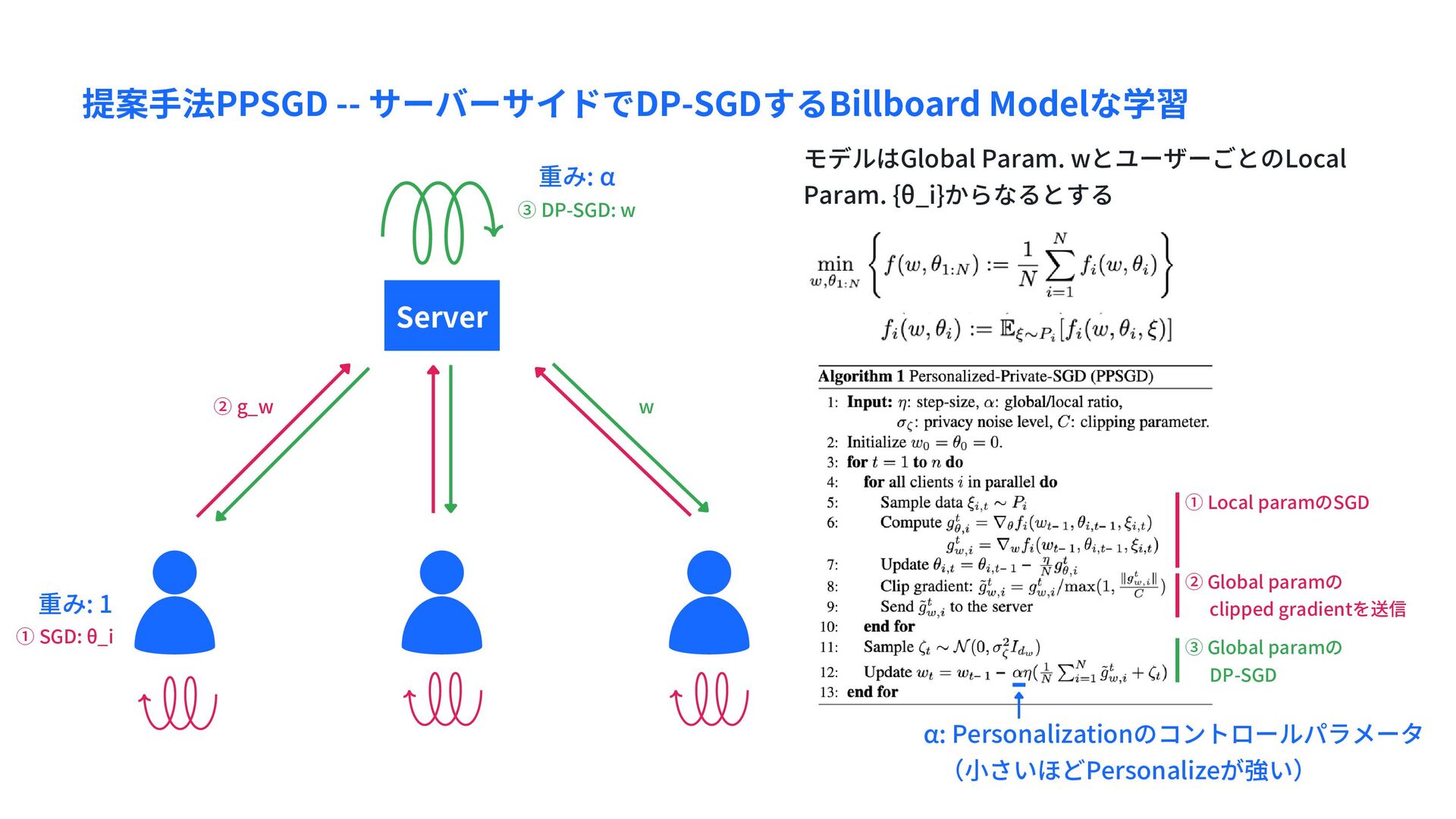
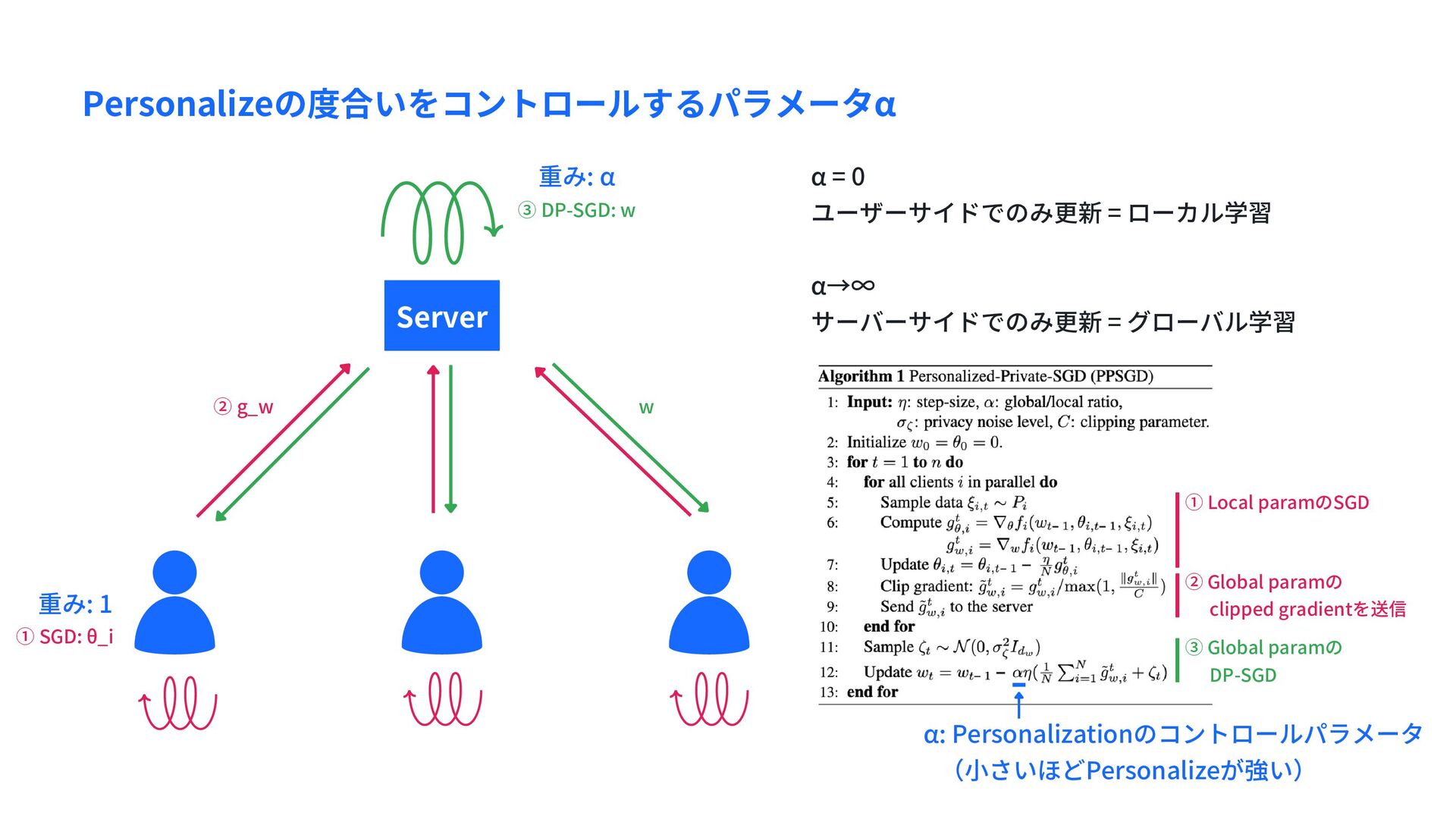
θ_i ② g_w w ① Local paramのSGD ② Global paramの clipped gradientを送信 ③ Global paramの DP-SGD モデルはGlobal Param. wとユーザーごとのLocal Param. {θ_i}からなるとする α: Personalizationのコントロールパラメータ (小さいほどPersonalizeが強い) 重み: 1 重み: α
w α = 0 ユーザーサイドでのみ更新 = ローカル学習 α→∞ サーバーサイドでのみ更新 = グローバル学習 重み: 1 重み: α ① Local paramのSGD ② Global paramの clipped gradientを送信 ③ Global paramの DP-SGD α: Personalizationのコントロールパラメータ (小さいほどPersonalizeが強い)
DP-SGDは(4)のときに (ε, δ)-DPになることが 知られている ① Local paramのSGD ② Global paramの clipped gradientを送信 ③ Global paramの DP-SGD M. Abadi+, "Deep Learning with Differential Privacy", 2016
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}