rsp, 0x30 xor r11d, r11d mov r10d, edi test edi, edi jng 0x023CFFCB mov ecx, [rdx+0x0C] test ecx, ecx jbe 0x023CFFCF mov ebx, edi dec ebx cmp ebx, ecx jnc 0x023CFFCF mov edi, [r8+0x0C] test edi, edi jbe 0x023CFFCF cmp ebx, edi jnc 0x023CFFCF mov ecx, [r9+0x0C] test ecx, ecx jbe 0x023CFFCF cmp ebx, ecx jnc 0x023CFFCF xor eax, eax mov ebx, [r8+r11*4+0x10] add ebx, [rdx+r11*4+0x10] mov [r9+r11*4+0x10], ebx add eax, ebx inc r11d cmp r11d, 0x01 jl 0x023CFF1B mov edi, r10d add edi, 0xFFFFFFFD mov ebx, 0x80000000 cmp r10d, edi cmovl edi, ebx cmp r11d, edi jl 0x023CFF53 mov ebx, r11d jmp 0x023CFFA3 mov r11d, ebx mov ecx, [rdx+r11*4+0x10] add ecx, [r8+r11*4+0x10] mov [r9+r11*4+0x10], ecx add eax, ecx mov ebx, r11d add ebx, 0x04 movsxd rbp, r11 mov r11d, [rdx+rbp*4+0x14] add r11d, [r8+rbp*4+0x14] mov [r9+rbp*4+0x14], r11d mov esi, [r8+rbp*4+0x18] add esi, [rdx+rbp*4+0x18] mov [r9+rbp*4+0x18], esi mov ecx, [r8+rbp*4+0x1C] add ecx, [rdx+rbp*4+0x1C] mov [r9+rbp*4+0x1C], ecx add eax, r11d add eax, esi add eax, ecx cmp ebx, edi jl 0x023CFF50 cmp ebx, r10d jnl 0x023CFFBF mov ecx, [r8+rbx*4+0x10] add ecx, [rdx+rbx*4+0x10] mov [r9+rbx*4+0x10], ecx add eax, ecx inc ebx cmp ebx, r10d jl 0x023CFFA8 add rsp, 0x30 pop rbp test [0x00000000004C0000], eax ret xor eax, eax jmp 0x023CFFBF mov rbp, rdx mov qword [rsp], r8 mov qword [rsp+0x08], r9 mov [rsp+0x10], r10d mov edx, 0xFFFFFF86 nop call 0x023A90A0 int3 hlt hlt hlt hlt hlt hlt hlt hlt hlt hlt hlt int sum = 0; for (int i = 0; i < size; i++) { c[i] = a[i] + b[i]; sum += c[i]; } return sum; www.takipi.com
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Simple Example – Part 2 c[i] = a[i] + b[i];](https://files.speakerdeck.com/presentations/2e235cf033680131532c464fdf997ddb/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
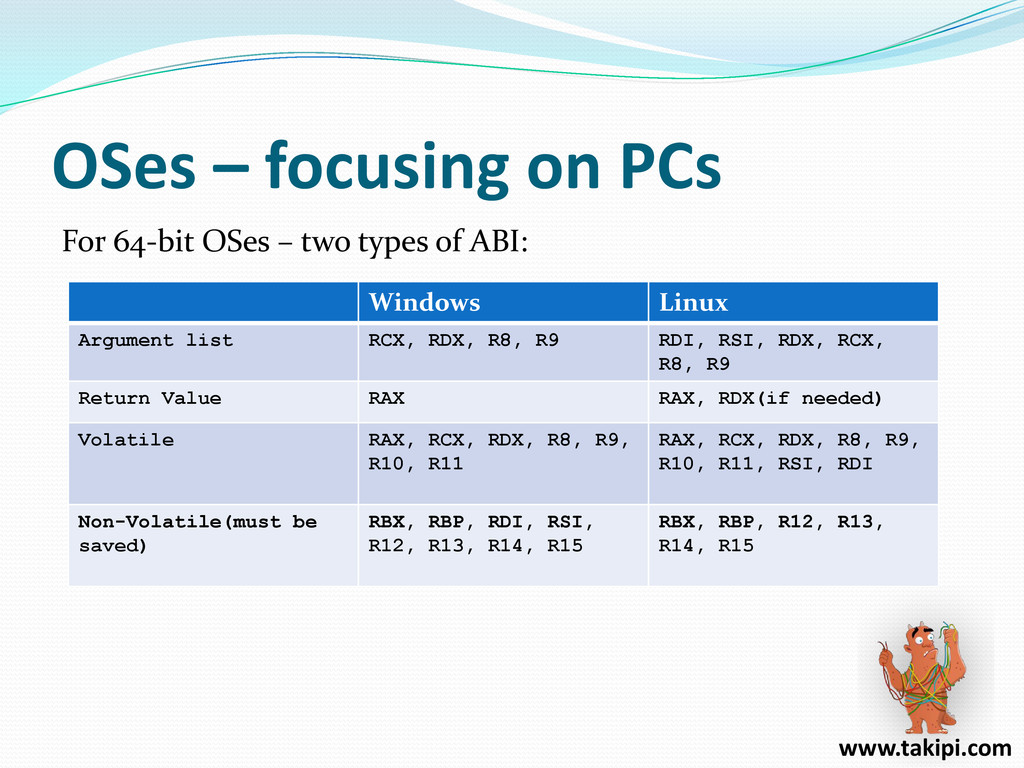{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![And after JIT…(~100 Insn.) mov [rsp-0x00006000], eax push rbp sub](https://files.speakerdeck.com/presentations/2e235cf033680131532c464fdf997ddb/slide_55.jpg){kind=link}
![And after JIT…(~100 Insn.) mov [rsp-0x00006000], eax push rbp sub](https://files.speakerdeck.com/presentations/2e235cf033680131532c464fdf997ddb/slide_56.jpg){kind=link}
![And after JIT…(~100 Insn.) mov [rsp-0x00006000], eax push rbp sub](https://files.speakerdeck.com/presentations/2e235cf033680131532c464fdf997ddb/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
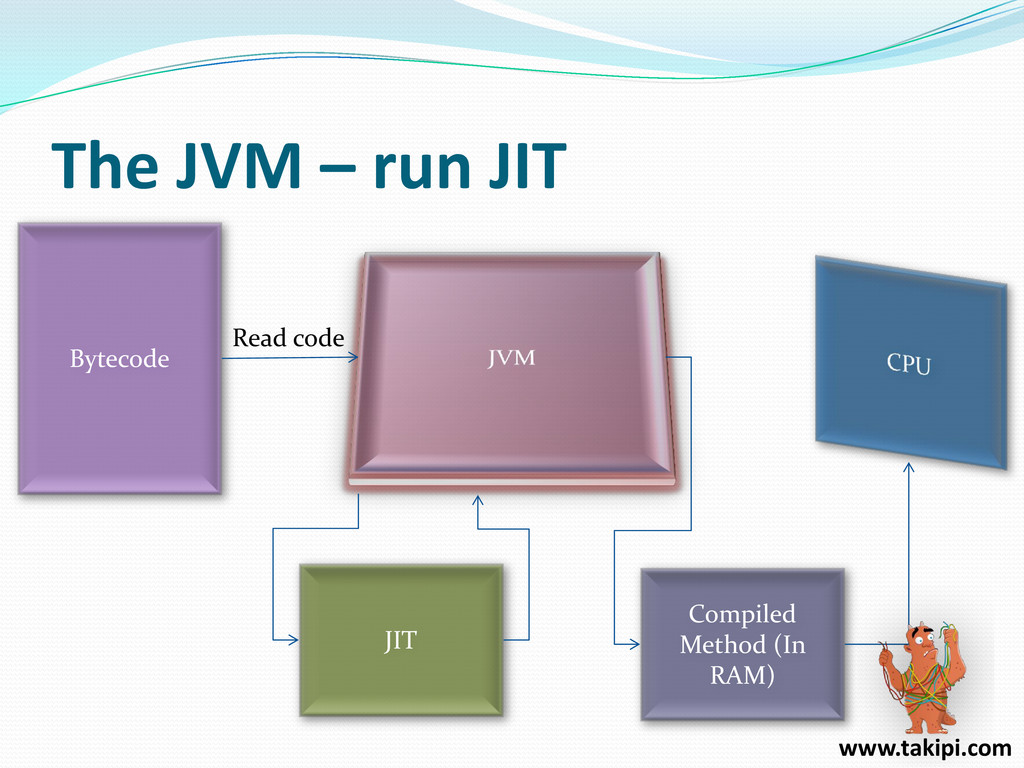{kind=link}
{kind=link}
{kind=link}
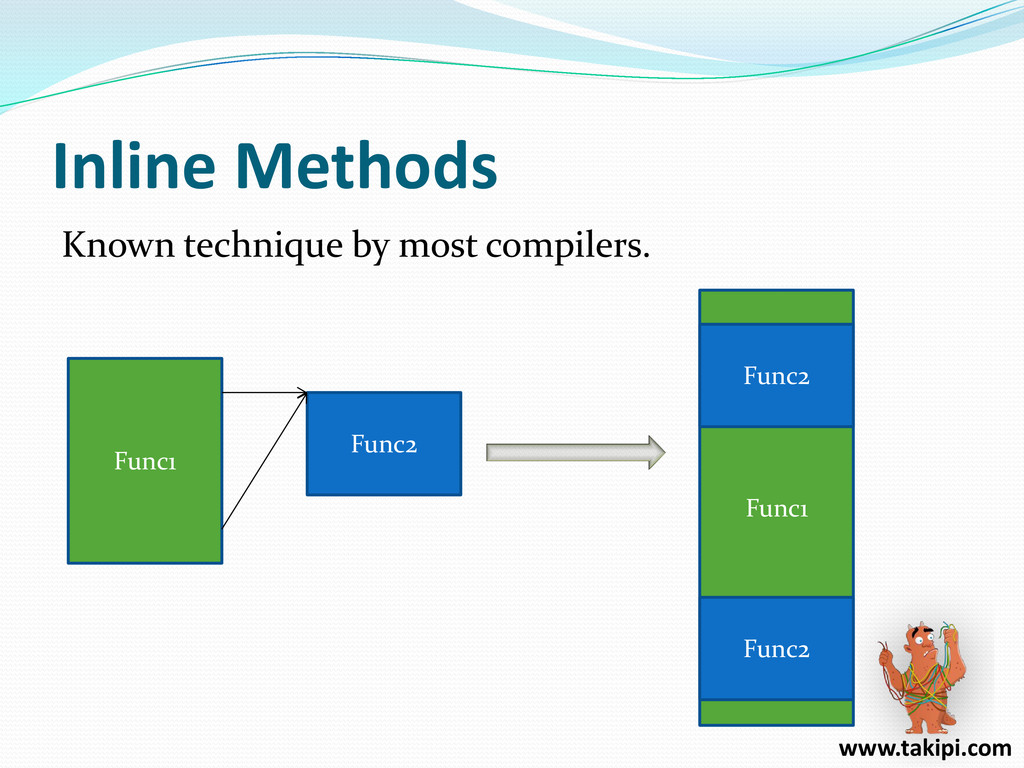{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! [email protected] @takipid www.takipi.com](https://files.speakerdeck.com/presentations/2e235cf033680131532c464fdf997ddb/slide_69.jpg){kind=link}