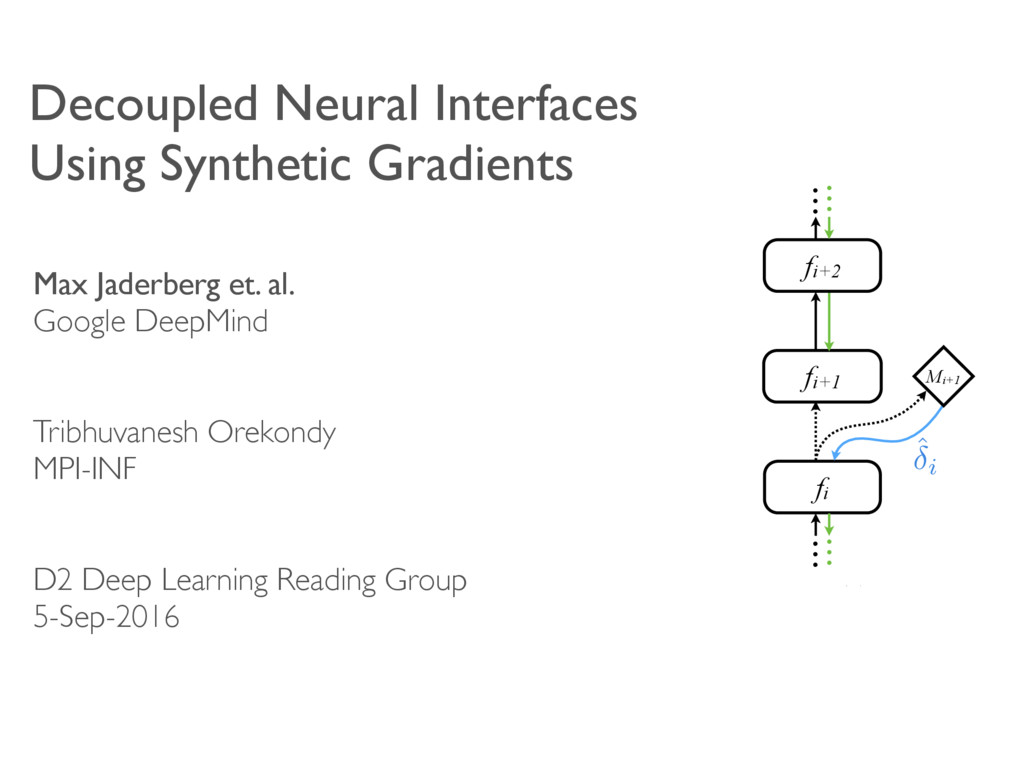
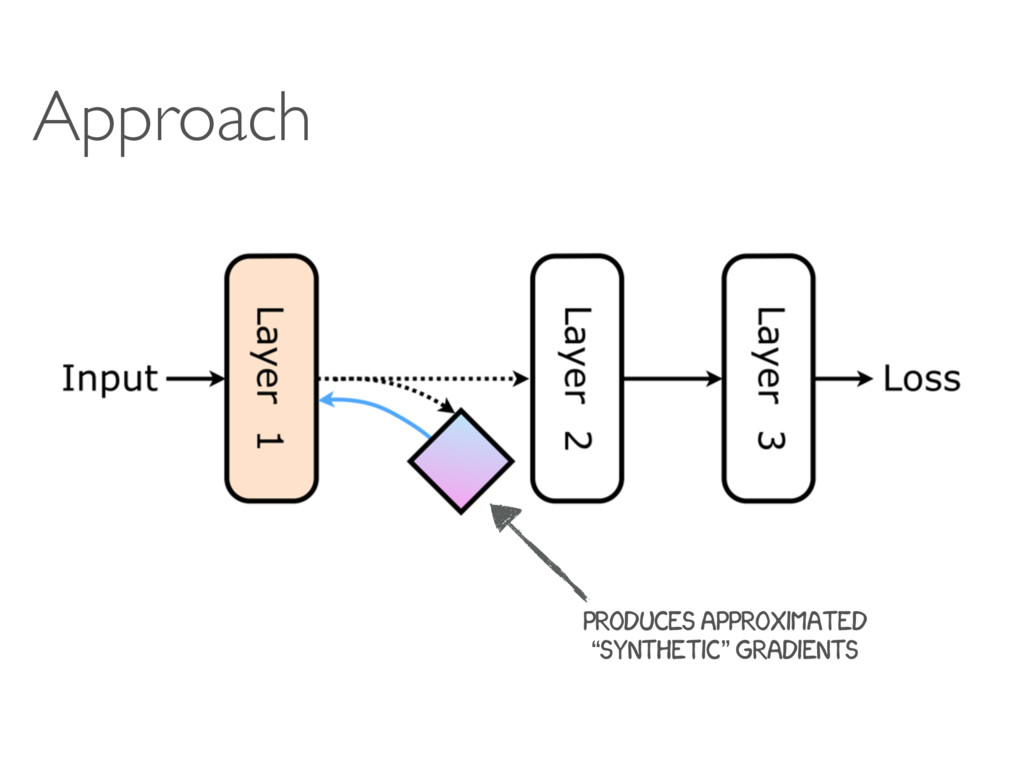
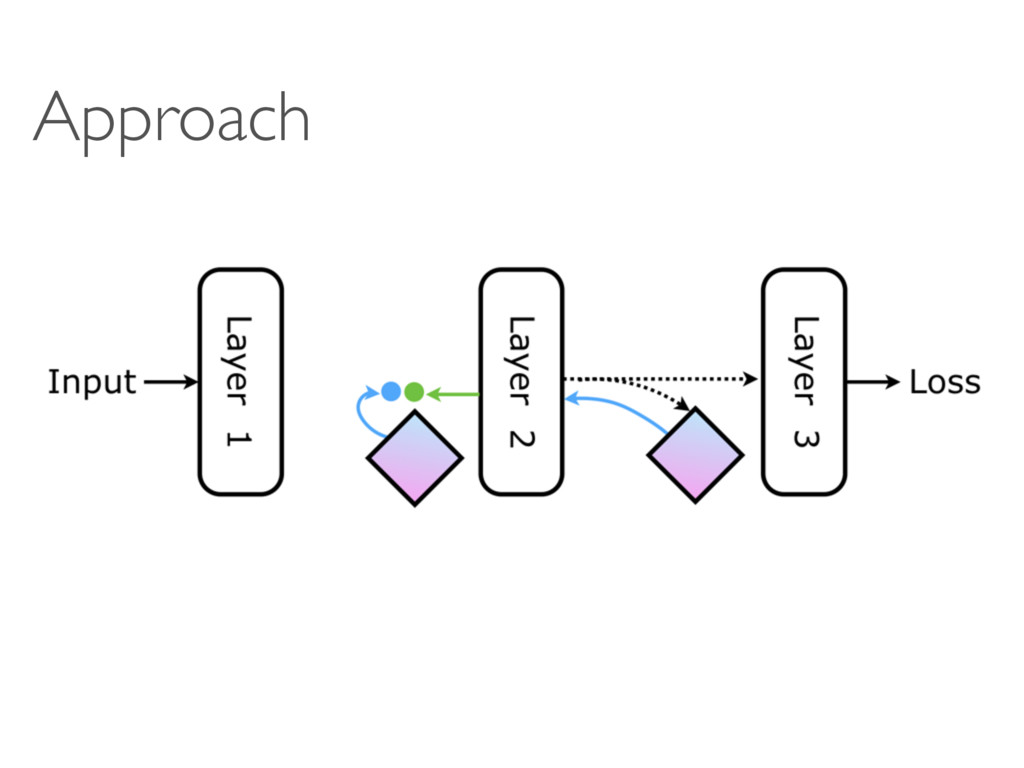
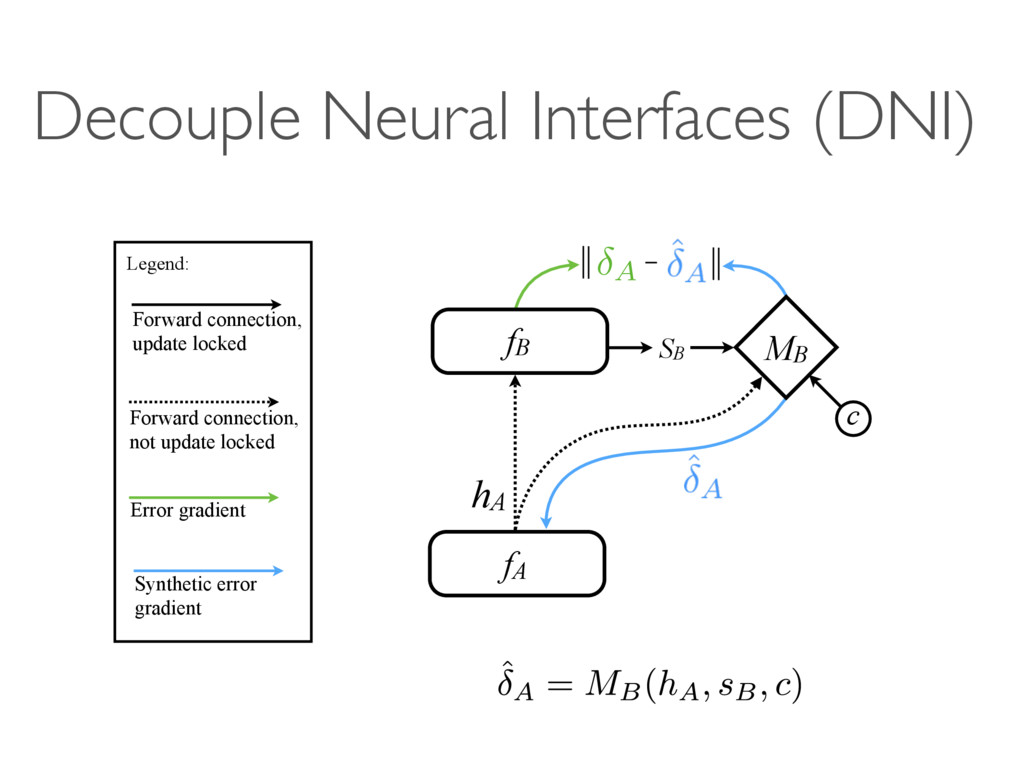
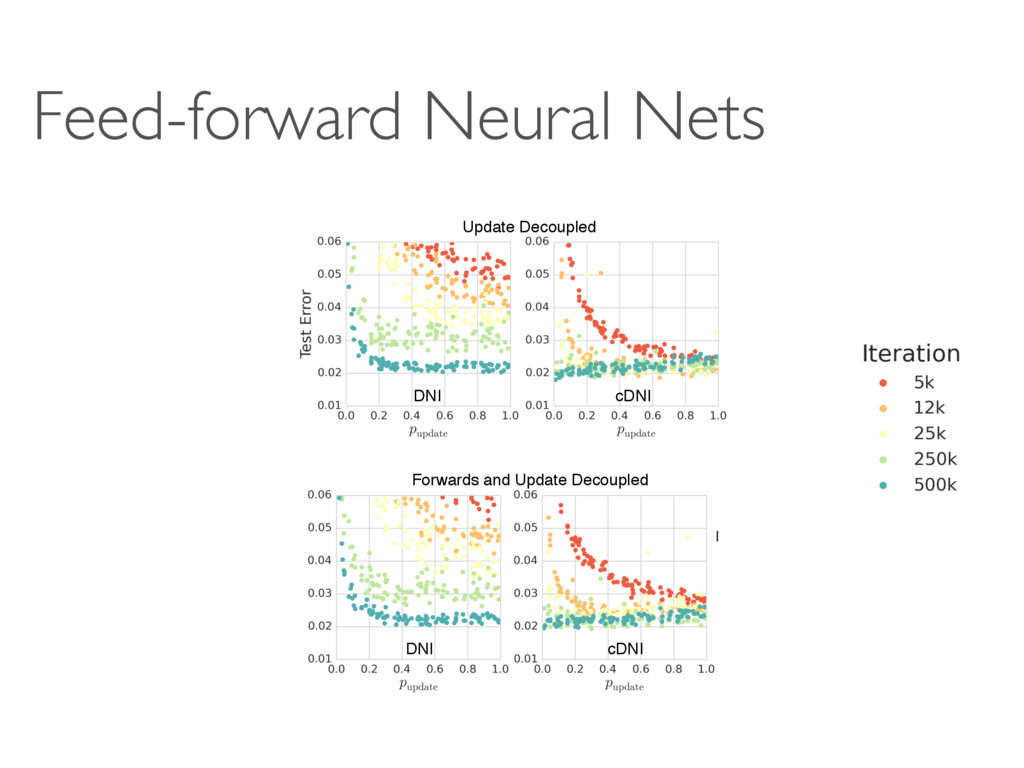
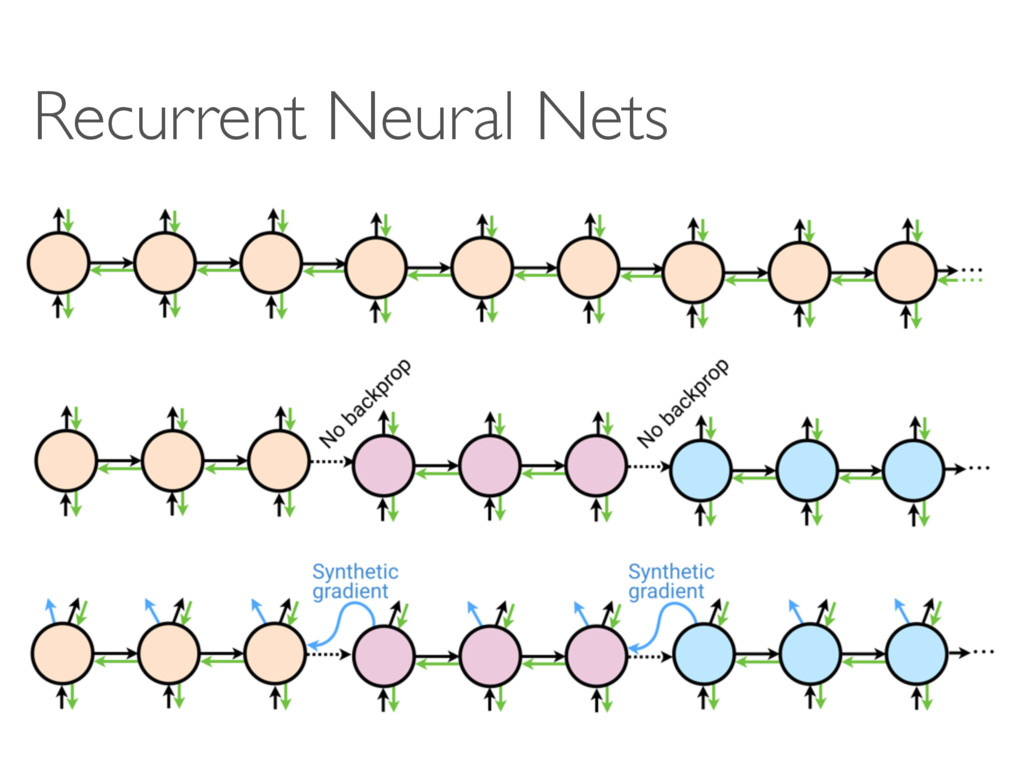
Google DeepMind Tribhuvanesh Orekondy MPI-INF D2 Deep Learning Reading Group 5-Sep-2016 A A B fA hA SB fB c MB fi fi+1 fi+2 … … … … fi fi+1 fi+2 … … … … Mi+1 i ˆ i i+1 (b) (c) ction, ction, ed r FN i+1 Fi 1 (a) A
c MB Forward connection, update locked Forward connection, not update locked Error gradient Synthetic error gradient Legend: (a) A A A!B A B A hA→ B ˆ A!B A!B SB ˆ A!B B c MA→B fi fi+1 fi+2 … … … … i i+1 (b) Forward connection, update locked Forward connection, not update locked Error gradient Synthetic error gradient Legend: Fi F (a)
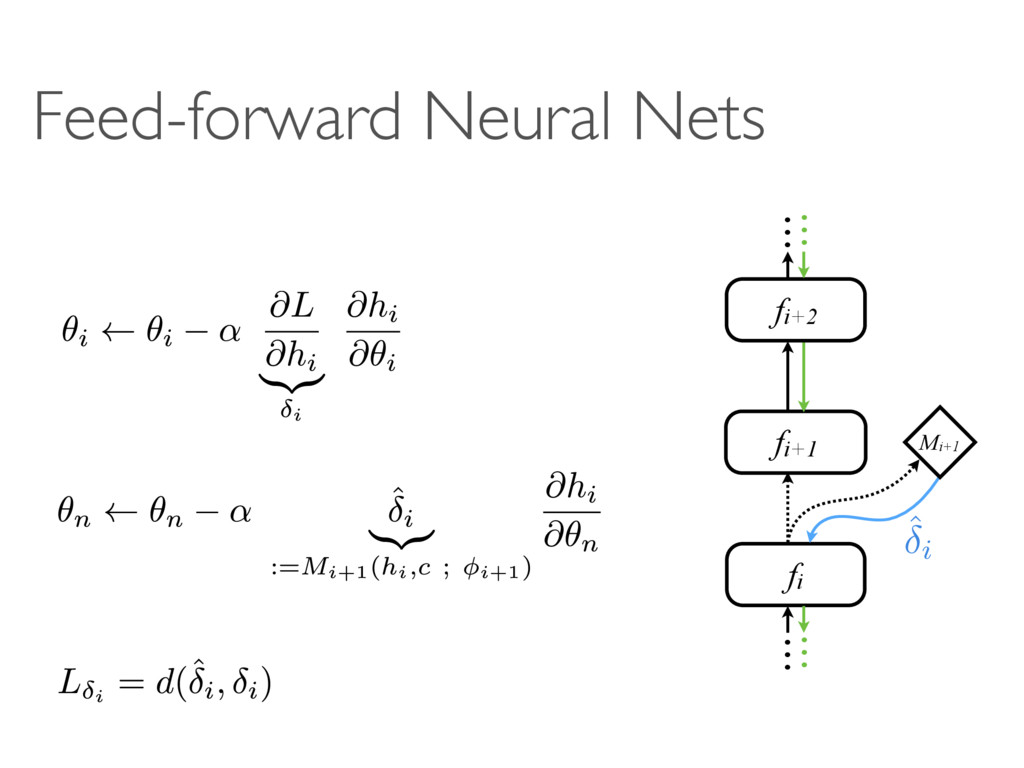
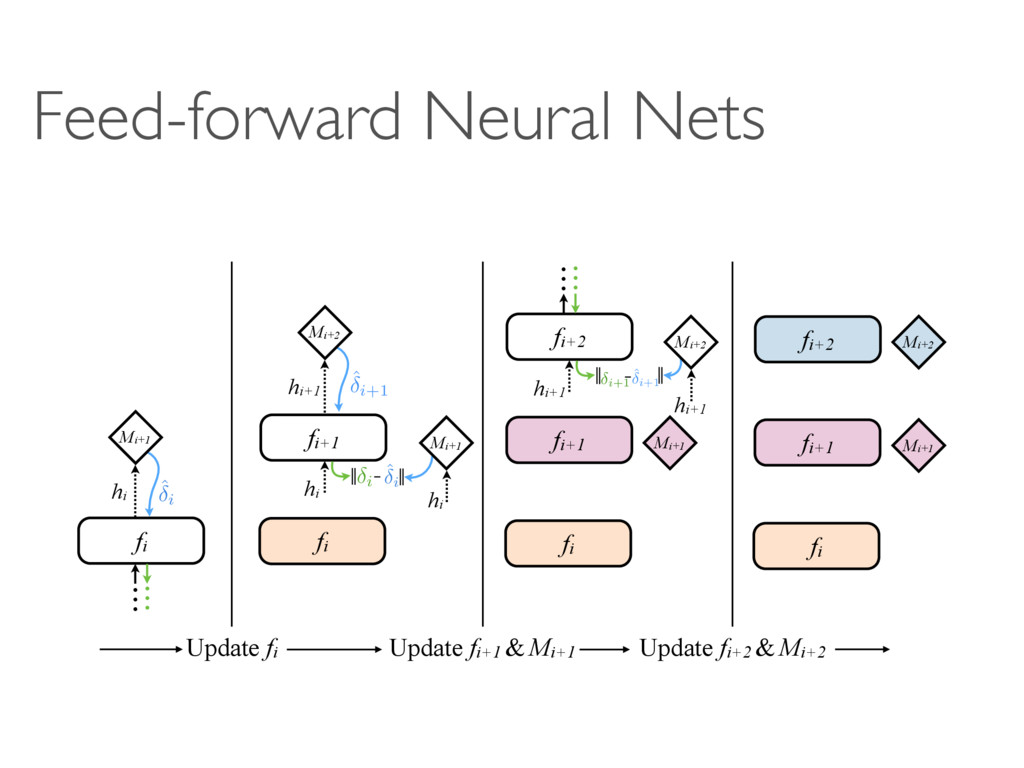
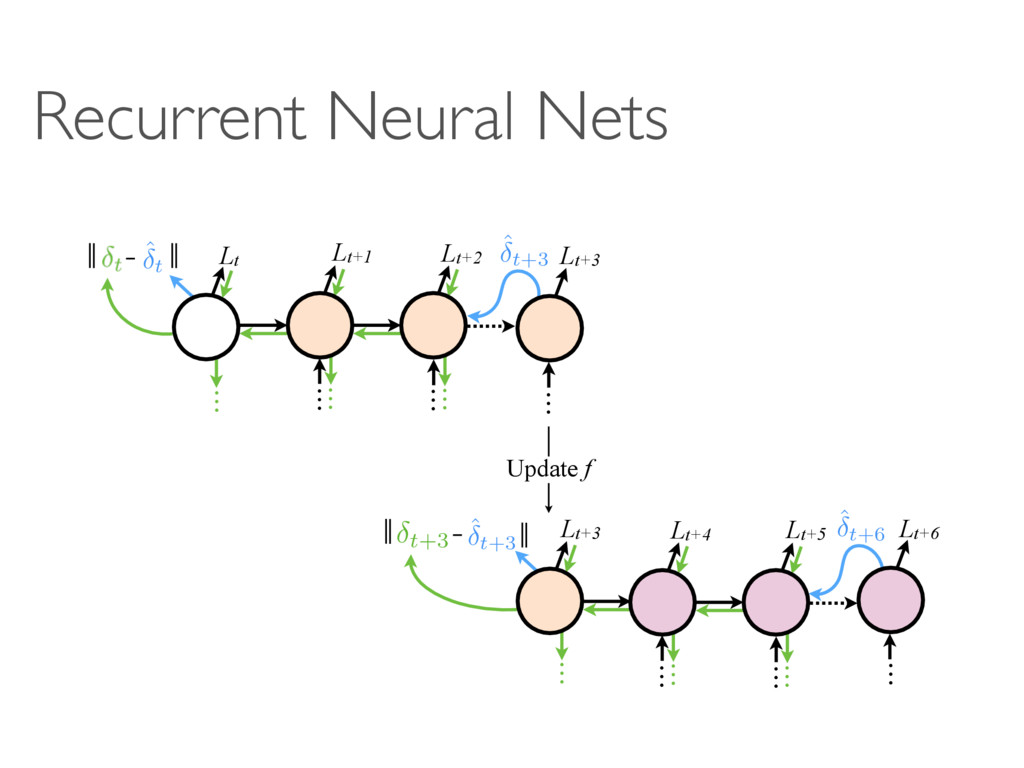
hi fi Mi+1 ˆ i hi i hi fi+1 fi Mi+1 Mi+2 hi+1 ˆ i+1 fi+2 … … Mi+2 hi+1 hi+1 ˆ i+1 i+1 fi+1 fi Mi+1 fi+2 Mi+2 Update fi Update fi+1 & Mi+1 Update fi+2 & Mi+2
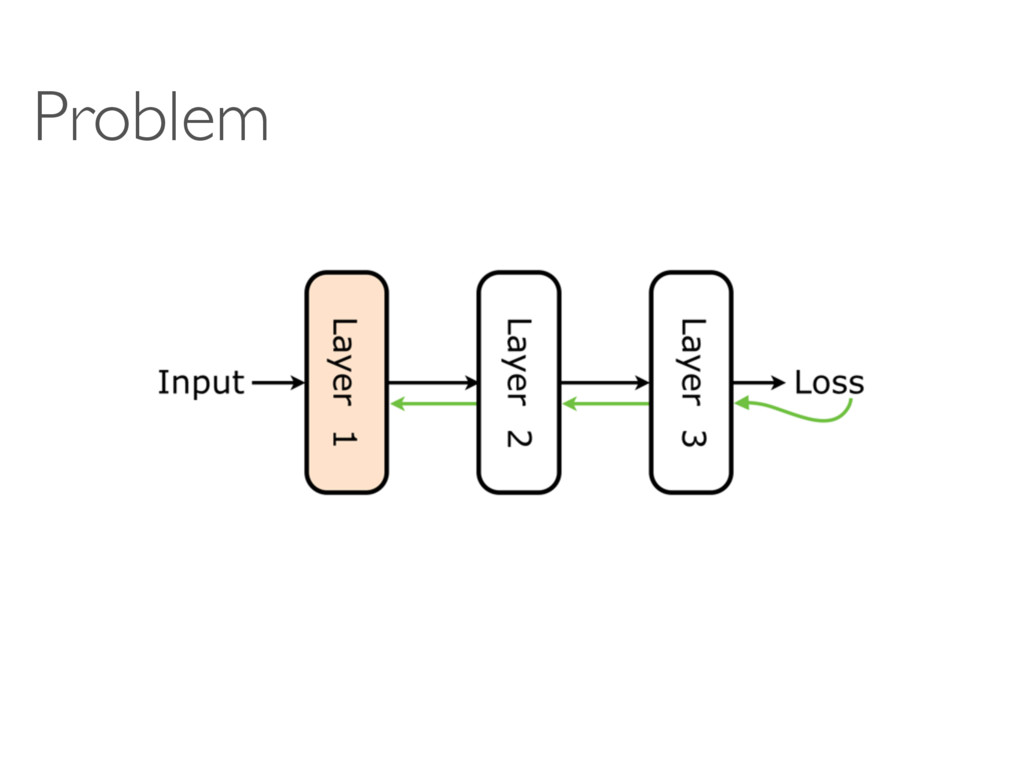
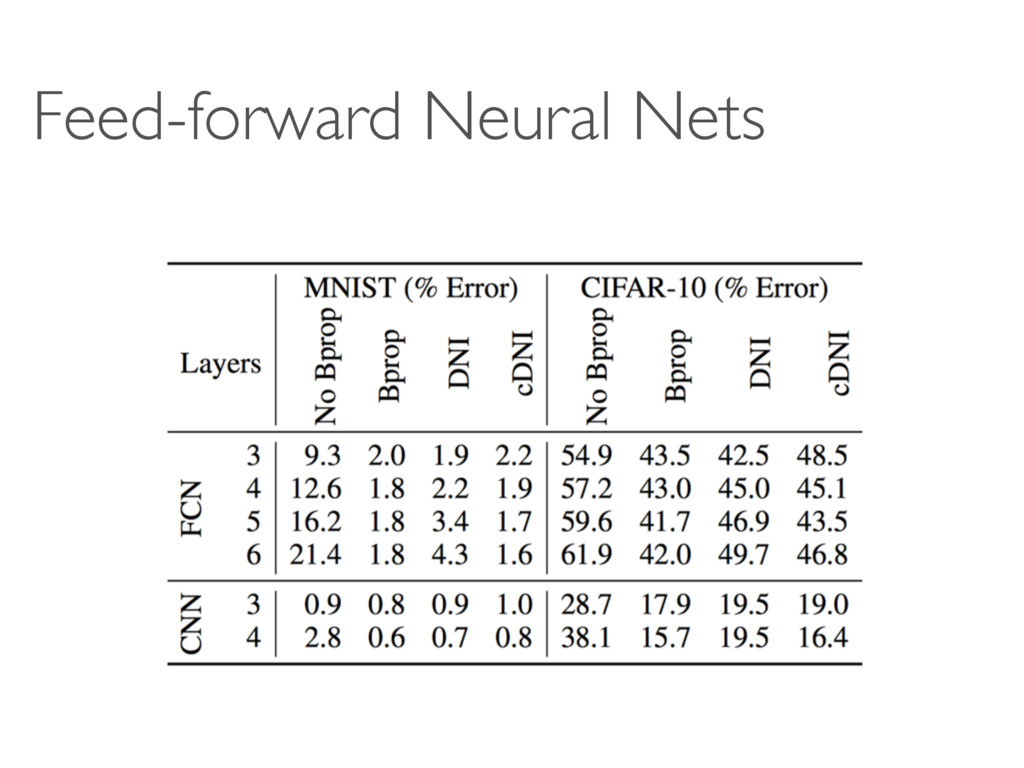
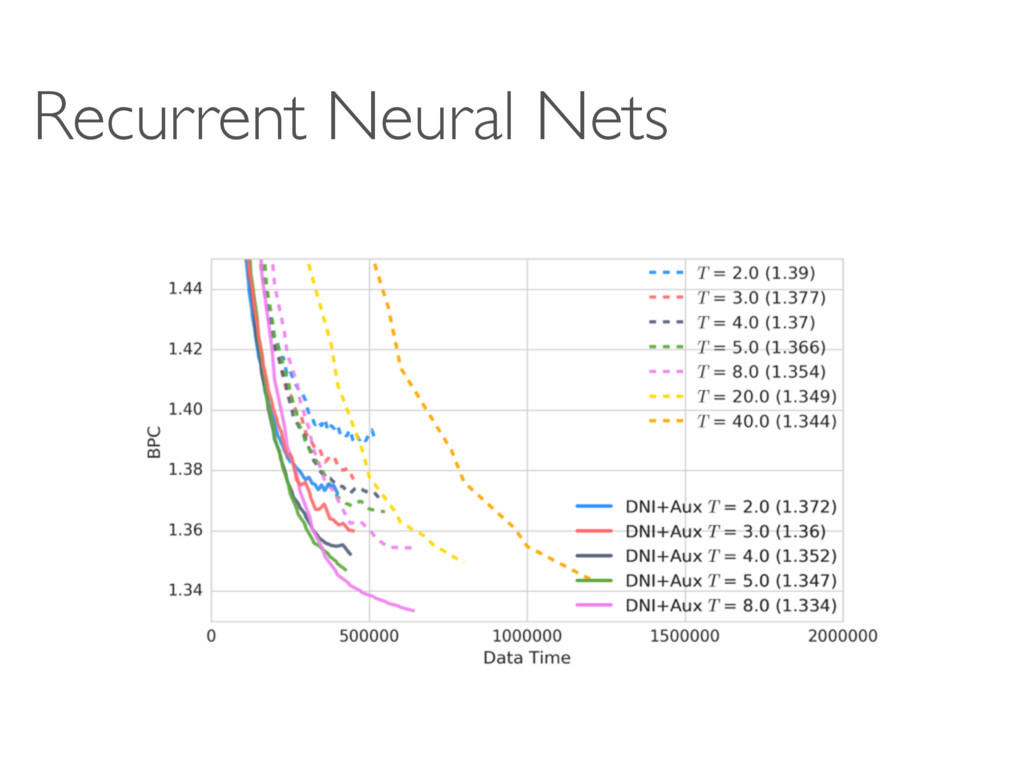
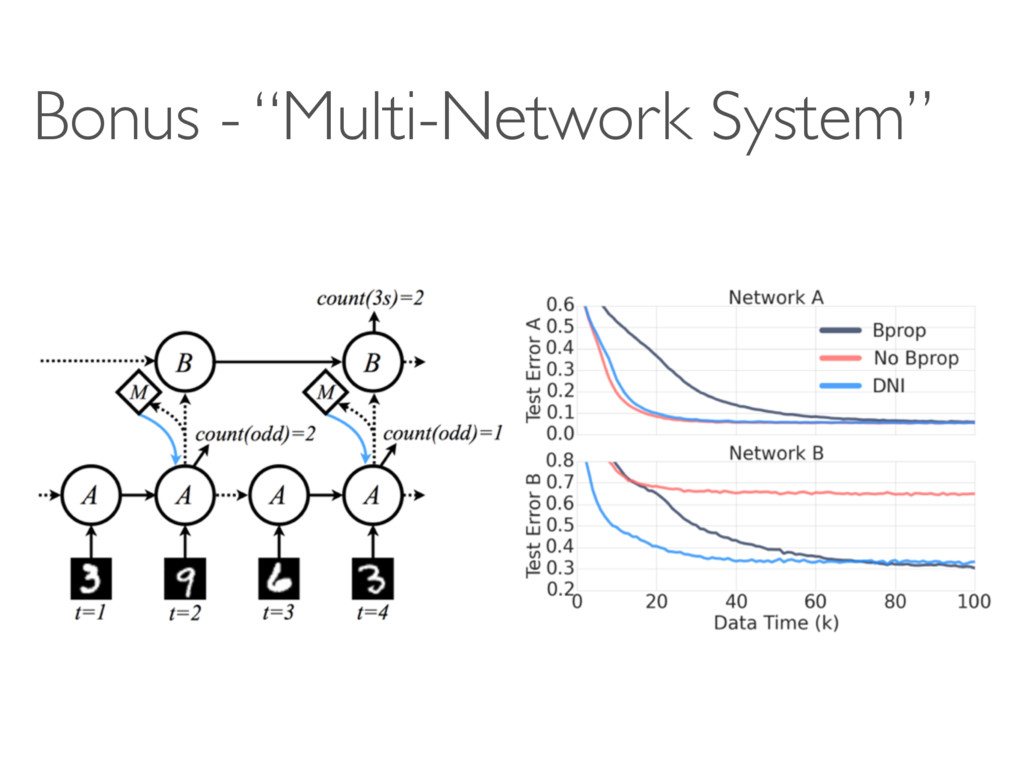
models become polynomially/exponentially deeper? • Overhead of training models (in run-time) • Module = “Linear Transform + ReLU + BatchNorm” Why not other variations? • Theory - why does it work?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}