exponential smoothing and the equivalent arma process. Journal of Forecasting, 3(3): 333–344, 1984. [Taylor+ 2018] Taylor, S. J. and Letham, B. Forecasting at scale. The American Statistician, 72(1):37–45, 2018. [Salinas+ 2020] Salinas, D., Flunkert, V., Gasthaus, J., and Januschowski, T. Deepar: Probabilistic forecasting with autoregressive recurrent networks. International Journal of Forecasting, 36(3):1181–1191, 2020. [Borovykh+ 2017] Borovykh, A., Bohte, S., and Oosterlee, C. W. Conditional time series forecasting with convolutional neural networks. arXiv preprint arXiv:1703.04691, 2017. [Oreshkin+ 2019] Oreshkin, B. N., Carpov, D., Chapados, N., and Bengio, Y. N-beats: Neural basis expansion analysis for interpretable time series forecasting. In International Conference on Learning Representations, 2019. [Nie+ 2022] Nie, Y., Nguyen, N. H., Sinthong, P., and Kalagnanam, J. A time series is worth 64 words: Long-term forecasting with transformers. International conference on learning representations, 2022. [Das+ 2023] Das, A., Kong, W., Leach, A., Mathur, S. K., Sen, R., and Yu, R. Long-term forecasting with TiDE: Timeseries dense encoder. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https: //openreview.net/forum?id=pCbC3aQB5W. [Zivot+ 2006] Zivot, E. and Wang, J. Vector autoregressive models for multivariate time series. Modeling financial time series with S-PLUS®, pp. 385–429, 2006. [Sen+ 2019] Sen, R., Yu, H.-F., and Dhillon, I. S. Think globally, act locally: A deep neural network approach to highdimensional time series forecasting. Advances in neural information processing systems, 32, 2019. [Zhou+ 2022] Zhou, T., Ma, Z., Wen, Q., Wang, X., Sun, L., and Jin, R. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. In International Conference on Machine Learning, pp. 27268–27286. PMLR, 2022. [Zhou+ 2021] Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., and Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence, 2021.
{kind=link}
{kind=link}
![2 Introduction 時系列予測分野における深層学習 – 深層学習モデル(DeepAR[Salinas+ 2020], N-BEATS[Oreshkin+ 2019]) が](https://files.speakerdeck.com/presentations/328df734631043ddbf867e05a8ab165b/slide_2.jpg){kind=link}
{kind=link}
![4 Related Work Local univariate models(ローカル単変量モデル) – ARIMA,指数平滑化法[McKenzie 1984],Prophet[Taylor+](https://files.speakerdeck.com/presentations/328df734631043ddbf867e05a8ab165b/slide_4.jpg){kind=link}
![5 Related Work 時系列予測のための大規模言語モデルを再利用する研究 – LLMTime[Gruver+ 2023]はGPT-3やLLaMA-2のZero-shot予測性能のベンチマーク – GPT-2を時系列予測タスクでfine-tuneする研究[Zhou+](https://files.speakerdeck.com/presentations/328df734631043ddbf867e05a8ab165b/slide_5.jpg){kind=link}
{kind=link}
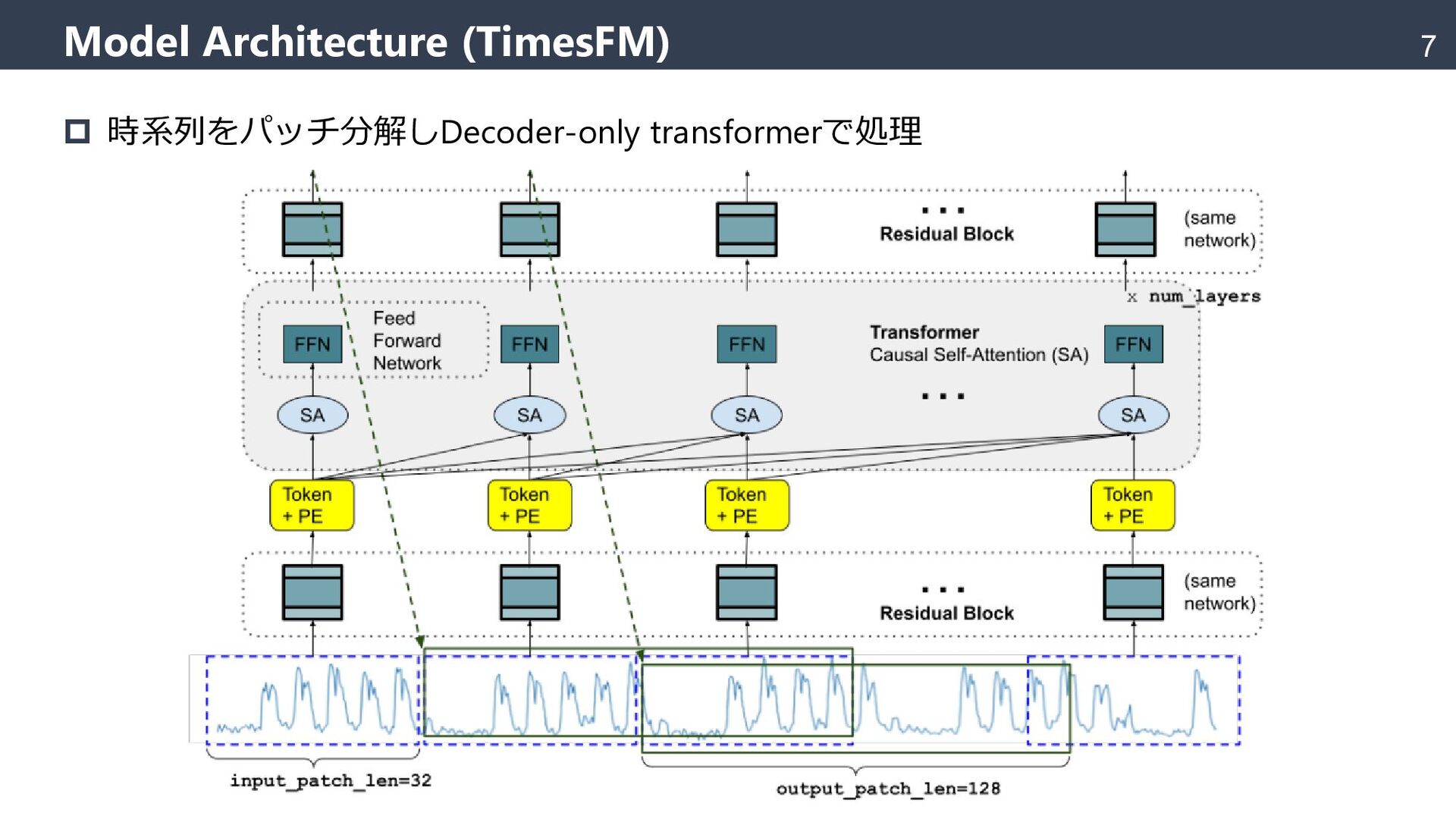{kind=link}
![8 Model Architecture (TimesFM) Patching – PatchTST[Nie+ 2022]を参考に時系列をパッチに分解 ](https://files.speakerdeck.com/presentations/328df734631043ddbf867e05a8ab165b/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
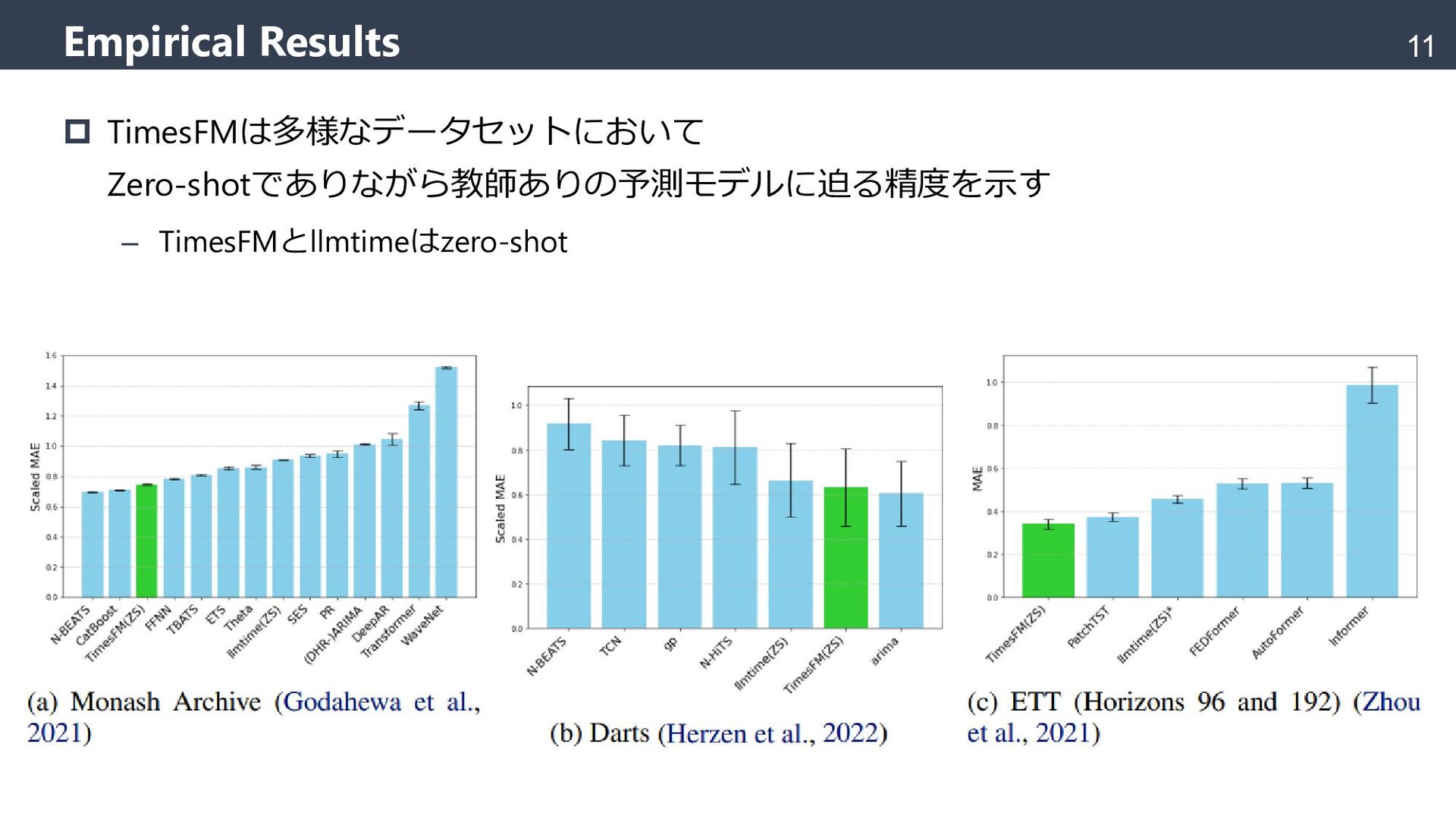{kind=link}
{kind=link}
{kind=link}
![14 Related Work 文献詳細 [McKenzie 1984] McKenzie, E. General](https://files.speakerdeck.com/presentations/328df734631043ddbf867e05a8ab165b/slide_14.jpg){kind=link}
{kind=link}
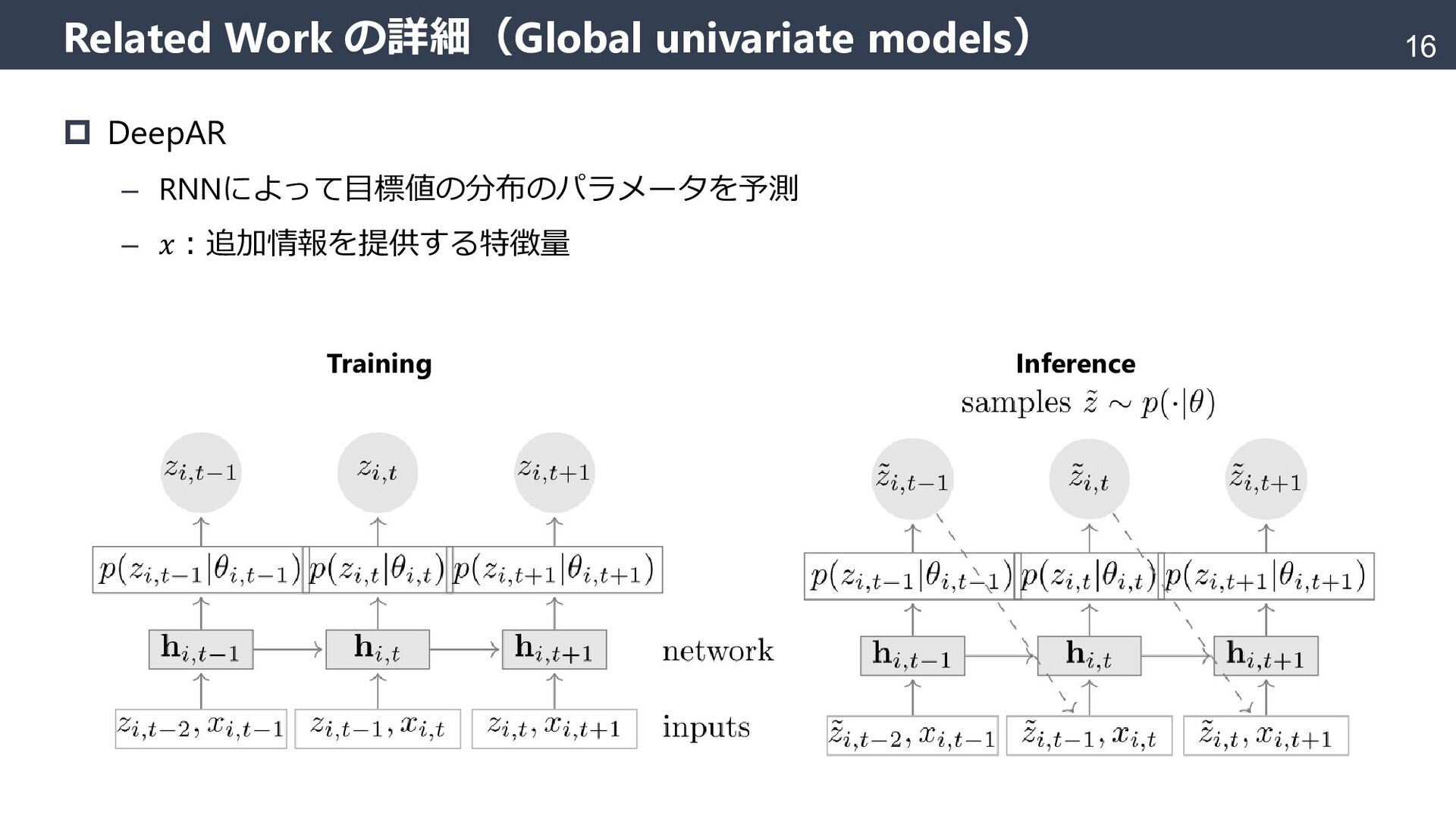{kind=link}
{kind=link}
{kind=link}
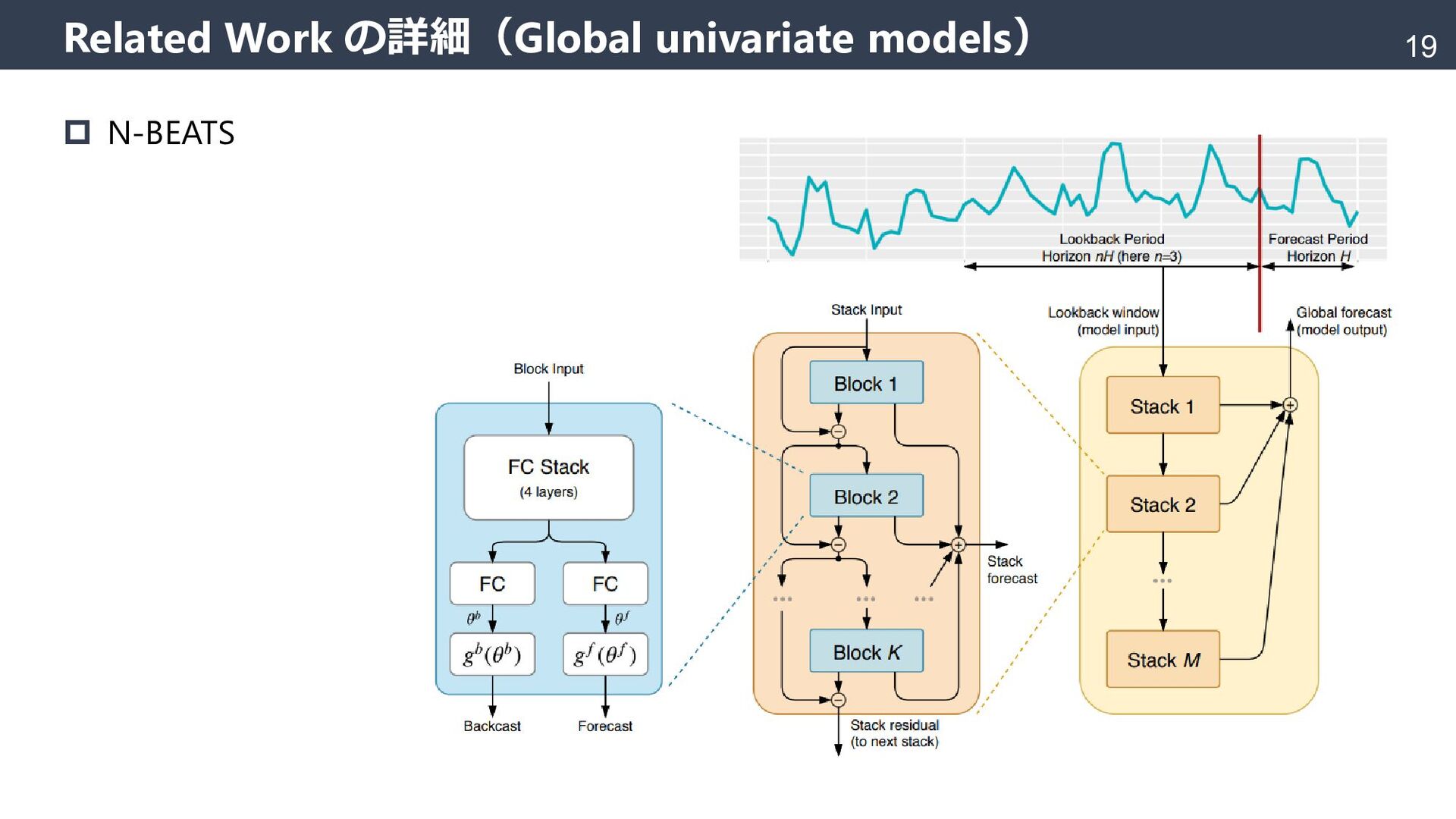{kind=link}
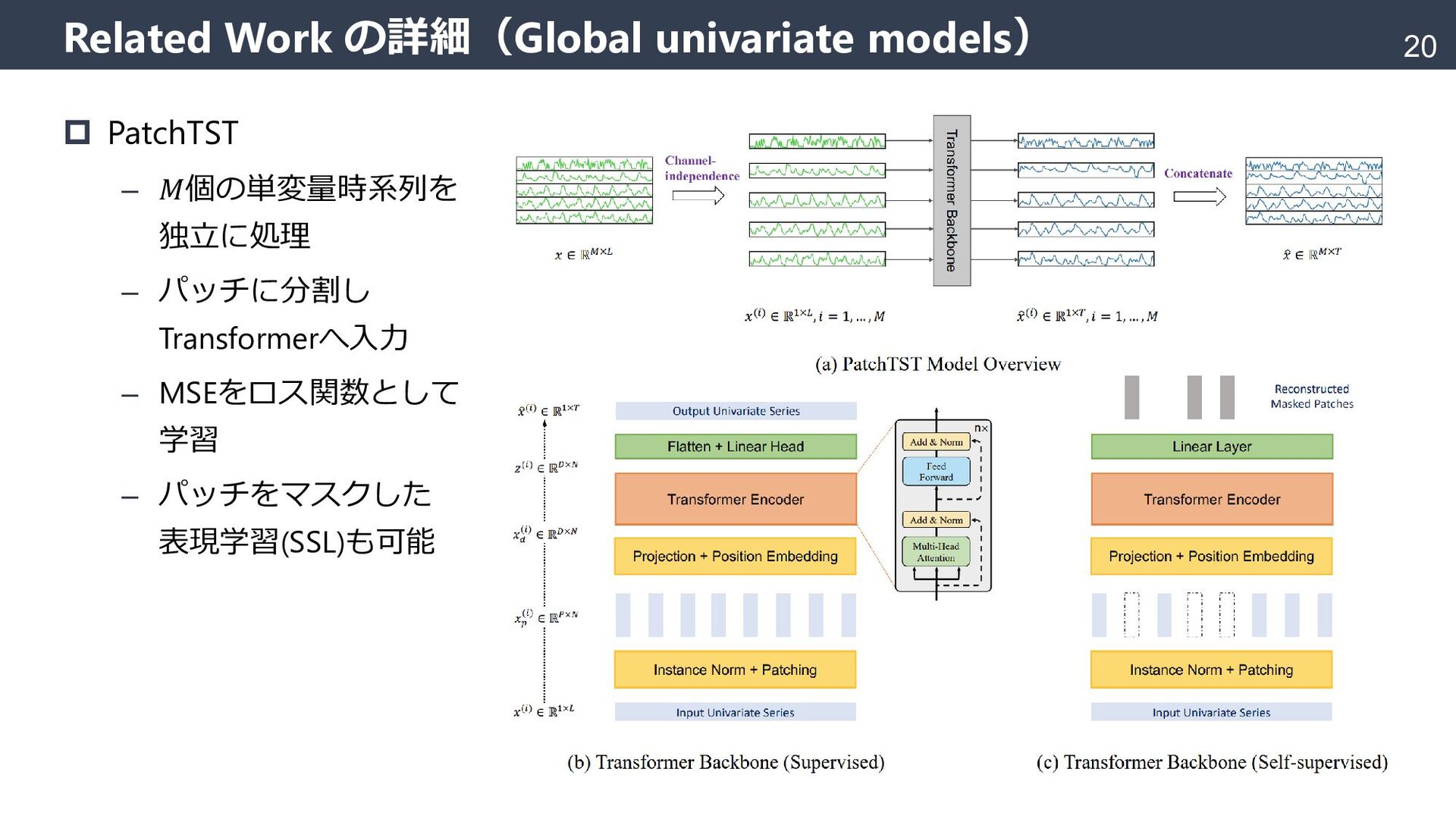{kind=link}
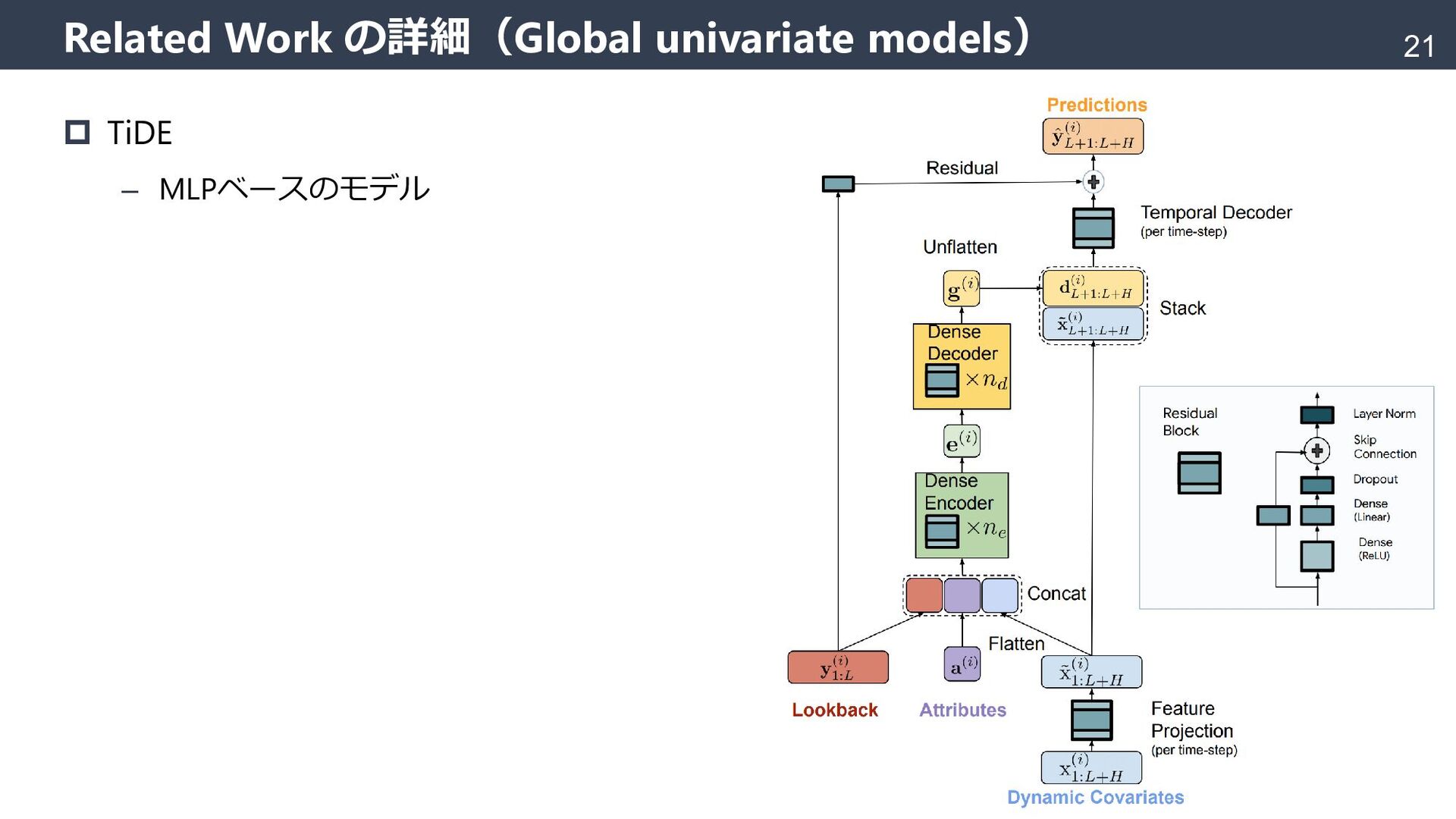{kind=link}