Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Gemini APIで音声文字起こし-実装の工夫と課題解決
Search
t-kikuchi
January 30, 2026
Technology
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Gemini APIで音声文字起こし-実装の工夫と課題解決
Gemini APIで音声文字起こし-実装の工夫と課題解決
t-kikuchi
January 30, 2026
More Decks by t-kikuchi
See All by t-kikuchi
AgentGatewayを試してみたかった
tkikuchi
0
290
最低限これだけ押さえれ大丈夫_Claude Enterprise/Team企業展開ガバナンス入門
tkikuchi
1
1.7k
Anthropic「Long-running a gents」をGeminiで再現してみた
tkikuchi
0
1k
Vertex AI Agent Engine で学ぶ「記憶」の設計
tkikuchi
0
240
コンテキストエンジニアリングとは何か?〜Claude Codeを使った実践テクニックとコンテキスト設計〜
tkikuchi
0
130
バッチ処理をEKSからCodeBuildを使ったGitHub Self-hosted Runnerに変更した話
tkikuchi
1
230
Claude Code導入後の次どうする? ~初心者が知るべき便利機能~
tkikuchi
0
160
ClaudeCodeを使ってAWSの設計や構築をしてみた
tkikuchi
0
230
ClaudeCode_vs_GeminiCLI_Terraformで比較してみた
tkikuchi
1
11k
Other Decks in Technology
See All in Technology
13年運用タイトルのサーバーサイドが辿り着いた現在地 ― モンスターストライクにおける技術・組織・AI活用から得た知見
mixi_engineers
PRO
1
320
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1.5k
最新IoT事例11選に学ぶ!現場の成功パターンと実践のコツ【SORACOM Discovery 2026】
soracom
PRO
0
120
現場で使える AWS DevOps Agent 活用ノウハウ - Release Management 機能の検証結果を添えて / AWS DevOps Agent Release Management and Know-How
kinunori
4
750
AI駆動開発は個人技からチーム戦へ:組織でAIを使いこなすための実践設計
moongift
PRO
0
130
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
580
現場との対話から始める “作る前に問い直す”業務改善
mochico50
2
340
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
240
歴史から理解するクラウドインフラのしくみ
kizawa2020
0
190
plamo-3-translateの開発
pfn
PRO
0
140
信頼できるテスティングAIをどう育てるか?
odan611
0
160
エンタープライズデータへ安全につなぐ Production-ready なエージェント設計 ― AI × MCP リファレンスアーキテクチャ ― #AIDevDay
cdataj
1
290
Featured
See All Featured
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Done Done
chrislema
186
16k
A Soul's Torment
seathinner
6
3.1k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.6k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Bash Introduction
62gerente
615
220k
The Invisible Side of Design
smashingmag
301
52k
Are puppies a ranking factor?
jonoalderson
1
3.7k
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
190
Transcript
Gemini APIで音声文字起こし 実装の工夫と課題解決 2026年01月30日 クラスメソッド株式会社 菊池聡規(@tttkkk215)
自己紹介 名前: 菊池 聡規(とーち) 部署: クラウド事業本部 普段の業務: AWSのコンサルティングやピープルマネジメント どちらかと言えばインフラ寄りの領域を担当 Xアカウント:
https://x.com/tttkkk215 ブログ: https://dev.classmethod.jp/author/tooti/ 好きな技術: コンテナ、Terraform、生成AI 2
背景など
きっかけ 会議の議事録を文字起こししたい Google Meetは自動文字起こしがあるが、招待されたTeams等では使えない SaaSでできるのは知っていたが... AIでサクッと作れる時代 自分で作ってみることに 技術選定 音声ファイルを処理できるマルチモーダルなLLMを調査 Geminiに辿り着く
Gemini APIを使うなら → Vertex AI なぜ作ったのか 4
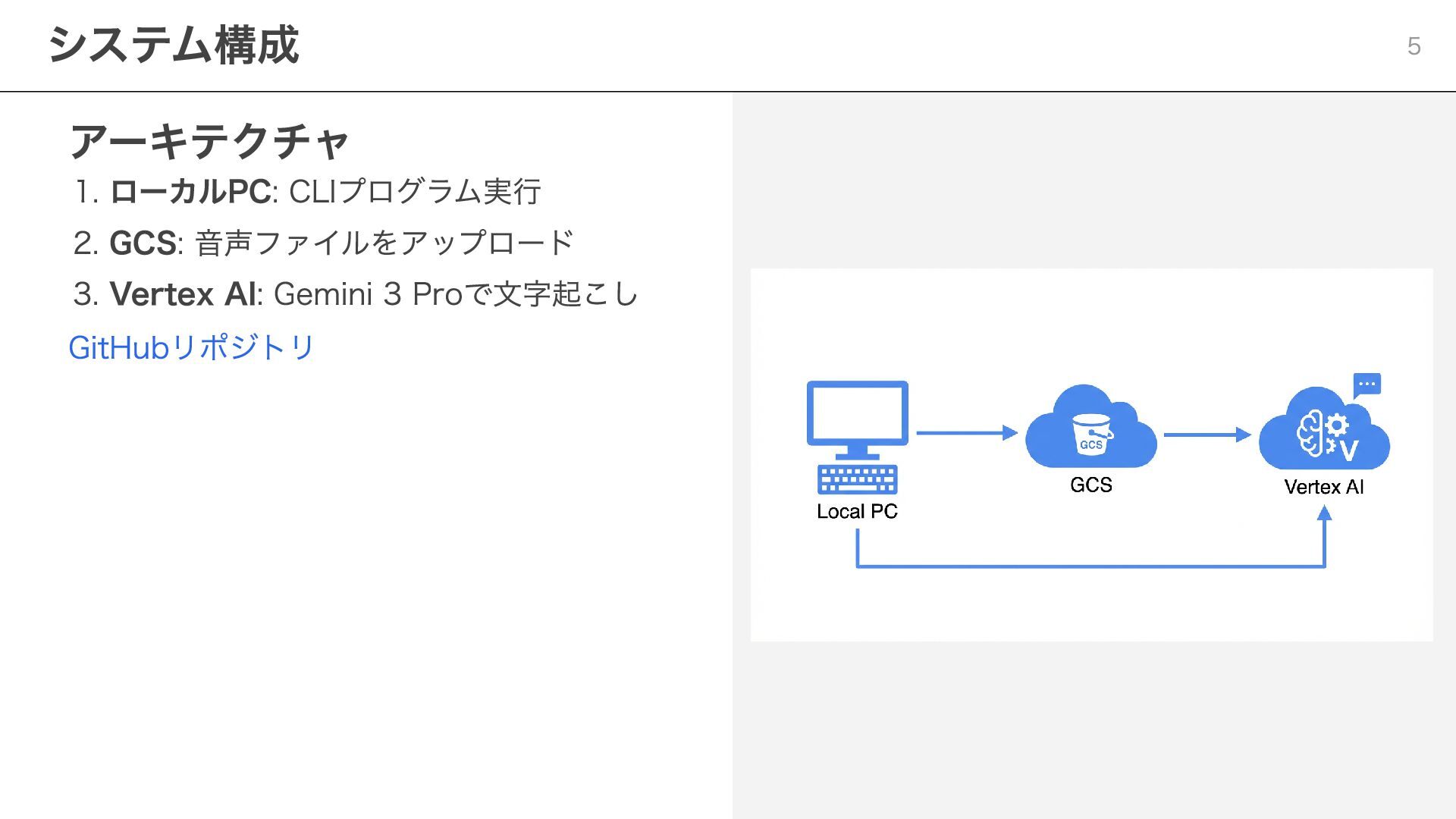
アーキテクチャ 1. ローカルPC: CLIプログラム実行 2. GCS: 音声ファイルをアップロード 3. Vertex AI:
Gemini 3 Proで文字起こし GitHubリポジトリ システム構成 5
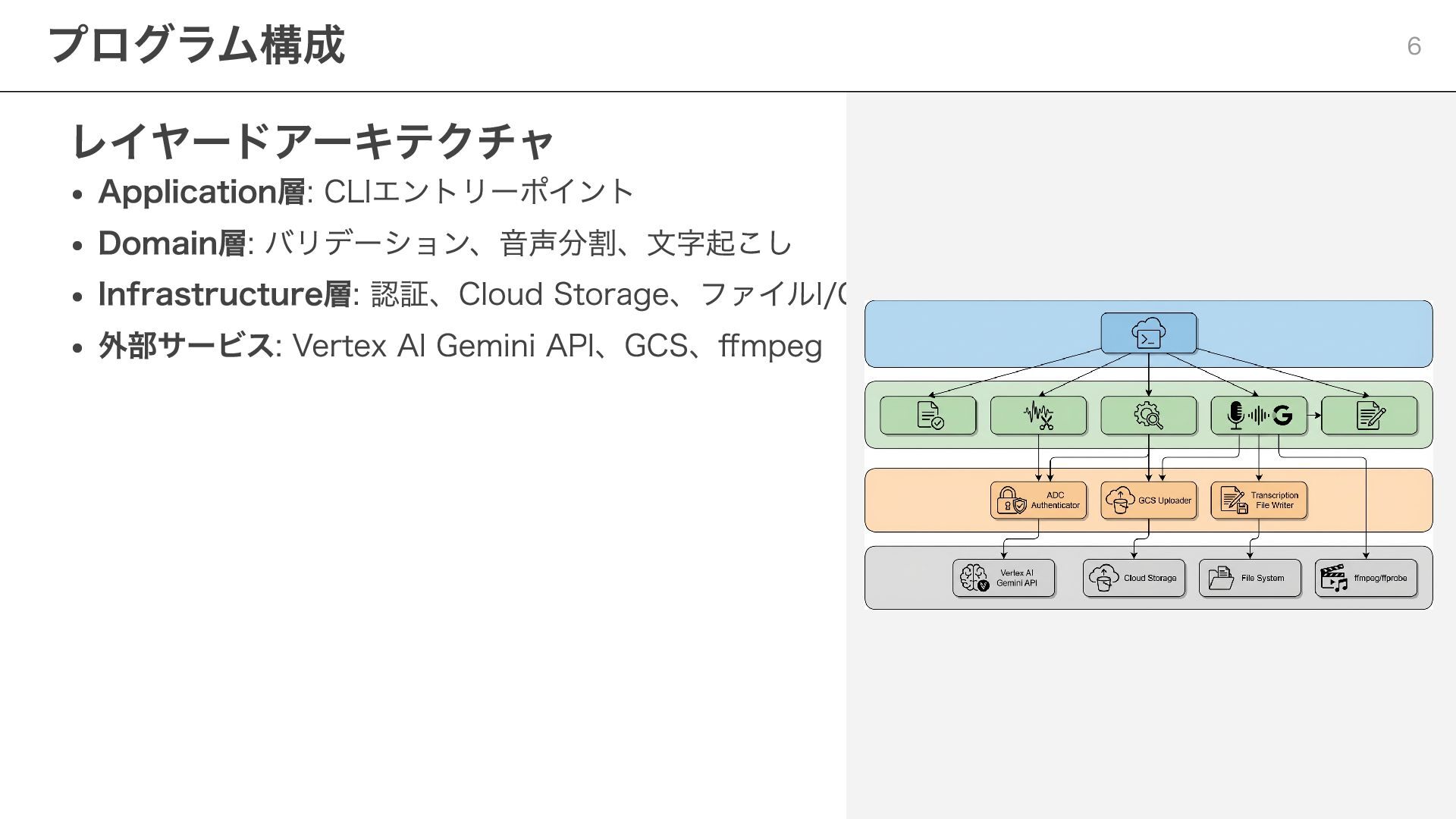
レイヤードアーキテクチャ Application層: CLIエントリーポイント Domain層: バリデーション、音声分割、文字起こし Infrastructure層: 認証、Cloud Storage、ファイルI/O 外部サービス: Vertex
AI Gemini API、GCS、ffmpeg プログラム構成 6
課題1: 出力形式の不安定性
期待する出力形式 00:00:15 | 話者A | こんにちは、今日はよろしくお願いします 00:00:18 | 話者B |
よろしくお願いします 00:01:23 | 話者A | それでは議題に入ります 実際の出力(LLMの非決定性) 実行1: "00:00:15 | 話者A | こんにちは" 正しい 実行2: "話者A (00:15): こんにちは" 形式が違う 実行3: "15秒目 話者A こんにちは" これも違う → 同じプロンプト、同じ音声でも毎回違う形式! 直面した根本的な問題 8
LLMの特性 要因 影響 ランダム性 出力が毎回変わる プロンプトの曖昧さ AIが自由に解釈 考えられた選択肢 1. 汎用パーサー
→ 形式のバリエーションが無限、網羅不可能 2. リトライ戦略 → 音声処理は重い(コスト高、時間かかる) 3. TEMPERATURE調整 (1.0→0.2) → 効果あり(ランダム性を抑制) → さらに確実にするため 二段階戦略 を採用 なぜこうなるのか? 9
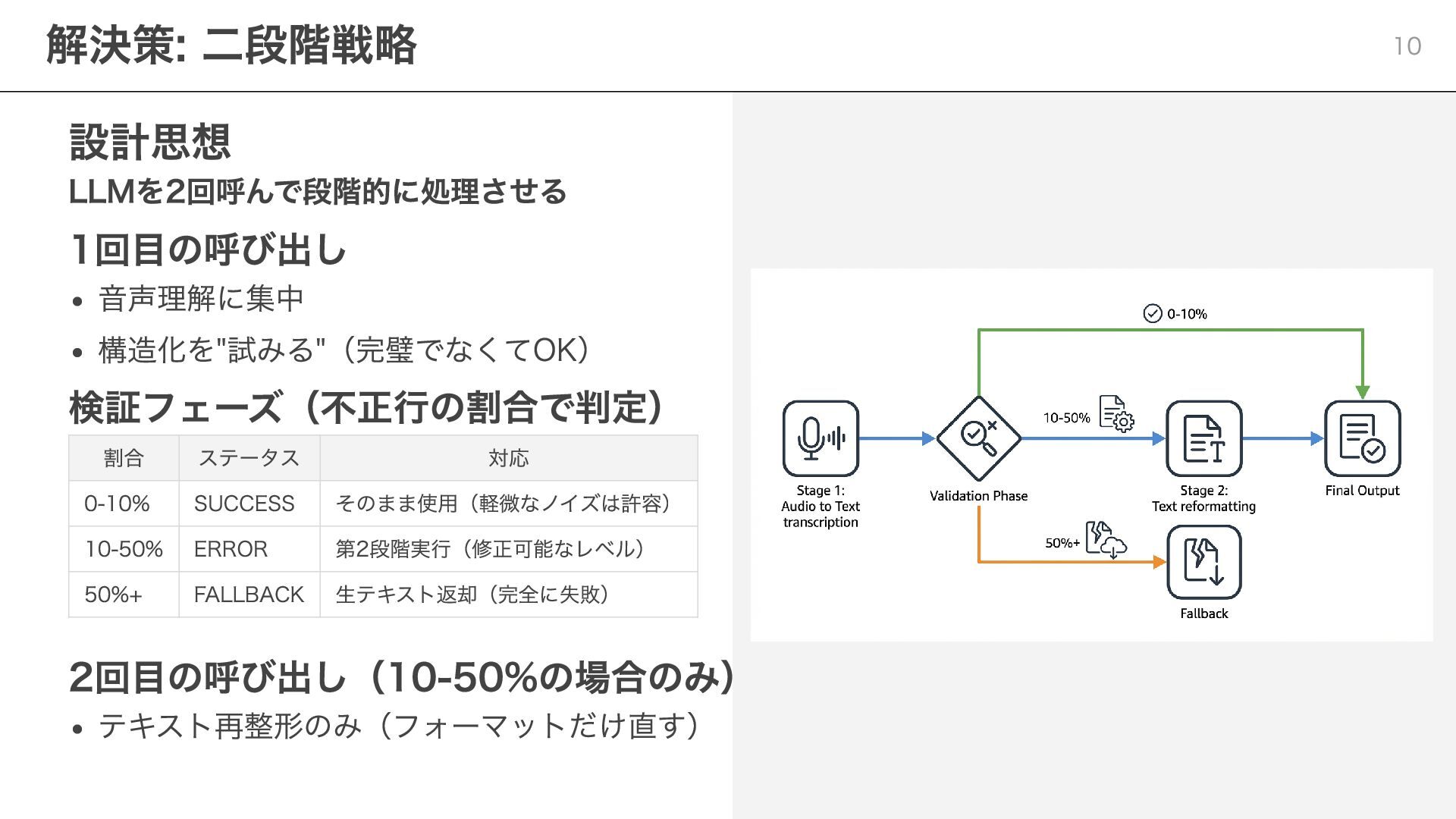
設計思想 LLMを2回呼んで段階的に処理させる 1回目の呼び出し 音声理解に集中 構造化を"試みる"(完璧でなくてOK) 検証フェーズ(不正行の割合で判定) 割合 ステータス 対応 0-10%
SUCCESS そのまま使用(軽微なノイズは許容) 10-50% ERROR 第2段階実行(修正可能なレベル) 50%+ FALLBACK 生テキスト返却(完全に失敗) 2回目の呼び出し(10-50%の場合のみ) テキスト再整形のみ(フォーマットだけ直す) 解決策: 二段階戦略 10
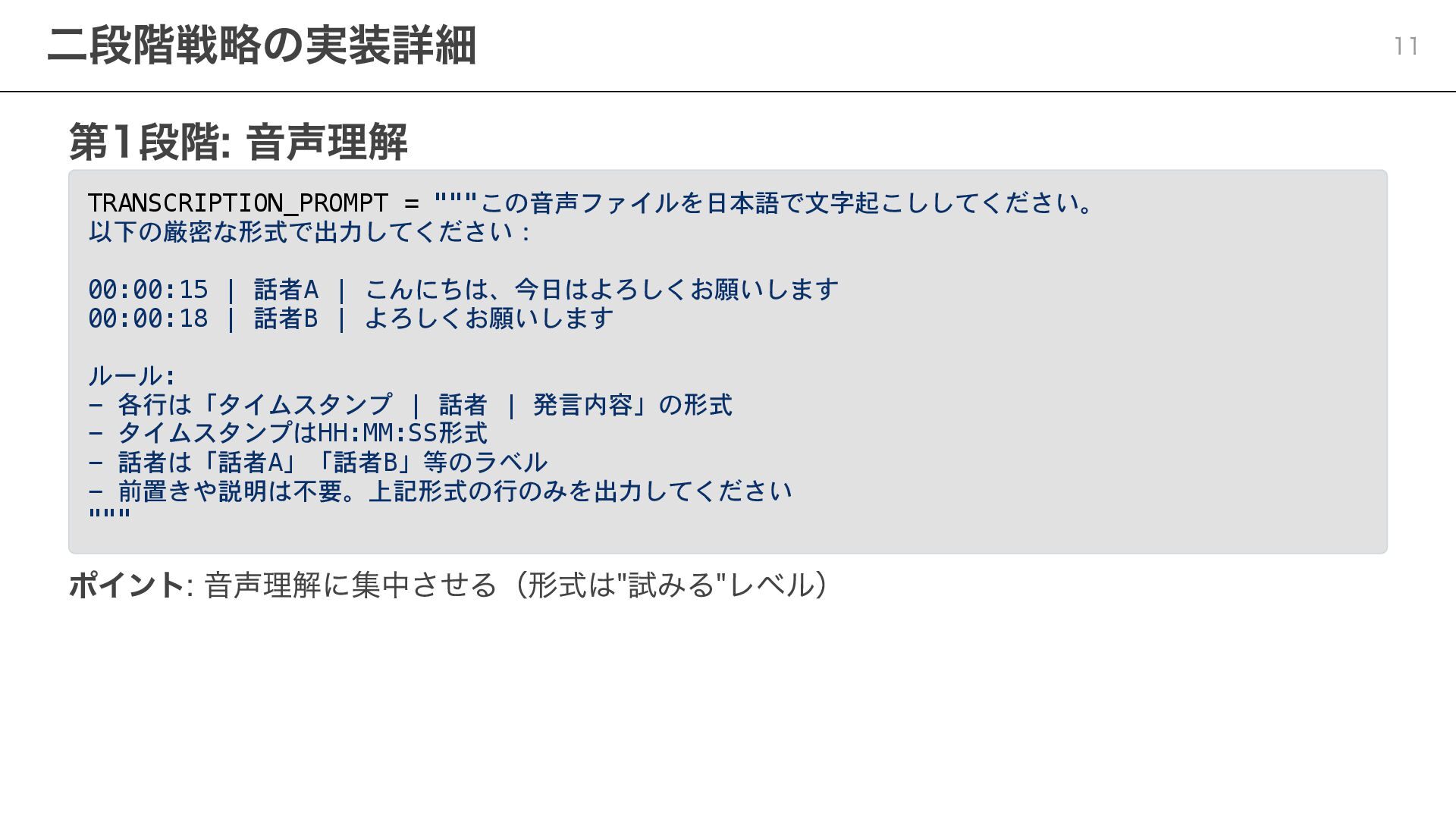
第1段階: 音声理解 TRANSCRIPTION_PROMPT = """この音声ファイルを日本語で文字起こししてください。 以下の厳密な形式で出力してください: 00:00:15 | 話者A |
こんにちは、今日はよろしくお願いします 00:00:18 | 話者B | よろしくお願いします ルール: - 各行は「タイムスタンプ | 話者 | 発言内容」の形式 - タイムスタンプはHH:MM:SS形式 - 話者は「話者A」「話者B」等のラベル - 前置きや説明は不要。上記形式の行のみを出力してください """ ポイント: 音声理解に集中させる(形式は"試みる"レベル) 二段階戦略の実装詳細 11
def validate_and_format(text: str) -> tuple[str, ValidationResult]: """出力を検証して品質判定""" lines = text.strip().split("\n")
malformed_count = 0 for line in lines: # "HH:MM:SS | 話者 | テキスト" 形式かチェック if not PATTERN.match(line): malformed_count += 1 malformed_ratio = malformed_count / total_lines if malformed_ratio <= 0.10: return ValidationStatus.SUCCESS # そのまま使える elif malformed_ratio <= 0.50: return ValidationStatus.ERROR # 第2段階へ else: return ValidationStatus.FALLBACK # 生テキスト返却 検証フェーズのロジック 12
REFORMAT_PROMPT_TEMPLATE = """以下の文字起こしテキストを、 指定された形式に厳密に変換してください。 【入力テキスト】 話者A (0:15): こんにちは 話者B: よろしくお願いします
(18秒) 【出力形式】 00:00:15 | 話者A | こんにちは 00:00:18 | 話者B | よろしくお願いします 【変換ルール】 1. 各発言を1行にまとめる 2. 「タイムスタンプ | 話者 | 発言内容」の形式 3. タイムスタンプはHH:MM:SS形式 4. 前置きや説明は不要。変換後の行のみを出力 【重要】 - 必ず各行に2つのパイプ文字「|」を含める - 発言内容は改変しない(そのまま転記) """ 第2段階: テキスト再整形 13
TEMPERATURE調整 + 二段階戦略 不正形式の行: 約50% → ほぼ0% 改善結果 14
課題2: プロンプトの品質
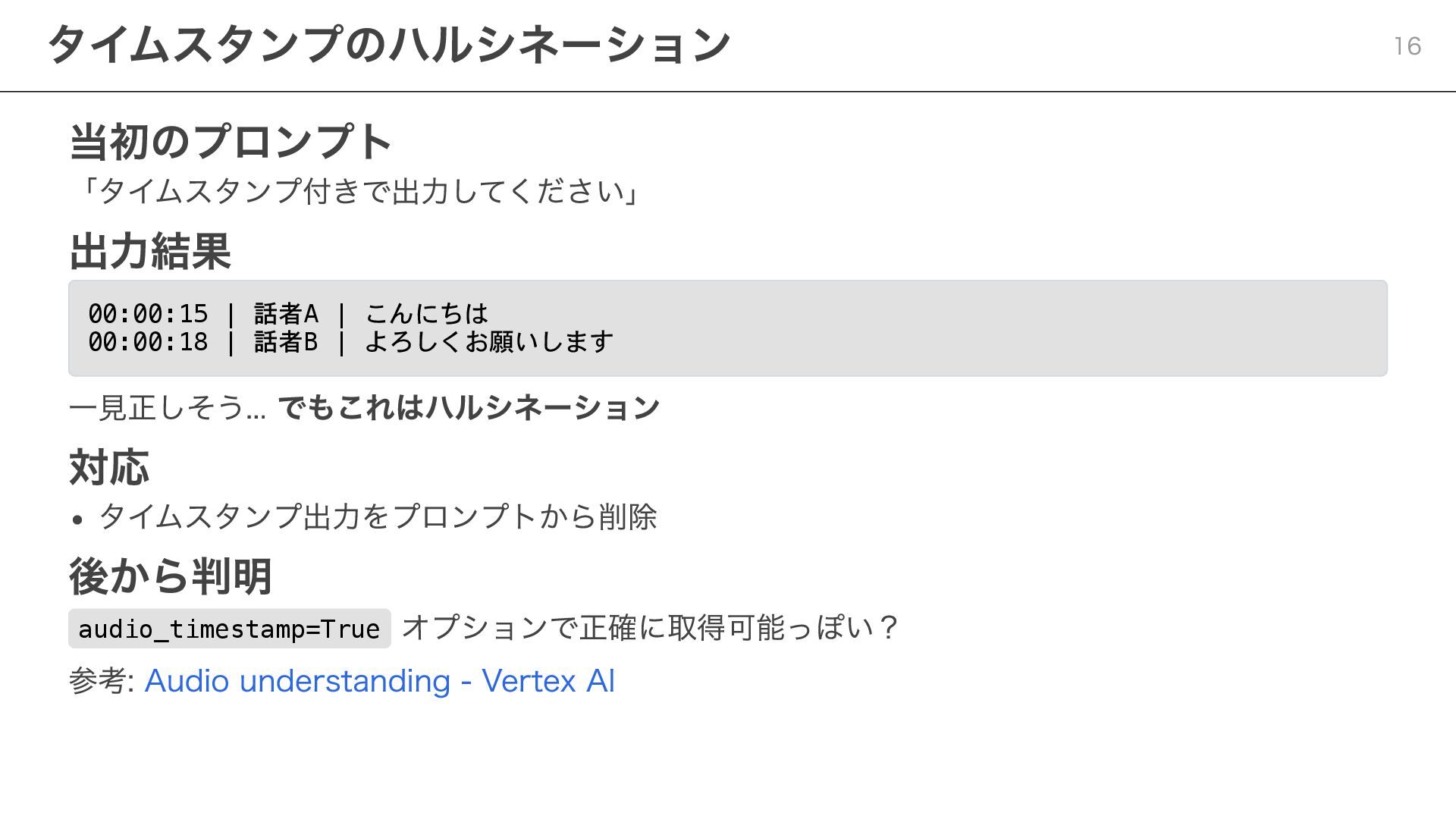
当初のプロンプト 「タイムスタンプ付きで出力してください」 出力結果 00:00:15 | 話者A | こんにちは 00:00:18 |
話者B | よろしくお願いします 一見正しそう... でもこれはハルシネーション 対応 タイムスタンプ出力をプロンプトから削除 後から判明 audio_timestamp=True オプションで正確に取得可能っぽい? 参考: Audio understanding - Vertex AI タイムスタンプのハルシネーション 16
課題3: 長時間音声の処理
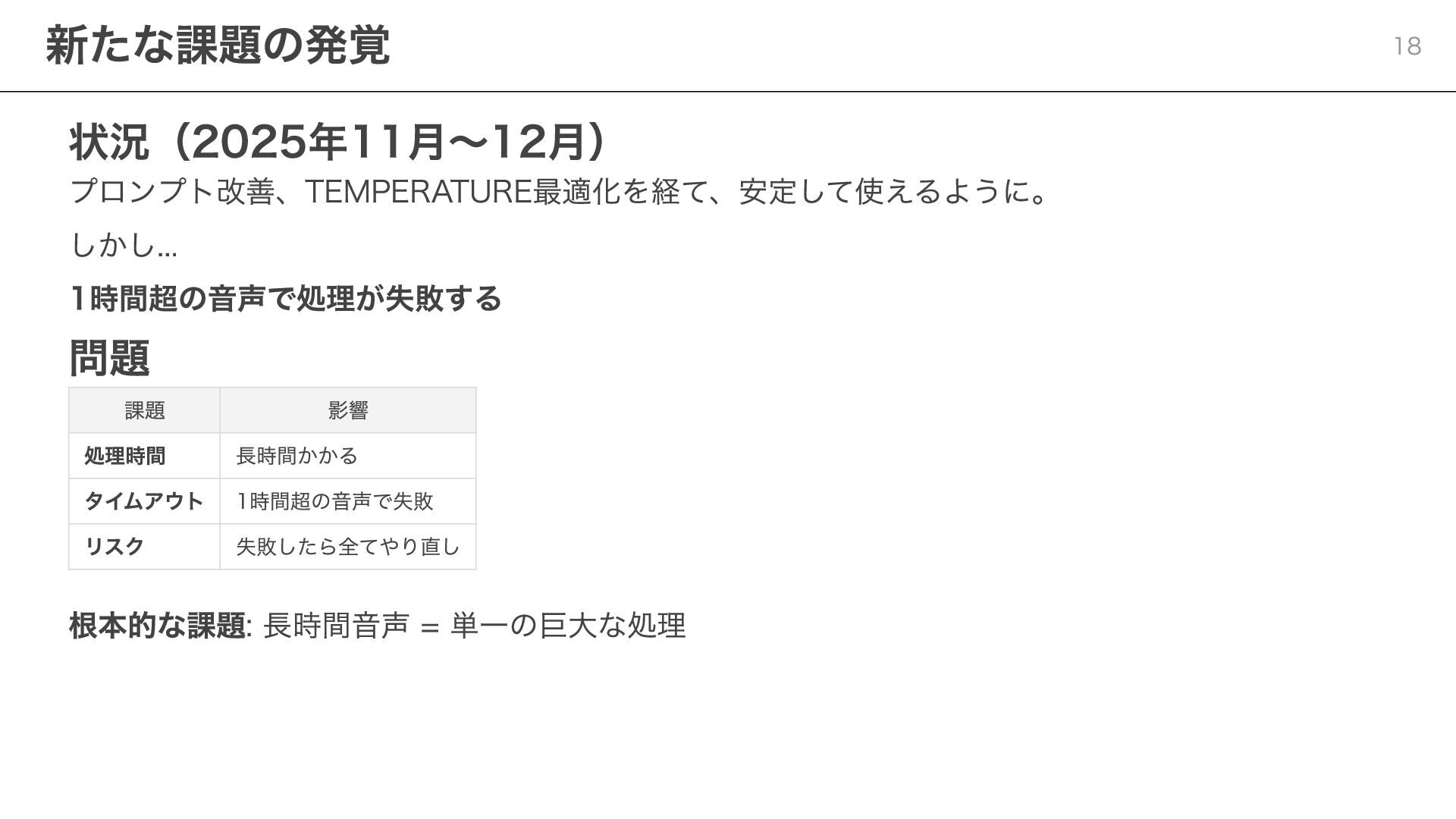
状況(2025年11月〜12月) プロンプト改善、TEMPERATURE最適化を経て、安定して使えるように。 しかし... 1時間超の音声で処理が失敗する 問題 課題 影響 処理時間 長時間かかる タイムアウト
1時間超の音声で失敗 リスク 失敗したら全てやり直し 根本的な課題: 長時間音声 = 単一の巨大な処理 新たな課題の発覚 18
選択肢1: ユーザーに手動分割させる ユーザー: ffmpegで音声を分割 → 各ファイルを個別に処理 → 結果を手動で結合 面倒、毎回コマンドを思い出す必要あり 選択肢2:
自動分割 (採用) 長時間音声を検出 → 自動分割 → 各チャンク処理 → 自動結合 ユーザーは何もしない 解決策の検討 19
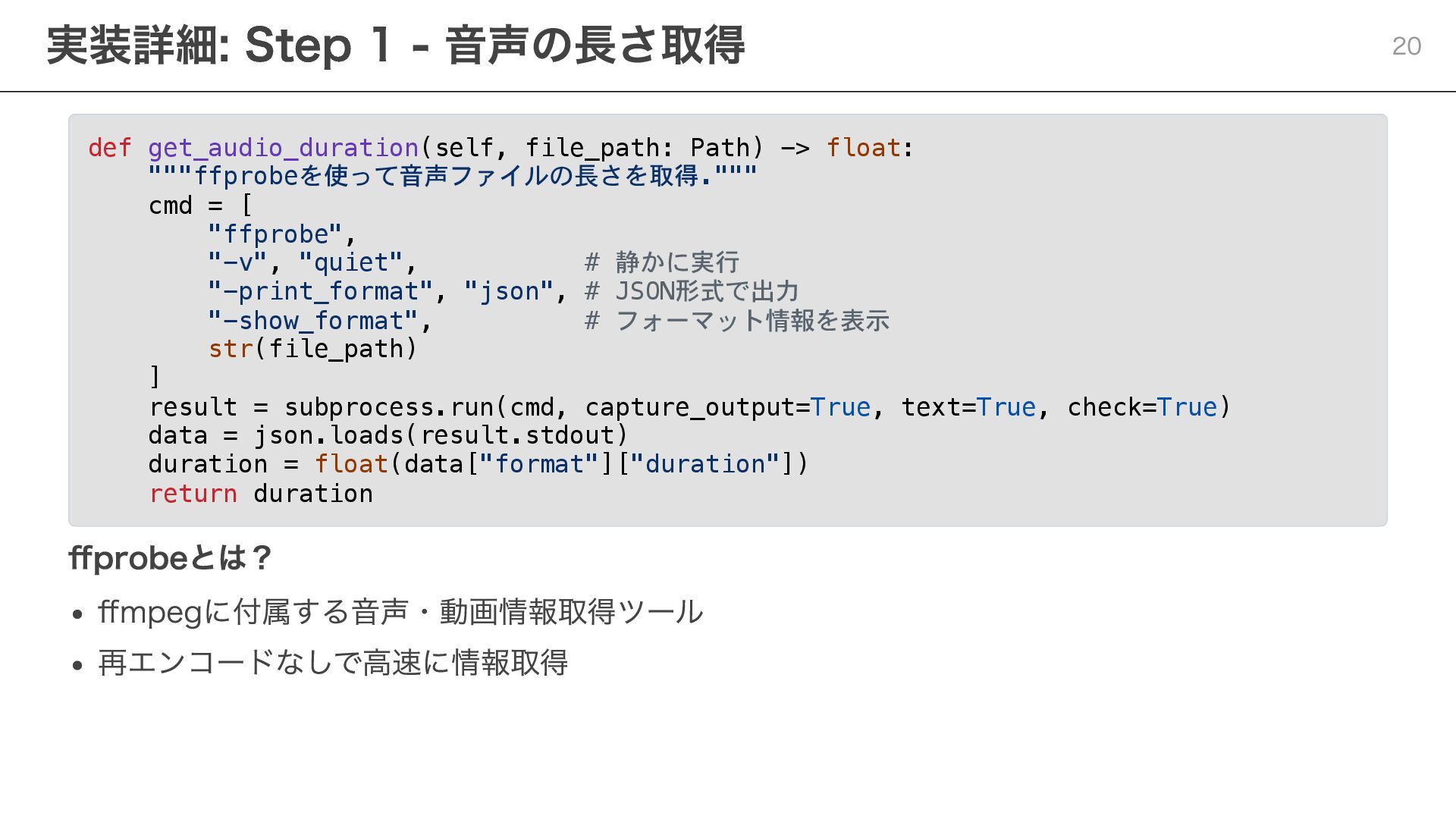
def get_audio_duration(self, file_path: Path) -> float: """ffprobeを使って音声ファイルの長さを取得.""" cmd = [
"ffprobe", "-v", "quiet", # 静かに実行 "-print_format", "json", # JSON形式で出力 "-show_format", # フォーマット情報を表示 str(file_path) ] result = subprocess.run(cmd, capture_output=True, text=True, check=True) data = json.loads(result.stdout) duration = float(data["format"]["duration"]) return duration ffprobeとは? ffmpegに付属する音声・動画情報取得ツール 再エンコードなしで高速に情報取得 実装詳細: Step 1 - 音声の長さ取得 20
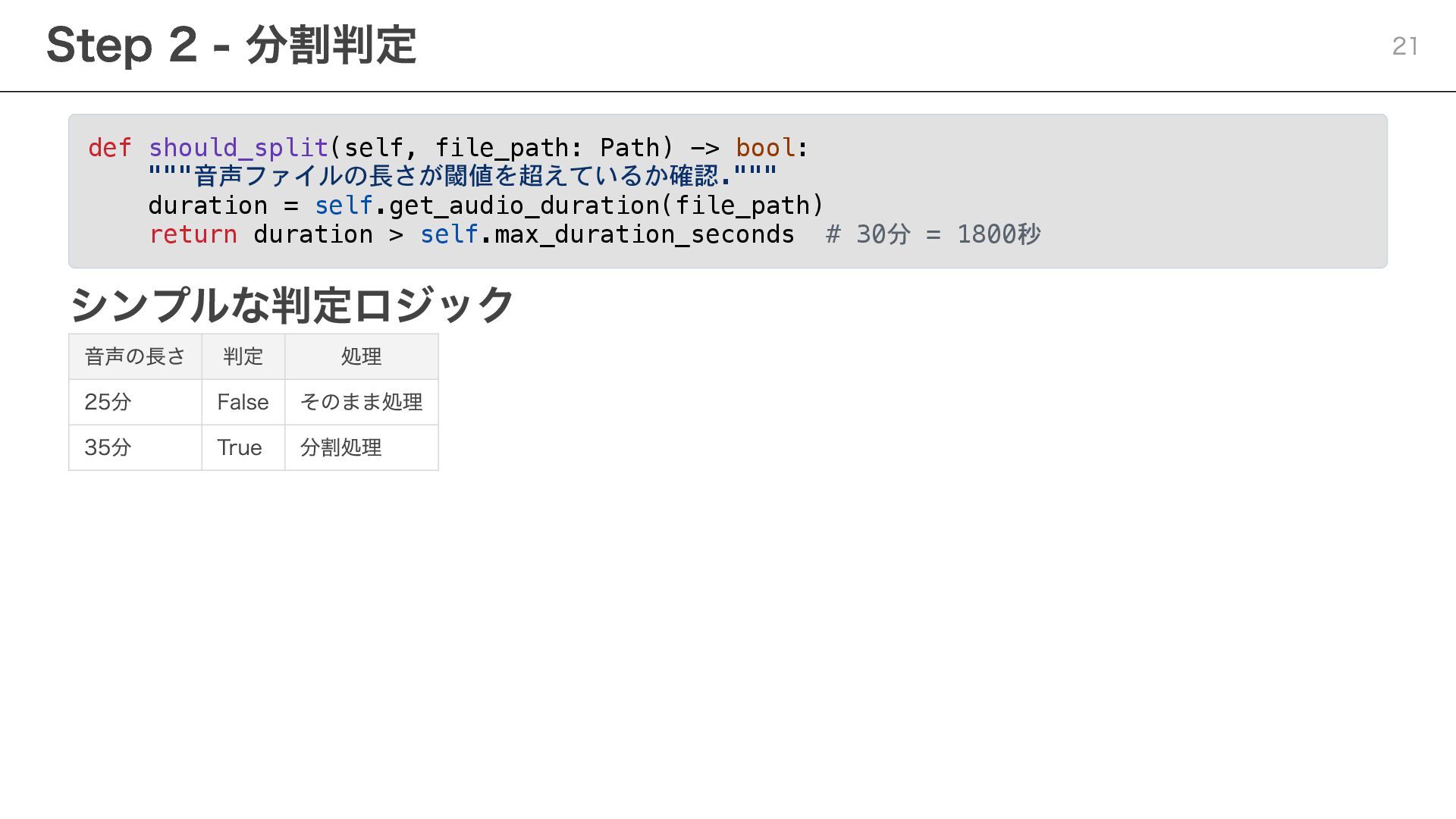
def should_split(self, file_path: Path) -> bool: """音声ファイルの長さが閾値を超えているか確認.""" duration = self.get_audio_duration(file_path)
return duration > self.max_duration_seconds # 30分 = 1800秒 シンプルな判定ロジック 音声の長さ 判定 処理 25分 False そのまま処理 35分 True 分割処理 Step 2 - 分割判定 21
def split_audio_file(self, file_path: Path, output_dir: Path = None) -> List[Path]:
"""音声ファイルをffmpegで時間に基づいて分割.""" cmd = [ "ffmpeg", "-i", str(file_path), # 入力ファイル "-f", "segment", # セグメントモード "-segment_time", str(self.chunk_duration_seconds), # 20分 "-c", "copy", # 再エンコードなし! "-reset_timestamps", "1", # タイムスタンプリセット output_pattern # "audio_part001.m4a" ] subprocess.run(cmd, capture_output=True, text=True, check=True) Step 3 - 音声分割 22
課題4: 話者識別の一貫性(未解決)
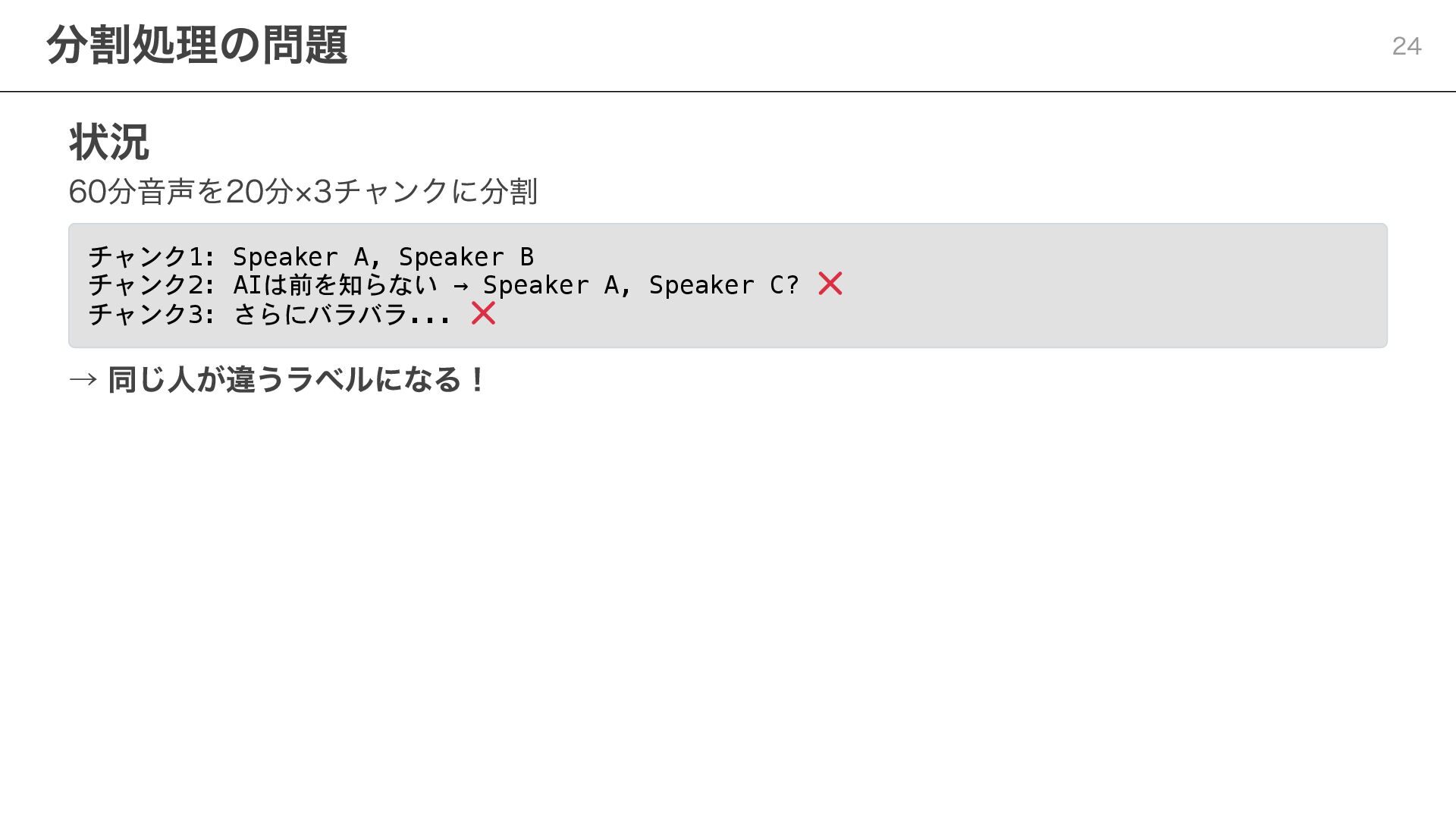
状況 60分音声を20分×3チャンクに分割 チャンク1: Speaker A, Speaker B チャンク2: AIは前を知らない →
Speaker A, Speaker C? チャンク3: さらにバラバラ... → 同じ人が違うラベルになる! 分割処理の問題 24
1. 話者特徴の抽出・照合 LLMに話者の声の特徴を抽出させる(声が高いとか低いとか) その特徴と音声を一緒に提示して話者を特定 結果: 全然精度が上がらなかった 2. 音声ファイルの圧縮 1時間超で失敗するのはサイズが原因では?とLLMから提案されたので圧縮して、1ファイルで Gemini
APIに送信してみた 結果: 状況は改善せず(エラーになる) ※ Gemini APIの仕様: プロンプトあたりの最大音声時間は 約8.4時間、または最大100万トーク ン、と記載 試したこと(うまくいかなかった) 25
アンカー音声方式 チャンク1から各話者の「声紋サンプル」を抽出 → チャンク2以降はそのサンプルを参照 → 「この声と同じならSpeaker A」 処理フロー 1. チャンク1でタイムスタンプ付き文字起こし(
audio_timestamp=True ) 2. 各話者の最適区間を選択(10-30秒) 3. ffmpegで音声切り出し → GCSにアップロード 4. チャンク2以降はアンカー音声と一緒にGeminiに送信 別案: 文脈による話者識別の修正 後処理で文脈から話者を推測・修正 ある程度はうまくいきそうだが、完全にLLMによる推測なので不安が残る これから試すこと 26
クラスメソッドで一緒に働きませんか? Google Cloud を使ったお客様支援 導入コンサルティング アーキテクチャ設計・構築 運用支援・最適化 技術ブログ発信文化 アウトプットを大切にする環境 年間数千本のテックブログ
エンジニアとしての成長 最新技術へのチャレンジ 興味のある方はお気軽にご連絡ください! Google Cloud エンジニア募集中! 27
ご清聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def validate_and_format(text: str) -> tuple[str, ValidationResult]: """出力を検証して品質判定""" lines = text.strip().split("\n")](https://files.speakerdeck.com/presentations/9f3a75eb2f6c44959684dd937e0d997c/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def split_audio_file(self, file_path: Path, output_dir: Path = None) -> List[Path]:](https://files.speakerdeck.com/presentations/9f3a75eb2f6c44959684dd937e0d997c/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}