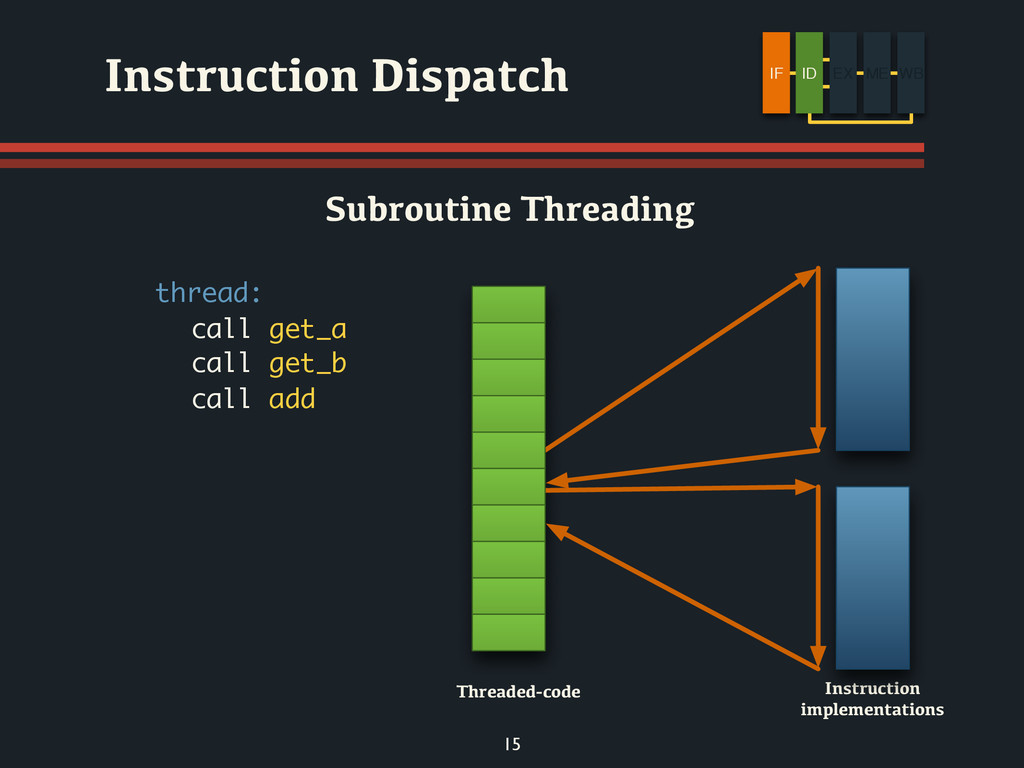
*thread++; /*...*/ 13 Instruction Dispatch Threaded-code Instruction implementations Direct Threading[1] [1]: James R. Bell, Threaded Code, CACM, 1973 IF ID EX ME WB
5:add 6:set a 0 0 1 push 1 pop 0 0 Bytecode Stack Stack ops 2 stack ops Stack caching[1] : keep top-of-stack in registers 1 1 1 2 2 4 1 8 9 [1]: M. Anton Ertl, Stack Caching for Interpreters, PLDI 1995 IF ID EX ME WB
b 3:add 4:set c 1:add c a b With register-based architecture: -35% native instruction count[1] +45% code size[1] [1]: Yunhe Shi et al., Virtual Machine Showdown: Stack versus registers, TACO 2008 IF ID EX ME WB
} else if (String && String) return a.concat(b); } else if (Num && String) return a.toString().concat(b); } else if (String && Num) return a.concat(b.toString()); } ... Runtime overhead of Dynamic Typing Implementation of : add IF ID EX ME WB
Instruction [1]: S. Brunthaler, Inline Caching Meets Quickening, ECOOP 2010 IF ID EX ME WB Performing the Computation get a get b add get a get b nadd generic add number add guard To fallback
1961 [2]: A. Goldberg & D. Robson, Smalltalk-80: the Language and Its Implementation 1983 • Meta-Circular virtual machine is written in the same language it implements • Original idea: meta-circular evaluator in LISP[1] • Smalltalk: the blue book reference implementation[2]
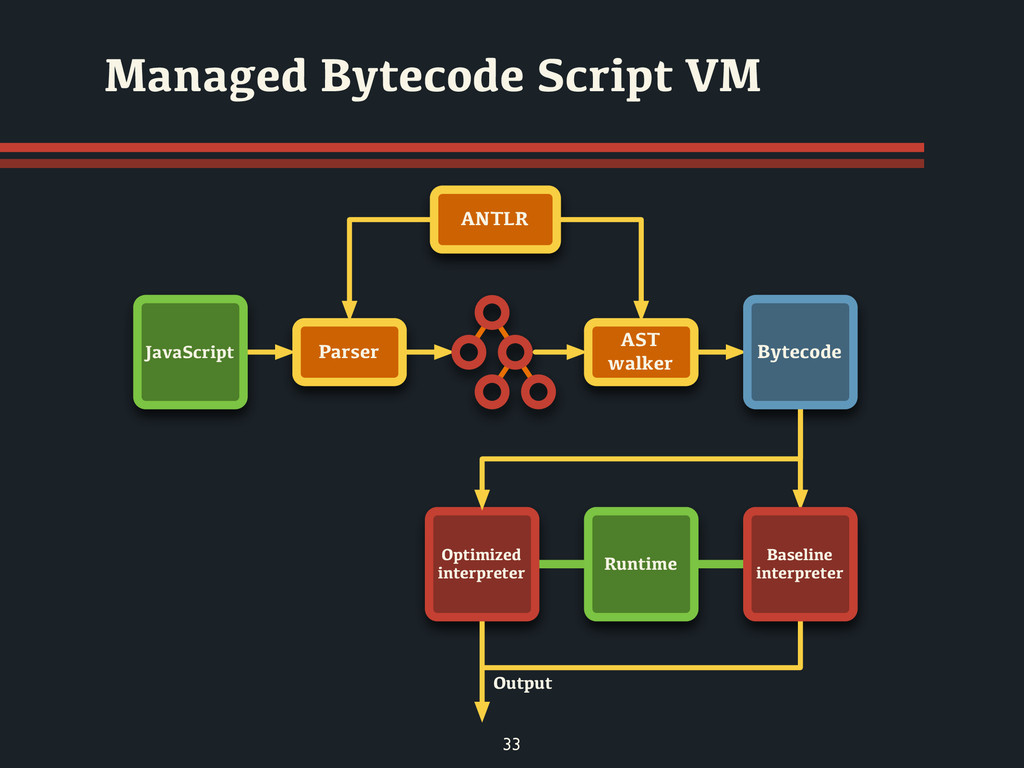
written in Java from Mozilla Foundation • Compile JavaScript source to Java classfile • Interpretation mode is included (AST) MBS Maxine VM Rhino Maxine VM
intermediate representation •Tracing PyPy’s interpreter[2] Running Python interpreter on Python tracing JIT Trace hot code in work load Modular VM: Related Work [1]: Chris Lattner and Vikram Adve, LLVM: A Compilation Framework for Lifelong Program Analysis & Transformation, CGO 2004 [2]: C.F. Bolz et al., Tracing the Meta-Level: PyPy’s Tracing JIT Compiler, ICOOOLPS
object layout Efficient resizable object layout[1] Memory Optimization on Maxine [1]: C. Chamers et al., An Efficient Implementation of Self, a Dynamically-Typed Object-Oriented Language Based on Prototypes, OOPSLA 1989
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![11 Cost of interpretation[1] Instruction dispatch Operand access Performing the](https://files.speakerdeck.com/presentations/da6f87a02a7f013264af0601935acf54/slide_10.jpg){kind=link}
![for (;;) switch(program[ip++]){ /*...*/ case add: sp[1]=sp[0]+sp[1]; sp++; break; /*...*/](https://files.speakerdeck.com/presentations/da6f87a02a7f013264af0601935acf54/slide_11.jpg){kind=link}
![Inst thread[]= {&add, &pop...}; goto *thread++; add: sp[1]=sp[0]+sp[1]; sp++; goto](https://files.speakerdeck.com/presentations/da6f87a02a7f013264af0601935acf54/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Quickening[1] 21 Instruction Stream Generic Instruction Quickened Instruction Stream Specialized](https://files.speakerdeck.com/presentations/da6f87a02a7f013264af0601935acf54/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![27 Meta-Circular VM [1]: John McCarthy, LISP 1.5 Programmer’s Manual](https://files.speakerdeck.com/presentations/da6f87a02a7f013264af0601935acf54/slide_26.jpg){kind=link}
![28 Meta-Circular JVM Conventional JVM Maxine VM[1] [1]: B. Titzer](https://files.speakerdeck.com/presentations/da6f87a02a7f013264af0601935acf54/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![41 •LLVM[1] Framework for building optimizing compilers Persistent low level](https://files.speakerdeck.com/presentations/da6f87a02a7f013264af0601935acf54/slide_40.jpg){kind=link}
{kind=link}