If you are running OpenStack, it's a central component of your infrastructure, providing the foundation for your VM, network, and systems management. Failure is not an option and monitoring is key.
So what are your options around monitoring?
And how do you know what metrics to look at to know that your environment is available and performing optimally?
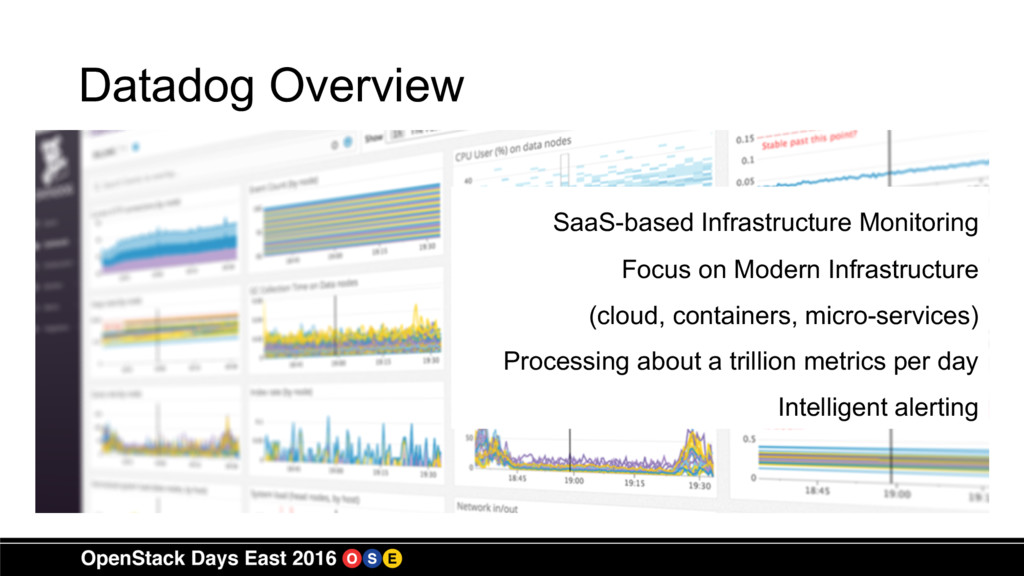
At Datadog we collect a trillion metrics a day for our customers on a variety of platforms
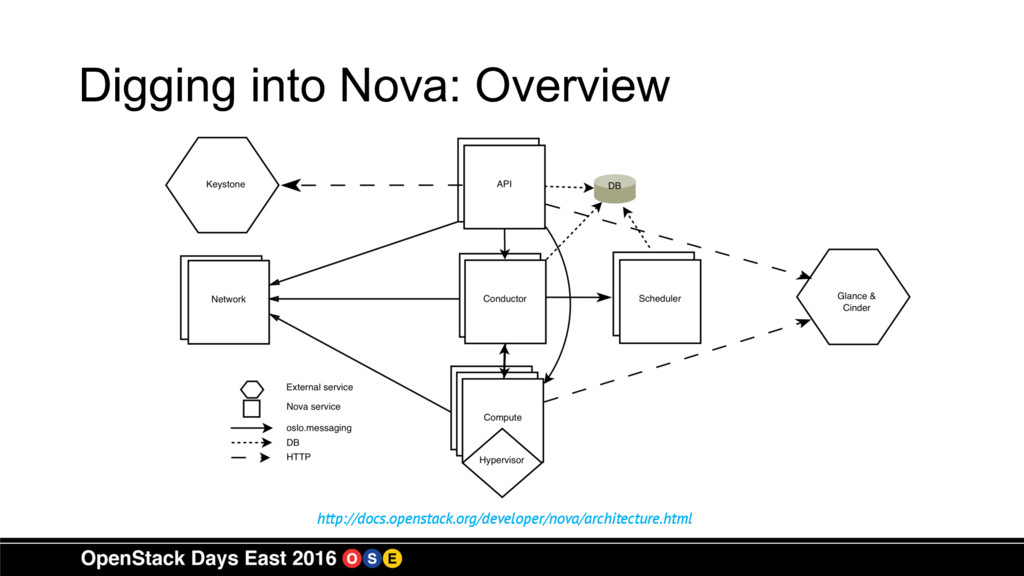
including OpenStack and have learned a lot about how to sift through all the data. This session will show you how to access performance data from OpenStack Nova, RabbitMQ, and other sources within your OpenStack environment. We will also look at parsing this data and figuring out how to take the appropriate action to ensure the environment remains healthy.
Check out this blog post for more information about our integration:
https://www.datadoghq.com/blog/openstack-monitoring-nova/
![Monitoring OpenStack and Dynamic Infrastructure Matthew Williams – [email protected] -](https://files.speakerdeck.com/presentations/11698544a8a34e0ea3c8bc5b8f143cde/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Monitoring OpenStack and Dynamic Infrastructure Matthew Williams – [email protected] -](https://files.speakerdeck.com/presentations/11698544a8a34e0ea3c8bc5b8f143cde/slide_52.jpg){kind=link}