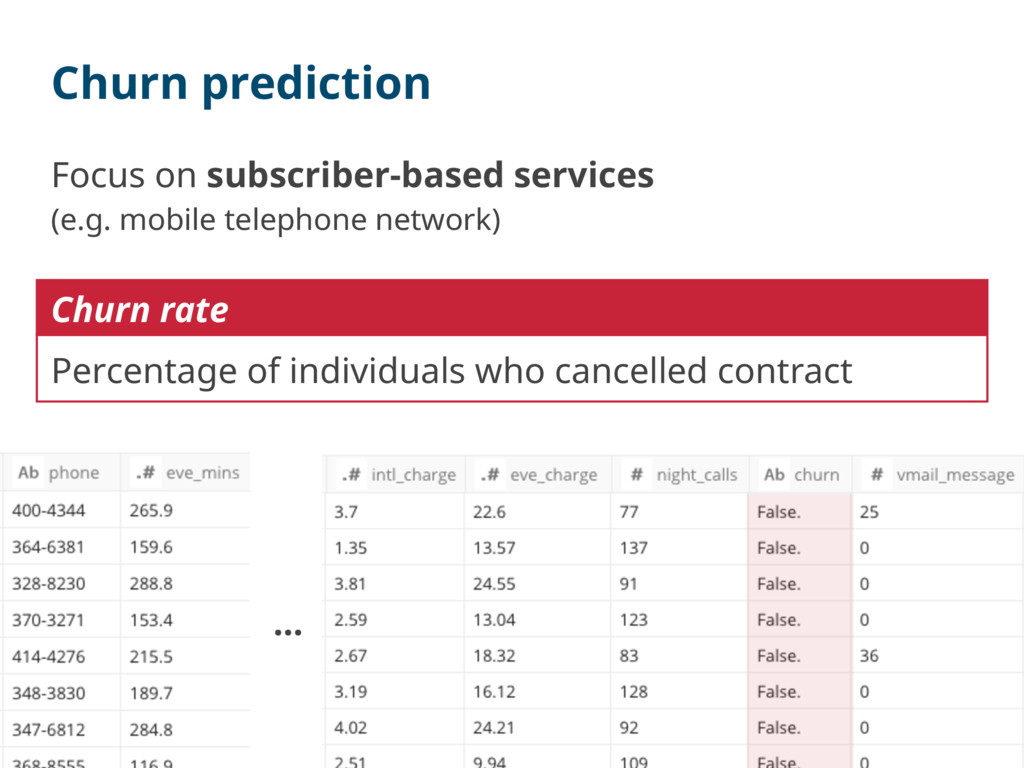
Datadog anomaly detection — thanks @nahi! Very difficult… Customer churn prediction on TD Random Forest on Hivemall & td-pandas Sales/consulting MTGs Attend 2 MTGs w/ @myui and other members
Datadog anomaly detection — thanks @nahi! Very difficult… Customer churn prediction on TD Random Forest on Hivemall & td-pandas Sales/consulting MTGs Attend 2 MTGs w/ @myui and other members
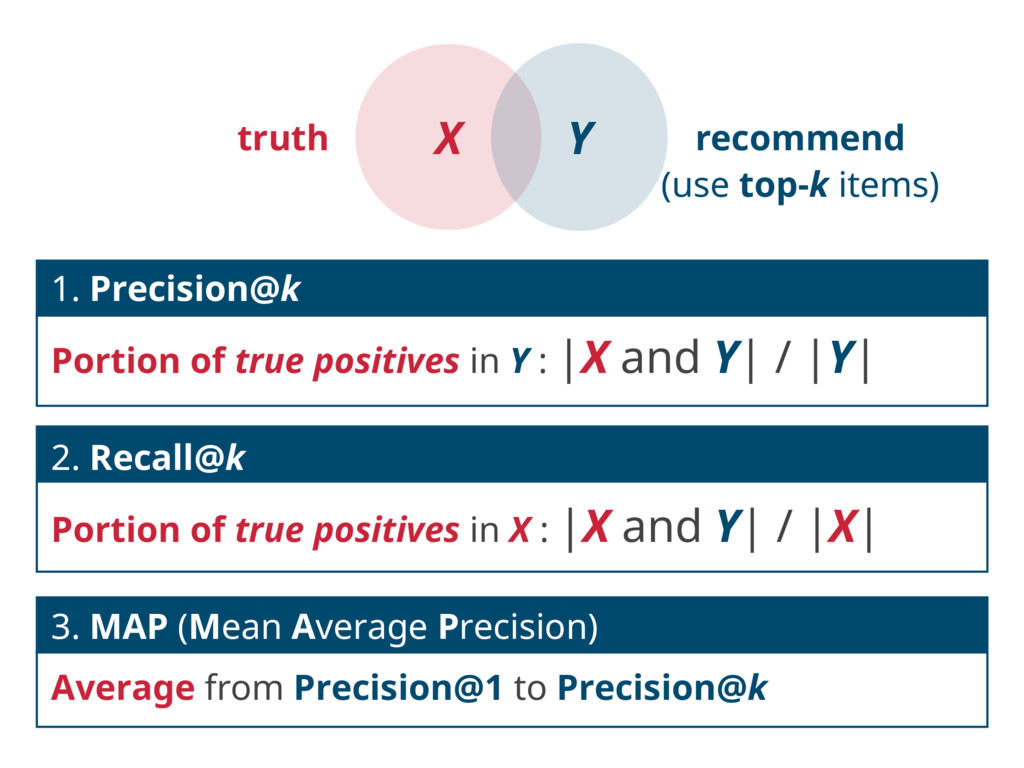
and Y| / |Y| 2. Recall@k Portion of true positives in X : |X and Y| / |X| 3. MAP (Mean Average Precision) Average from Precision@1 to Precision@k truth recommend (use top-k items) X Y
Datadog anomaly detection — thanks @nahi! Very difficult… Customer churn prediction on TD Random Forest on Hivemall & td-pandas Sales/consulting MTGs Attend 2 MTGs w/ @myui and other members
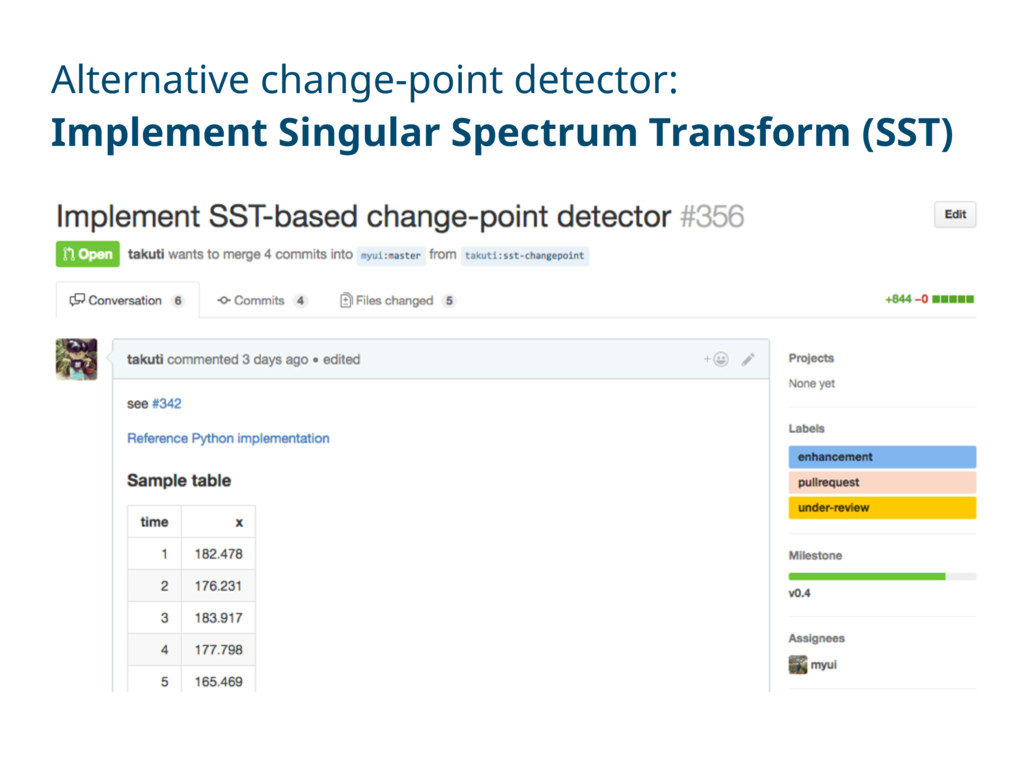
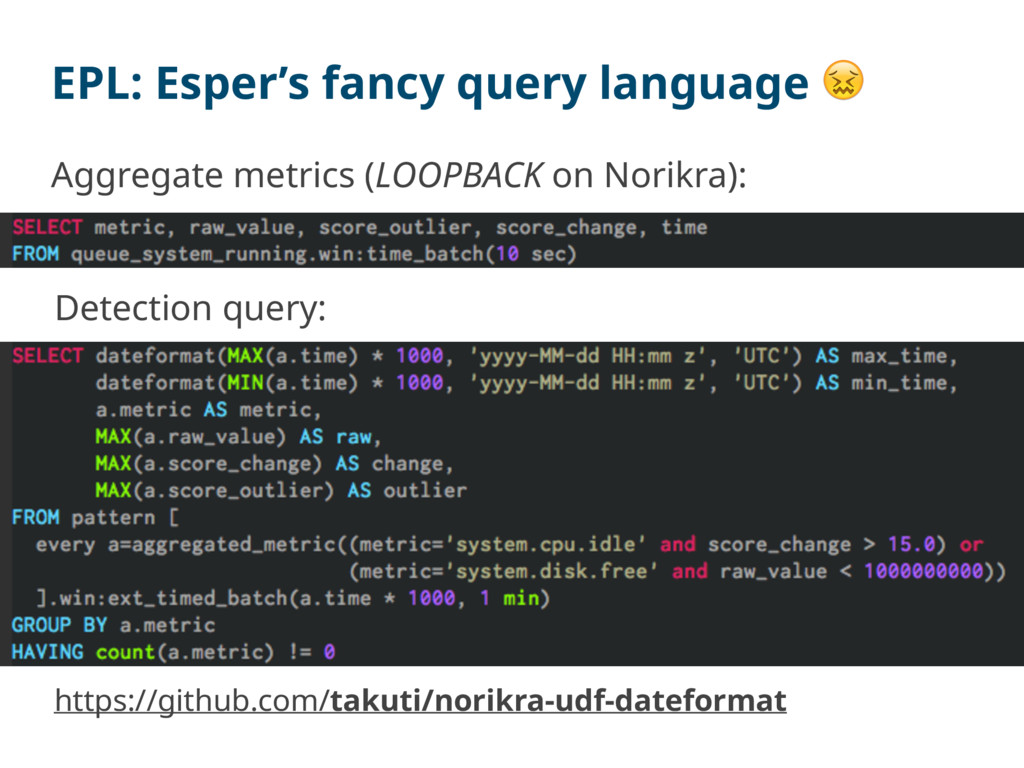
5 165.469 … … SELECT time, changefinder(x, “-changepoint_threshold 0.005") FROM timeseries ORDER BY time ASC SELECT time, sst(x, "-threshold 0.005") FROM timeseries ORDER BY time ASC Change-point detection on Hivemall
Datadog anomaly detection — thanks @nahi! Very difficult… Customer churn prediction on TD Random Forest on Hivemall & td-pandas Sales/consulting MTGs Attend 2 MTGs w/ @myui and other members
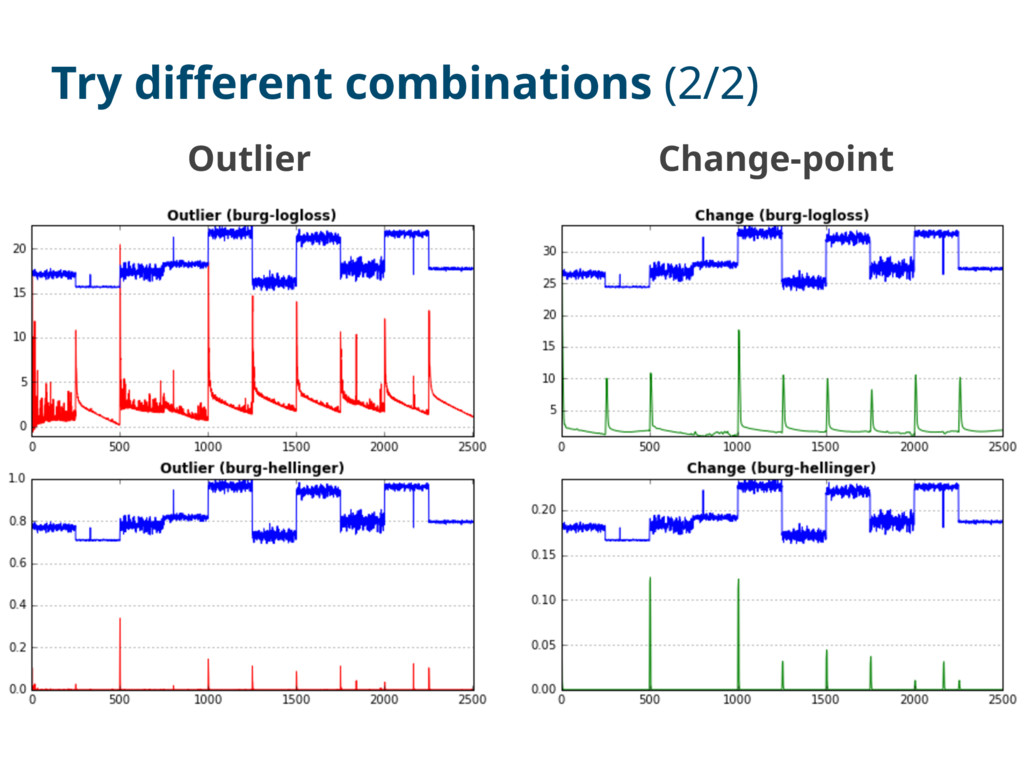
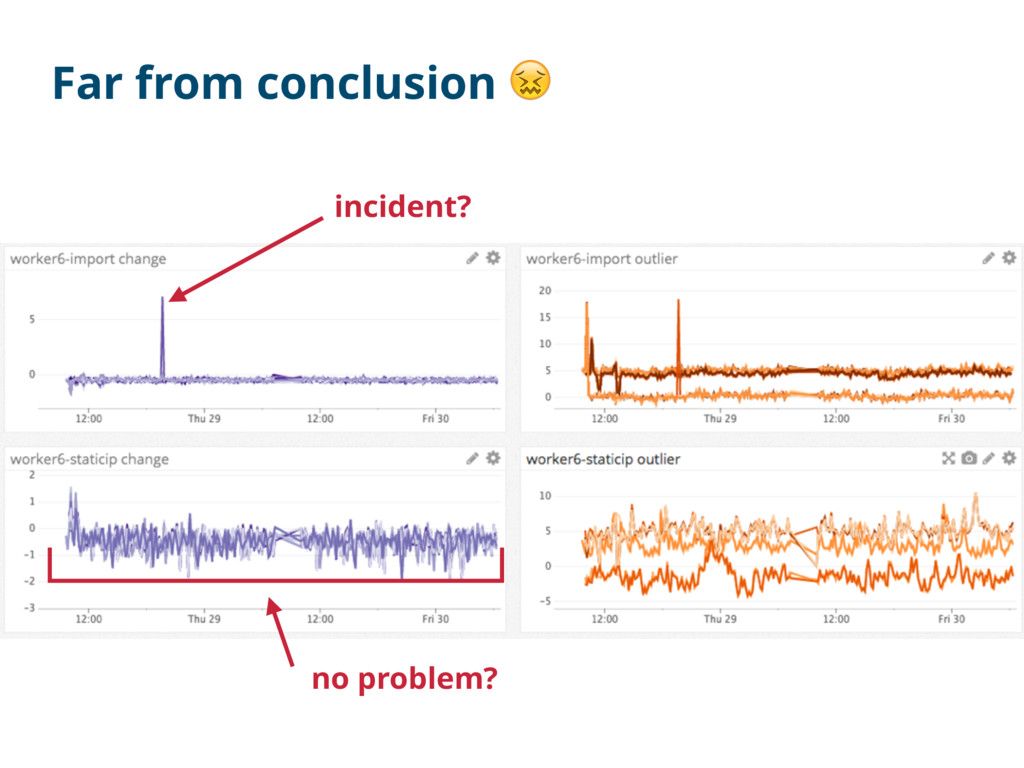
outlier scores We need to detect from more complex conditions reduce false positives (e.g. check if metric-A AND metric-B show high outlier scores) https://www.datadoghq.com/blog/introducing-outlier-detection-in-datadog/
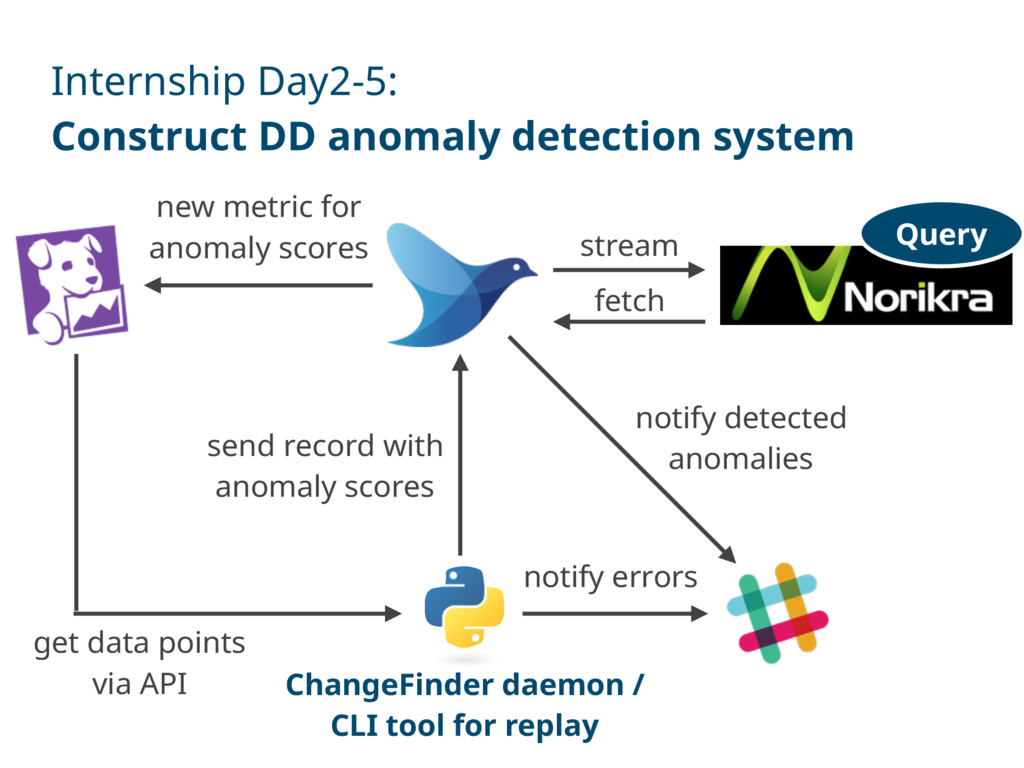
via API new metric for anomaly scores ChangeFinder daemon / CLI tool for replay send record with anomaly scores notify detected anomalies notify errors stream fetch Query
via API new metric for anomaly scores ChangeFinder daemon / CLI tool for replay send record with anomaly scores notify detected anomalies notify errors stream fetch Query Yay! My intern has been finished! (?)
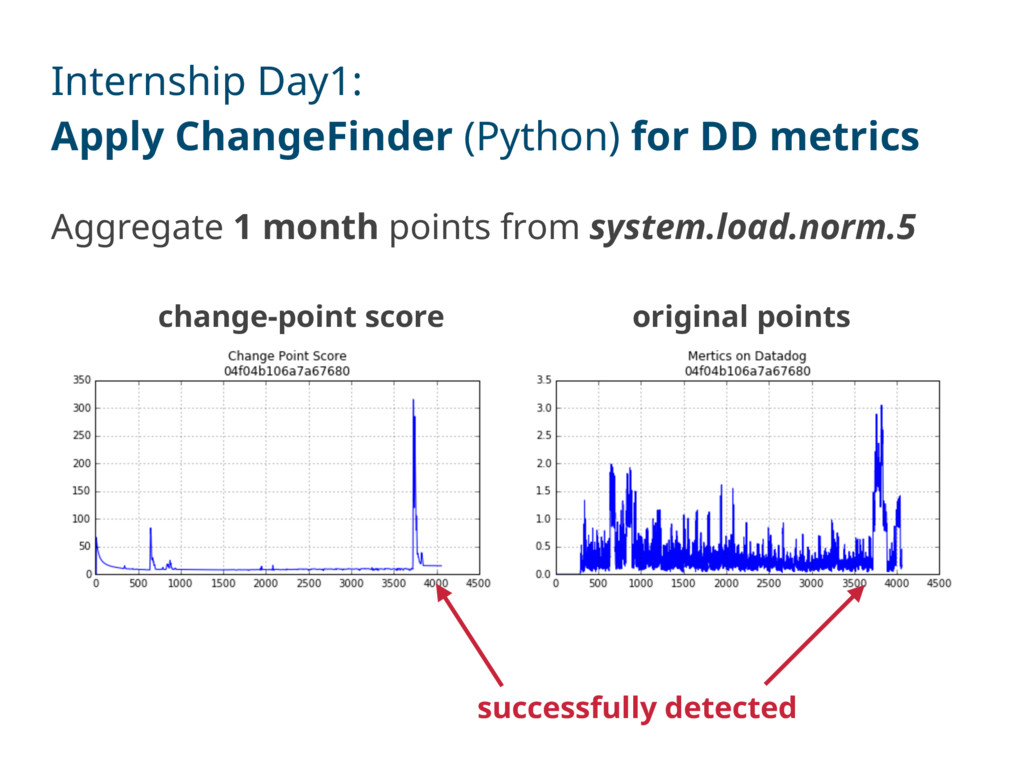
soon as possible Feasibility of ChangeFinder for DD metrics CF works as expected on some metrics Hard to figure out useful metrics due to CF’s instability Lack of Norikra-side evaluation
too short to build useful anomaly detector w/ sufficient evaluation Future directions Continuous discussions w/ metric observers More static analysis w/ different methods and options re:dash integration + can be research project
Datadog anomaly detection — thanks @nahi! Very difficult… Customer churn prediction on TD Random Forest on Hivemall & td-pandas Sales/consulting MTGs Attend 2 MTGs w/ @myui and other members
Datadog anomaly detection — thanks @nahi! Very difficult… Customer churn prediction on TD Random Forest on Hivemall & td-pandas Sales/consulting MTGs Attend 2 MTGs w/ @myui and other members
Datadog anomaly detection — thanks @nahi! Very difficult… Customer churn prediction on TD Random Forest on Hivemall & td-pandas Sales/consulting MTGs Attend 2 MTGs w/ @myui and other members
skills Integrating numerous middleware Science Understanding concepts behind equations Having practical point of view (e.g. complexity, usability) Human factor Experience on various data to incorporate heuristics Communication skills to get customers’ requirements
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CF also has 4 hyperparameters r (float; [0, 1]) k](https://files.speakerdeck.com/presentations/60d7198f9d5048b6bb1187830c0357b2/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
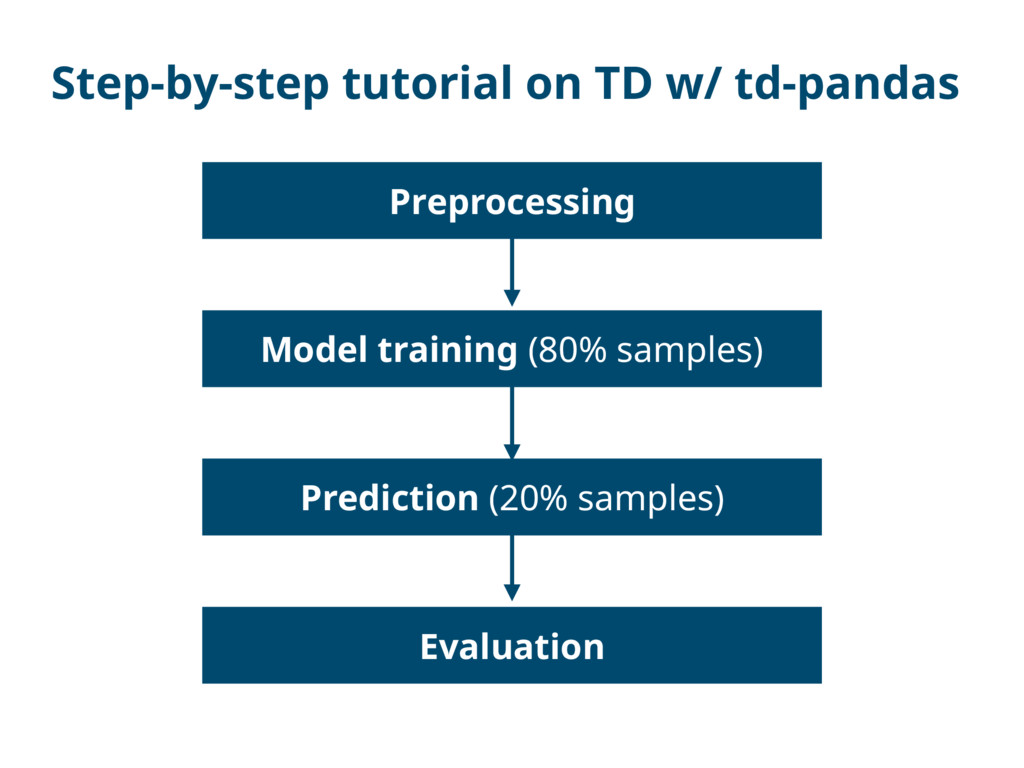{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
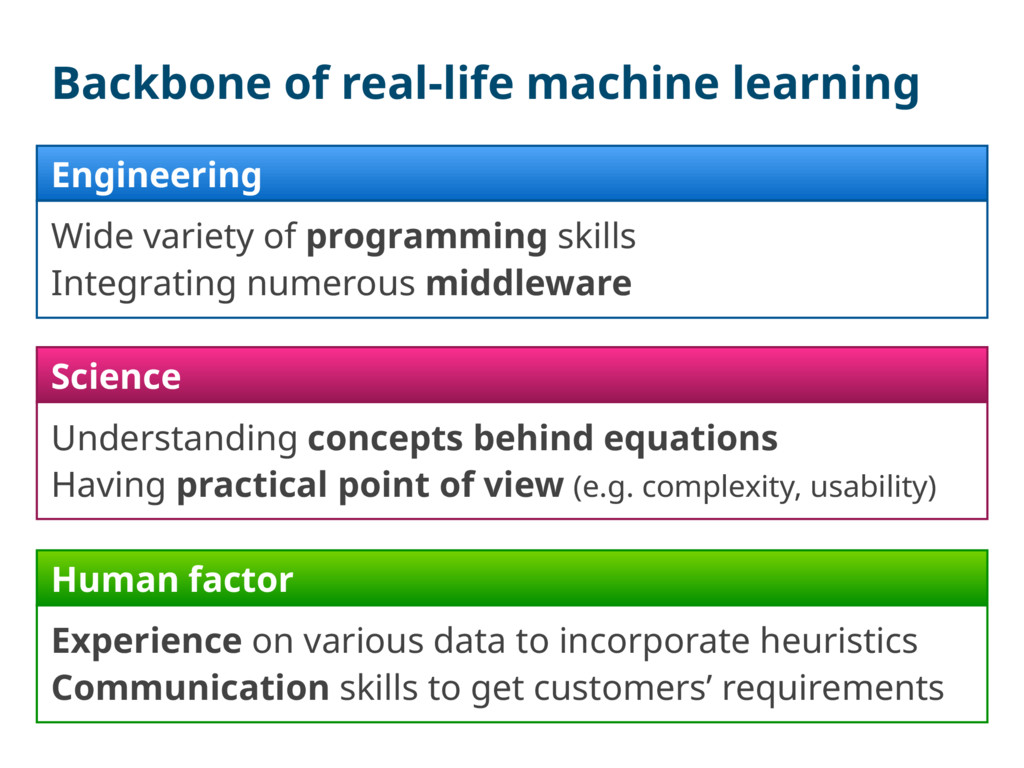{kind=link}
{kind=link}
{kind=link}
{kind=link}