In August 2021, I joined dely Inc. as a data engineer responsible for building a new data platform for kurashiru › Currently, I work as a data engineer/PjM (Scrum Master) in the personalization-related team. › In 2022, I was selected as the Snowflake Data Superhero Yuya Harigae | harry @gappy50
- Introduction of kurashiru/kurashiru in the Future - Data Platform in the Past - Why Snowflake? - Snowflake’s Near-Real-Time Data Pipeline - How Do We Use Data Platform for kurashiru’s Personalization Function - External Functions to AWS/dbt/for Future ML - kurashiru in the Future
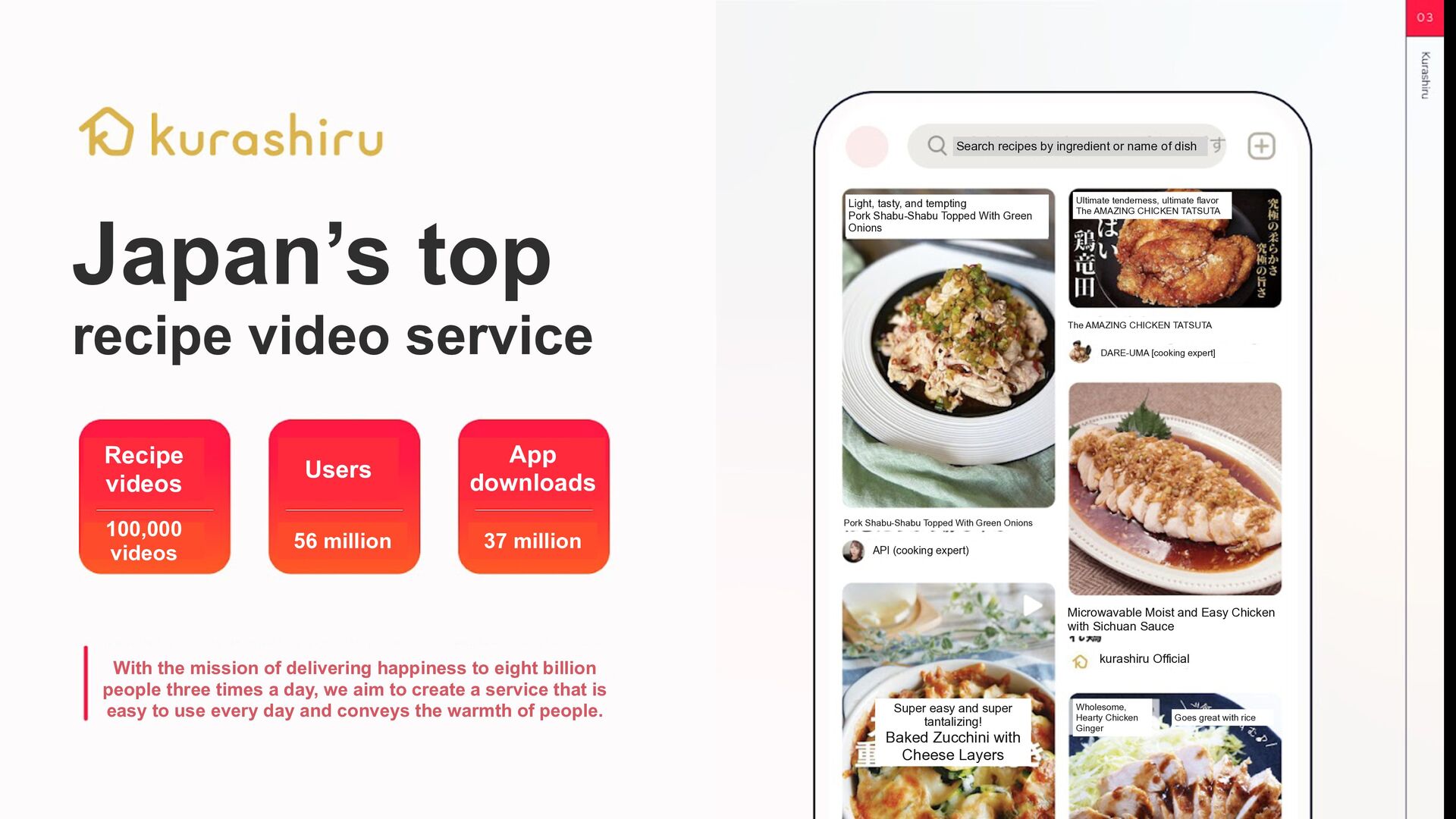
downloads Users 100,000 videos 56 million 37 million With the mission of delivering happiness to eight billion people three times a day, we aim to create a service that is easy to use every day and conveys the warmth of people. Search recipes by ingredient or name of dish Light, tasty, and tempting Pork Shabu-Shabu Topped With Green Onions Ultimate tenderness, ultimate flavor The AMAZING CHICKEN TATSUTA Pork Shabu-Shabu Topped With Green Onions The AMAZING CHICKEN TATSUTA Microwavable Moist and Easy Chicken with Sichuan Sauce Super easy and super tantalizing! Baked Zucchini with Cheese Layers Wholesome, Hearty Chicken Ginger API (cooking expert) DARE-UMA [cooking expert] kurashiru Official Goes great with rice
do not necessarily eat the same food tomorrow as they ate yesterday › If the remaining food is still in the refrigerator, maybe people eat it again › If the remaining food is still in the refrigerator, it is more satisfying for the user to search › Difficulty in setting tasks for making recommendations › We have tried various approaches by building ML models so far › Can we solve the above problem simply by creating ML models to make inferences?
do not necessarily eat the same food tomorrow as they ate yesterday › If the remaining food is still in the refrigerator, maybe people eat it again › If the remaining food is still in the refrigerator, it is more satisfying for the user to search › Difficulty in setting tasks for making recommendations › We have tried various approaches by building ML models so far › Can we solve the above problem simply by creating ML models to make inferences?
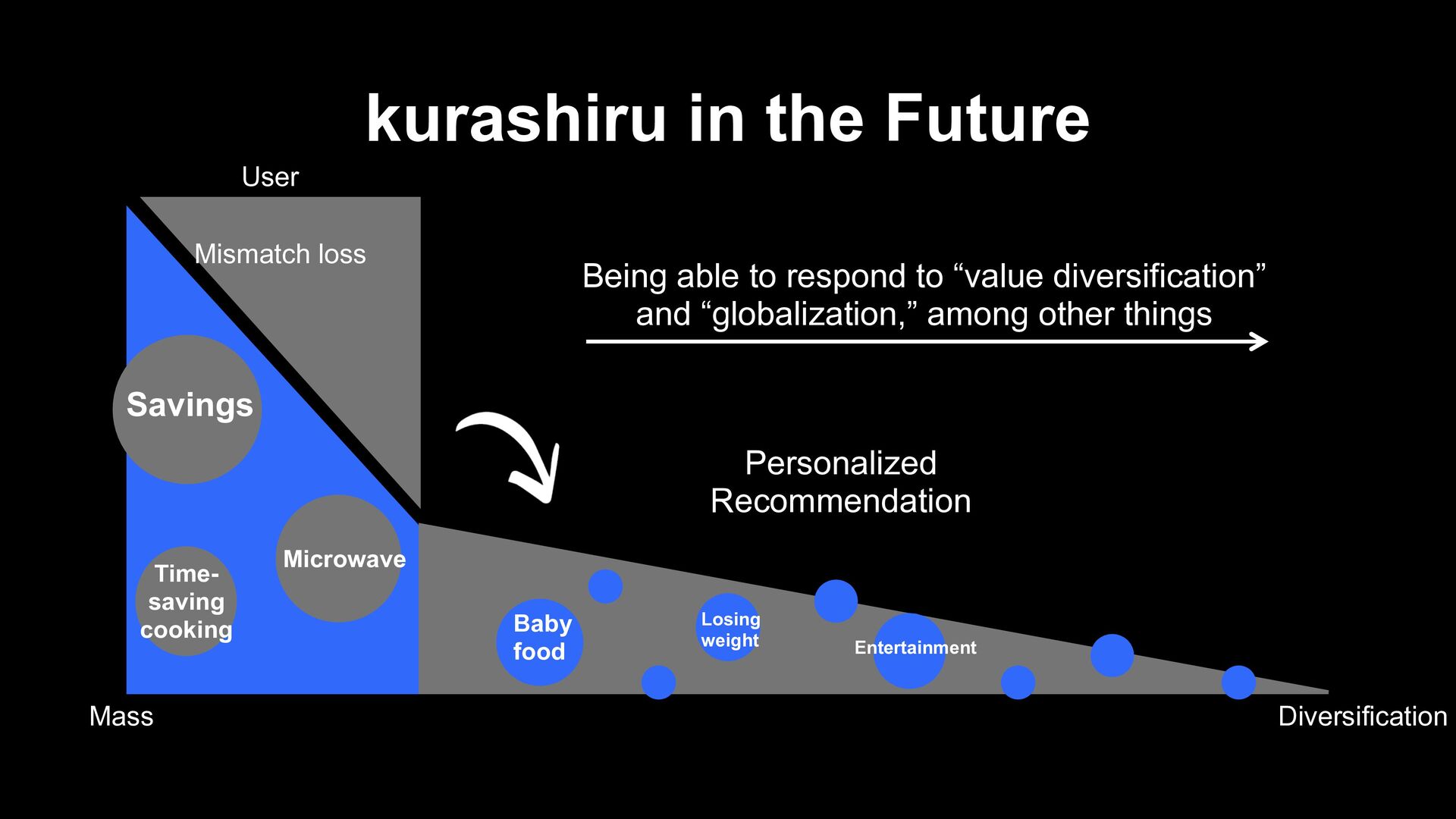
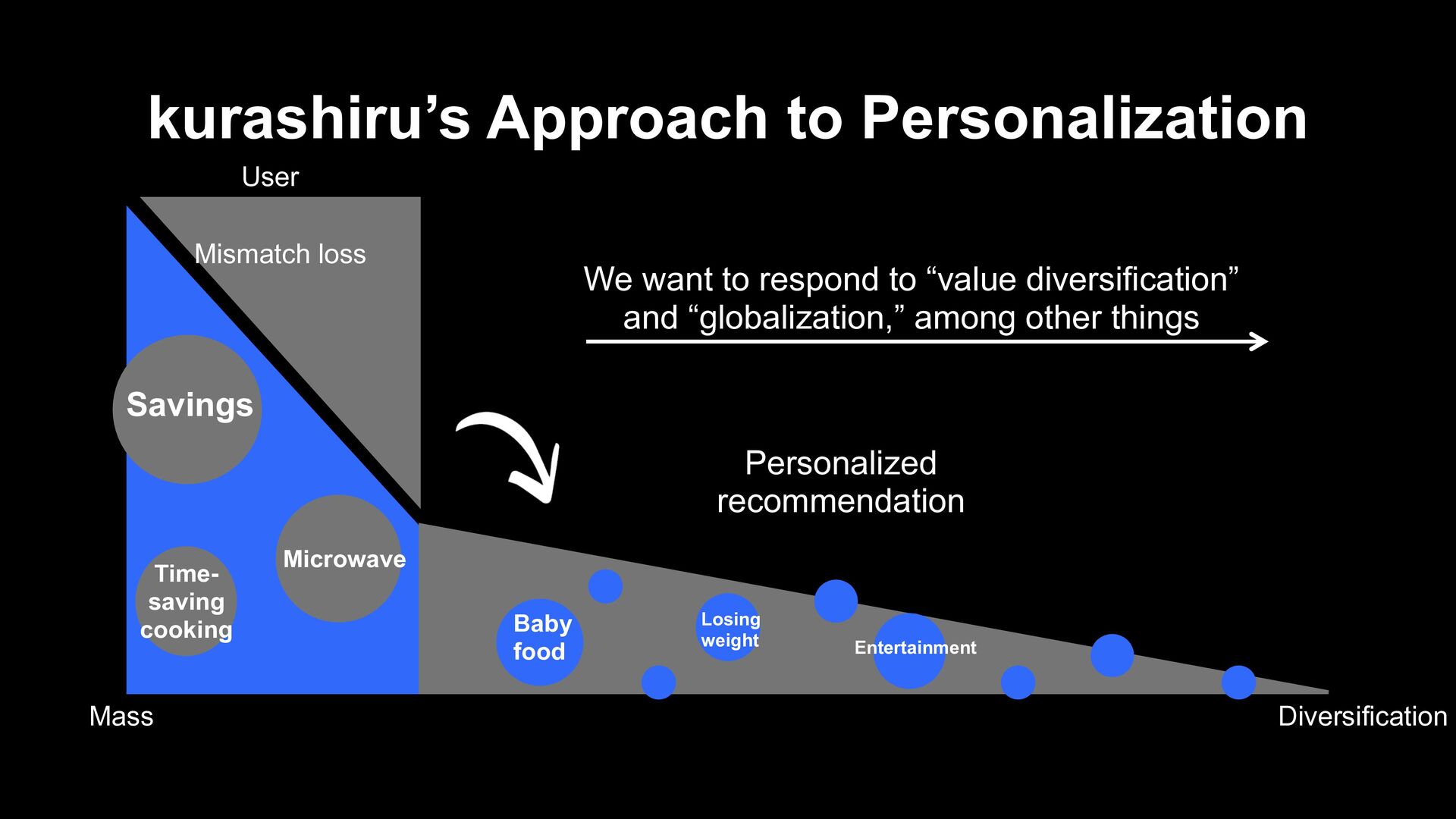
Recommendation Being able to respond to “value diversification” and “globalization,” among other things Diversification Mass Microwave Mismatch loss Baby food Losing weight Entertainment
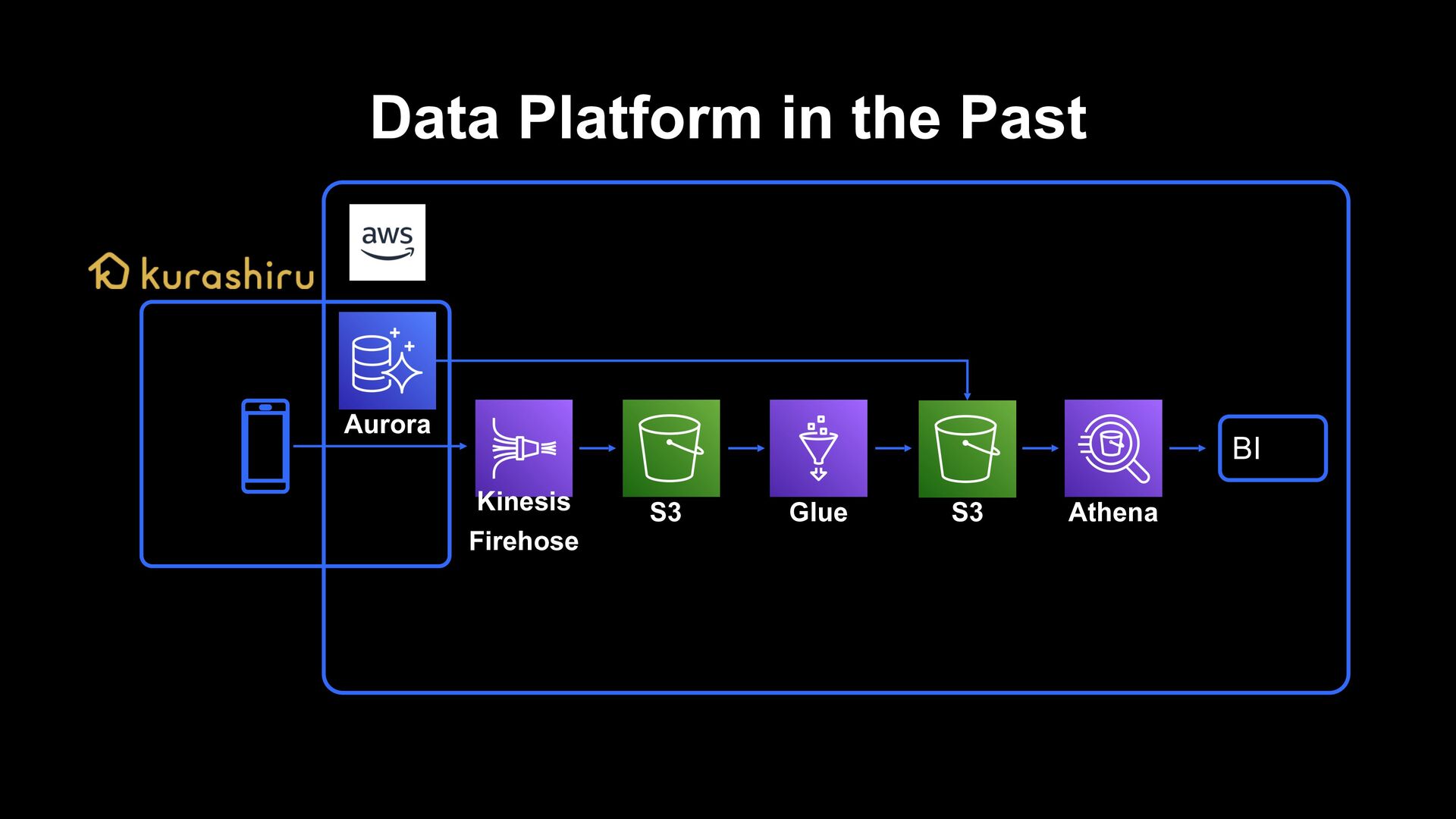
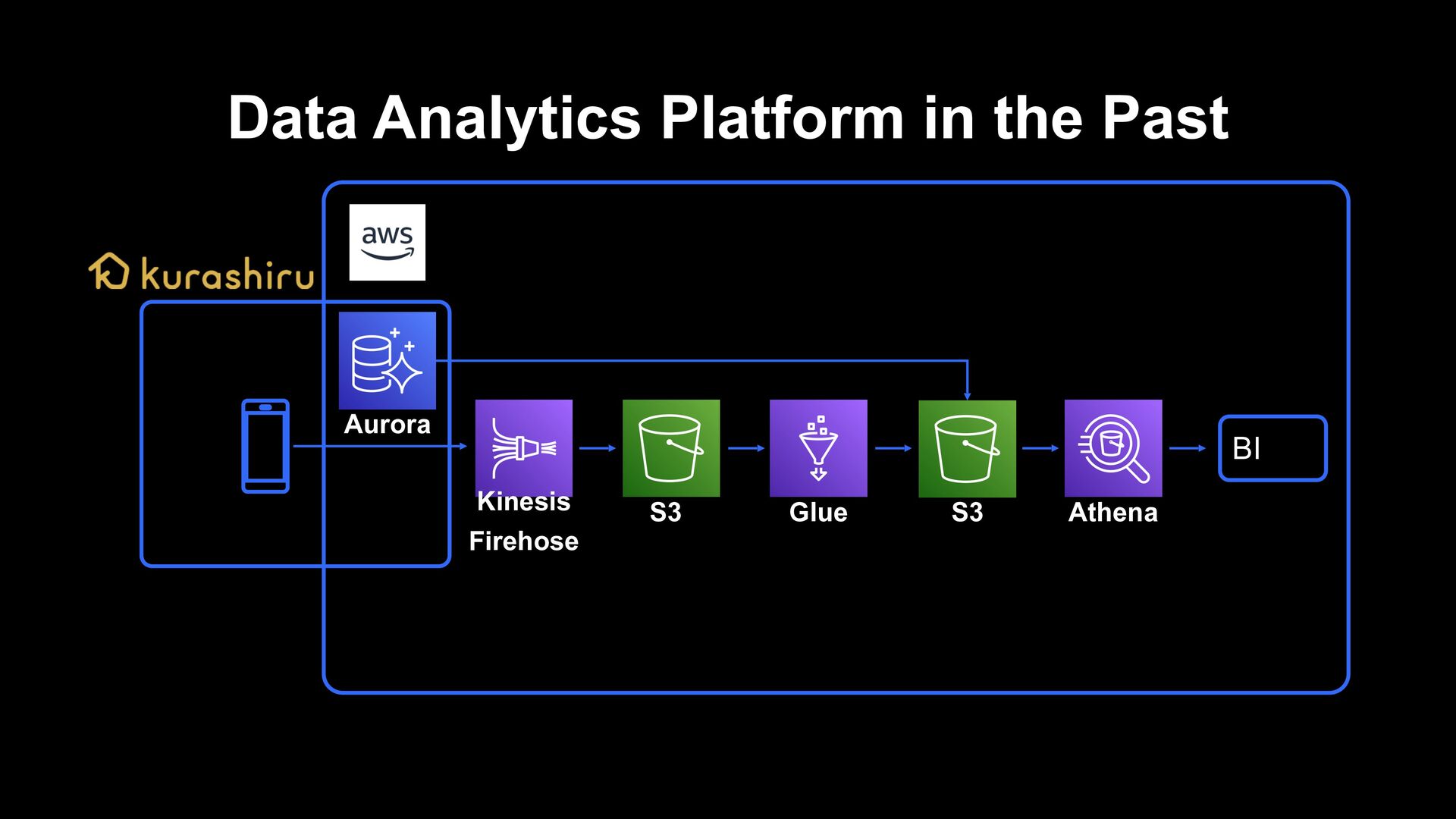
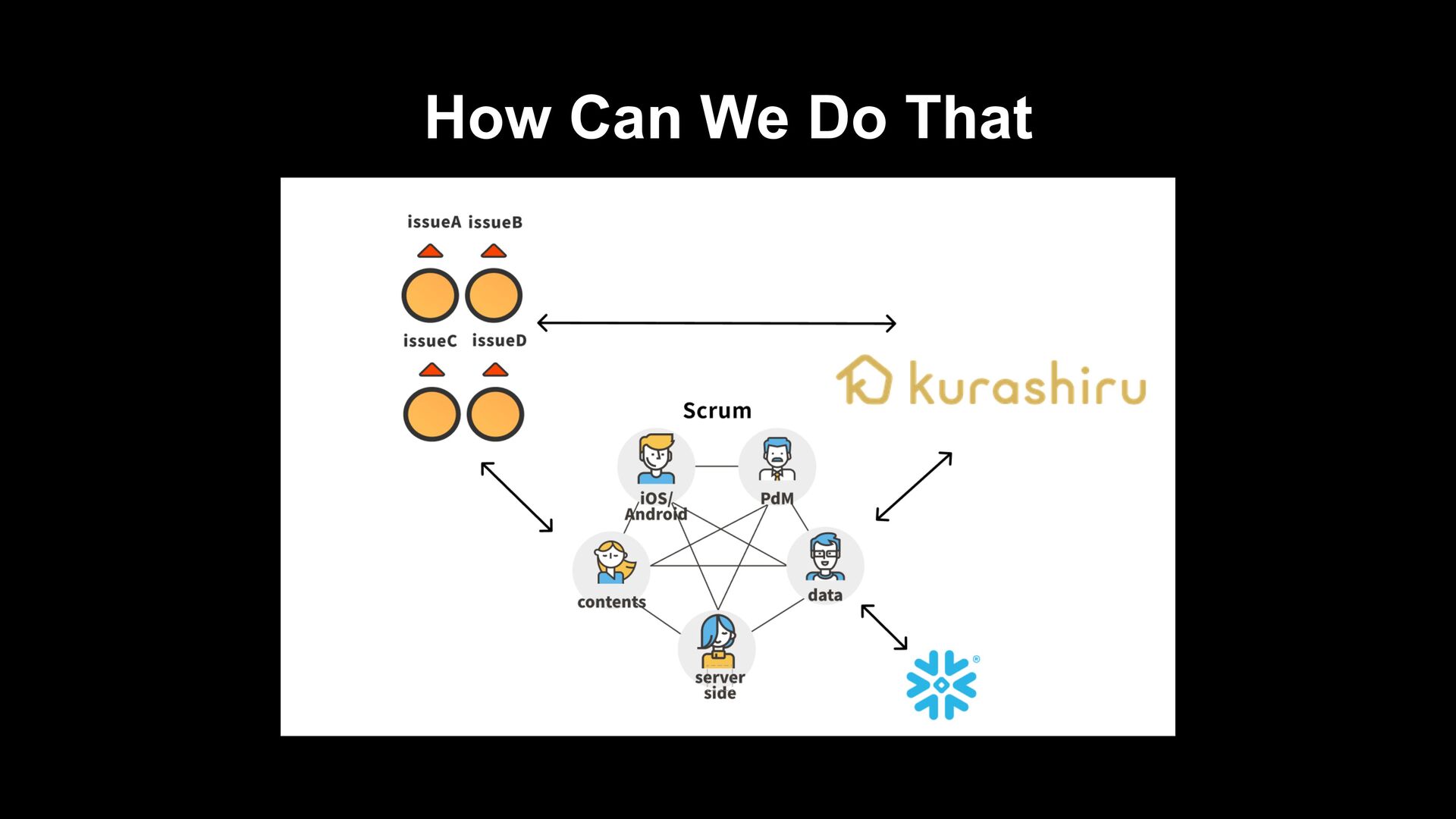
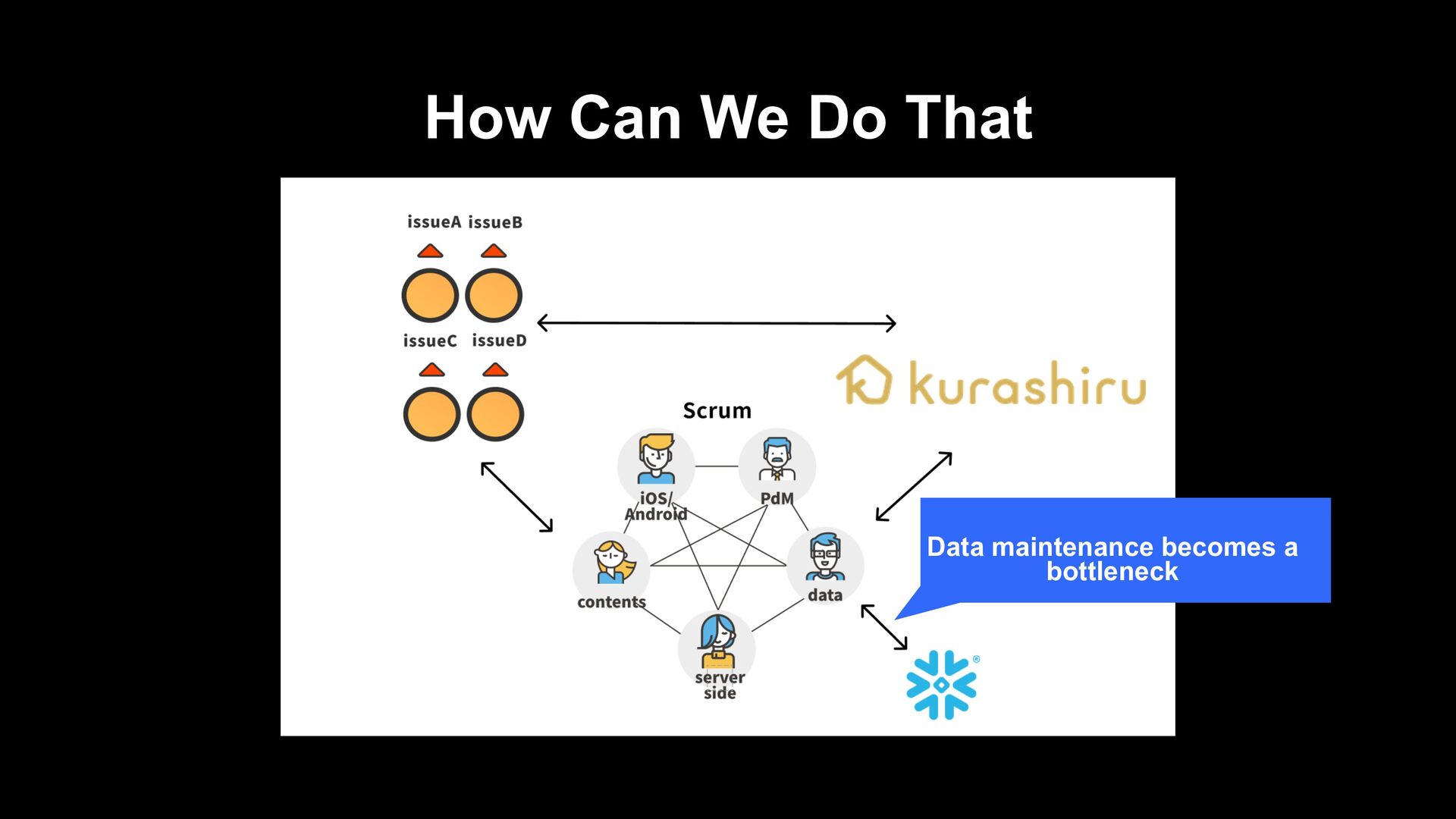
verification of effect, kurashiru can perform necessary analysis for kurashiru to some extent › A culture is fostered where everyone writes queries for analyzing/visualizing regardless of whether they are engineers/PdM/marketers › On the other hand, it is also a state where data chaos is created › It required less data engineer resources It was a good data platform optimized to the limit for analysis purposes
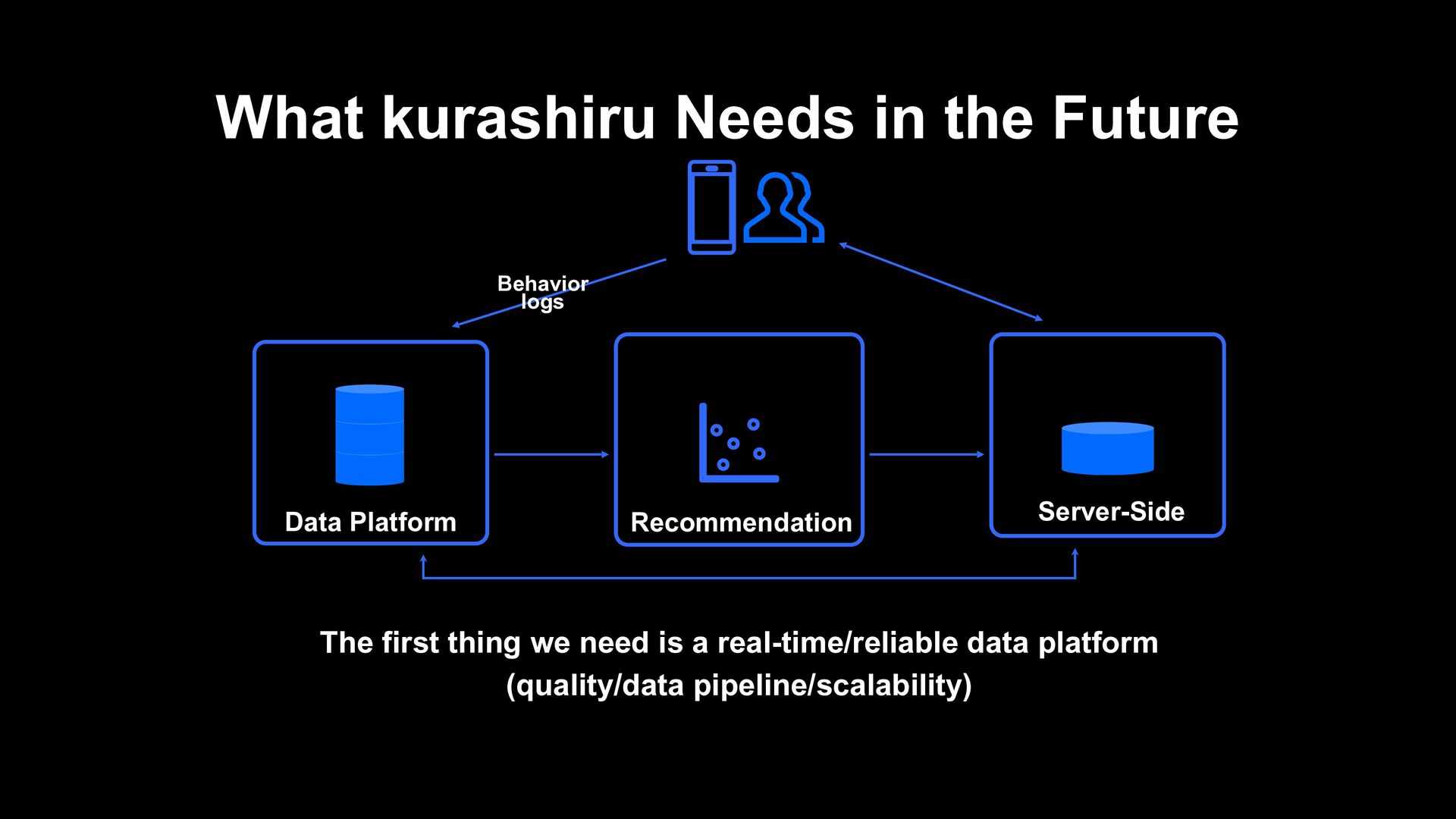
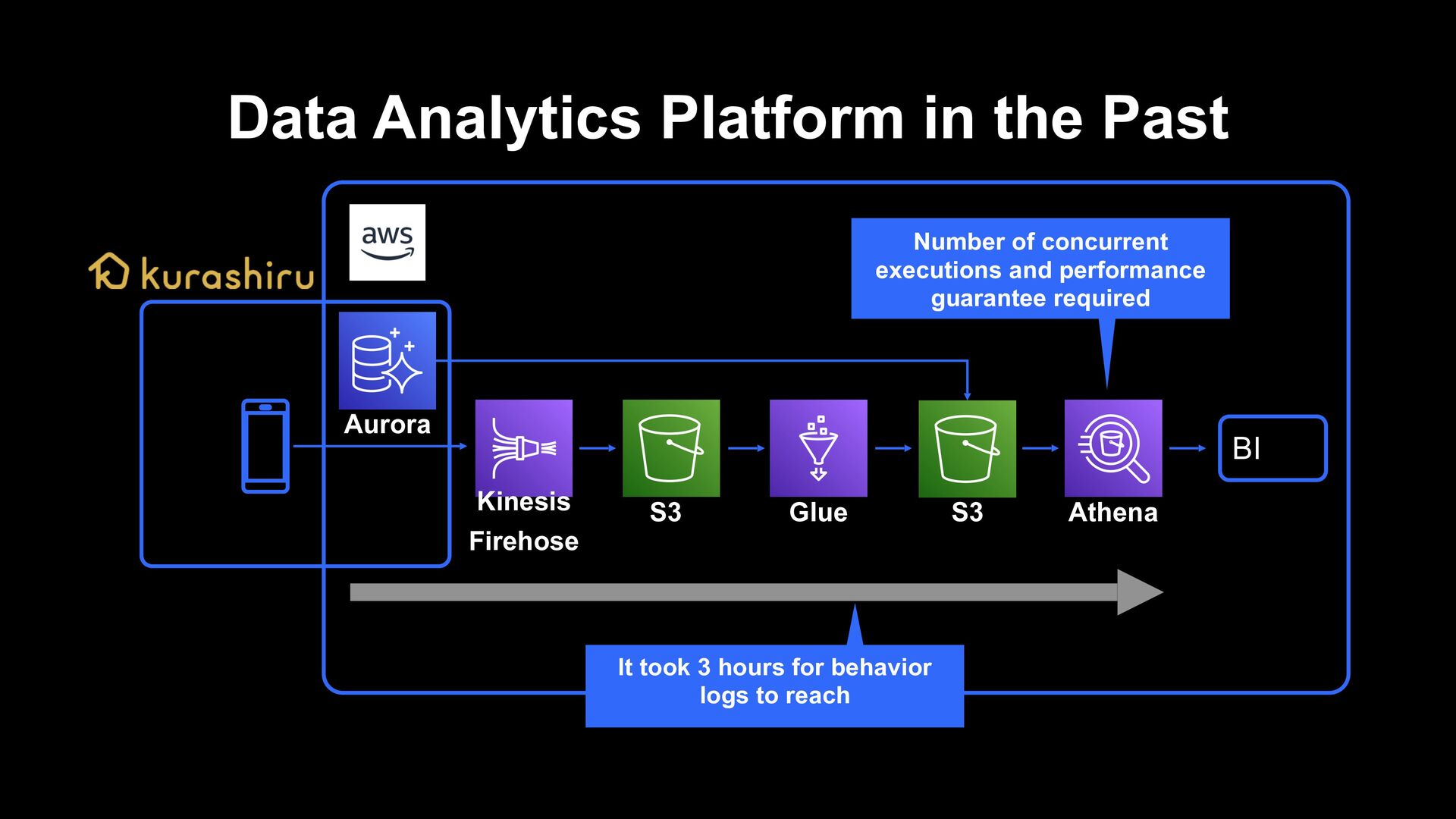
› It took about 3 hours for behavior logs to be analyzed › It took decent time/cost to do ETL the behavior data that is performed 300 million times a day Scalability and responsiveness of DWH › Assuming the use by ML and apps, we need DWH which can guarantee scalability and performance Engineering resources › Especially, data engineer resources are limited and considering additional development and operation of existing data pipelines, agility will be low › It could not support data quality and deal with data chaos such as scattered indicators Issues of Data Analytics Platform in the Past
AWS data platform, existing assets and data can be used as they are › Virtually no need to manage infrastructure or detailed management according to workload › There are benefits from storage isolation and multiple approaches are enabled by work load isolation › Computing resources scale instantly with almost no limit › There are many functions to do ELT and create data pipelines to managed › Easy to migrate from existing AWS data platform, existing assets and data can be used as they are Functional convenience for data engineering Good compatibility with multi-cloud/data sharing/modern data stack › Good compatibility with dbt (described later) and data stacks that are mainstream overseas, and is less likely to be locked by vendor › Easy to deploy Snowflake machine learning and options with AI services are available › When data utilization advances, we can expect a future where kurashiru log data sharing becomes possible
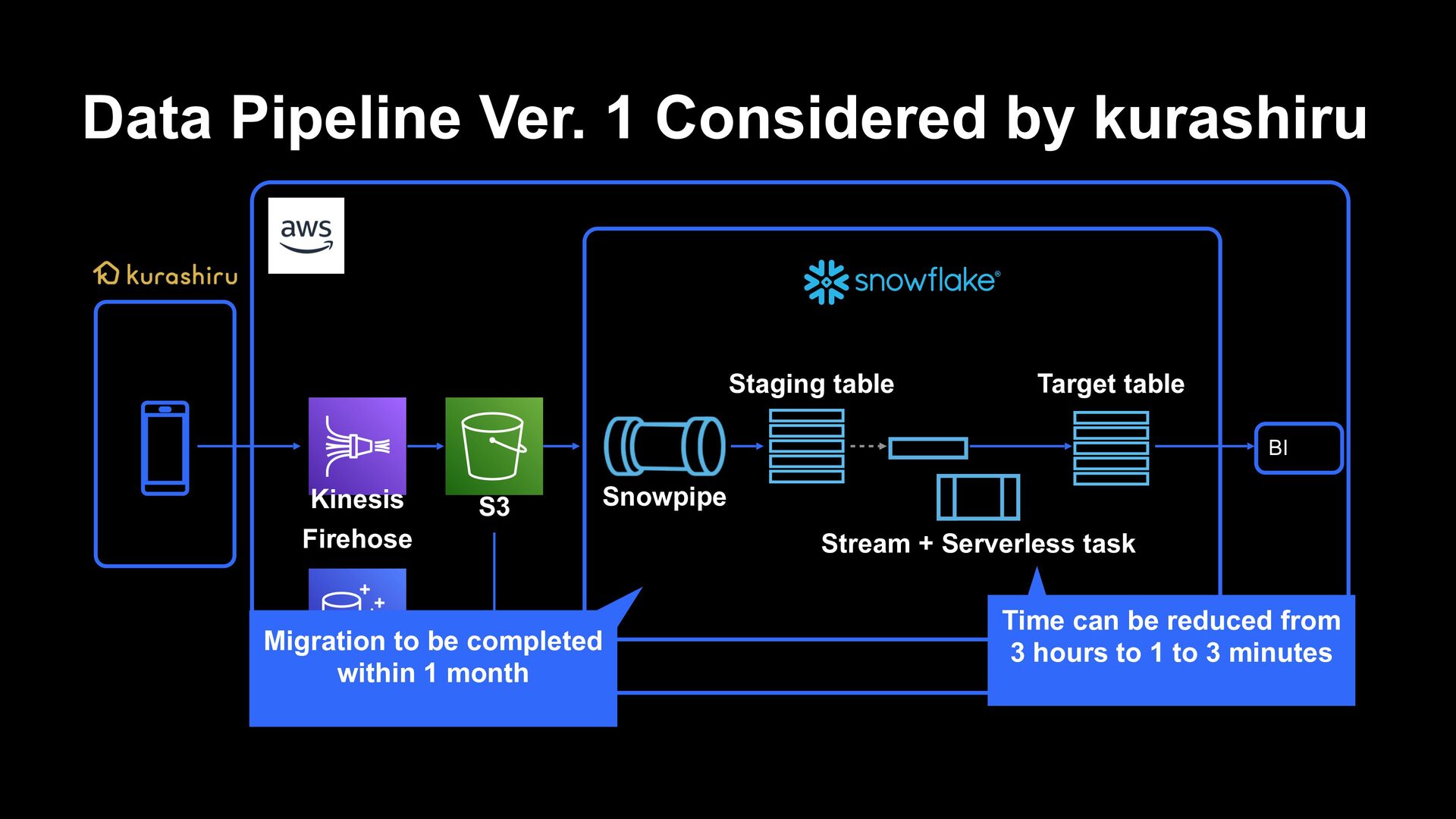
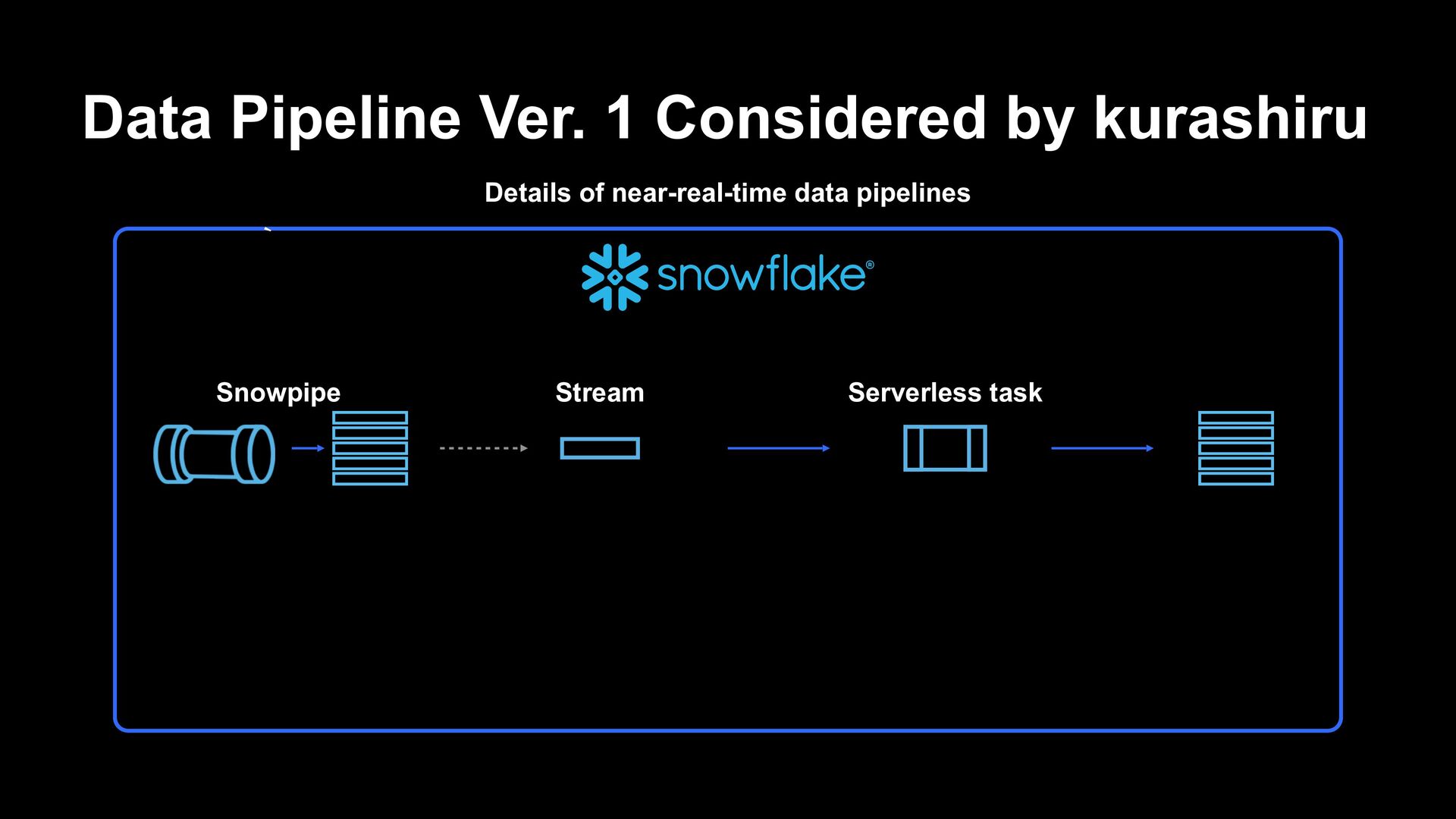
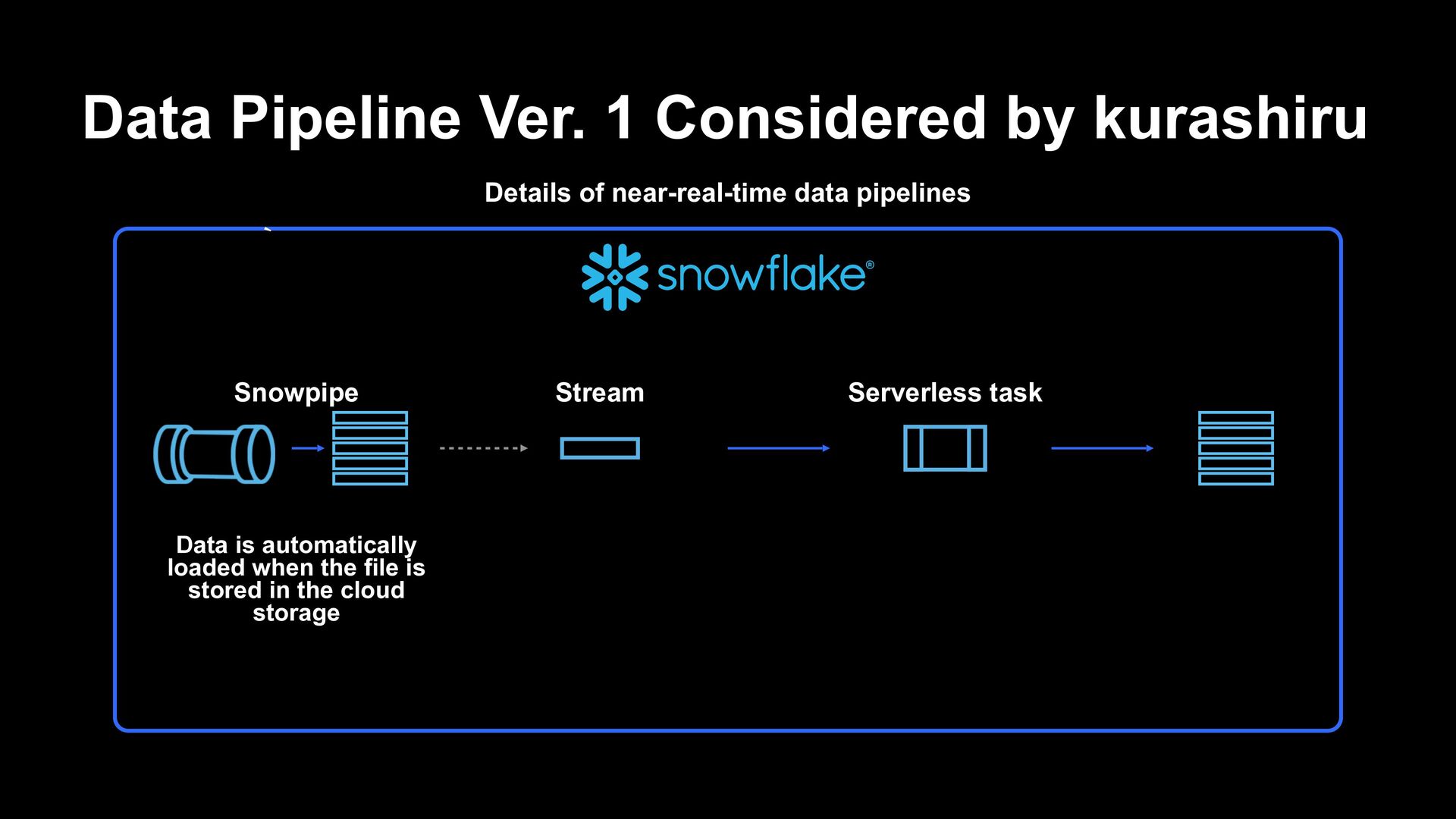
S3 Snowpipe Stream + Serverless task Staging table Target table Time can be reduced from 3 hours to 1 to 3 minutes Migration to be completed within 1 month
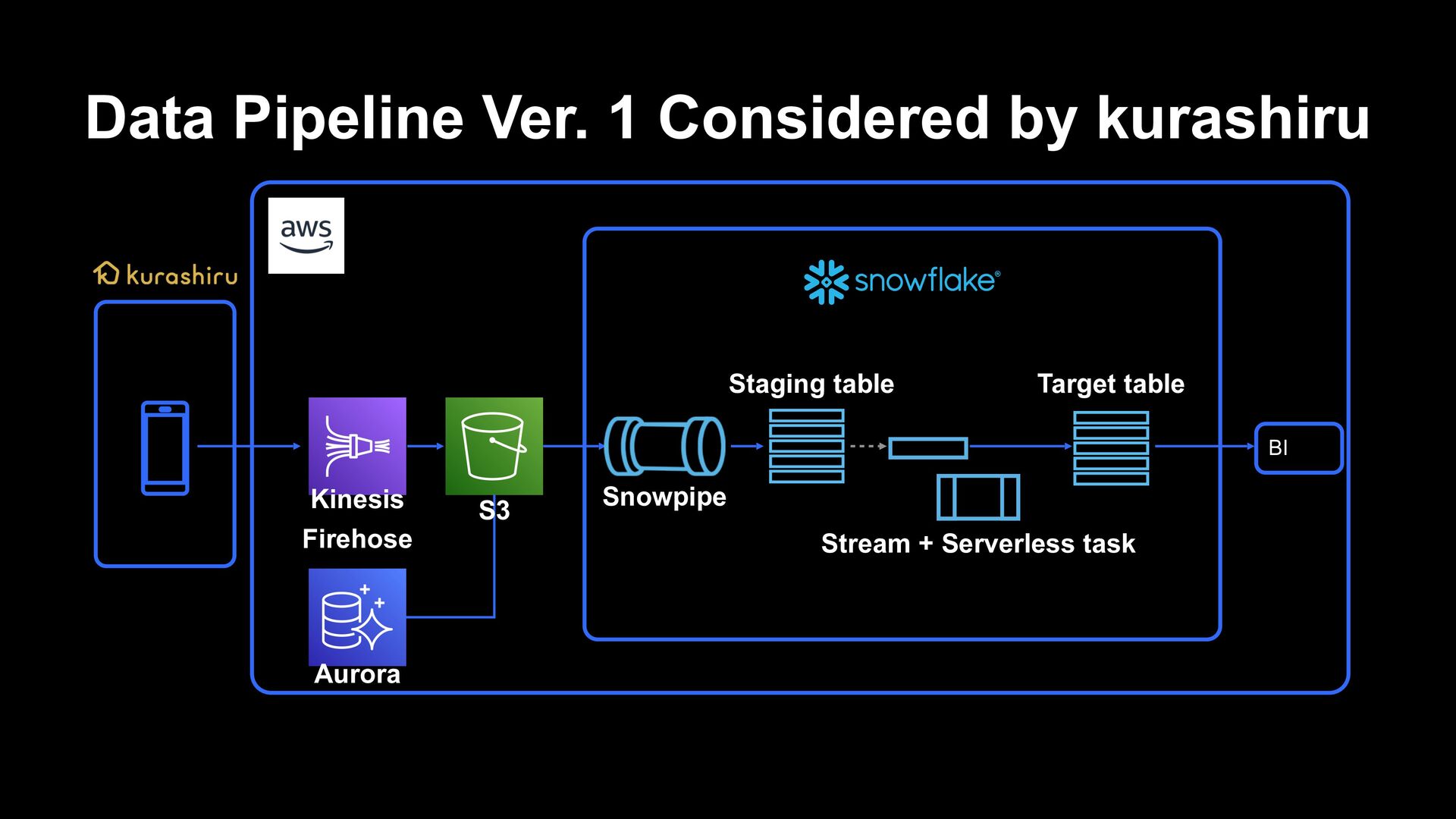
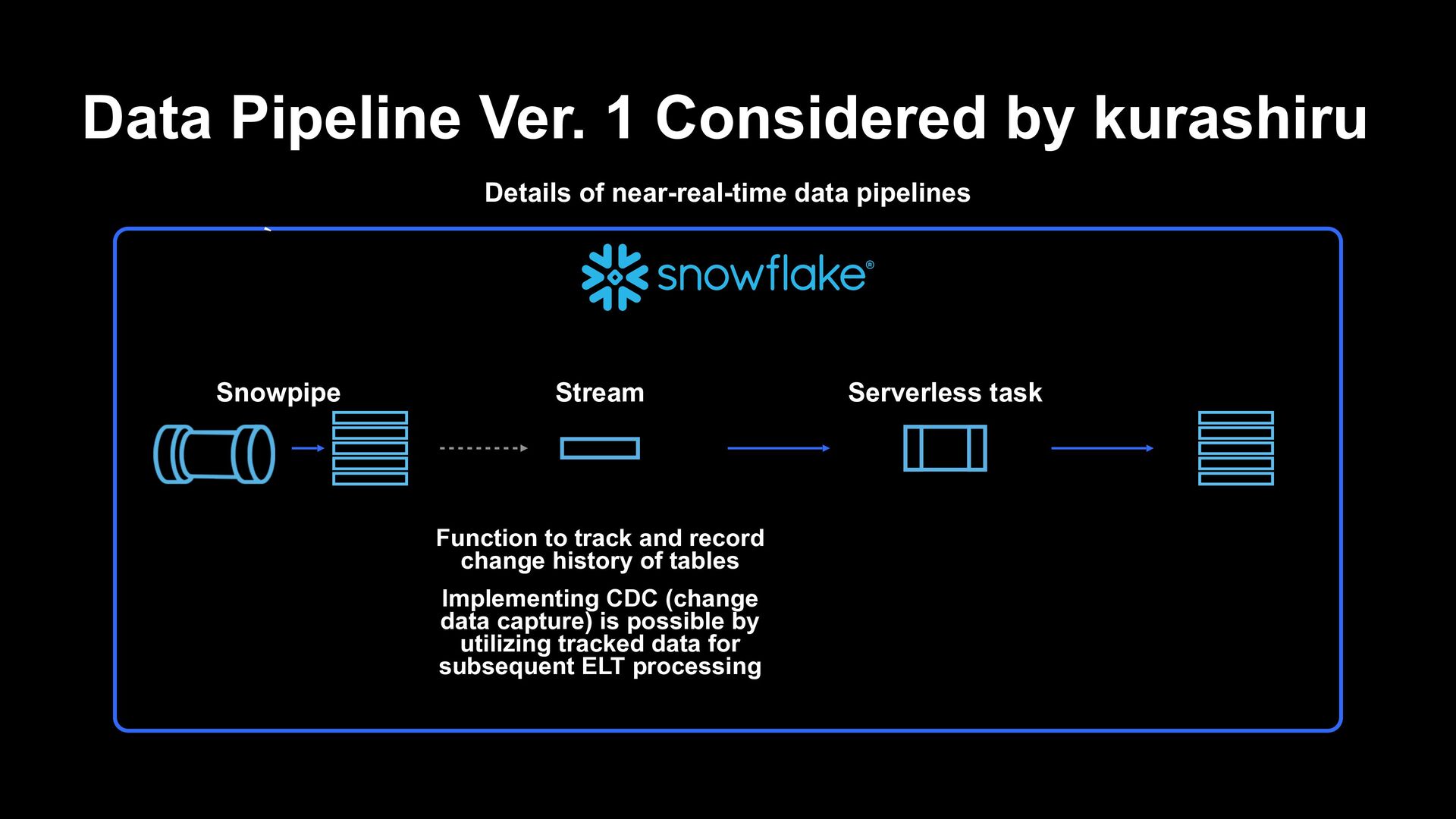
to track and record change history of tables Implementing CDC (change data capture) is possible by utilizing tracked data for subsequent ELT processing ʆ Data Pipeline Ver. 1 Considered by kurashiru
queries/scripts periodically Complex data pipelines can be implemented by combining tasks to form a DAG Charged by the second operated, and computing resources are also executed by ideal size depending on the situation ʆ Data Pipeline Ver. 1 Considered by kurashiru Serverless task
to run queries/scripts periodically Complex data pipelines can be implemented by combining tasks to form a DAG Charged by the second operated, and computing resources are also executed by ideal size depending on the situation ʆ Data Pipeline Ver. 1 Considered by kurashiru
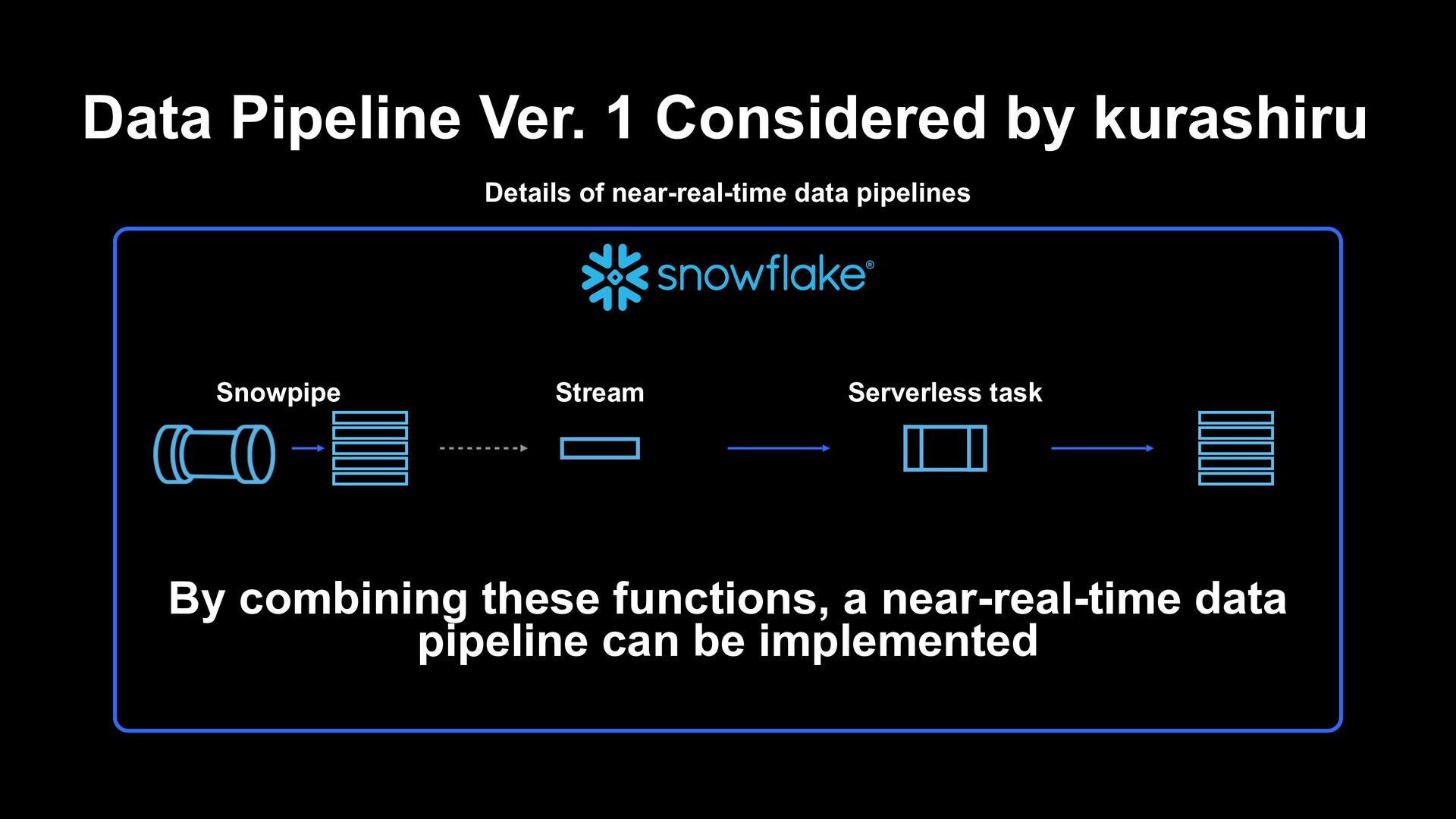
data engineering resources, the migration from the existing data analytics platform to new data platform was completed within a few months from looking into implementation to production › Taking advantage of the characteristics of near-zero maintenance, we are able to operate in a state where there is almost no need for fault tolerance and workload monitoring (such state continues even now, about a year after the migration) › Operation is easy just to pay a little attention to cost on a daily basis Thanks to near-real-time data pipeline, › Now we have obtained an environment where client behaviors can be analyzed within minutes › Managed ELT processing with CDC/serverless tasks enabled cost-optimized pipeline operation
Mismatch loss Baby food We want to respond to “value diversification” and “globalization,” among other things Losing weight kurashiru’s Approach to Personalization Entertainment
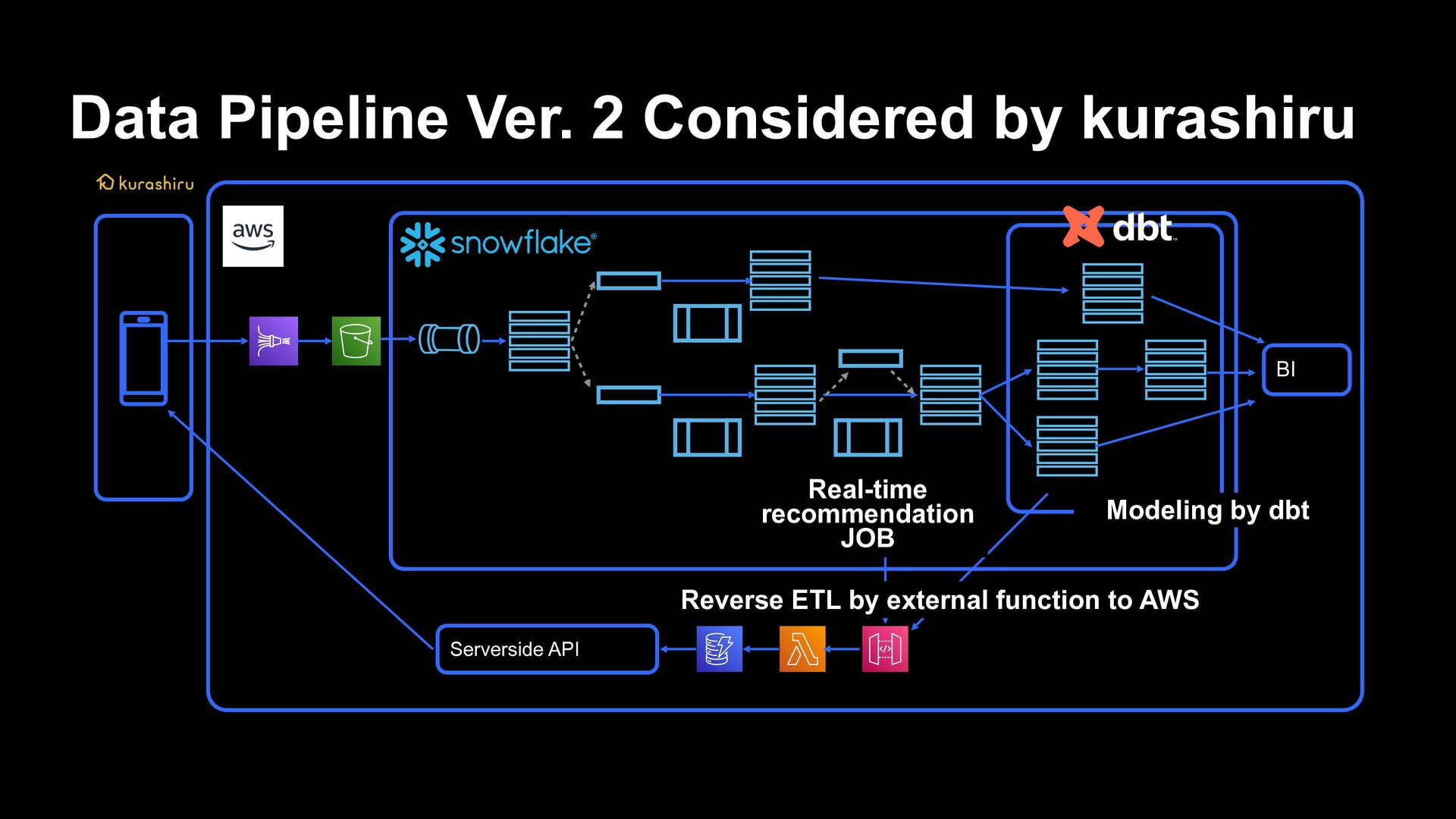
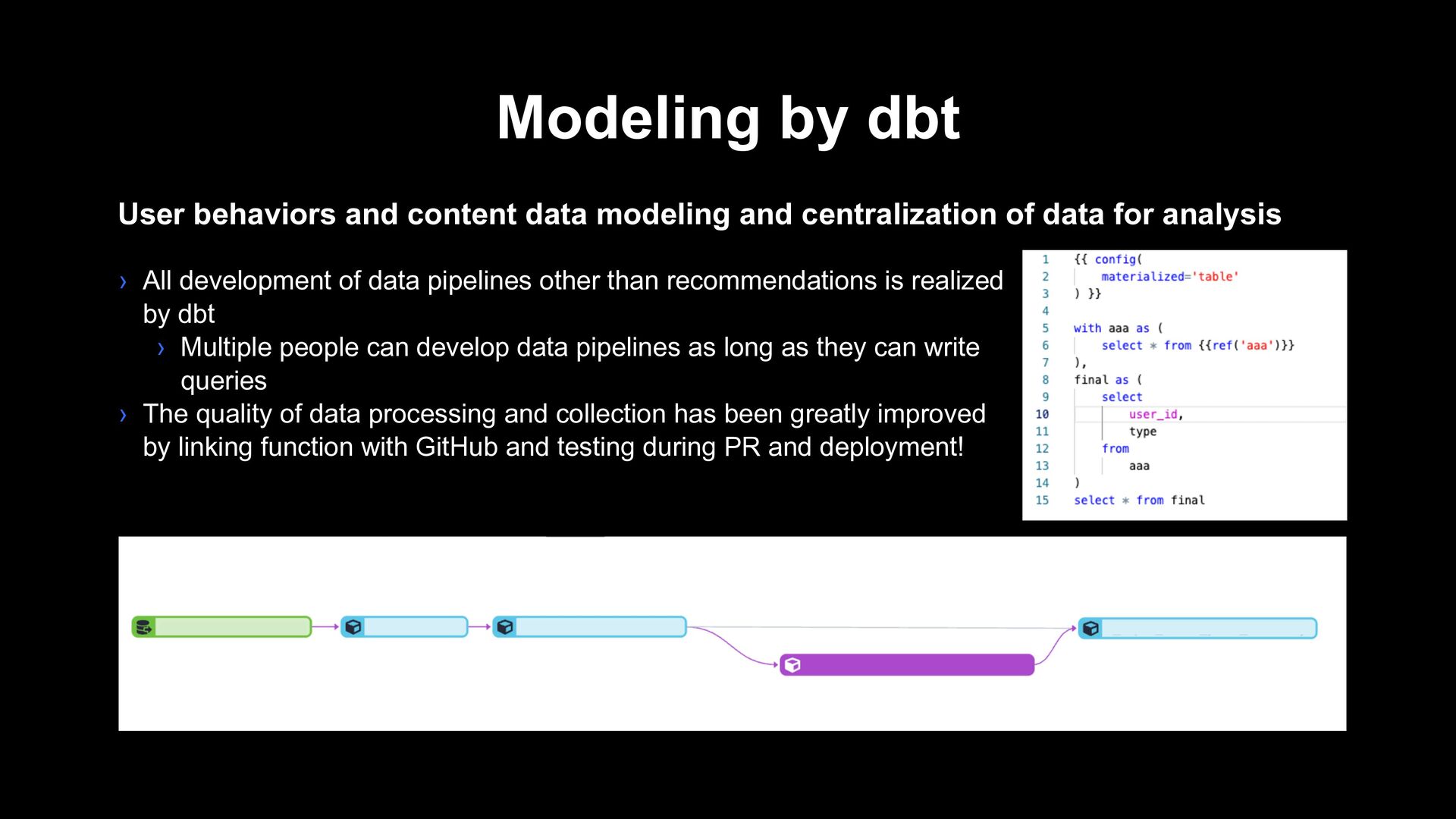
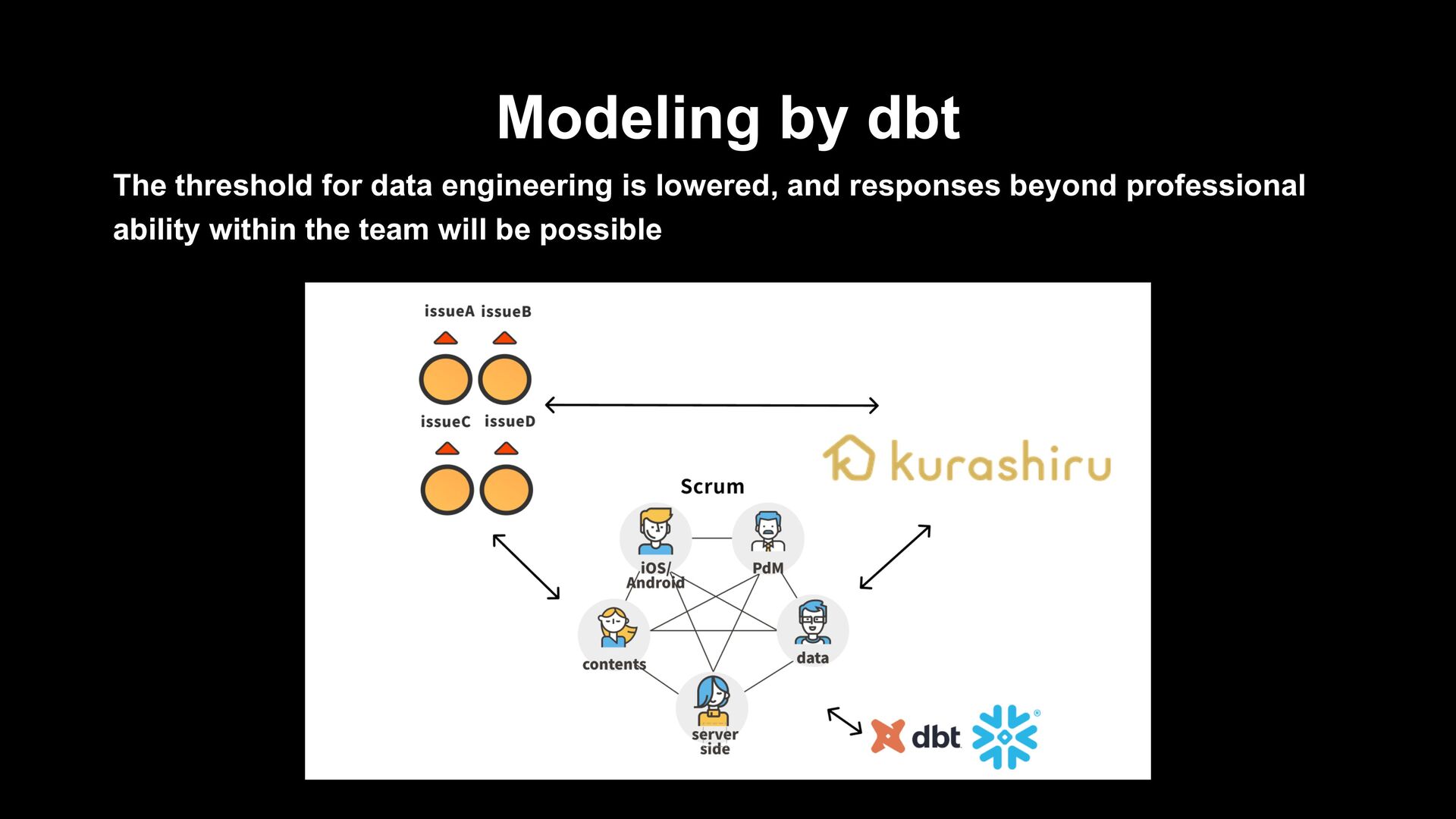
centralization of data for analysis › All development of data pipelines other than recommendations is realized by dbt › Multiple people can develop data pipelines as long as they can write queries › The quality of data processing and collection has been greatly improved by linking function with GitHub and testing during PR and deployment!
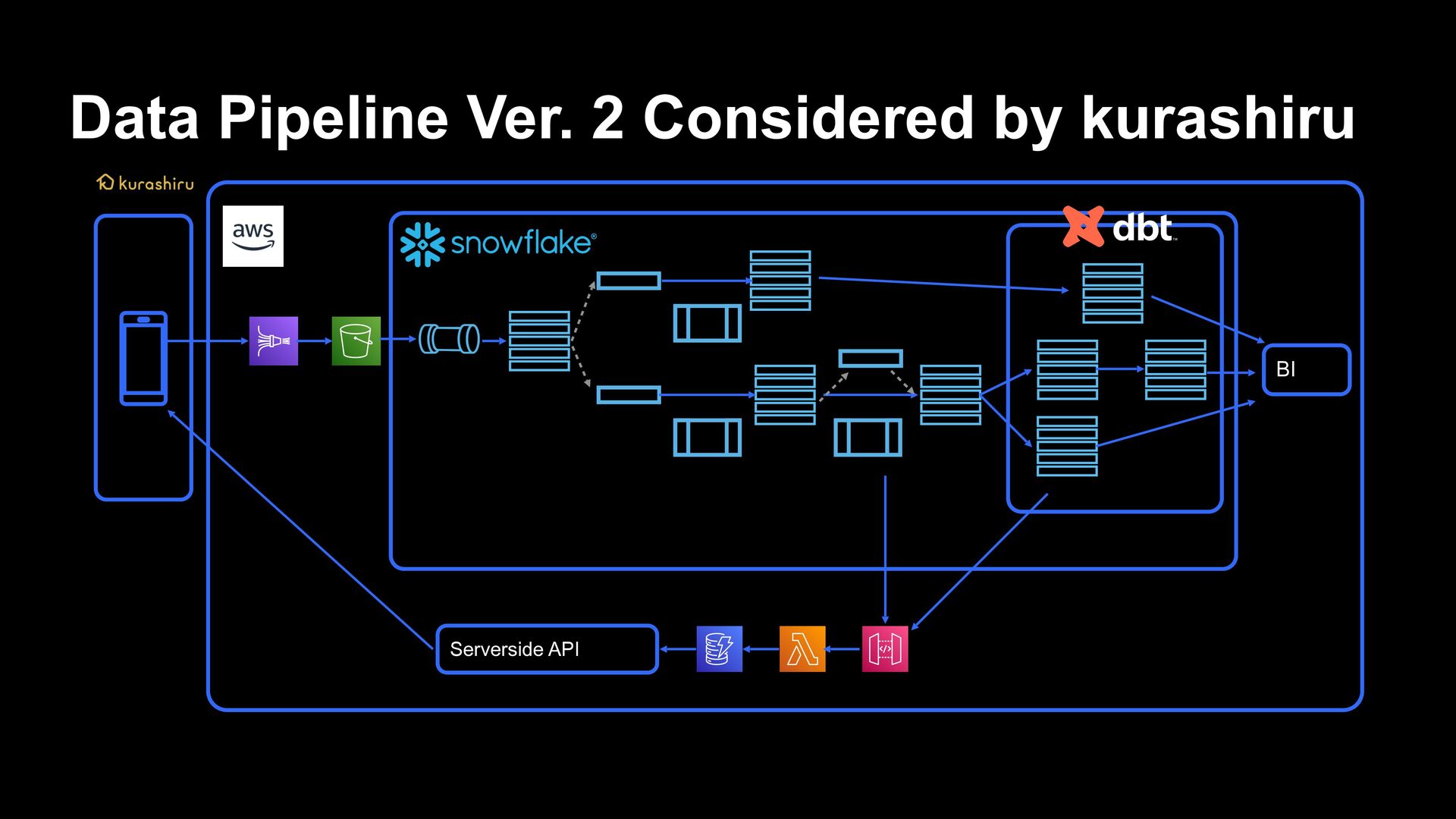
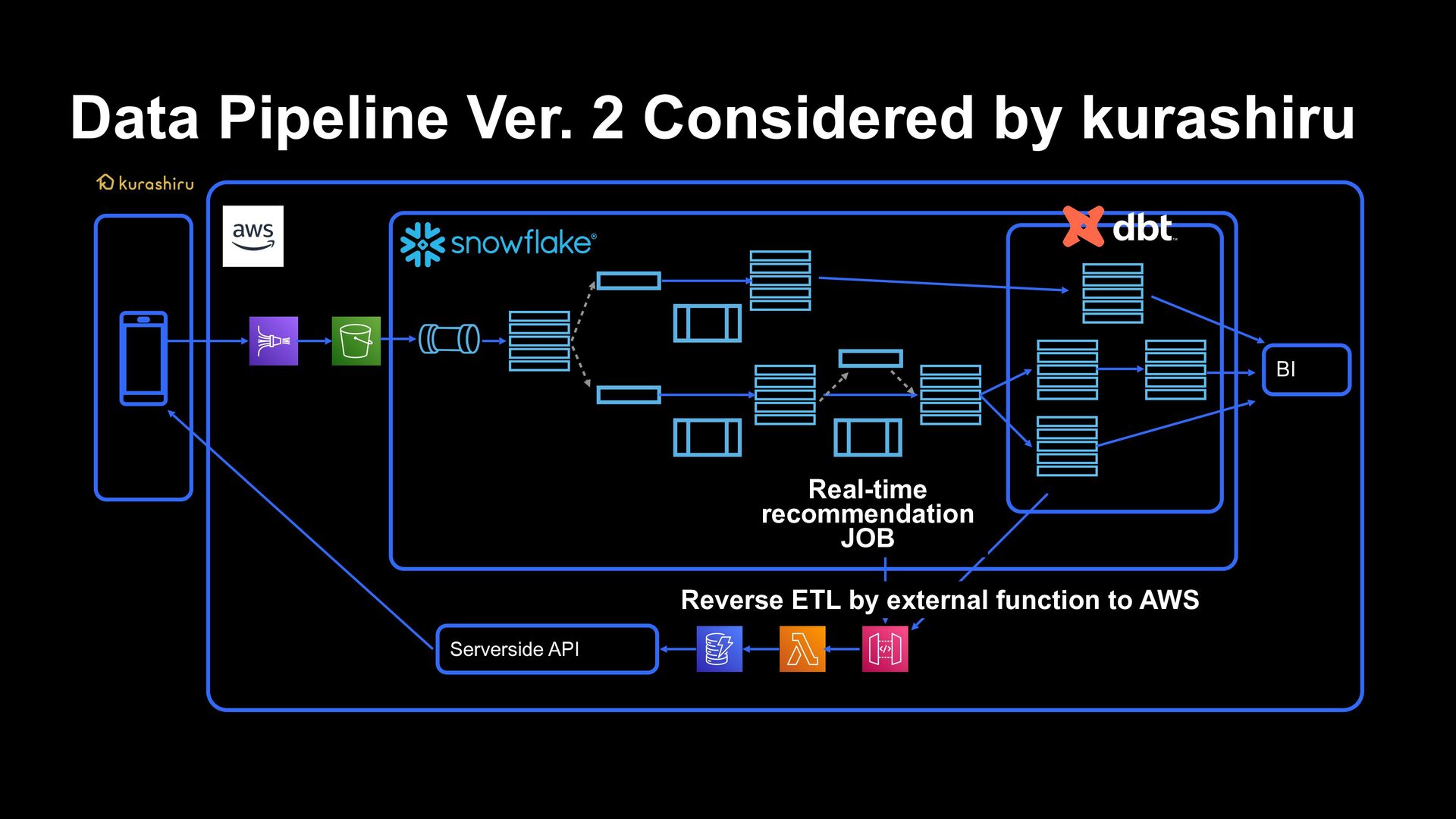
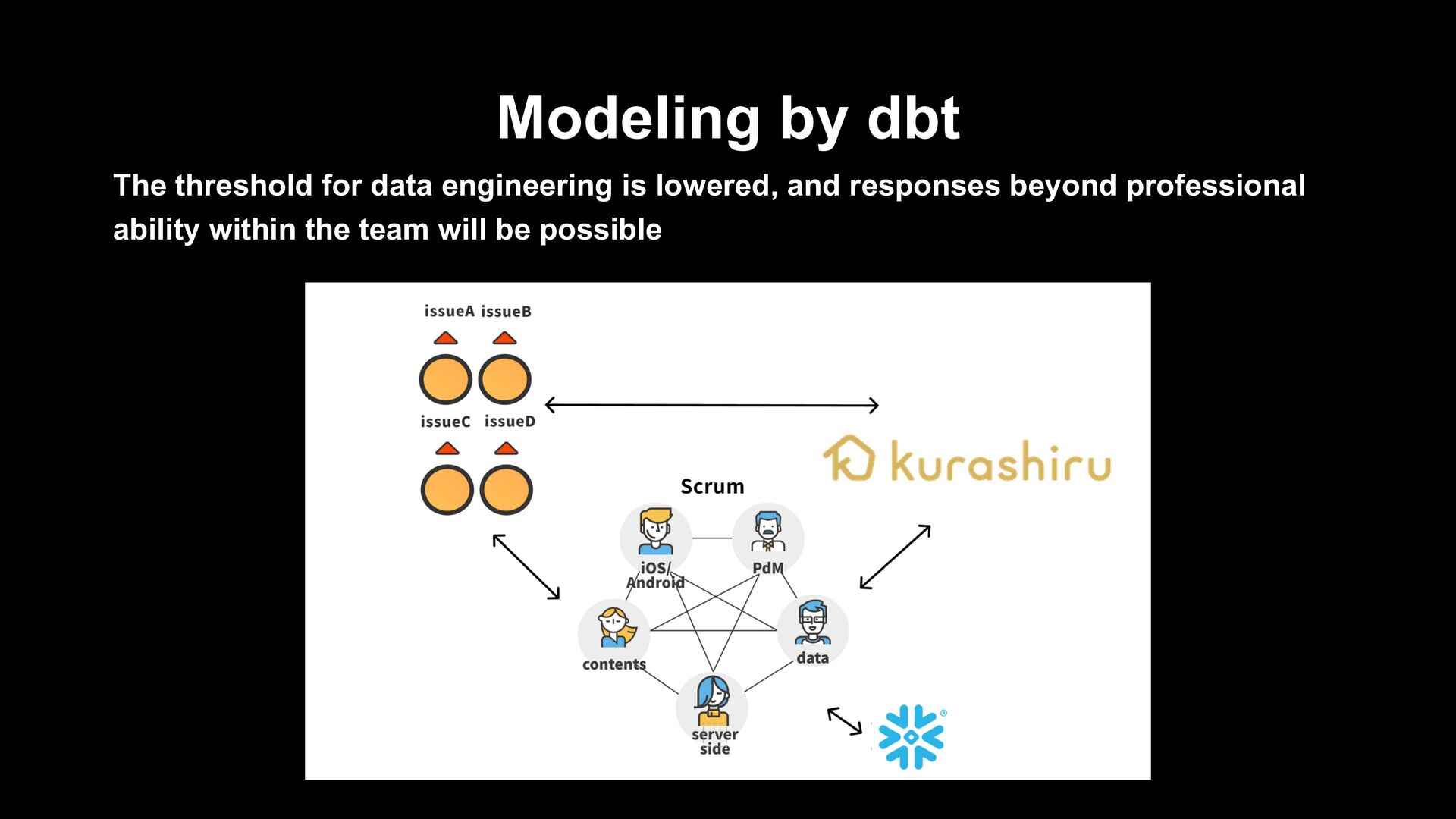
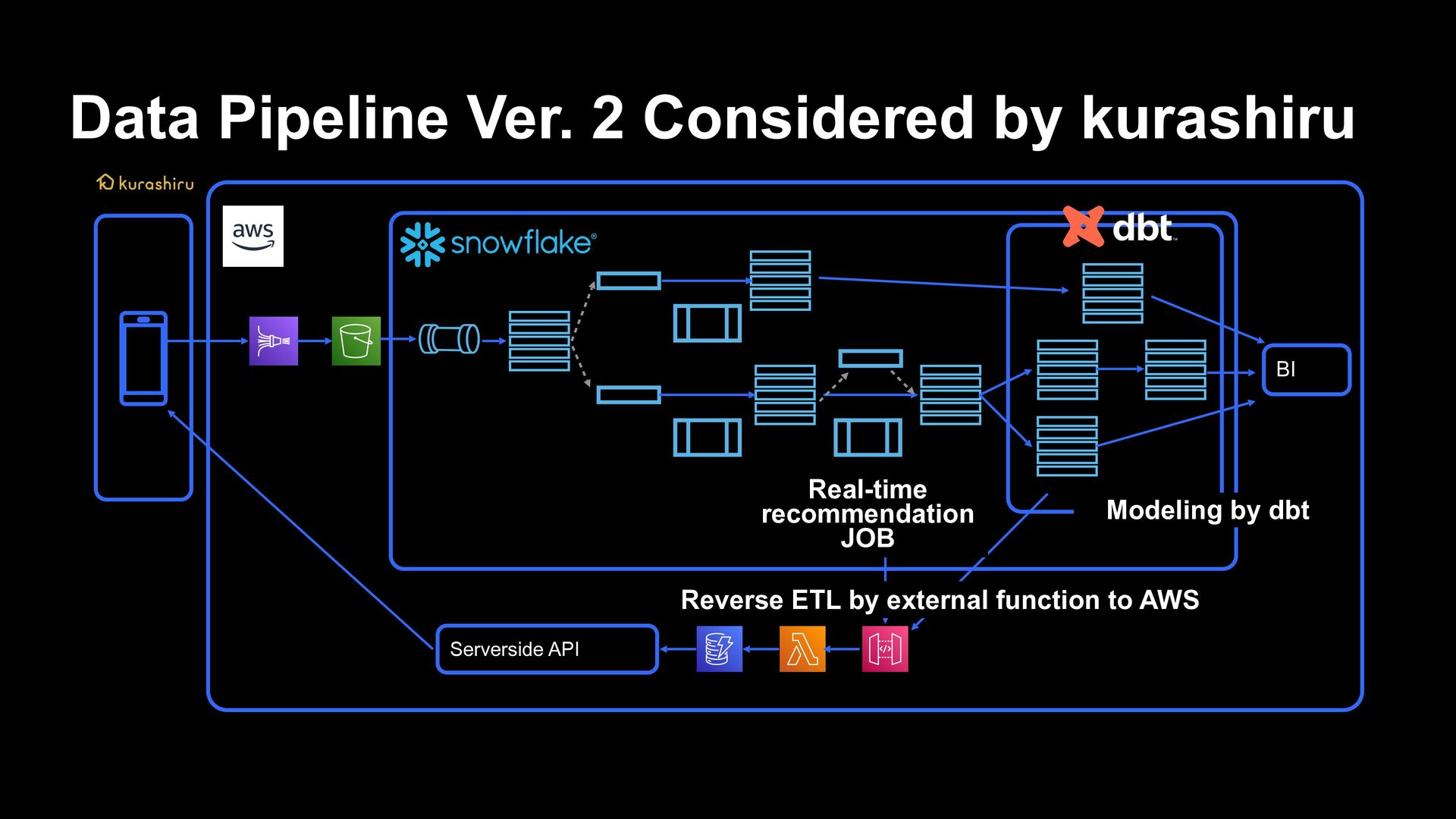
by Snowflake › Snowflake’s data pipelines › ELT processing in situations where real-time performance and cost performance are required, and closer to the staging layer › Benefits from the advantages of Snowpipe and Serverless Task › When an approach which is closer to data engineer is required › Data pipeline implemented in dbt › To be used for ETL processing from DWH layer › Data which is not required for daily/hourly processing or real-time property › Cases where it is necessary to ensure data quality The threshold for data engineering is lowered, and responses beyond professional ability within the team will be possible
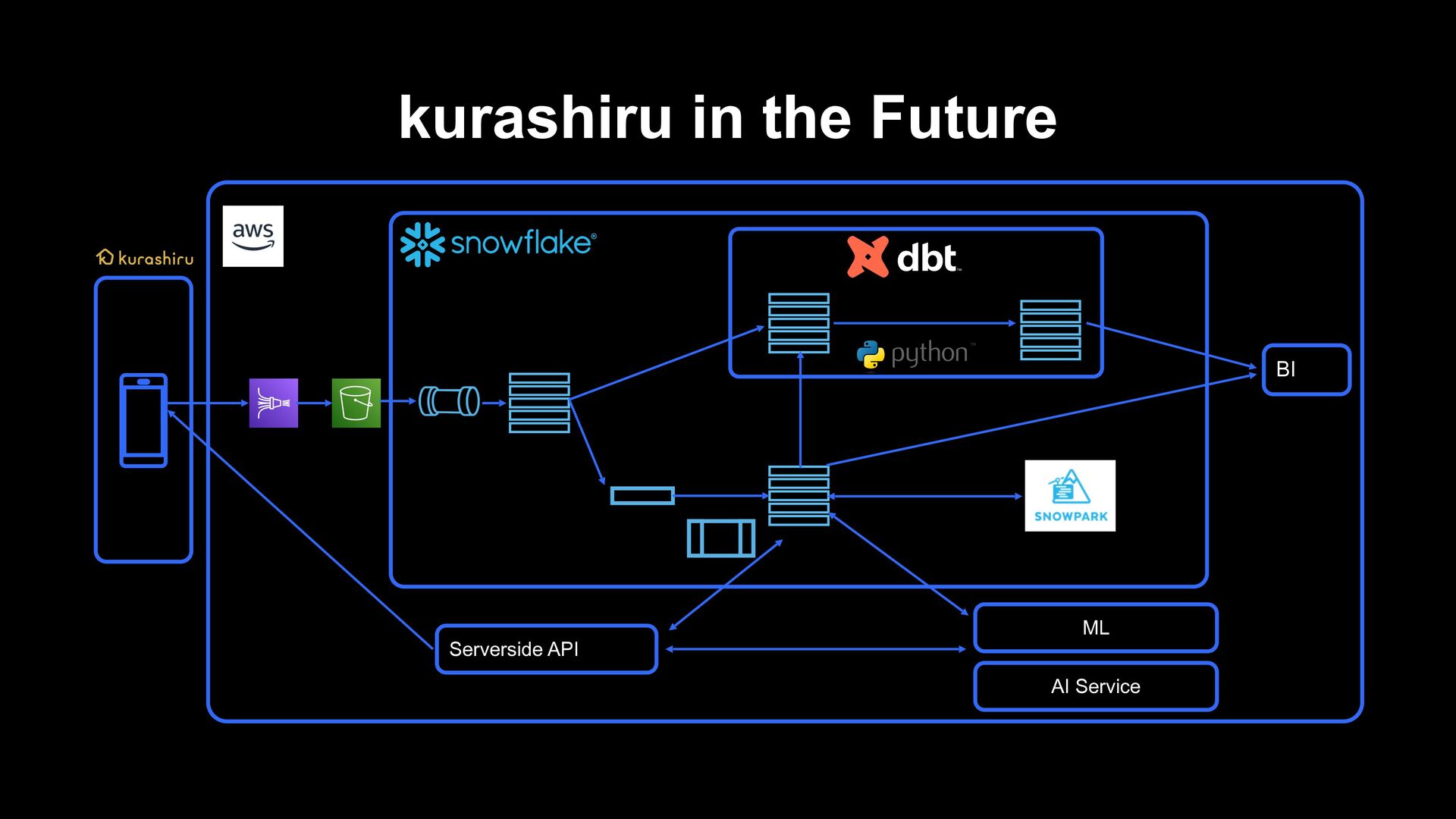
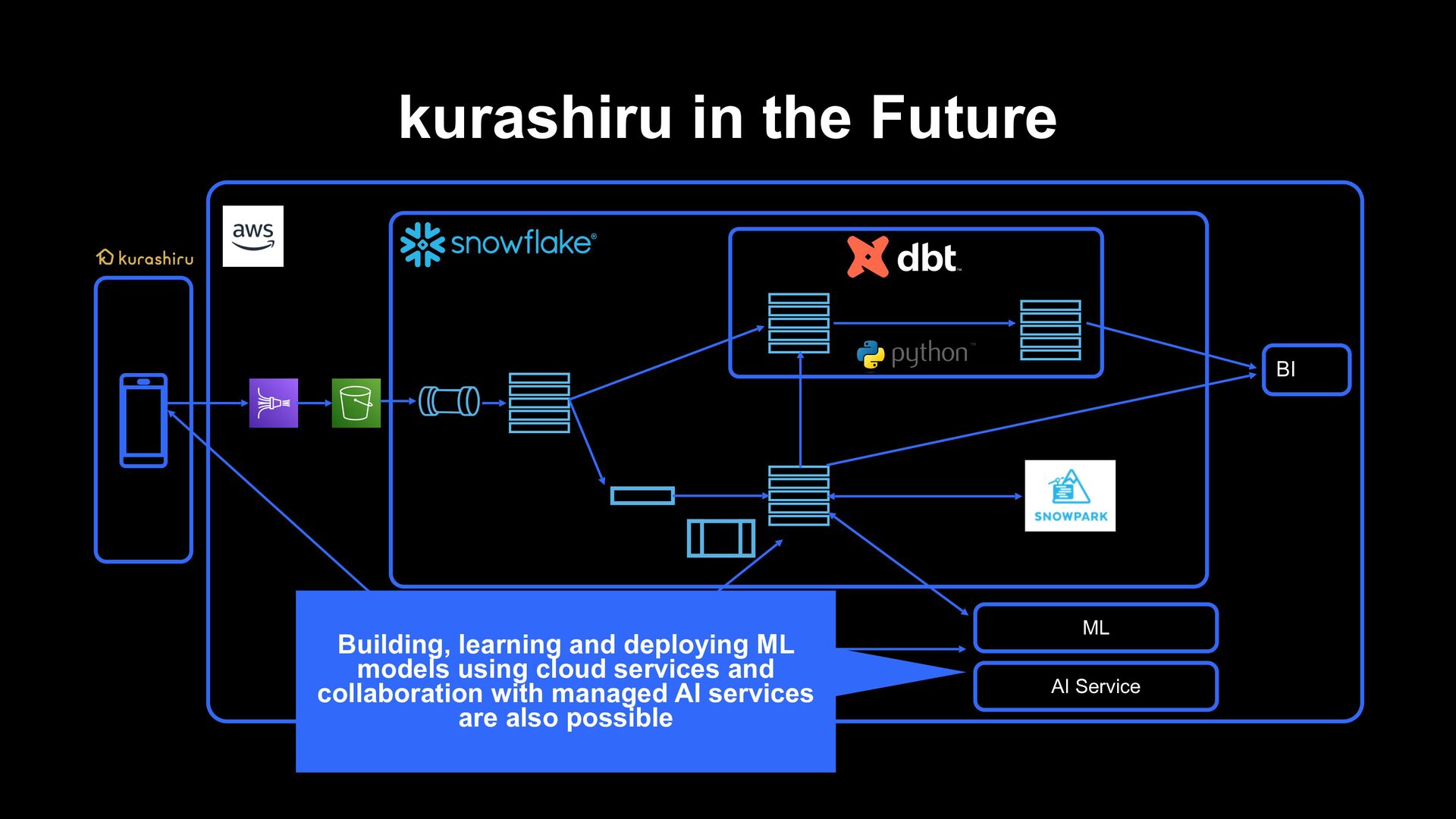
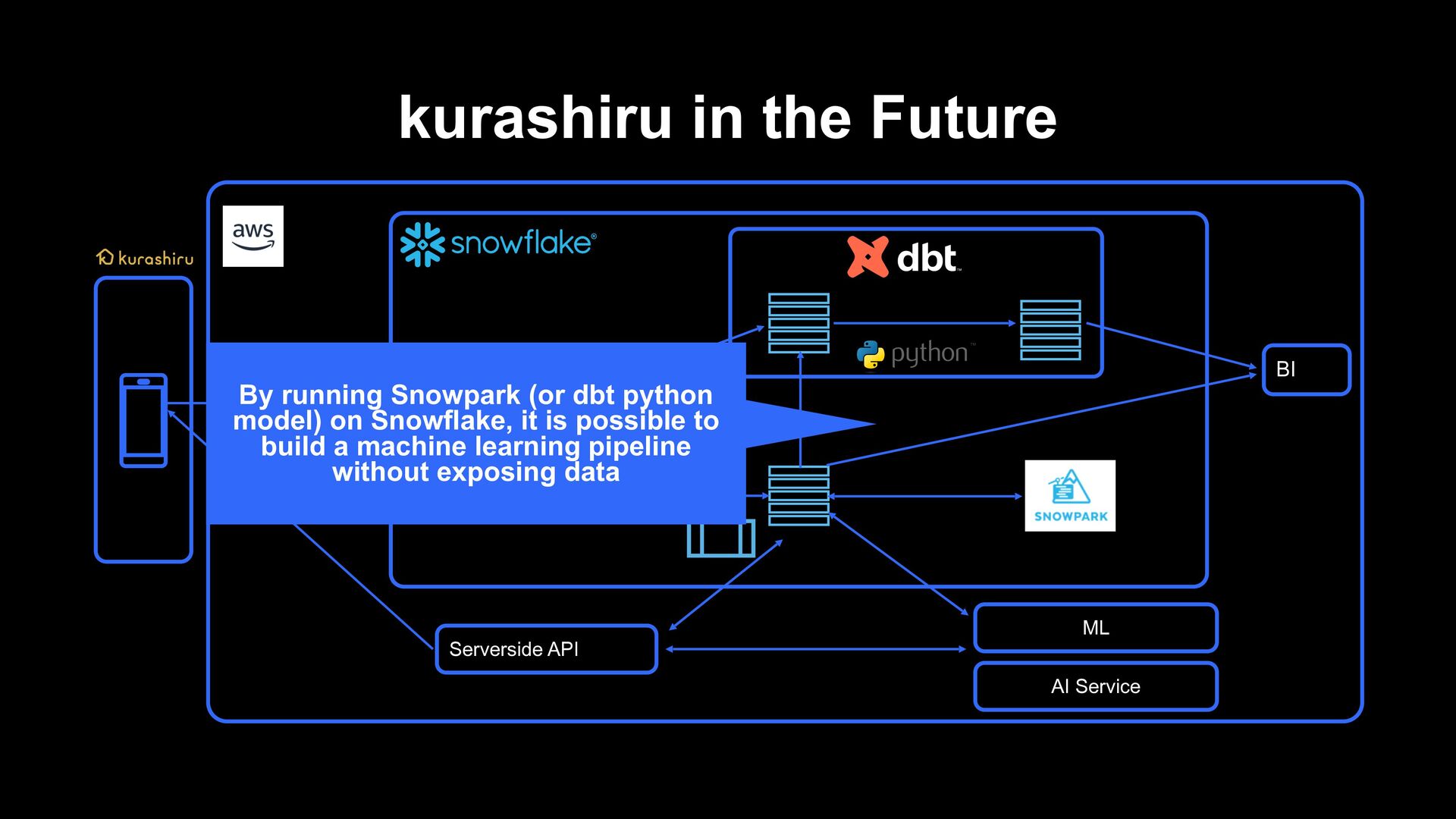
makes recommendations from user behaviors possible › Implementing processing from preprocessing to recommendation processing to reflection to applications in a pipeline on Snowflake › It is now possible to reflect to recommendations in near-real-time from user behaviors › Currently, recommendation processing is implemented based on rules › In the future, applications are expected such as API for AI Service, cloud managed service and a foundation for machine learning for performing learning/inference using Snowpark for Python
makes recommendations from user behaviors possible › Implementing processing from preprocessing to recommendation processing to reflection to applications in a pipeline on Snowflake › It is now possible to reflect to recommendations in near-real-time from user behaviors › Currently, recommendation processing is implemented based on rules › In the future, applications are expected such as API for AI Service, cloud managed service and a foundation for machine learning for performing learning/inference using Snowpark for Python Collect necessary data
makes recommendations from user behaviors possible › Implementing processing from preprocessing to recommendation processing to reflection to applications in a pipeline on Snowflake › It is now possible to reflect to recommendations in near-real-time from user behaviors › Currently, recommendation processing is implemented based on rules › In the future, applications are expected such as API for AI Service, cloud managed service and a foundation for machine learning for performing learning/inference using Snowpark for Python Execute preprocessing
makes recommendations from user behaviors possible › Implementing processing from preprocessing to recommendation processing to reflection to applications in a pipeline on Snowflake › It is now possible to reflect to recommendations in near-real-time from user behaviors › Currently, recommendation processing is implemented based on rules › In the future, applications are expected such as API for AI Service, cloud managed service and a foundation for machine learning for performing learning/inference using Snowpark for Python Recommendation processing
makes recommendations from user behaviors possible › Implementing processing from preprocessing to recommendation processing to reflection to applications in a pipeline on Snowflake › It is now possible to reflect to recommendations in near-real-time from user behaviors › Currently, recommendation processing is implemented based on rules › In the future, applications are expected such as API for AI Service, cloud managed service and a foundation for machine learning for performing learning/inference using Snowpark for Python Reflect to server
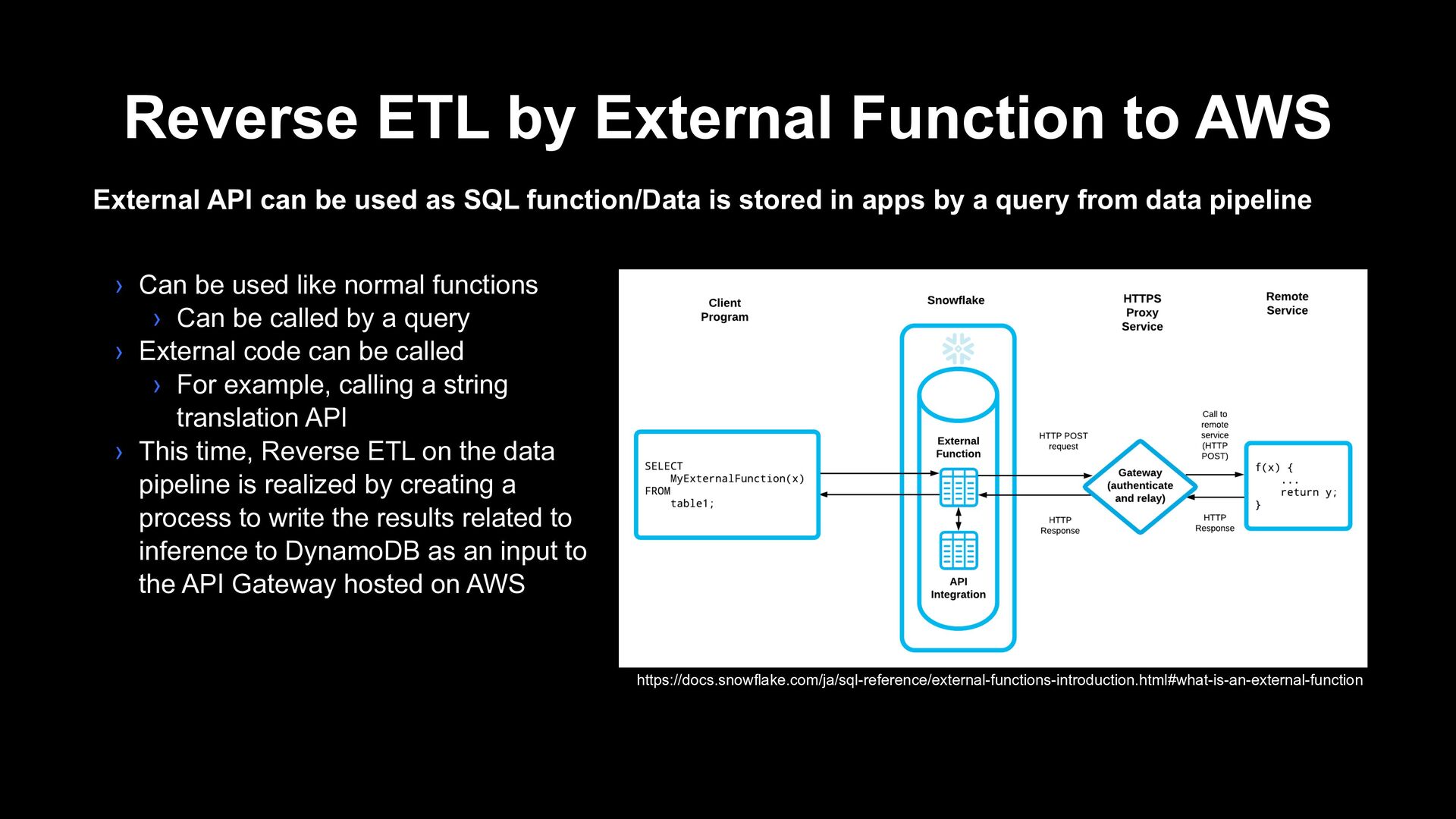
can be used as SQL function/Data is stored in apps by a query from data pipeline › Can be used like normal functions › Can be called by a query › External code can be called › For example, calling a string translation API › This time, Reverse ETL on the data pipeline is realized by creating a process to write the results related to inference to DynamoDB as an input to the API Gateway hosted on AWS
of the data pipeline which has been built up to now › We want to fulfill the purpose of recommending diverse contents in kurashiru › A phase in which we feel it is difficult to continue rule based changes › We will create a better recommendation system by developing the idea of the pipeline in the past › A managed machine learning service delivered by the cloud › AI Service by a third party › Development of a recommendation system that learns and infers on Snowflake using Snowpark and dbt python model, and building a machine learning pipeline kurashiru in the Future
increasing the diverse contents kurashiru’s Approach to Personalization We want users to enjoy kurashiru more by recommending diverse contents unique to kurashiru
increasing the diverse contents We will have a new phase which will be more fun! kurashiru’s Approach to Personalization We want users to enjoy kurashiru more by recommending diverse contents unique to kurashiru
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}