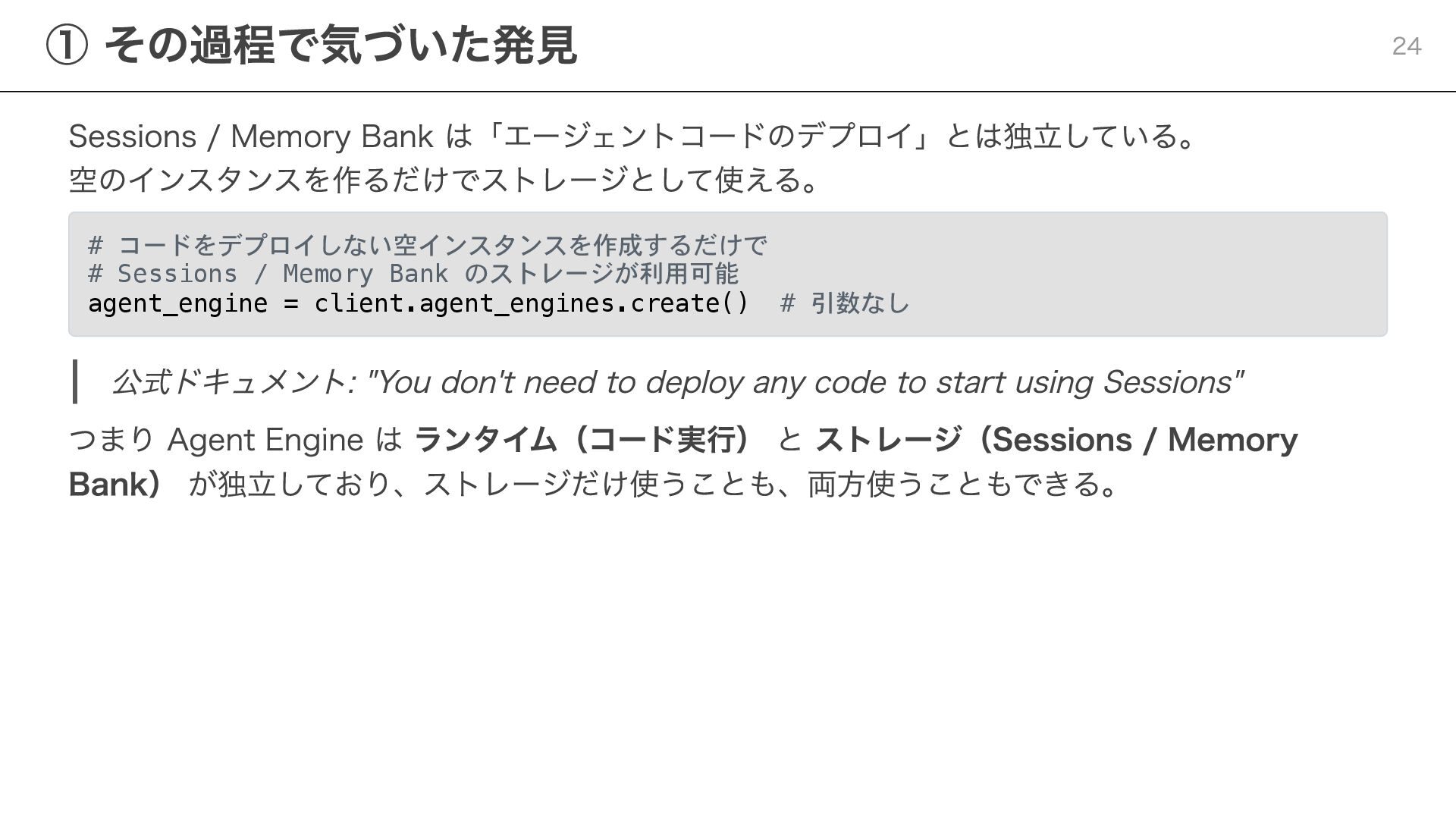
/ Memory Bank のストレージが利用可能 agent_engine = client.agent_engines.create() # 引数なし 公式ドキュメント: "You don't need to deploy any code to start using Sessions" つまり Agent Engine は ランタイム(コード実行) と ストレージ(Sessions / Memory Bank) が独立しており、ストレージだけ使うことも、両方使うこともできる。 ① その過程で気づいた発見 24
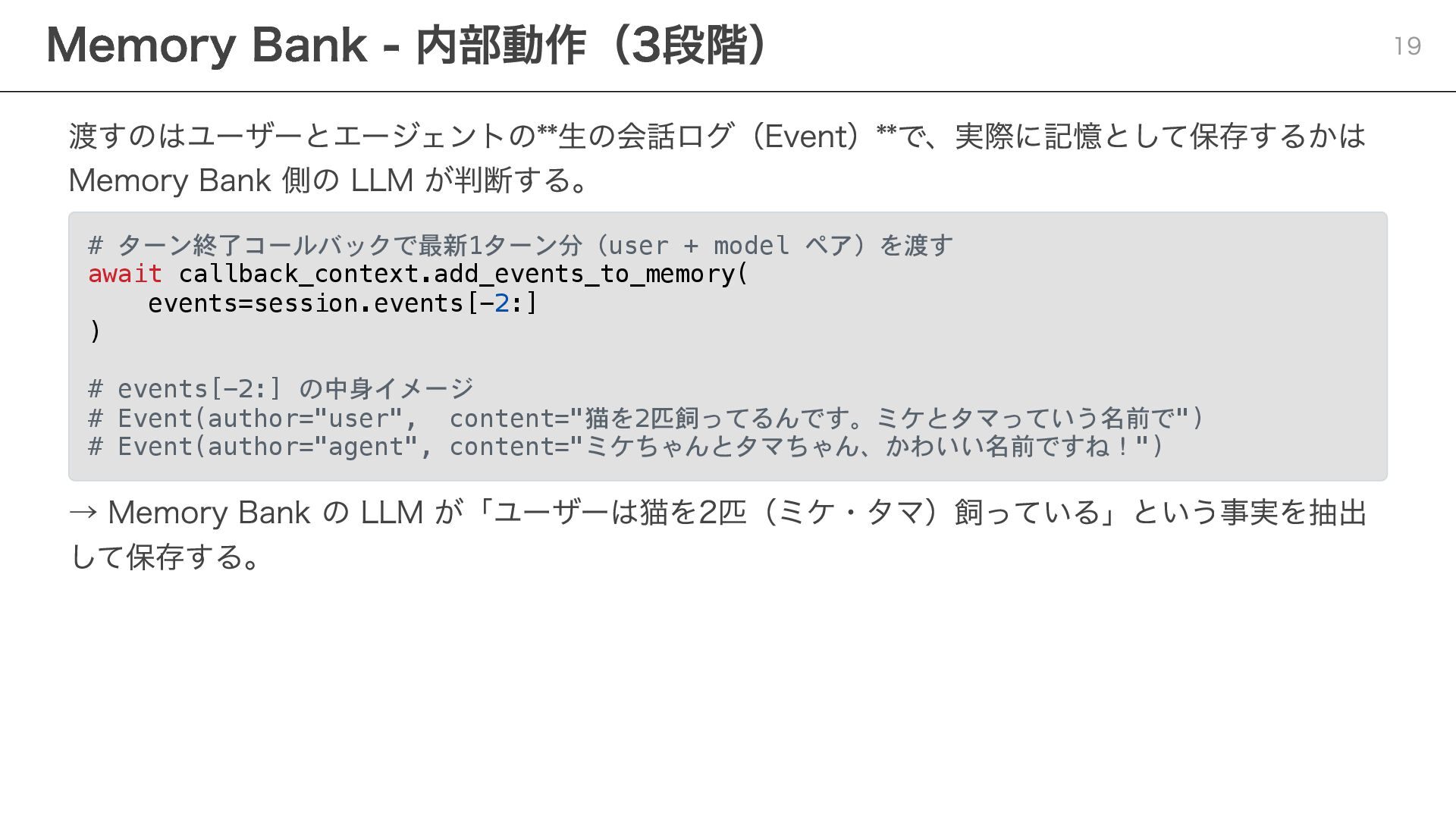
Memory Bank に送る方法 # ADK の想定パターン: 毎ターン終了後に会話を記憶として保存 async def after_agent(callback_context: CallbackContext): await callback_context.add_session_to_memory() ただし毎ターン Memory Bank に送ると、 GenerateMemories API が呼ばれるたびに Extraction LLM(Gemini 2.5 Flash Thinking On)が動き、トークン課金が発生する(GCP の課金 SKU で実際に確認済み) SKU 課金単位 memory bank Gemini 2.5 Flash GA Text Output (Thinking On) トークン数 memory bank memories stored in global メモリ数 × 月 memory bank memories retrieved in global 取得回数 Thinking On モデルは通常の Gemini より割高なため、毎ターン呼ぶと積み上がる。 ③ Memory Bank に保存できているのに読み込めなかった 27
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![セッションをまたいでユーザー情報を蓄積 内部動作: 抽出(Extraction)→ 統合(Consolidation)→ 非同期生成 PreloadMemoryTool : 毎ターン開始時に自動で記憶をシステムプロンプトに注入 LLMが受け取るイメージ: [MEMORY]](https://files.speakerdeck.com/presentations/c4f4b089f20e47378669c5dd0eb8129d/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
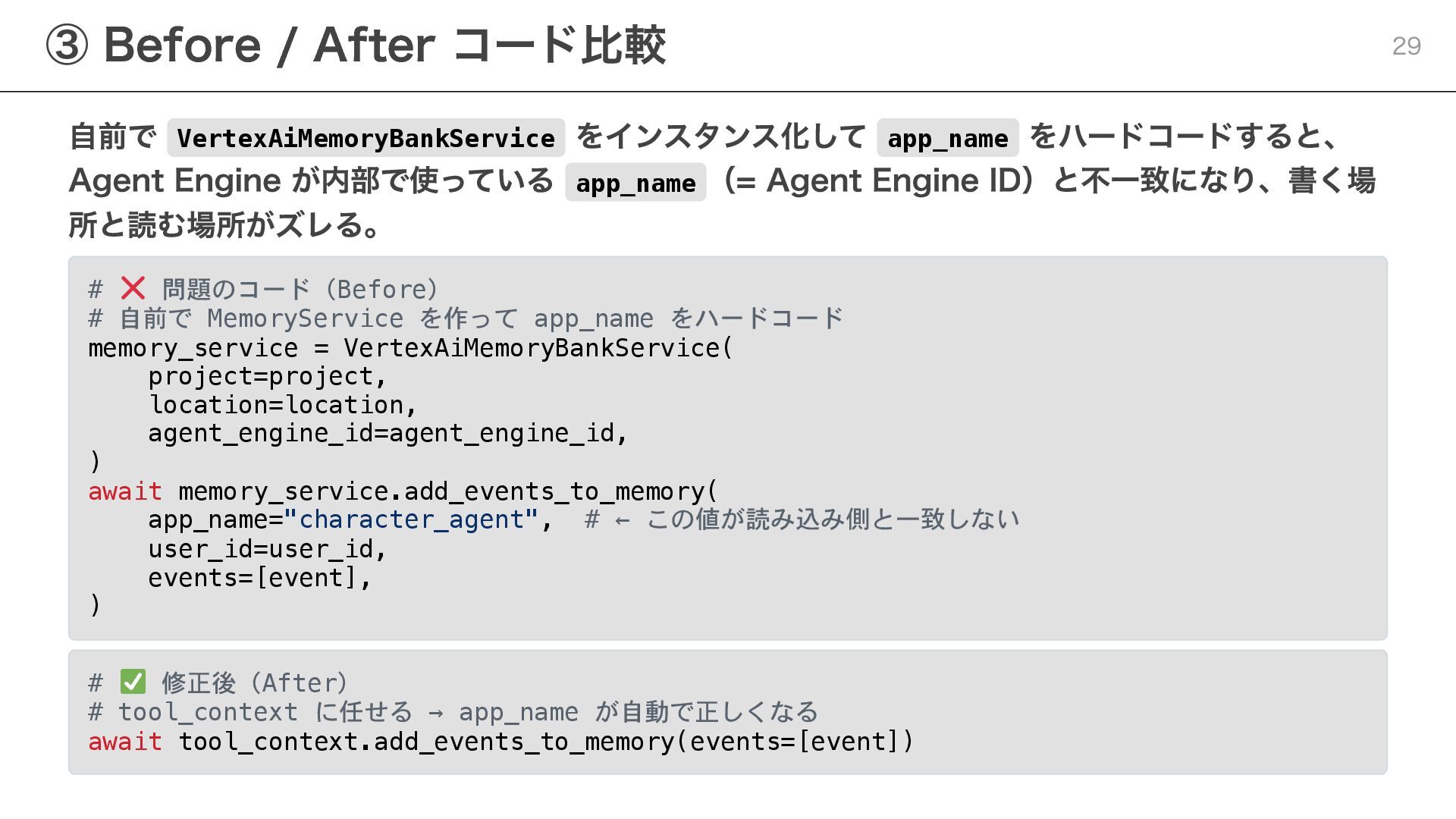{kind=link}
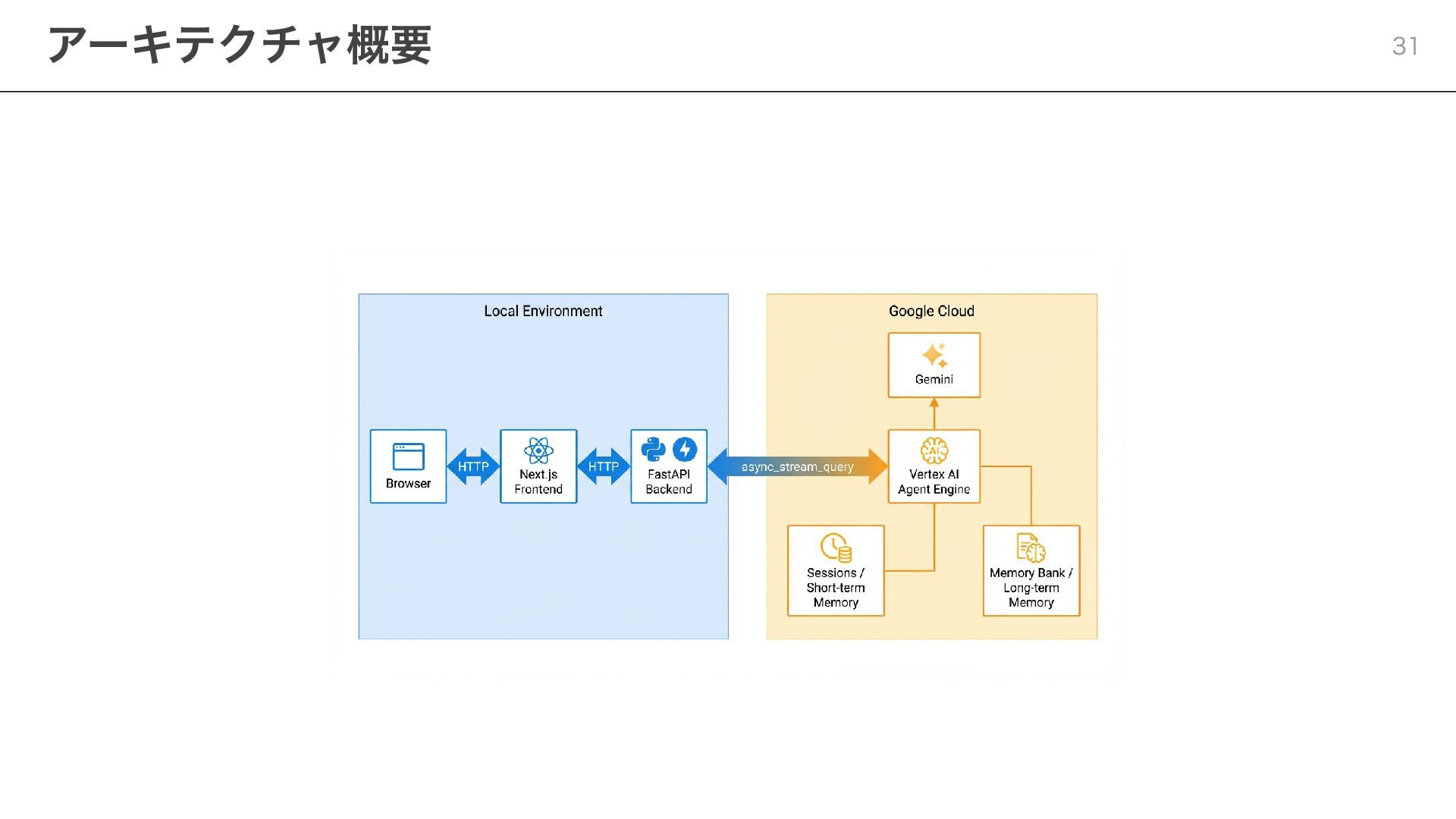
{kind=link}
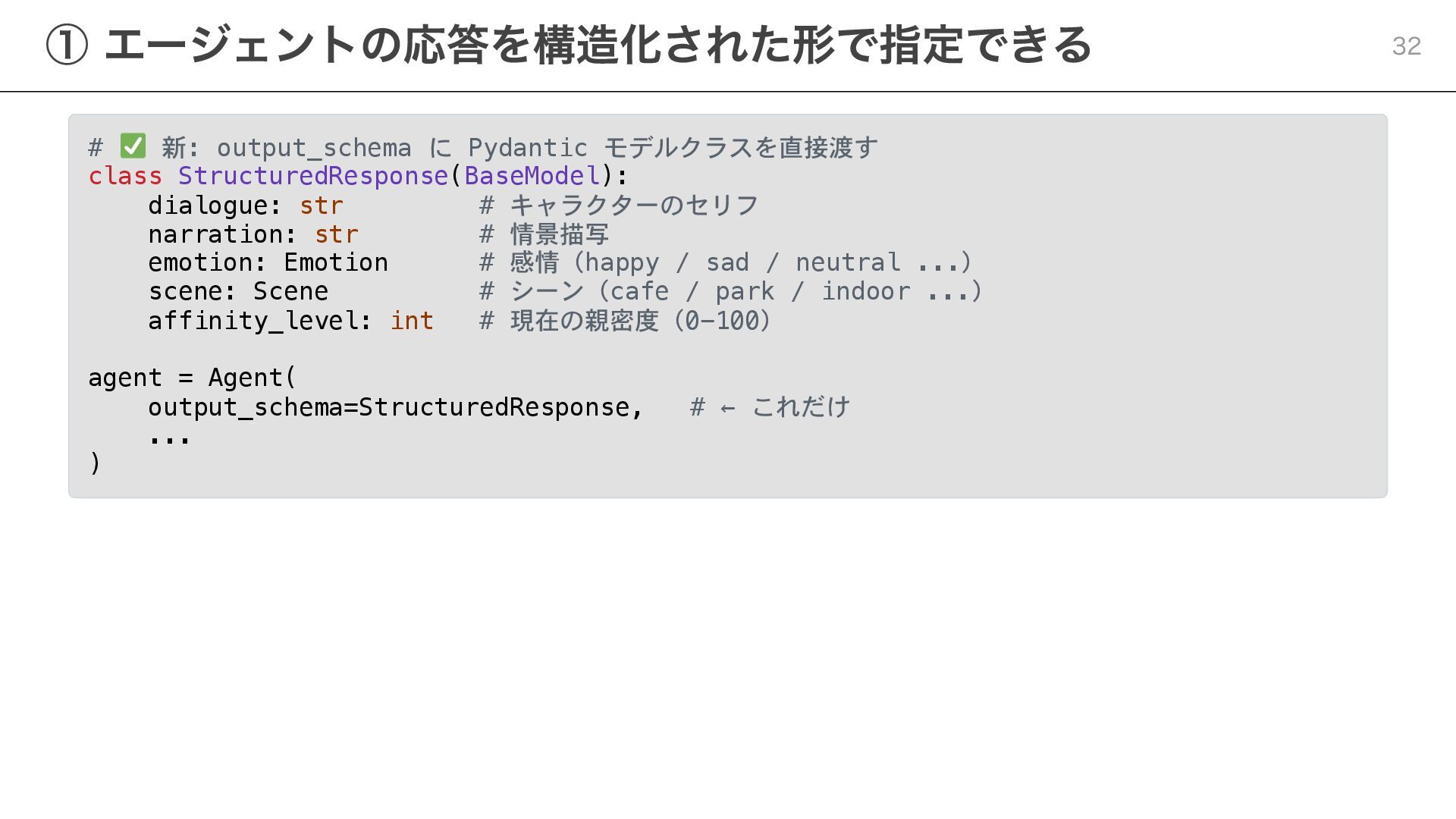
{kind=link}
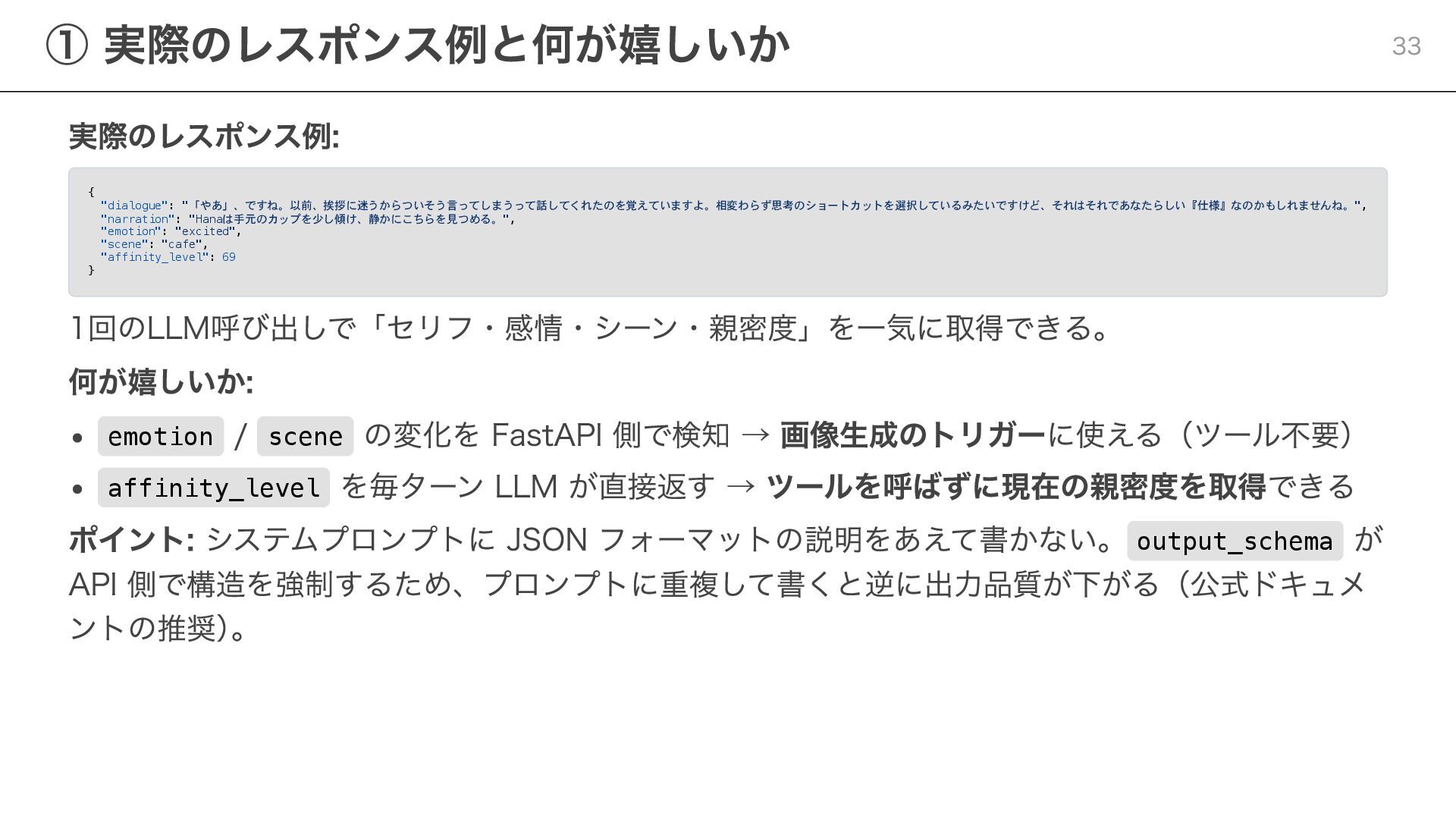
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}