Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
知ろう!使おう!HDF5ファイル!/pycon-jp-2019-talk
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
thinkAmi
September 17, 2019
Programming
11k
5
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
知ろう!使おう!HDF5ファイル!/pycon-jp-2019-talk
PyCon JP 2019の発表資料です
thinkAmi
September 17, 2019
More Decks by thinkAmi
See All by thinkAmi
Djangoでのメール送信 - 設定からテストまで/djangocongress-jp-2019-talk
thinkami
1
13k
Django・WSGIミドルウェア入門/django-congress-jp-2018-talk
thinkami
4
5.6k
自分のための機械学習をしてみた話
thinkami
0
690
Xamarinで作るAndroid Wearアプリ
thinkami
1
2.8k
FluentMigratorでDBマイグレーション
thinkami
0
2.3k
デプロイボタンを使ってみた
thinkami
0
1.1k
Vagrant + Berkshelf でお手軽写経環境構築
thinkami
1
1.4k
Twilio入門
thinkami
0
1.7k
おひとりさま環境でのChef-solo使用例
thinkami
2
1.5k
Other Decks in Programming
See All in Programming
2年かけて Deno に DOMMatrix を実装した話 / How I implemented DOMMatrix in Deno over two years
petamoriken
0
110
ルールを書いて終わらせないハーネスエンジニアリング
yug1224
4
1.7k
AIが無かった頃の素敵な出会いの話
codmoninc
1
210
JAWS-UG横浜 #102 AWSサ終供養LT会 成仏できない AWS サービスたち 〜本日、三体供養します〜
maroon1st
0
230
全PRの83%がAIレビューだけでマージできるようになった開発組織はその後どうなったか
athug
0
300
吝嗇家のためのAI活用 / AI development for miser - ChatGPT + Issue Driven Development
tooppoo
0
190
ビデオ通話が繋がる0.2秒で何が起きているのか
supurazako
2
150
共通化で考えるべきは、実装より公開する型だった
codeegg
0
270
ITヒヤリハットを整理してみた ~ライフサイクルと原因から考える再発防止策~
koukimiura
1
110
AI時代のPHPer生存戦略 ~「言語、もうなんでもよくない?」に本気で向き合う~
vivion
0
150
5分で問診!Composer セキュリティ健康診断
codmoninc
0
580
はてなアカウント基盤 State of the Union
cockscomb
1
1.3k
Featured
See All Featured
Making the Leap to Tech Lead
cromwellryan
135
10k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
270
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.9k
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
470
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
We Are The Robots
honzajavorek
0
280
HDC tutorial
michielstock
2
750
New Earth Scene 8
popppiees
3
2.4k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
230
The Mindset for Success: Future Career Progression
greggifford
PRO
0
430
Transcript
知ろう!使おう!HDF5 ファイル! PyCon JP 2019 talk 2019/9/17 @thinkAmi
お前誰よ / Who are you ? @thinkAmi Python/Django/Web アプリケーションエンジニア Blog
:メモ的な思考的な (http://thinkami.hatenablog.com/) ( 株) 日本システム技研 PyCon JP 2019 Gold Sponsor (2016-18 Silver Sponsor) ギークラボ長野 Python Boot Camp in 長野 みんなのPython 勉強会 in 長野
知ろう!使おう!HDF5 ファイル! PyCon JP 2019 talk 2019/9/17 @thinkAmi
HDF5 ファイルを見たことがある方 (*.h5 / *.hdf5)
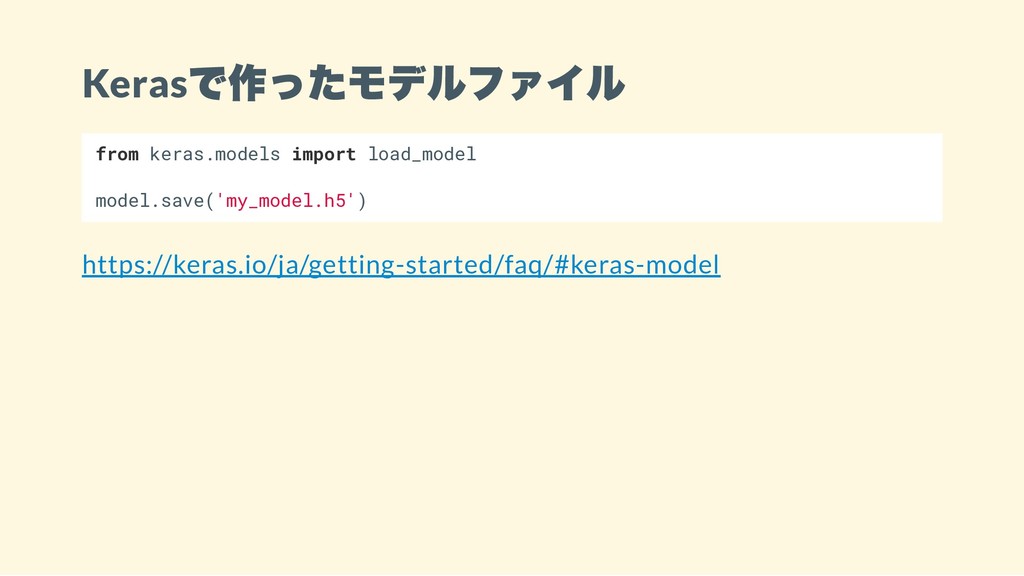
Keras で作ったモデルファイル from keras.models import load_model model.save('my_model.h5') https://keras.io/ja/getting-started/faq/#keras-model
クラウド 風力発電: AWS でのオープンデータ | Amazon Web Services ブログ https://aws.amazon.com/jp/blogs/news/power-from-wind-open-data-
on-aws/ 基礎的な AWS のサービスと Hierarchical Data (HDF) 50 テラバイト
話すこと 知ろう! 見よう! 使おう! ローカル、サーバー、そしてクラウドへ バージョンアップ!
話さないこと HDF5 ファイルとNumPy
おしらせ ハッシュタグ:#pyconjp #pyconjp_5 ソースコードはGitHub に公開済 https://github.com/thinkAmi/PyCon_JP_2019_talk スペースの関係上、スライド上は一部省略 スライドも公開 https://speakerdeck.com/thinkami/pycon-jp-2019-talk 「HDF5
ファイル」の発音
1. 知ろう!
HDF5 とは HDF 5
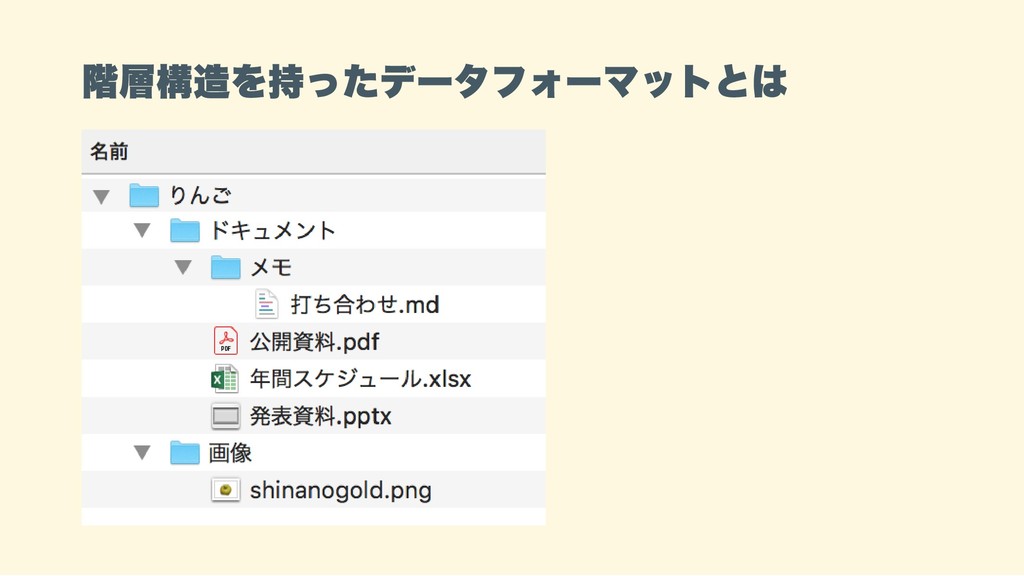
HDF 5 HDF Hierarchical Data Format 階層構造を持ったデータフォーマット The HDF Group
がサポート https://www.hdfgroup.org/ HDF5 ファイルの開発を進めるNPO 団体 米国立スーパーコンピュータ応用研究所 (NCSA: National Center for Supercomputing Applications) 発
階層構造を持ったデータフォーマットとは
HDF 5 5 現在のバージョン 過去にはバージョン4 もあり バージョン4 と5 の間では、互換性なし Python
のライブラリも異なる
HDF5 が使われている領域 https://www.hdfgroup.org/
事例 JAXA のG-Portal での公開データ 地球観測衛星データ提供システム https://gportal.jaxa.jp/gpr/index/index 降水量、海面水温、海上風速、...
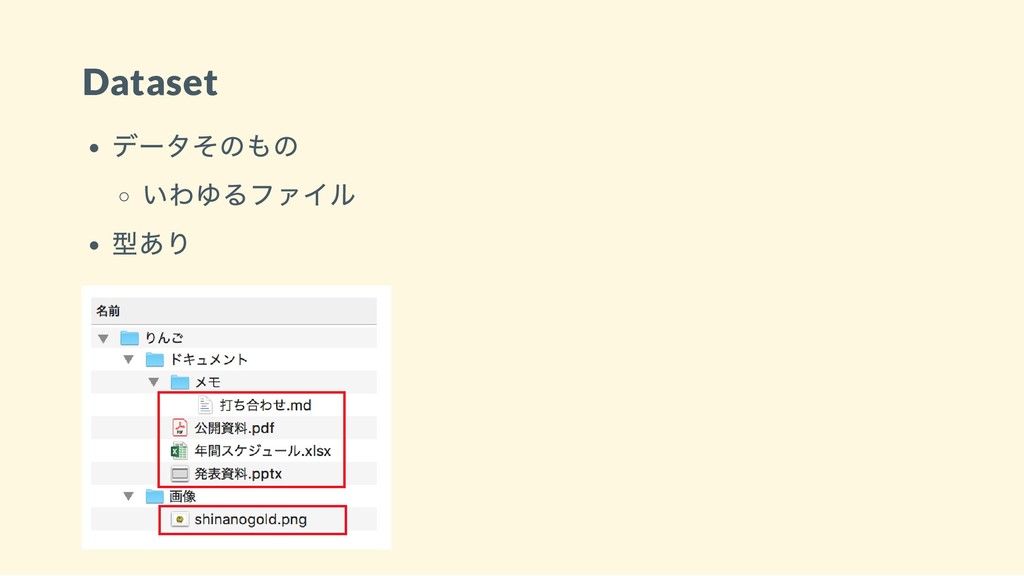
HDF5 ファイルの構造 主なもの Dataset Group Attribute
Dataset データそのもの いわゆるファイル 型あり
Group Dataset をまとめて入れておくもの いわゆるディレクトリ Group の中にGroup も入れられる
Attribute Dataset やGroup に紐付ける注釈のようなもの いわゆるプロパティ
HDF5 ファイルと言語バインディング 公式 C, Fortran, C++, Java, P/Invoke サードパーティ Python,
R, Julia, 他 参考:HDF5 Language Bindings https://portal.hdfgroup.org/display/HDF5/HDF5+Language+Bind ings
HDF5 ファイルとプラットフォーム クロスプラットフォーム Windows, Mac, Linux
Android やiOS で使えるの? 公式サポートなし サードパーティとして、Swift やpure Java で書かれたものあり https://github.com/alejandro-isaza/HDF5Kit https://github.com/jamesmudd/jhdf
2. 見よう!
見るためのツール ViTables HDFView
ViTables とは PyTables ファミリー HDF5 の他、PyTables データをサポート 公式ページ http://vitables.org/
HDFView とは The HDF Group が提供しているビューワー & エディタ Open JDK
11 で動作 HDF5 の他、HDF4 もサポート 公式ページ https://portal.hdfgroup.org/display/HDFVIEW/HDFView
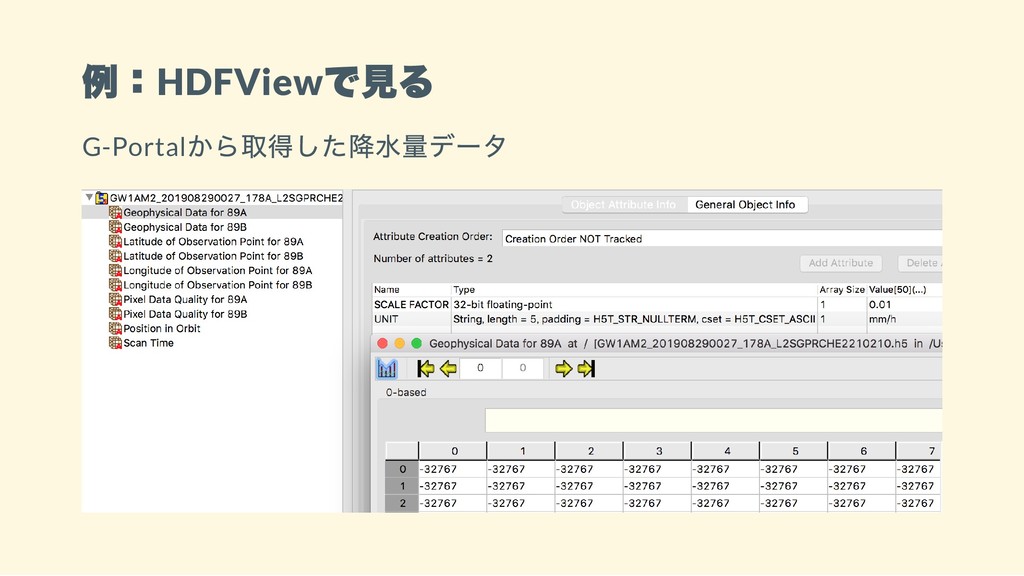
例:HDFView で見る G-Portal から取得した降水量データ
3. 使おう!
Python ライブラリ h5py PyTables Pandas では、HDF5 ファイルとのI/F にPyTables を使用 https://pandas.pydata.org/pandas-
docs/stable/user_guide/io.html#hdf5-pytables
ライブラリの比較 名前 Layer 特徴 h5py 低 HDF5 API を忠実に再現 PyTables
高 HDF5 ファイルを拡張、テーブル概念の追加やパフ ォーマンス改善等を実装。よりデータベースに近い 詳細については、各ライブラリのFAQ を参照 http://docs.h5py.org/en/stable/faq.html#what-s-the-difference- between-h5py-and-pytables http://www.pytables.org/FAQ.html#how-does-pytables-compare- with-the-h5py-project
h5py とPyTables のデータ互換性 例:PyTables で作った文字列データを、h5py で読む # PyTables でファイルを作る with
tables.open_file(filepath, 'w') as f: dataset = f.create_vlarray('/', 'str_data', atom=VLUnicodeAtom()) dataset.append(' シナノゴールド') # PyTables で開く with tables.open_file(filepath, 'r') as f: node = f.get_node(where='/', name='str_data') for row in node.iterrows(): print(row) # => シナノゴールド # h5py で開く with h5py.File(filepath, mode='r') as f: dataset = f['str_data'] print(dataset[0]) # => [12471 12490 12494 12468 12540 12523 12489]
HDF5 ファイルの操作 h5py を使った操作例 作成 読込 検索 圧縮 バージョン Python
3.7.4 h5py 2.10.0 PyTables については、GitHub 参照
今回作成するHDF5 ファイルのイメージ
作成
HDF5 ファイルを開く 書込・読込は、 mode で切り替え import h5py output = OUTPUT_DIR.joinpath('use_h5py.h5')
# with を抜けると、書き込まれる with h5py.File(output, mode='w') as file: # 処理
Group 作成 group = file.create_group('apple')
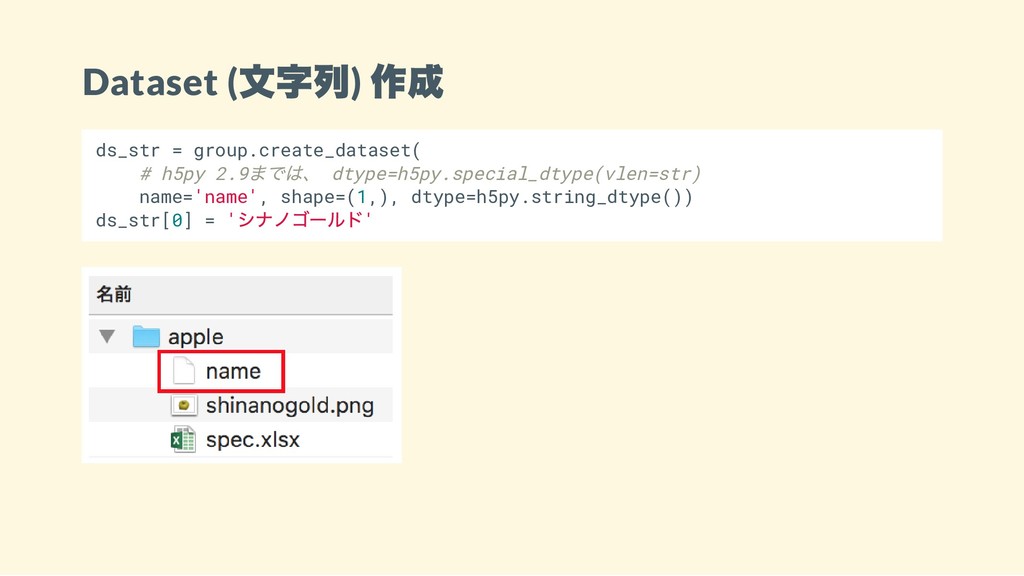
Dataset ( 文字列) 作成 ds_str = group.create_dataset( # h5py 2.9
までは、 dtype=h5py.special_dtype(vlen=str) name='name', shape=(1,), dtype=h5py.string_dtype()) ds_str[0] = ' シナノゴールド'
Dataset ( 画像) 作成 # 画像を読み込み image_path = INPUT_DIR.joinpath('shinanogold.png') with
image_path.open(mode='rb') as img: image_binary = img.read() # NumPy 配列化 image_data = np.frombuffer(image_binary, dtype='uint8') # バイナリの型定義 TYPE_OF_BINARY = h5py.special_dtype(vlen=np.dtype('uint8')) # 画像を設定 ds_img = group.create_dataset( 'image', image_data.shape, dtype=TYPE_OF_BINARY) ds_img[0] = image_data
Dataset (Excel) 作成 画像と変わらない excel_path = INPUT_DIR.joinpath('mybook.xlsx') with excel_path.open(mode='rb') as
excel: excel_binary = excel.read() # np.frombuffer() を使うところだけが違う excel_data = np.frombuffer(excel_binary, dtype='uint8') ds_excel = group.create_dataset( 'spec', excel_data.shape, dtype=TYPE_OF_BINARY) ds_excel[0] = excel_data
Attribute 作成 Group, Dataset のどちらにも作成可能 # Group のAttribute group.attrs['title'] =
' りんご情報' # Dataset のAttribute ds_str.attrs['color'] = ' 黄色系'
読込
Dataset ( 文字列) の読込 Group/Dataset な形で、Dataset を取得 dataset = file['apple/name']
print(dataset[0]) # => シナノゴールド
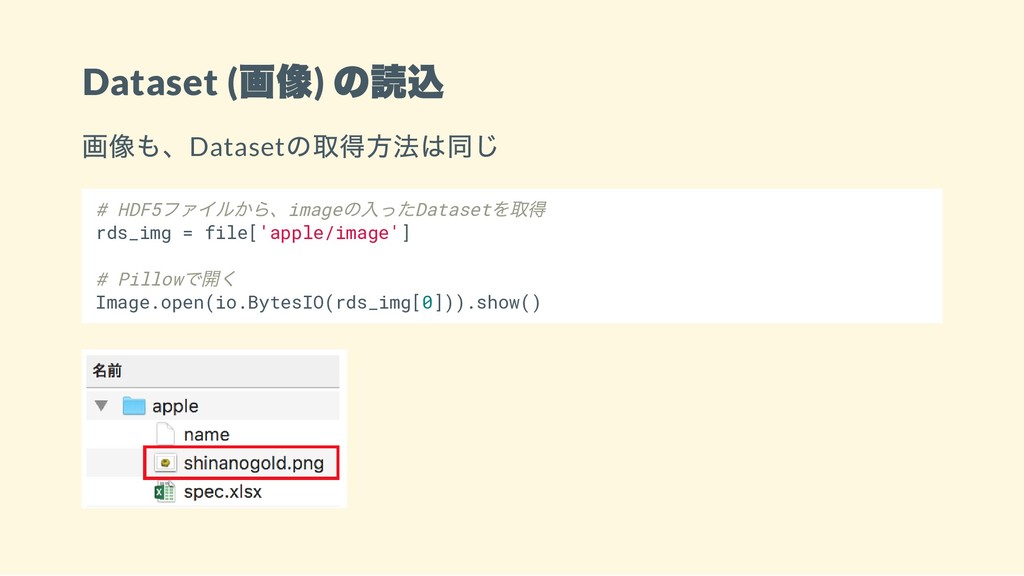
Dataset ( 画像) の読込 画像も、Dataset の取得方法は同じ # HDF5 ファイルから、image の入ったDataset
を取得 rds_img = file['apple/image'] # Pillow で開く Image.open(io.BytesIO(rds_img[0])).show()
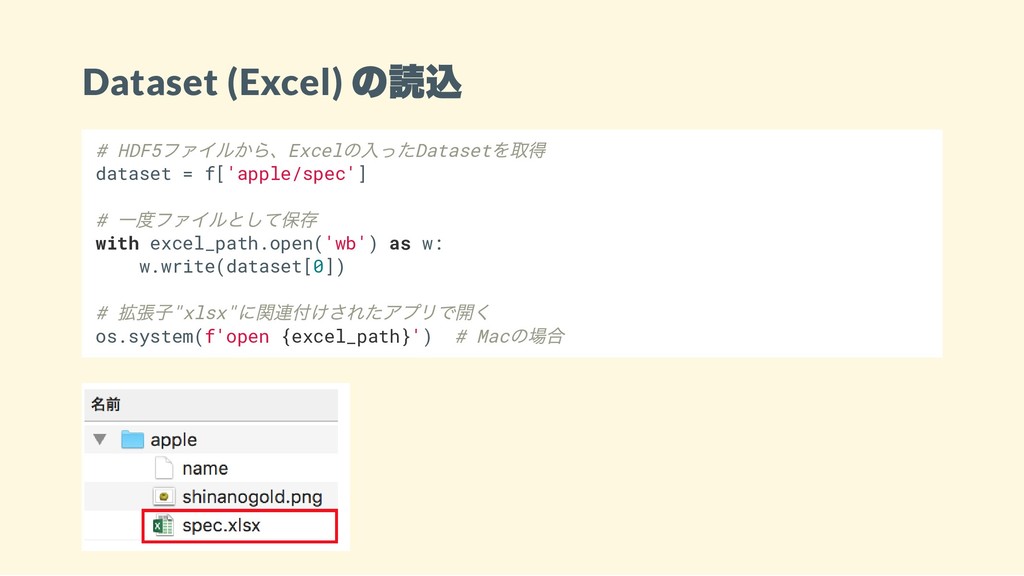
Dataset (Excel) の読込 # HDF5 ファイルから、Excel の入ったDataset を取得 dataset =
f['apple/spec'] # 一度ファイルとして保存 with excel_path.open('wb') as w: w.write(dataset[0]) # 拡張子"xlsx" に関連付けされたアプリで開く os.system(f'open {excel_path}') # Mac の場合
検索
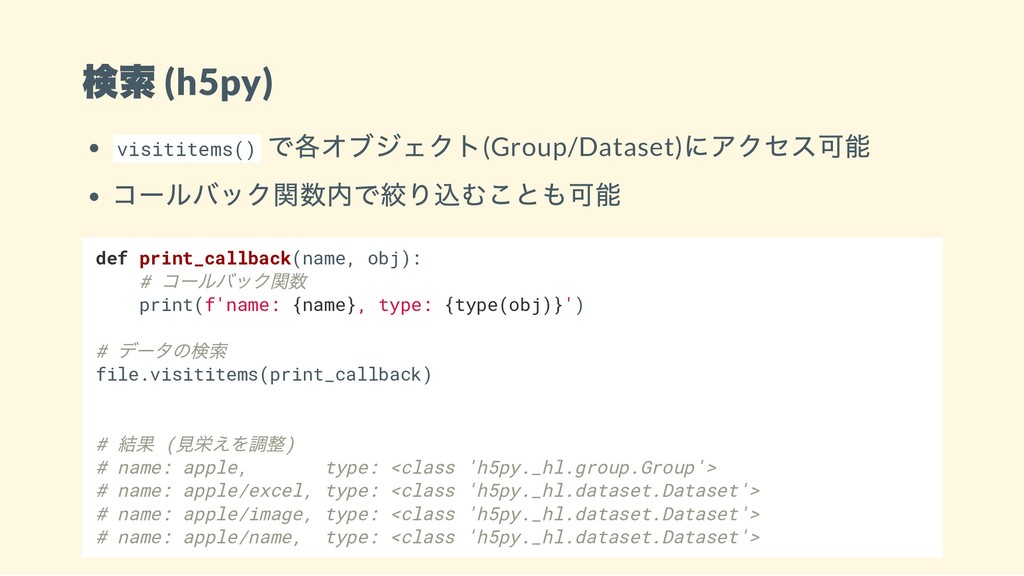
検索 (h5py) visititems() で各オブジェクト(Group/Dataset) にアクセス可能 コールバック関数内で絞り込むことも可能 def print_callback(name, obj): #
コールバック関数 print(f'name: {name}, type: {type(obj)}') # データの検索 file.visititems(print_callback) # 結果 ( 見栄えを調整) # name: apple, type: <class 'h5py._hl.group.Group'> # name: apple/excel, type: <class 'h5py._hl.dataset.Dataset'> # name: apple/image, type: <class 'h5py._hl.dataset.Dataset'> # name: apple/name, type: <class 'h5py._hl.dataset.Dataset'>
検索 (PyTables) list_nodes() walk_groups() walk_nodes()
圧縮
gzip 圧縮 10MB のバイナリをDataset に入れると、無圧縮では約170MB create_dataset() の引数 compression に圧縮形式 (gzip
など) を入れる with h5py.File(compression_file_path, mode='w') as file: compression = file.create_dataset( 'big_size_data', big_size_data.shape, dtype=TYPE_OF_BINARY, # 圧縮形式を指定 compression='gzip') compression[0] = big_size_data # HDF5 ファイルのサイズを表示 print(f'{str(os.path.getsize(compression_file_path)).rjust(10)} [compress]') # => 10003716 [compress] ( 約10MB)
PyTables の場合 デフォルトで圧縮済
ところで import pathlib import h5py BASE_DIR = pathlib.Path(__file__).resolve().parents[0] OUTPUT_DIR =
BASE_DIR.joinpath('output', 'h5py') output = OUTPUT_DIR.joinpath('use_h5py.h5') with h5py.File(output, mode='w') as file: ...
HTTP + HDF5 ファイル h5serv HDF REST API に準拠し、HTTP でHDF5
ファイルを操作 Tornado ベース The HDF Group のリポジトリにて提供 https://github.com/HDFGroup/h5serv
HDF REST API とは ネットワークを使ってHDF5 ファイルを操作する時のインタフェース The HDF Group のリポジトリにて定義を提供
https://github.com/HDFGroup/hdf-rest-api
h5serv の使い方 Python スクリプトとして起動 起動時のオプションあり https://h5serv.readthedocs.io/en/latest/Installation/ServerSet up.html#server-con guration $ python
h5serv --port=5000 --toc_name=mytoc.h5 --domain=example.com
h5serv でDataset 作成 Dataset の型定義をPOST URL_BASE = 'http://test.example.com:5000/' str_type =
{'charSet': 'H5T_CSET_UTF8', 'class': 'H5T_STRING', 'strPad': 'H5T_STR_NULLTERM', 'length': 'H5T_VARIABLE'} payload = {'type': str_type, 'shape': 1} res1 = requests.post( URL_BASE + 'datasets', json=payload ).json()
h5serv でDataset 作成 Dataset の中身をPUT url = URL_BASE + 'datasets/'
+ res1.get('id') + '/value' res2 = requests.put( url, json={ 'value': ' ワールド' } )
h5serv で作成されたもの 2 つのHDF5 ファイル 全体の構造を管理するHDF5 ファイル (mytoc.h5) データが格納される実際のHDF5 ファイル
(test.h5) $ python h5serv --port=5000 --toc_name=mytoc.h5 --domain=example.com URL_BASE = 'http://test.example.com:5000/'
中身を見てみる 全体の構造を管理するファイル
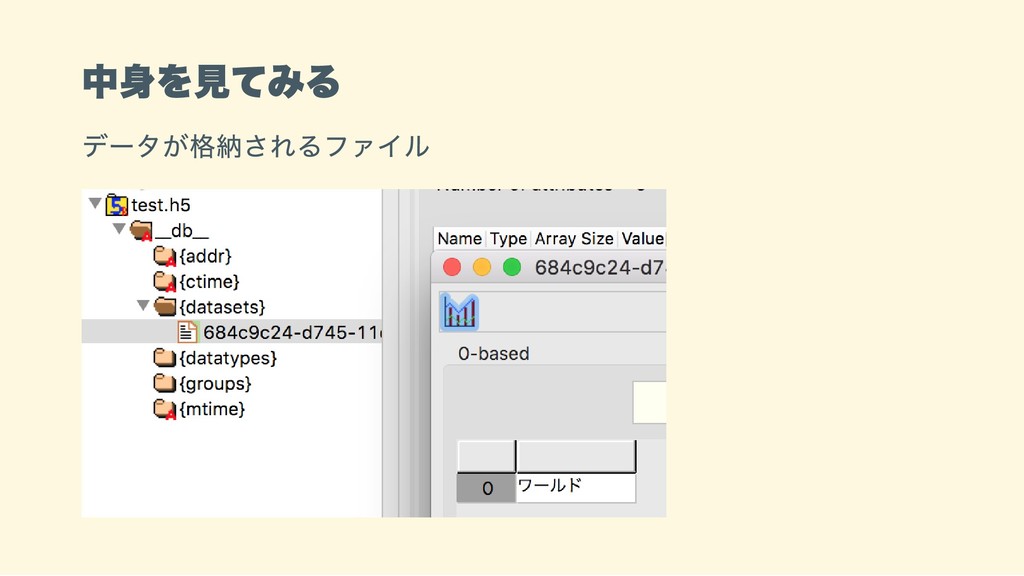
中身を見てみる データが格納されるファイル
h5py 資産があるんだけど...
h5pyd HDF REST API のクライアントライブラリ The HDF Group のリポジトリにて提供 https://github.com/HDFGroup/h5pyd-
h5py とほぼ互換のAPI を持つ 少し書き換えるだけで、既存コードのHTTP 化が可能
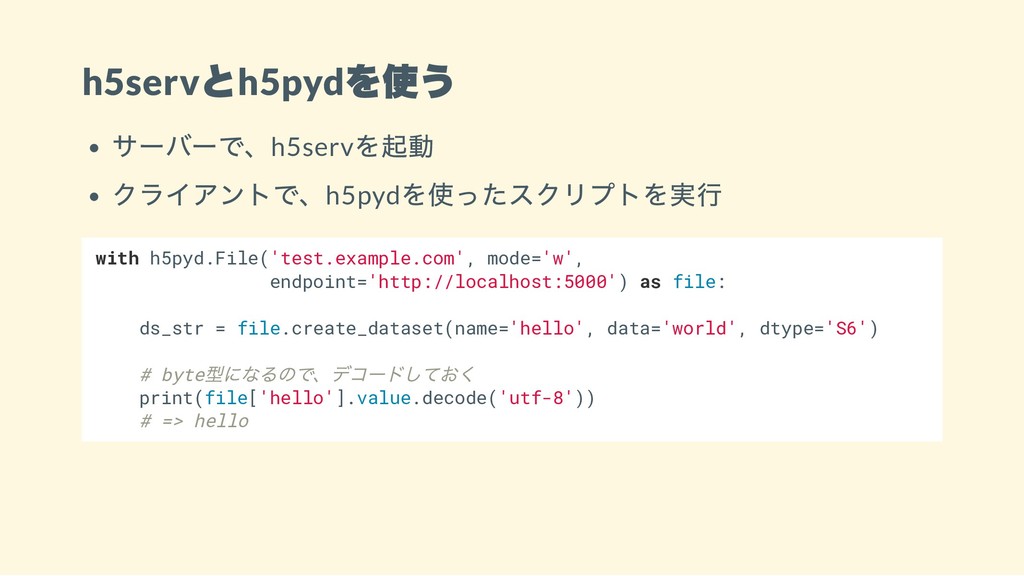
h5serv とh5pyd を使う サーバーで、h5serv を起動 クライアントで、h5pyd を使ったスクリプトを実行 with h5pyd.File('test.example.com', mode='w',
endpoint='http://localhost:5000') as file: ds_str = file.create_dataset(name='hello', data='world', dtype='S6') # byte 型になるので、デコードしておく print(file['hello'].value.decode('utf-8')) # => hello
h5serv を動かすサーバーにHDF5 ファイルを保存 サーバーにディスク容量が必要...
HSDS HSDS = Highly Scalable Data Service The HDF5 Grouop
のリポジトリにて提供 https://github.com/HDFGroup/hsds クラウドネイティブな構成 データの保管先はAWS S3
自前でHSDS を動かすの大変そう Docker Compose を使ったインストール手順はあるものの...
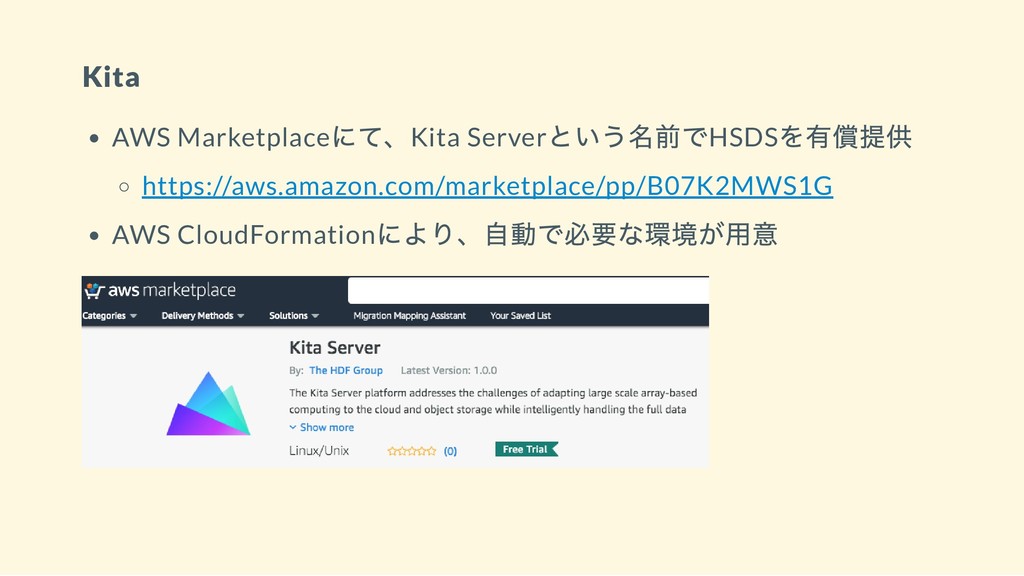
Kita AWS Marketplace にて、Kita Server という名前でHSDS を有償提供 https://aws.amazon.com/marketplace/pp/B07K2MWS1G AWS CloudFormation
により、自動で必要な環境が用意
Kita 事例:WIND ツールキット 50TB のオープン気象データモデルデータセット https://aws.amazon.com/jp/blogs/news/power-from-wind-open-data- on-aws/
4. バージョンアップ
HDF5 のバージョン 5 現在のバージョン 過去にはバージョン4 もあり バージョン4 と5 の間では、互換性なし Python
のライブラリも異なる “ “
HDF5 のバージョン HDF5 x.y.z 現在は、2 系統 HDF5 1.8.x 系 HDF5
1.10.x 系 ライブラリによっては、1.8.x しかサポートしてない場合も
ライフサイクル マイグレーションページに記載あり https://portal.hdfgroup.org/display/HDF5/Migrating+from+HDF5 +1.8+to+HDF5+1.10 1.8 系:2020 年5 月でパッチリリース終了 HDF HDF5
における境界外読み取りに関する脆弱性 https://jvndb.jvn.jp/ja/contents/2019/JVNDB-2019- 002044.html 1.12 系:2019 年夏にリリース予定( だった)
1.10 系を使う上での注意点 1.10.0~1.10.2 と、それ以降では互換性がない https://portal.hdfgroup.org/display/HDF5/Software+Changes+fr om+Release+to+Release+for+HDF5-1.10 1.10.3 では大きなパフォーマンス改善があった
h5py で使われるバージョン HDF5 のライブラリ libhdf5 を自動的で検知・利用 自分で指定することも可能 $ brew install
hdf5 /usr/local/Cellar/hdf5/1.10.5_1 $ export HDF5_DIR=/usr/local/Cellar/hdf5/1.10.5_1 $ pip install --no-binary=h5py h5py >>> h5py.version.info h5py 2.10.0 HDF5 1.10.5 # 指定したバージョン
今後のロードマップ HDF5 Roadmap 2019-2020 https://www.slideshare.net/HDFEOS/hdf5-roadmap-20192020 新しいアーキテクチャの登場 デフォルトの文字エンコードが UTF-8 に Group,
Dataset, Attribute の各名前に使用可
まとめ 科学技術分野以外でも、HDF5 ファイルは手軽に使える Python ライブラリが充実している h5py, PyTables, h5serv, h5pyd, HSDS
ローカルだけでなく、サーバー・クラウドでも利用可能 今後もHDF5 ファイルには機能が追加されていく予定
次のステップ 書籍「Python and HDF5 」(Andrew Collette 著、米オライリー) Python ライブラリの扱い方 意外と奥が深い、HDF
の世界(Python ・h5py 入門) - Qiita https://qiita.com/simonritchie/items/23db8b4cb5c590924d95 Getting started with HDF5 and PyTables - PyCon Slovakia(SK) 2018 https://pyvideo.org/pycon-sk-2018/getting-started-with-hdf5- and-pytables.html
公式情報 The HDF Group のtwitter https://twitter.com/hdf5 HDF Forum https://forum.hdfgroup.org/latest SlideShare
The HDF-EOS Tools and Information Center https://www.slideshare.net/HDFEOS Youtube https://www.youtube.com/channel/UCRhtsIZquL3r-zH-R-r9-tQ
Enjoy HDF5 life!!
落ち穂拾い 時間が余ったら...
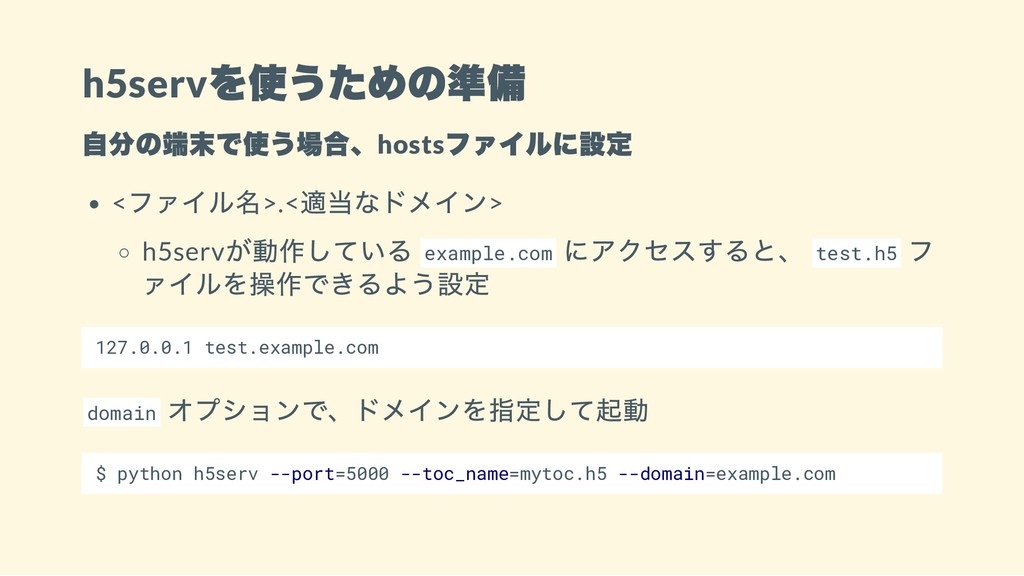
h5serv を使うための準備 自分の端末で使う場合、hosts ファイルに設定 < ファイル名>.< 適当なドメイン> h5serv が動作している example.com
にアクセスすると、 test.h5 フ ァイルを操作できるよう設定 127.0.0.1 test.example.com domain オプションで、ドメインを指定して起動 $ python h5serv --port=5000 --toc_name=mytoc.h5 --domain=example.com
h5serv を使うための準備 操作対象のファイルを作成 中身は空で問題ない p = Path(__file__).resolve().parents[0].joinpath('h5serv', 'data', 'test.h5') with
h5py.File(p, mode='w') as f: pass この時点での data ディレクトリ構成 $ tree . ├── public/ ├── readme.txt └── test.h5
h5serv での動作確認 型定義を作成 str_type = {'charSet': 'H5T_CSET_UTF8', 'class': 'H5T_STRING', 'strPad':
'H5T_STR_NULLTERM', 'length': 'H5T_VARIABLE'} payload = {'type': str_type, 'shape': 1} res1 = requests.post( URL_BASE + 'datasets', json=payload ).json()
h5serv での動作確認 確認すると、test.h5 が作成され、型定義のあるDataset が作成される ├── mytoc.h5 ├── public/ ├──
readme.txt └── test.h5
バージョン (HDF5 x.y.z) x: major version number ライブラリやファイルフォーマットの大きな変更あり y: minor
version number 新しい機能によるファイルフォーマットの変更 偶数はstable 、奇数はdevelop z: release number バグ修正等ライブラリの改善、フォーマットの変更なし https://portal.hdfgroup.org/display/HDF5/HDF5+Library+Release+ Version+Numbers
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Attribute 作成 Group, Dataset のどちらにも作成可能 # Group のAttribute group.attrs['title'] =](https://files.speakerdeck.com/presentations/bc83d8a8df064d9aa05204b9b9d0db0c/slide_40.jpg){kind=link}
{kind=link}
![Dataset ( 文字列) の読込 Group/Dataset な形で、Dataset を取得 dataset = file['apple/name']](https://files.speakerdeck.com/presentations/bc83d8a8df064d9aa05204b9b9d0db0c/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ところで import pathlib import h5py BASE_DIR = pathlib.Path(__file__).resolve().parents[0] OUTPUT_DIR =](https://files.speakerdeck.com/presentations/bc83d8a8df064d9aa05204b9b9d0db0c/slide_51.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![h5serv を使うための準備 操作対象のファイルを作成 中身は空で問題ない p = Path(__file__).resolve().parents[0].joinpath('h5serv', 'data', 'test.h5') with](https://files.speakerdeck.com/presentations/bc83d8a8df064d9aa05204b9b9d0db0c/slide_81.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}