Twitch has over six hundred engineers, millions of concurrent viewers, and is one of the highest trafficked sites on the internet today. Our API handles hundreds of thousands of requests per second and powers many different clients. The API aggregates hundreds of underlying services together in a singular, (hopefully) coherent package.
Adopting a GraphQL API enabled us to rewrite our aging web and mobile clients within a few months, giving users a much snappier experience. We’ve built tooling to optimize for developer velocity on the service side as well. Code generation keeps the cost of adding types and fields minimal, and automated integration tests ensure changes are safe. We’ve wrangled dataloaders into shape to provide efficient, high-performance operations across a multitude of backing services.
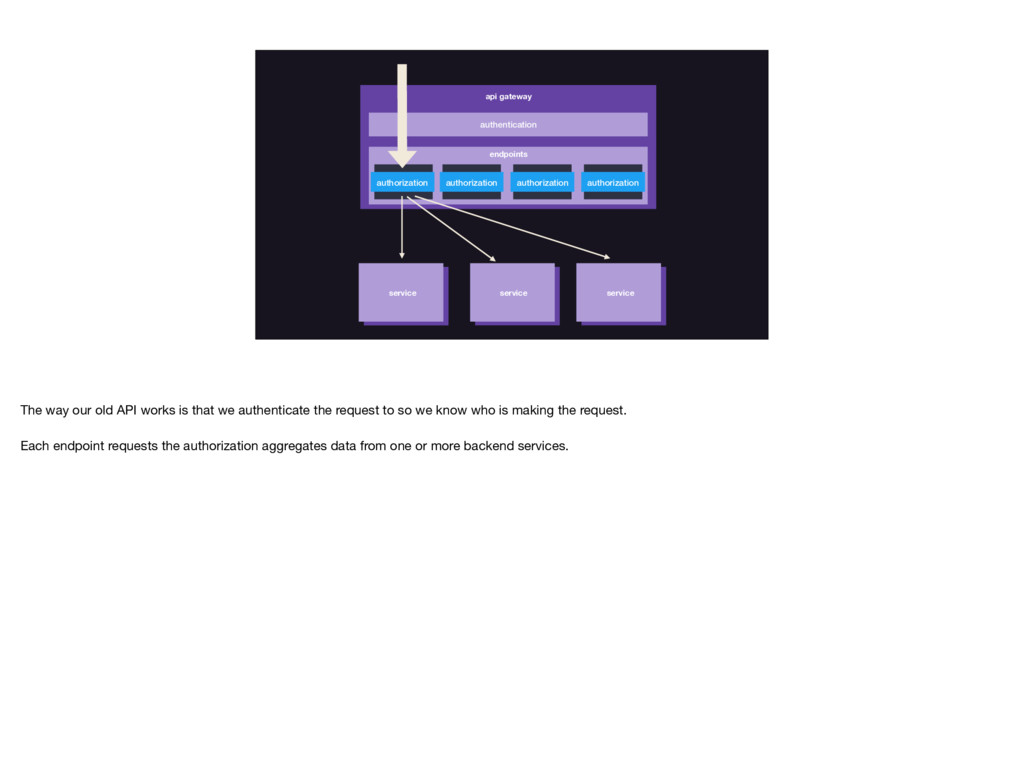
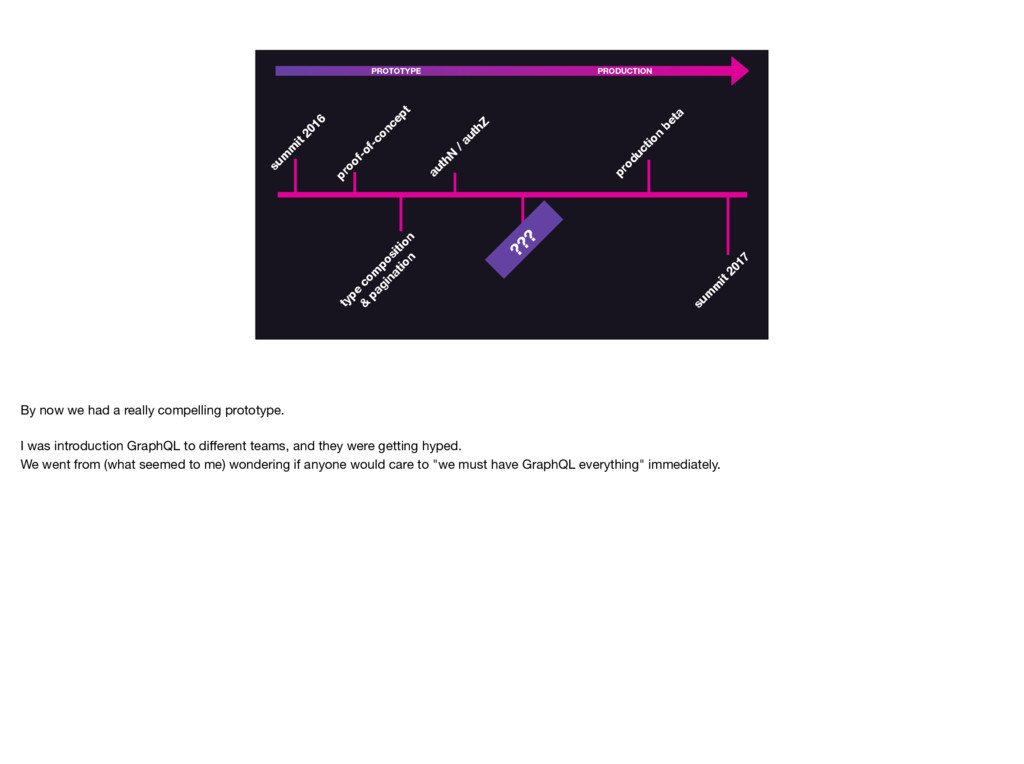
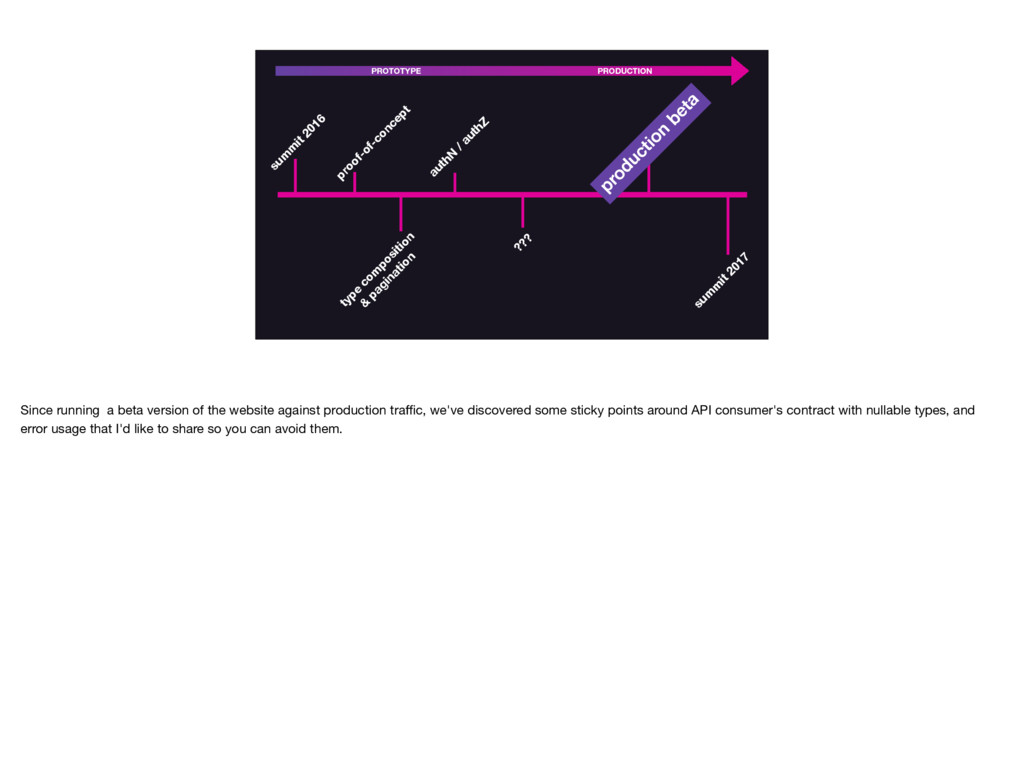
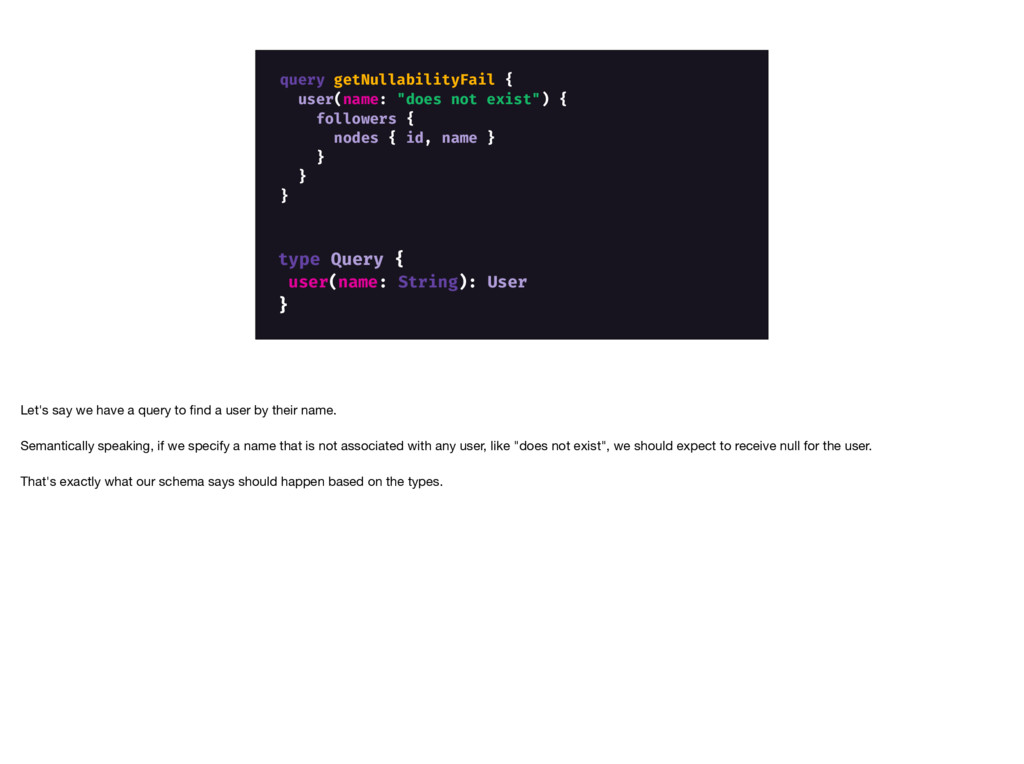
And perhaps most importantly, GraphQL has acted as a guiding force to a more standardized and flexible service ecosystem. We’ve been pushed to reconsider past decisions around service aspects like authorization and pagination, and have come out with much improved systems.
Presented at GraphQL Summit 2017.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![type Query { users(ids: [ID!], names: [String!]): [User] } type](https://files.speakerdeck.com/presentations/aa905ff495344bbc8fe68c093fb0f527/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![type Query { users(ids: [ID!], names: [String!]): [User] streams(first: Int](https://files.speakerdeck.com/presentations/aa905ff495344bbc8fe68c093fb0f527/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
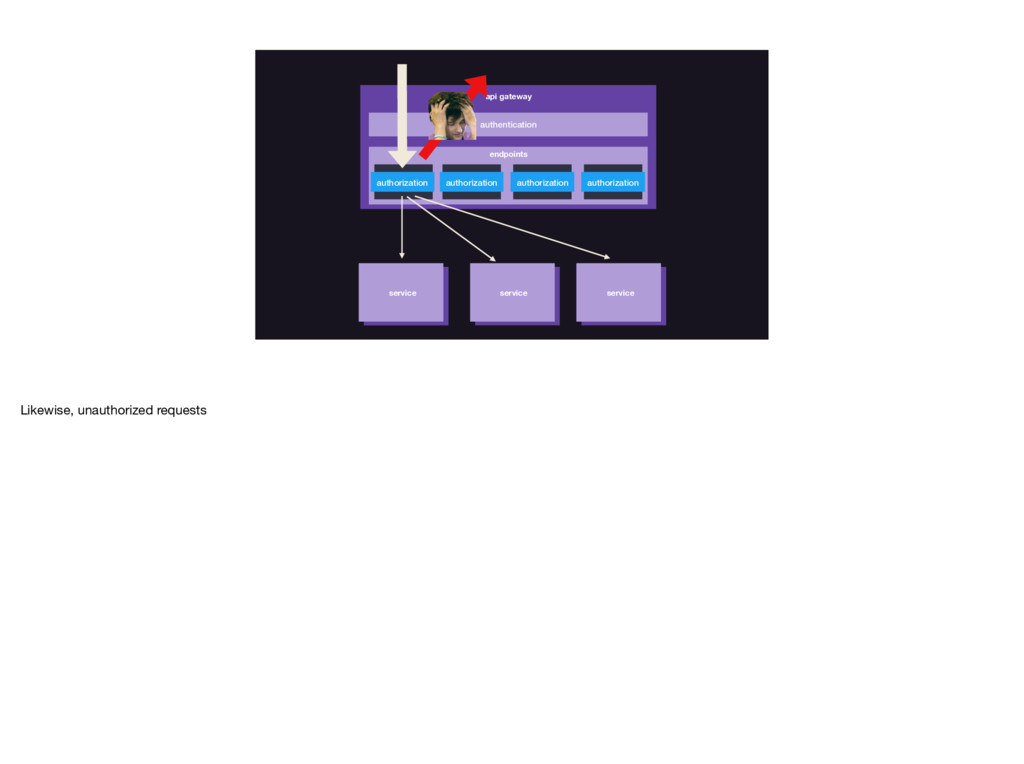{kind=link}
{kind=link}
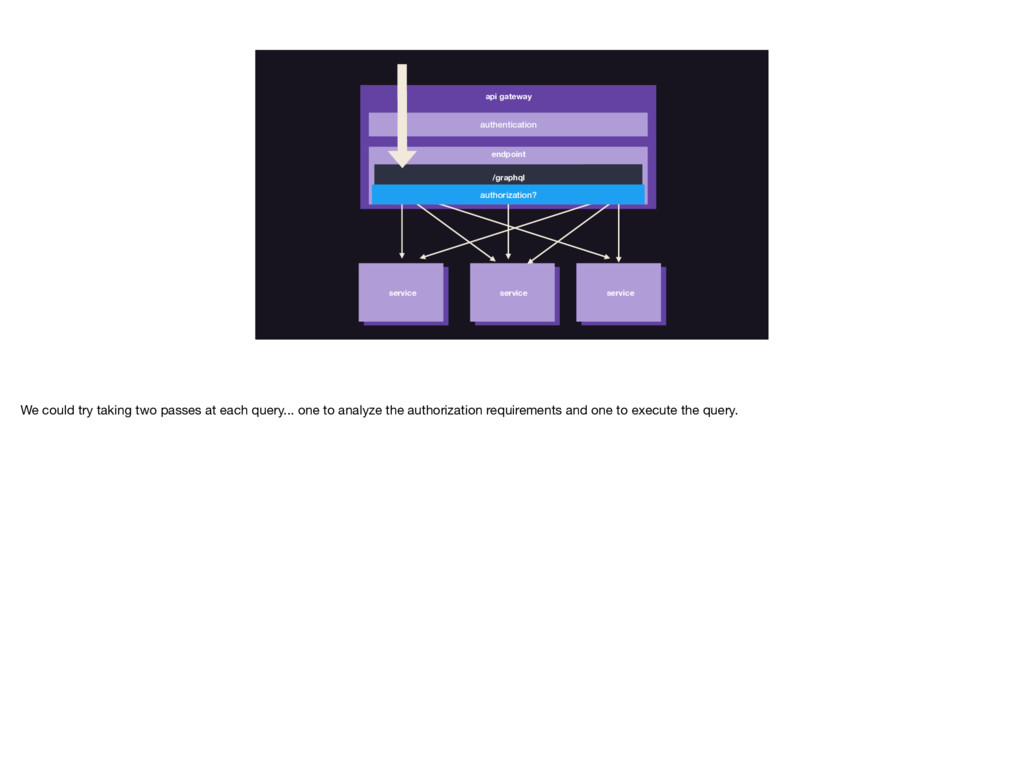{kind=link}
{kind=link}
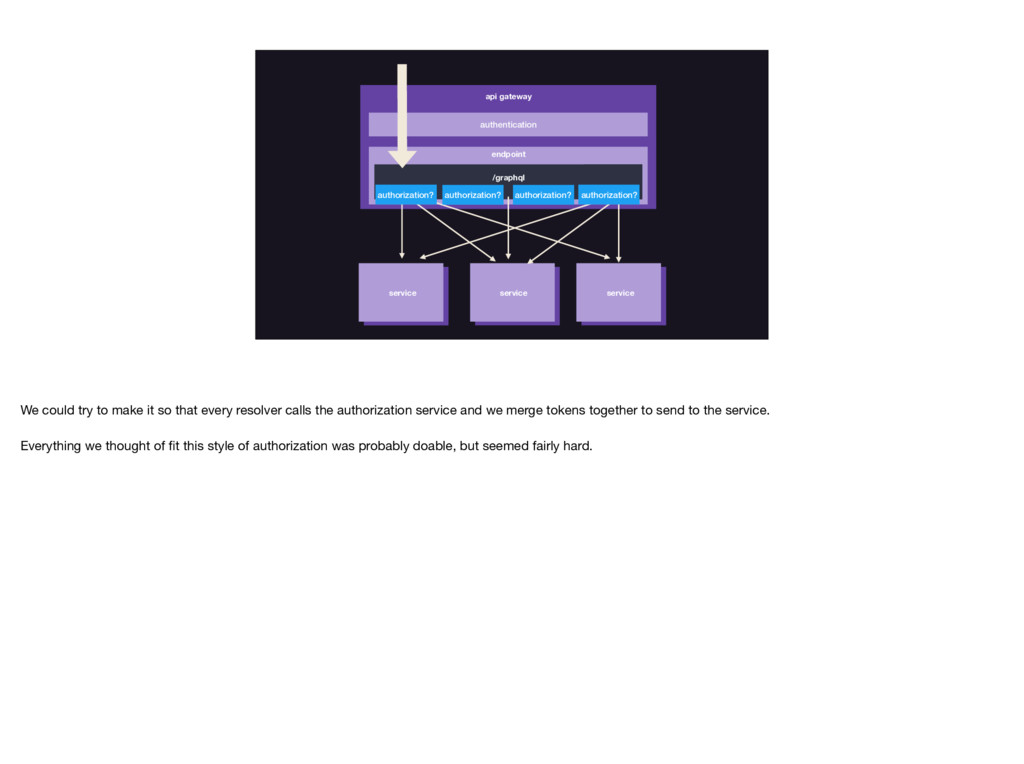{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}