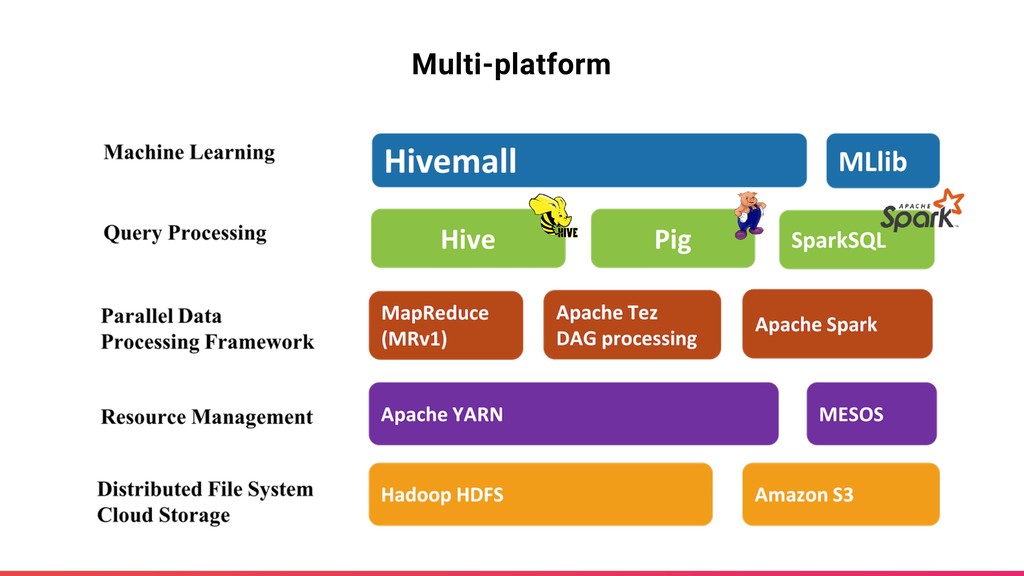
on Hadoop ecosystem Multi-platform Hive, Spark, Pig Versatile Efficient, generic functions ‣ Scalable ML library implemented as Hive UDFs ‣ OSS project under Apache Software Foundation Released on Mar 5, 2018
BIGINT TEXT FLOAT index weight ( ) ‣ libSVM formatɹɹɹɹɹɹɹɹɹɹɹɹɹɹ 10 : 3.4, 123 : 0.5, 34567 : 0.231 ‣ can be text ɹ ɹɹɹɹɹɹɹɹɹɹ price : 600, size : 2.5 ‣ -only means = 1.0ʢe.g., categoricalʣ male = male : 1.0 index weight index
reducers perform model averaging in parallel FROM ( SELECT logress(features, label, "-total_steps ${total_steps}") as (feature, weight) FROM training ) t -- map-only task GROUP BY feature; -- shuffled to reducers
b = foreach a generate flatten( logress(features, label, '-total_steps ${total_steps}') ) as (feature, weight); c = group b by feature; d = foreach c generate group, AVG(b.weight); store d into 'a9a_model';
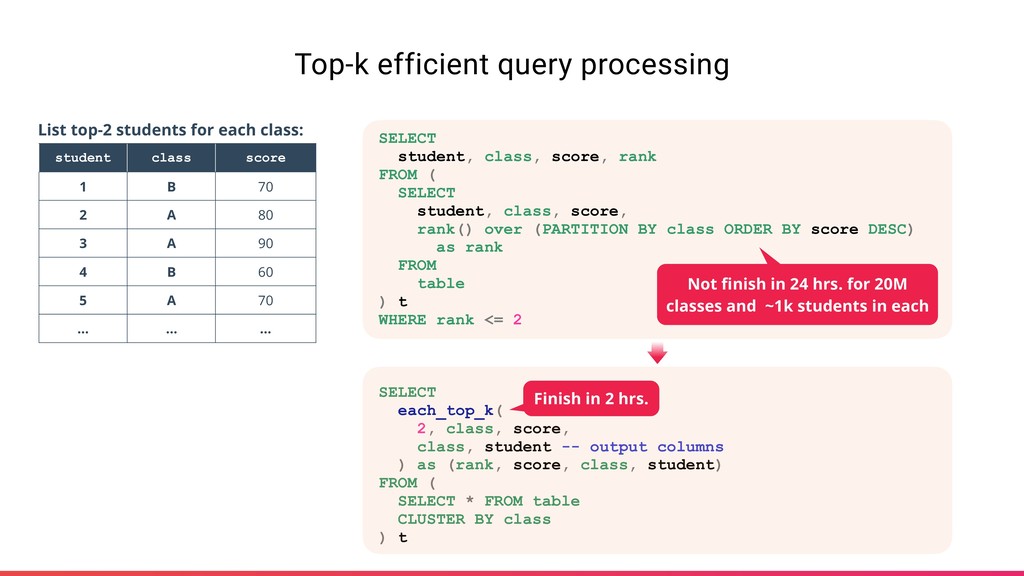
2 A 80 3 A 90 4 B 60 5 A 70 … … … List top-2 students for each class: SELECT student, class, score, rank FROM ( SELECT student, class, score, rank() over (PARTITION BY class ORDER BY score DESC) as rank FROM table ) t WHERE rank <= 2 SELECT each_top_k( 2, class, score, class, student -- output columns ) as (rank, score, class, student) FROM ( SELECT * FROM table CLUSTER BY class ) t Not finish in 24 hrs. for 20M classes and ~1k students in each Finish in 2 hrs.
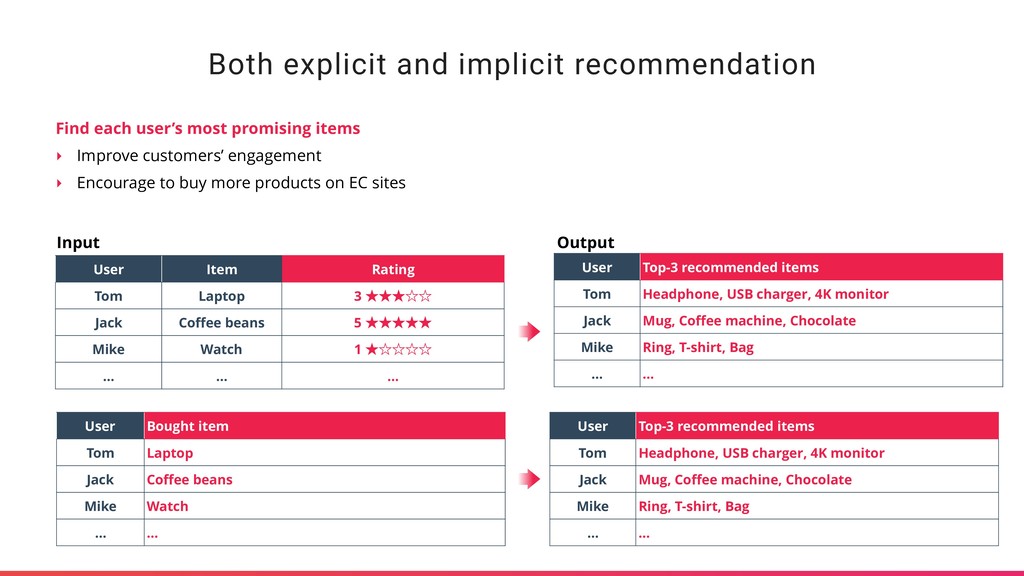
items ‣ Improve customers’ engagement ‣ Encourage to buy more products on EC sites User Item Rating Tom Laptop 3 ˒˒˒ˑˑ Jack Coffee beans 5 ˒˒˒˒˒ Mike Watch 1 ˒ˑˑˑˑ … … … User Top-3 recommended items Tom Headphone, USB charger, 4K monitor Jack Mug, Coffee machine, Chocolate Mike Ring, T-shirt, Bag … … Input Output User Bought item Tom Laptop Jack Coffee beans Mike Watch … … User Top-3 recommended items Tom Headphone, USB charger, 4K monitor Jack Mug, Coffee machine, Chocolate Mike Ring, T-shirt, Bag … …
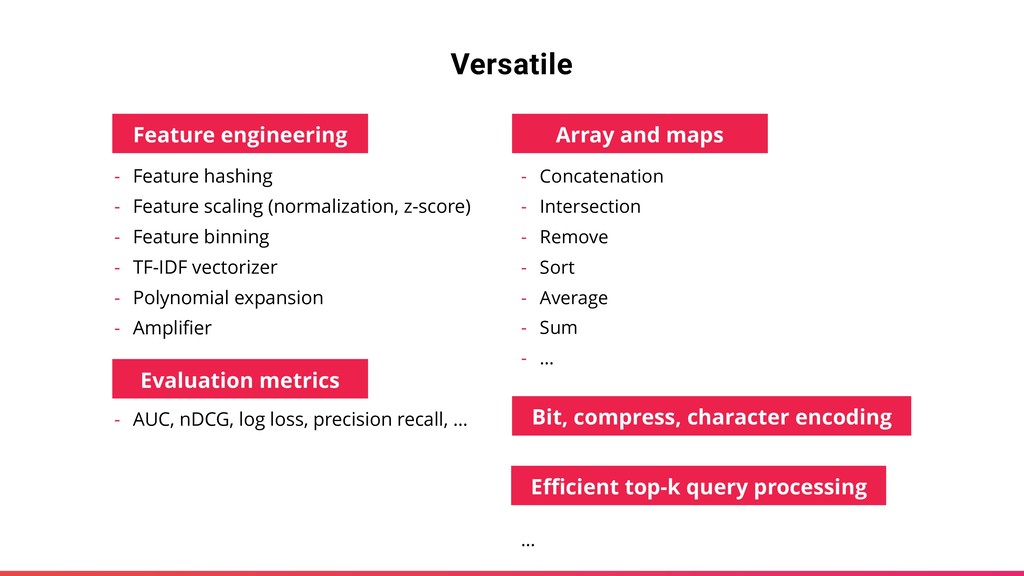
N-grams, … ‣ ɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹɹ ["Hello", "world"] ‣ apple Sketching ‣ Geospatial functions select tokenize('Hello, world!') select singularize('apples') SELECT count(distinct user_id) FROM t SELECT approx_count_distinct(user_id) FROM t SELECT map_url(lat, lon, zoom) as osm_url, map_url(lat, lon, zoom,'-type googlemaps') as gmap_url FROM ( SELECT 51.51202 as lat, 0.02435 as lon, 17 as zoom UNION ALL SELECT 51.51202 as lat, 0.02435 as lon, 4 as zoom ) t
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}