simpler substitutes Ø This paper proposed a complex word identification model and a simplification mechanism which relies on a word- embedding lexical substitution model. 2
simpler substitutes Ø This paper proposed a complex word identification model and a simplification mechanism which relies on a word- embedding lexical substitution model. 3 complex word identification
simpler substitutes Ø This paper proposed a complex word identification model and a simplification mechanism which relies on a word- embedding lexical substitution model. 4 Lexical substitution
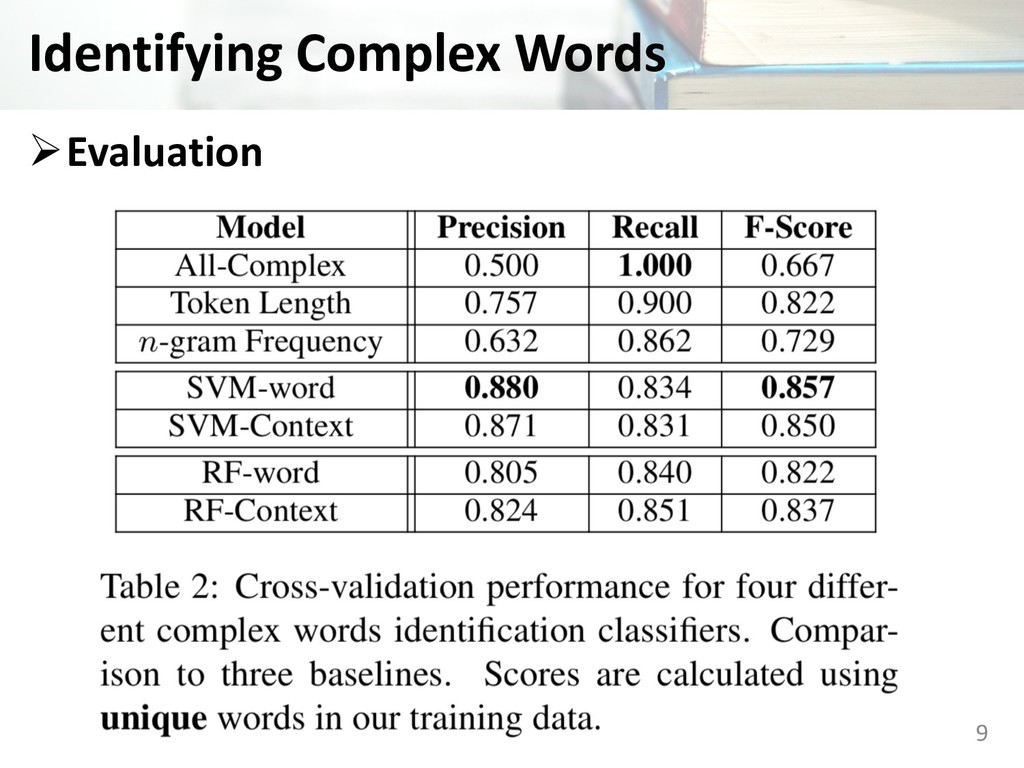
(Shardlow2013) • Random Forest Classifier (Shardlow2013) Ø Features • Word-specific feature: e.g.) Word length, Number of syllables, Word frequency (Google Web1T corpus), Number of WordNet synonyms • Context-specific feature: e.g.) Average length of words in the sentence, Average number of syllables, Average word frequency, Average number of WordNet synonyms, Sentence length 7
as complex • Token Length: thresholding for word length the length threshold with the best performance was 7 •n-gram Frequency: thresholding for word frequency using Google n-gram counts the frequency threshold with the best performance was 19,950,000 8
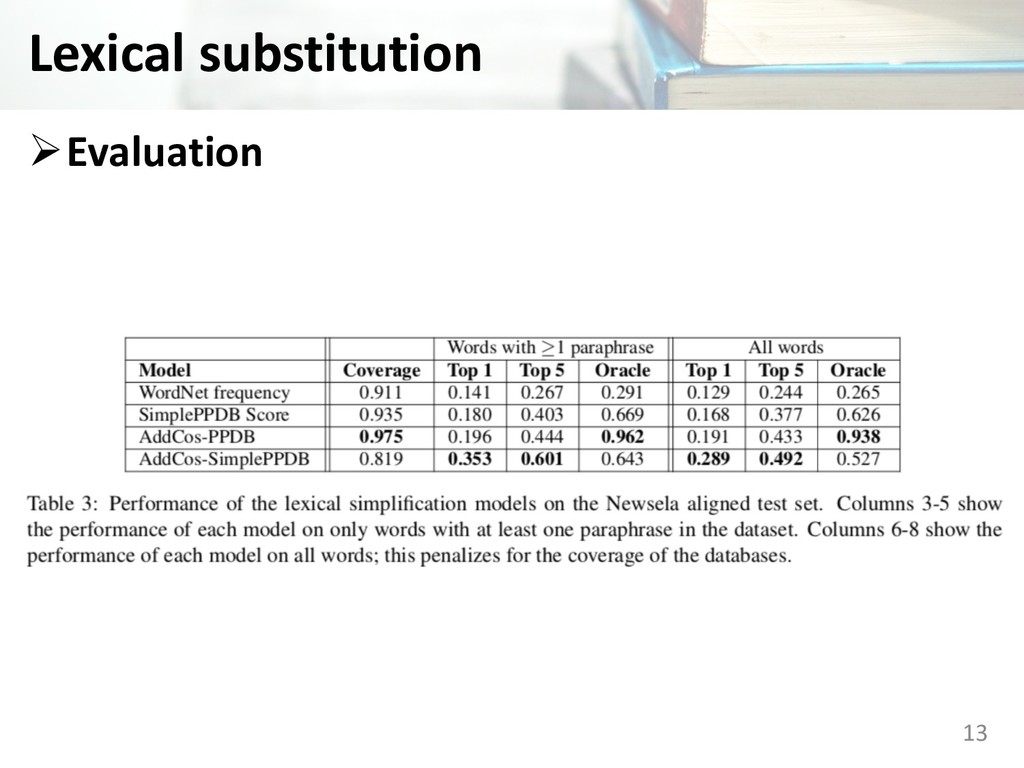
of a complex word are ranked in decreasing order of Google n-gram frequency • Simple PPDB Score: All SimplePPDB synonyms of a complex word are ranked in decreasing order of their SimplePPDB score 12
a simplification mechanism which relies on a word- embedding lexical substitution model. • Complex word identification: SVM-context • Lexical substitution: AddCos-SimplePPDB 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}