Video of the 10 minute talk:
https://www.youtube.com/watch?v=ImOOLwGyj-w
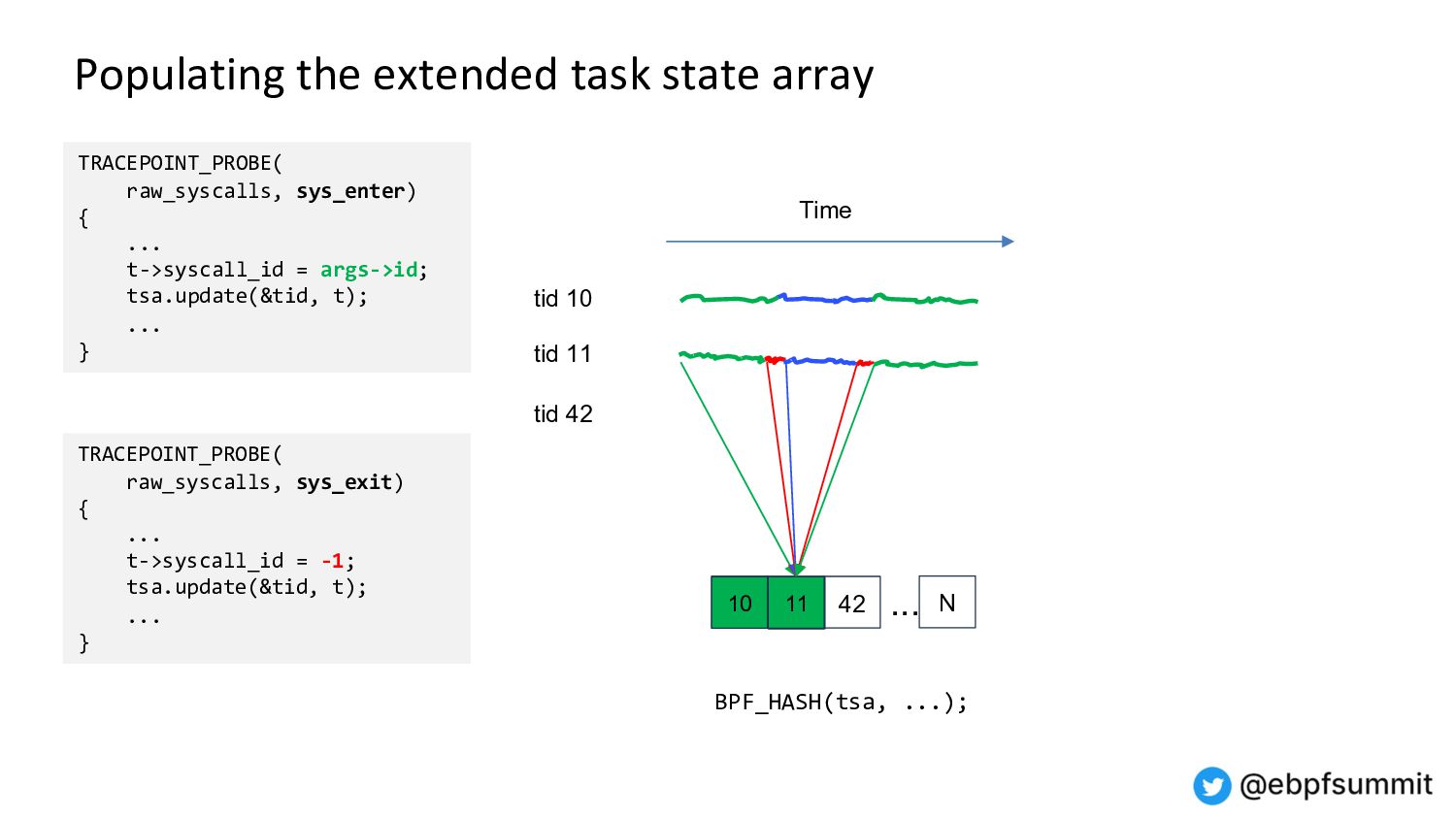
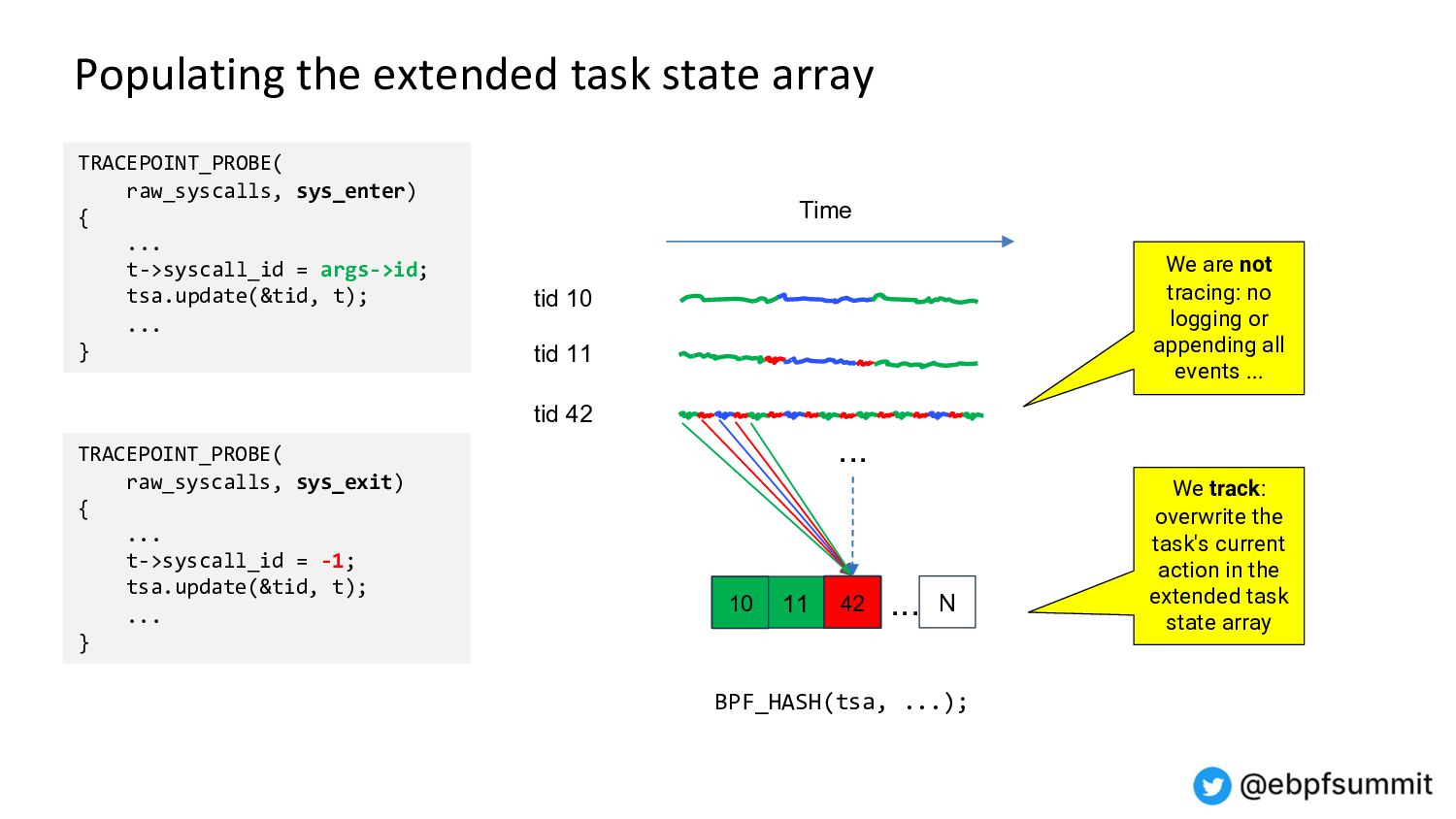
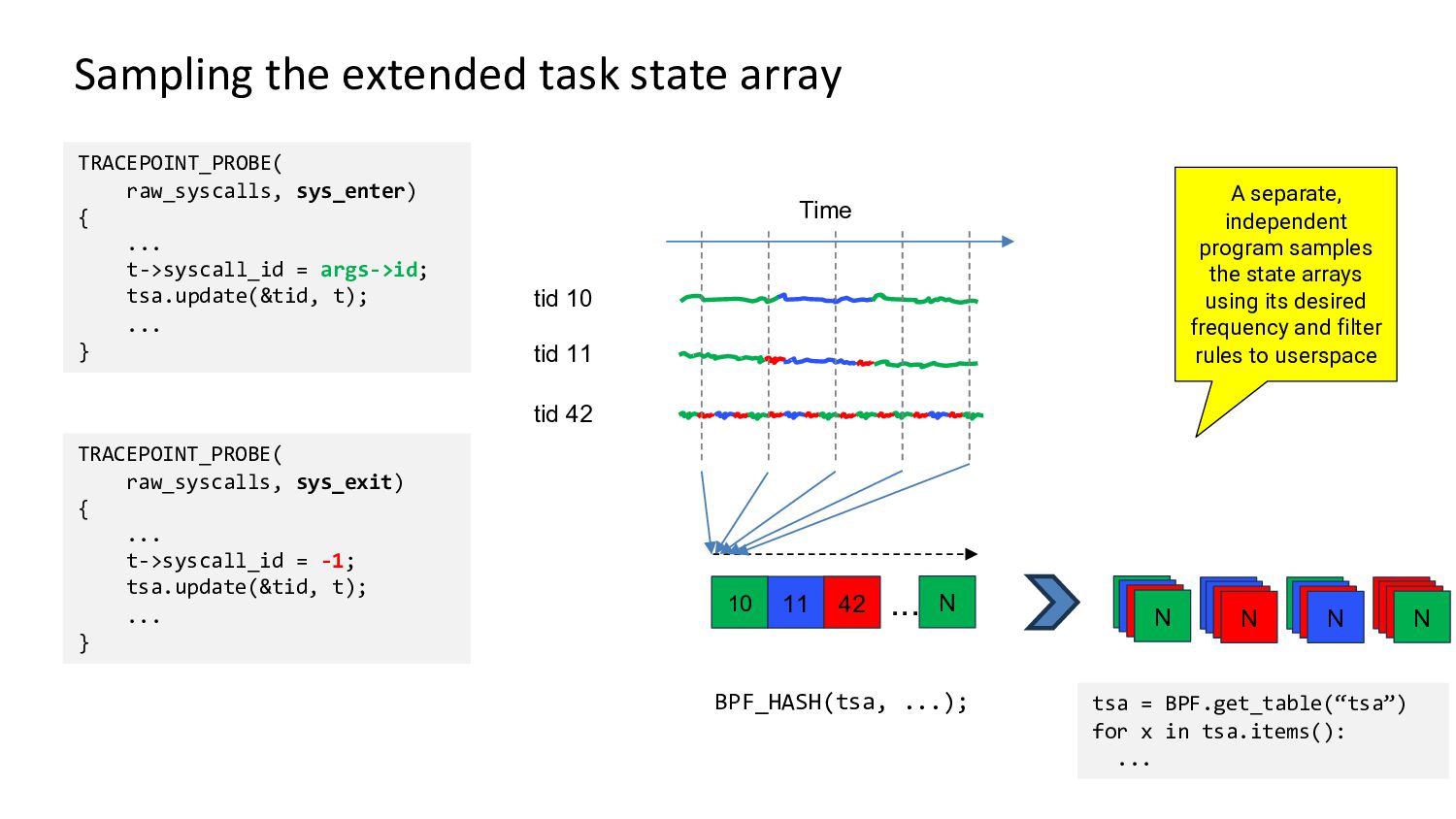
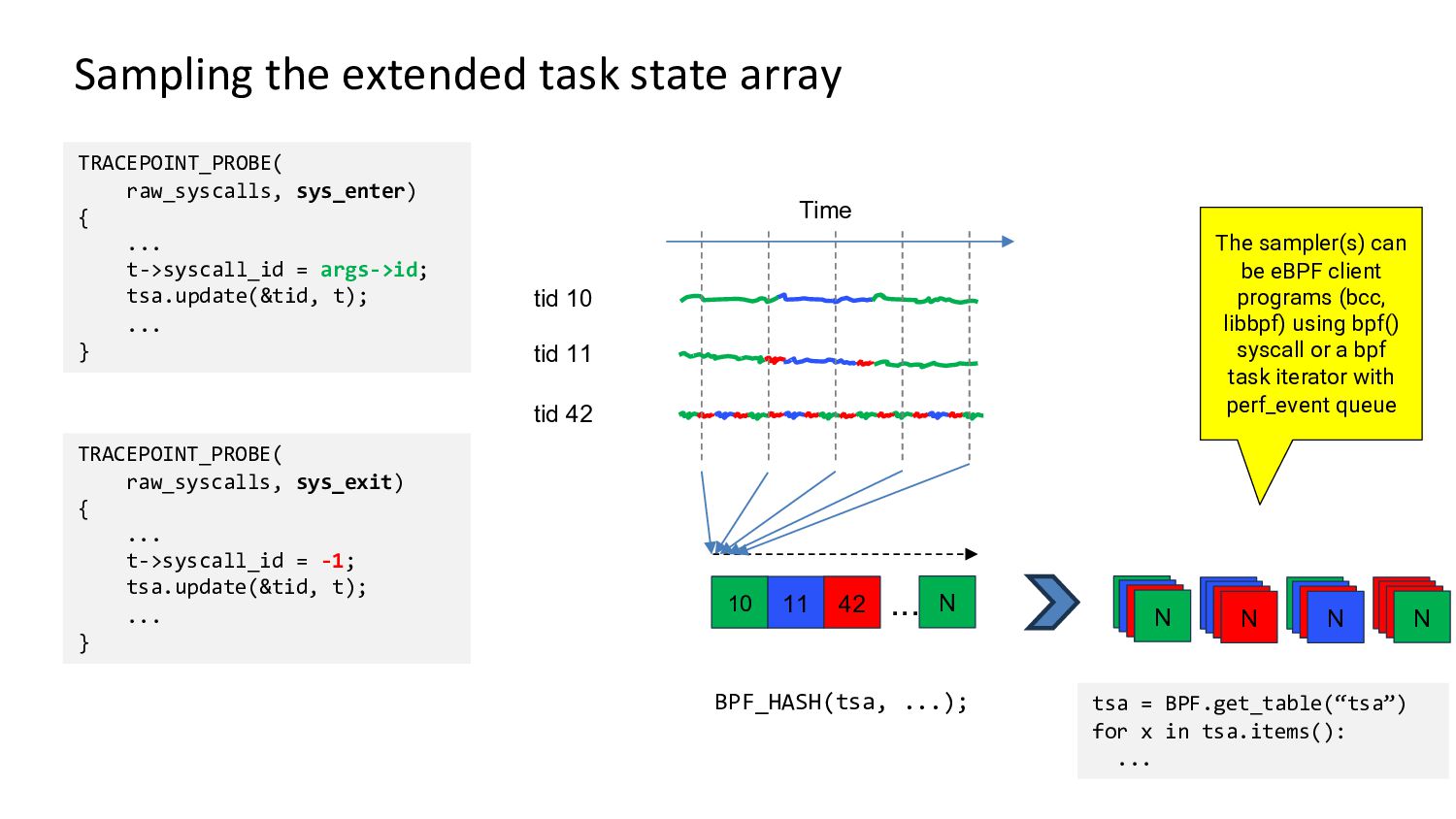
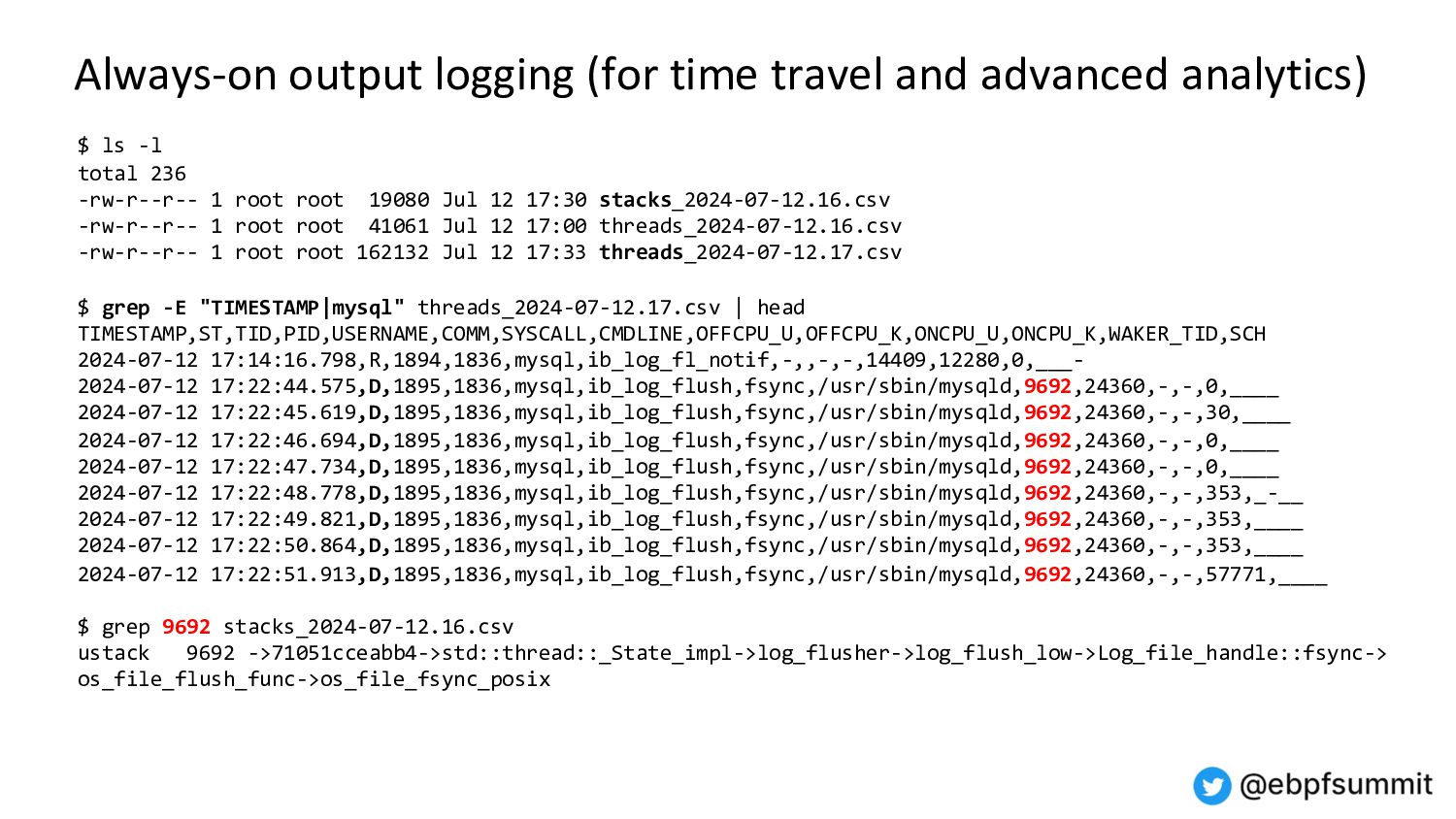
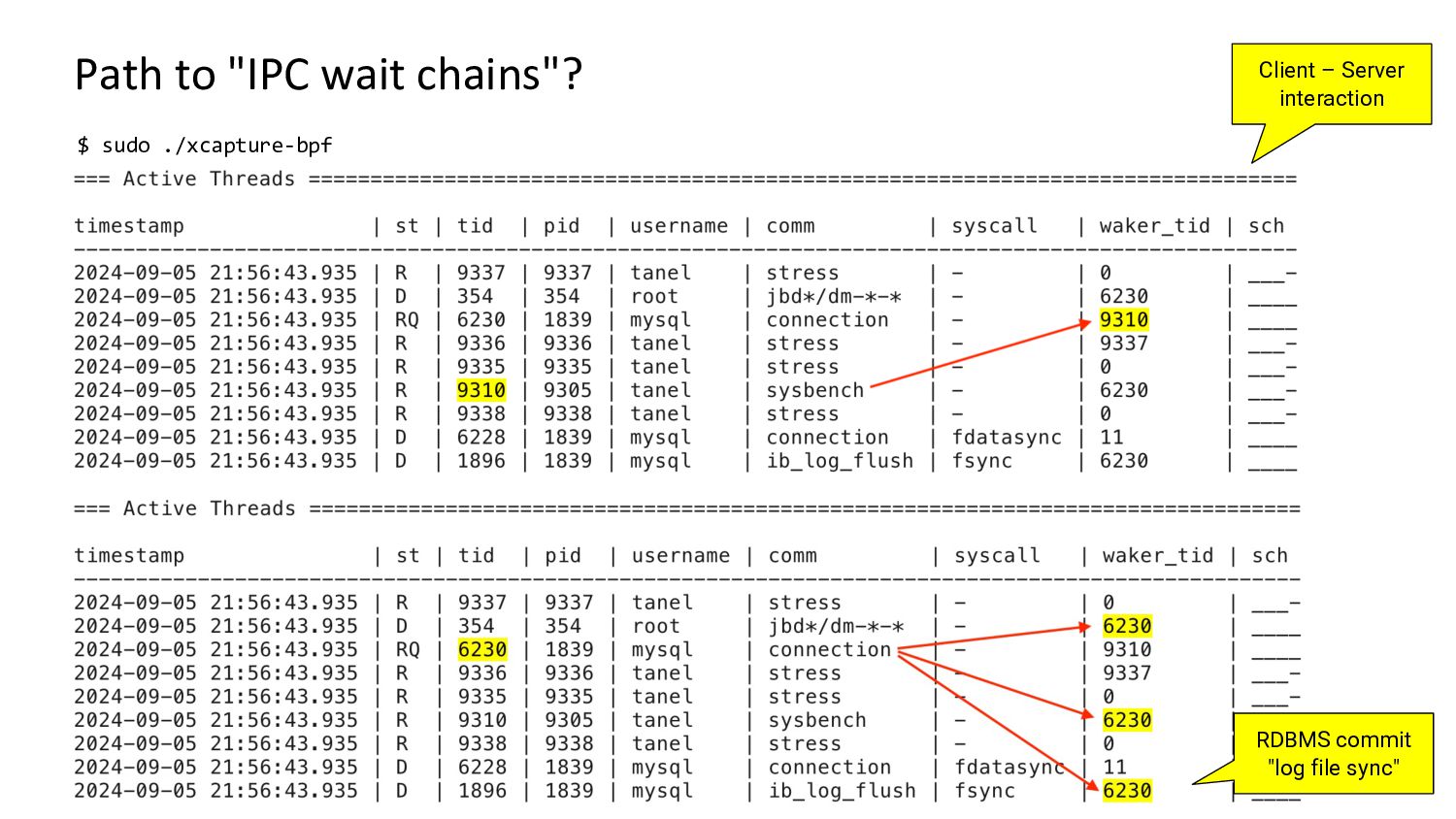
Demo and architecture of the 0x.tools xtop & xcapture-bpf programs using always-on eBPF probes to maintain an “extended task state array”, with periodic state sampling for reporting and display.
This is not traditional tracing, profiling, or global metrics accumulation, but a new approach combining “thread states of interest” sampled over time with application-specific context. It provides visibility into all threads, what they are doing on the CPU, and the reasons for going off the CPU.
This method gives you a reasonable view into the whole system activity, with the ability to drill down into individual thread levels - without having to trace and log every single event.
{kind=link}
{kind=link}
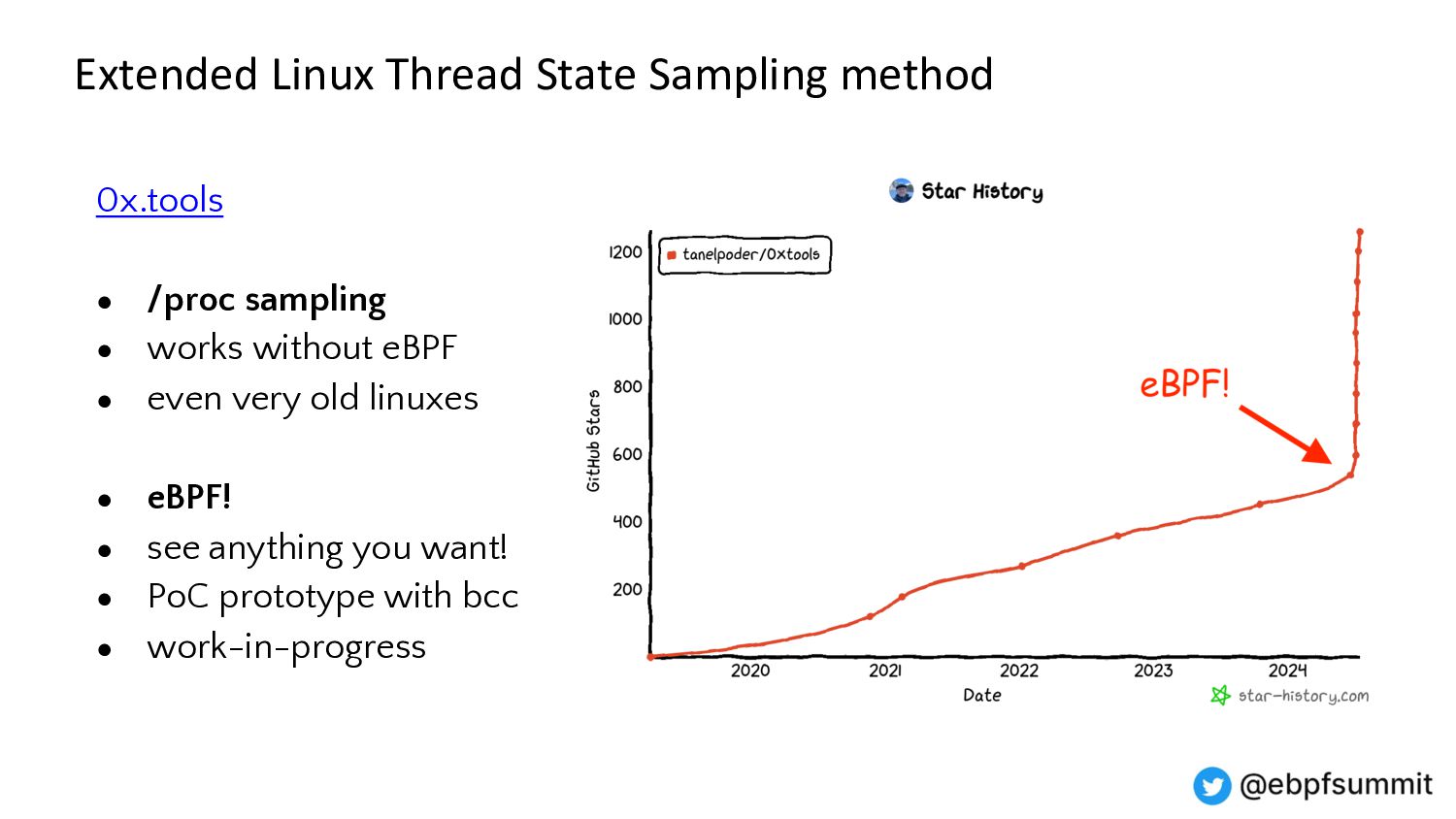{kind=link}
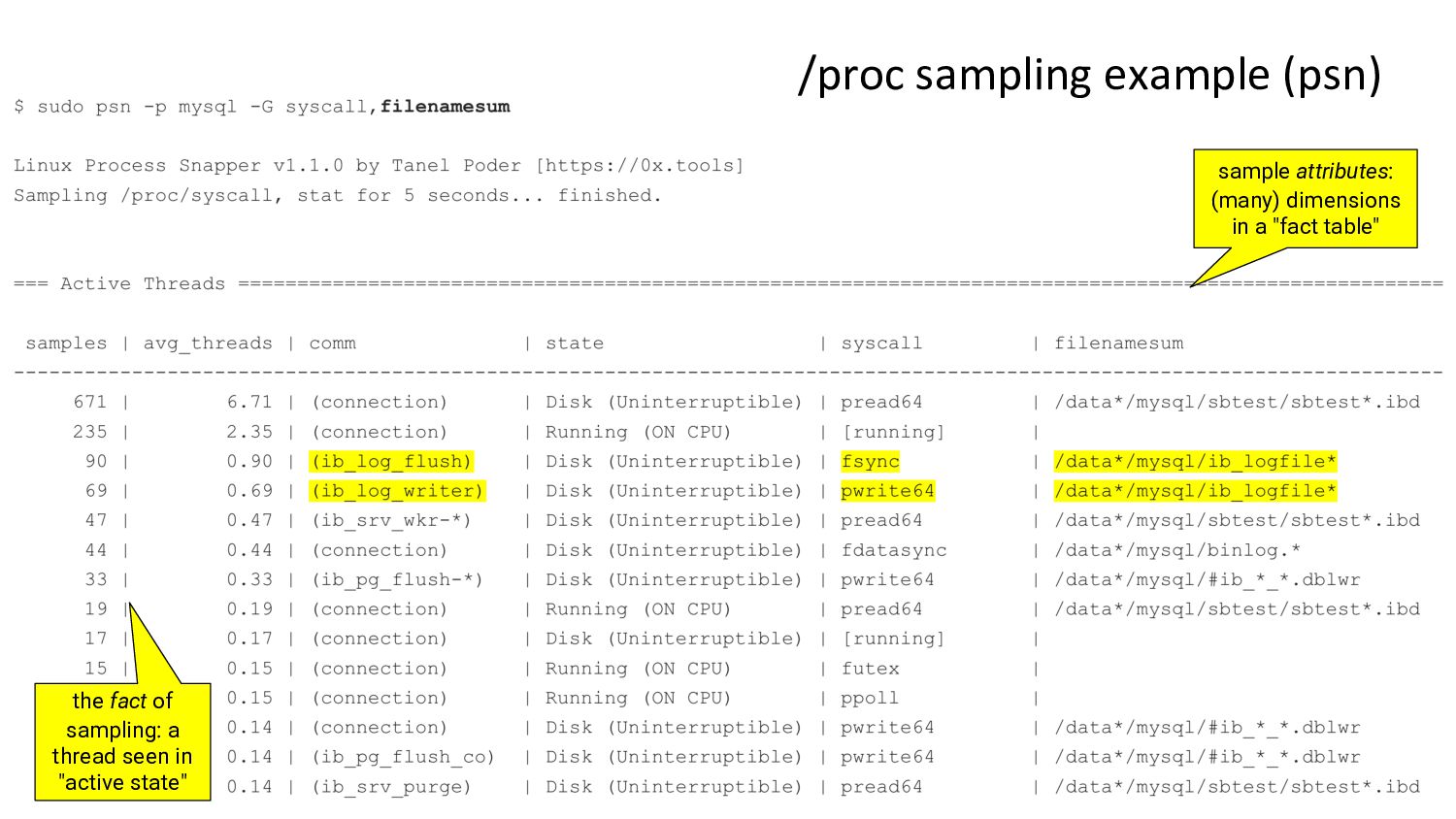{kind=link}
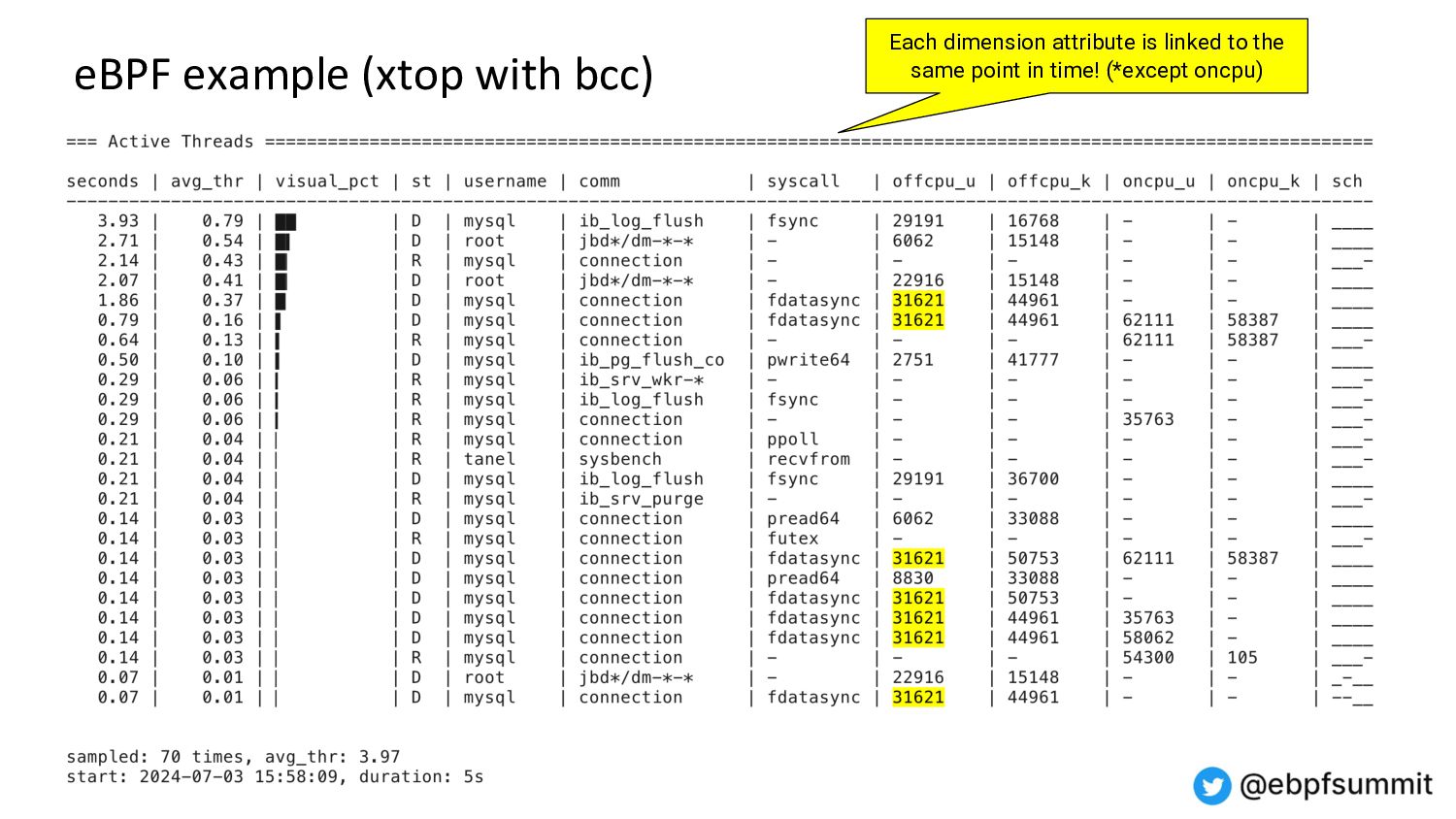{kind=link}
{kind=link}
{kind=link}
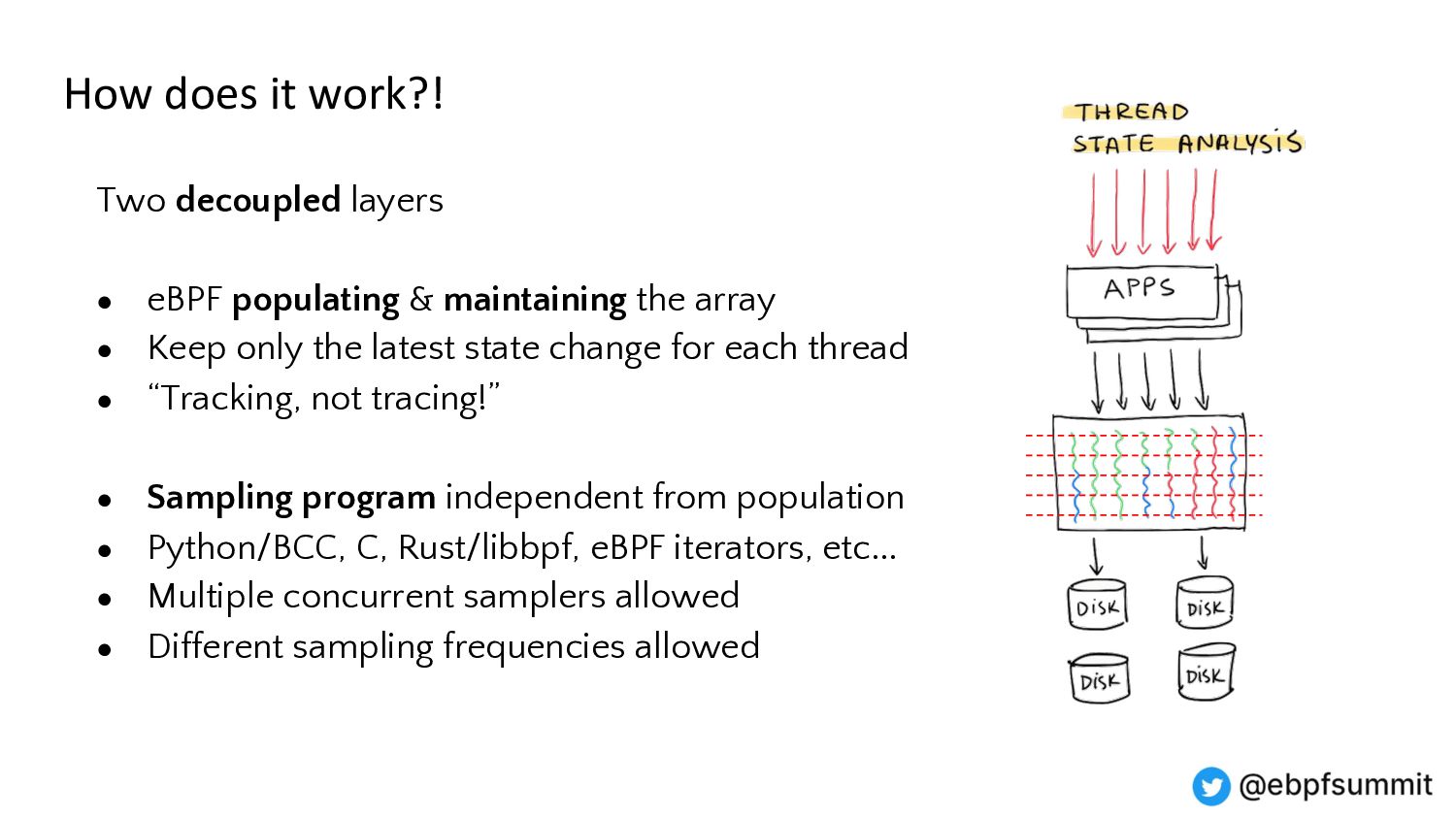{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}