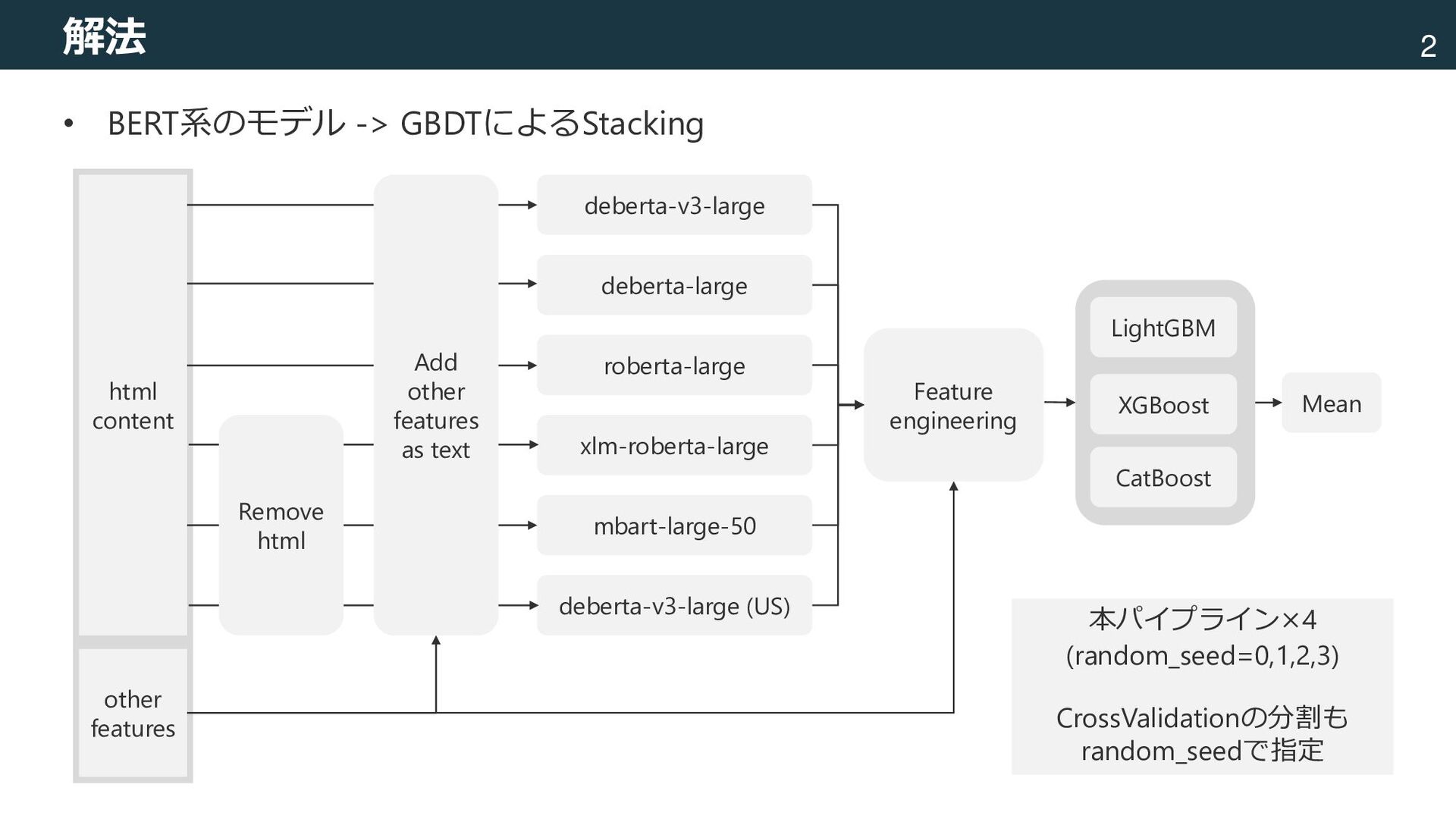
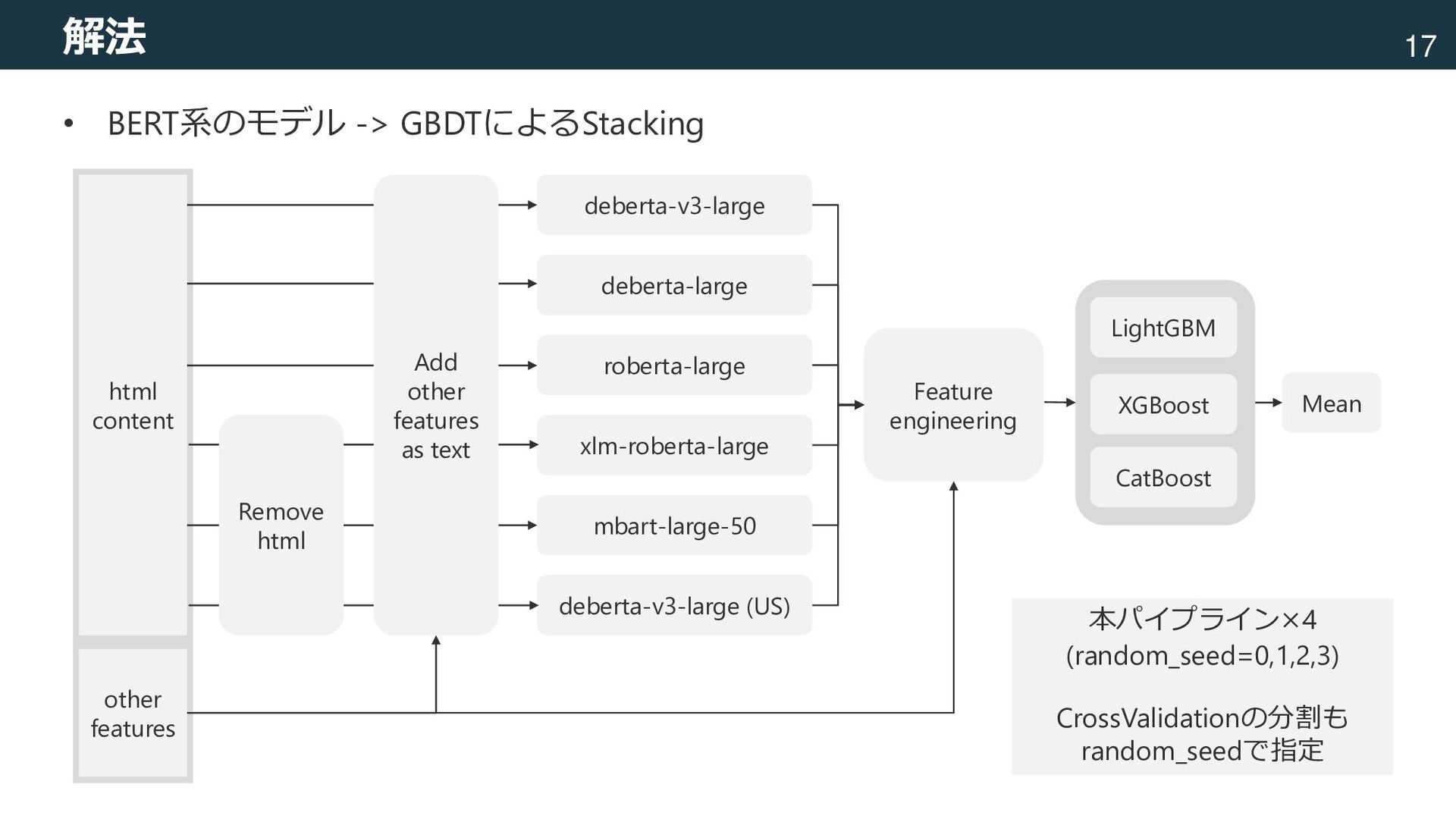
mbart-large-50 deberta-v3-large (US) LightGBM XGBoost CatBoost Mean Feature engineering raw data html content other features Add other features as text Remove html 本パイプライン×4 (random_seed=0,1,2,3) CrossValidationの分割も random_seedで指定
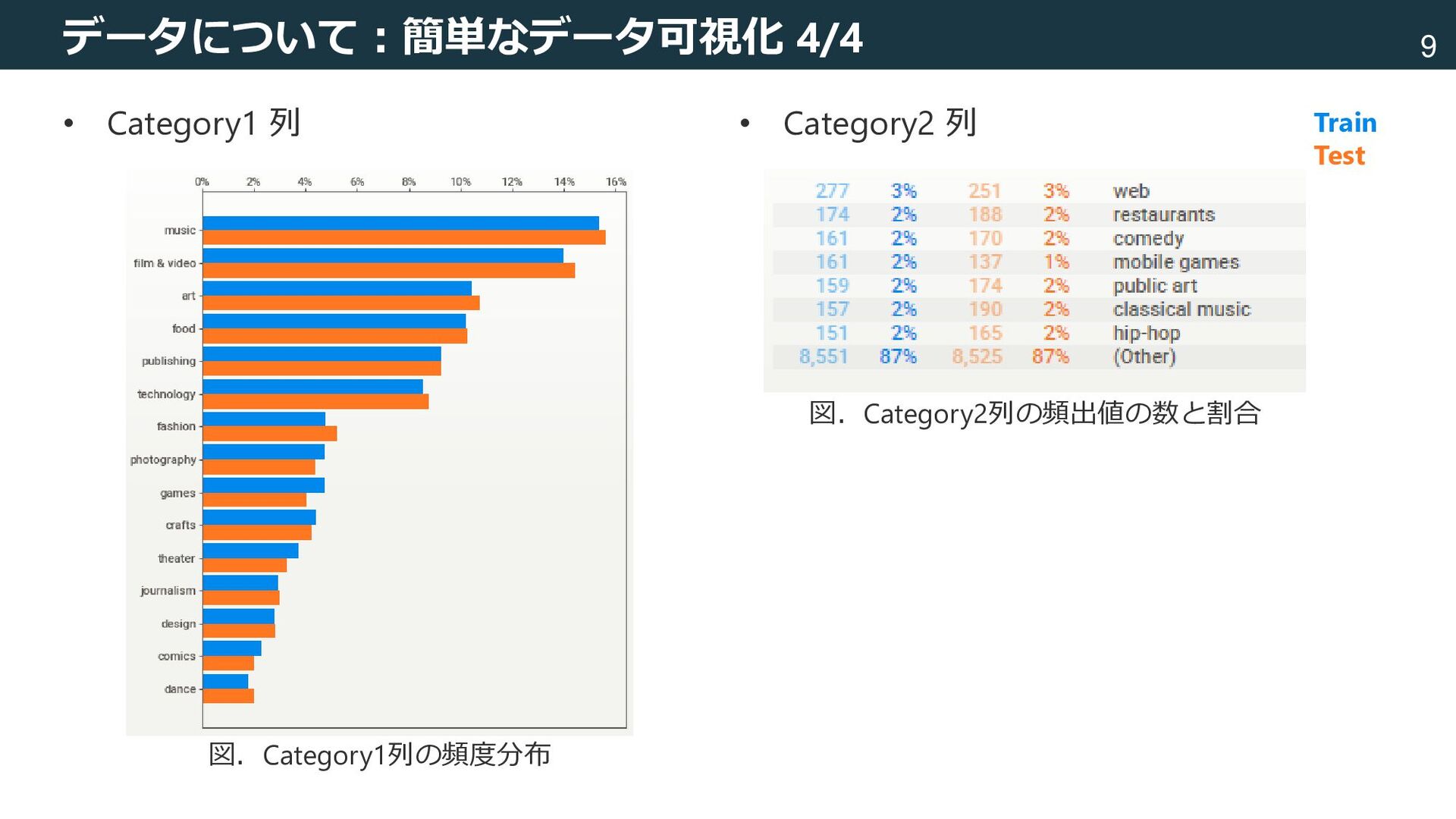
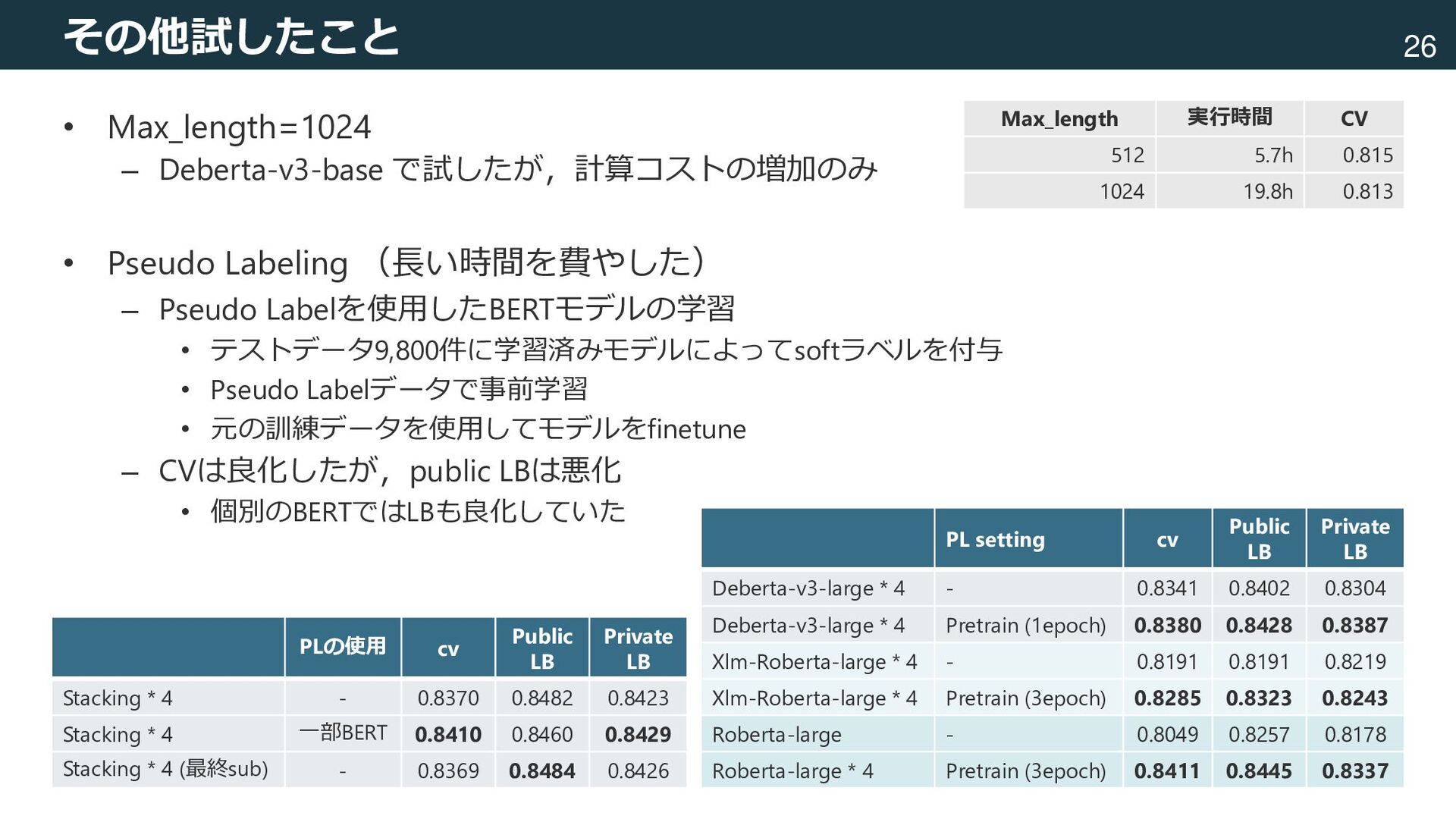
– Test data : 9800件 • State 列(目的変数) – 正例・負例はほぼ同数 図はsweetviz[fbdesignpro, 2020]を使用して出力 [fbdesignpro, 2020] fbdesignpro. fbdesignpro/sweetviz: Visualize and compare datasets, target values and associations, with one line of code. GitHub. Published November 30, 2020. Accessed October 5, 2022. https://github.com/fbdesignpro/sweetviz
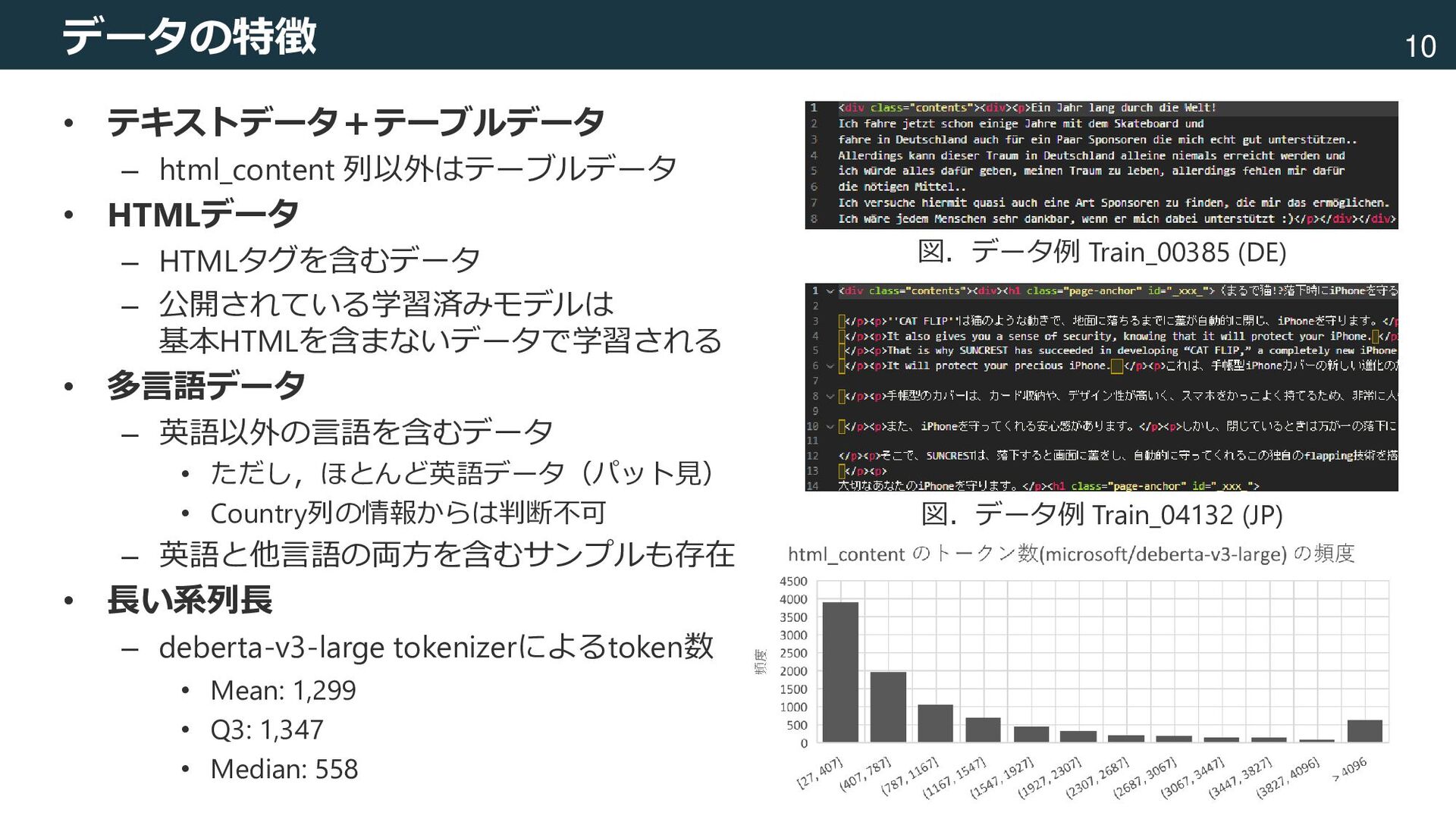
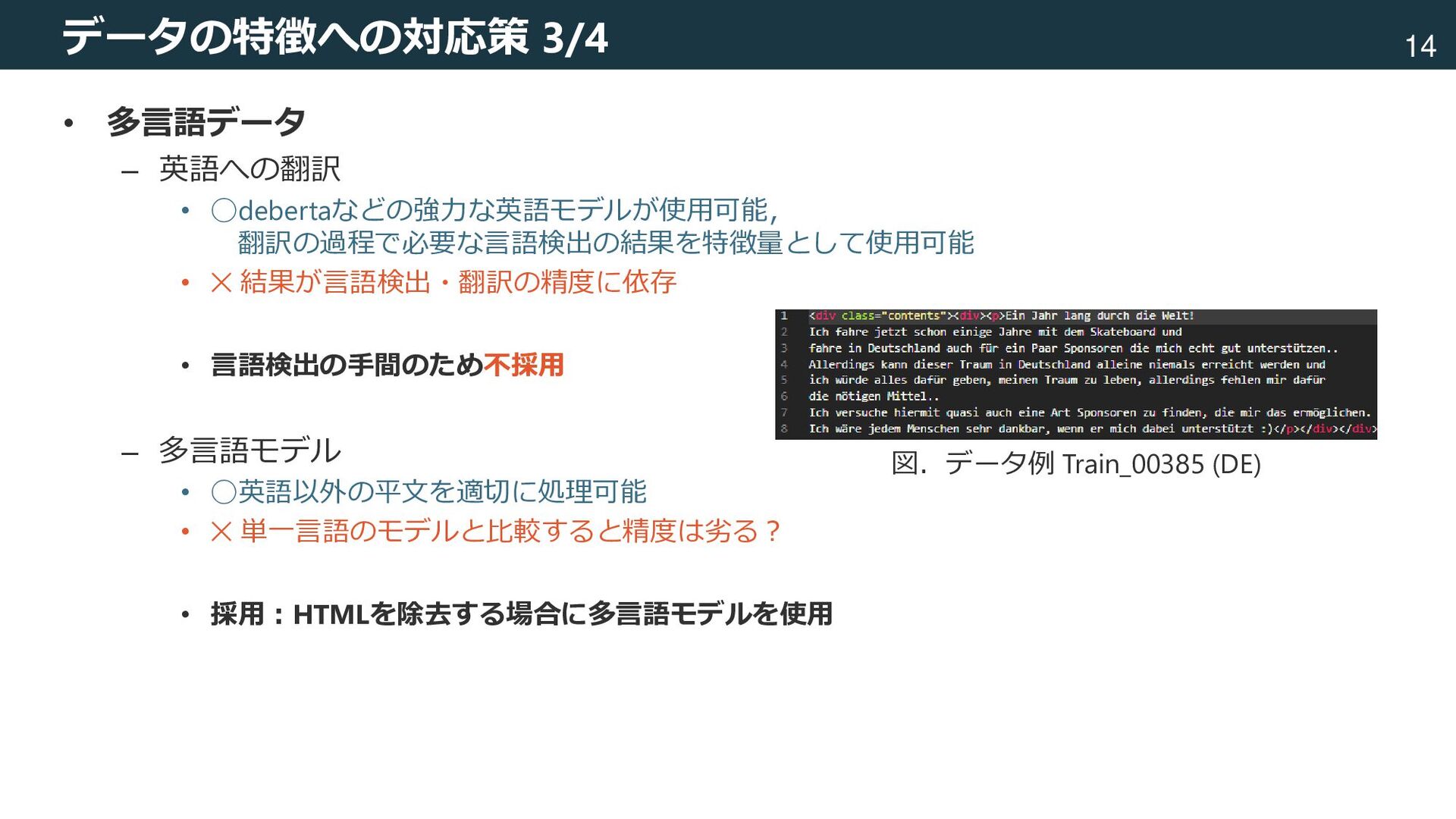
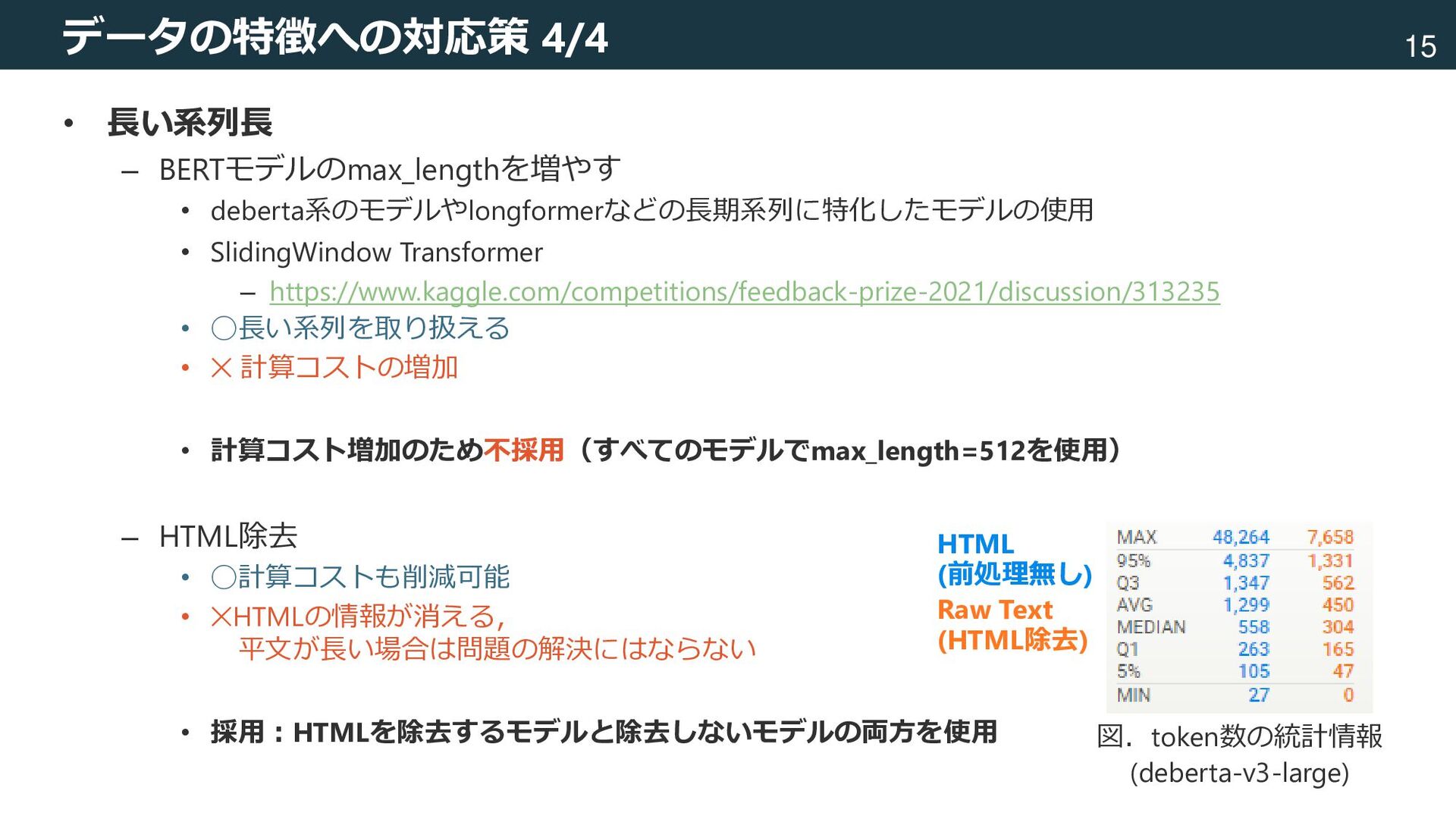
テキスト+テーブル,HTML,多言語,長系列 [Devlin+, 2018] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018). 図.論文[Devlin+, 2018]から引用
mbart-large-50 deberta-v3-large (US) LightGBM XGBoost CatBoost Mean Feature engineering raw data html content other features Add other features as text Remove html 本パイプライン×4 (random_seed=0,1,2,3) CrossValidationの分割も random_seedで指定
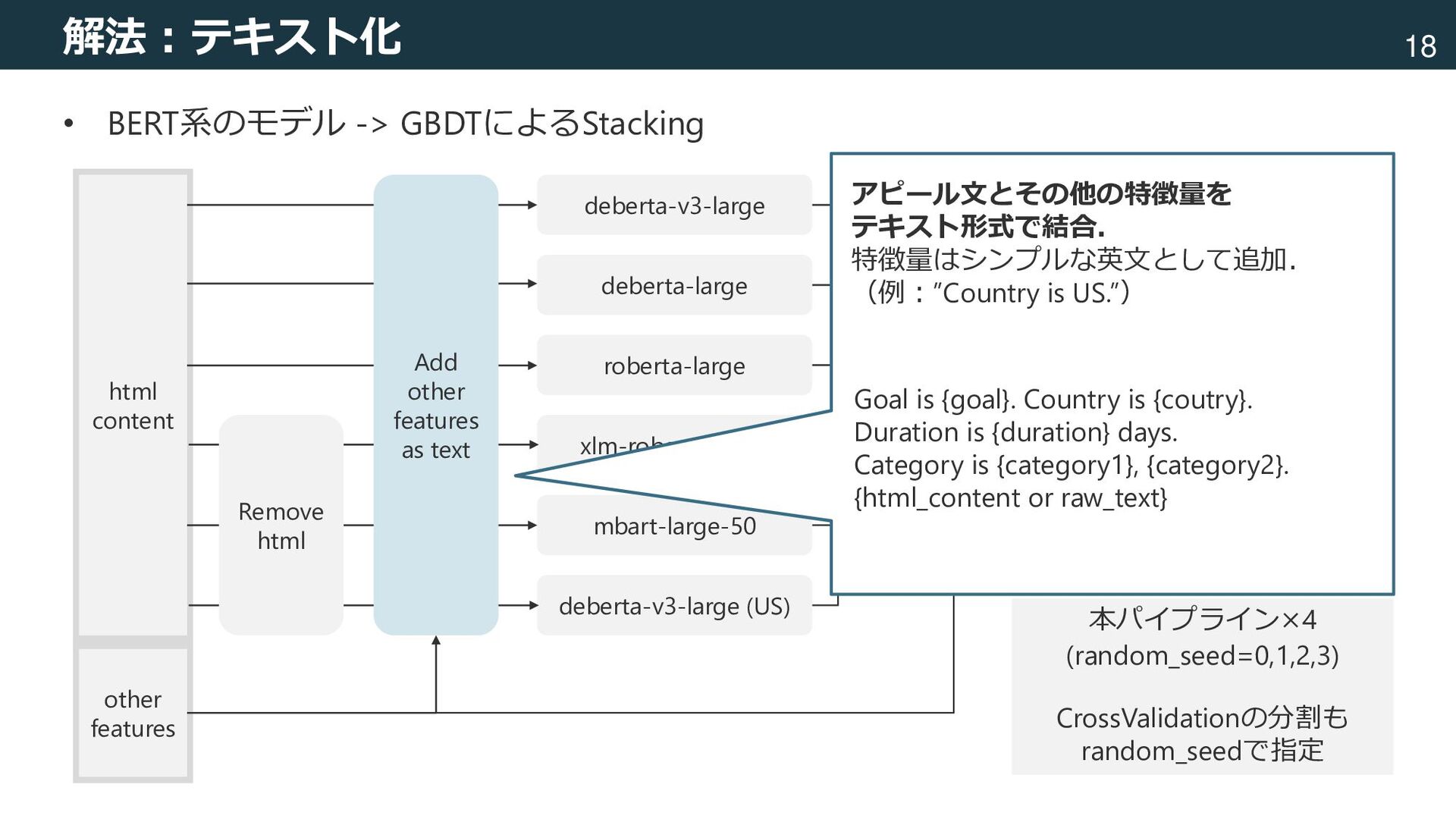
mbart-large-50 deberta-v3-large (US) LightGBM XGBoost CatBoost Mean Feature engineering raw data html content other features Add other features as text Remove html Goal is {goal}. Country is {coutry}. Duration is {duration} days. Category is {category1}, {category2}. {html_content or raw_text} アピール文とその他の特徴量を テキスト形式で結合. 特徴量はシンプルな英文として追加. (例:”Country is US.”) 本パイプライン×4 (random_seed=0,1,2,3) CrossValidationの分割も random_seedで指定
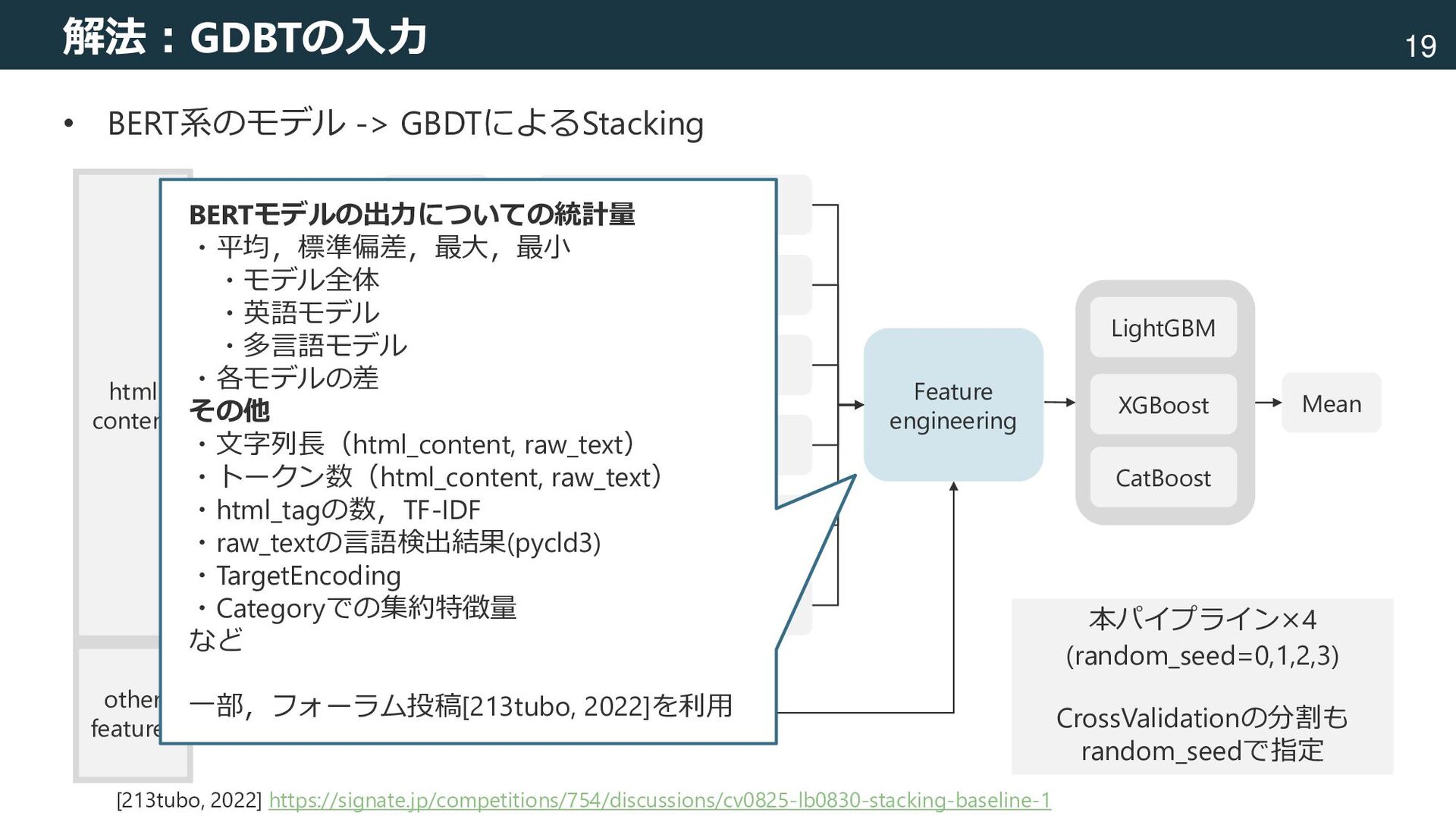
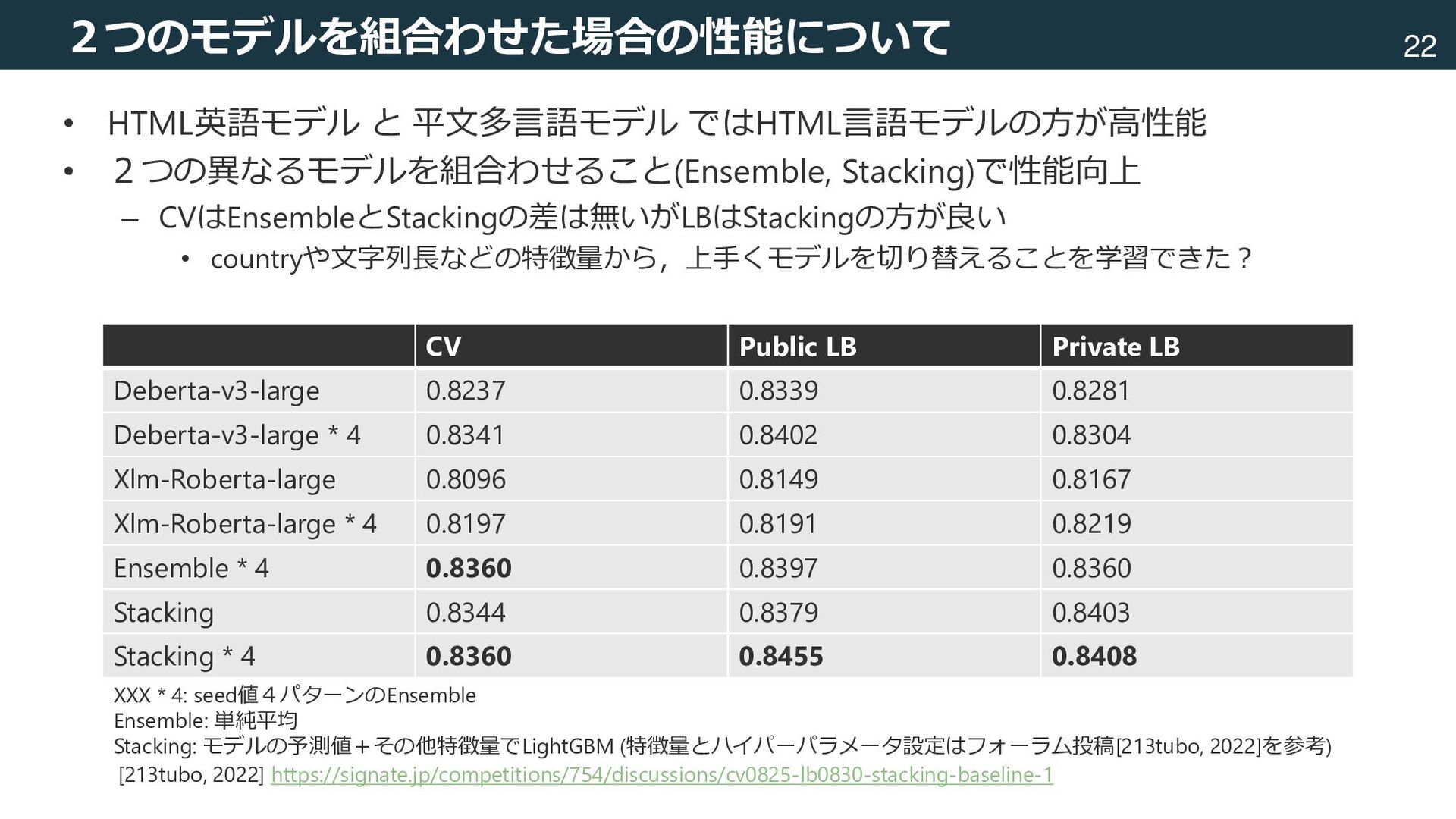
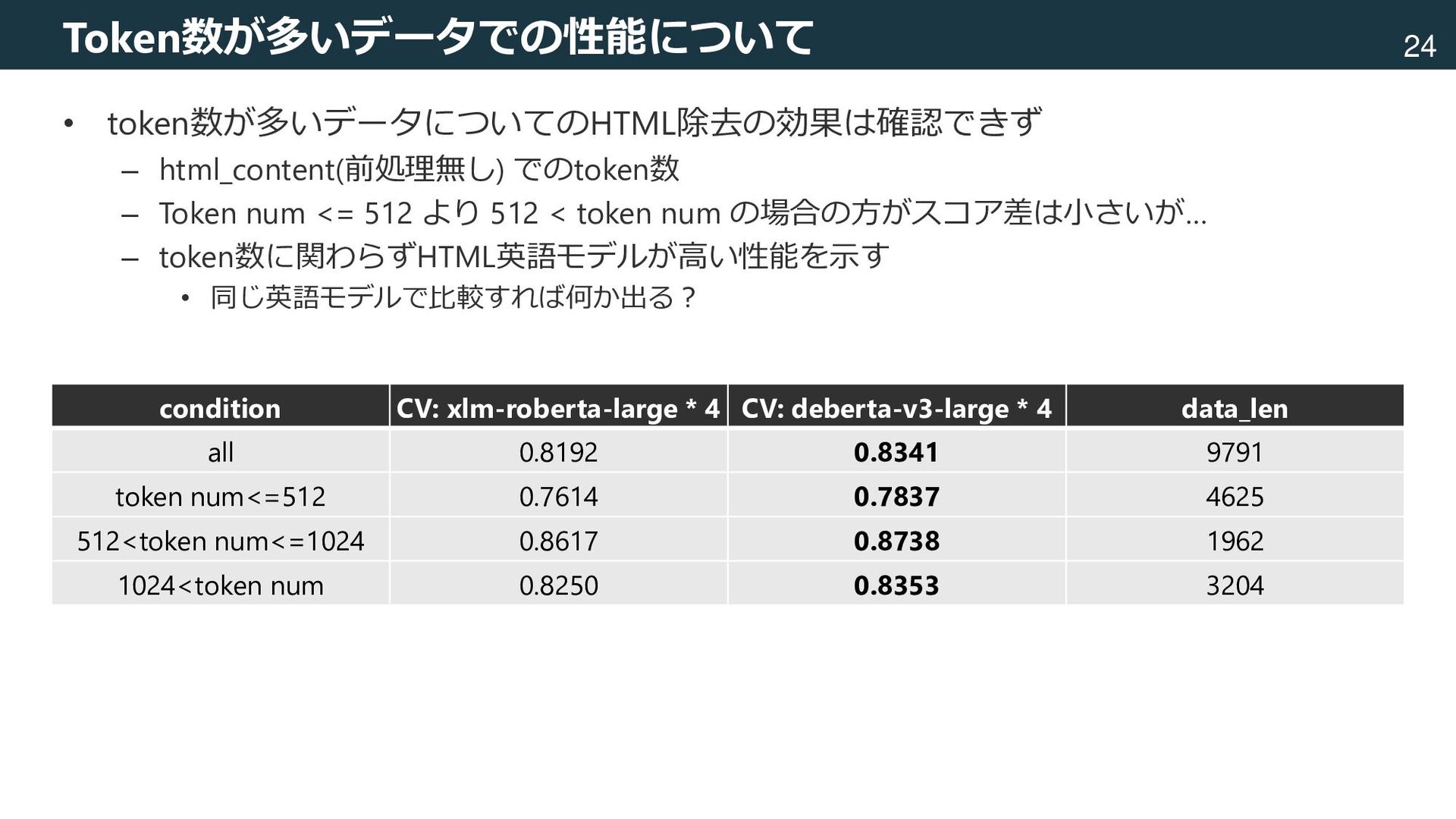
mbart-large-50 deberta-v3-large (US) LightGBM XGBoost CatBoost Mean Feature engineering raw data html content other features Add other features as text Remove html BERTモデルの出力についての統計量 ・平均,標準偏差,最大,最小 ・モデル全体 ・英語モデル ・多言語モデル ・各モデルの差 その他 ・文字列長(html_content, raw_text) ・トークン数(html_content, raw_text) ・html_tagの数,TF-IDF ・raw_textの言語検出結果(pycld3) ・TargetEncoding ・Categoryでの集約特徴量 など 一部,フォーラム投稿[213tubo, 2022]を利用 本パイプライン×4 (random_seed=0,1,2,3) CrossValidationの分割も random_seedで指定 [213tubo, 2022] https://signate.jp/competitions/754/discussions/cv0825-lb0830-stacking-baseline-1
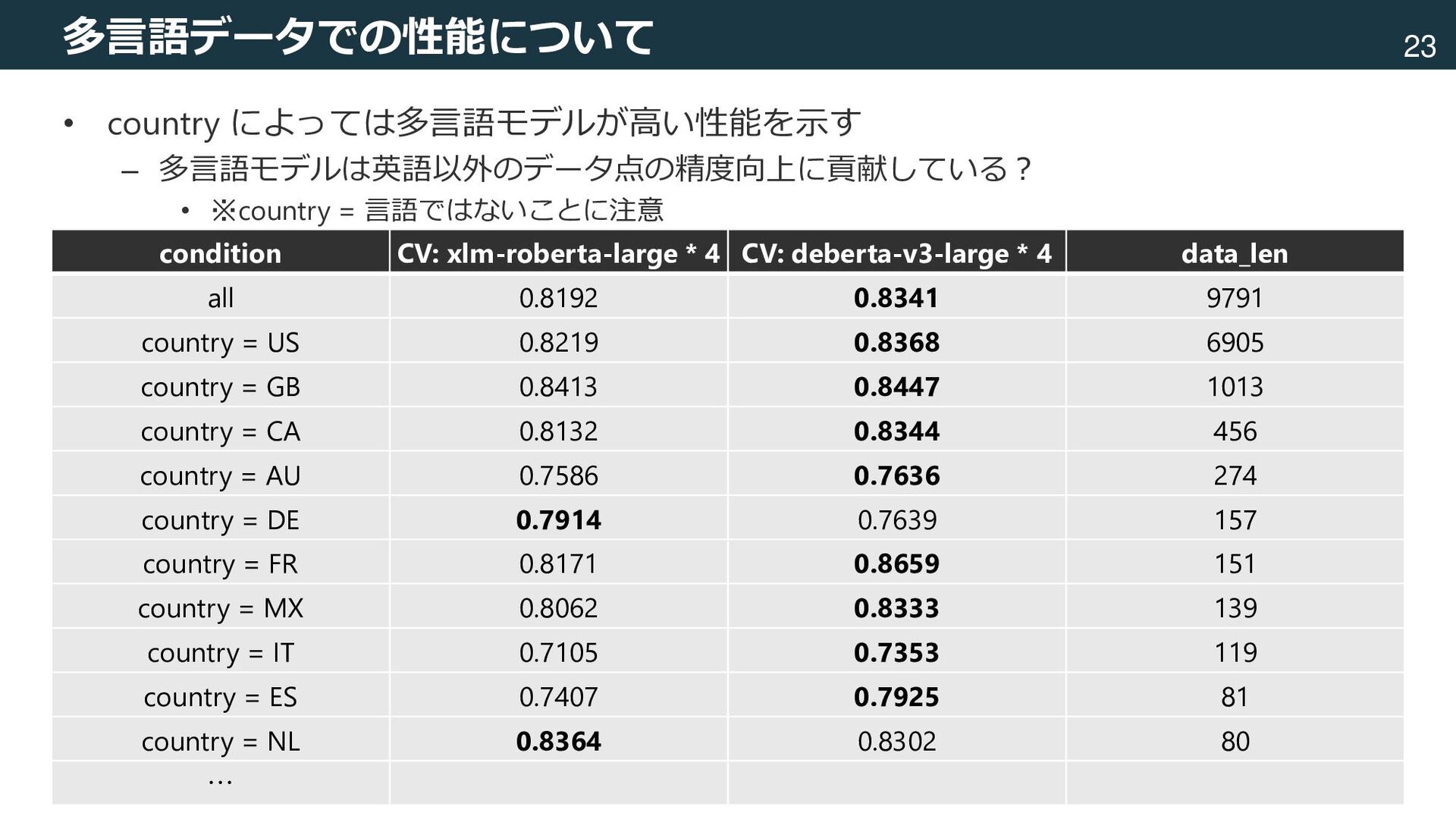
言語ではないことに注意 condition CV: xlm-roberta-large * 4 CV: deberta-v3-large * 4 data_len all 0.8192 0.8341 9791 country = US 0.8219 0.8368 6905 country = GB 0.8413 0.8447 1013 country = CA 0.8132 0.8344 456 country = AU 0.7586 0.7636 274 country = DE 0.7914 0.7639 157 country = FR 0.8171 0.8659 151 country = MX 0.8062 0.8333 139 country = IT 0.7105 0.7353 119 country = ES 0.7407 0.7925 81 country = NL 0.8364 0.8302 80 …
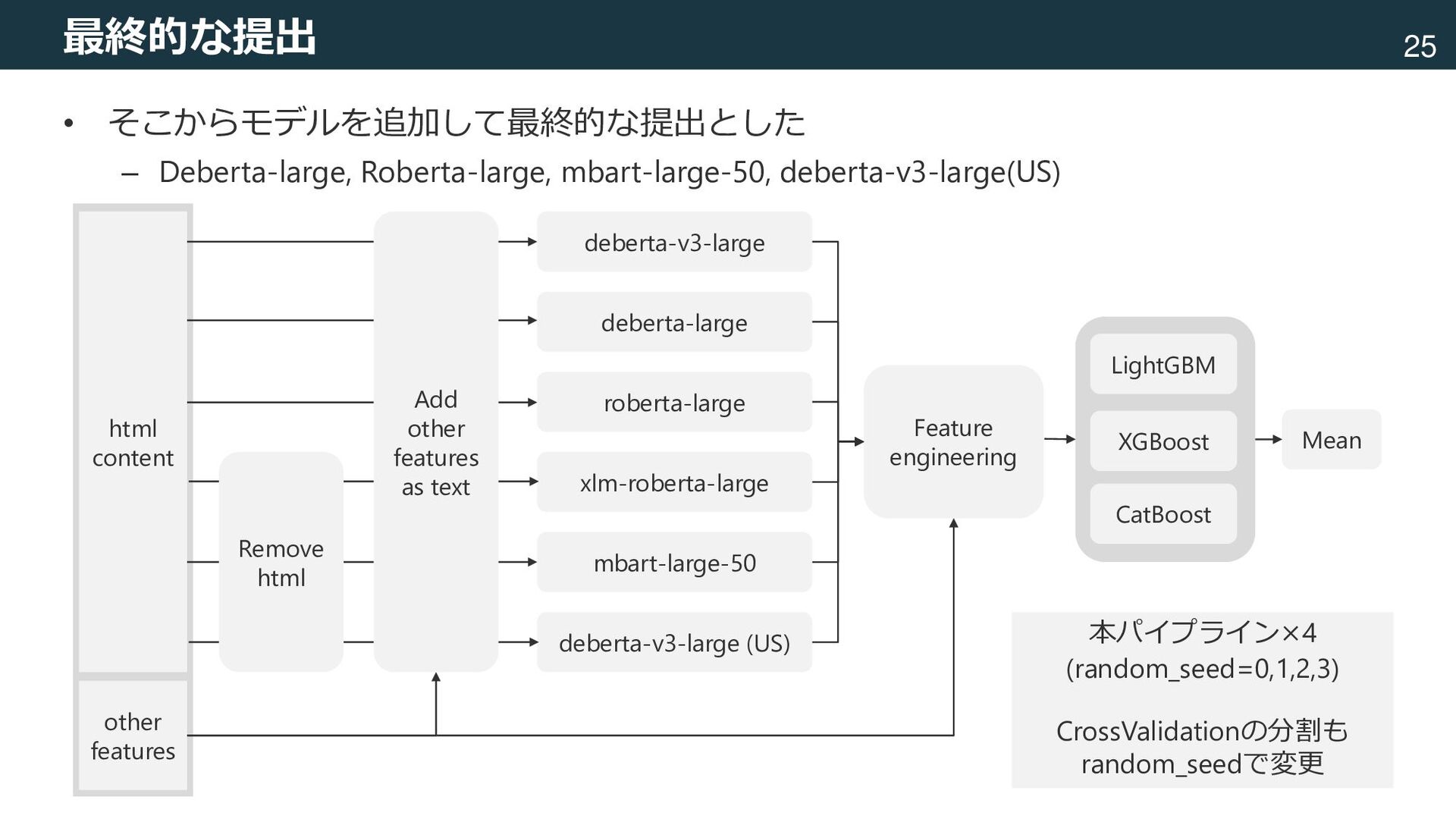
XGBoost CatBoost Mean Feature engineering raw data html content other features Add other features as text Remove html 本パイプライン×4 (random_seed=0,1,2,3) CrossValidationの分割も random_seedで変更 • そこからモデルを追加して最終的な提出とした – Deberta-large, Roberta-large, mbart-large-50, deberta-v3-large(US)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
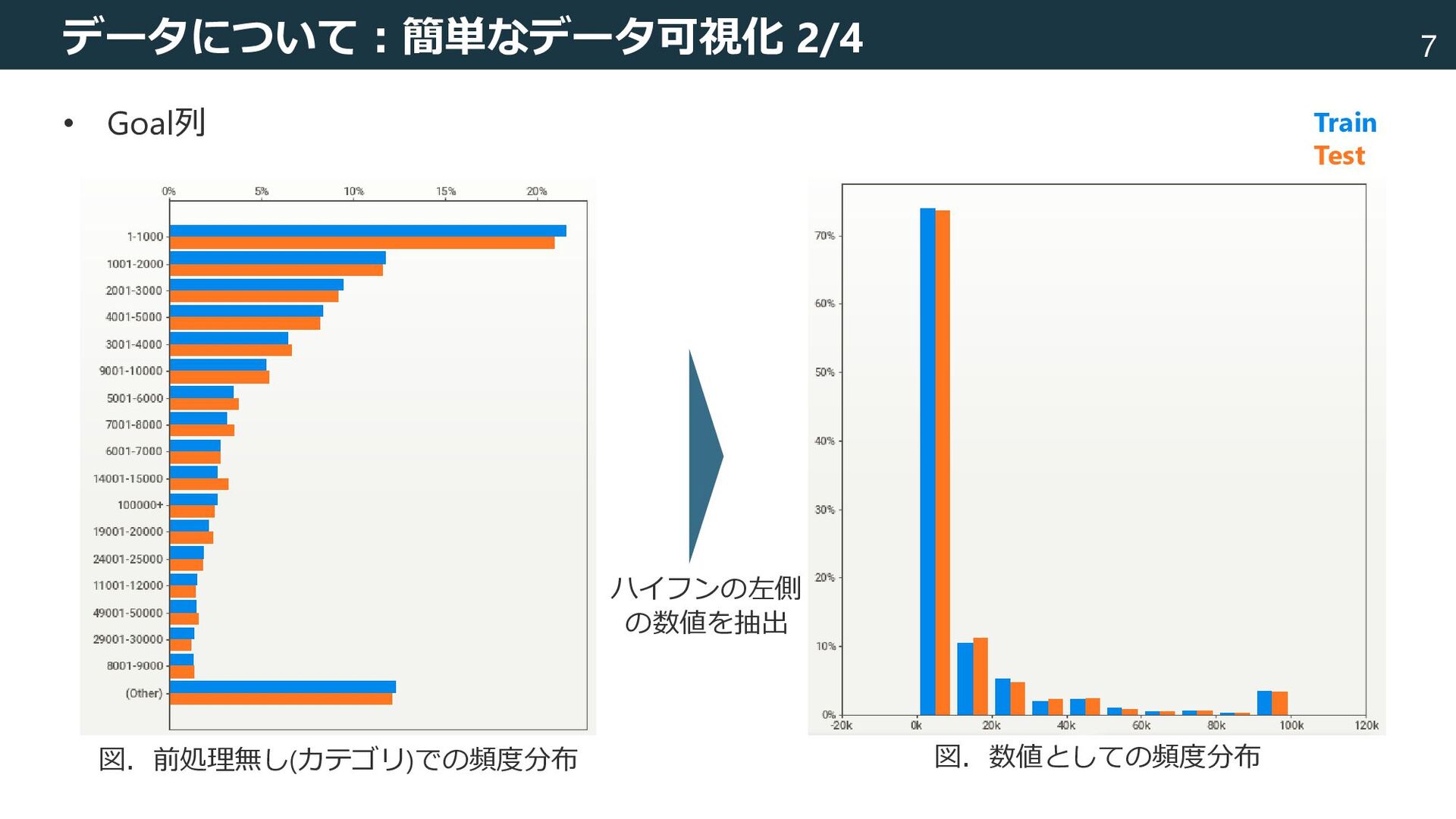
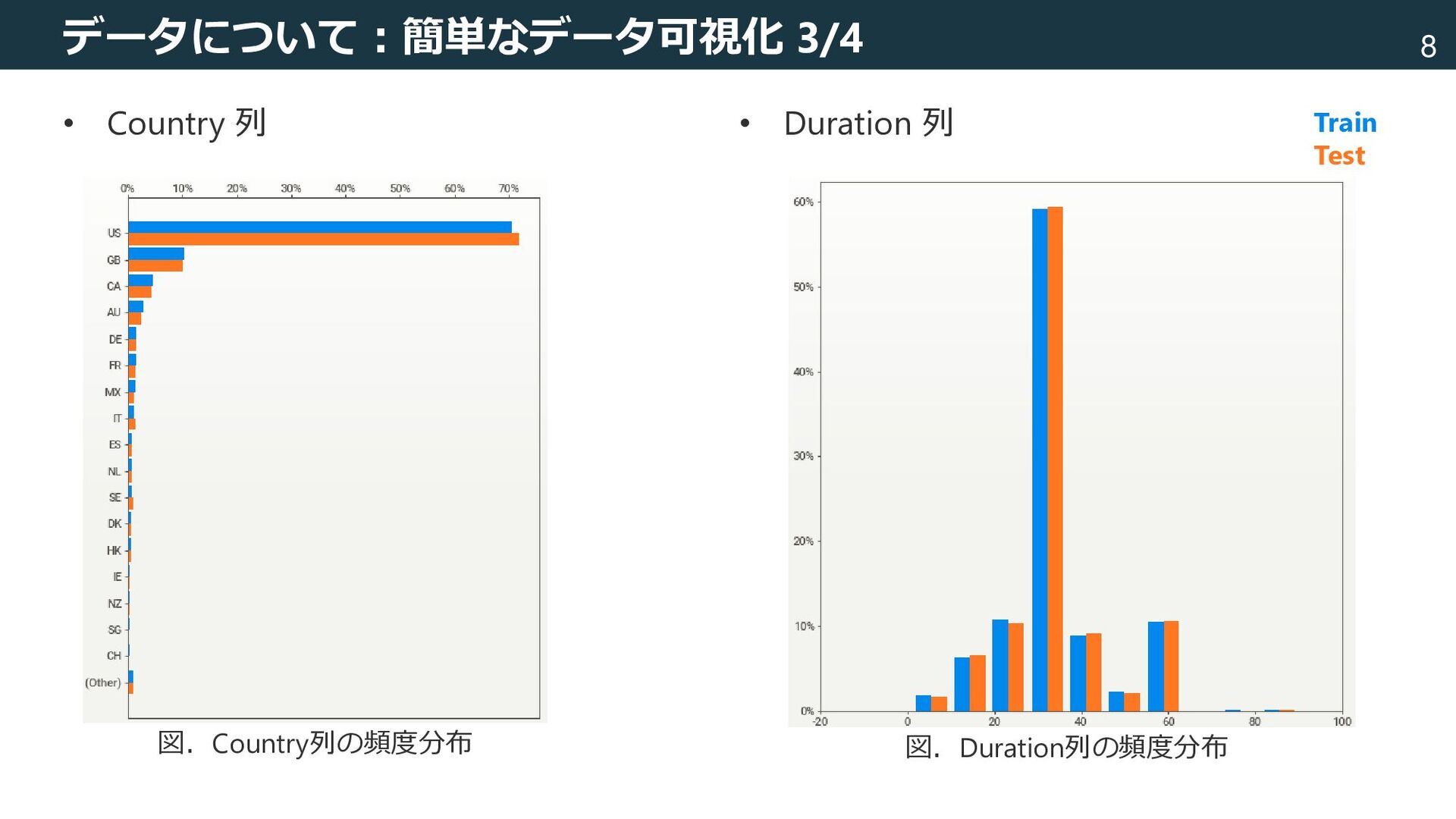
![5 データについて • 説明変数と目的変数 [state] 二値変数(0/1) [country] アルファベット二文字の国コード 例:US [category1],](https://files.speakerdeck.com/presentations/ee4adee4ed5541c9967317162991d56d/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![11 解法の方針 • BERT[Devlin+, 2018]系モデルの利用 – 自然言語処理(文書分類)におけるデファクトスタンダード • 前述のデータ特徴に対応する –](https://files.speakerdeck.com/presentations/ee4adee4ed5541c9967317162991d56d/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}