Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
WebRTC と AI の組み合わせ
Search
tnoho
October 22, 2024
Technology
1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
WebRTC と AI の組み合わせ
tnoho
October 22, 2024
More Decks by tnoho
See All by tnoho
WebRTC と Rust と 8K 60fps
tnoho
2
2.3k
P2P ではじめる WebRTC のつまづきどころ
tnoho
1
500
WebRTC の映像を Python から自由に加工する sora-python-sdk の仕組み
tnoho
0
2.1k
Other Decks in Technology
See All in Technology
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
2
530
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
260
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
480
StepFunctionsとGraphRAGを活用した暗黙知活用のためのRAG基盤
yakumo
0
140
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
810
文字起こし基盤の信頼性
abnoumaru
0
120
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
3
790
41歳でAWSが好きすぎてITエンジニアになったおっさんの話
yama3133
1
740
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
620
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
230
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.3k
JAWS_ICEBERG_BASECAMP
iqbocchi
2
110
Featured
See All Featured
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
160
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Ethics towards AI in product and experience design
skipperchong
2
330
Chasing Engaging Ingredients in Design
codingconduct
0
240
Code Review Best Practice
trishagee
74
20k
Speed Design
sergeychernyshev
33
1.9k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
420
YesSQL, Process and Tooling at Scale
rocio
174
15k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
Fireside Chat
paigeccino
42
4k
Marketing to machines
jonoalderson
1
5.6k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Transcript
WebRTC と AI の組み合わせ tnoho
ちょっとその前に
8K 対応 AV1 リアルタイムエンコーダー ミサオネットワーク社との共同開発 • 8K30fps / 4K 120fps
に対応 • HDMI 2.1 入力 • USB-PD でモバイルブースターで動作 • (高校生の)お弁当箱サイズ • もちろん WebRTC、しかも Chrome の WebRTC である libwebrtc 採用 • 8K30fps を WebRTC 配信サーバーで配信可能 Inter BEE 2024 (11/13-15) @幕張メッセ ミサオネットワークブースで展示いたします
8K をインターネットで配信?
30Mbps 15Mbps 7Mbps 3Mbps 1Mbps 512kbps
None
配信できそうでしょ? • 15Mbps でもまだ綺麗 • ここ1-2年で発売された PC は 8K 対応の
AV1 デコーダを搭載 (Intel N100 も!) • スマートフォンはまだ無理 • 3Mbps でも、何が写ってるかはわかる 16台の FullHD 監視カメラ映像を 3Mbps でブラウザに送れる!保存できる!(そのうち) Inter BEE 2024 (11/13-15) @幕張メッセ ミサオネットワークブースで展示します!( 2回目)
30Mbps Original
最強の WebRTC Native Client Momo!!!
WebRTC と AI の組み合わせ LTのタイムテーブル見る限り僕の喋ることは残ってないはず
自己紹介 tnoho ハードからソフトまで何でも屋 WebRTC Native Client Momo と Sora Python
SDK の原作者 時雨堂の中の人ではない
WebRTC と AI WebRTC = Web リアルタイムコミュニケーション • リアルタイムではなくなった瞬間に WebRTC
であるメリットは失われてしまう • 遅延して良いなら HLS の方がよっぽど扱いやすい • そして AI にもリアルタイム性が求められる
AI = NVIDIA? AI といえば NVIDIA と連想するのがかなり一般化しているが、 初期費用も運転費用も高価な GPU を使って採算がとれる世界は狭い
末端の機器で推論を行えば、このコストを軽減できるため エッジ AI が盛んに実装されている 同じ考えでブラウザで推論を行えばサーバー費用はモデルの転送量程度となる
画像認識機能を内蔵した監視カメラの映像を WebRTC で送るといった、 エッジ AI のインターフェイスに WebRTC を使うパターン これにより得られるメリット •
UI に Web ブラウザで作ることができる • 低レイテンシーで遠隔での応答速度をあげることができる エッジ AI に WebRTC AI WebRTC
エッジ AI に WebRTCの実現 WebRTC の映像音声データの他、エッジ AI の推論結果も WebRTC を介して送ることができる
DataChannel も使えるが映像や音声と推論結果やセンサーデータを同期させたくなるので、 WebRTC Encoded Transform でエンコード済みのフレームデータに入れ込むのもあり エッジ AI のソフトウェアに WebRTC を組み込む必要が生じるが、 そもそもエッジ AI を組めるような人には難しくない話 最近 C++ の軽量な WebRTC 実装けっこうあるもんね。 え、 Python でパワーでなんとかした?まぁ、最近エッジ機器も強力だもんね・・・
AI データセンターに WebRTC AI データセンターとのインターフェイスに WebRTC を使うという用途も考えられる • 生成AIを使った対話システム •
音声認識を使った字幕 などはエッジでは十分な性能が得られずリアルタイム性が要求されるため、 推論を行うサーバーとの通信に WebRTC を利用するメリットは大きい 特にUI にブラウザが使えるのは作り易く、利用者も利用しやすい WebRTC AI
AI データセンターに WebRTC の実現 ブラウザやクライアント機器から WebRTC で受け取った映像や音声を推論にかけることとなる インターフェイス自体は様々な方法がある(僕が作った Sora Python
SDK を使うのもよし) ただし、AI データセンター側ではかなり厳しいコストとの戦いが待っている リアルタイム性を維持するためには映像や音声を接続中は常時推論にかけるしかないが、 そうするとお金が常時溶けている状態になってしまうので工夫が必要 キーワードで起動するとか、無音時間は削るとか・・・
AI データセンターに WebRTC の実例 TMPS 社製 WebRTC 会議システム WebMeeting Software
Suite には音声認識機能があり、 このケースに該当しているので以下の方法でコストを減らしている • ユーザーがリクエストを送ると AWS Fargate でコンテナを立ち上げ受信を開始する ◦ サーバーサイドで WebRTC を受信してデコードしてあげないと音声認識に回せない辛さ ◦ それなりにCPUを使うのでリソースを確保しておくのにもコストがかかるので仕組みで改善 • 発話区間検出(VAD)を行い音声があった分だけ音声認識に送信 ◦ 誰も喋っていない音声データまで音声認識に送ってしまうとコストが余計にかかるので ◦ え、 Sora Python SDK に VAD 機能がある?つまりそういうことだよ。
WebRTC にエッジ AI WebRTC の映像音声通信の向上に AI を使うパターンは以下が挙げられる • 仮想背景 •
ノイズキャンセリング • 音声認識 • 圧縮コーデック これらはブラウザ内、もしくはクライアントアプリケーションとして実装されるエッジ AI となる また、一部ブラウザのノイズキャンセリングは RNNoise が使われているので AI を使っている WebRTC AI
WebRTC にエッジ AI の実現 ブラウザやクライアントアプリケーションの実行環境に十分な性能があるかわからない難しさ なるべく多くの環境をカバーするためには • AI モデル自体の軽量化 •
前処理、後処理の高速化 などが必要になるが、これには多大な投資を要する。 また、苦労して作ったモデルをクライアントに入れる必要があるため、単体でのビジネスは困難
WebRTC にエッジ AI の実例 WebRTC でエッジ AI といえば仮想背景! でも、超大企業以外は Google
の Selfie Segmentation を使っている https://research.google/blog/background-features-in-google-meet-powered-by-web-ml/ さらっと書かれている以下の一文をやるコストが高すぎる
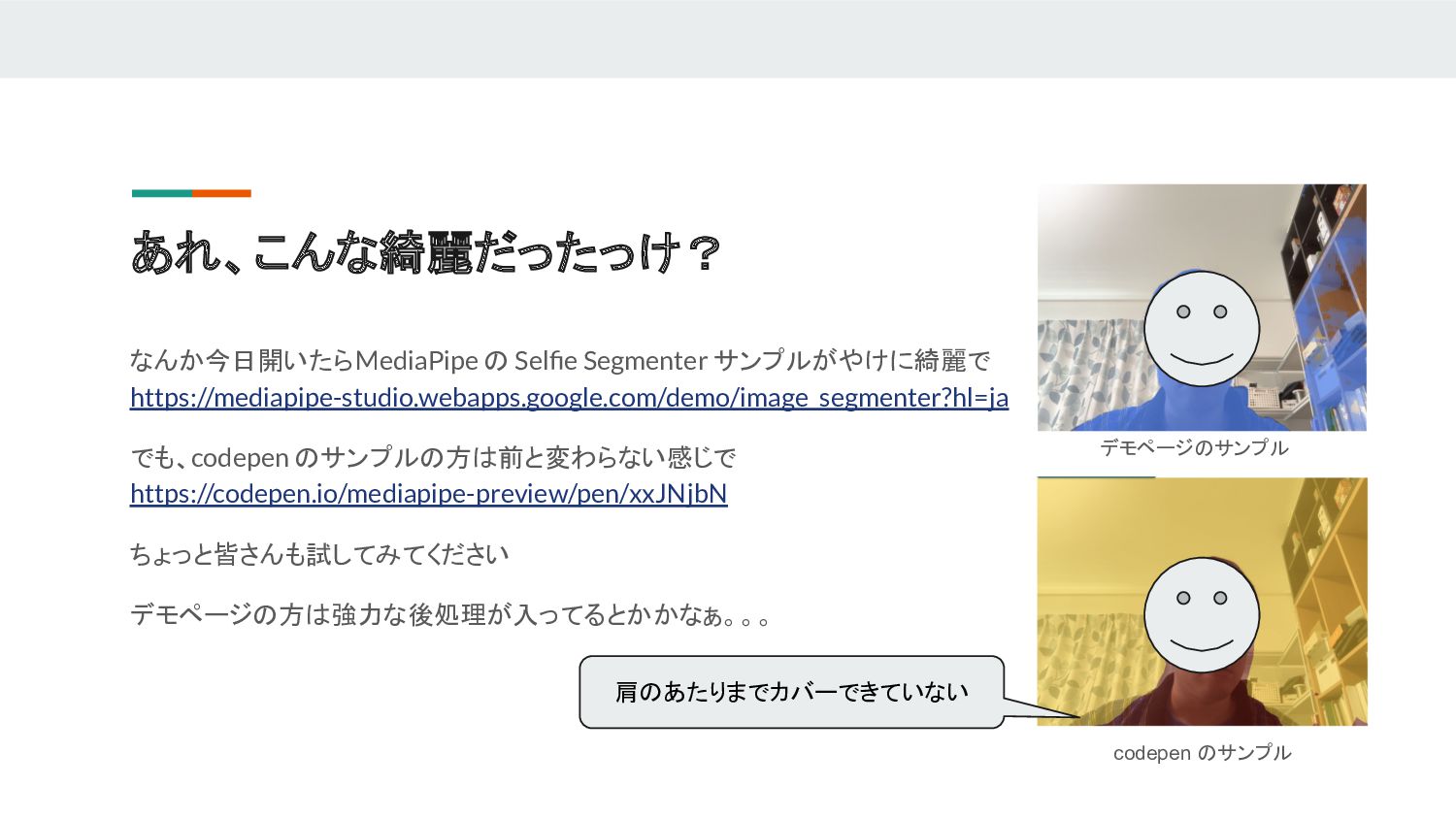
あれ、こんな綺麗だったっけ? なんか今日開いたら MediaPipe の Selfie Segmenter サンプルがやけに綺麗で https://mediapipe-studio.webapps.google.com/demo/image_segmenter?hl=ja でも、codepen のサンプルの方は前と変わらない感じで
https://codepen.io/mediapipe-preview/pen/xxJNjbN ちょっと皆さんも試してみてください デモページの方は強力な後処理が入ってるとかかなぁ。。。 デモページのサンプル codepen のサンプル 肩のあたりまでカバーできていない
Selfie Segmenter の後処理 先の通り機械学習モデルは横並びで同じのをどこも使っています。 でも、Google さんは後処理の内容は記事にしてくれたのですが、 後処理自体はオープンソースにされませんでした。 というわけで、同じモデルを使っていても後処理で結構差があります。 WebMeeting Software
Suite の後処理は気合い入れて作ってあるので、 Google さんのデモページに近い感じですね。後処理同じっぽい。 WebMeeting Software Suite の仮想背景
まとめ 個人的な肌感覚では単体でビジネスとして成立しているエッジ AI のインターフェイスに WebRTC を組み合わせ るという用途以外ではビジネス的にはかなり難しい そもそもリアルタイム性のある AI の開発に非常にコストがかかり、
加えてリアルタイムのため要求リソースも多く占有時間も長くなりがちなためにコストがかかる “作ってみてできた” と “ビジネスとして成立する ” の距離がかなり遠いのでは
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}