Share
2026/5/28 19:00 ~ 21:00 「AIエージェント設計勉強会 〜long-runningタスクの設計と実践知〜」登壇資料 https://layerx.connpass.com/event/391940/ https://engineersguildvol10.peatix.com/view
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
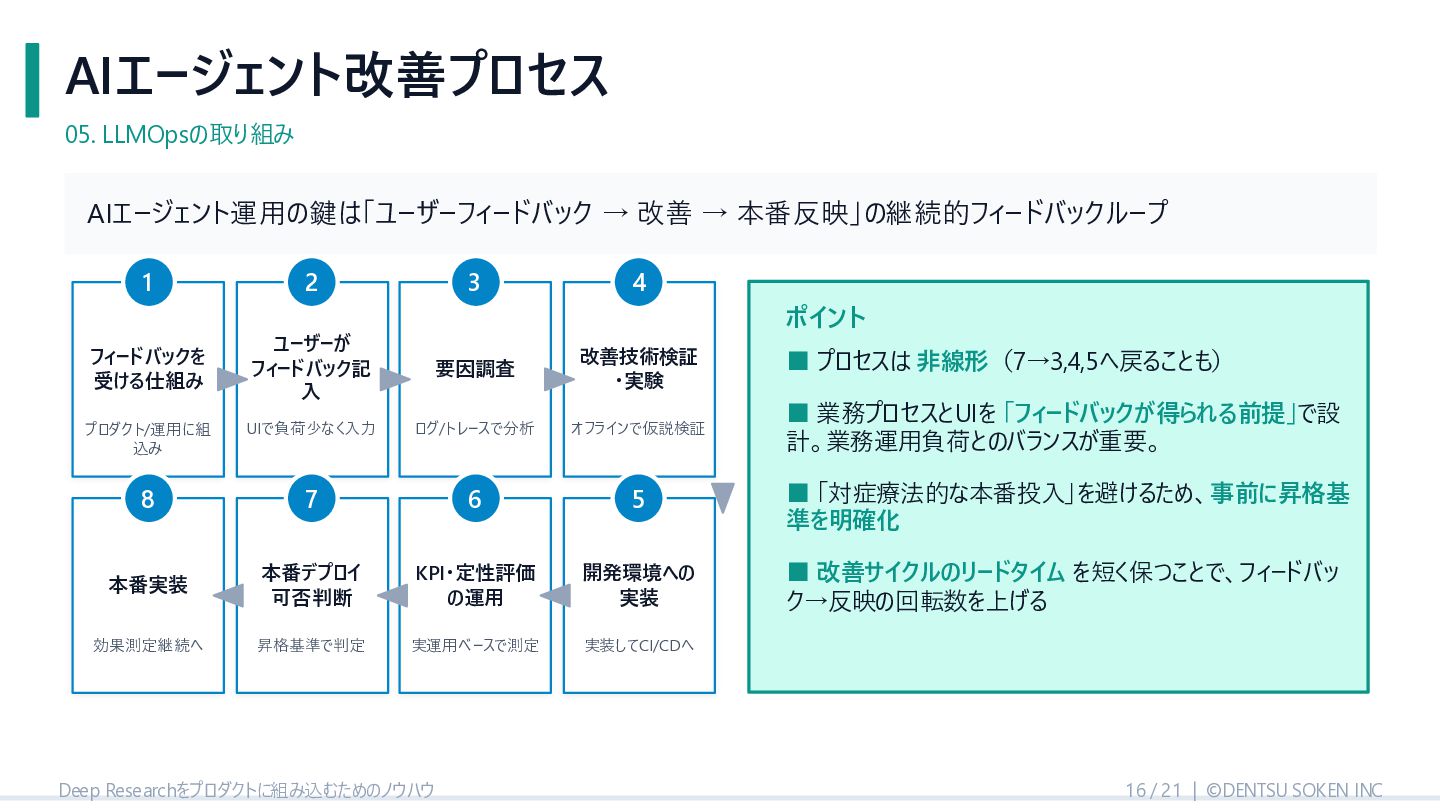{kind=link}
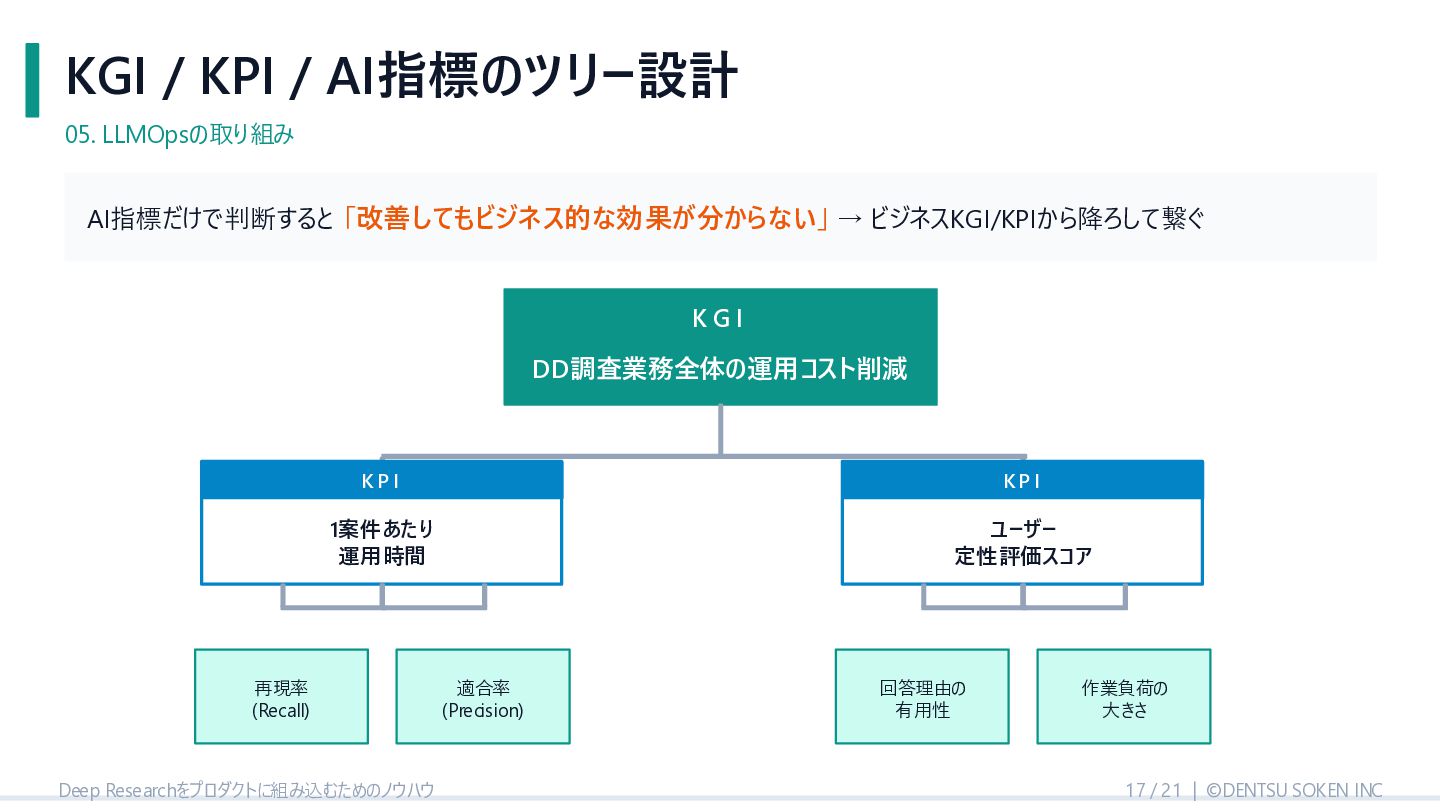{kind=link}
{kind=link}
{kind=link}
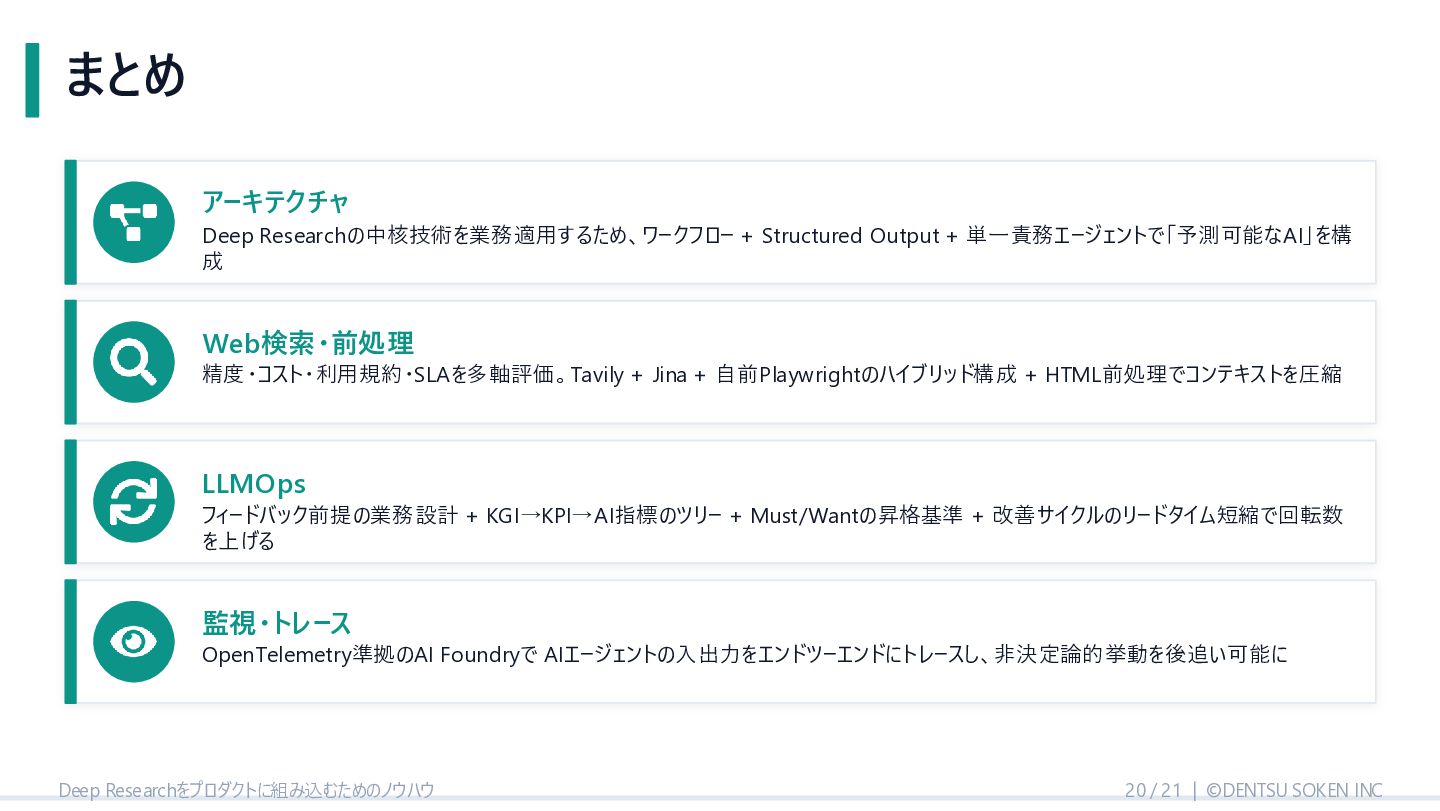{kind=link}
{kind=link}