Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
intro-paper_0928.pdf
Search
MARUYAMA
September 25, 2017
180
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
intro-paper_0928.pdf
MARUYAMA
September 25, 2017
More Decks by MARUYAMA
See All by MARUYAMA
vampire.pdf
tmaru0204
0
200
Misspelling_Oblivious_Word_Embedding.pdf
tmaru0204
0
210
Simple_Unsupervised_Summarization_by_Contextual_Matching.pdf
tmaru0204
0
200
Controlling_Text_Complexity_in_Neural_Machine_Translation.pdf
tmaru0204
0
180
20191028_literature-review.pdf
tmaru0204
0
160
Hint-Based_Training_for_Non-Autoregressive_Machine_Translation.pdf
tmaru0204
0
150
Soft_Contextual_Data_Augmentation_for_Neural_Machine_Translation_.pdf
tmaru0204
0
180
An_Embarrassingly_Simple_Approach_for_Transfer_Learning_from_Pretrained_Language_Models_.pdf
tmaru0204
0
170
Addressing_Trobulesome_Words_in_Neural_Machine_Translation.pdf
tmaru0204
0
180
Featured
See All Featured
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
240
Odyssey Design
rkendrick25
PRO
2
730
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
350
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Product Roadmaps are Hard
iamctodd
55
12k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.4k
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
390
Scaling GitHub
holman
464
140k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
Transcript
Sentence Alignment Methods for Improving Text Simplification Systems Sanja ˇStajner,
Marc Franco-Salvador, Simone Paolo Ponzetto, Paolo Rosso, Heiner Stuckenschmidt Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Short Papers), pages 97–102, July 30 - August 4, 2017. B4 丸⼭ 拓海
概要 Ø アライメント⼿法の提案 Ø 提案⼿法により、Newsela コーパスの⽂アライ メントをとり、平易化のためのデータセットを 構築 Ø 新たに構築されたデータセットを⽤いること
で、標準的なPB-SMTモデルでも、最先端の平易 化システムを上回る 1
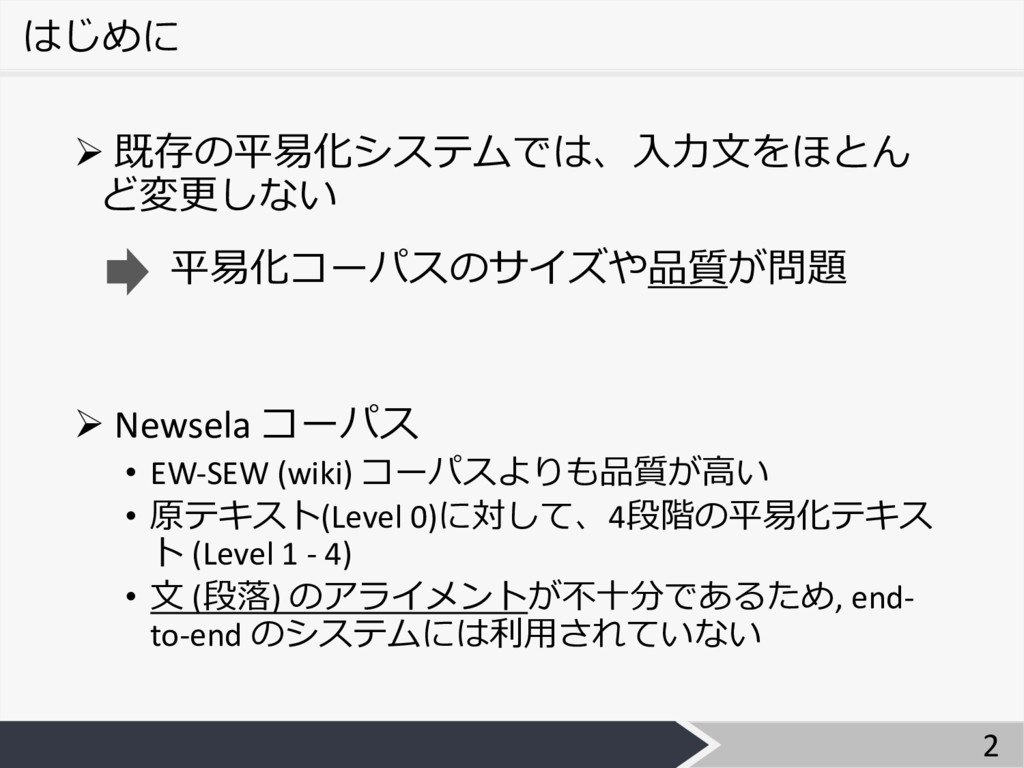
はじめに Ø 既存の平易化システムでは、⼊⼒⽂をほとん ど変更しない Ø Newsela コーパス • EW-SEW (wiki)
コーパスよりも品質が⾼い • 原テキスト(Level 0)に対して、4段階の平易化テキス ト (Level 1 - 4) • ⽂ (段落) のアライメントが不⼗分であるため, end- to-end のシステムには利⽤されていない 平易化コーパスのサイズや品質が問題 2
はじめに Øいくつかのアライメント⼿法の提案と⽐較 Ø 貢献 • Lexically-basedとSemantically-basedのアライメント⼿ 法を⽐較 • 「⼿作業による平易化において、元のテキストの順 序が保持される」という仮説を検証
• 標準的なPB-SMTモデルでも、新しいアライメント ⼿法により、 最先端の平易化システムに繋がる 3
⼿法 Øアライメント⼿法 • Most Similar Text (MST) • MST with
Longest Increasing Sequence (MST- LIS) Ø 類似度計算⼿法 • Character 3-Gram (C3G) • WAVG • Continuous Word Alignment-based Similarity Analysis (CWASA) 4
Øアライメント⼿法 • Most Similar Text (MST) • MST with Longest
Increasing Sequence (MST- LIS) ⽂間類似度を計算し, 平易⽂を最も近い難解⽂と対応 付ける MSTに 1-n対応(⽂分割)の処理を追加 仮説 平易化テキストは、原テキストの情報(順序)を保持し ている 5 ⼿法
Ø類似度計算⼿法 • Character 3-Gram (C3G) [Lexically-based] • WAVG [Semantically-based] •
Continuous Word Alignment-based Similarity Analysis (CWASA) [Semantically-based] TF – IDFによる重み付け Wikipediaからskip-gramにより, 単語の分散表現を獲得 単語ベクトルの平均を⽂ベクトルとする 全ての単語のコサイン類似度を計算することで, 最適な アライメントを⾒つける 6 ⼿法
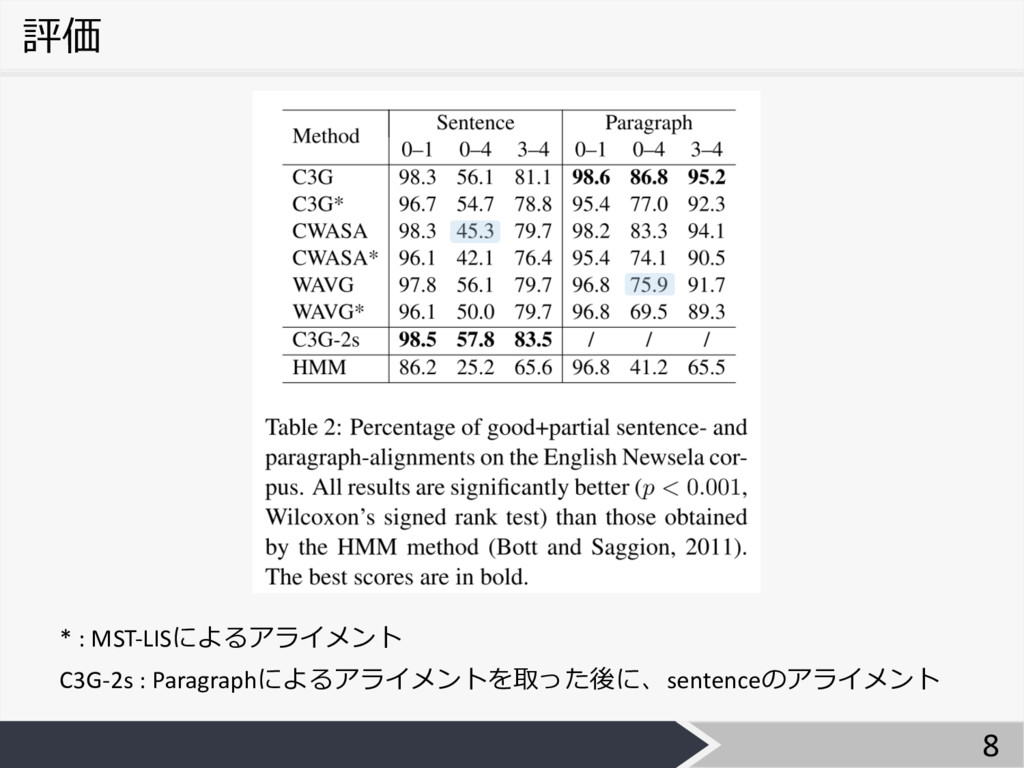
評価 ØNewselaコーパスからランダムに10テキスト選 択 (Level 0, 1, 3, 4)に6種類の⼿法を適⽤し⽐較 Ø ⼈⼿評価
• 3つのペア(0-1, 0-4, 3-4)に対し、2⼈のアノテータに より3段階の評価 0 : 意味的に全く⼀致しない 1 : 部分的に⼀致する (partial matches) 2 : 同じ意味である (good matches) 7
評価 * : MST-LISによるアライメント C3G-2s : Paragraphによるアライメントを取った後に、sentenceのアライメント 8
評価 Ø PB-SMTを利⽤した評価 • Training data • Tuning data, Test
data 9 (1) EW-SEW (wiki) (2) Newsela (neighboring levels, C3G-2s) + Wiki (3) Newsela (all levels, C3G-2s) + Wiki (4) Newsela (neighboring levels, HMM) + Wiki Amazon Mechanical Turkによって得られた8つの参照⽂ をもつデータセット
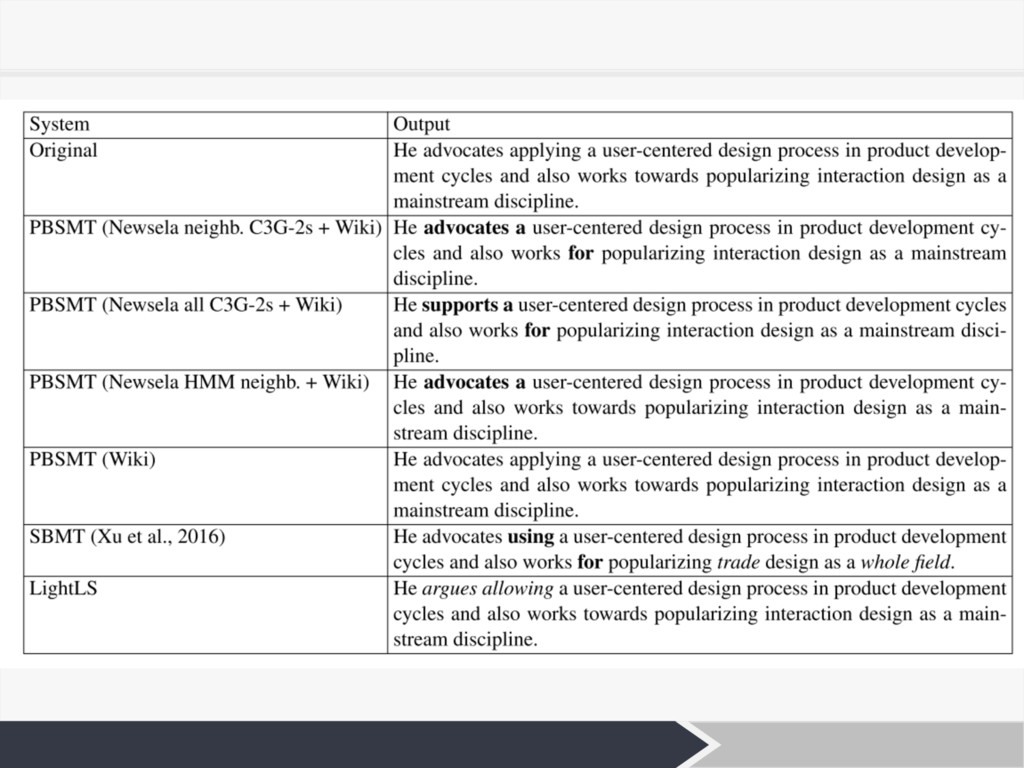
評価 Ø 機械翻訳を利⽤した評価 • Correctness and Number of Changes •
Grammaticality (G) and Meaning Preservation (M) − 1 〜 5の5段階でスコア付け • Simplicity of sentences (S) − -2 〜 +2の5段階でスコア付け 10
まとめ Ø ⽂(段落)のアライメント⼿法の提案 ØLevel 0-4のアライメントでは、Semantically- based(WAVG, CWASA)よりもLexically-based(C3G, C3G-2s)の⽅が優れている Ø新たなデータセットを加えることで標準的な PB-SMTモデルでも、最先端の平易化システムを
上回る 11
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Ø類似度計算⼿法 • Character 3-Gram (C3G) [Lexically-based] • WAVG [Semantically-based] •](https://files.speakerdeck.com/presentations/681e99f38ebf40d1b8ad9eec3a205060/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}