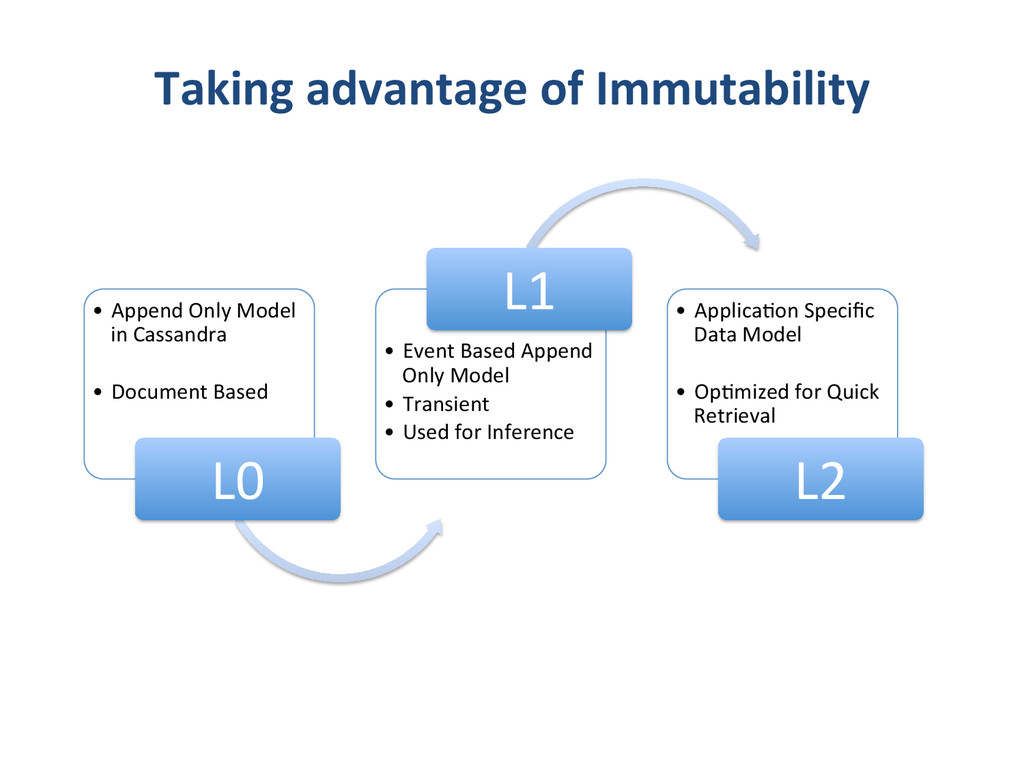
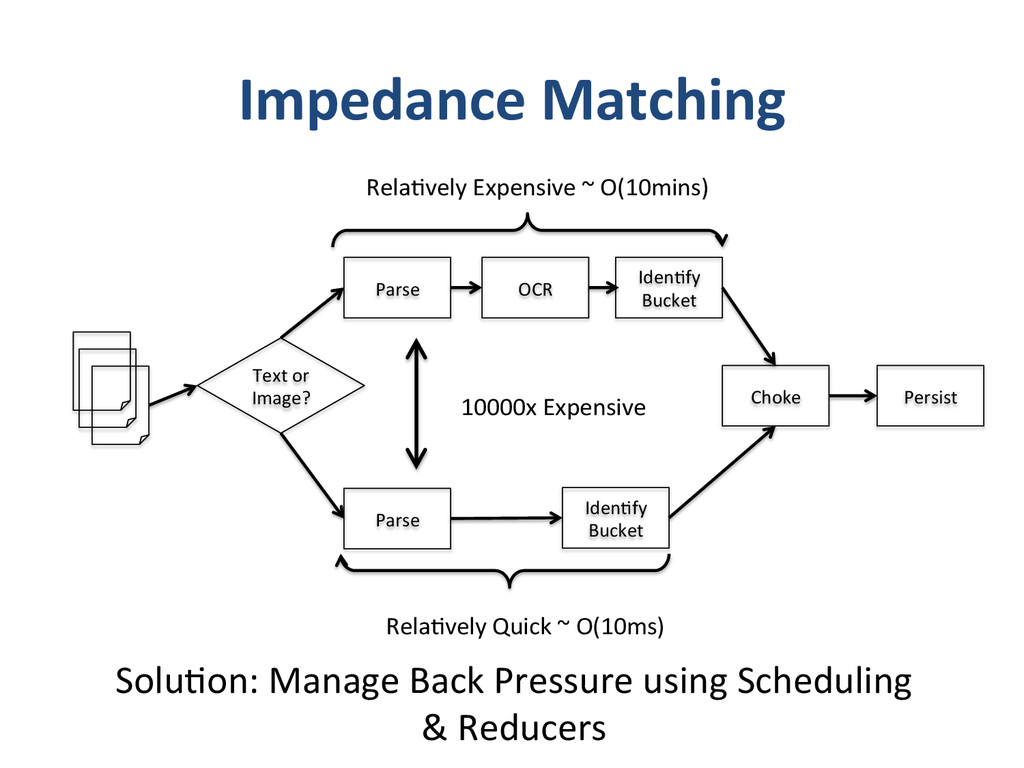
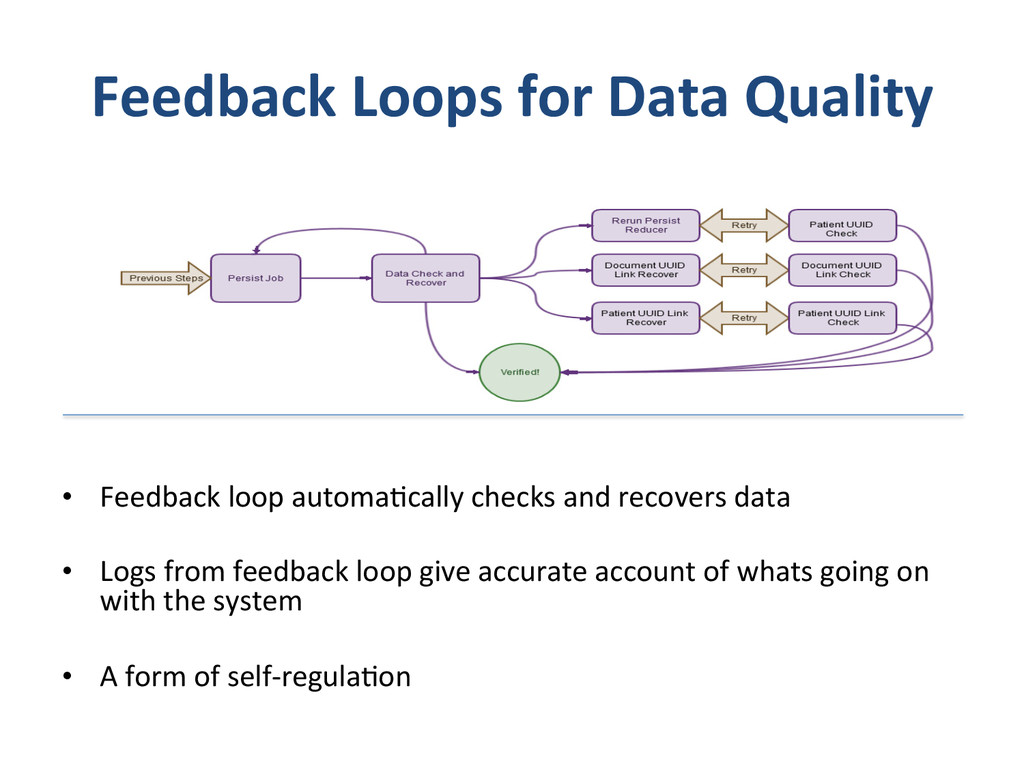
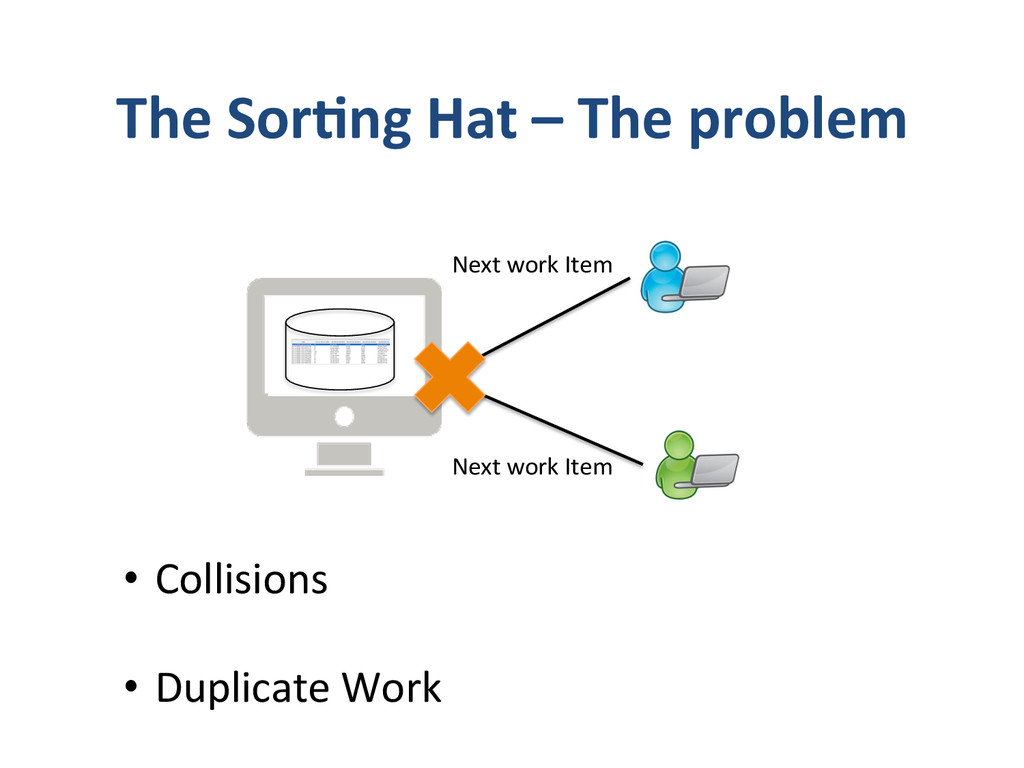
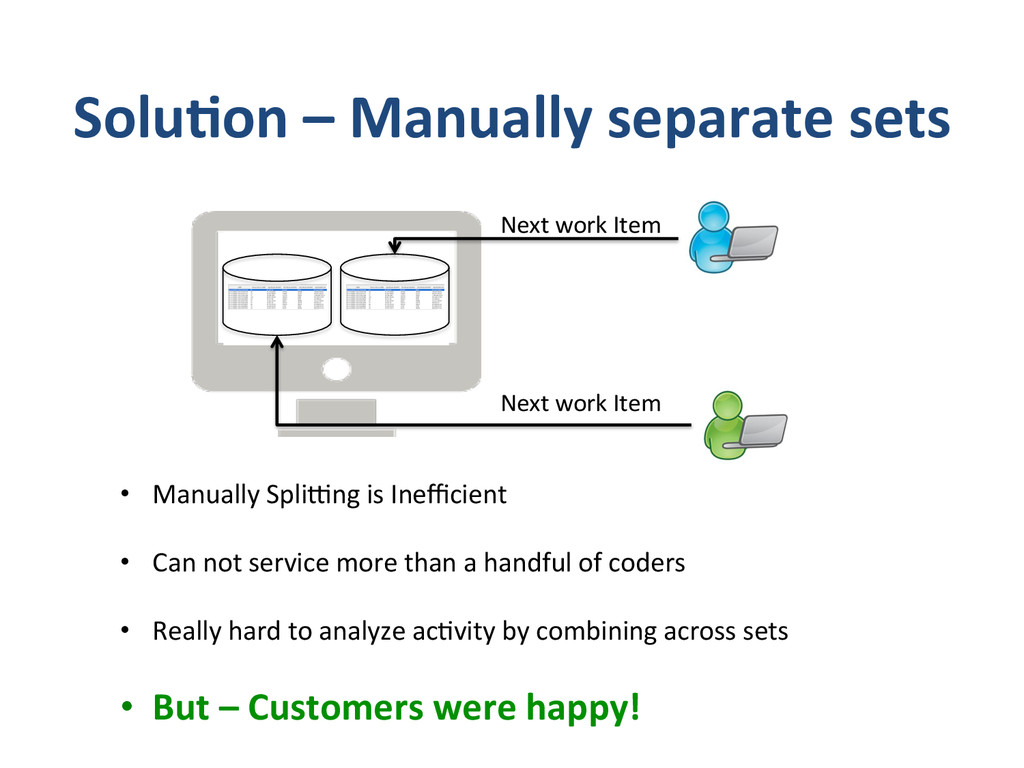
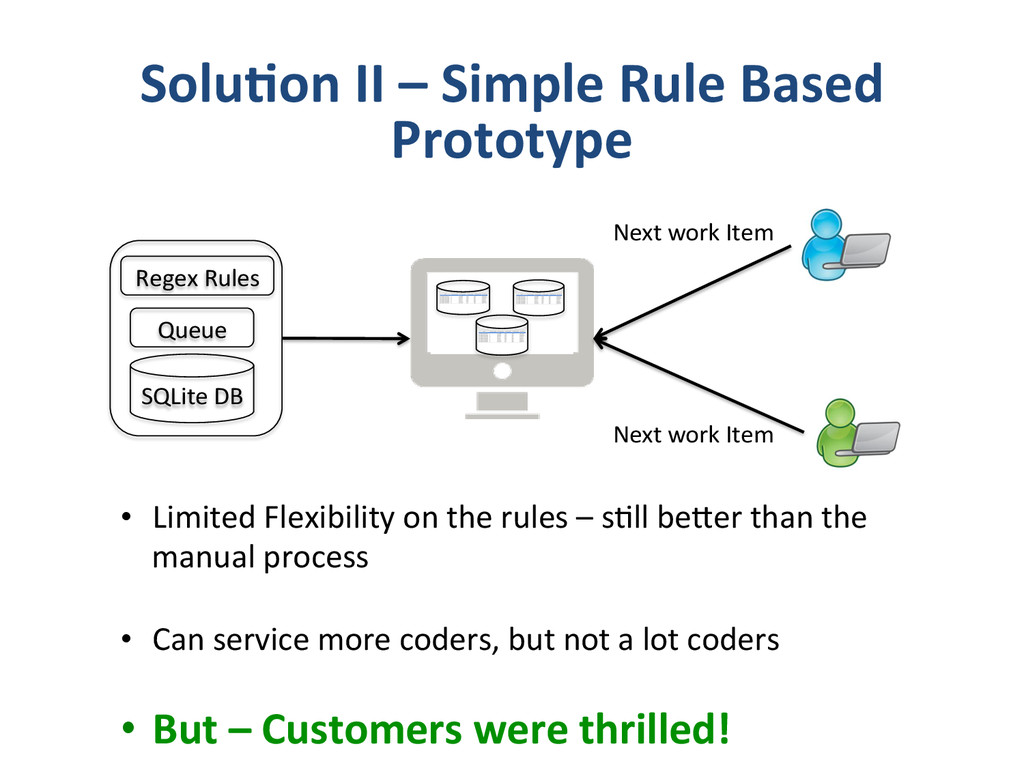
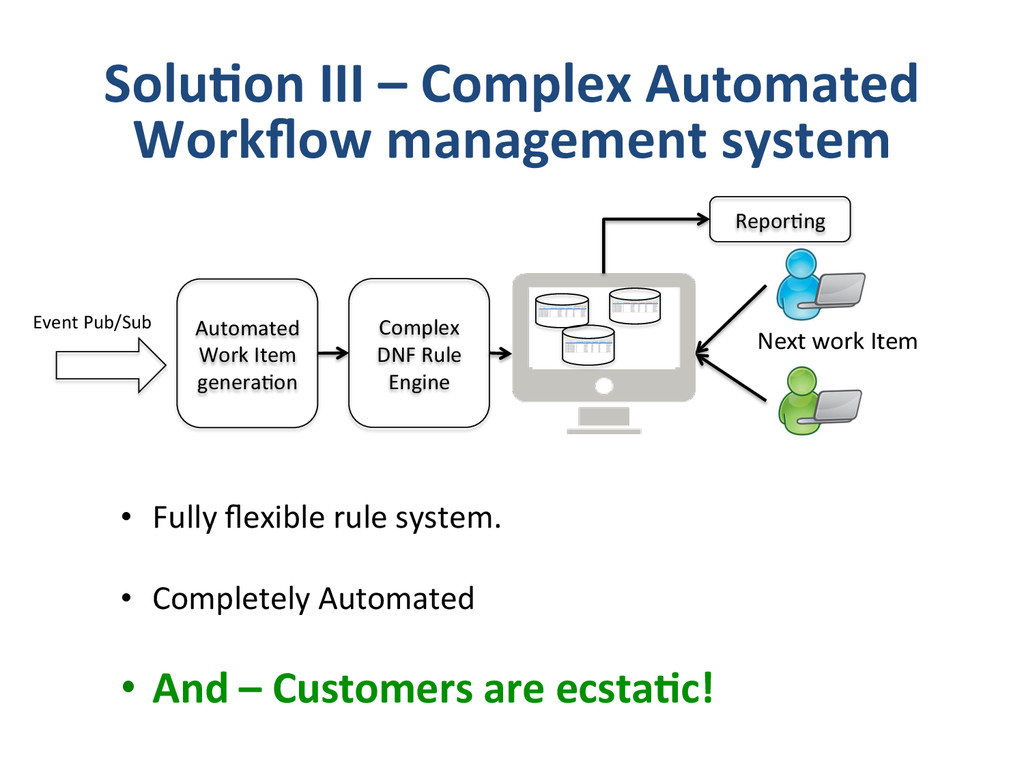
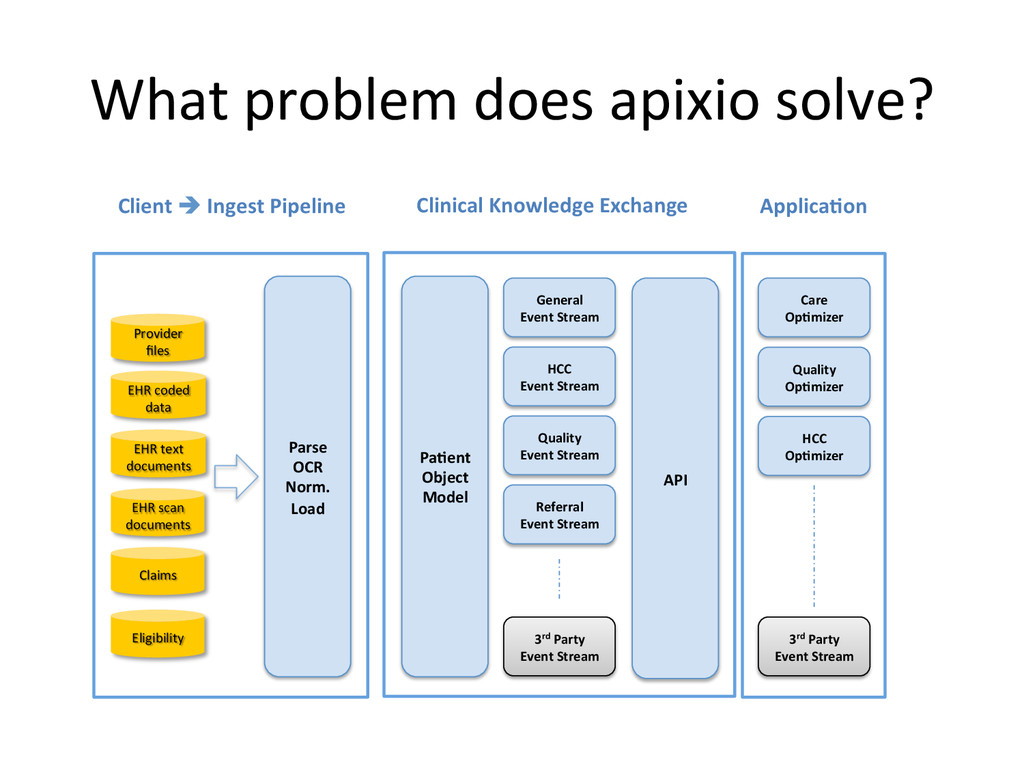
– What we do and why we do? • Apixio’s foray into big-‐data – Our first system – Our second system • De-‐normalized pa8ent model • One monster job doing everything • Update model • Impedence mismatches – Our third system • separate I/O and Computa8on Jobs • Move to an append only model • “some-‐what” denormalized data (lots of small denormalized chunks) • Logging – log everything in json • Co-‐ordinator – A custom job management system. • Lessons Learnt – Log Everything (and if you can log as JSON, even beser) – Logging is Data – Impedence mismatches can kill performance of distributed systems – make sure you don’t overdrive any single component. – Cassandra likes an append only model – if you are building systems using cassandra, try to build them around append only models. – Lambda architecture -‐ we had arrived here – if we had started – If you trust that you are going in the right direc8on and quickly iterate, and you will get to there, successfully – winning all the way. same place – and no-‐one else got there by planning to get there.
{kind=link}
{kind=link}
{kind=link}
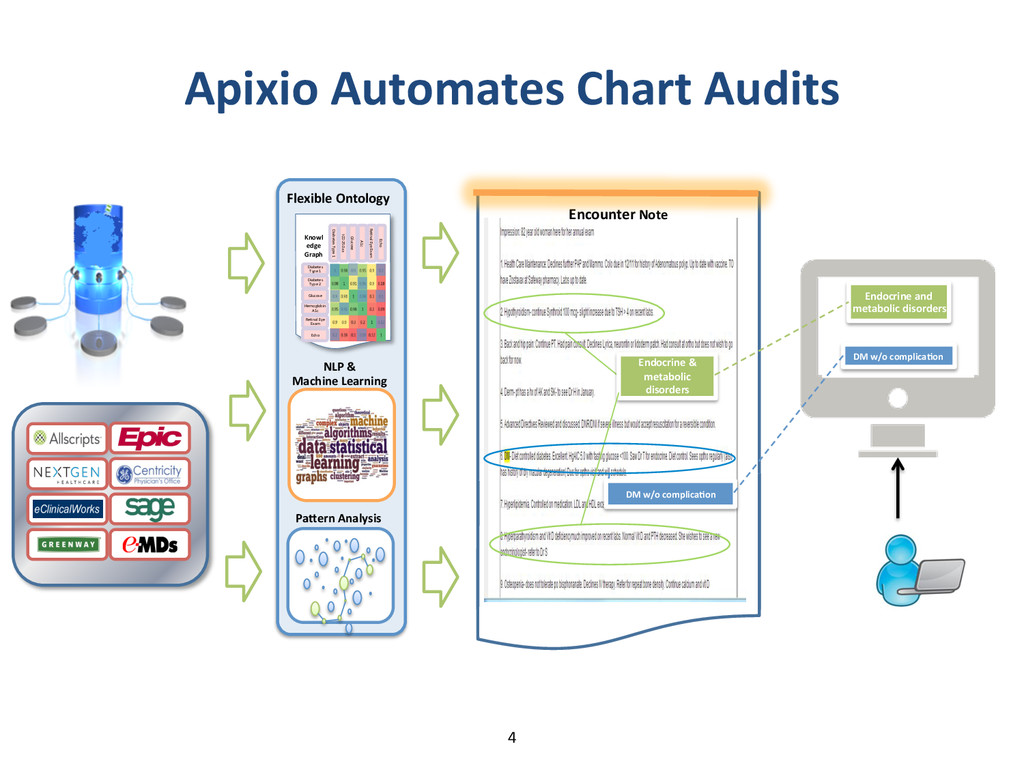{kind=link}
{kind=link}
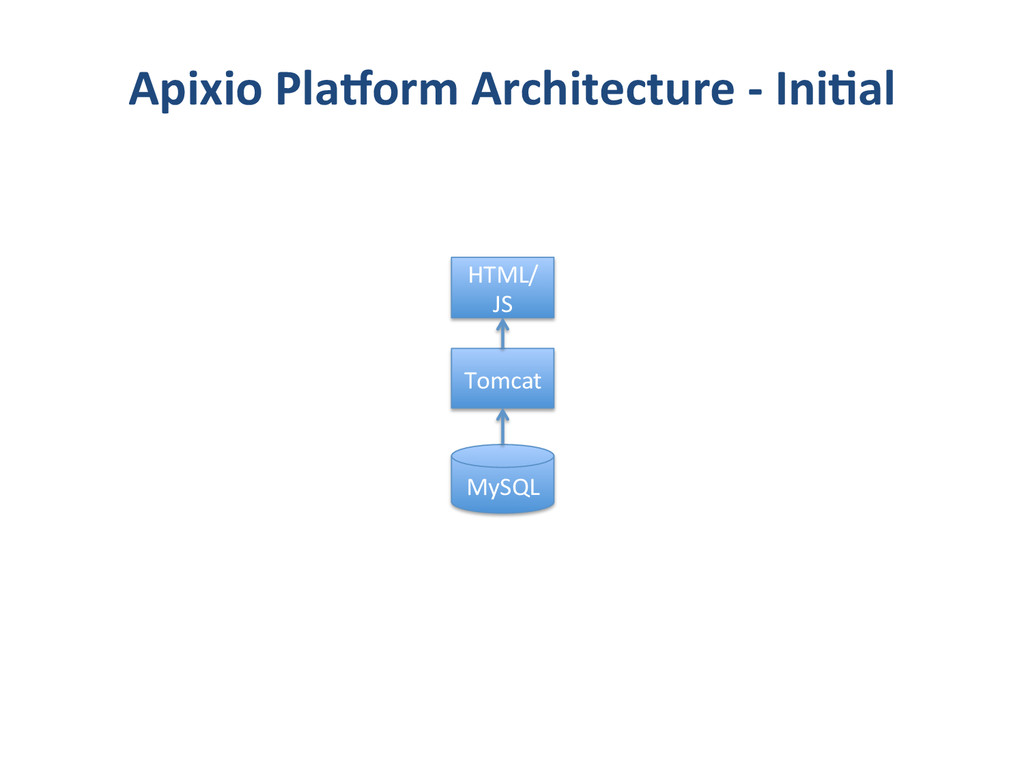{kind=link}
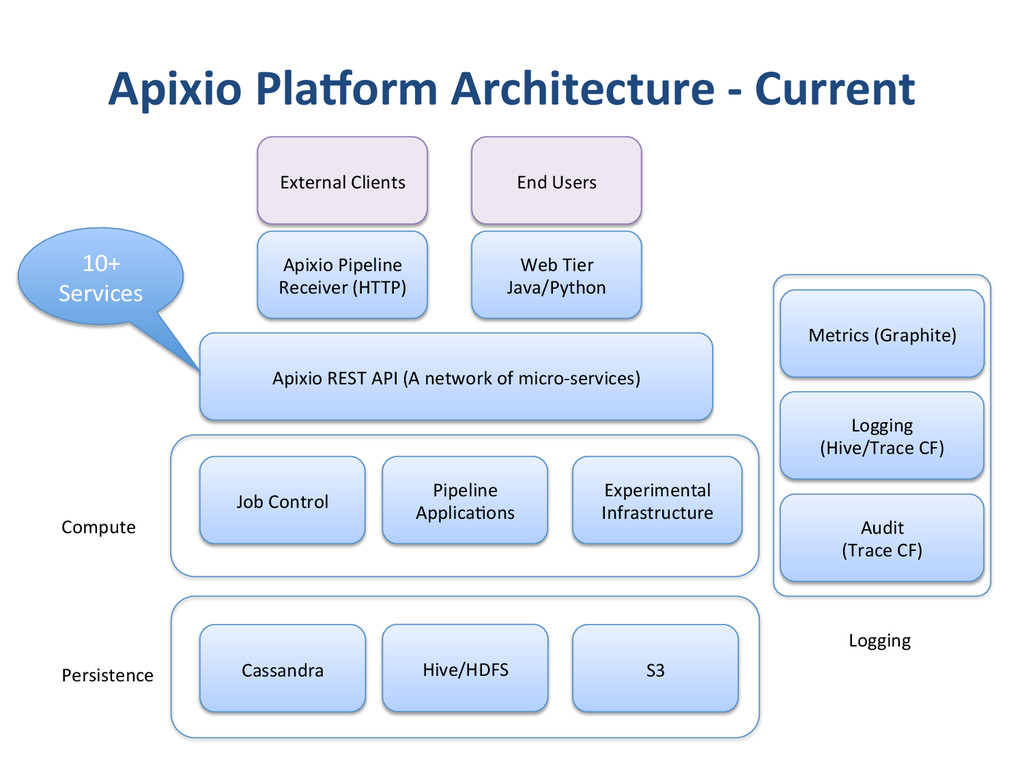{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
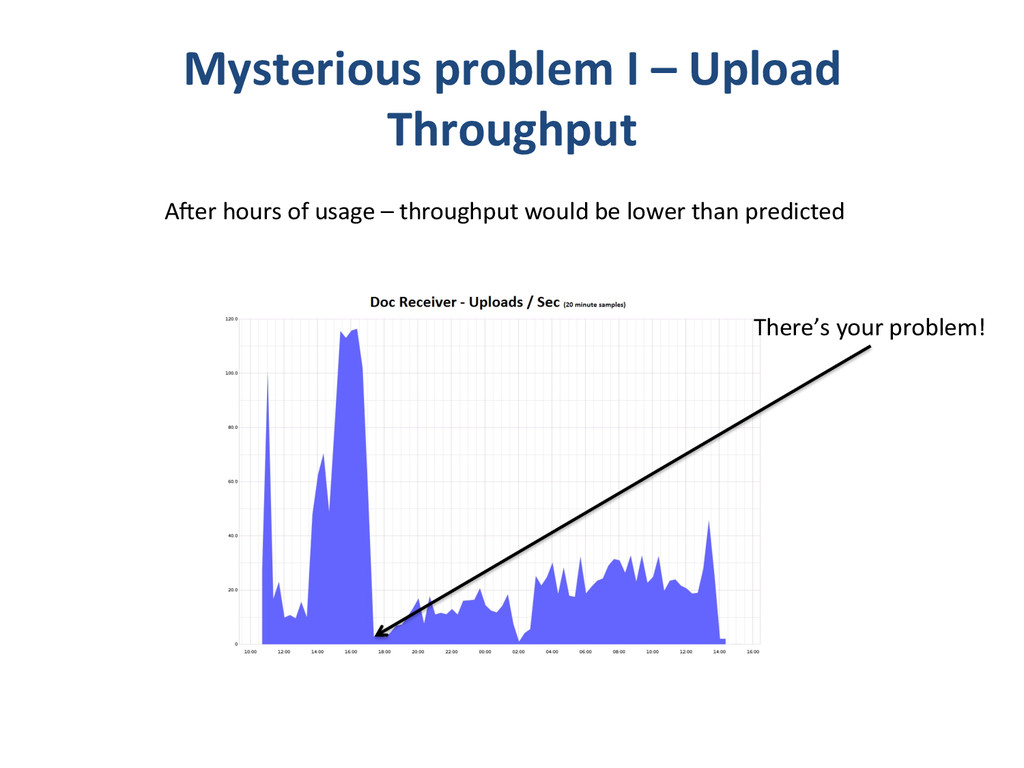{kind=link}
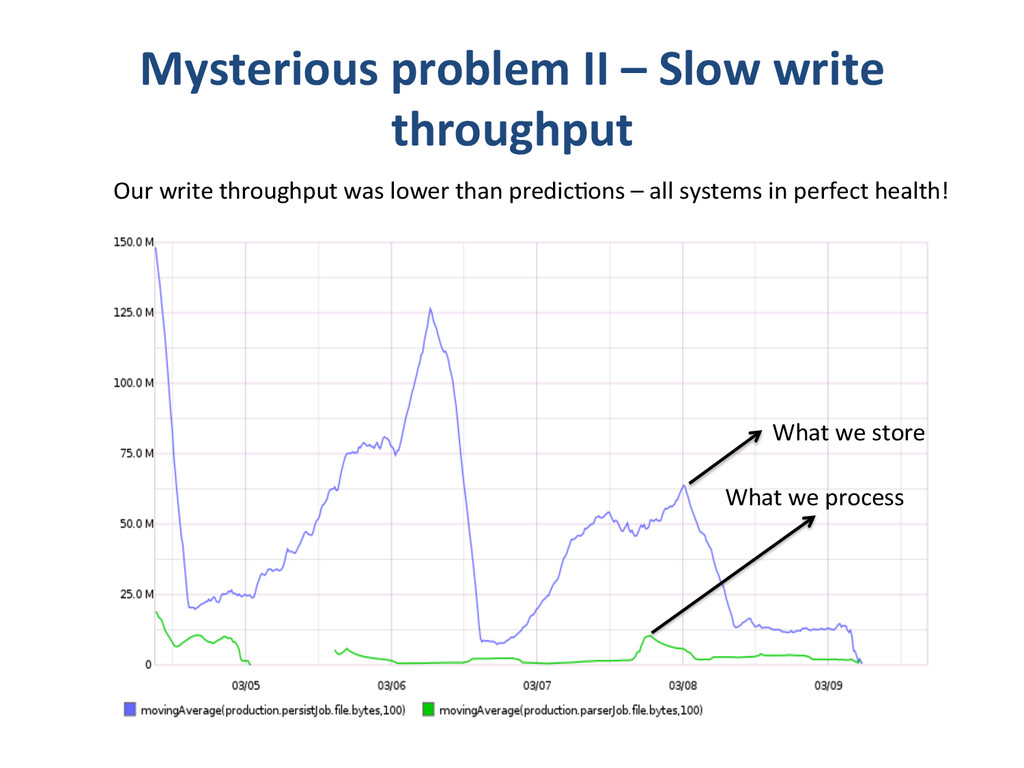{kind=link}
{kind=link}
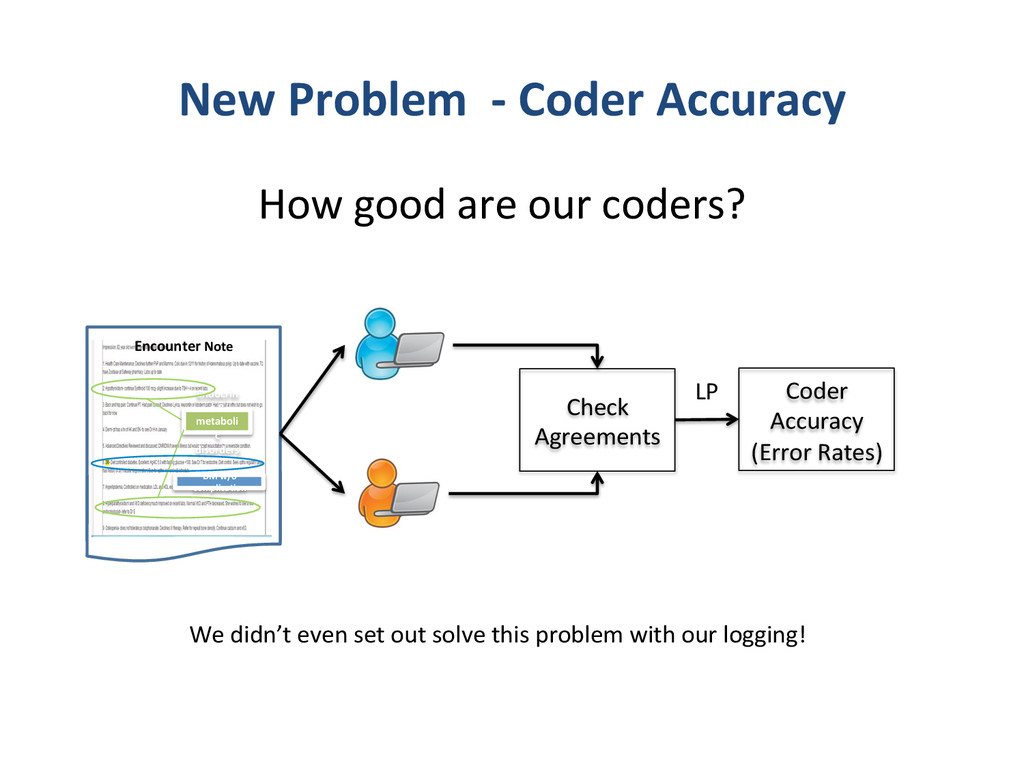{kind=link}
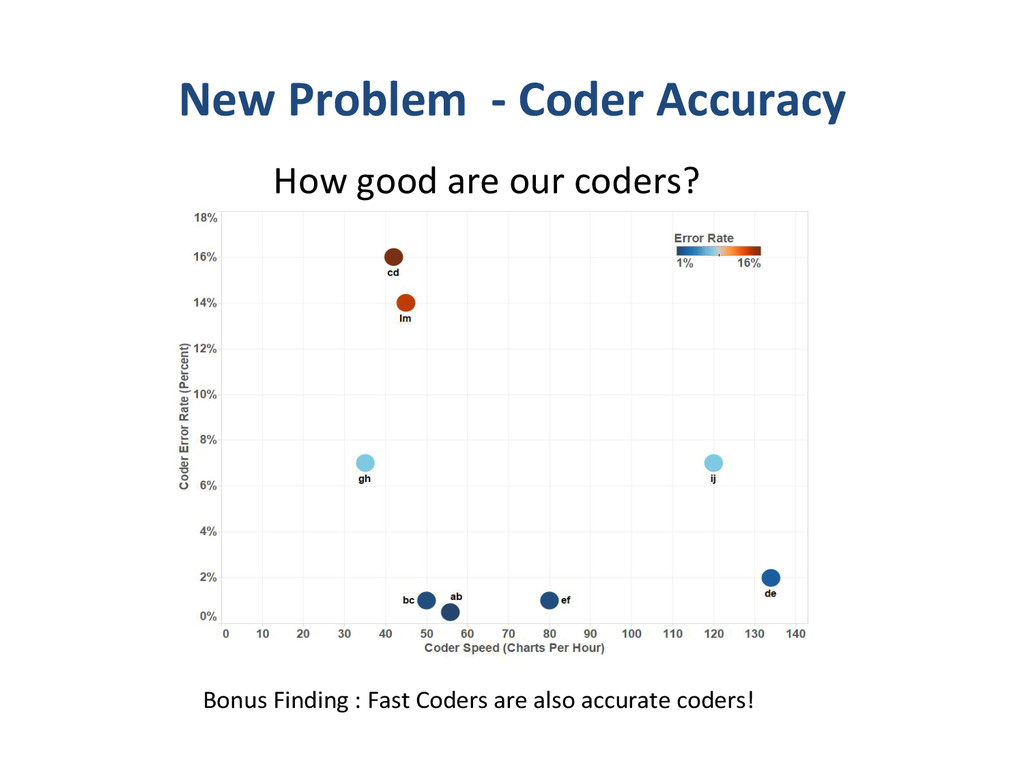{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
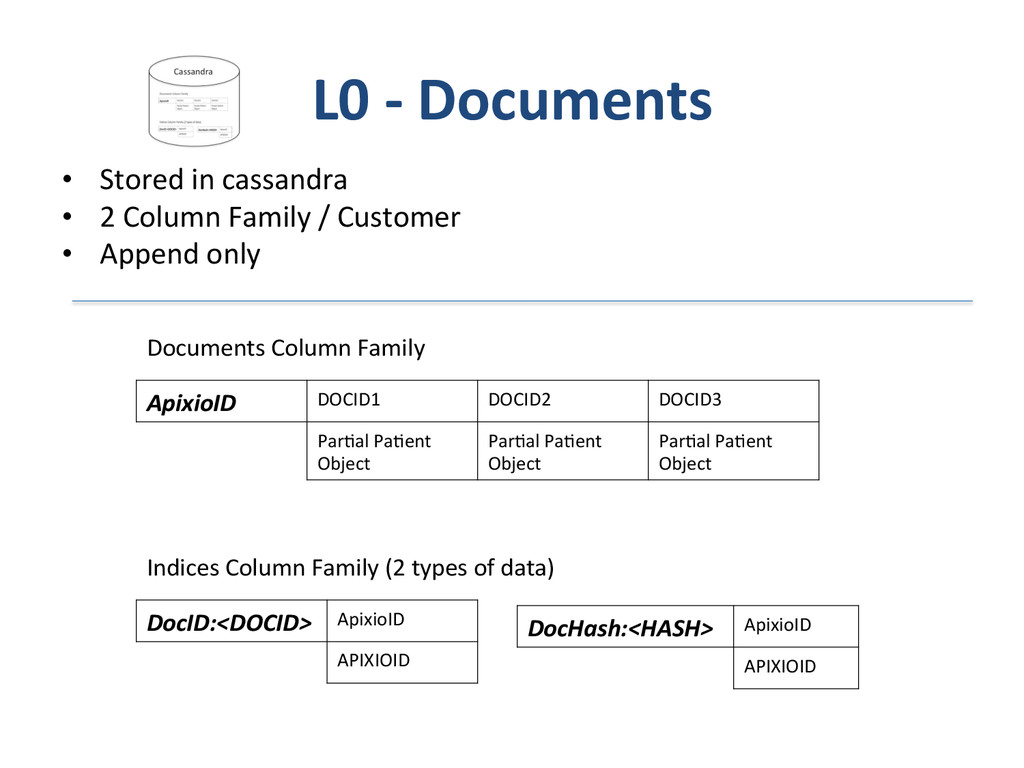{kind=link}
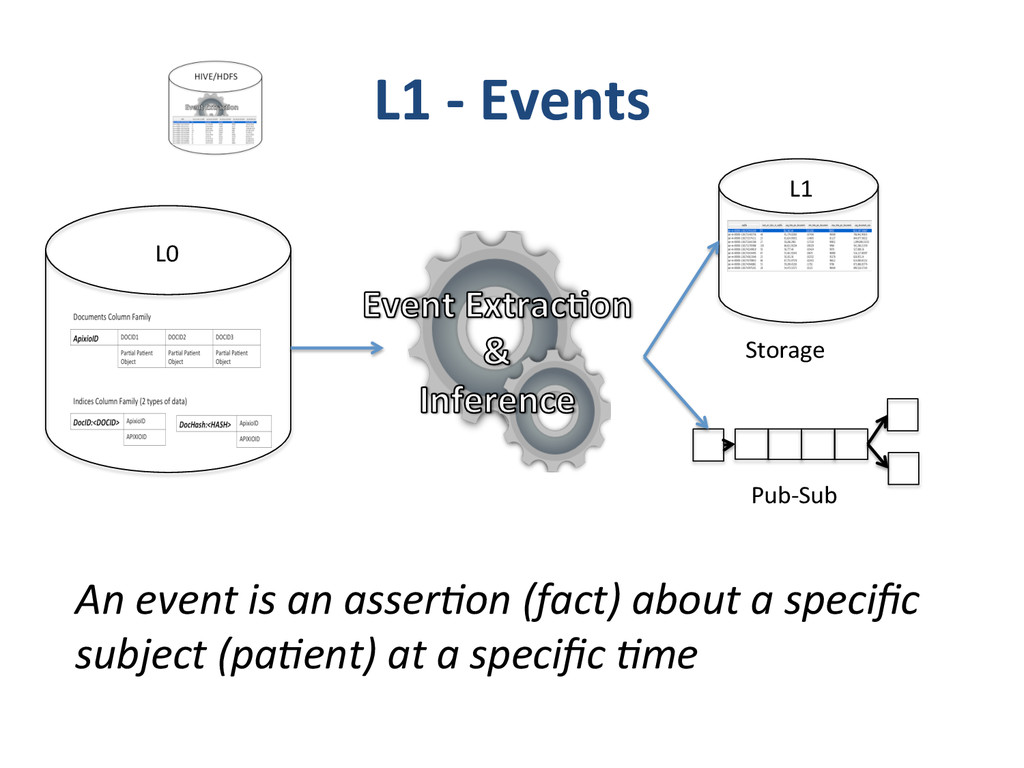{kind=link}
{kind=link}
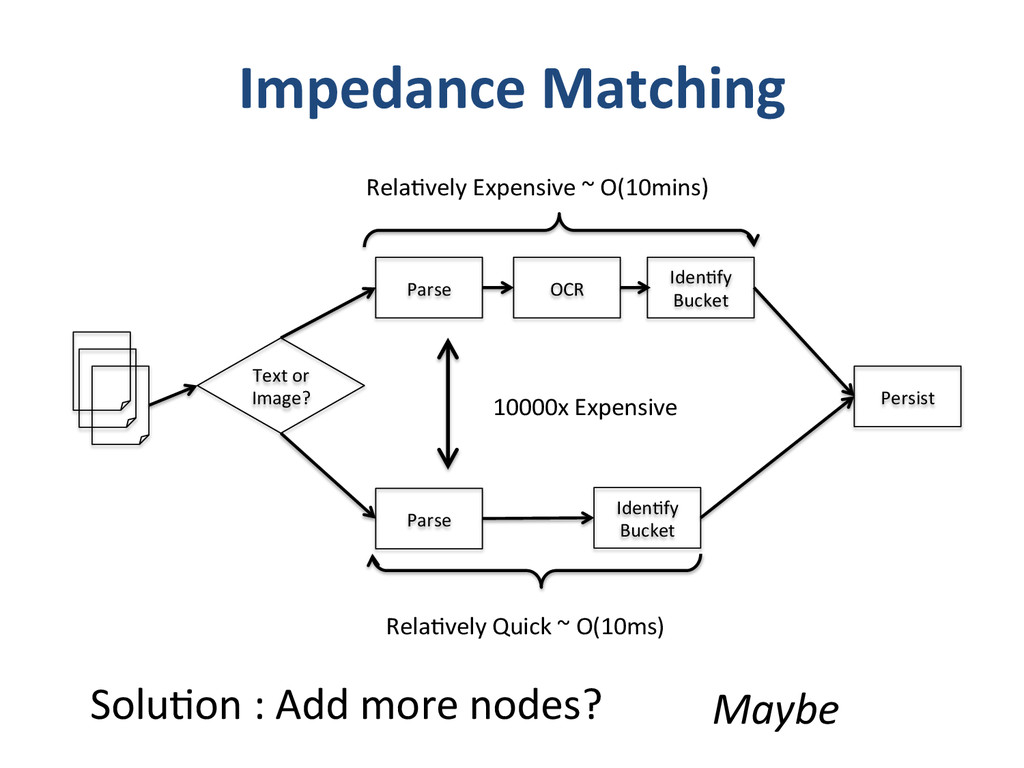{kind=link}
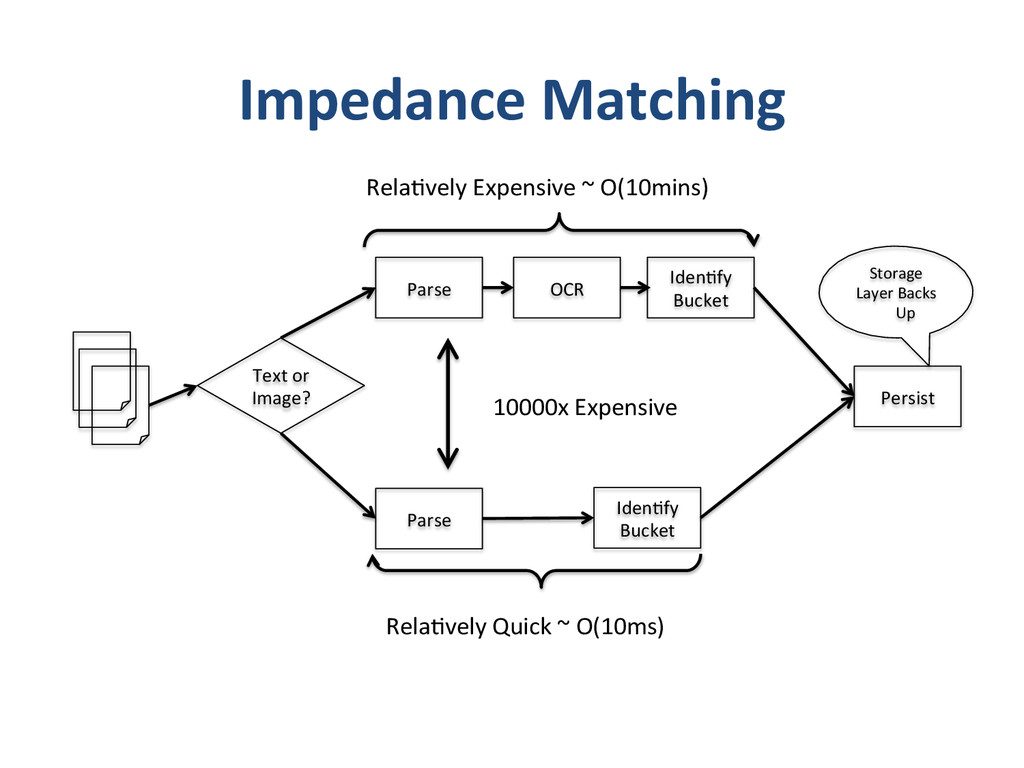{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}