Talk at ODSC Europe 2018: https://odsc.com/training/portfolio/apache-hivemall-query-based-handy-scalable-machine-learning-hive
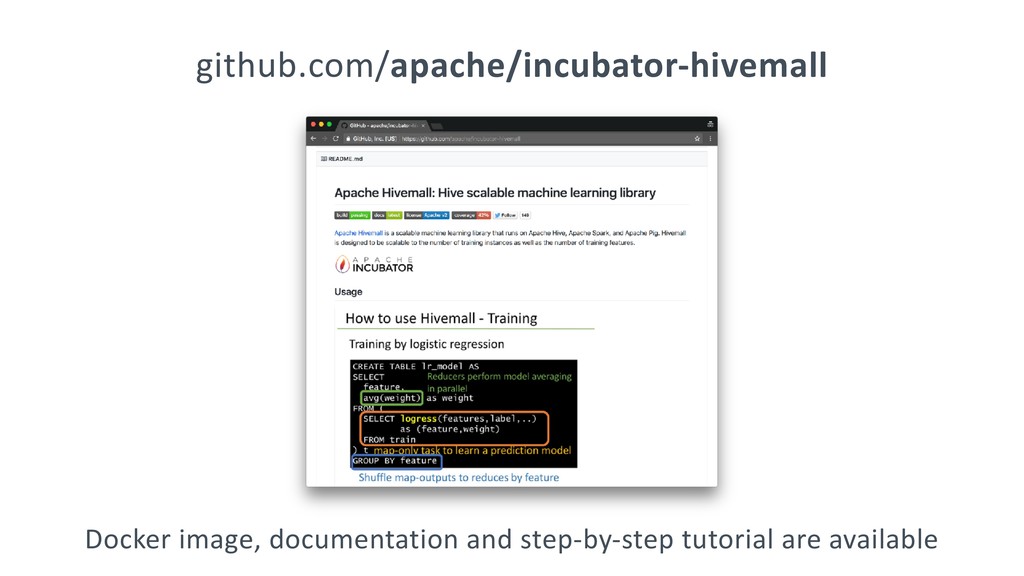
Apache Hivemall: https://github.com/apache/incubator-hivemall
Documentation: http://hivemall.incubator.apache.org/userguide/
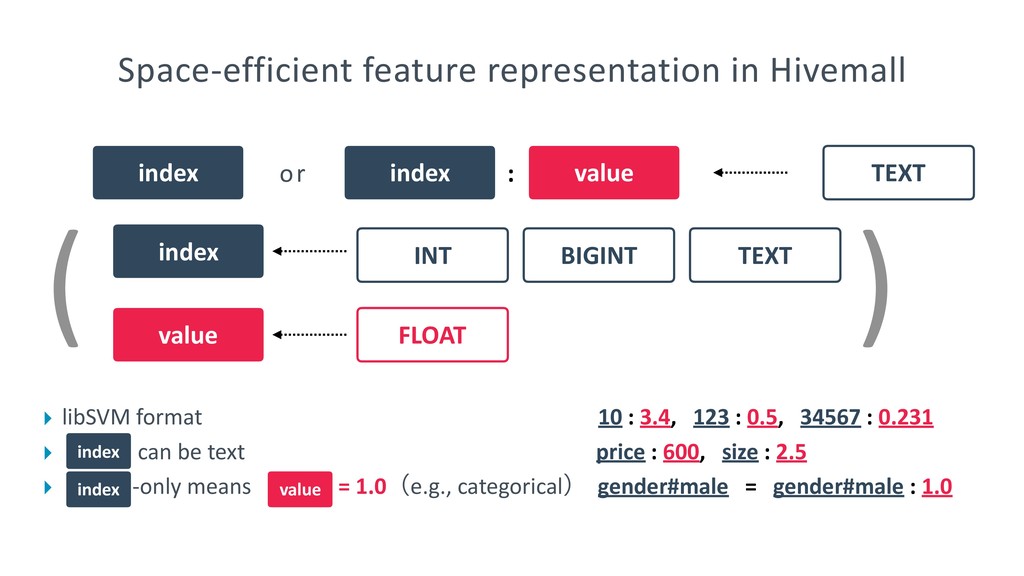
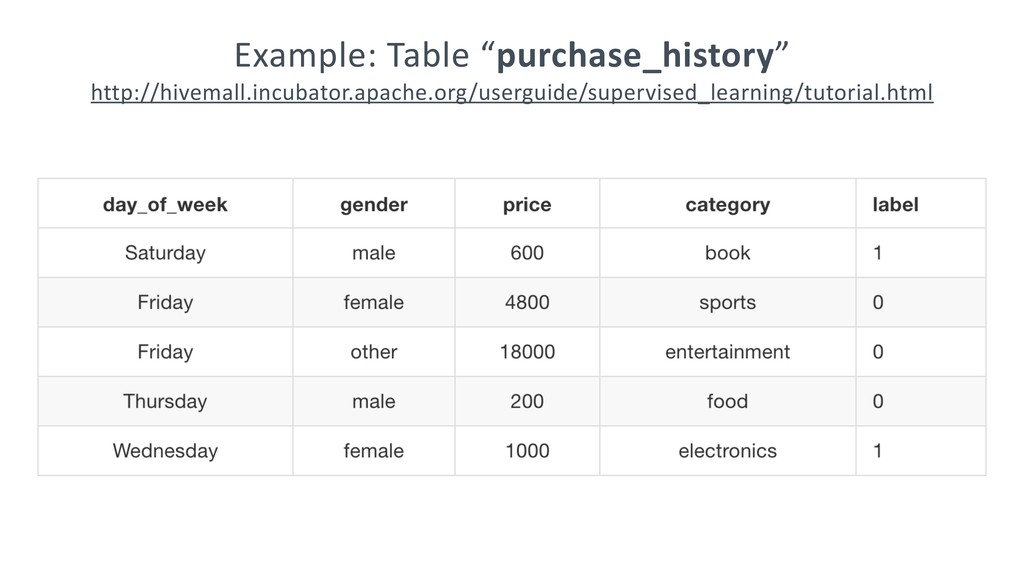
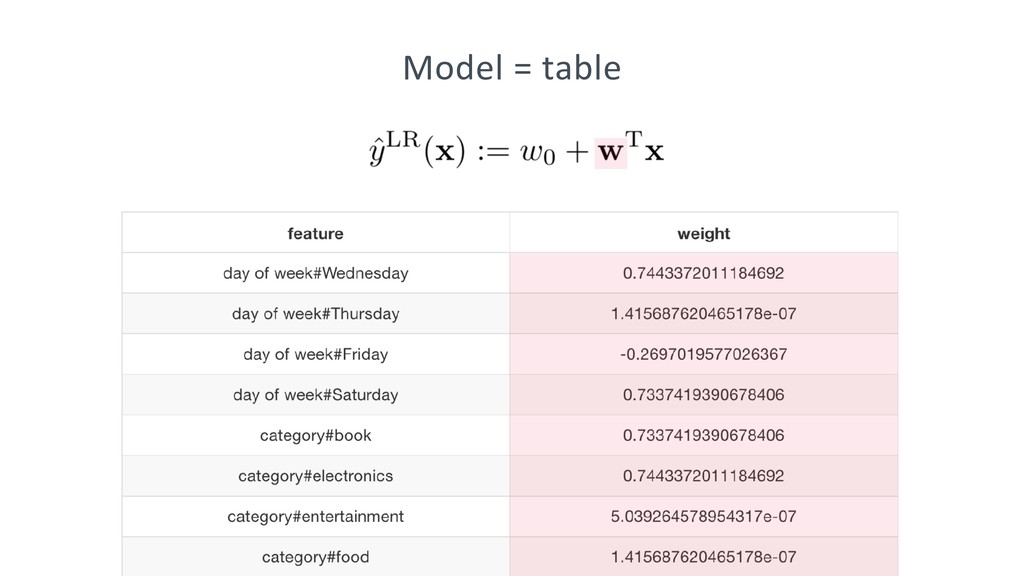
Step-by-step tutorial: http://hivemall.incubator.apache.org/userguide/supervised_learning/tutorial.html
Demo video: https://www.youtube.com/watch?v=cMUsuA9KZ_c
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
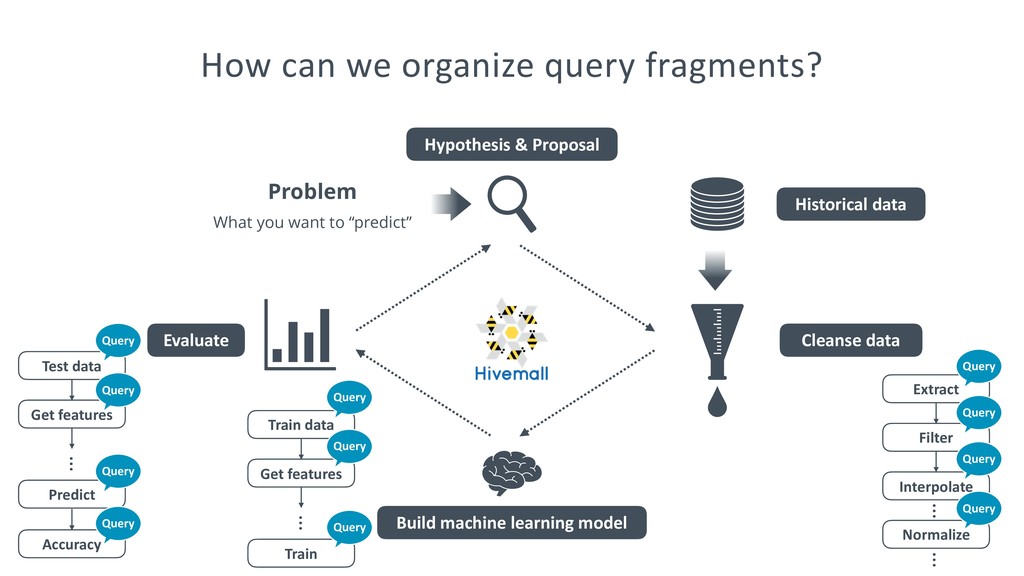{kind=link}
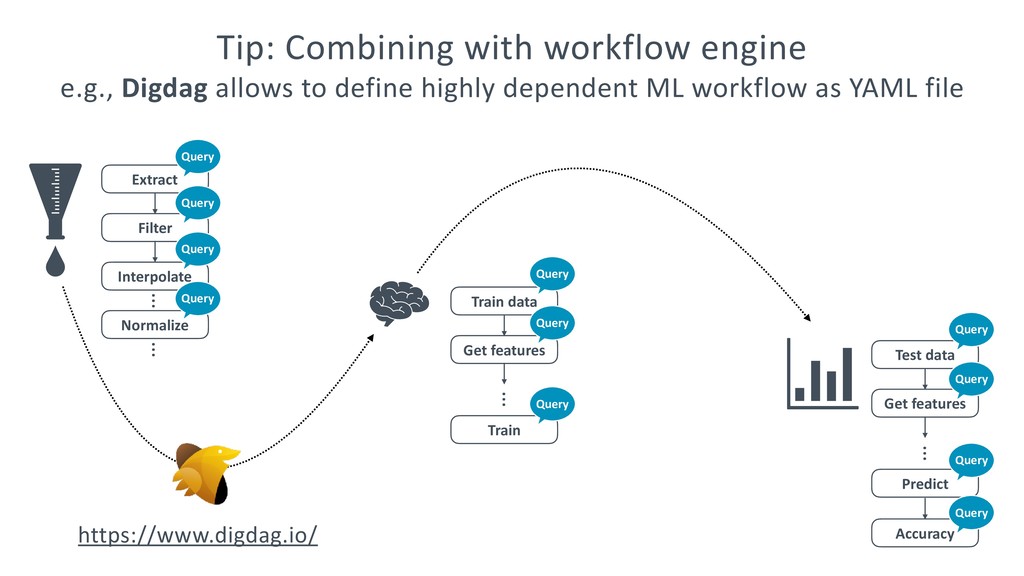{kind=link}
{kind=link}
{kind=link}
{kind=link}
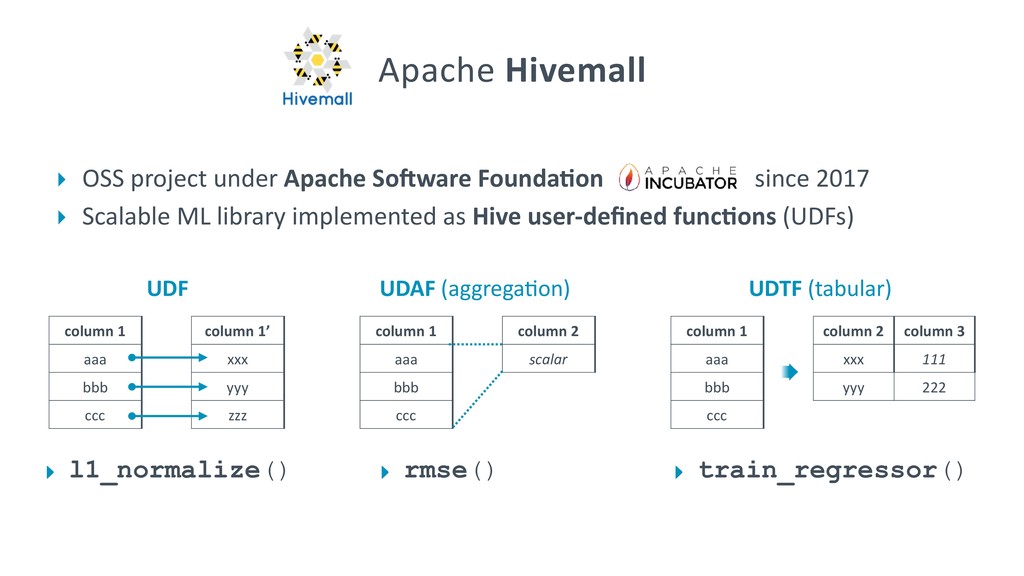{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}