a variety of sources - Use data effectively i.e. querying and analytics - Events can be more complex than simple measurements - Event based architecture - a natural fit
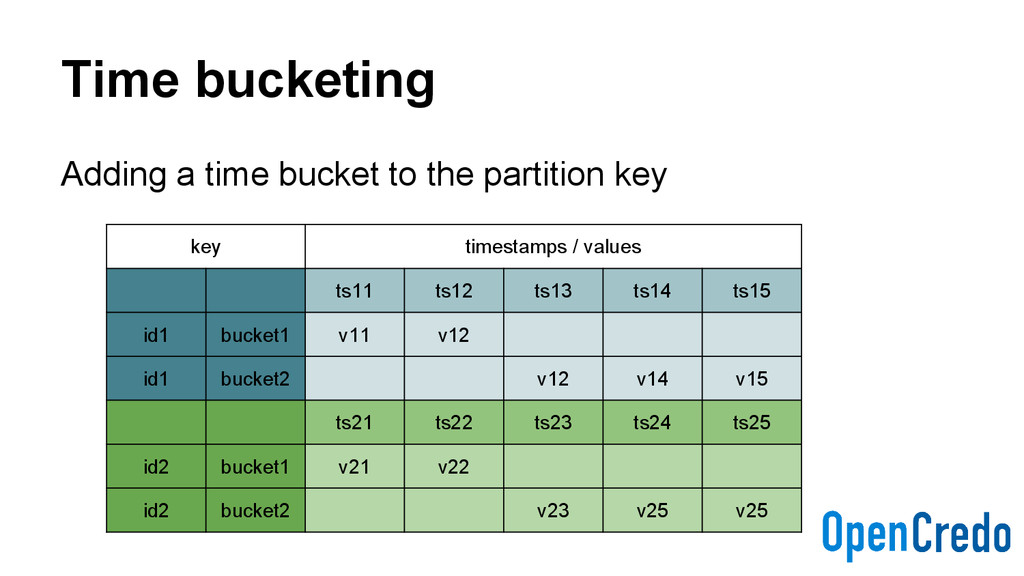
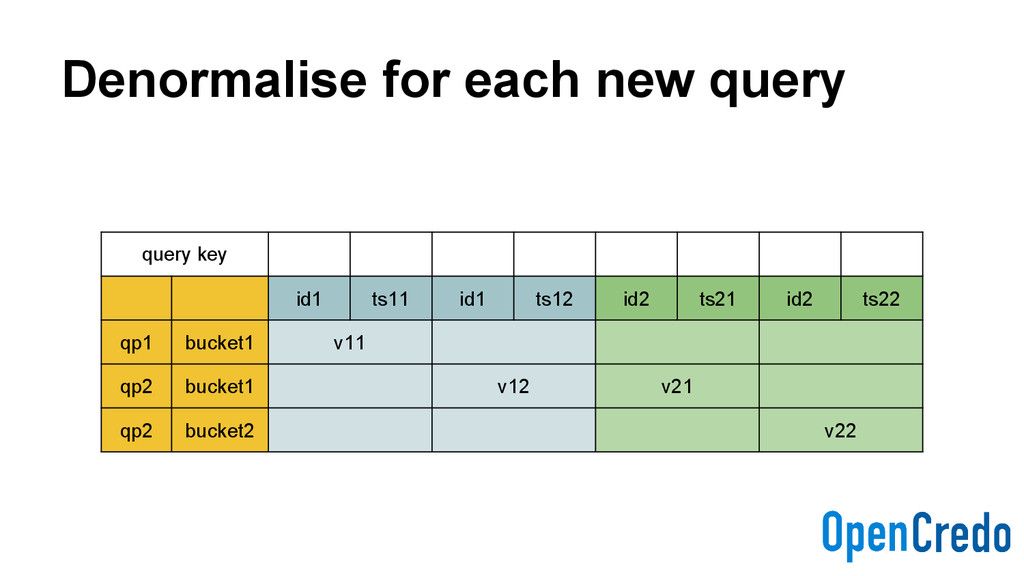
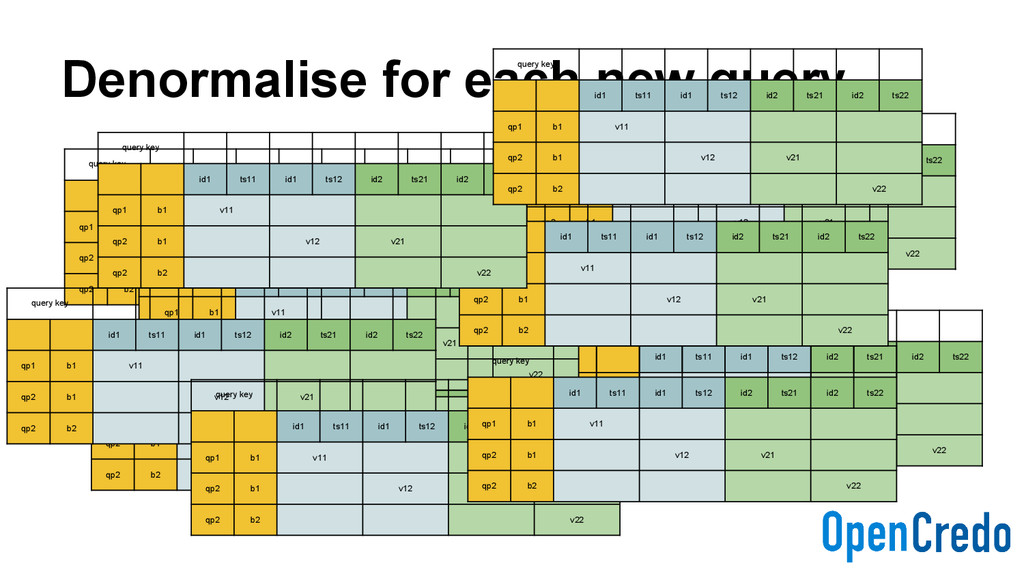
Higher disk usage - Disk space is cheap, but not free - Write latency may be impacted - Writing to the denormalised indexes - Time-bucket indexes may create hotspots - “Hot shards”
- Support analytics - Changes in the data model - Allow for extension in the architecture - Guarantees vs. performance - Consistency vs. latency - Should be tunable
/ ReST interface - Create events: POST - Query events: GET with parameters - Clear service contract, easy to use - Accessible anywhere you have http! - Decouples interface from implementation
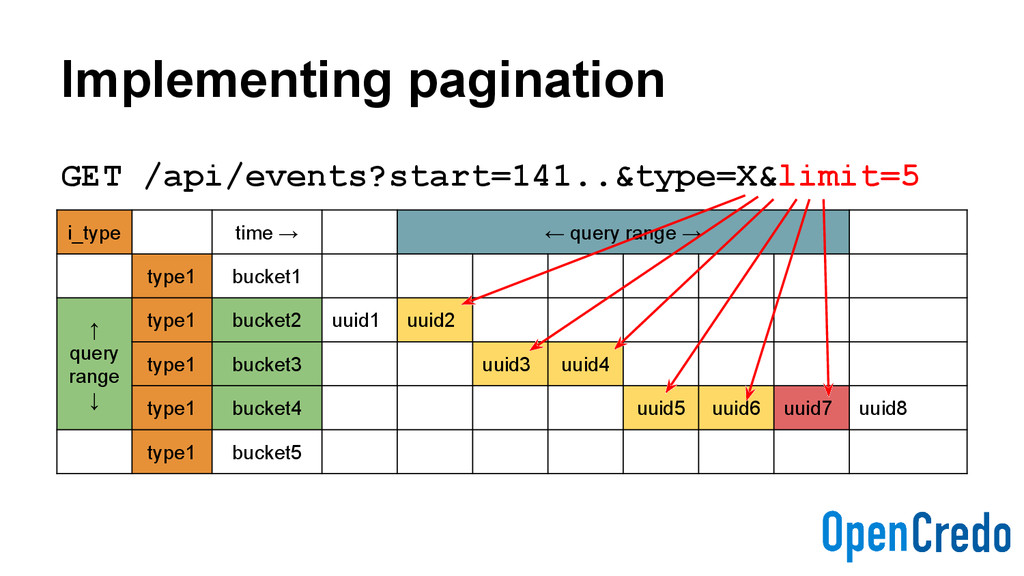
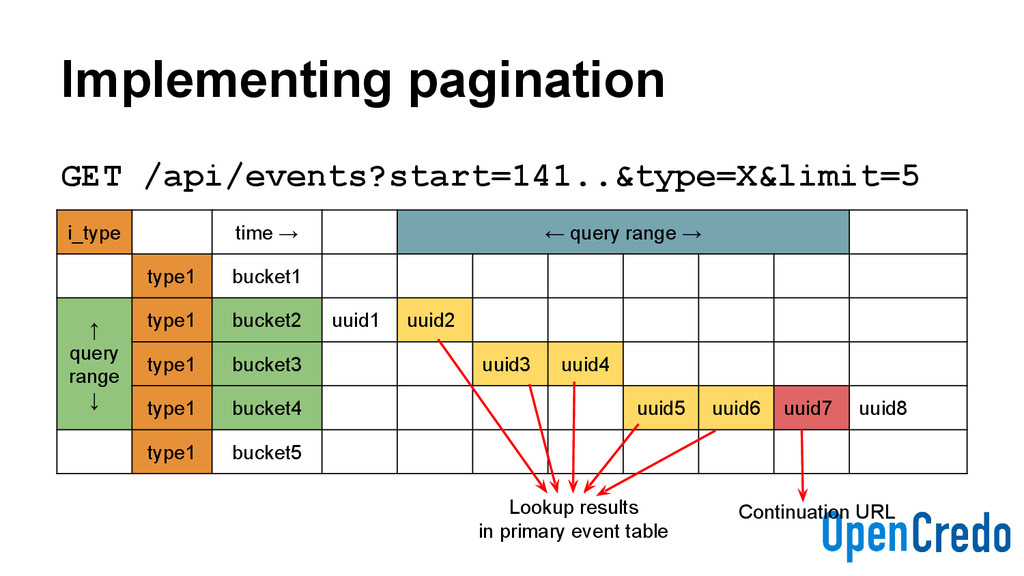
start time (range) - startOffset X milliseconds ago (range) - end absolute end time (range) - limit number of items returned - order ASC or DESC - tag indexed values - type indexed values
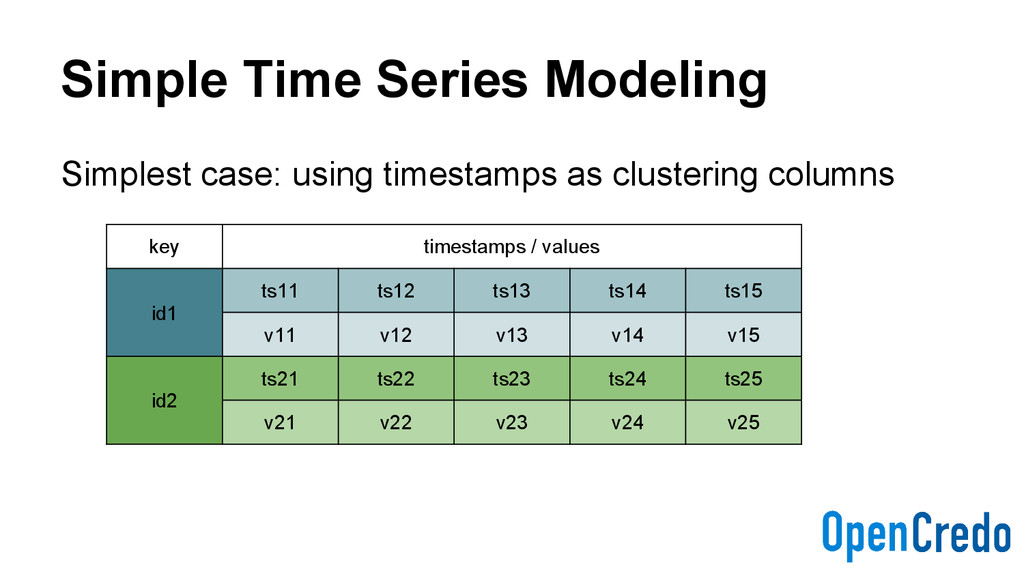
eventid timeuuid, primary key ((type, tbucket), eventid) ) with clustering order by (eventid asc); - No actual values, timeuuid of event is enough - There are multiple index tables; one for each query type - Ascending/descending versions
could use MySQL or MongoDB (or txt files) - Client only needs to be able to - Understand JSON data structures - Follow URIs - GET parameters work in an intuitive way - Disk consumption is reasonable - Extensible - More than just a data store - Driving a pub/sub mechanism on top of events
need that - Still quick enough for our use-cases - More complex service code - Needs to execute multiple CQL queries in sequence - Using CQL batches when possible - Cluster hotspots can still occur
specified start time - Until now (*) - Of type X - In ascending order (*) - Each “page” to return 5 items - With a continuation URL to iterate GET /api/events?start=141..&type=X&limit=5
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}