Fujita et. al., ” Attention-based ASR with Lightweight and Dynamic Convolutions,” Proc. ICASSP2020. • Y. Fujita et. al, “Insertion-Based Modeling for End-to-End Automatic Speech Recognition,” Proc. INTERSPEECH2020. • X. Chang et. al., “End-to-End ASR with Adaptive Span Self-Attention,” Proc. INTERSPEECH2020. (co-author Y. Fujita and M. Omachi) 2021 • M. Omachi et. al., ” End-to-end ASR to jointly predict transcriptions and linguistic annotations,” Proc. NACCL 2021. • Y. Fujita et. al., “Toward Streaming ASR with Non-Autoregressive Insertion-based Model,“ Proc. INTERSPEECH 2021. • T. Maekaku et. al., “Speech Representation Learning Combining Conformer CPC with Deep Cluster for the ZeroSpeech Challenge 2021,” Proc. INTERSPEECH 2021. • T. Wang et. al., “Streaming End-to-End ASR based on Blockwise Non-Autoregressive Models,” Proc. INTERSPEECH 2021. (co-author Y. Fujita) • Y. Higuchi et. al., “A Comparative Study on Non-Autoregressive Modelings for Speech-to-Text Generation,” Proc. ASRU 2021. (co-author Y. Fujita) • X . Chang et. al., “An Exploration of Self-Supervised Pretrained Representations for End-to-End Speech Recognition,” Proc. ASRU 2021. (co-author T.Maekaku) • F. Boyer et. al., “A Study of Transducer Based End-to-End ASR with ESPnet: Architecture, Auxiliary Loss and Decoding Strategies,” Proc. ASRU 2021. (co-author Y. Shinohara and T. Ishii) 2022 • M. Omachi et. al., “Non-autoregressive End-to-end automatic speech recognition incorporating downstream natural language processing,” Proc. ICASSP 2022. • T. Maekaku et. al., “An exploration of HuBERT with large number of cluster units and model assessment using Bayesian Information Criterion,” Proc. ICASSP 2022. • T. Maekaku et. al,, “Attention Weight Smoothing Using Prior Distributions for Transformer-Based End-to-End ASR,” Proc. INTERSPEECH2022. • Y. Shinohara et. al., “Minimum Latency Training of Sequence Transducers for Streaming End-to-End Speech Recognition,” Proc. INTERSPEECH 2022. • X. Chang et. al., “End-to-End Integration of Speech Recognition, Speech Enhancement, and Self-Supervised Learning Representation, ” Proc. INTERSPEECH 2022 (co-author Y. Fujita and T. Maekaku)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
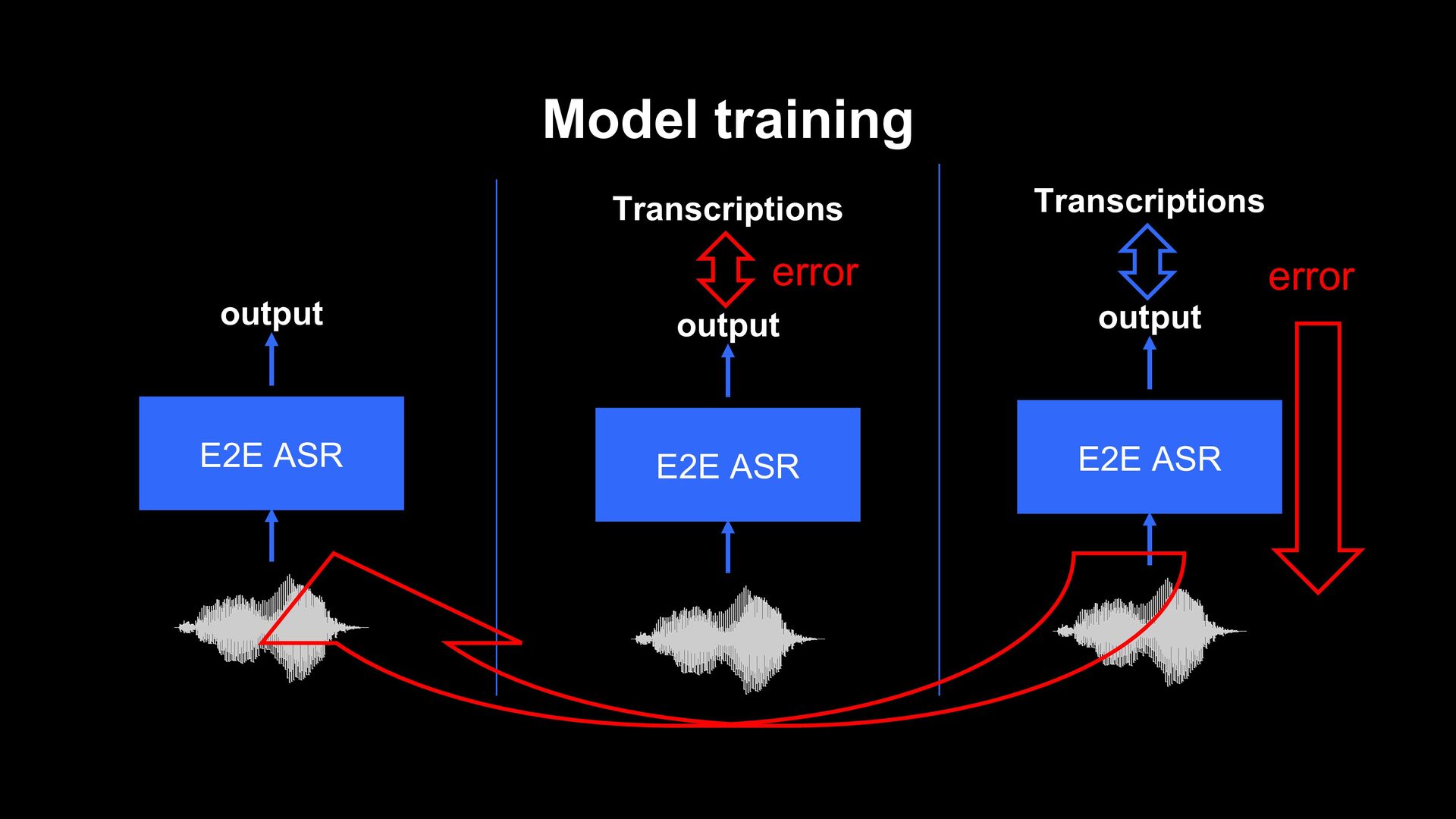
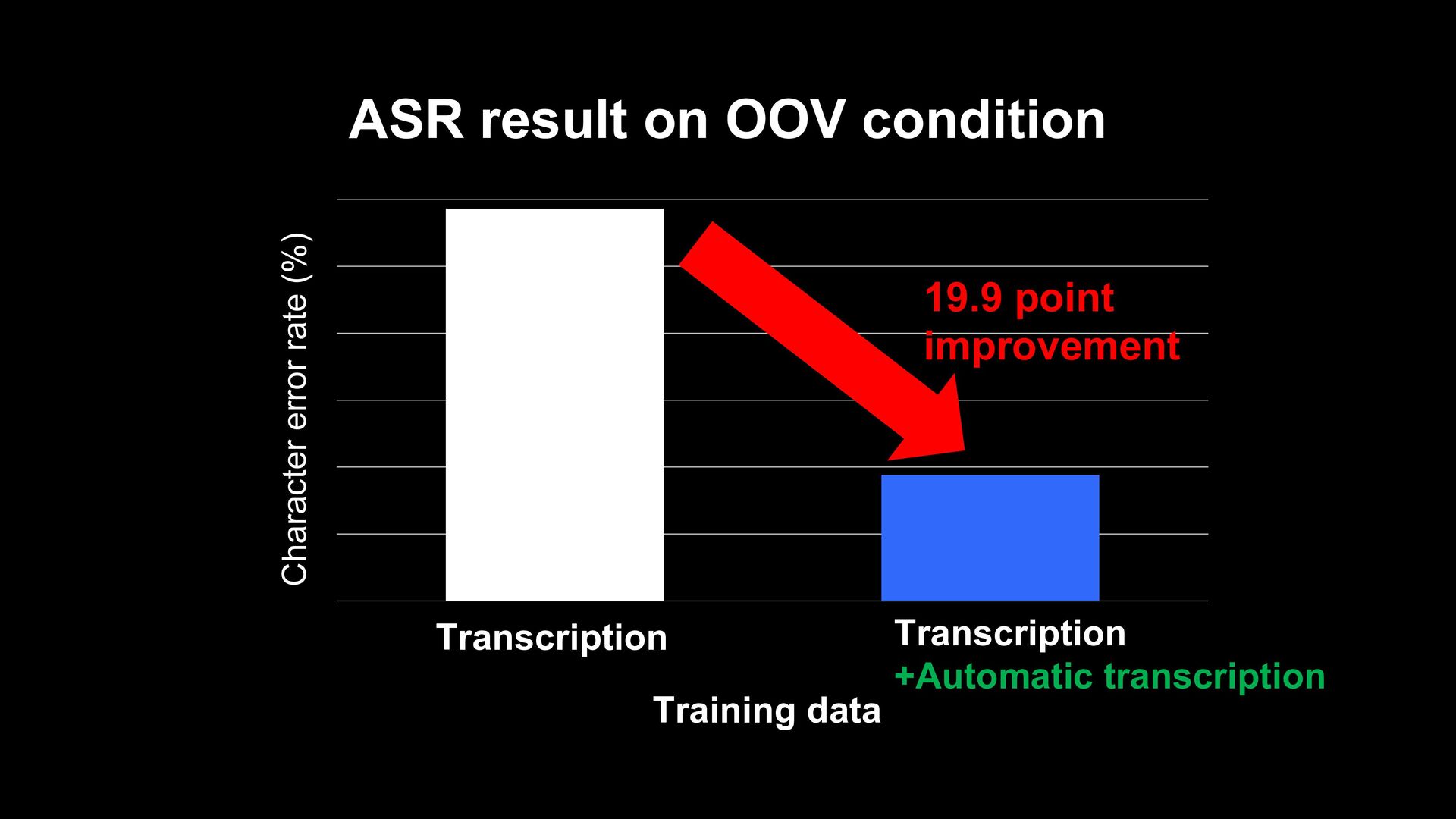
![Data augmentation [1] using untranscribed speech [1] Y. He., et](https://files.speakerdeck.com/presentations/e549eadc41a84bef91c8e7e1b9192b22/slide_49.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
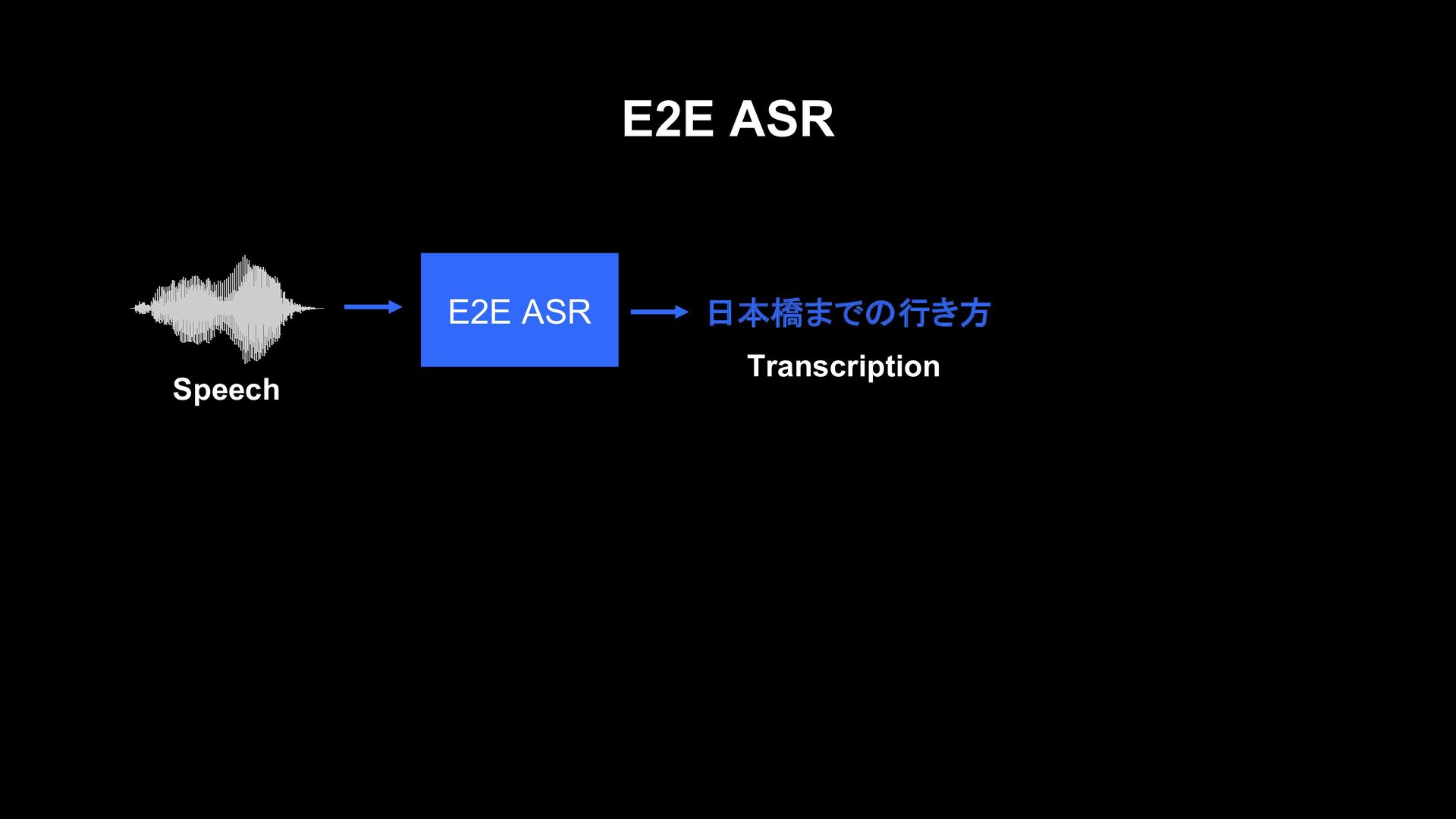
![Joint prediction of graphemes and phonemes [2] [2] M. Omachi.,](https://files.speakerdeck.com/presentations/e549eadc41a84bef91c8e7e1b9192b22/slide_54.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}