - テーブルを絞り込まずにソートした場合 - EXPLAIN SELECT * FROM parent_table ORDER BY uc; - filesortはクイックソートのこと - ある程度のサイズであればメモリ上で、閾値を超えると一時ファイルを作ってソートするので遅い Extra: Using filesort ポイント
Group By句があるクエリでソートの条件に集約関数を利用 - SELECT dc, MIN(uc) FROM parent_table GROUP BY dc ORDER BY MIN(uc); - UNION実行時 - (SELECT * FROM parent_table) UNION (SELECT * FROM parent_table); - ディスク上に一時表が作られるので重たい処理になる Extra: Using filesort ポイント
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}