The University of Aizu, Fukushima, Japan * Current affiliation is Graduate School of Information Science and Technology, The University of Tokyo, Japan User Modeling in Folksonomies: Relational Clustering and Tag Weighting
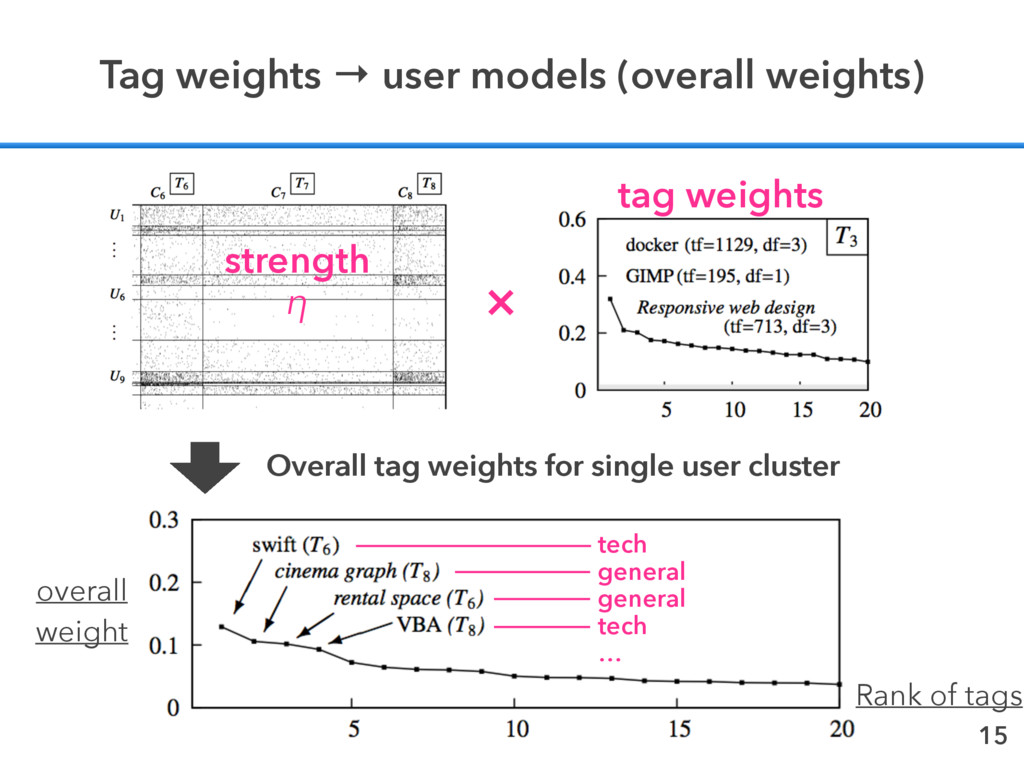
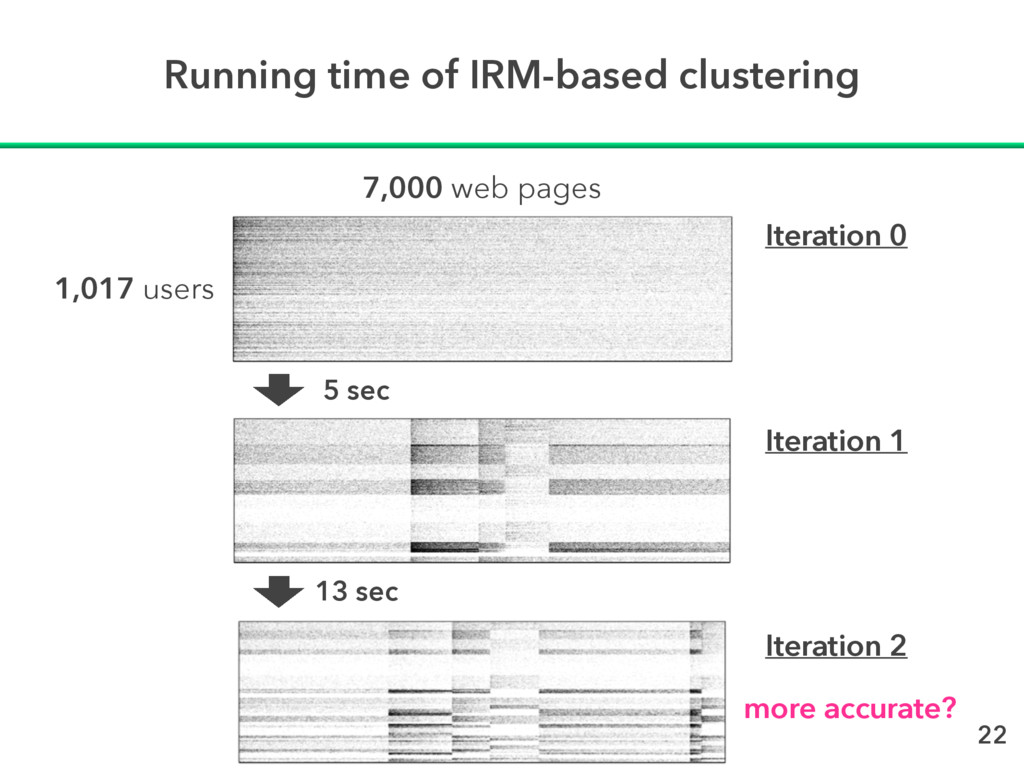
clustering ✦ Find group structures with strength = η C. Kemp et al. Learning systems of concepts with an infinite relational model. In Proc. of AAAI2006, pp. 381–388, July 2006. assign clusters and then sorted
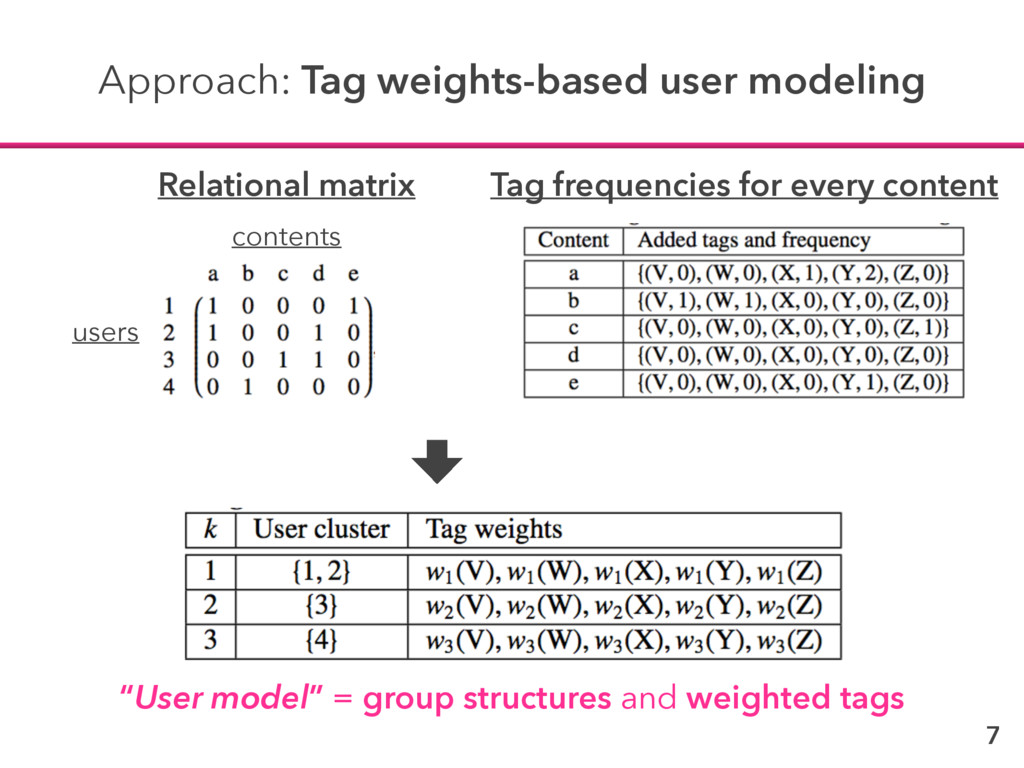
information retrieval Term Frequency (TF) Terms appear many times → characteristic Inverse Document Frequency (IDF) Terms appear in many different documents → irrelevant (e.g. a, the) use similar idea
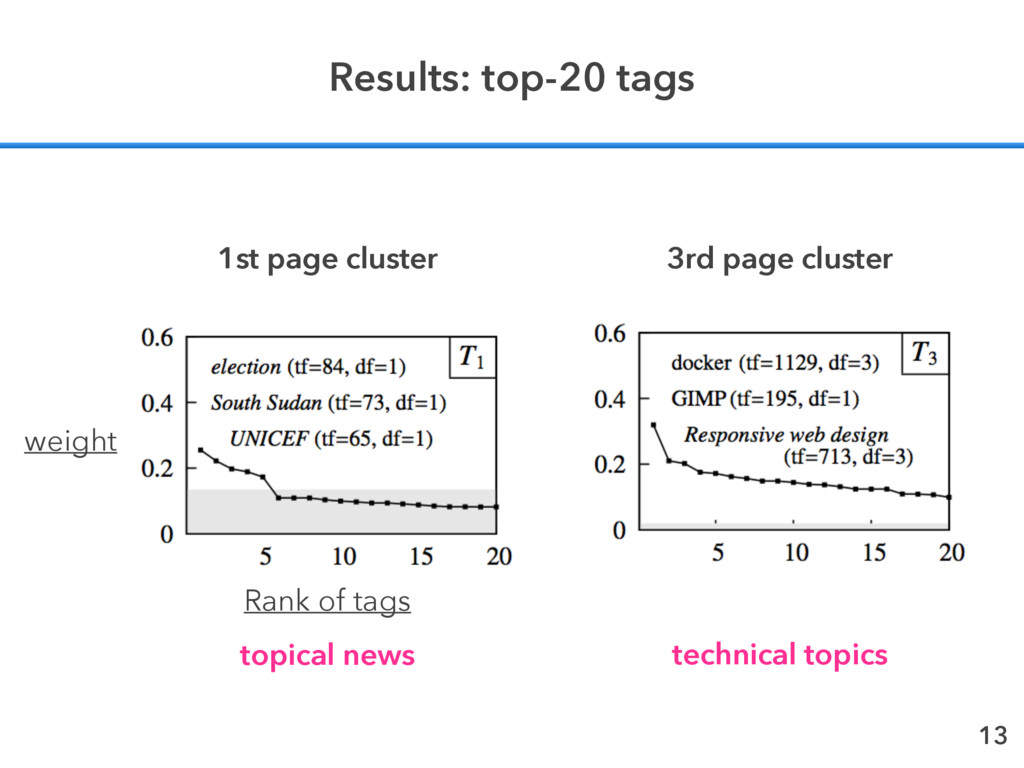
Term Frequency (TF) Tags appear many times → characteristic Inverse Document Frequency (IDF) Tags appear in many different content clusters → irrelevant
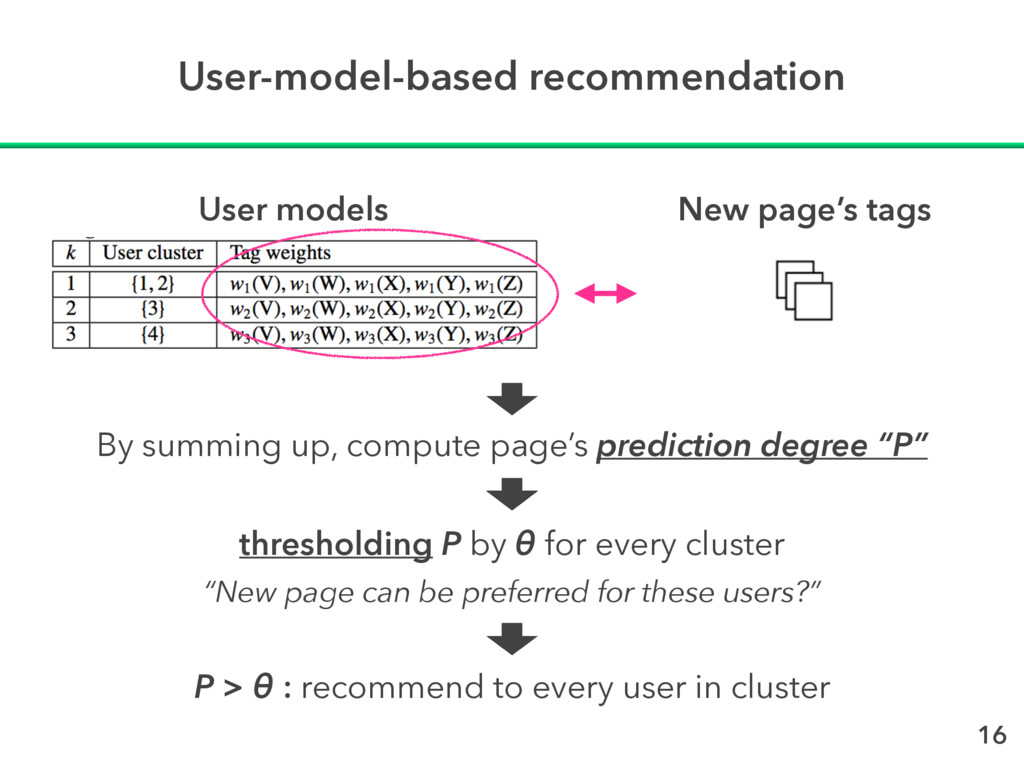
θ for every cluster 16 By summing up, compute page’s prediction degree “P” “New page can be preferred for these users?” P > θ : recommend to every user in cluster
Hatena bookmark 172,365 tuples in total ✦ 5-fold cross validation with F-measure ✦ User modeling by using learning data ✦ Thresholding all test tuples for every user cluster
relational clustering and tag weighting Achieved faster, sketchy recommendation 2. How to tackle problems 3. Recommender system-based evaluation 1. What is Folksonomies? — Problem formulation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![5 Related work [Niwa et al. 2006] S. Niwa et](https://files.speakerdeck.com/presentations/cba4ace8d17f4ddca17be973b5f2f34b/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}