Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
2025/11/14 ロボセミでの発表資料
Search
takeofuture
November 14, 2025
Technology
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
2025/11/14 ロボセミでの発表資料
takeofuture
November 14, 2025
More Decks by takeofuture
See All by takeofuture
MarineGym 水中シミュレータ
takeofuture
0
57
BLUVIC(SportへのAI活用)ハッカソン発表資料
takeofuture
0
18
Forklift Goal Condition Reinforcement Learning by Gazebo + ROS2 topic
takeofuture
0
99
ROSAというLLM使ったROSエージェントをおもちゃに実装してみた話
takeofuture
0
240
20240827_LLM発表
takeofuture
0
300
Other Decks in Technology
See All in Technology
「AIに依存している」と 「AIを使いこなしている」の違い
k8yasuma
0
110
LLM/Agent評価:トップ営業の発言を「正解」にする 〜暗黙的正解による評価を営業資産に変える〜
takkuhiro
1
230
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
14
2.1k
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
860
Claude Code公式skillで 自分の仕事を少しずつ手放そう!(Claude Code開発ノウハウ大公開スペシャル by クラスメソッド)
kaym
1
480
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
180
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
210
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
3.1k
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
420
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
130
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
2
190
Making sense of Google’s agentic dev tools
glaforge
1
260
Featured
See All Featured
Technical Leadership for Architectural Decision Making
baasie
3
440
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
340
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
590
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Designing Experiences People Love
moore
143
24k
The Invisible Side of Design
smashingmag
301
52k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
180
Transcript
0 RoboFactory: Exploring Embodies Agent Collaboration with Compositional Constraints 第54回ロボティクス勉強会
コンピュータビジョンカンファレンス(ICCV2025)で 発表されたロボティクス関連の論文を自分なりに理解して要約紹介 柴田 たけお X: @takeofuture Yiran Qin, Li Kang, Xiufeng Song, Zhenfei Yin, Xiaohong Liu, Xihui Liu, Ruimao Zhang, Lei Bai ICVV 2025(POSTER)/ arXiv 2503.16408 https://github.com/MARS-EAI/RoboFactory https://iranqin.github.io/robofactory/ 3つの制約で、ロボは協調する
興味のある仕事 ▪ システム開発 ▪ 先端技術と情報技術の融合と応用 ▪ データサイエンス ▪ AI(生成AI,分析AI,識別AI), 統計や機械学習
▪ 愛知県名古屋市生まれ豊田市育ち ▪ 大学,大学院では地球物理専攻 ▪ 本業ロサンゼルス商社のデータサイエンティスト 個人でAI関連含むプロジェクト多数やったつもり ▪ 愛知県豊田市の空家に年数回滞在(日米2拠点生活) 趣味 ▪ キャンプやハイキング ▪ 自転車旅行 ▪ 青春18切符でのんびり列車旅行 ▪ 食べること 写真
▪ このジャンルのこのテーマを選んだ動機 ▪ 内容概要(複数ロボットの協調動作シミュレーション) ▪ この方法の特徴:(3つの制約でシミュレーション) ▪ 全体の工程 ▪ データ生成パイプライン
▪ 学習データ生成用シミュレータ ▪ コマンドの流れとデータ生成結果 ▪ 模倣学習とその成果 ▪ 補足:対象となるロボット型番 目次
このジャンルのこのテーマを選んだ動機 •人間の社会活動の中で通常複数の動作が協調して動かす必要がある(例:外科手術)。 •現場で必要なのは衝突回避・同時動作・手先の向きなど “物理に直結する制約”の担保。 •ここではGPT-4oを用いた高レベル計画+論理/空間/時間の制約を インタフェース化してチェックするという、 実運用に近い枠組みを出していて面白い。 •ManiSkillなどシミュレータでのデータ作成・評価が実用的。 (大量・安価・安全に反復生成/正解ラベルが取りやすい 制約違反の可視化・再学習ループが回しやすい)
•“動画を作る”だけでなく、物理法則はもちろんのこと“制約を守って動かす”層が必要。 高レベルAI(計画)× 制約インタフェース × シミュレータ評価 の組合せが鍵。
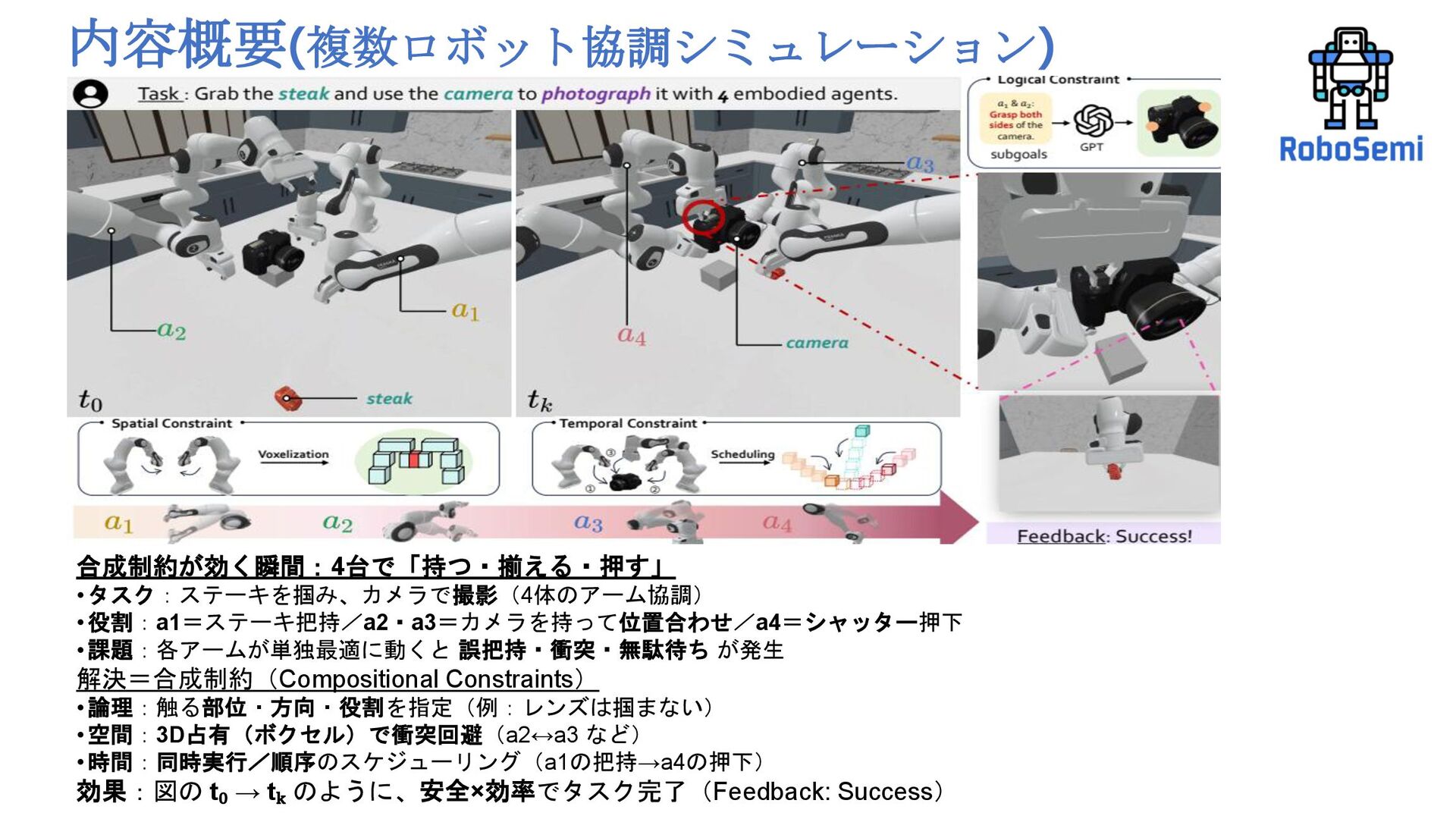
内容概要(複数ロボット協調シミュレーション) 合成制約が効く瞬間:4台で「持つ・揃える・押す」 • タスク:ステーキを掴み、カメラで撮影(4体のアーム協調) • 役割:a1=ステーキ把持/a2・a3=カメラを持って位置合わせ/a4=シャッター押下 • 課題:各アームが単独最適に動くと 誤把持・衝突・無駄待ち が発生
解決=合成制約(Compositional Constraints) • 論理:触る部位・方向・役割を指定(例:レンズは掴まない) • 空間:3D占有(ボクセル)で衝突回避(a2 a3 など) • 時間:同時実行/順序のスケジューリング(a1の把持→a4の押下) 効果:図の t₀ → tₖ のように、安全×効率でタスク完了(Feedback: Success)
この方法の特徴:3つの制約でシミュレーション ねらい:テキストの合成制約(論理・空間・時間)を物理的な判定基準に写像し、 各ステップの軌道を機械的に検証できるようにする。 ① 論理(Logical)— どこを・どの向きで触るか • 相互作用位置(Interaction Position):各3Dアセットに接触点を注釈(例:カメラの“ハンドル”と“シャッター”は別) •
相互作用方向(Interaction Direction):動作ごとの進入方向を注釈(例:シャッターは正面から押す) → 位置・姿勢がルールに一致しているかを判定 ② 空間(Spatial)— どこを占有し、衝突しないか • 深度+関節状態から3D占有を構築(5cm³ボクセル) • 変化中のアームと周囲の占有関係をチェックし、衝突/侵入を検出 → 空間ロジック(作業域・最小距離など)に違反しないかを判定 ③ 時間(Temporal)— いつ・どう並行するか • サブゴールセット Gₙₑₓₜ に対し、動的占有の時間推移をモデル化 • 同時実行/順序の整合を解析し、非合理なスケジューリングを防止 → 「同時持ち上げ ±0.5s」「A完了→5s後にB」等を満たすかを判定 効果:テキスト制約 → 物理表現(位置・方向/3D占有/時間占有)→ 自動チェック 違反なら停止+理由フィードバック→再計画、合格なら前進。 ⇒ 安全 × 効率なマルチ協調データを安定に生成。
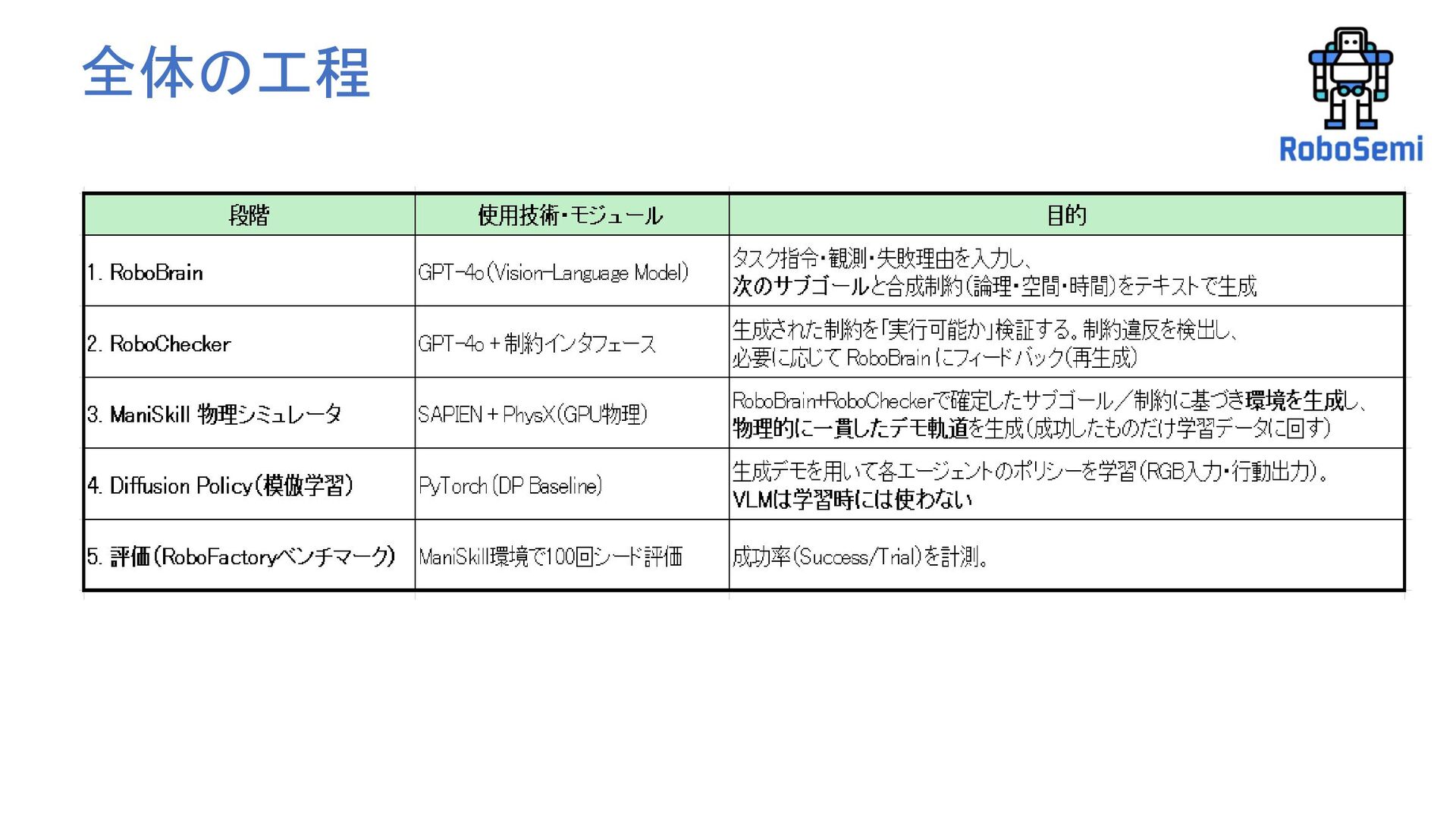
全体の工程
データ生成パイプライン Task / Images / Previous Feedback │ ▼ GPT-4o
(RoboBrain) ── subgoals + constraints (text/JSON風) │ 例: {"Logical":...,"Spatial":...,"Temporal":...} │ (Pythonパーサで数値引数に変換) ▼ Motion Primitives (Python関数) MOVE/GRASP/LIFT/ALIGN/PRESS(...params) │ └─ 目標姿勢(SE3)・接触点・進入方向・速度など ▼ Trajectory Generator (Python) 目標の離散軌道: waypoints → action 列 形式: trajectory ∈ ℝ^[T × (8 × N_agents)] # Franka=7関節+gripper=1 │ ▼ Simulator (ManiSkill / SAPIEN) step(action_t) at t=1..T ── obs_t 入力 action_t: ℝ^[8×N] (float32) 出力 obs_t: - RGB画像: uint8 [H×W×3](例 320×240) - 状態: q∈ℝ^7, qd∈ℝ^7, gripper∈ℝ^1(float32) - (任意)接触/衝突フラグ等 │ ▼ RoboChecker (Python + GPT-4oでCheckCode生成) テキスト制約 + obs + trajectory → 物理インターフェースで検証 VI=Validate_Interaction(接触点) VD=Validate_Direction(進入方向/姿勢) VSO=Validate_Spatial_Occupancy(3D占有/衝突) VS=Validate_Scheduling(同時/順序) 出力: {valid: bool, reason: str} ├─ valid=false → reason を Feedback として RoboBrain に戻して再計画 └─ valid=true → 次ステップ/次サブゴールへ 概念フロー •RoboBrain(GPT-4o) • 入力:タスク指示(text)、観測(画像/要約)、前回の違反理由(text) • 出力:subgoals(text/JSON風)、constraints={Logical/Spatial/Temporal}(text) • テキスト→(Pythonパーサ)→ モーションプリミティブ( MOVE/GRASP/LIFT/ALIGN/PRESS(...))呼び出し → 暫定軌道を合成 •Trajectory / Action • 形式:trajectory ∈ float32 [T, 8×N_agents](Franka:7関節+gripper=8 ) • 実行時(Gym)はマルチアームなら {uid: action8} の辞書を渡す実装もあり (保存は連結形が多い) •Simulator(ManiSkill / SAPIEN) • 入力:action_t ∈ float32 [8×N] • 出力(Observation):画像 uint8[H,W,3](+必要なら Depth/Seg)、 状態(q, qd, gripper など float32) •RoboChecker(Python + GPT-4oでCheckCode生成) • テキスト制約+obs+trajectory → 物理インターフェースで検証 • VI(接触点)/VD(進入方向)/VSO(3D占有)/VS(同時・順序) • 出力:{valid: bool, reason: str} (false なら理由を RoboBrain に返し再計画) 要点:計画・制約生成=GPT-4o(テキスト)/実行=数値アクション。 RoboCheckerがテキスト制約を数値の判定に写像し、検証→再計画で安全・効率に収束。
RoboBrain での GPT-4o 利用サンプル タスク指示・観測・過去の違反を入れて、 サブゴールと合成制約(Logical/Spatial/Temporal)を 構造化テキスト/JSONで出させるプロンプト。 RoboChecker 側での GPT-4o
利用サンプル “テキスト制約 → どの検証器(VI/VD/VSO/VS)をどう呼ぶか” のCheckCode生成。
ManiSkill:GPU対応ロボット操作シミュレータ •概要 ManiSkill はロボット操作・模倣学習向けの高速物理シミュレータ。 GPU並列化された SAPIEN + NVIDIA PhysX を基盤に構築。
https://maniskill.readthedocs.io •特徴 • GPUで数千環境を同時シミュレート(30,000 FPS超) • 高精度な接触・摩擦・関節制約をPhysXが再現 • RGB/Depth画像・状態情報をリアルタイム生成 • 強化学習/模倣学習のデータ生成・評価基盤 •物理エンジン PhysX が剛体力学・ジョイント拘束・摩擦・反発を解き、 SAPIEN がカメラ・ロボット・レンダリングを統合。 参考 ManiSkill3: GPU Parallelized Robotics Simulation (arXiv 2024) GitHub: haosulab/ManiSkill 学習データ生成用シミュレータ
コマンドの流れとデータ生成結果(GITHUBレポのコマンド解釈) GITのサンプルではLift Barrierを例示しているがTake Photoを試行 python script/run_task.py configs/table/take_photo.yaml # 1エピソードだけ“手書きプラン”で実行・可視化 *tasks/take_photo.py
#タスク本体、4アーム構成,「物体を所定位置へ」「カメラ2本で整準」「最後の1本がシャッター押下」等の成功条件や観測を定義 *planner/solutions/take_photo.py #モーションの台本、これが起動の設計図 *planner/motionplanner.py #間接角のシークエンス *assets/objects/{camera,meat}_annotated}/model_data.json #例えばcameraであれば left_handle / right_handle / shutter 等のラベル付き点・法線を記録 *configs/table/take_photo.yaml #オブジェクトをどこに置くか、アームの初期姿勢、カメラの位置/解像度、乱数ゆらぎなどを記述。randp_scale / randq_scale に基づく物体配置・姿勢の微小ランダム化 >>>最初の環境設定などは乱数で揺らぐがその後と手続きはすべて決め打ち python -m robofactory.script.generate_data --config robofactory/configs/table/take_photo.yaml --num 150 --save-video #模倣学習データ生成 >>>基本は上記RUN_TASKと同じだがManiSkillで試行を繰り返し、指定数「成功エピソード」が貯まるまで回し成功回だけを保存,模倣学習用の学習データにする。 上記150の成功起動データを学習データとして模倣学習させる。 GitHub版には,論理/空間/時間の“汎用制約インターフェース(RoboChecker)”は省略されている。 代わりに,制約は「台本+注釈+物理エンジン」に“埋め込み”で近似 RoboFactory Task "Takeo_Photo" 学習データ成功例:決め打ちのロジックで作成 http://www.youtube.com/watch?v=A8sFRM80BuQ
模倣学習とその成果 今回実際にコードを動かし 試行を150から200に増やすことで成功率は24%に上昇しているので まだまだ試行を増やしてやれば精度はさらに上がる可能性あり シ ミ ュ レ ー タ
で 模 倣 学 習 し た 4 本 ア ー ム の 協 調 作 業 の 成 功 例 右:模倣学習の結果(成功例) https://youtu.be/KRkrcWa8T2Y
補足:対象となるロボット型番 何をシミュレートしている? • ロボット:Franka Emika Panda(7自由度)+平行グリッパ(シミュレータではグリッパ1DoFとして扱い、1アーム=8次元:7関節+グリッパ) • 台数:タスクにより 1〜4台(TakePhoto は4台など)
• 制御:関節位置制御(pd_joint_pos)で action_t ∈ ℝ^[8×N] を毎ステップ投げる • 観測:各アームの視点RGB+グローバルRGB(Depth/Segは構成次第) 実世界で互換性が高い実機は? • Franka Emika Panda + Franka Hand ◦ DoF・関節順・可動域・位置/インピーダンス制御が近く、libfranka/ROS のエコシステムも豊富。 ◦ マルチビュー・エゴ視点カメラも現実に取り付けやすい。 その他代替(調整必要) • Kinova Gen3(7DoF)、KUKA LBR iiwa(7DoF)、UFactory xArm 7(7DoF) ◦ 7DoFで軌道生成・可動域の相性は比較的良い。 ◦ グリッパはRobotiq 2F-85/140等の平行グリッパを使うとシミュレーションの把持モデルに近づく。 • UR5e(6DoF) ◦ 6DoFでも可だが「冗長性なし」になるため台本(solutions)やIKを少し調整が必要。 sim→real の実務チェック(要点) 1. 関節順序・正負・リミットを合わせる(Franka準拠) 2. 座標系(ベース/EE/カメラ)と単位(m・rad)を一致 3. グリッパ開度→実機幅のスケーリング 4. カメラ:内外部パラメータ・取り付け位置を YAML と揃える 5. 制御周期(シミュレータのΔt vs 実機制御周波数)と遅延を補償 6. 把持点注釈(model_data.json)の接触点・方向を実機に合わせて再定義可能にしておく **論文&実装は“Franka Panda前提のマルチアーム操作”**です。 http://www.youtube.com/watch?v=DTJi9ttrViY Robotic Materials’ Smart Hand on Franka Emika’s Panda Bin picking using the FCI research interface https://robodk.com/robot/ja/Franka/Emika-Panda
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}