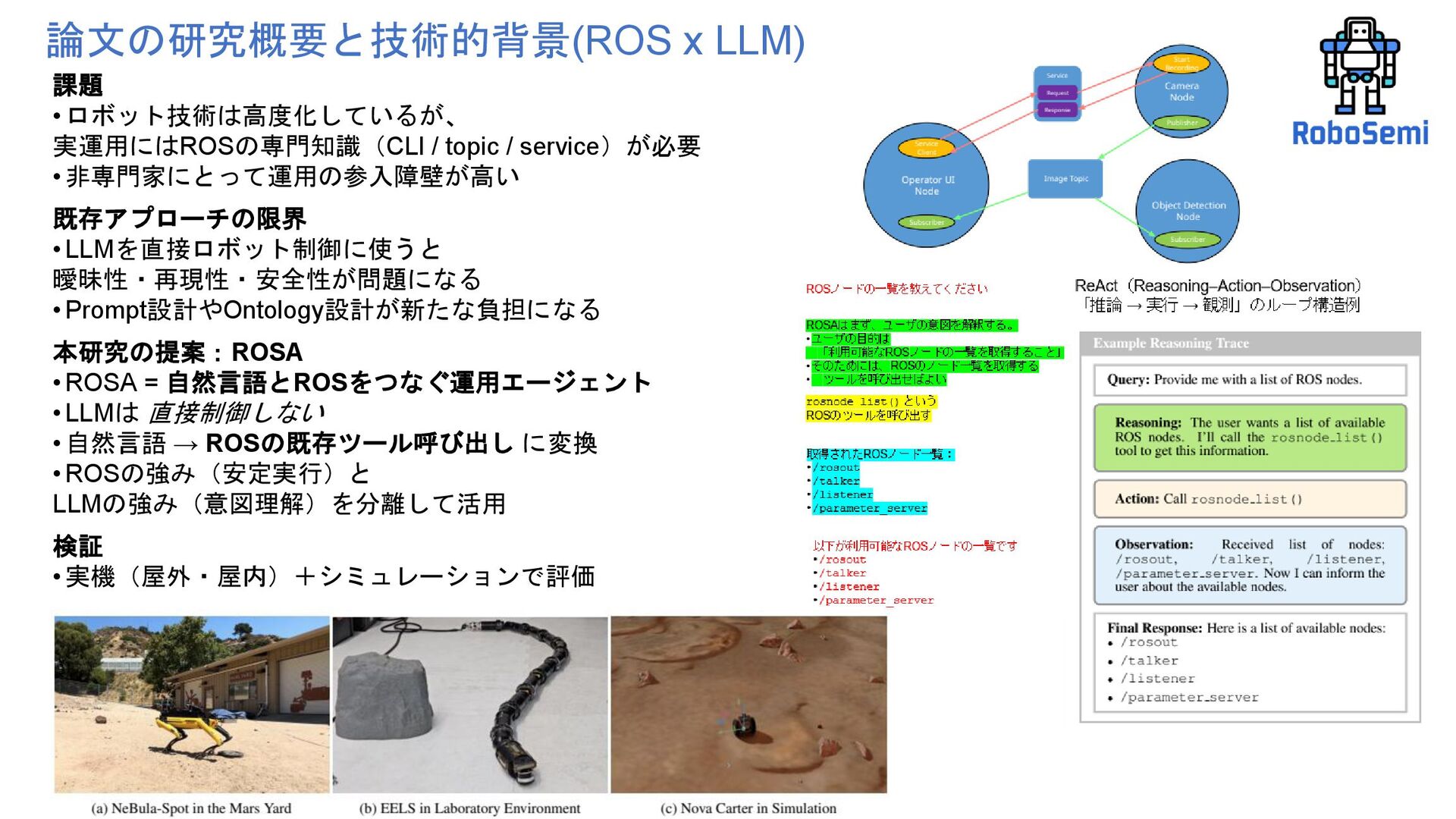
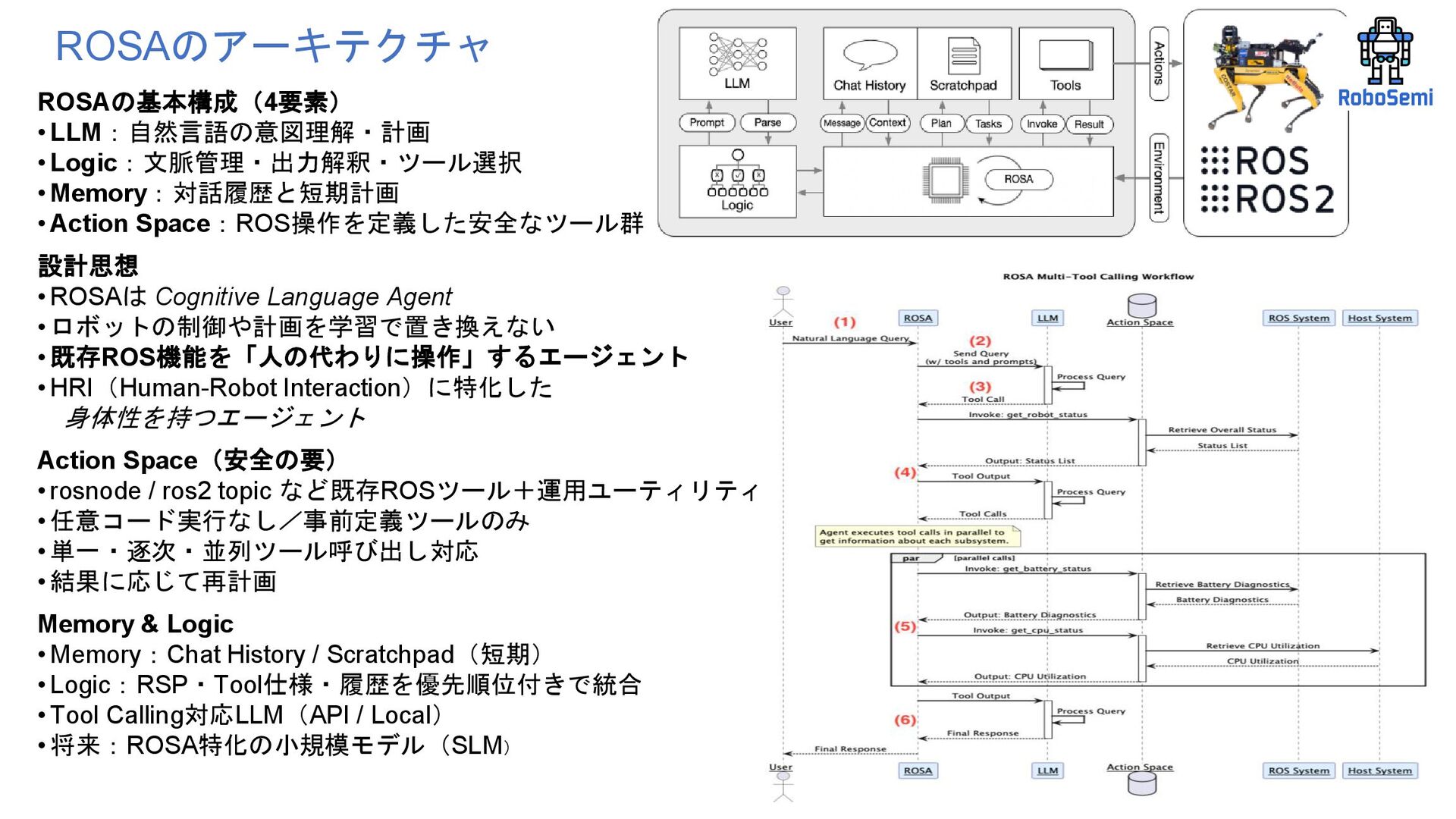
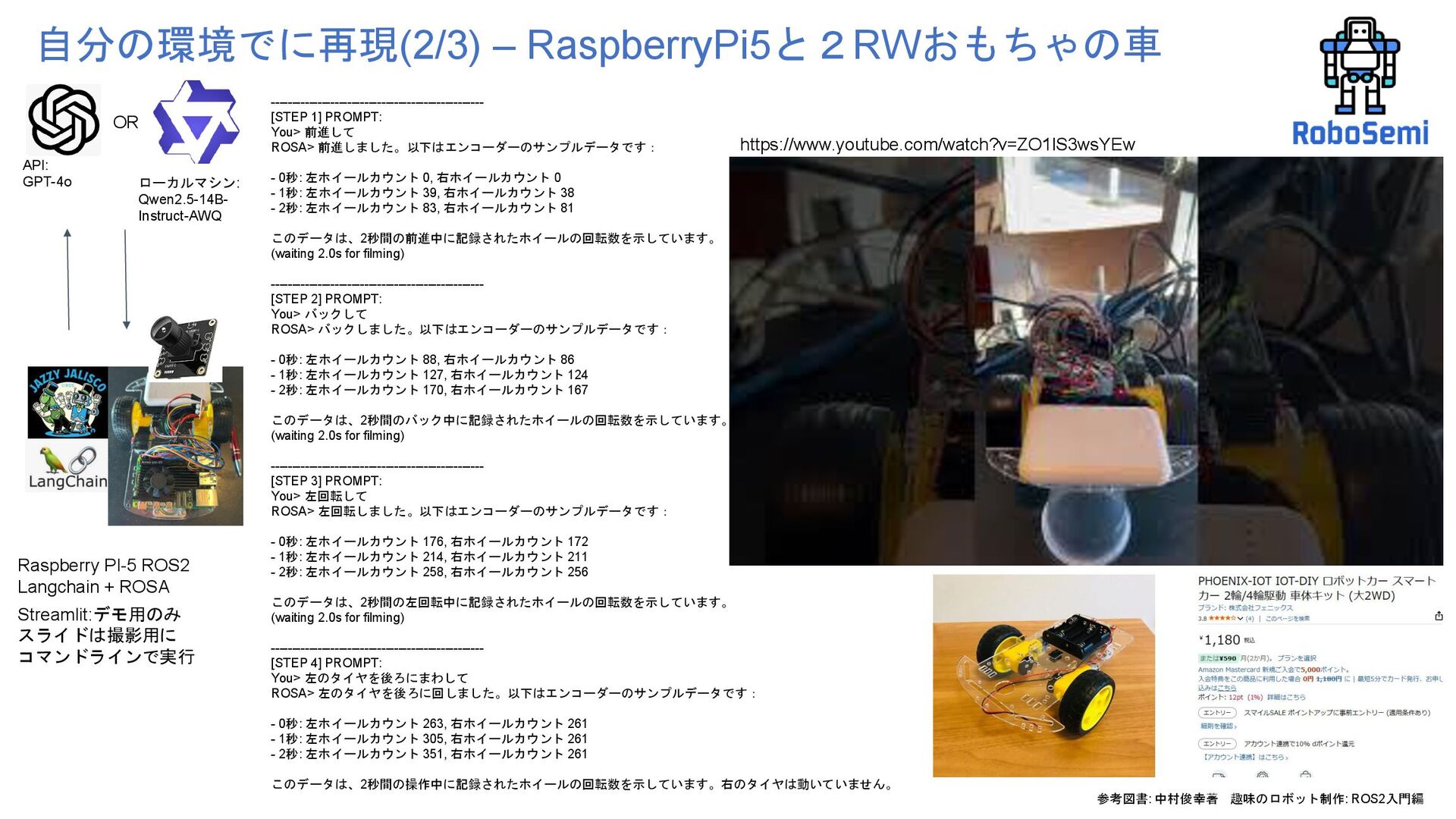
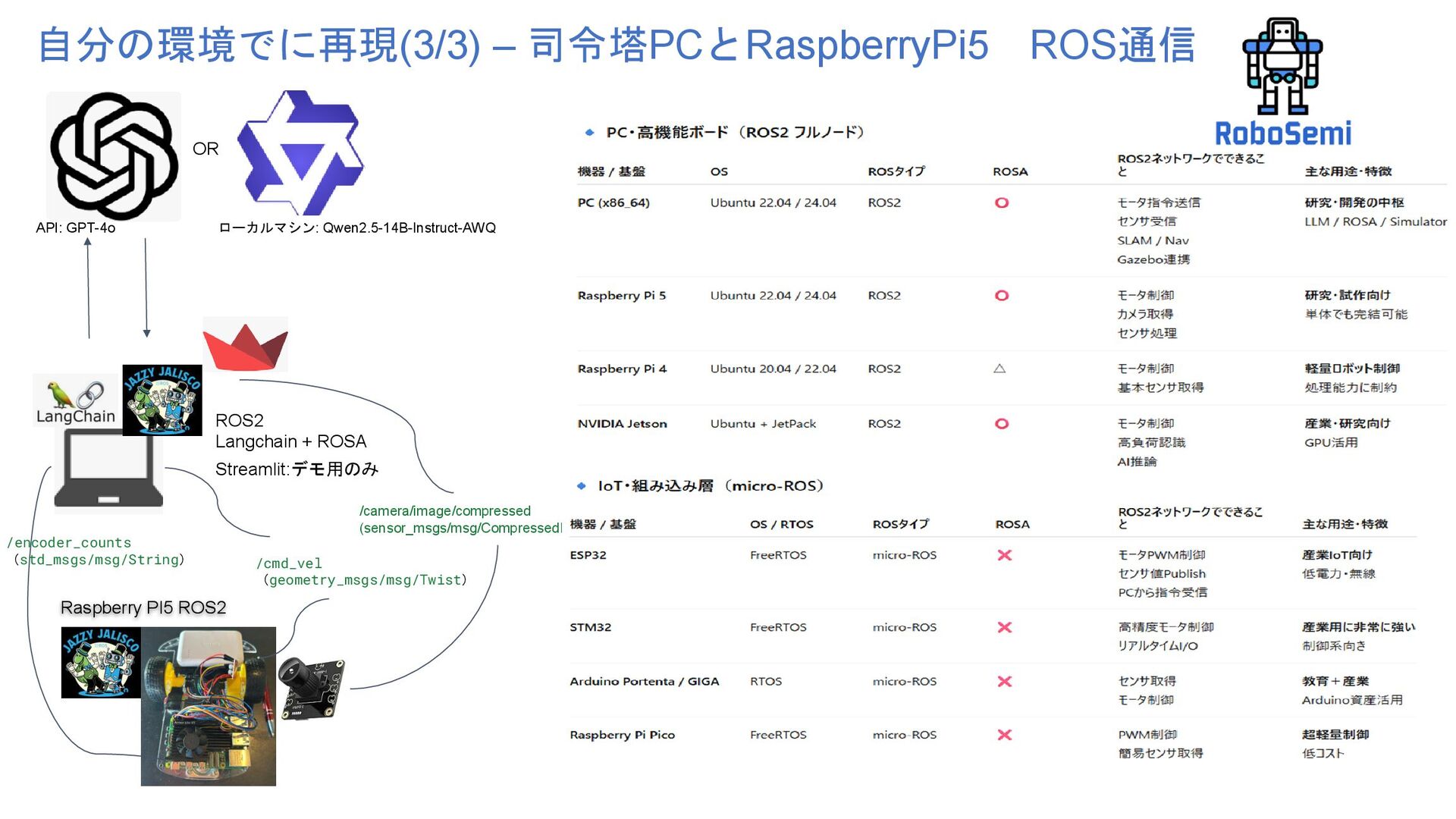
Operating System Agent 第55回ロボティクス勉強会 Authors: Rob Royce, Marcel Kaufmann, Jonathan Becktor, Sangwoo Moon, Kalind Carpenter,Kai Pak, Amanda Towler, Rohan Thakker, Shehryar Khattak Affiliation: NASA Jet Propulsion Laboratory California Institute of Technology https://arxiv.org/pdf/2410.06472 https://github.com/nasa-jpl/rosa 自然言語でロボットを操作する 電子工作、ロボティクスの初心者が ROSAというLLM使ったROSエージェントをおもちゃに実装してみた話
NeBula autonomy stack * JPL Mars Yard(屋外・不整地) * Visual Language Model(VLM)を搭載 •できること * 立つ・歩く・回転などの基本動作 * カメラ映像の内容を自然言語で説明 * ROSツール操作はすべてROSAが 内部で処理 •特徴的な点 動作前に確認を要求(安全確認) 操作は会話ベースで進行 ユーザ: 「ねえ Spot、立ち上がって。」 ROSA: 「立ち上がりました。次は何をしますか?」 ユーザ: 「1メートルほど前に進んで、左に15度回転して。」 ROSA: 「前に1メートル進み、左に15度回転します。安全を確認してください。」 ユーザ: 「うん、安全だから実行して。」 ROSA: 「前に1メートル進み、左に15度回転しました。次はどうしますか?」 ユーザ: 「カメラには何が見えている?」 ROSA: 「砂地の開けた場所が見えます。大きな岩が点在していて、左に20メートルほどのところに木々があり、右前方25メートルほどの位置に建物が見えます。」 ユーザ: 「なるほど。じゃあ、カメラ映像を見せて。」 ROSA: 「カメラ映像を表示しています。次は何をしますか?」 ROSA Demo: NeBula-Spot in JPL's Mars Yard This video demonstrates basic command and control plus scene understanding using ROSA: The Robot Operating System Agent. ROSA was developed at NASA Jet Propulsion Laboratory to enable advanced human-robot interaction using natural language. Read the paper on arXiv: https://arxiv.org/abs/2410.06472v1 Check out ROSA on GitHub: https://github.com/nasa-jpl/rosa https://www.youtube.com/watch?v=mZTrSg7tEsA
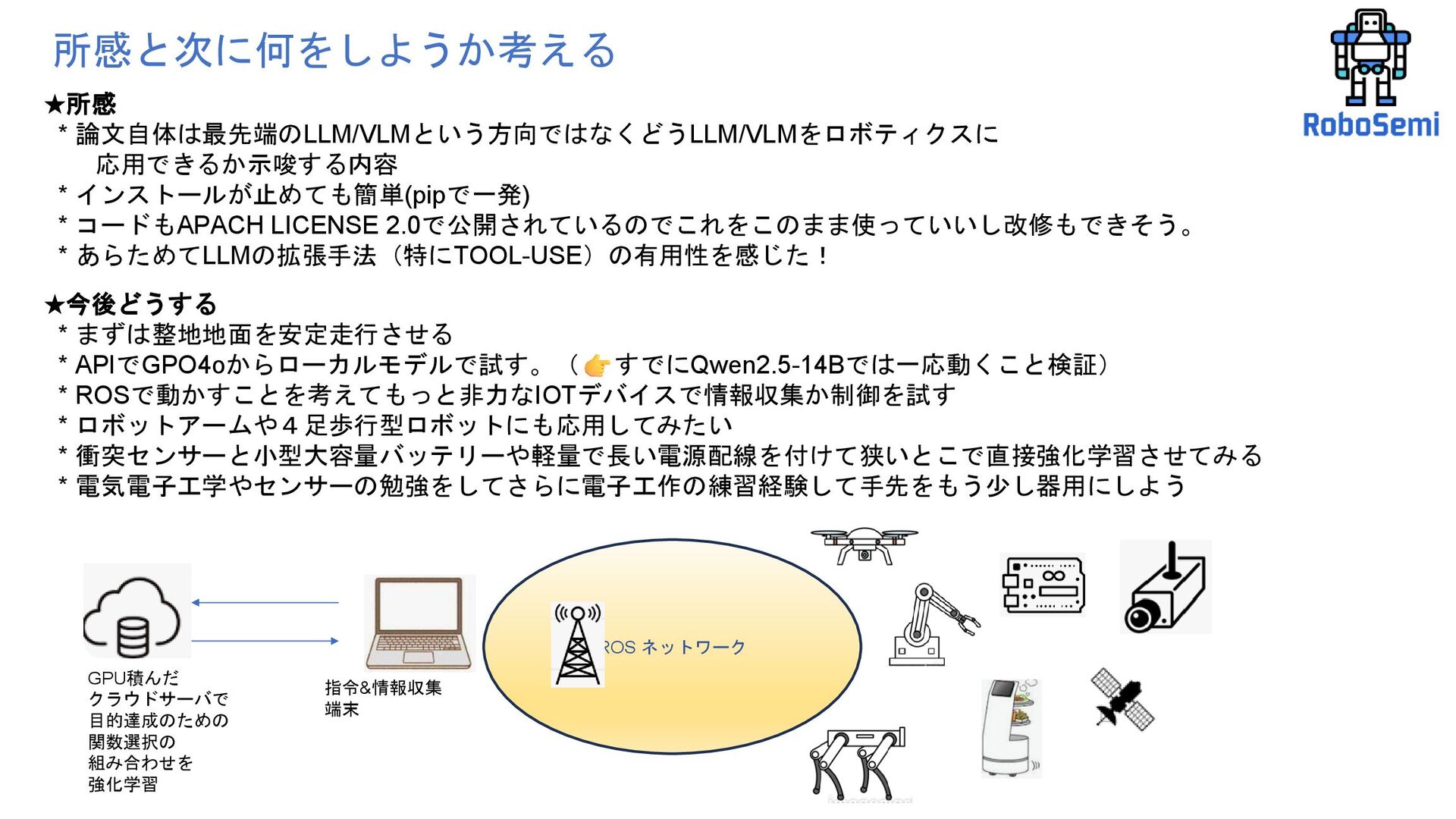
* LiDAR・カメラ・移動を統合 •特徴 * 曖昧な命令を * ROSAが自律的に分解 * マルチステップ・マルチツール実行 * 初心者でも安全に試行可能 ★3つのデモから見えたこと。 自然言語を 有効なROS操作に変換 不可能な命令には 対話で誘導 ロボットの状態を 文脈付きで説明 専門知識の学習コストを大幅に削減 ユーザ: 「行けるところまで 前に進んで。」 ROSA: 「できるだけ 前進するためには、 障害物や危険がないか 確認する必要があります。 LiDARスキャンを 実行しますか?」 ユーザ: 「はい、お願いします。」 ROSA: 「LiDARスキャンを 実行しました。 約4メートル前方に 障害物を検知しました。 進んでもよろしいですか?」 ユーザ: 「はい、進んでください。」 ROSA: 「了解しました。 4メートル前進しました。」 ユーザ: 「周囲を360度見渡した 映像を見せて。」 ROSA: 「カメラを回転させて、 複数のスナップショットを 撮影できます。 何枚撮影しますか?」 ユーザ: 「カメラの視野角は 90度だと考えて。」 ROSA: 「視野角が90度の場合、 周囲360度をカバーするために 4枚の画像を撮影しました。」 ROSA Demo: Carter with Nvidia IsaacSim This video demonstrates the integration of ROSA with Nvidia IsaacSim. ROSA was developed at NASA Jet Propulsion Laboratory to enable advanced human-robot interaction using natural language. Read the paper on arXiv: https://arxiv.org/abs/2410.06472v1 Check out ROSA on GitHub: https://github.com/nasa-jpl/rosa https://www.youtube.com/watch?v=mm5525G_EfQ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}