Presentation by Tammy Butow and Thomissa Comellas
Key Takeaways
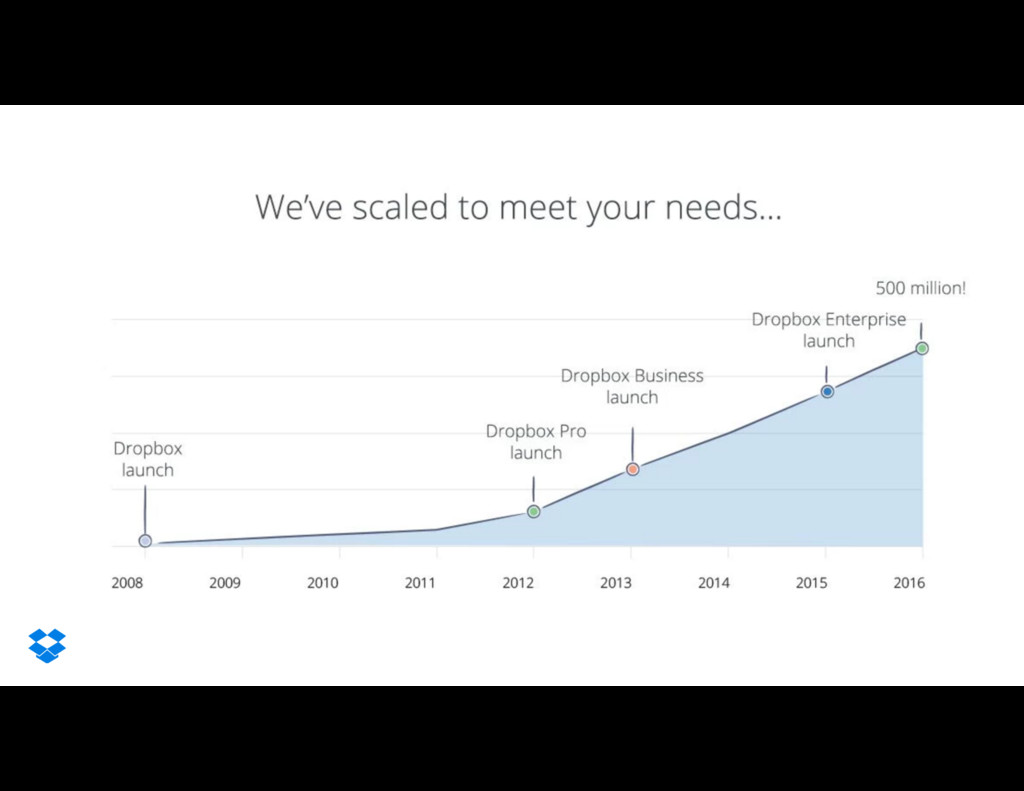
+ Learn how Dropbox uses disaster recovery testing on extremely large scale systems.
+ Understand the benefits of establishing a culture that encourages and promotes active failure testing.
+ Hear about the principles that Dropbox uses allowing teams to focus on the system seams for aggressive failure testing.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
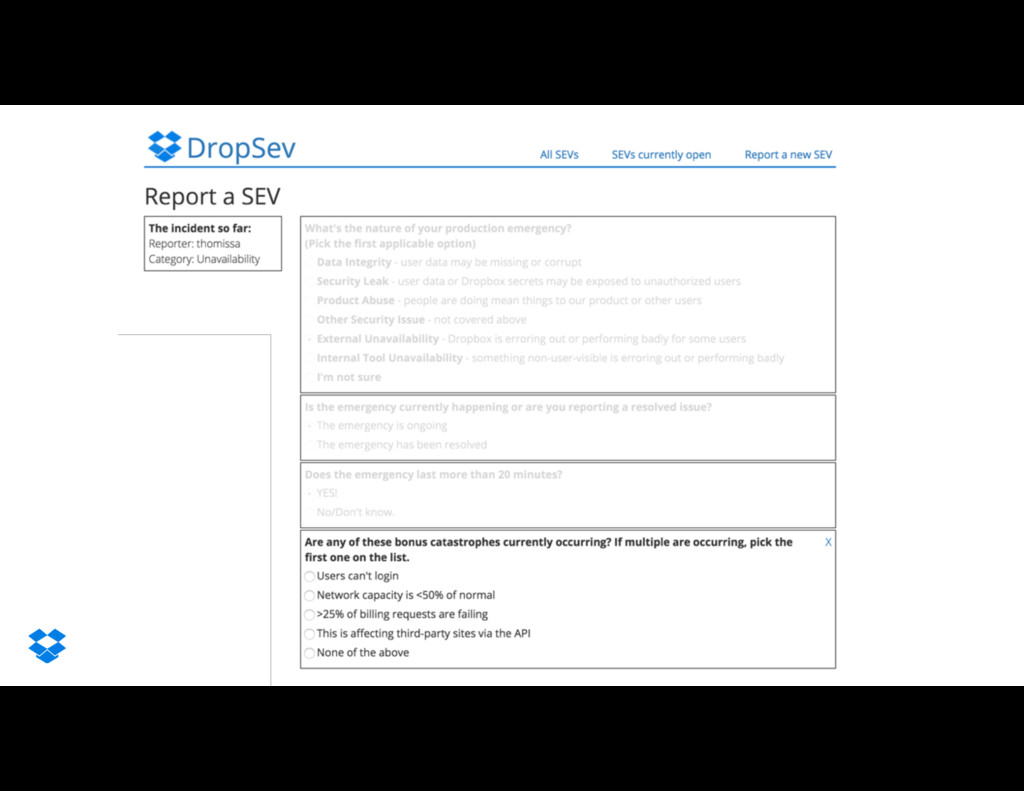{kind=link}
{kind=link}
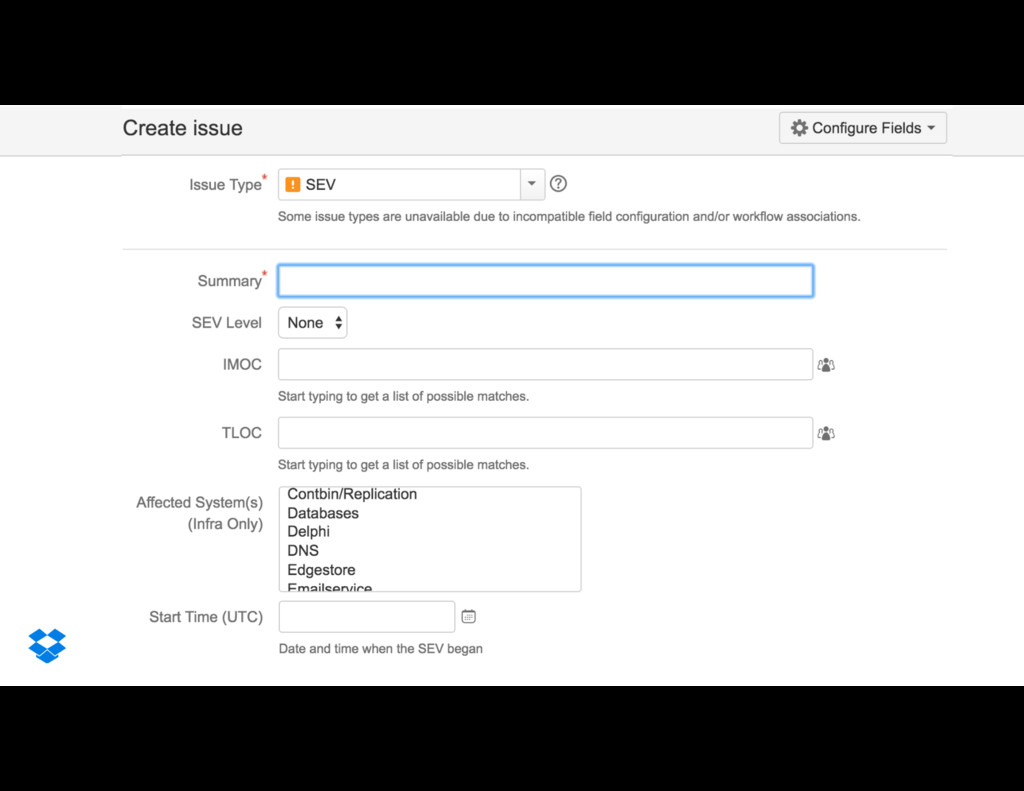{kind=link}
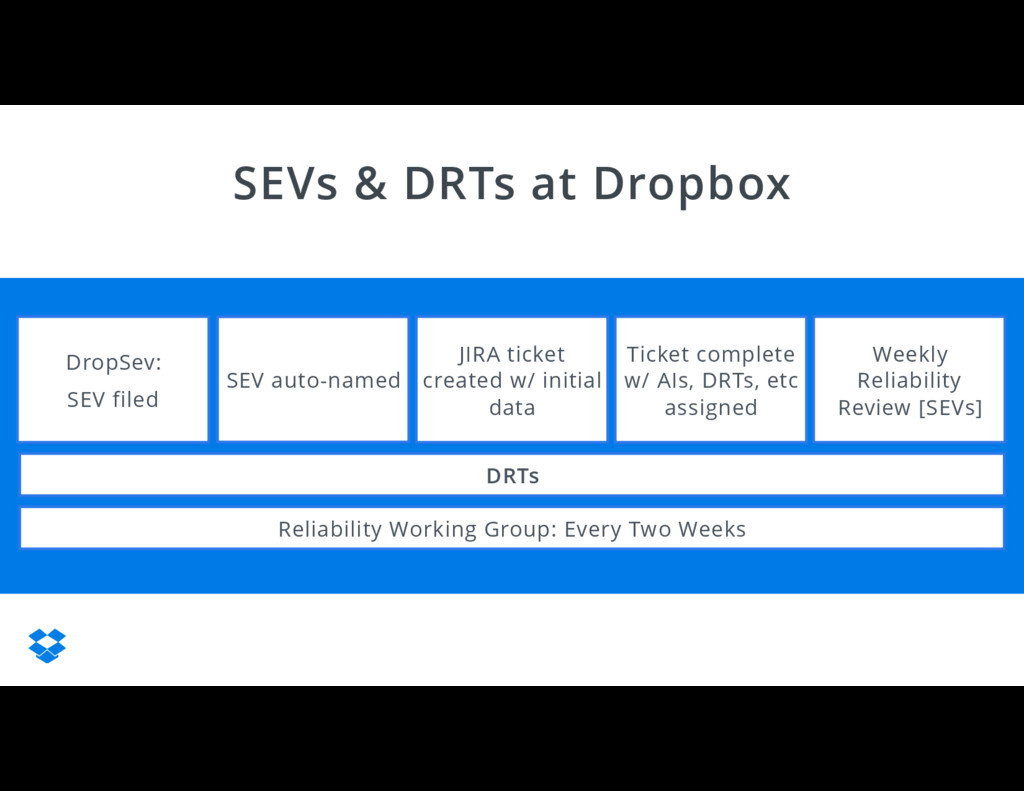{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
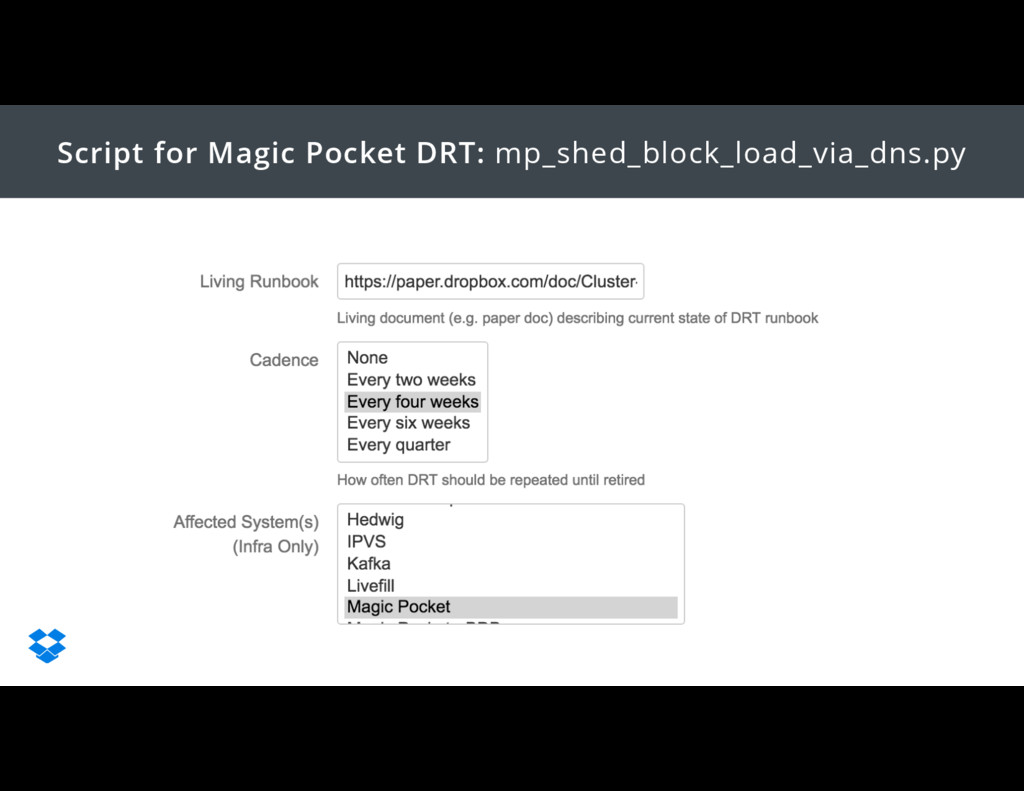{kind=link}
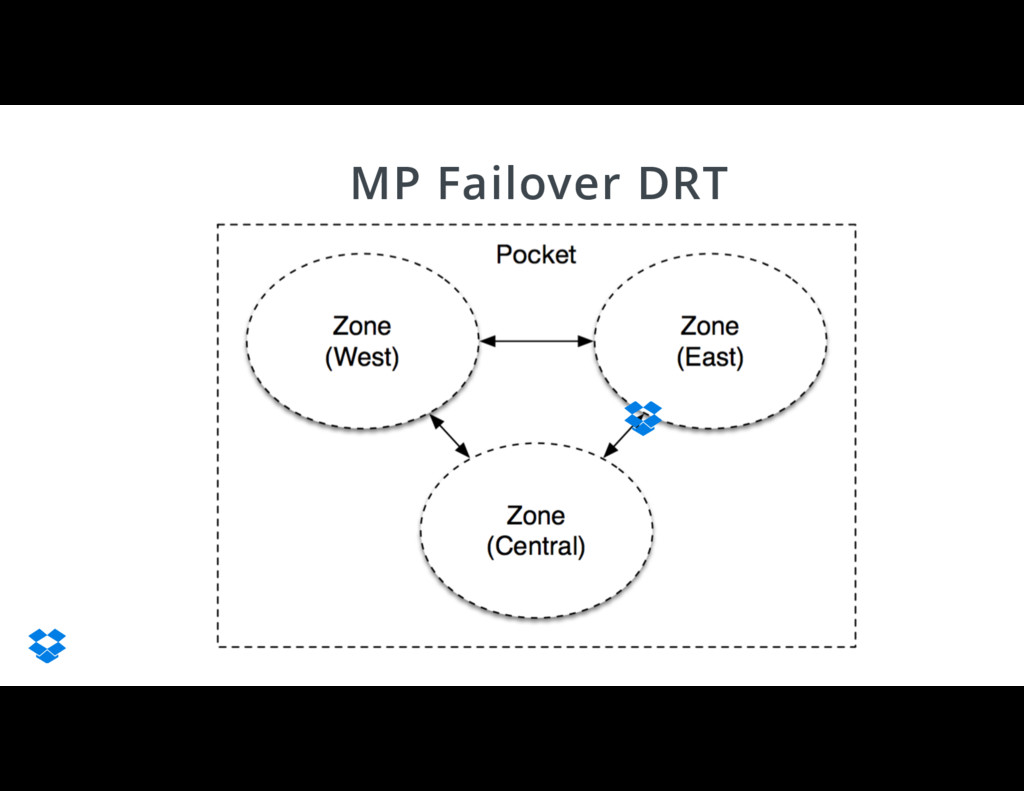{kind=link}
{kind=link}
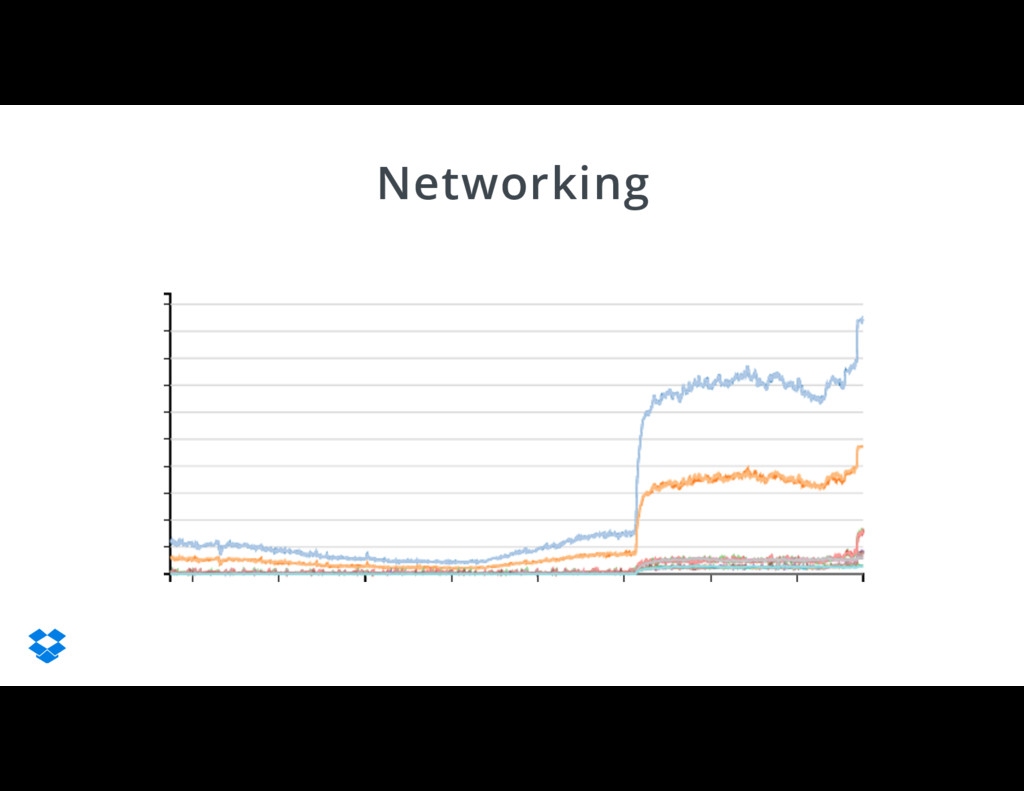{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
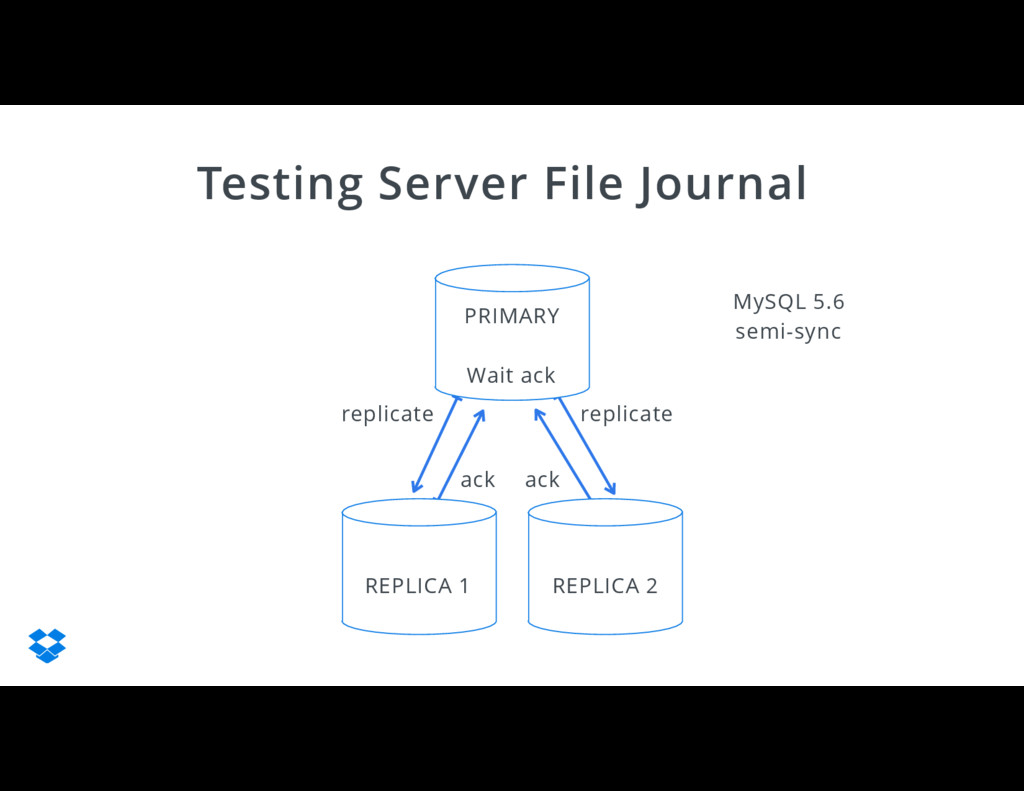{kind=link}
{kind=link}
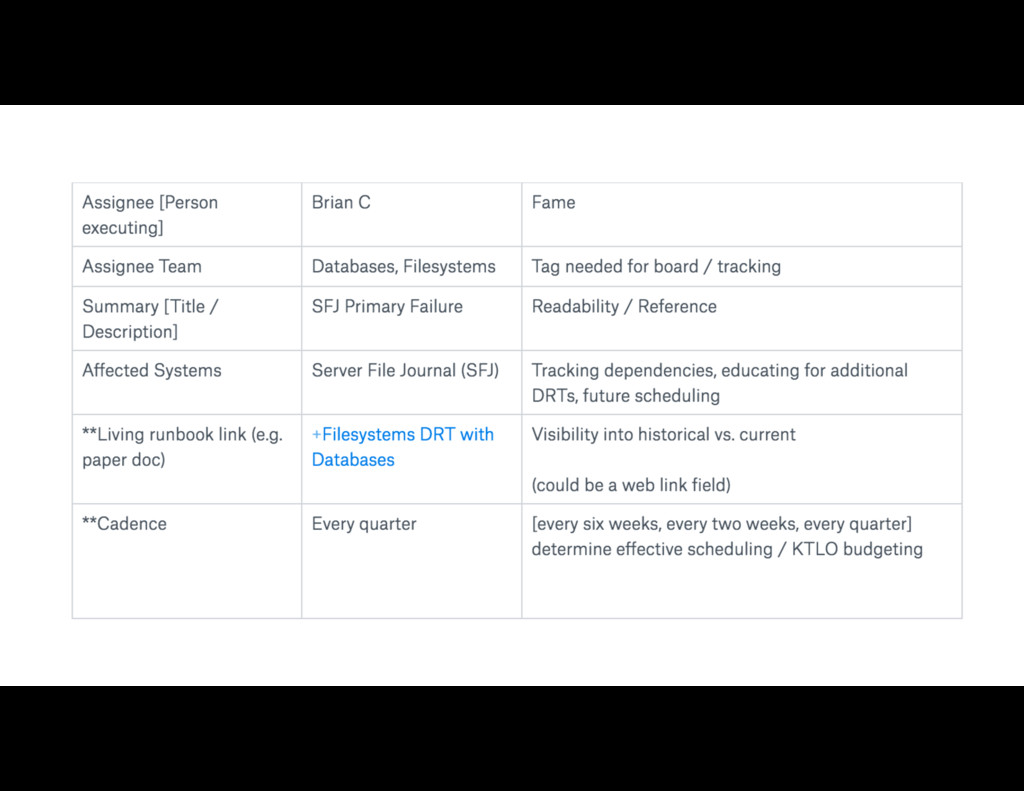{kind=link}
{kind=link}
![[0:20] Run command: $ select hostname, global.rpl_semi_sync_slave_enabled Expected outcome:](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_43.jpg){kind=link}
![[0:22] Run command: $ stop slave; set global rpl_semi_sync_slave_enabled=0; start](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_44.jpg){kind=link}
![[0:26] Check if threads running has spiked on mysql perf](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_45.jpg){kind=link}
![[0:27] Likely to see a spike in lock failures and](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_46.jpg){kind=link}
![[0:30] Threads running will continue to rise [0:32] You should](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_47.jpg){kind=link}
![[0:34] End the DRT by enabling semi-sync, you will start](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_48.jpg){kind=link}
{kind=link}
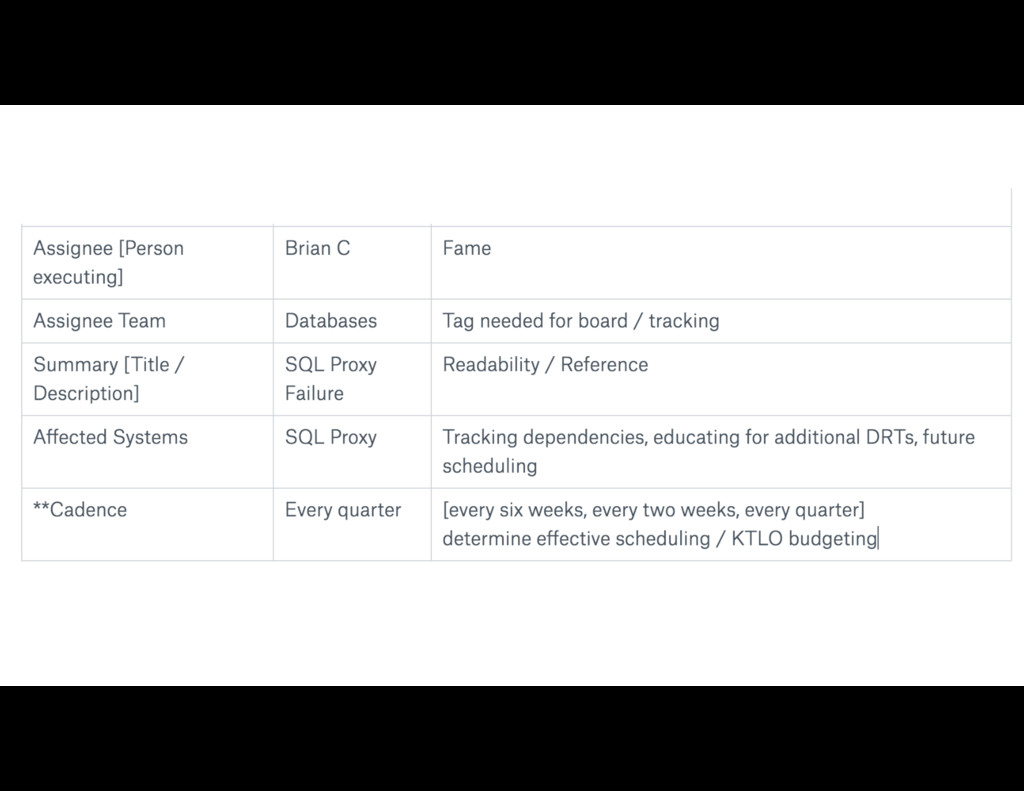{kind=link}
![[0:00] Log into to any sql-proxy host [0:20] Run command:](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_51.jpg){kind=link}
![[0:22] Run command: $ stop sqlproxy_global [0:26] Wait for a](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_52.jpg){kind=link}
![[0:27] Now start sql proxy again $ start sqlproxy_global Expected](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_53.jpg){kind=link}
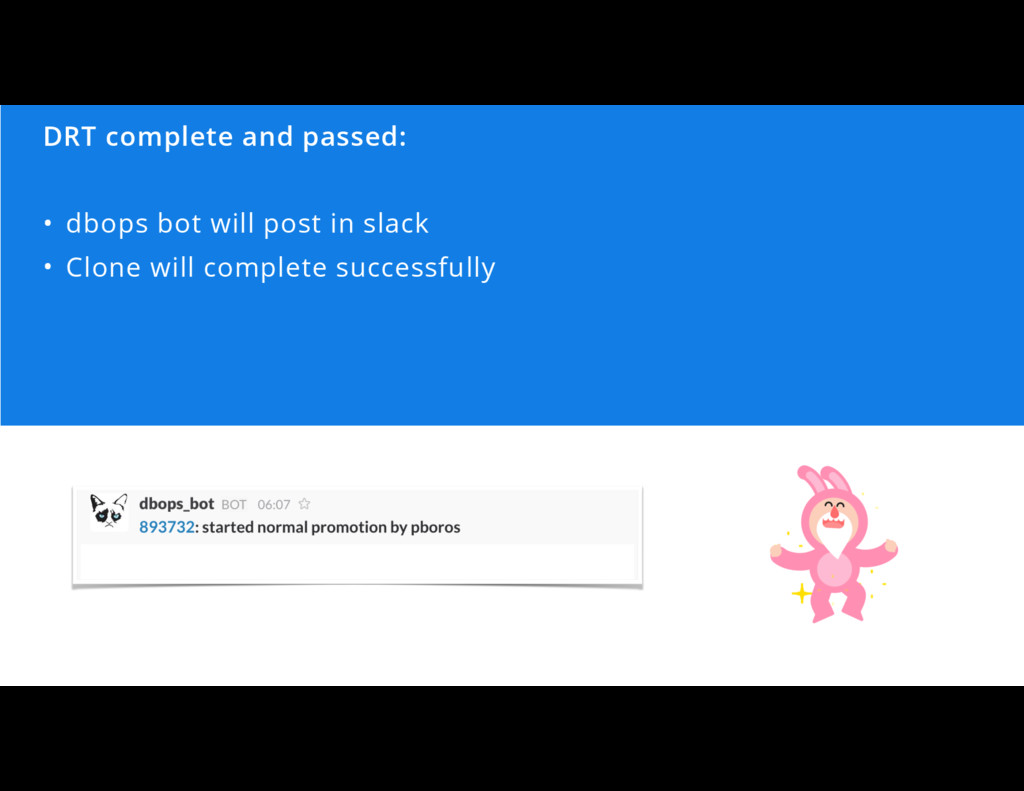
![[0:27] DRT passed! Send an email that it is finished](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_54.jpg){kind=link}
{kind=link}
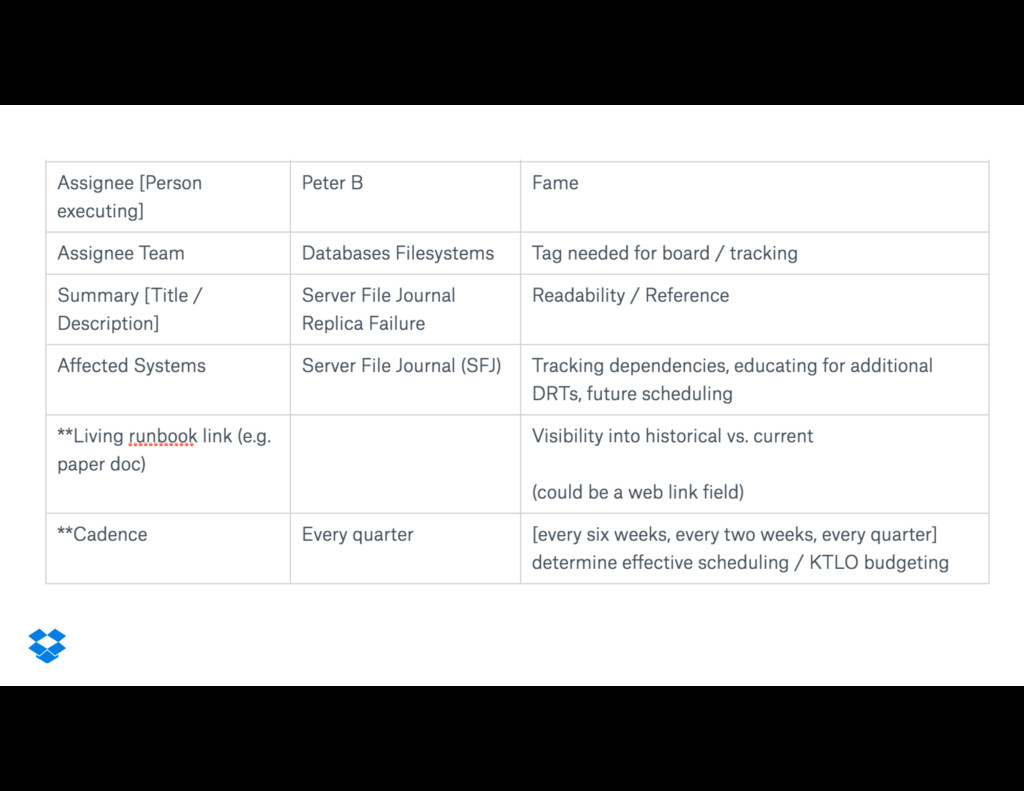{kind=link}
{kind=link}
![[0:00] Choose host to perform DRT on with Filesystems team](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_58.jpg){kind=link}
![[0:10] Fail one replica from production by killing mysqld on](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_59.jpg){kind=link}
{kind=link}
{kind=link}
![[0:20] Run command: $ select hostname, global.rpl_semi_sync_slave_enabled Expected outcome:](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_62.jpg){kind=link}
![[0:22] Run command: $ stop slave; set global rpl_semi_sync_slave_enabled=0; start](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_63.jpg){kind=link}
![[0:26] Check if threads running has spiked on mysql perf](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_64.jpg){kind=link}
![[0:27] Likely to see a spike in errors on the](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_65.jpg){kind=link}
![[0:30] Threads running and threads connected will continue to rise](https://files.speakerdeck.com/presentations/ec8a26d5bdfa4d13b395b0d702e65d41/slide_66.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}