While textbooks and papers often present dynamic programming algorithms in an imperative style, there's usually nothing intrinsically imperative about them. In this talk I describe a framework for thinking about dynamic programming algorithms in a functional style and present two algorithms (matrix-chain multiplication and string edit distance) implemented in Haskell.
This presentation was delivered at the FP-Syd functional programming user group in Sydney, Australia in May, 2015.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Actually programming MATRIX-CHAIN-ORDER(p) n <- length[p] - 1 for i](https://files.speakerdeck.com/presentations/58fadd2b671940ea99fe3fec545f909c/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
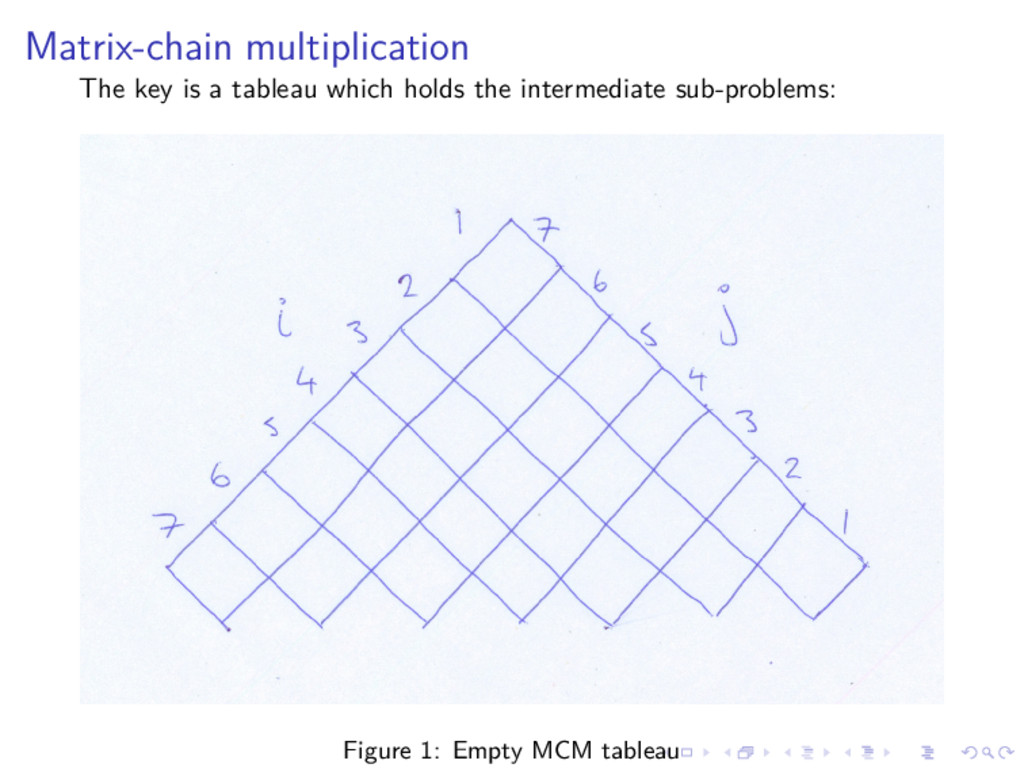{kind=link}
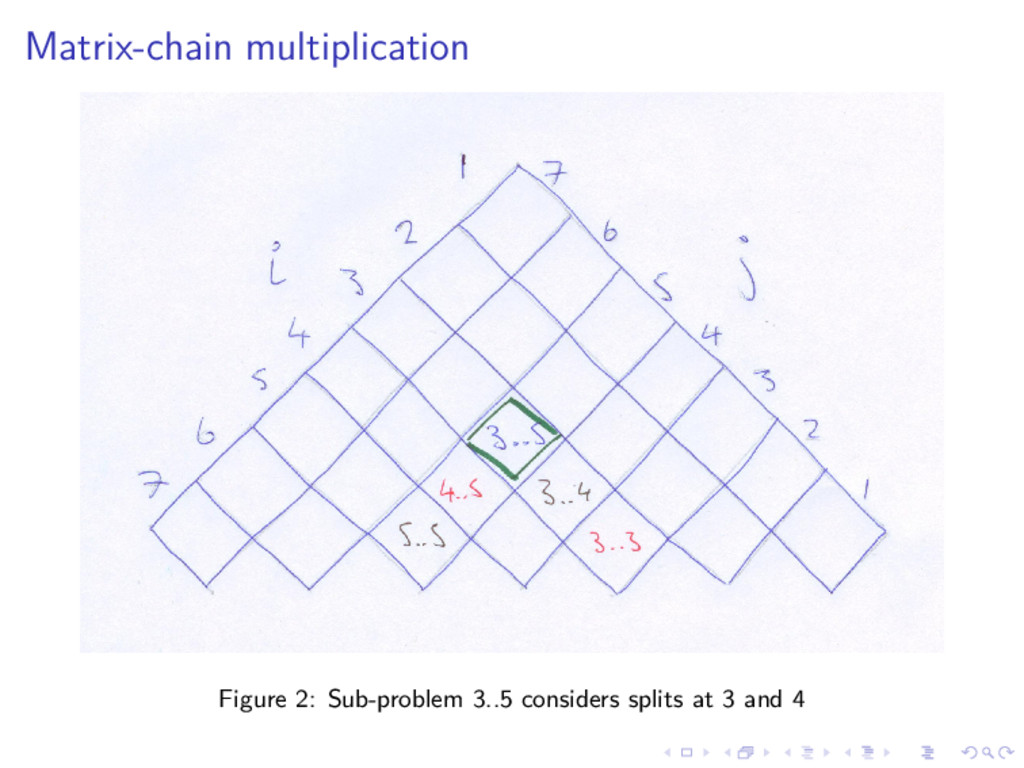{kind=link}
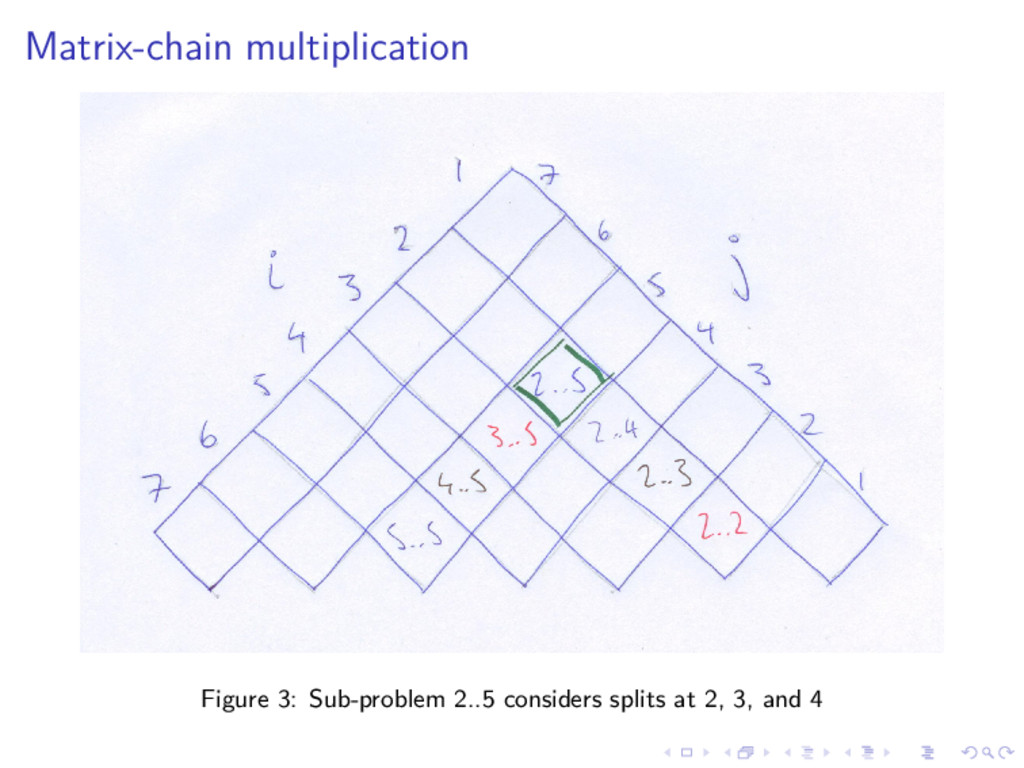{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Wagner-Fischer algorithm We’ll find (Int, [Op]) solutions which include the](https://files.speakerdeck.com/presentations/58fadd2b671940ea99fe3fec545f909c/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}