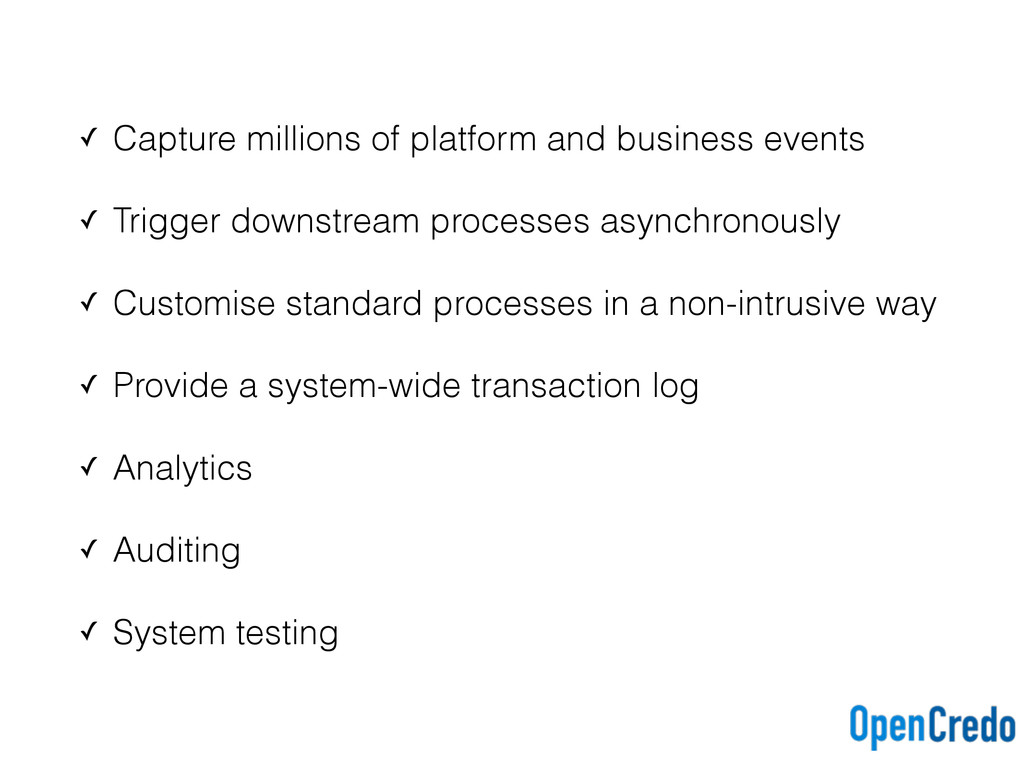
downstream processes asynchronously ✓ Customise standard processes in a non-intrusive way ✓ Provide a system-wide transaction log ✓ Analytics ✓ Auditing ✓ System testing
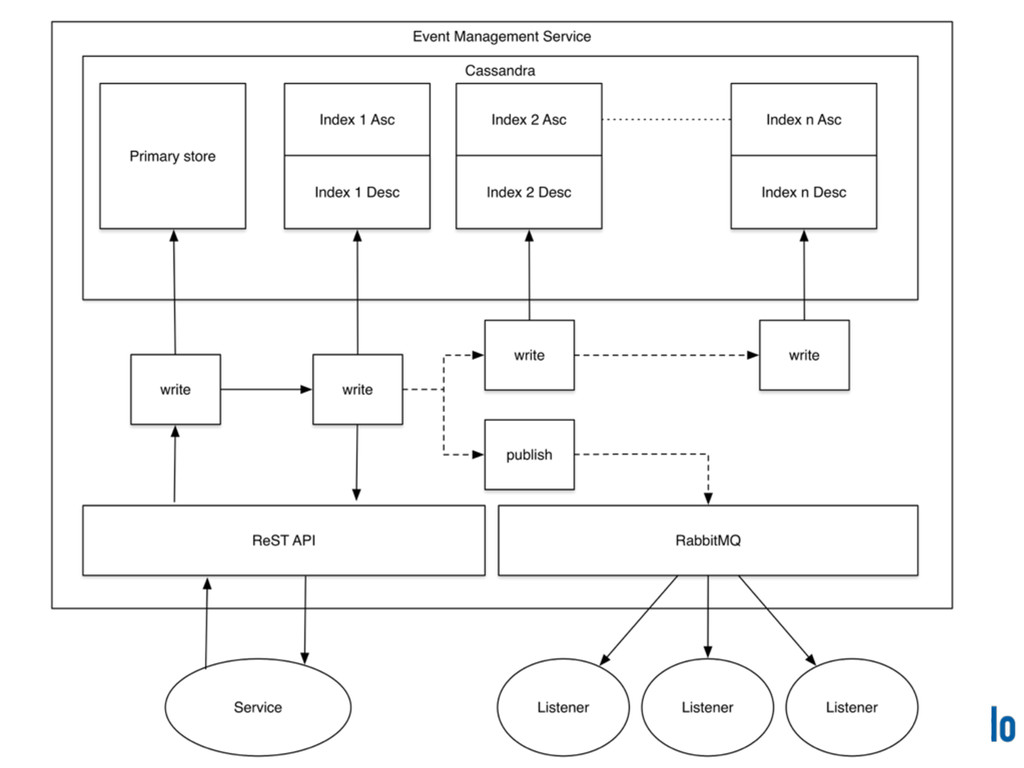
asynchronously • Basic client guarantee: if a POST is successful the event has been persisted “sufficiently” • Events can be published to a message broker
sufficiently performant for our use-cases • More complex service code • Needs to execute multiple CQL queries in sequence • Cluster hotspots can still occur, in theory
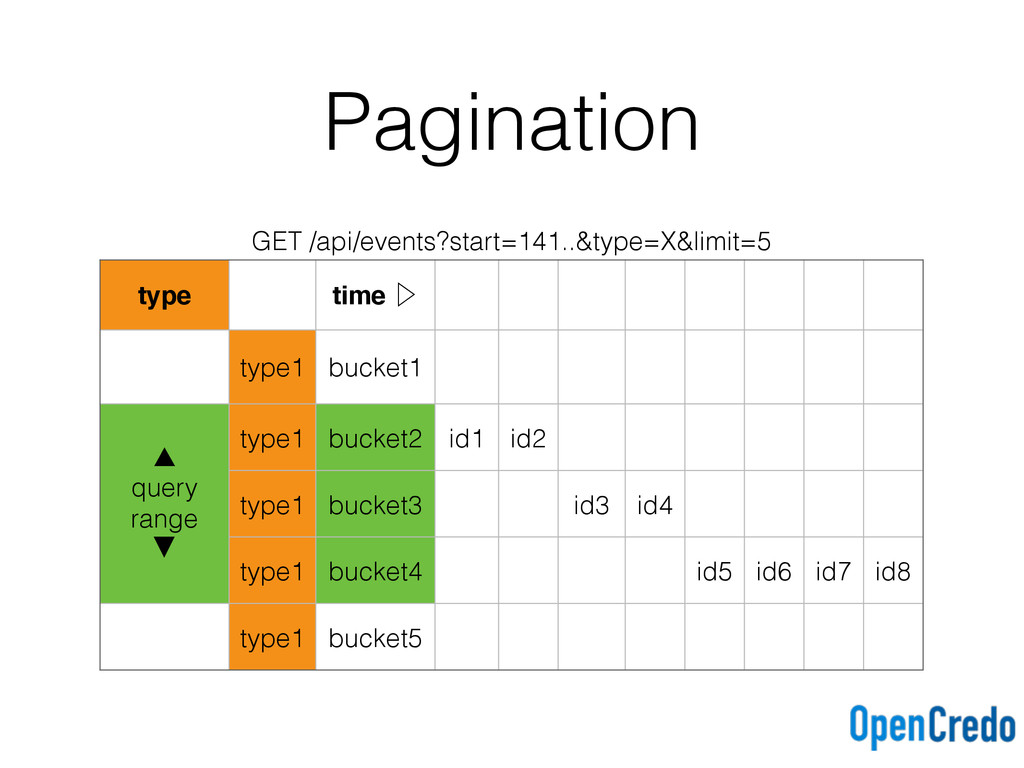
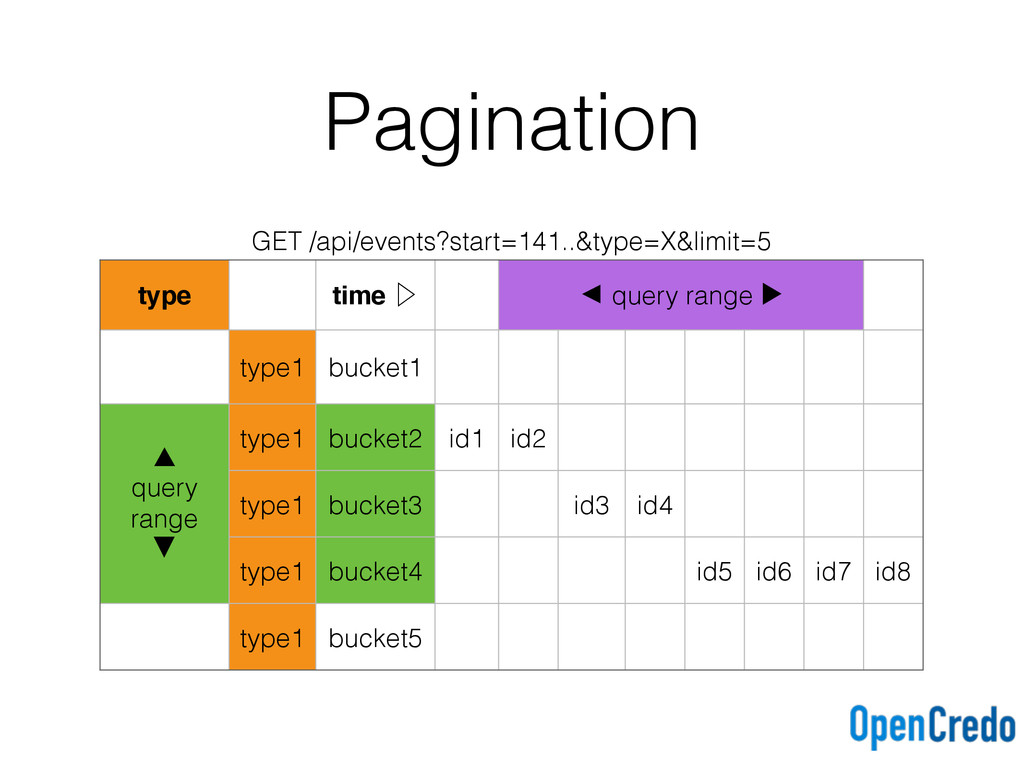
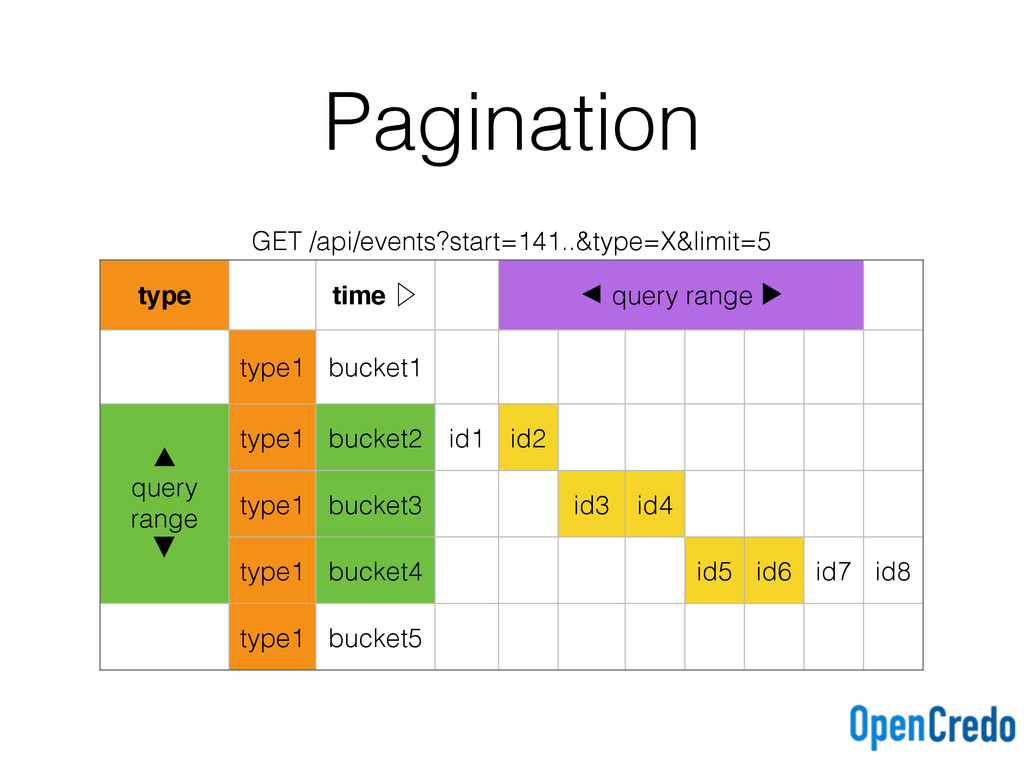
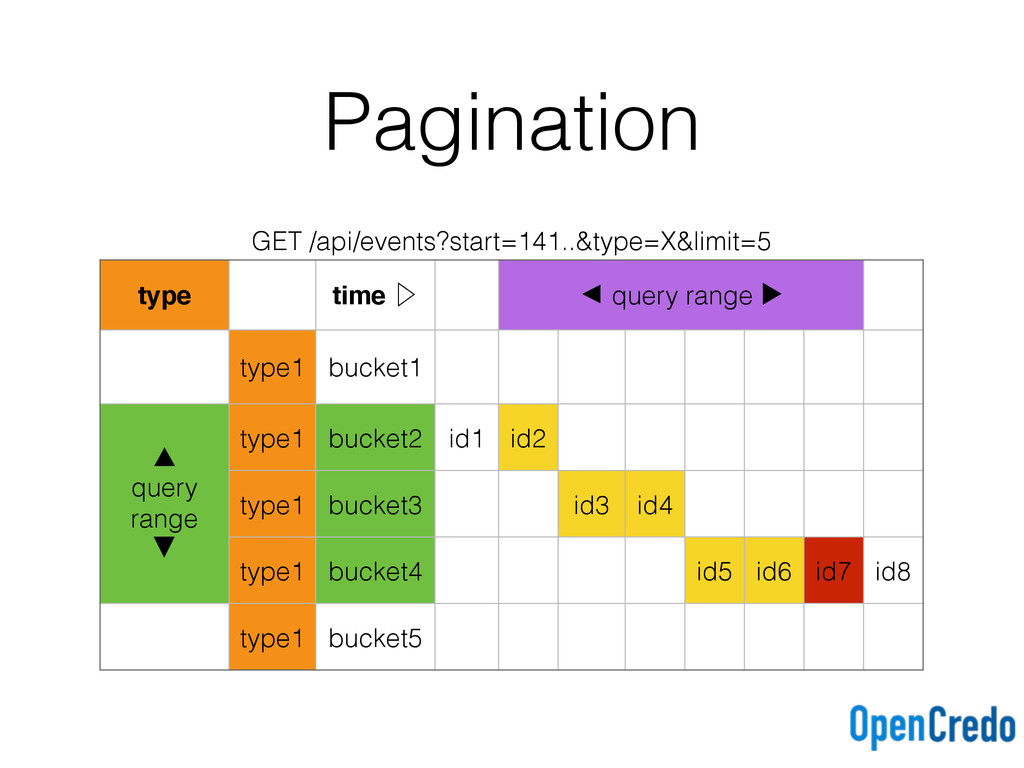
key ((type, tbucket), eventid)) with clustering order by (eventid asc); events_by_type_desc ( tbucket text, type text, eventid timeuuid, primary key ((type, tbucket), eventid)) with clustering order by (eventid desc); Ascending and descending time buckets for each query type
• Client latency increases moderately with increased parallel load (40ms to 60ms, +10ms on the client) • Current behaviour exceeds by far current target volumes
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
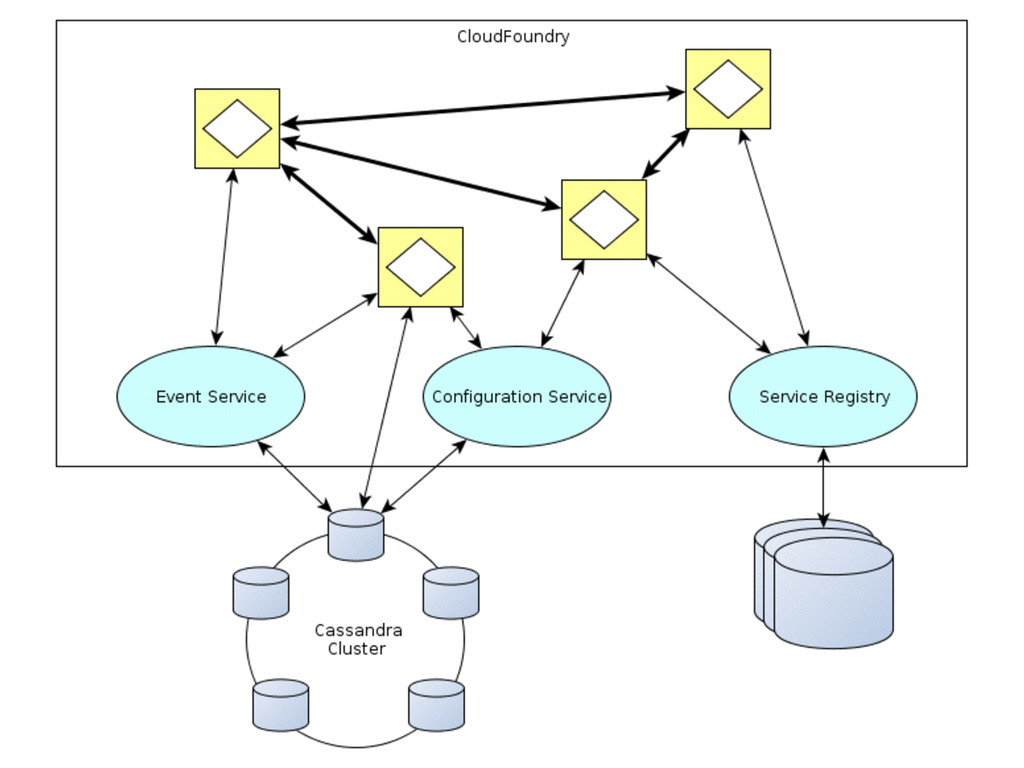{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
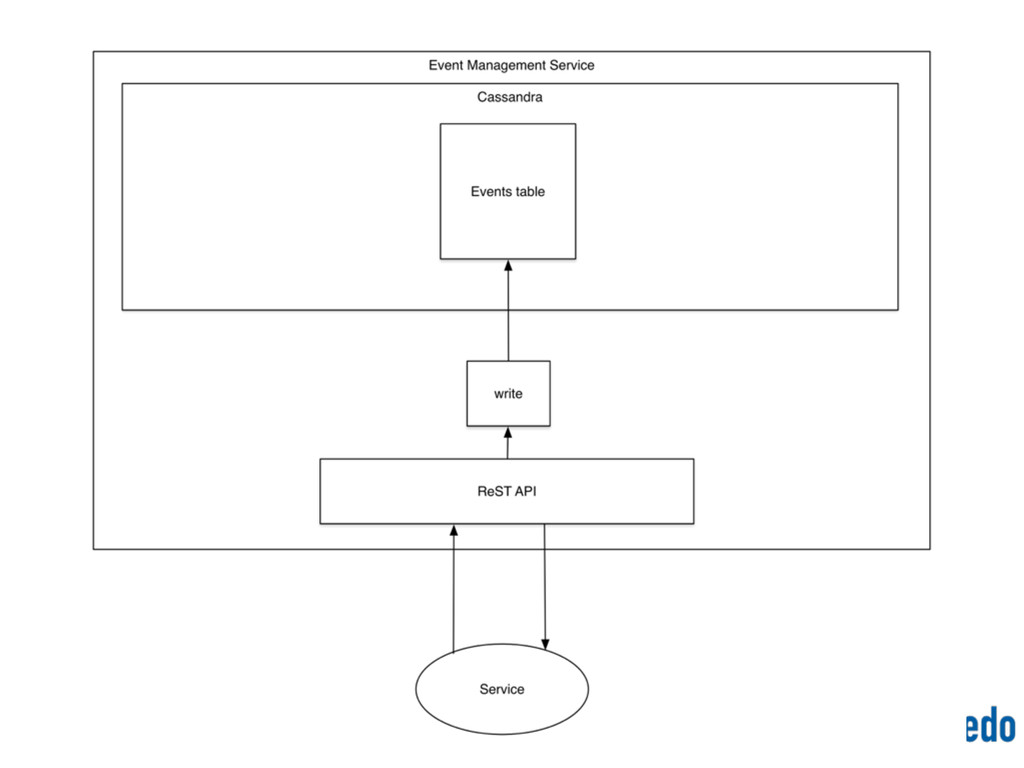{kind=link}
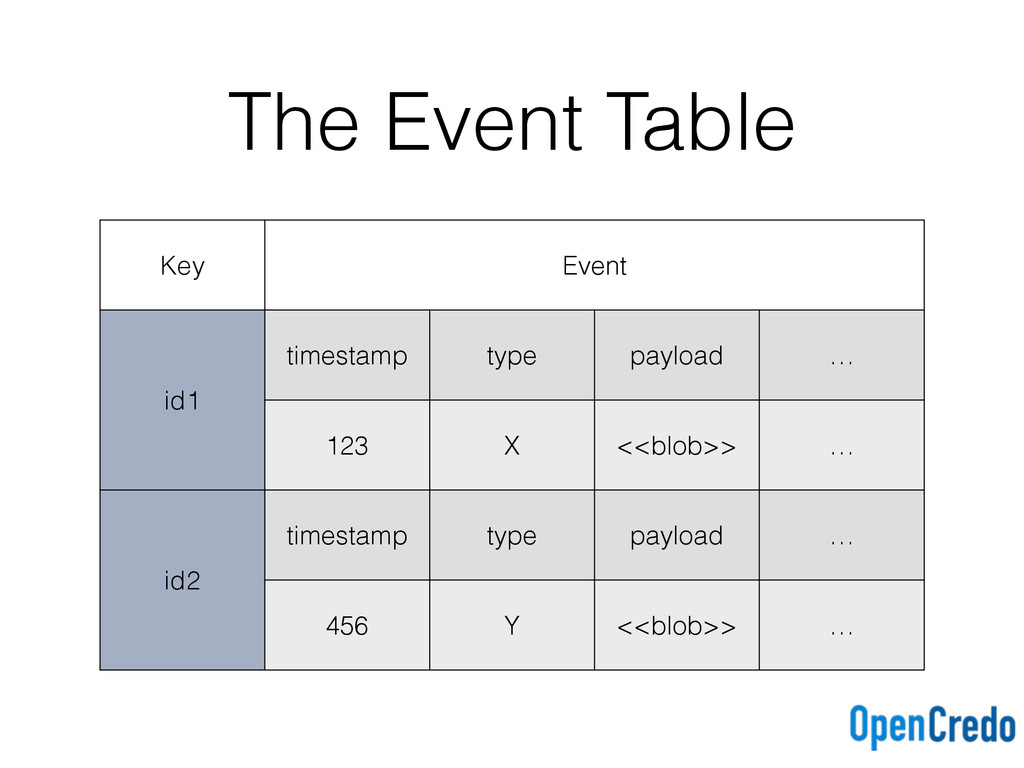{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}