small fraction of a service and its evaluation. The part of the service that receives the change is “the canary,” and the remainder of the service is “the control.” Canarying is effectively an A/B testing process.
respond to roughly exponential increases in traffic • Canaries should start from the least practical percentage of traffic (i.e. percentage where you still get useable signal). ◦ Advanced: if you have risk dimensions other than traffic - you should adjust the stages to take those into account as well. • You should avoid location/userbase discriminations ◦ This skews your data and has the potential to degrade user experience for a particular demographic.
widely solved, however: ◦ Most books/articles on the topic heavily handwave around the evaluation part: ▪ "Make sure it looks right, then..." ▪ "If it's functioning correctly, proceed with..." ◦ Solutions that do exist are either: ▪ Proof-of-Concept/Simplistic (Pulumi canary strategies) ▪ Support only simple static metric thresholds (Flagger, Canarini) ▪ Hard to integrate outside of their specific environment (Kayenta)
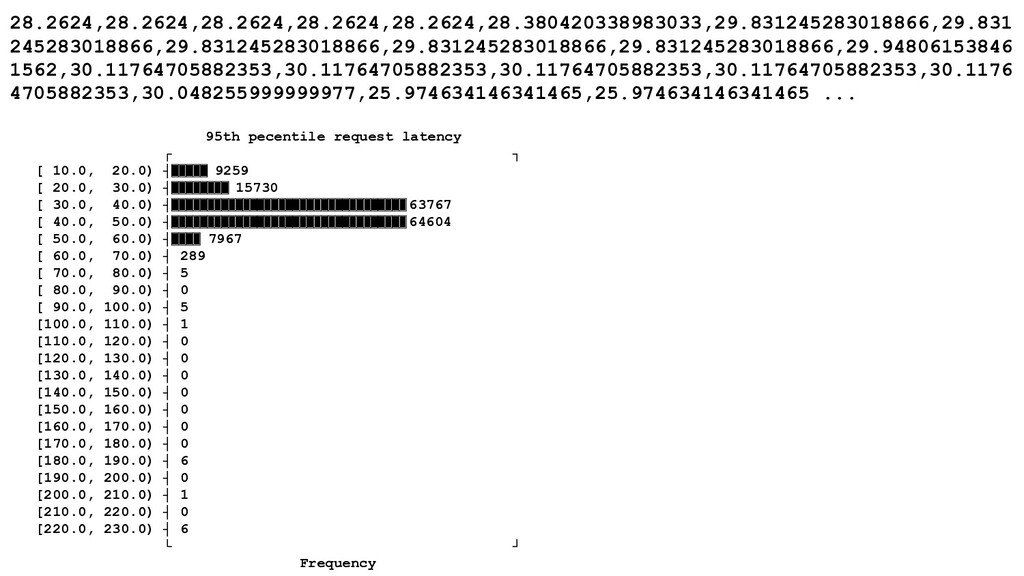
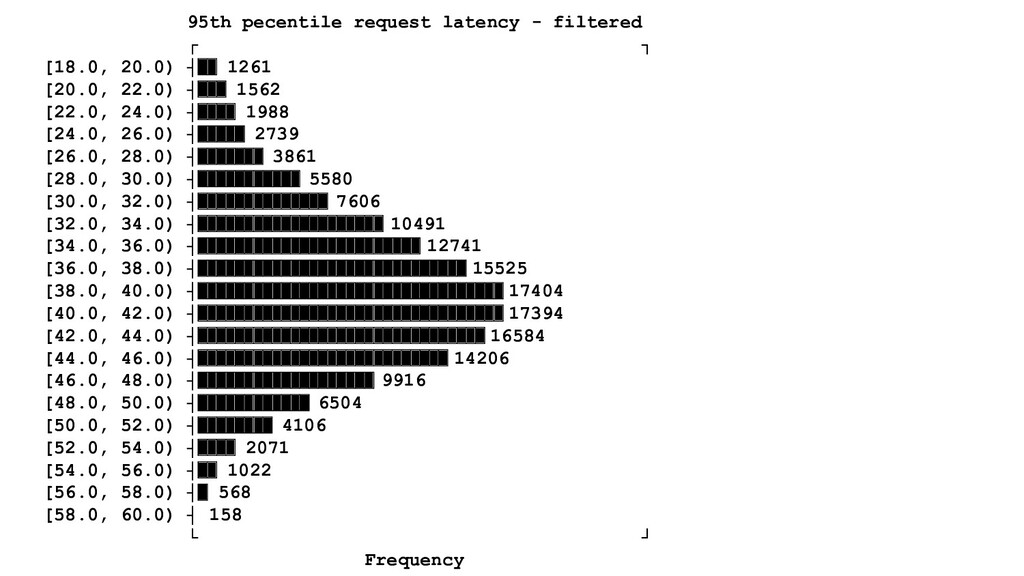
you need to have good metrics. Garbage in -> garbage out. • Metrics need to be carefully selected. Focus on customer, preventing past incidents and your dependent services. ◦ Application metrics (e.g. not "CPU is X%, Memory is Y% but "Has user been served a request?") ◦ Make sure you're using "canonical" error codes, i.e. known good vs. known valid/bad ◦ Avoid queries/metrics with grouping
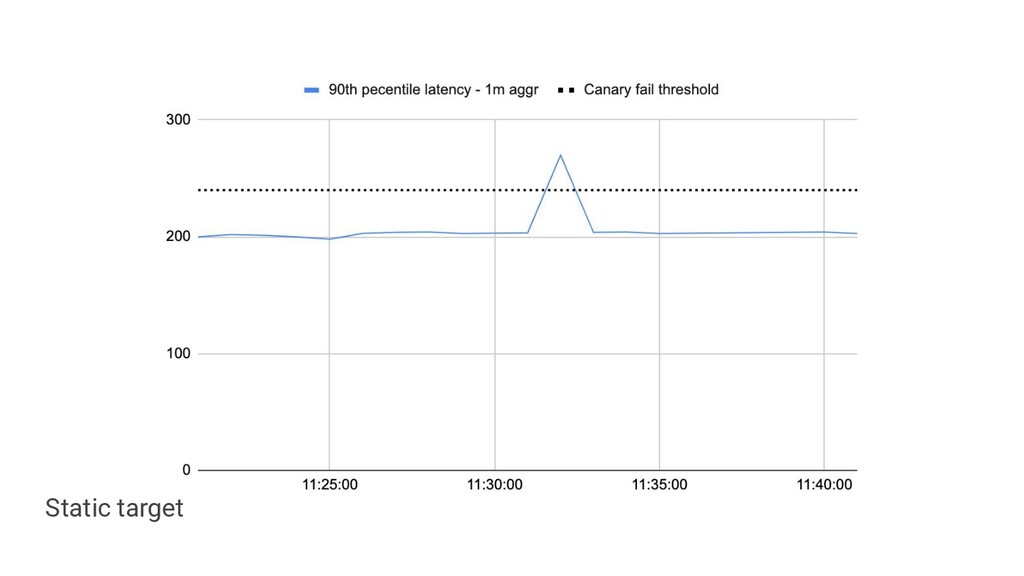
negative rate • Maintenance of static comparisons is toilsome • Doesn't catch the "common-law" SLO violations • It's easy to set arbitrary thresholds which alert on wrong things
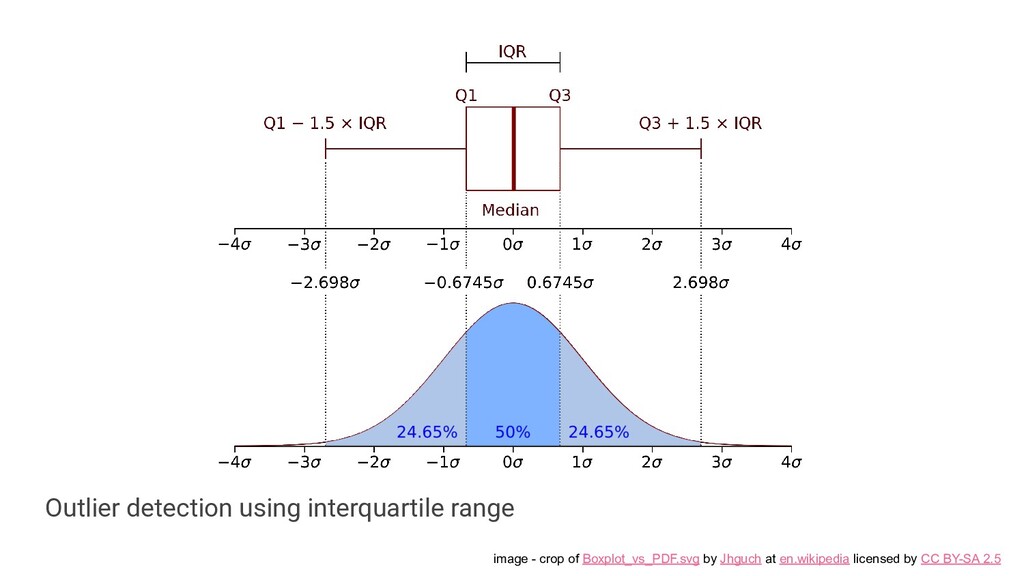
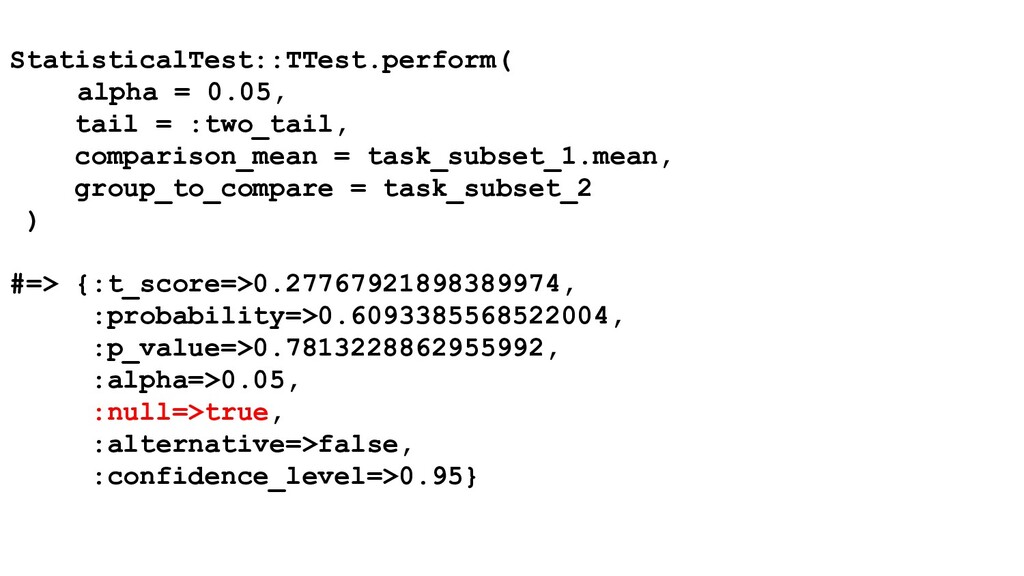
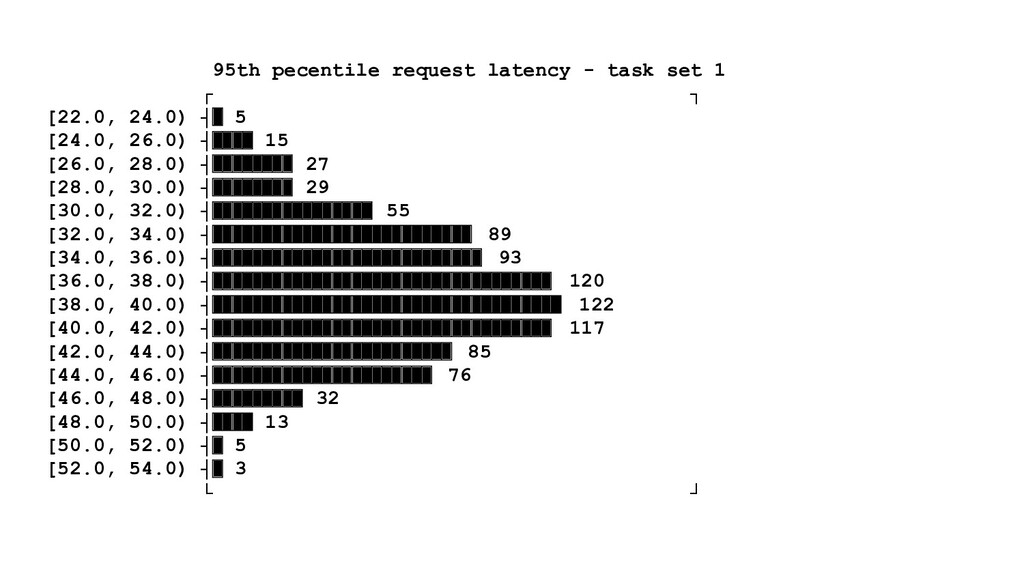
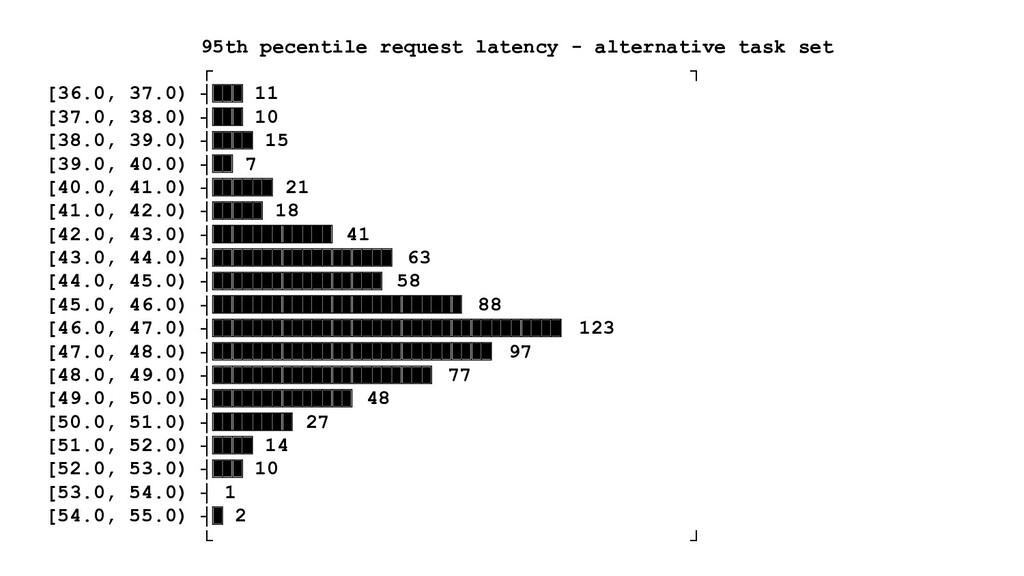
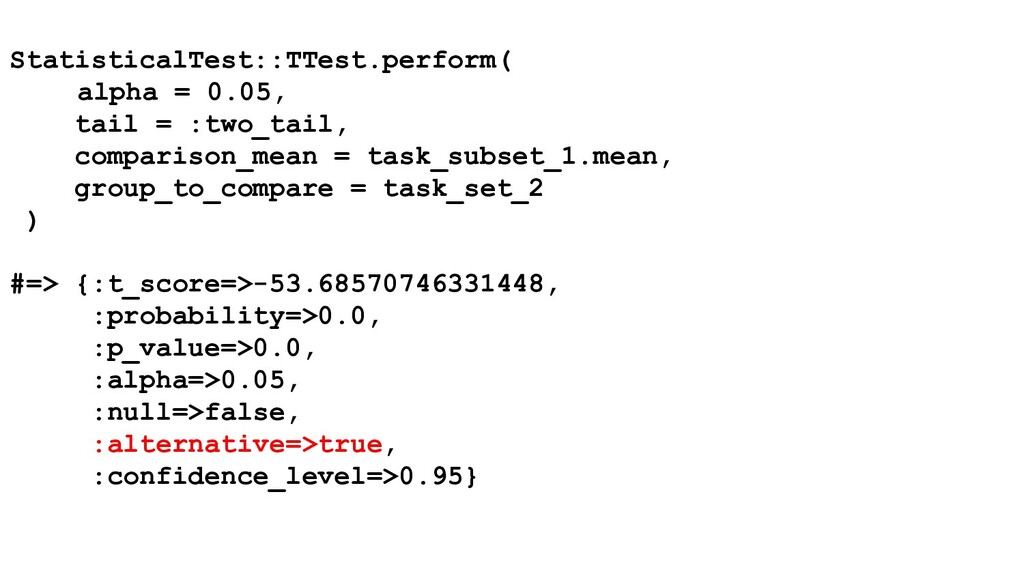
evaluate the canary metrics against the control population • Leveraging statistical analysis to: ◦ Reliably compare canary and control metrics ◦ De-noise metrics and rule out false positives ◦ Exclude random events
work in some specific cases (notably bimodal distributions) • The only existing OSS solution - Kayenta is very tightly integrated with its' parent project (Spinnaker)
work in some specific cases (notably bimodal distributions) • The only existing OSS solution - Kayenta is very tightly integrated with its' parent project (Spinnaker) • Statistics
tasks from different geographical locations or sublocations • If you use metrics from dependencies, make sure you filter out the tasks that are actually talking to your service (using trace annotations, etc.) • Do not compare task's past to its' future (do not perform canaries on 100% deployment)
"warm" tasks to cold start • Prefer more "immediate" effects (e.g. latency, error rates), have different mechanisms for handling very slow errors (like memory inefficiency)
write good playbooks, extensively document checks: ◦ What is a true false positive? ◦ What do the coefficients mean ◦ Remember: garbage in -> garbage out • Canary checks maintenance should be a shared responsibility
that an estimate taken from our mean extends // to a similar-looking population. Generally, higher significance // level means lower amount of false positives, but a higher chance // to miss something. In latency, we need a pretty strict threshold // in order to be confident, whereas in error rates for a highly // reliable service, we want a higher pvalue threshold to catch // issues since we're certain any amount of deviation is // significant. significance_level = 0.01
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
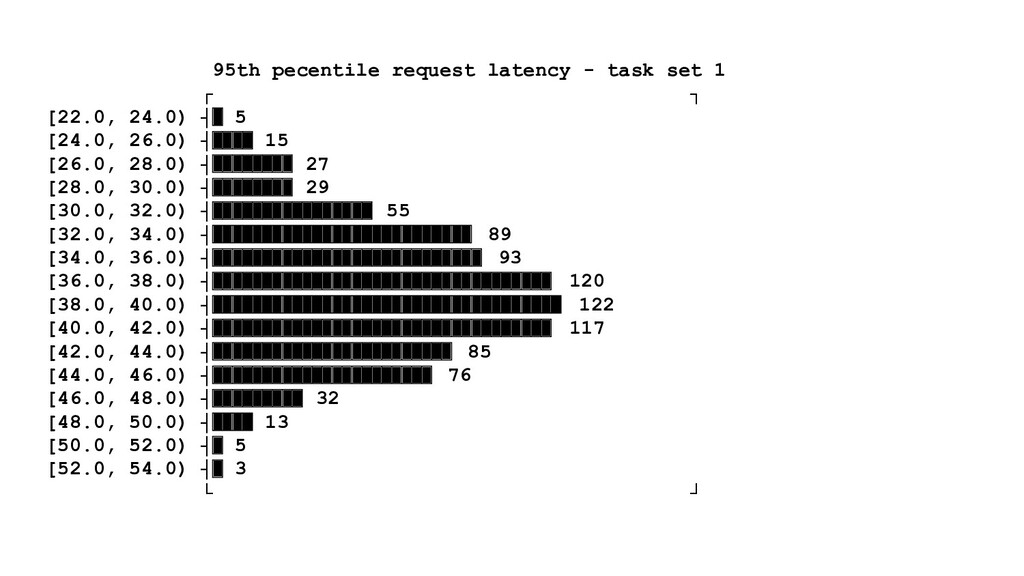{kind=link}
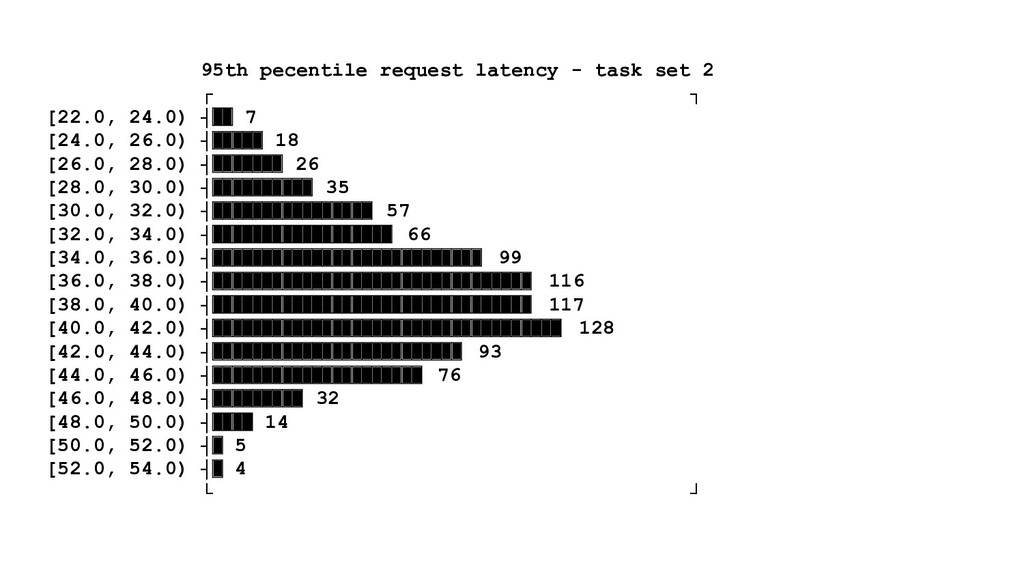{kind=link}
{kind=link}
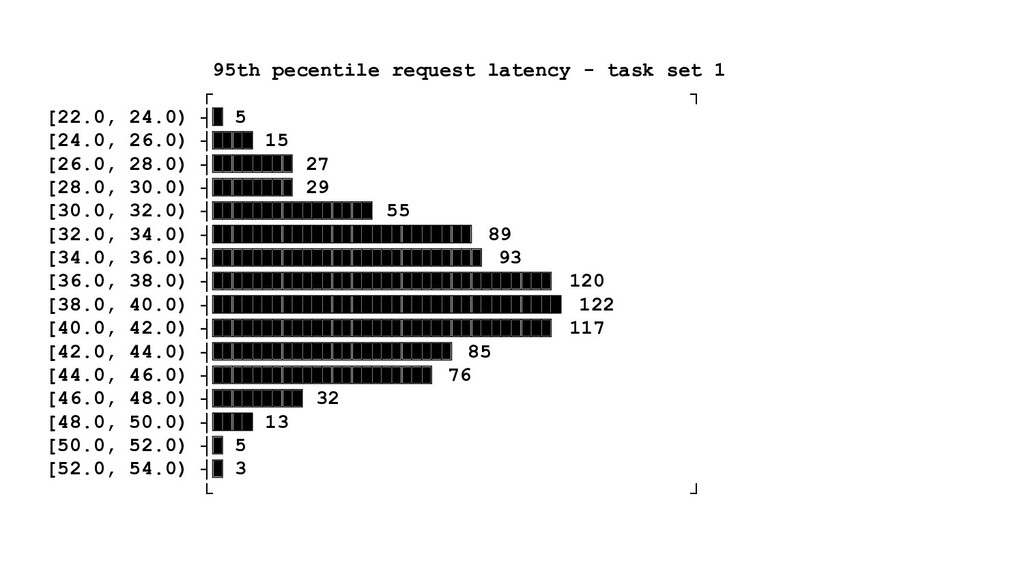{kind=link}
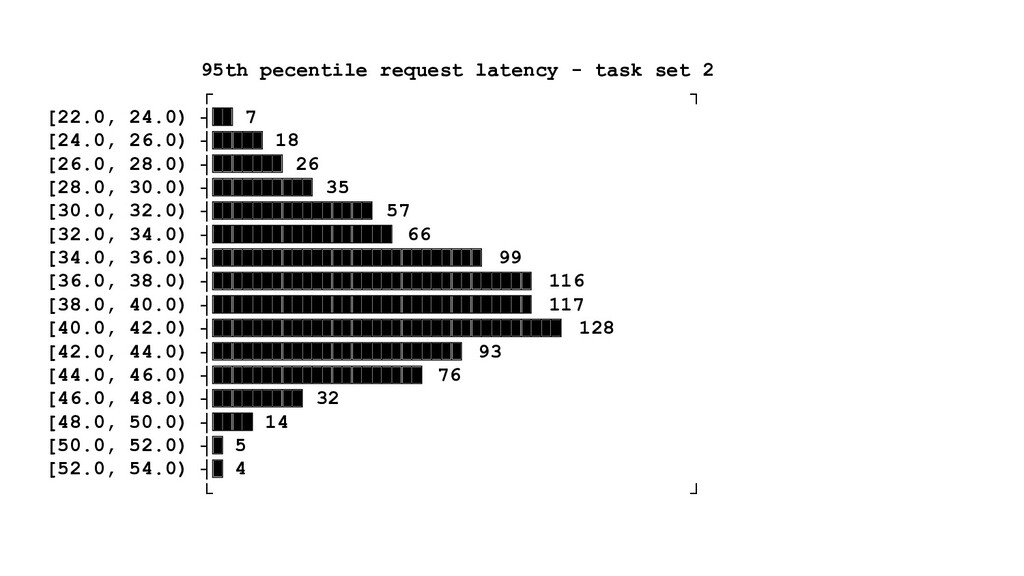{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}