Data A. Conneau, D. Kiela, H. Schwenk, L. Barrault, and A. Bordes, Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 670–680, 2017. Nagaoka University of Technology Takumi Maruyama Literature review:
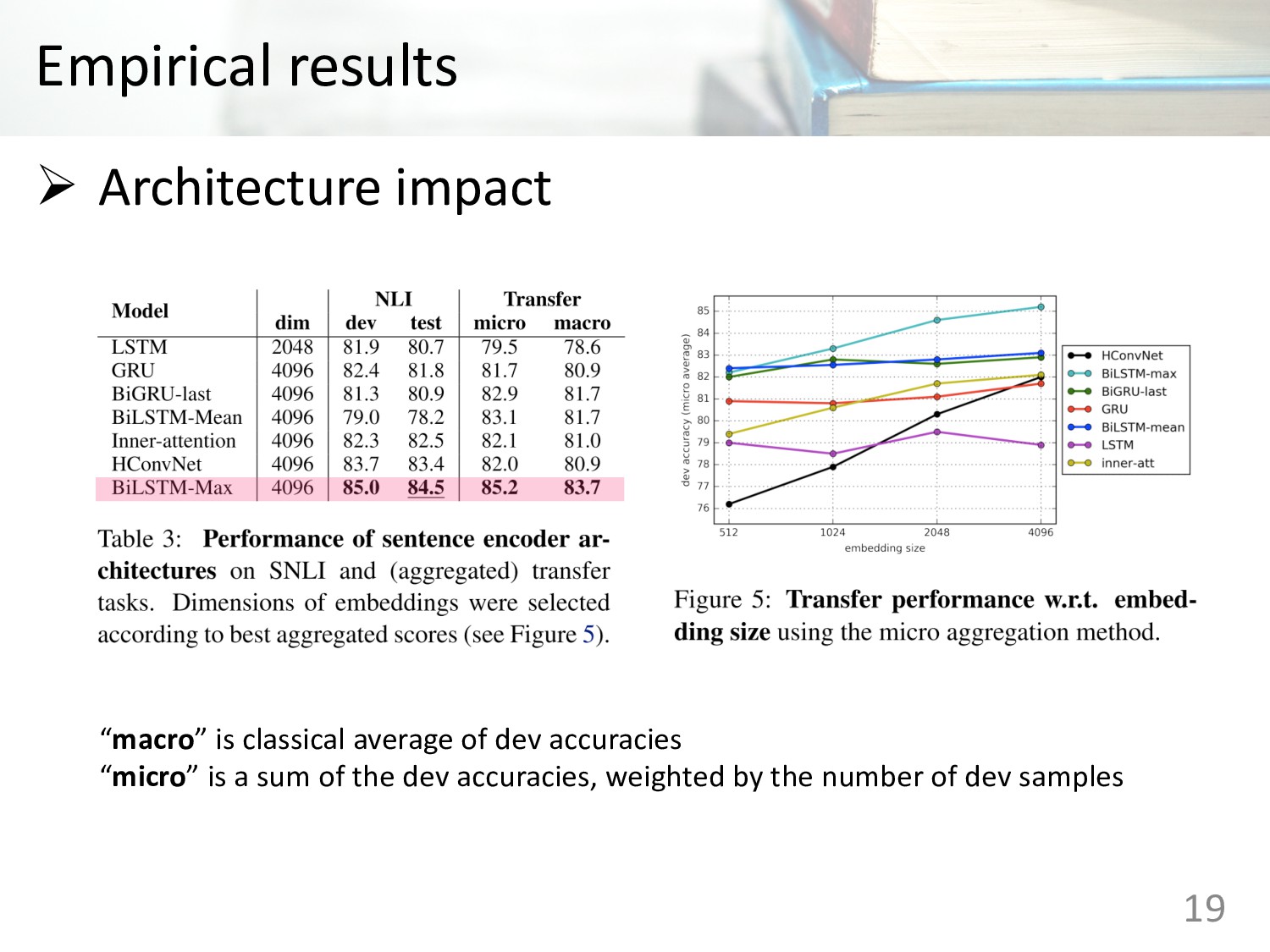
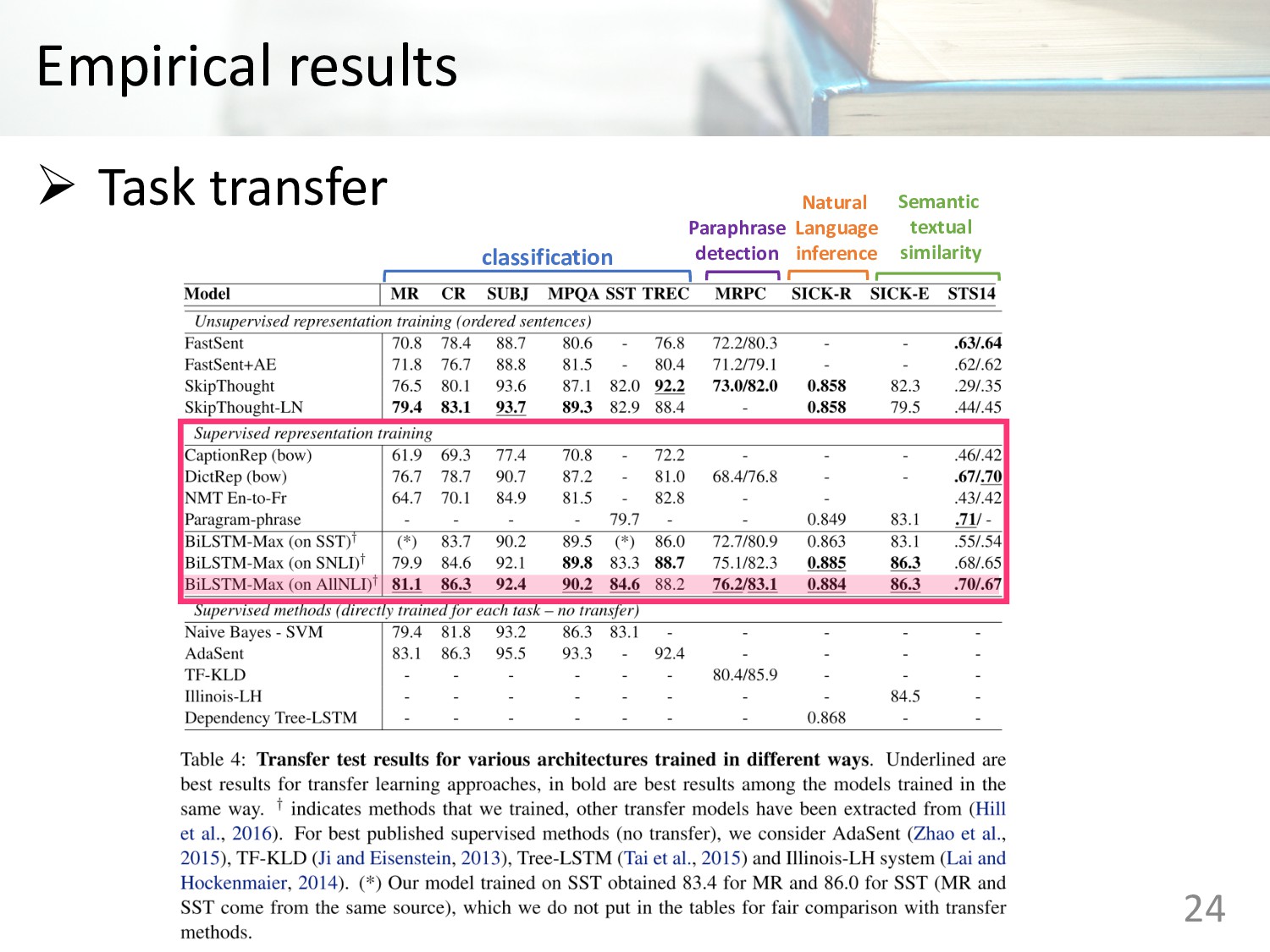
the supervised data of the Stanford Natural Language Inference datasets Ø Sentence embeddings with supervised data were tested on 12 different transfer tasks Ø BiLSTM network with max pooling makes the best current universal sentence encoding methods 2
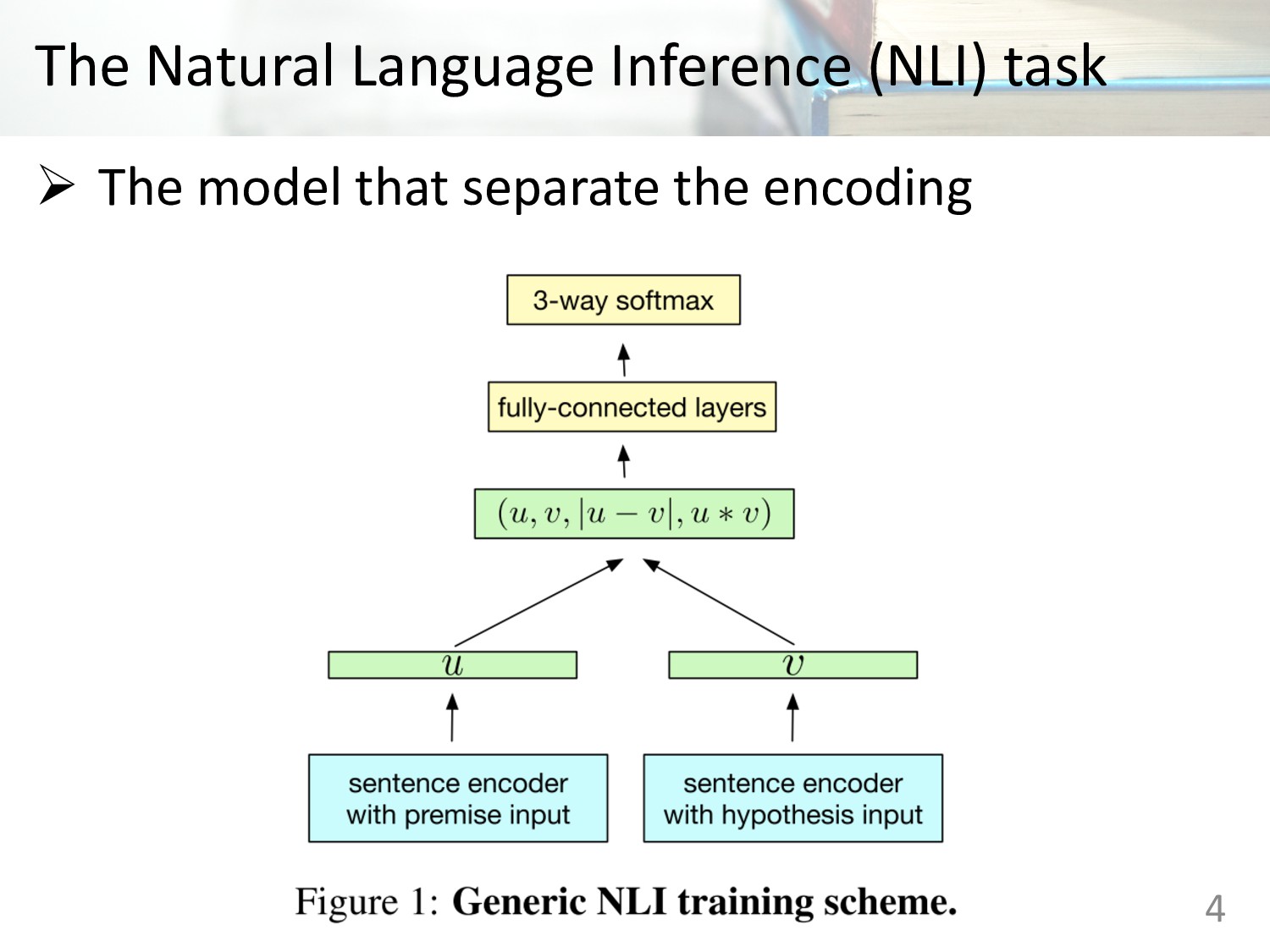
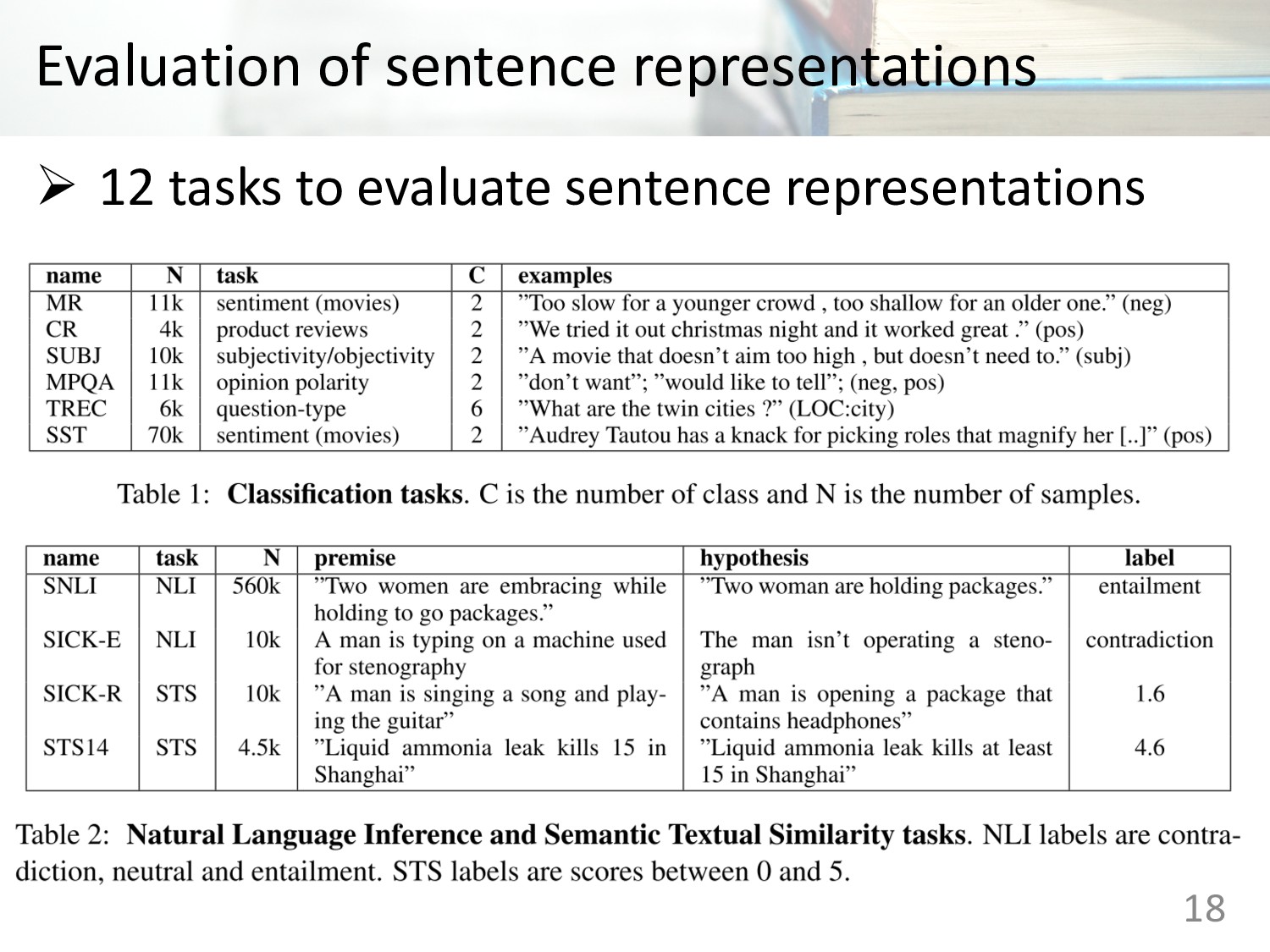
Inference (SNLI) dataset : • Consist 570k human-generated English sentence pairs • Manually labeled with one of three categories: entailment, contradiction and neutral https://nlp.stanford.edu/projects/snli 3
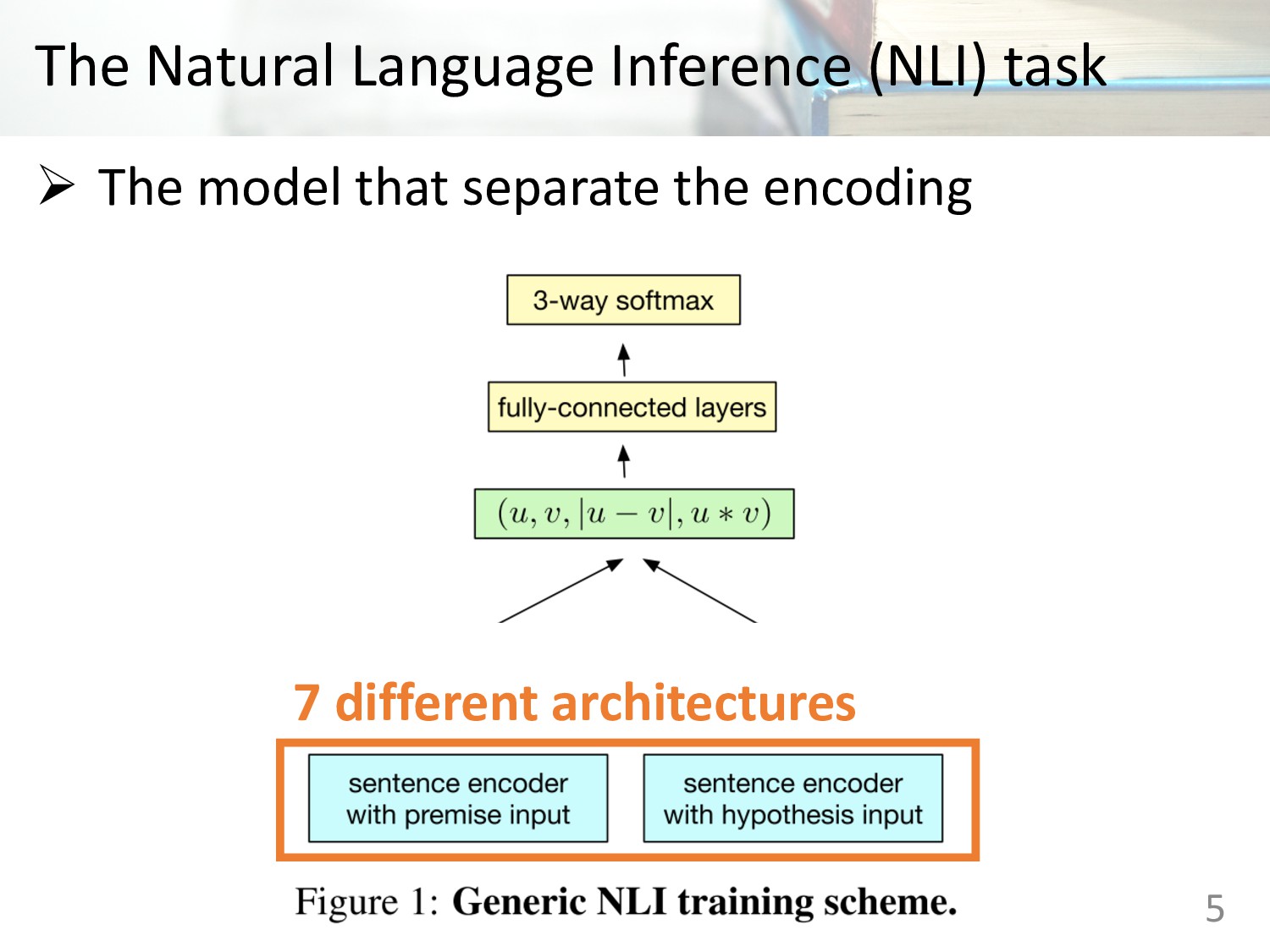
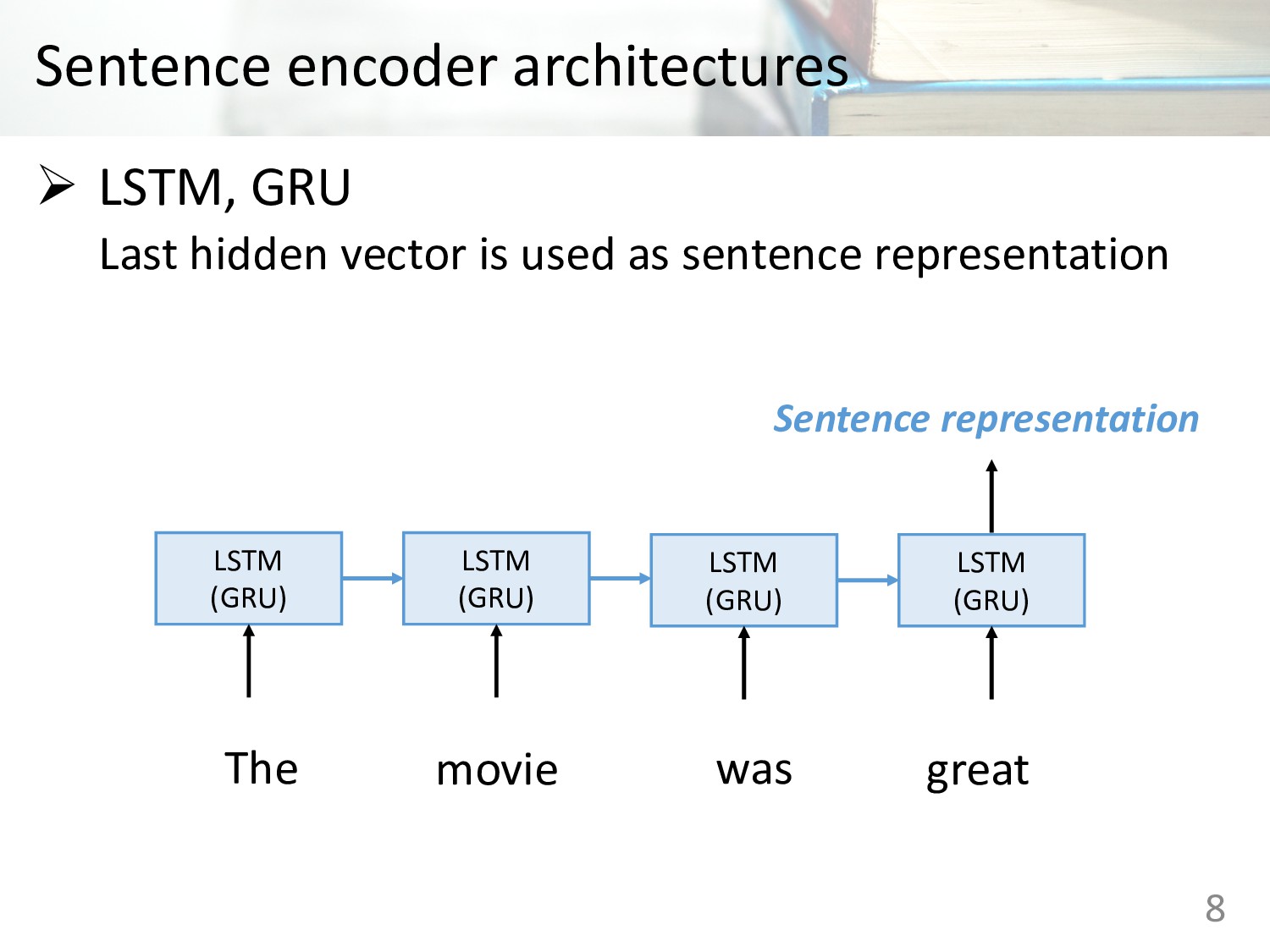
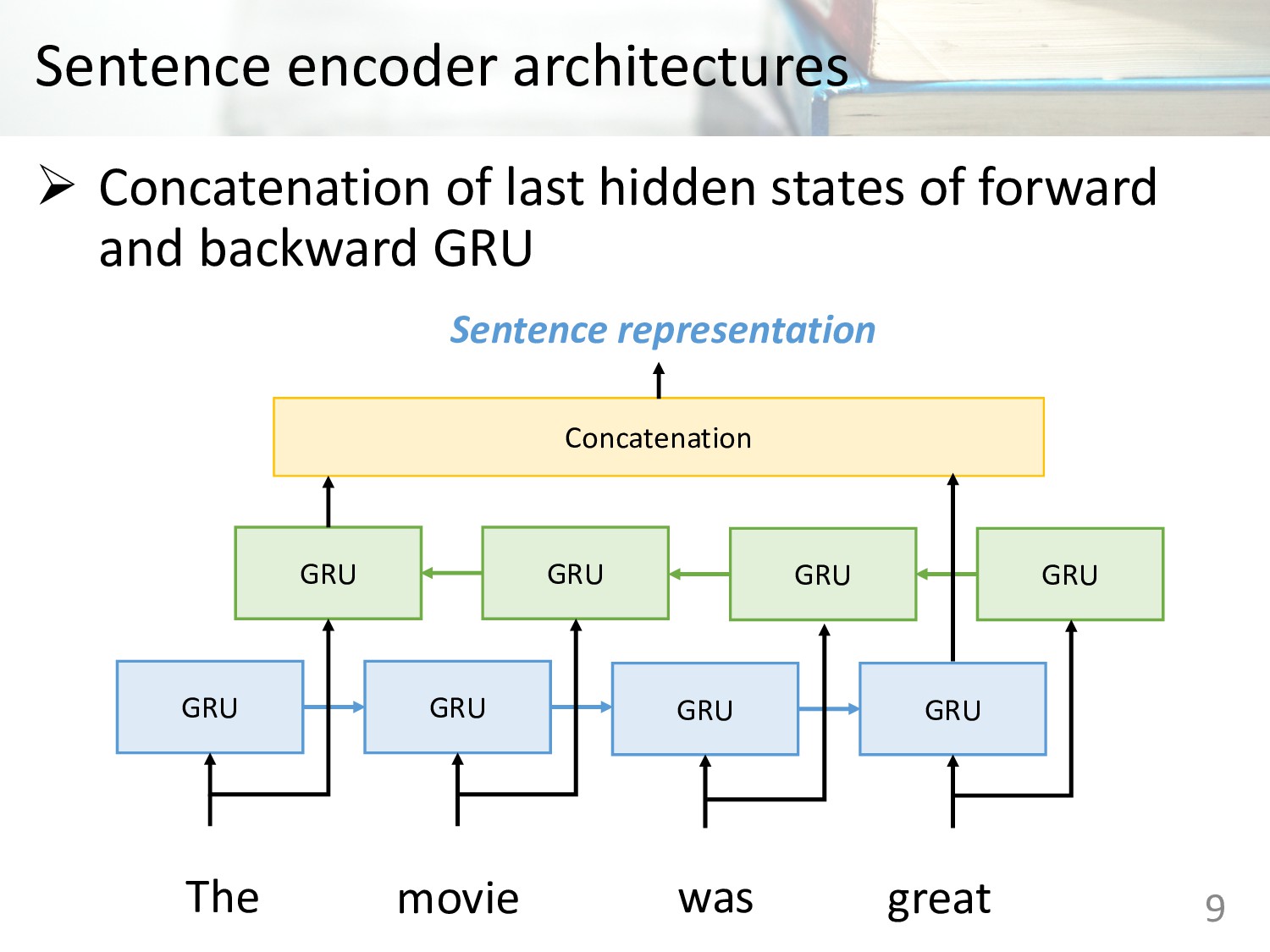
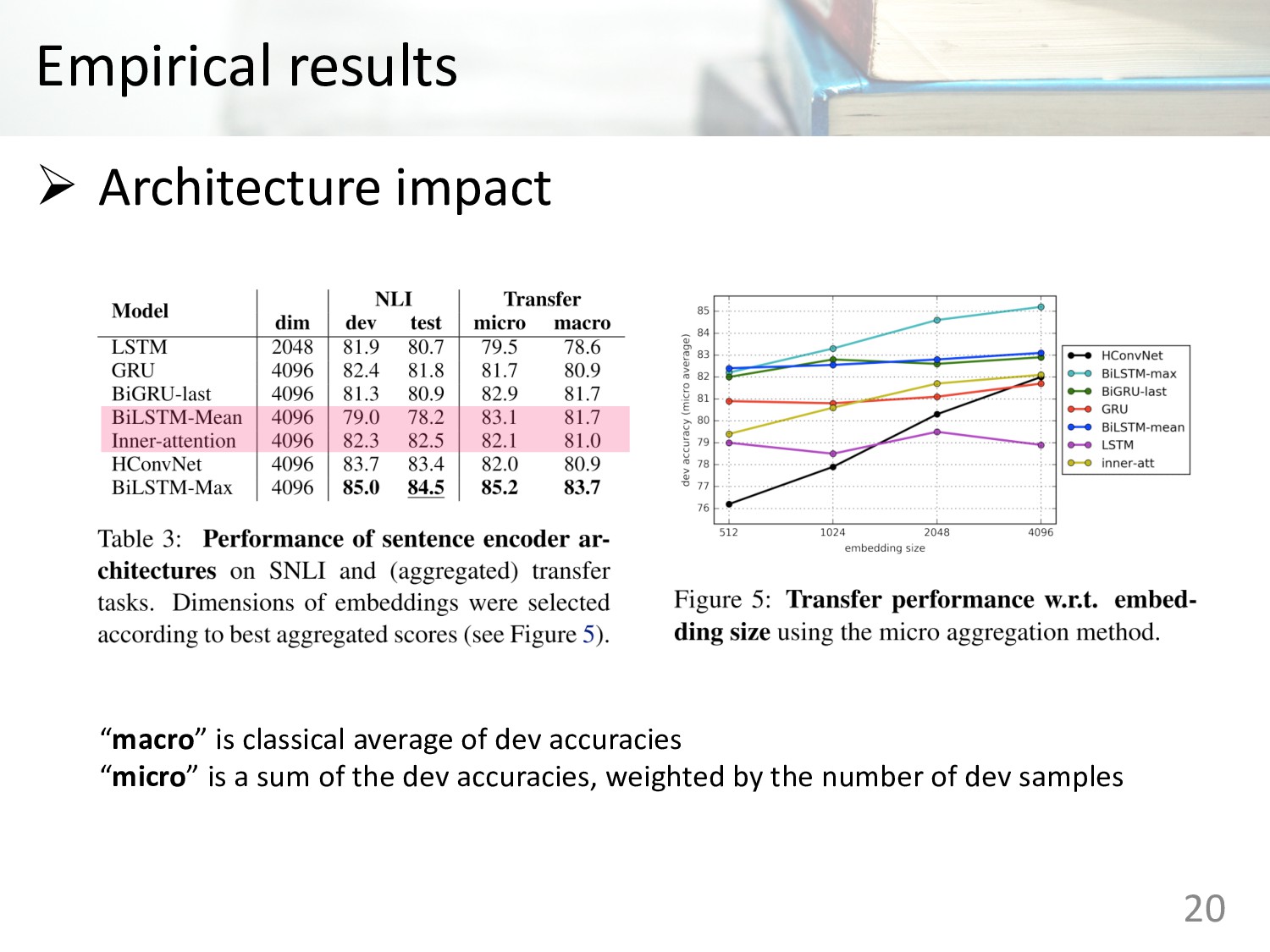
Memory (LSTM) • Gated Recurrent Units (GRU) • Concatenation of last hidden states of forward and backward GRU • Bi-directional LSTMs with mean pooling • Bi-directional LSTMs with max pooling • Self-attentive network • Hierarchical convolutional networks 6
Memory (LSTM) • Gated Recurrent Units (GRU) • Concatenation of last hidden states of forward and backward GRU • Bi-directional LSTMs with mean pooling • Bi-directional LSTMs with max pooling • Self-attentive network • Hierarchical convolutional networks 7
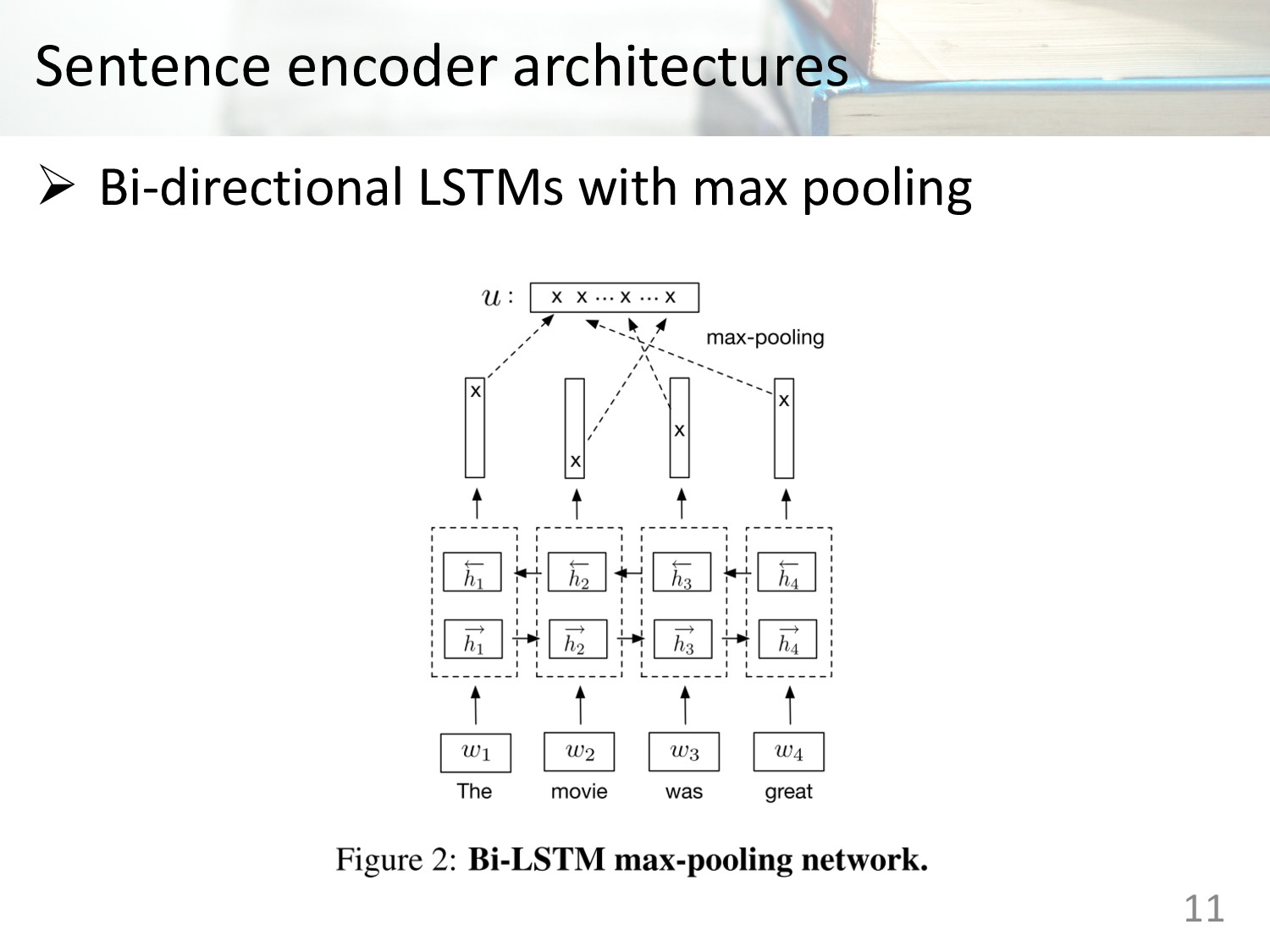
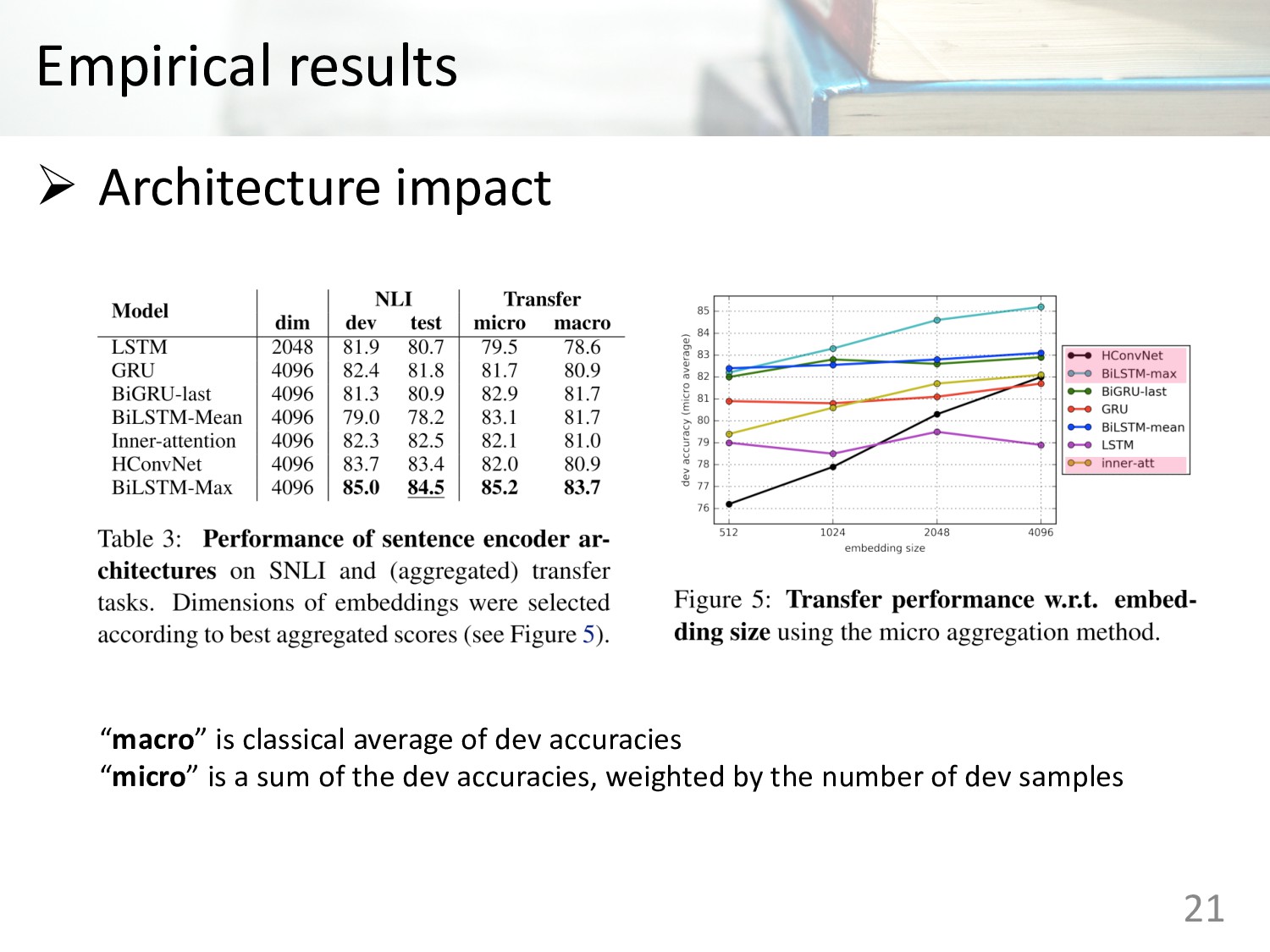
Memory (LSTM) • Gated Recurrent Units (GRU) • Concatenation of last hidden states of forward and backward GRU • Bi-directional LSTMs with mean pooling • Bi-directional LSTMs with max pooling • Self-attentive network • Hierarchical convolutional networks 10
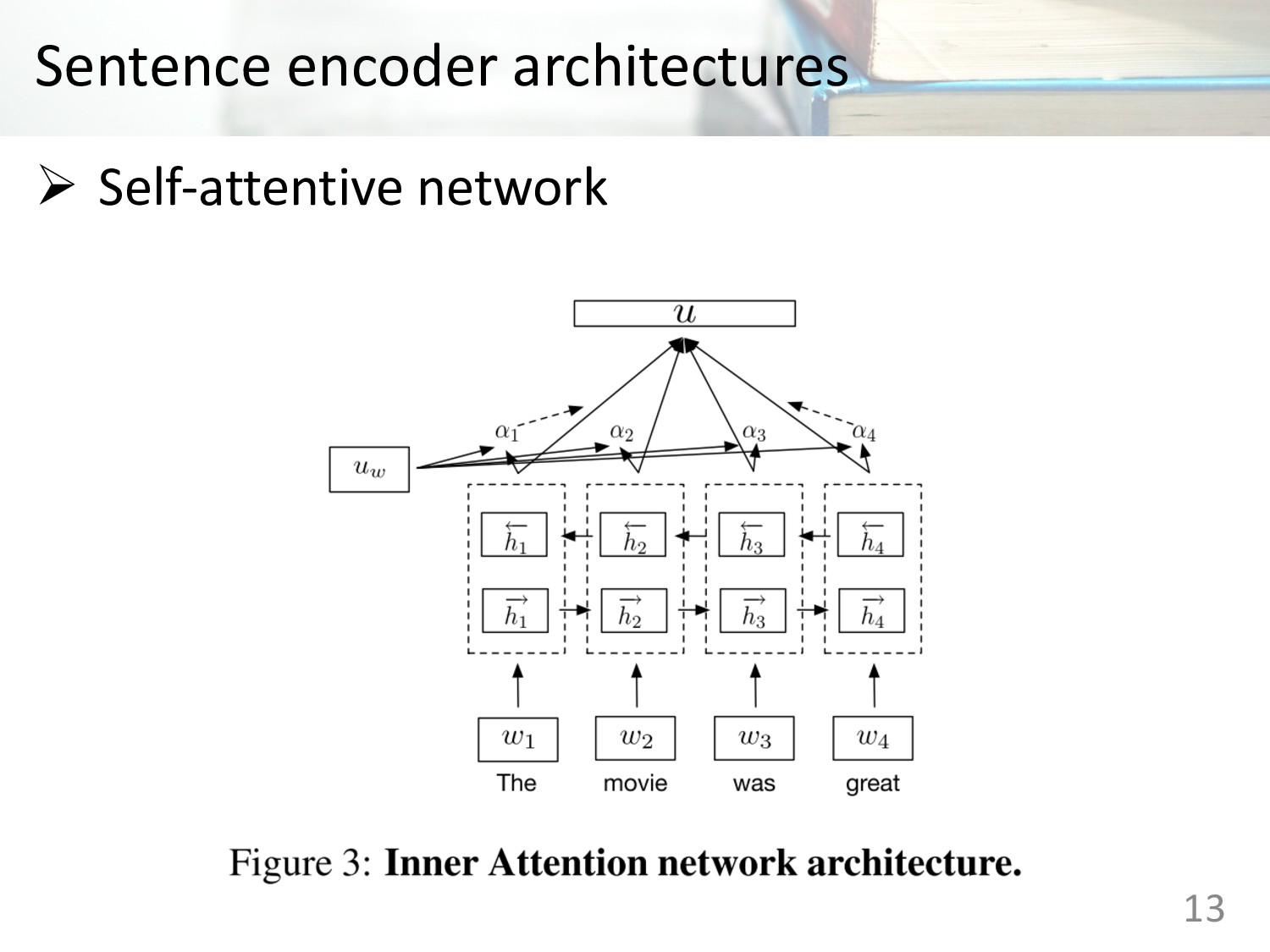
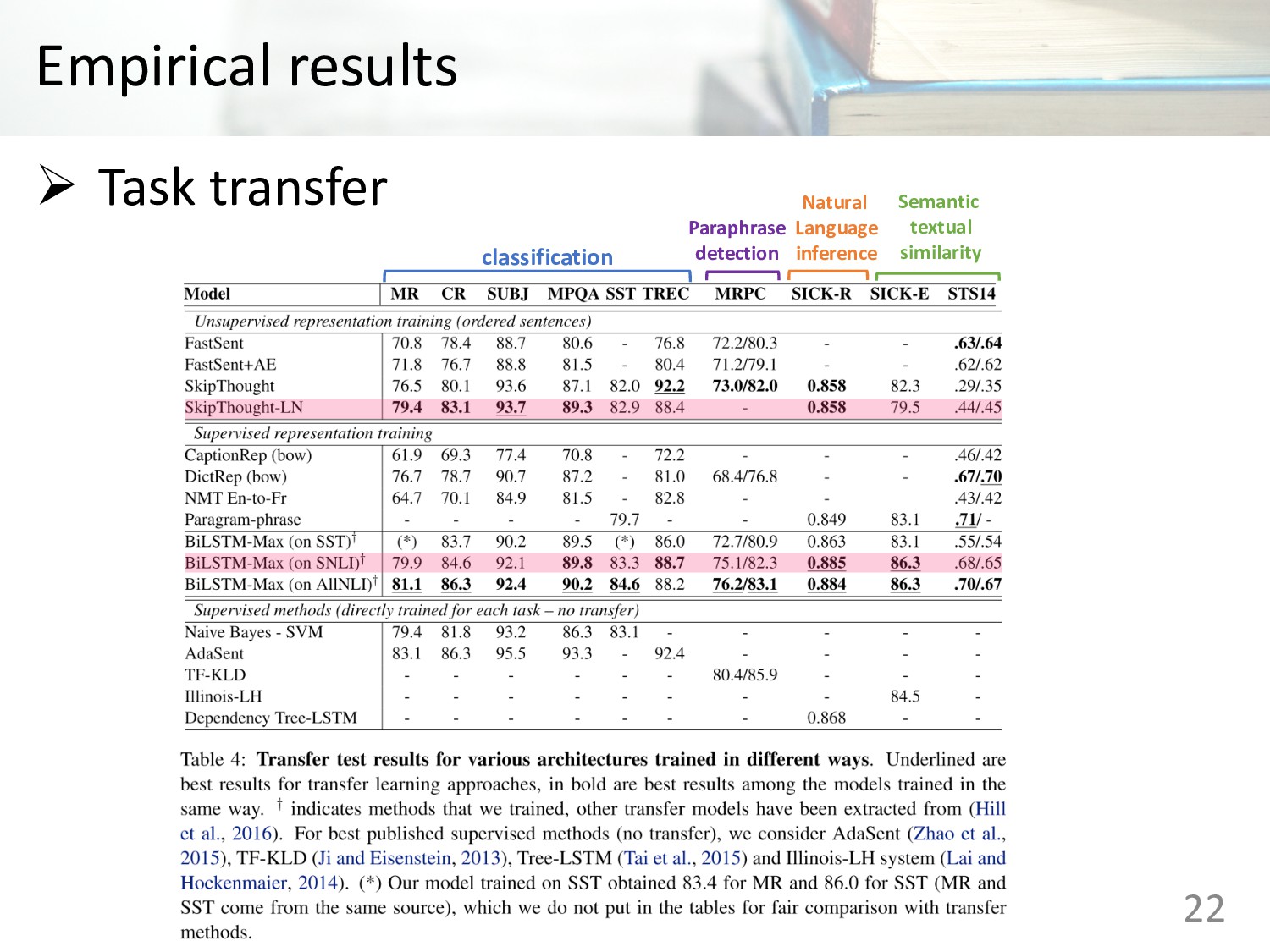
Memory (LSTM) • Gated Recurrent Units (GRU) • Concatenation of last hidden states of forward and backward GRU • Bi-directional LSTMs with mean pooling • Bi-directional LSTMs with max pooling • Self-attentive network • Hierarchical convolutional networks 12
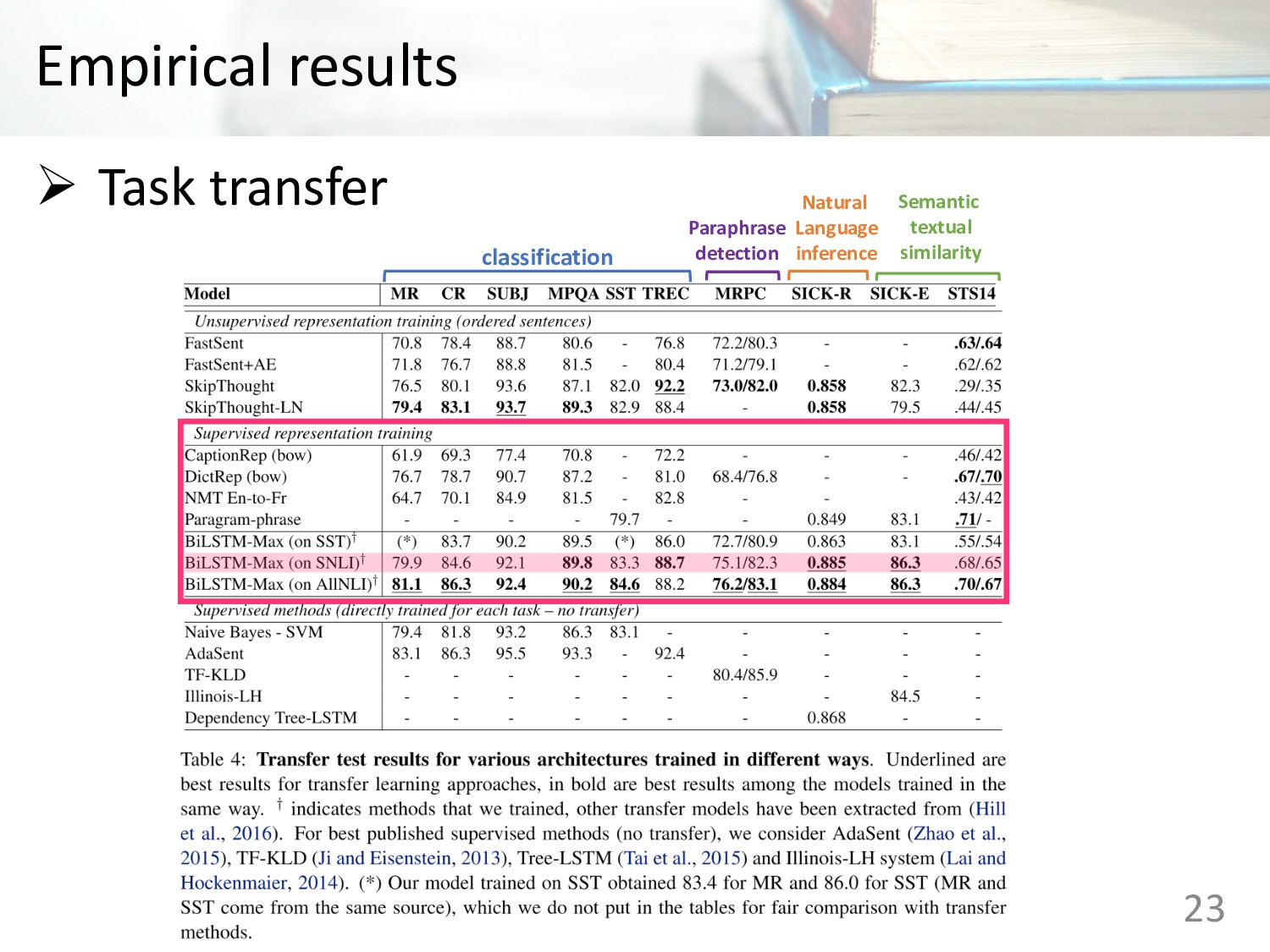
Memory (LSTM) • Gated Recurrent Units (GRU) • Concatenation of last hidden states of forward and backward GRU • Bi-directional LSTMs with mean pooling • Bi-directional LSTMs with max pooling • Self-attentive network • Hierarchical convolutional networks 14
the supervised data Ø Sentence embeddings with supervised data were tested on 12 different transfer tasks Ø BiLSTM network with max pooling makes the best current universal sentence encoding methods 25
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}