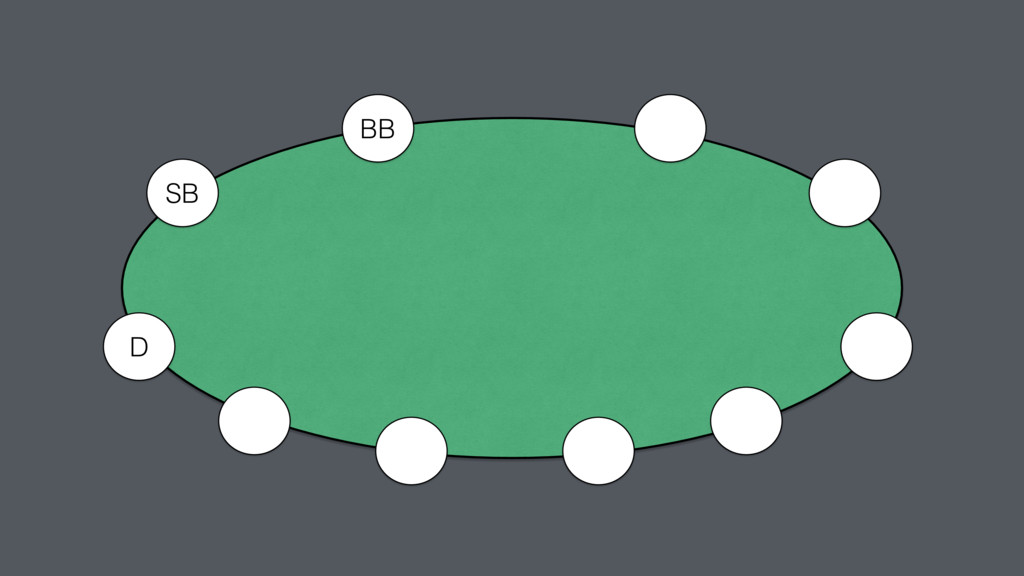
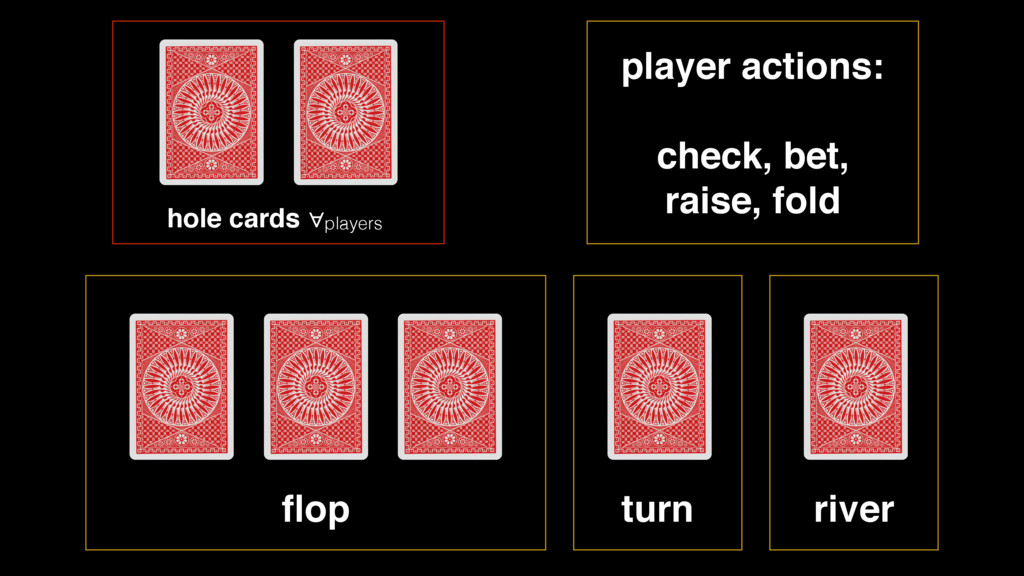
sized perfect information games. The correct decision at a particular moment depends upon the probability distribution over private information that the opponent holds, which is revealed through their past actions.
10160 (10170 in Go) past approaches include pre-solving the entire game or abstraction via Counterfactual Regret Minimization (CFR) DeepStack: attempts to solve for a Nash Equilibrium
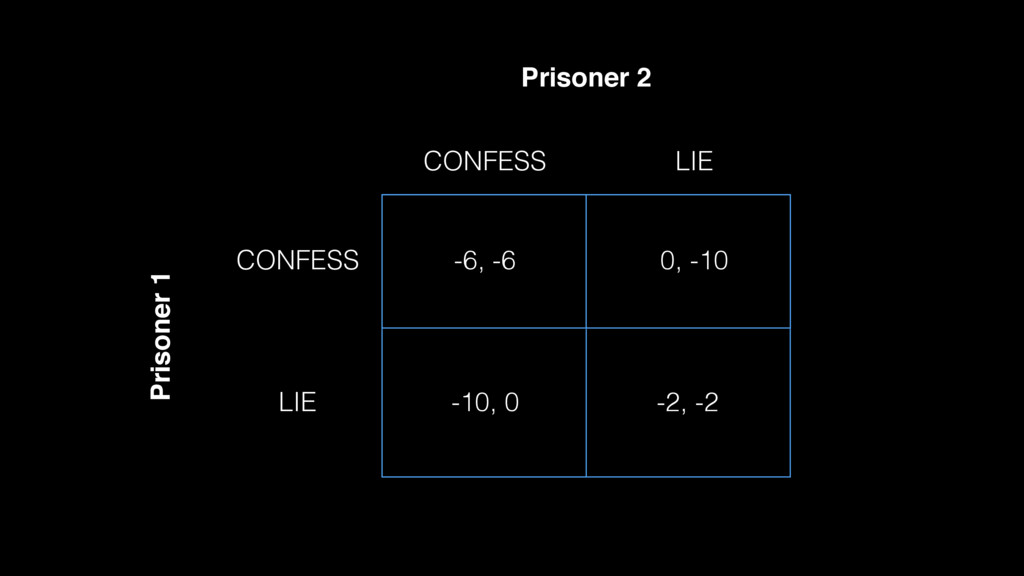
players Si = strategy for player i such that: S = S1 x S2 x S3 … x Sn is the set of strategy profiles f(x) = (f1(x), f2(x), …fn(x)) is the payoff function evaluated at x ∈ S
and x-i equal S for all other players IFF player i ∈ {1, … n} chooses strategy xi then payout function = fi(x) ; it follows that x* ∈ S will produce a Nash Equilibrium such that ∀i, xi ∈ Si : fi(xi*, x-i*) ≥ fi(xi*, x-i*)
≥ fi(xi*, x-i*) the strategy profile will produce a Nash Equilibrium so long as no unilateral deviation from the strategy by any single player results in an improved payoff function
range of public actions determine a player’s range: function of the card’s they’ll play for what price expected utility: estimation of the payout function
maximize expected utility against a best-response opponent strategy exploitability: difference in expected utility of a best-response strategy and the expected utility under a NE
the current public state depth-limited lookahead: learned value function restricted set of lookahead actions: difference in expected utility of a best-response strategy and the expected utility under a NE
of play next actions: discard previous strategy and determine action using CFR algorithm. input: our stored range and a vector of opponent counterfactual values update our range and opponent counter factual values
those computed in the re-solved strategy for our chosen action update our own range using the computed strategy and Bayes’ rule chance action: replace the opponent counterfactual values with those computed for this chance action from the last resolve update our own range by zeroing out impossible hands given the new public state
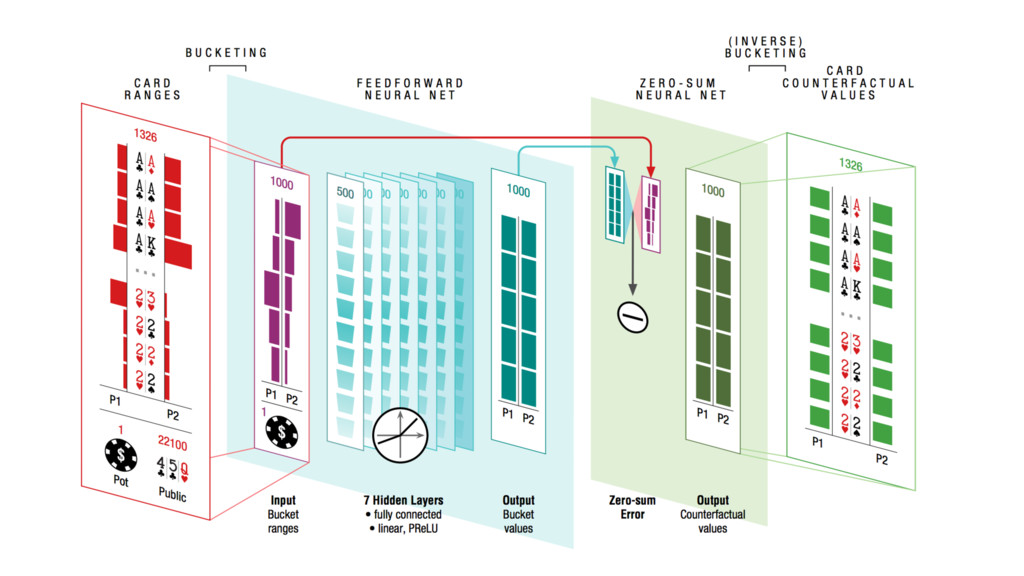
approximates the resulting values if the public state were to be solved with the current iteration’s ranges input: public state = players’ ranges, pot size, public cards output: vector of counterfactual values for holding any hand for both players
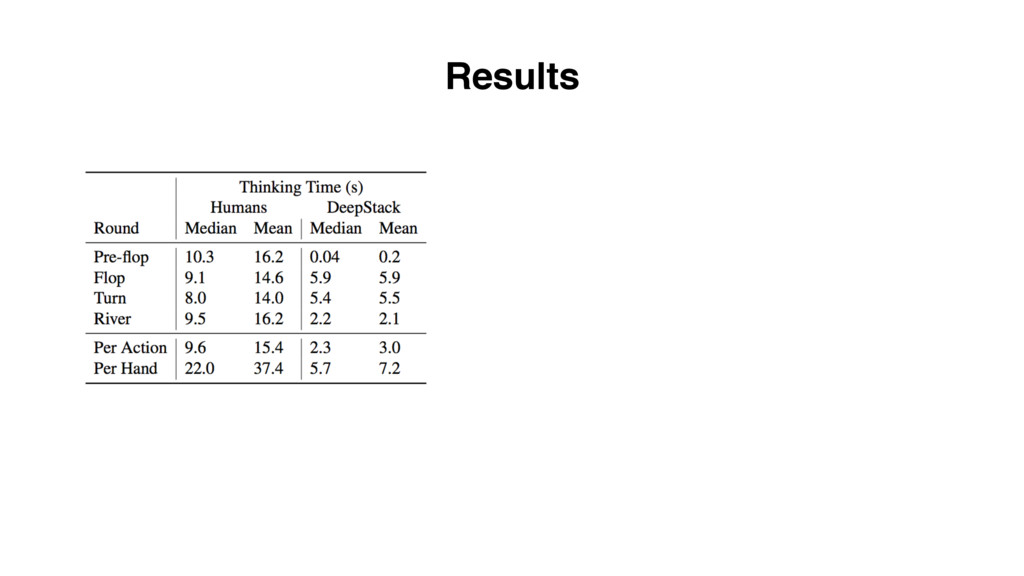
tree limited to only 4 actions: fold, call, 2 or 3 bet, all-in optimization for decision speed: allows DeepStack to play at conventional human speed decision points reduced form 10160 to 107 can be solved in < 5 seconds using a GeForce GTX 1080
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
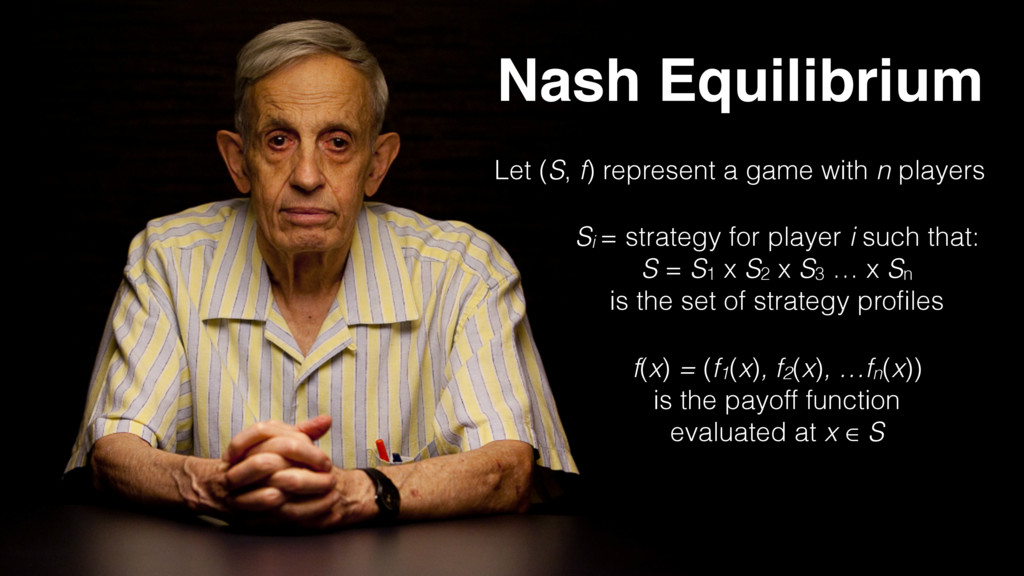{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}