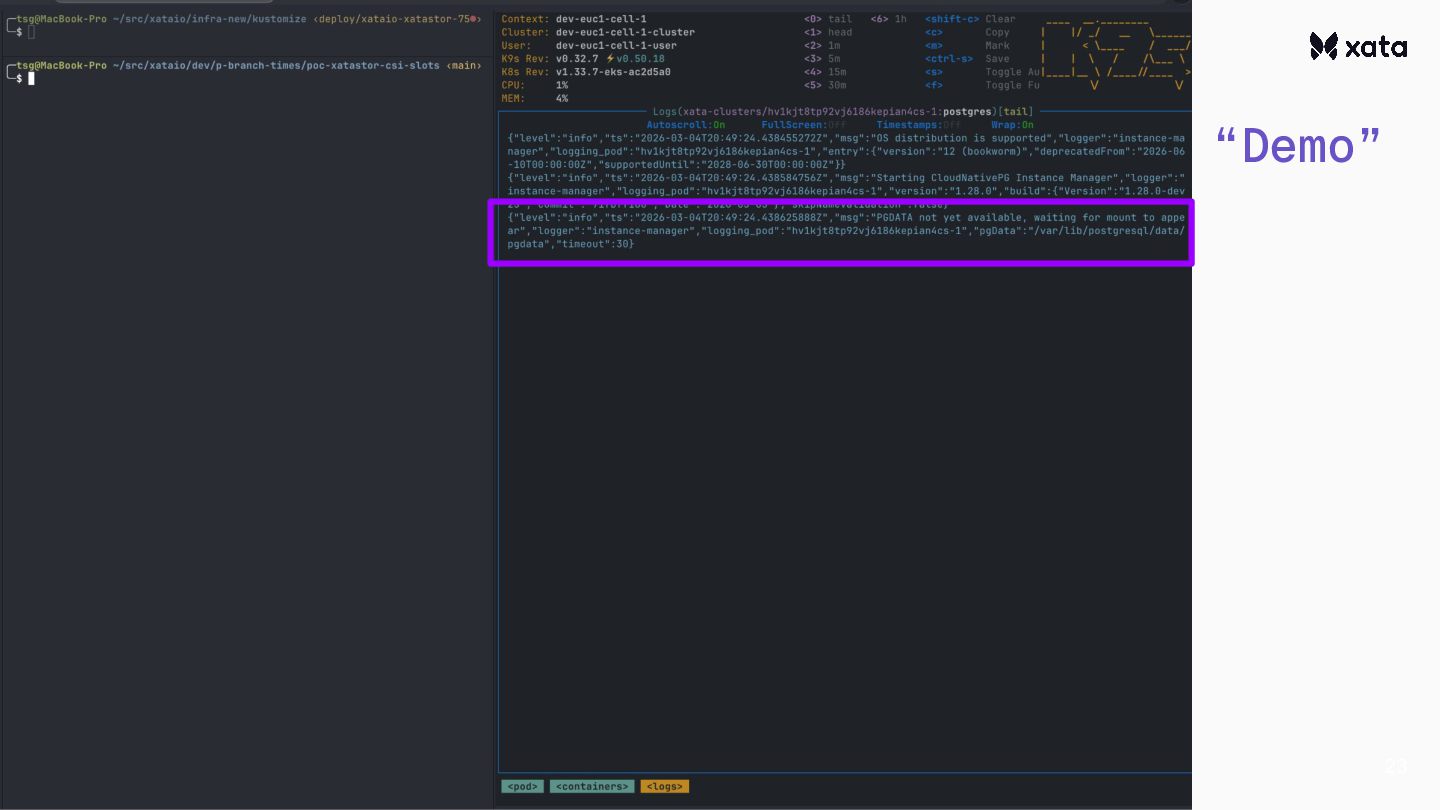
CloudNativePG (CNPG) is a popular and battle-tested operator for running Postgres on top of Kubernetes. At Xata, we’ve been using CNPG and extending it in several different directions. One of them is implementing a scale-to-zero plugin: clusters hibernate when inactive and they wake up automatically when new connections are created.
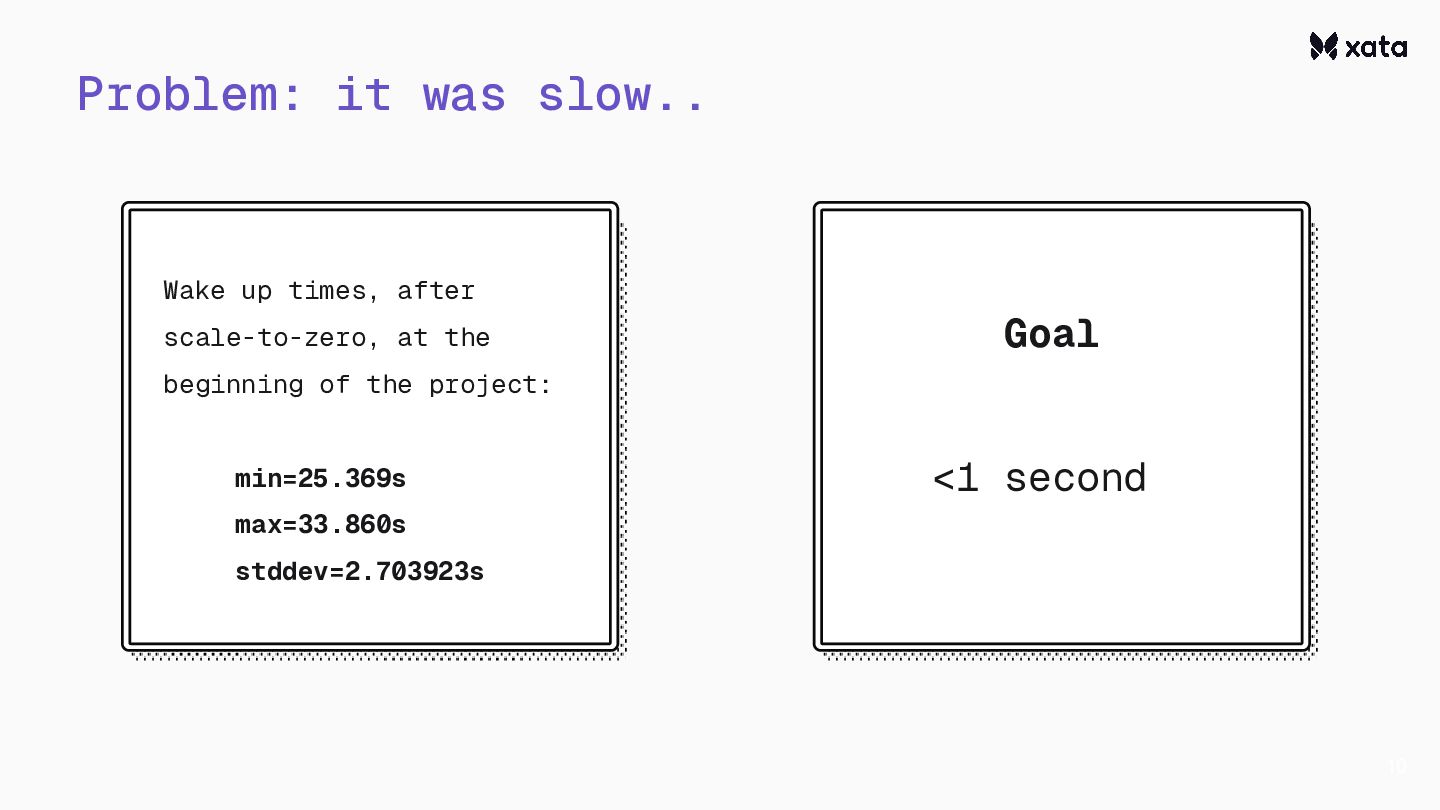
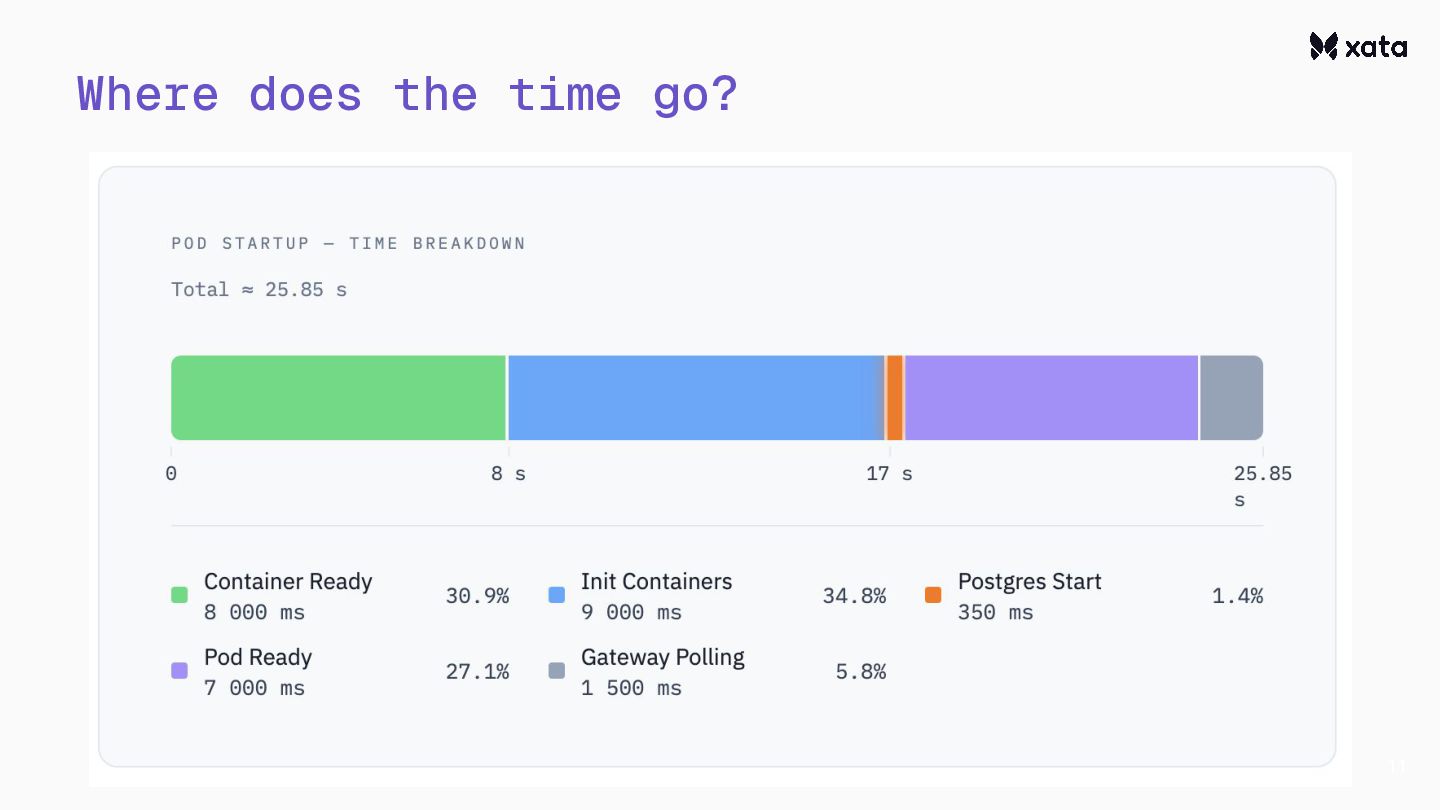
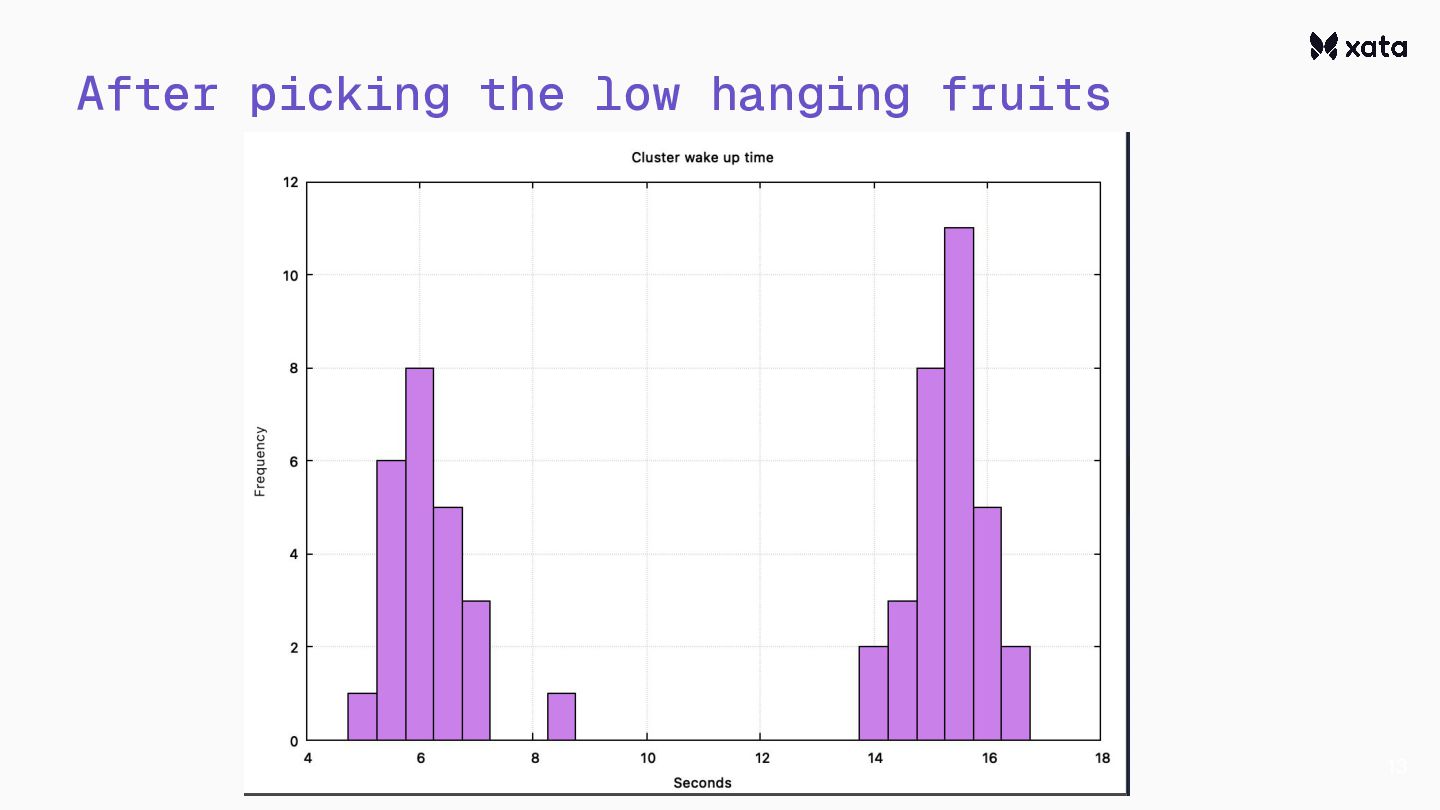
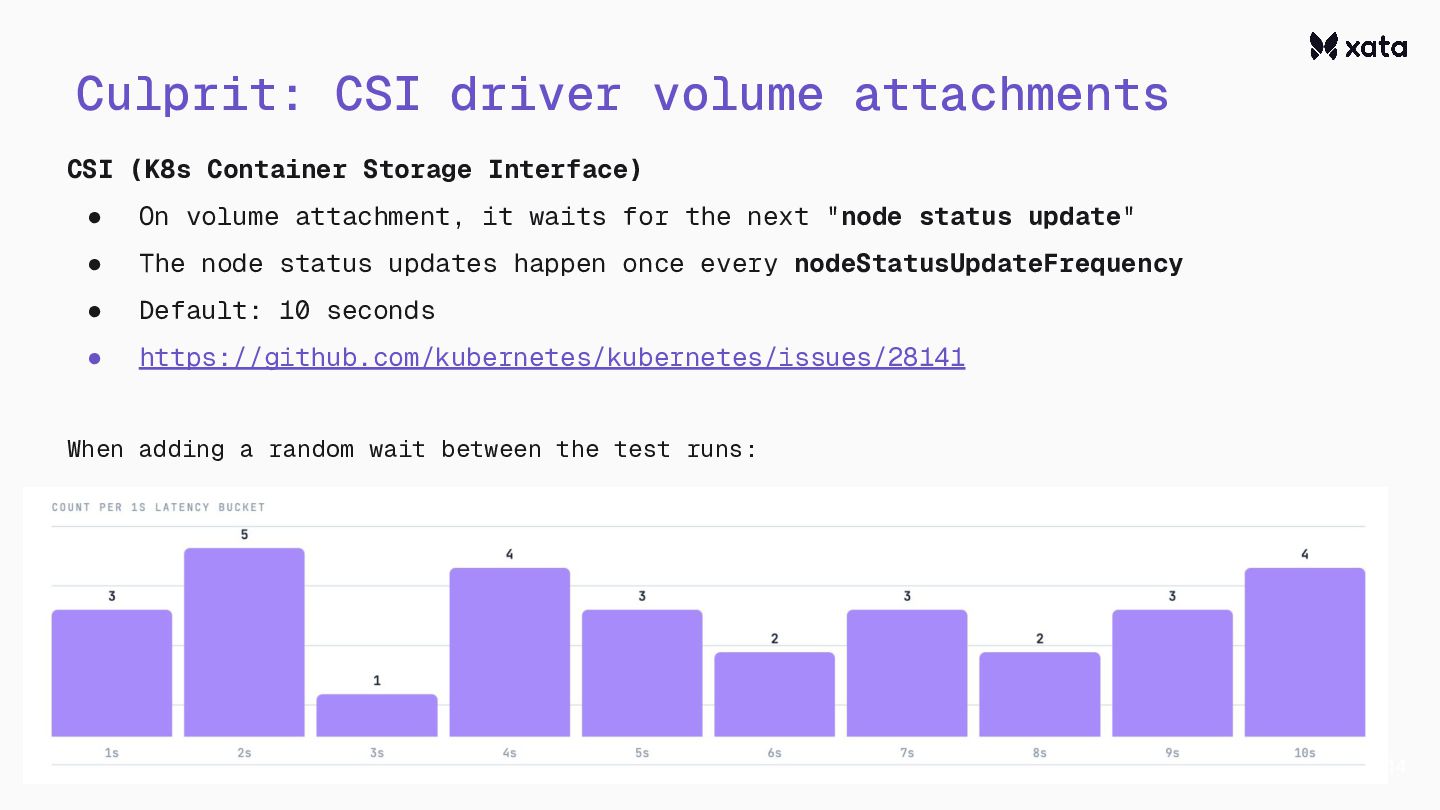
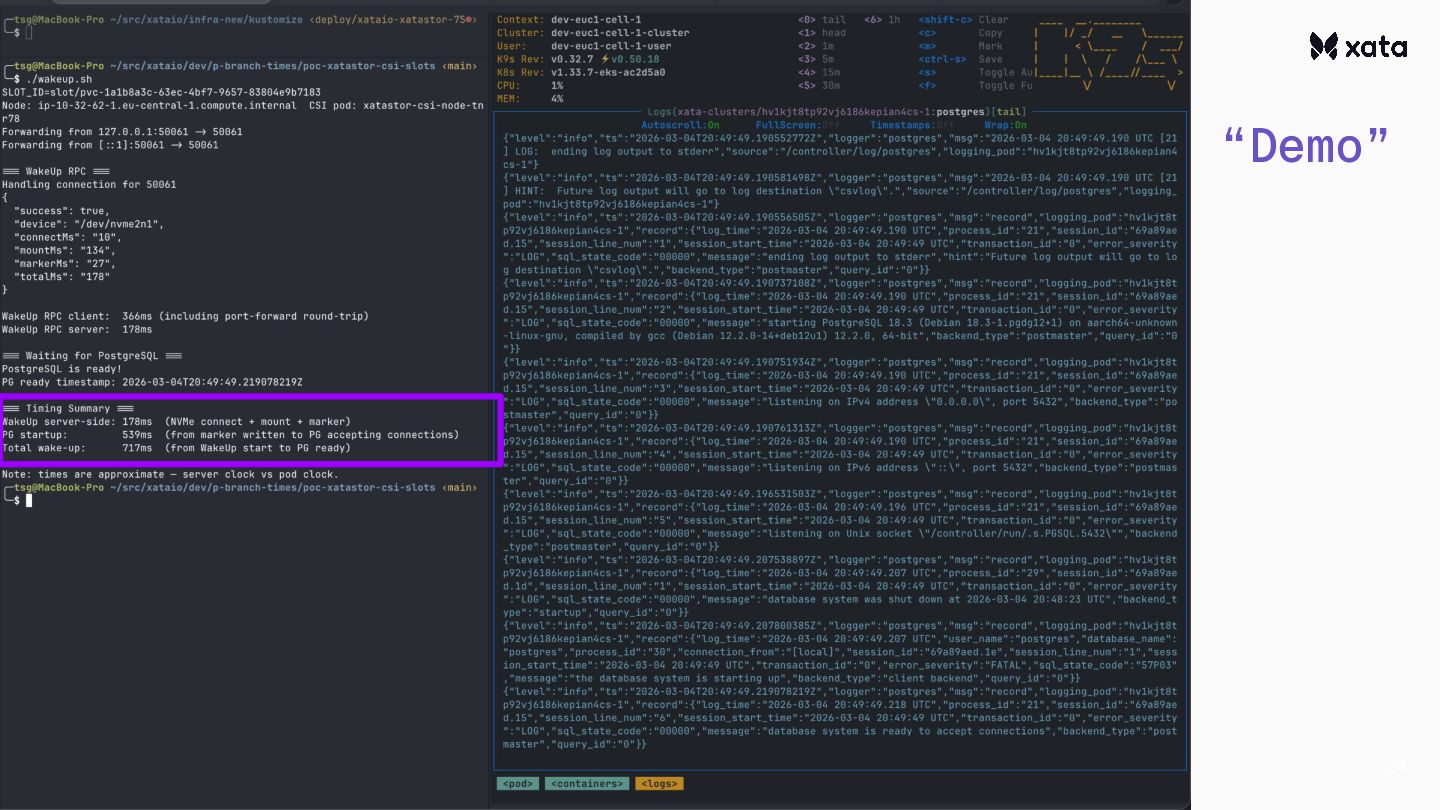
After adding scale-to-zero, we’ve faced the challenge that the CNPG wake-up from hibernation is rather slow.This is an optimization story about how we reduced the wake-up times from 20+ seconds to under one second.
{kind=link}
{kind=link}
{kind=link}
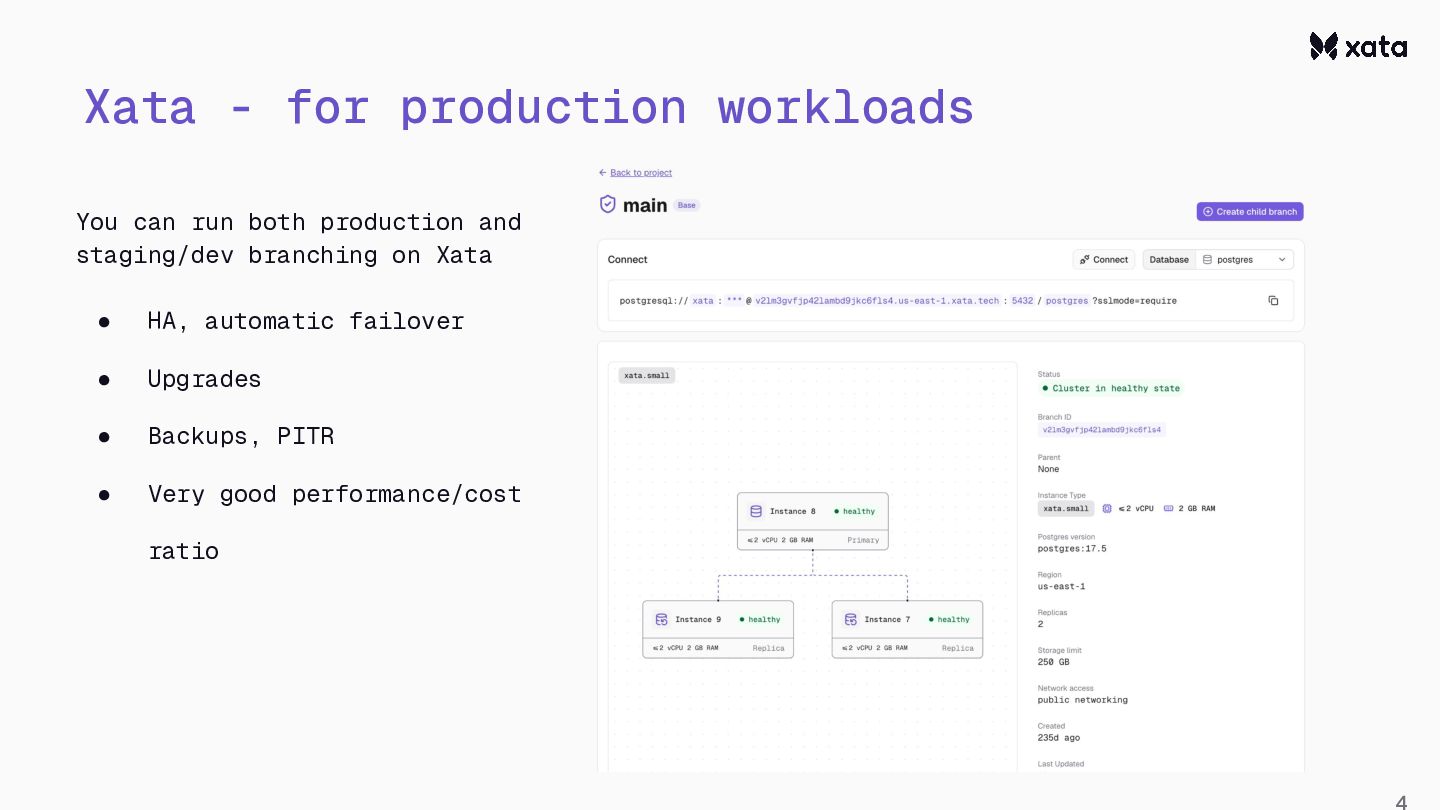{kind=link}
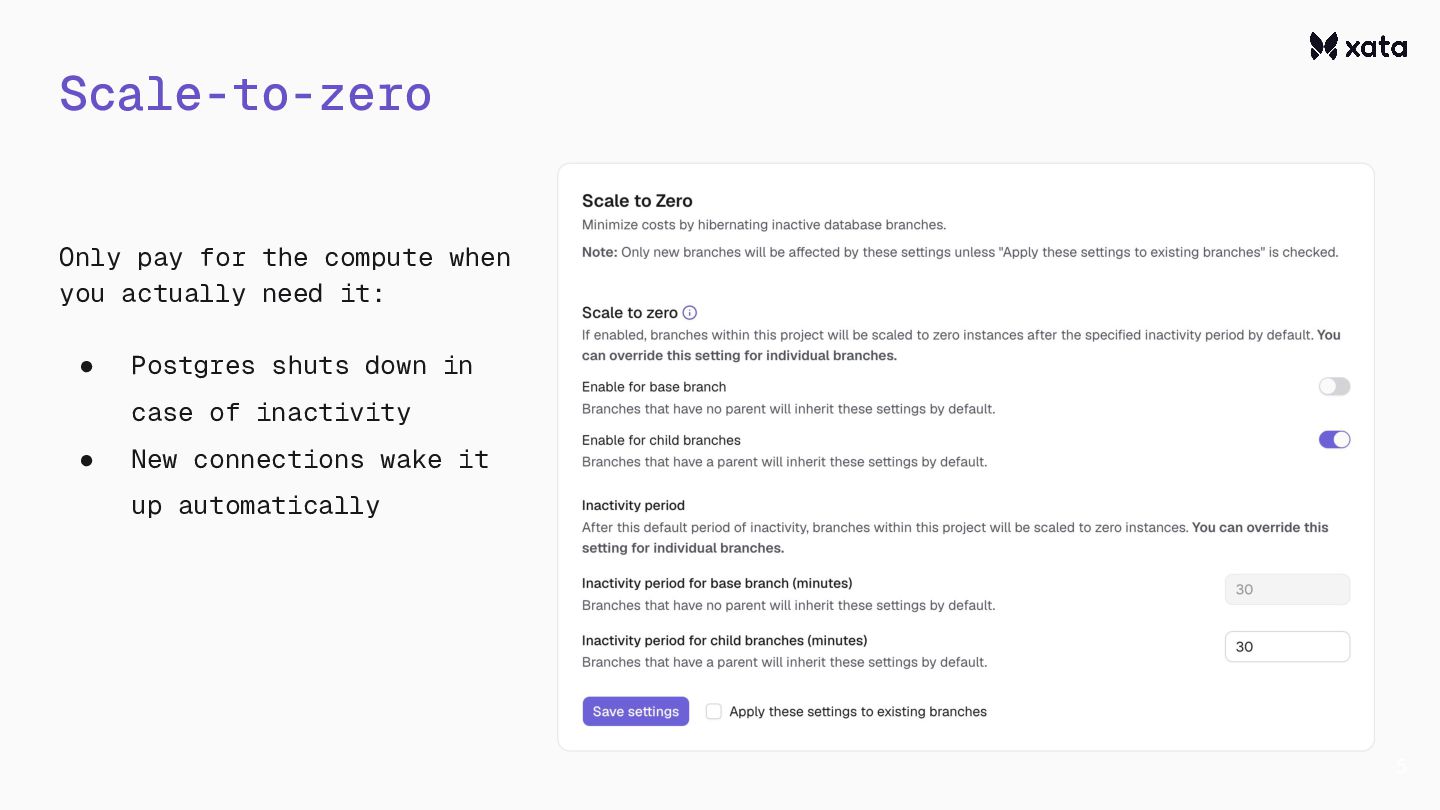{kind=link}
{kind=link}
{kind=link}
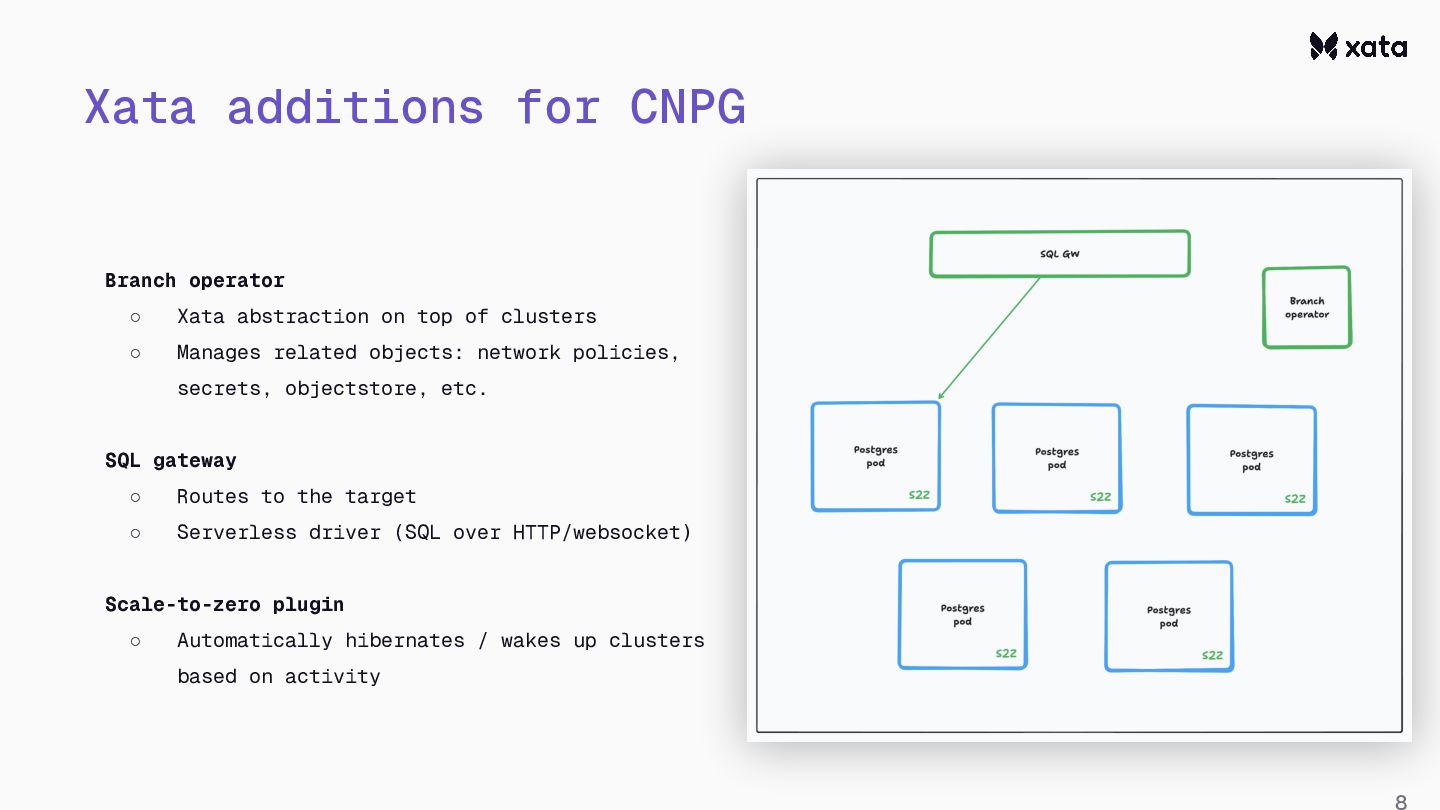{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
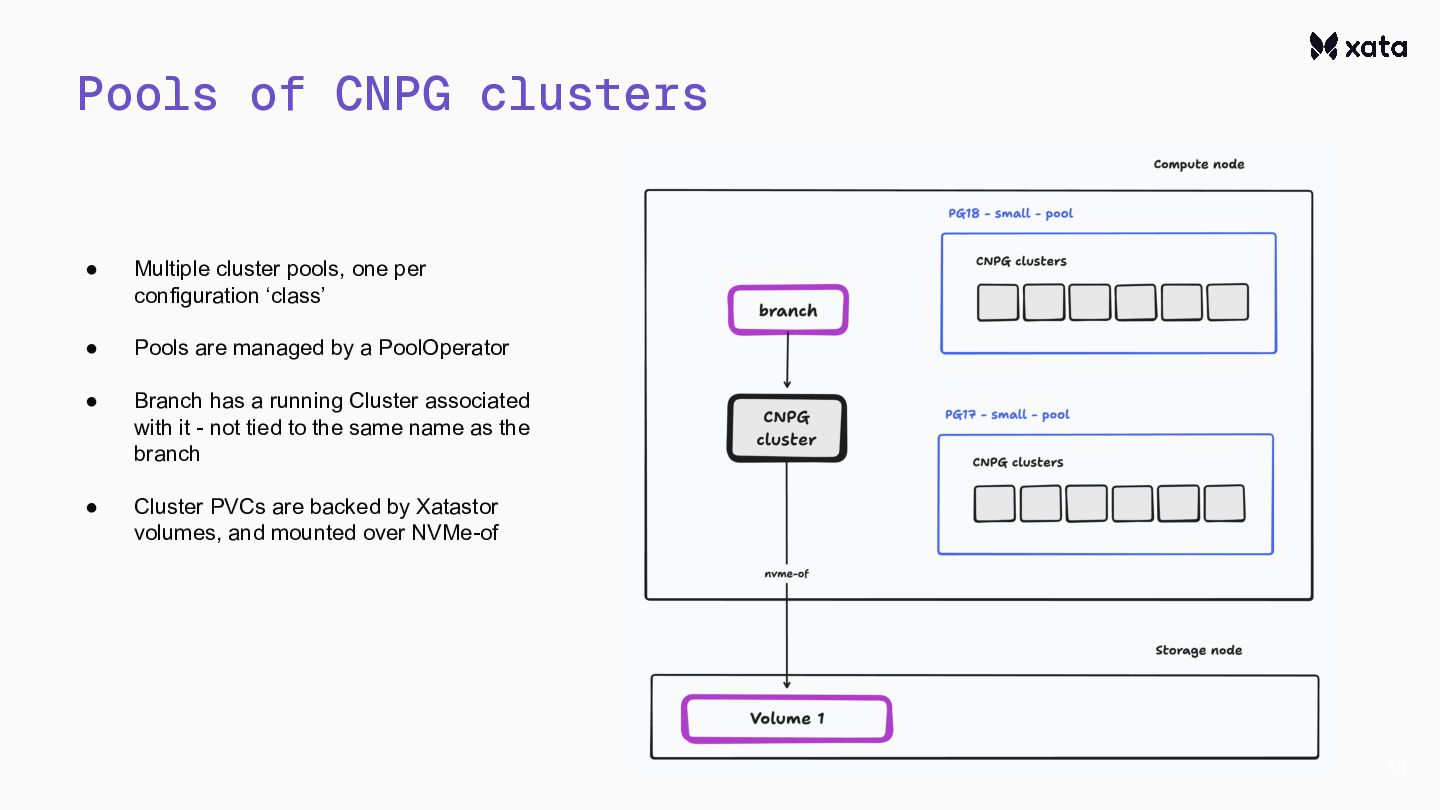{kind=link}
{kind=link}
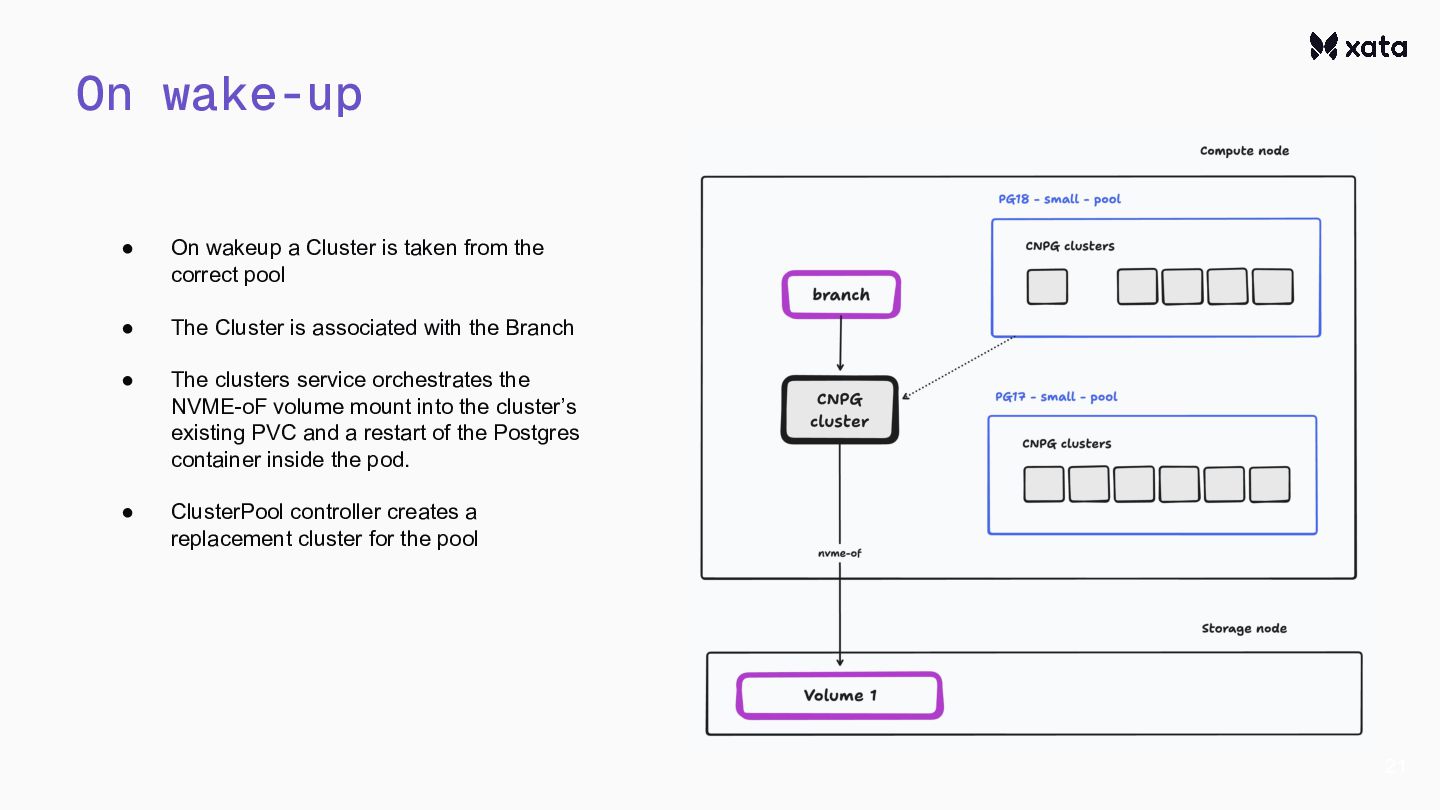{kind=link}
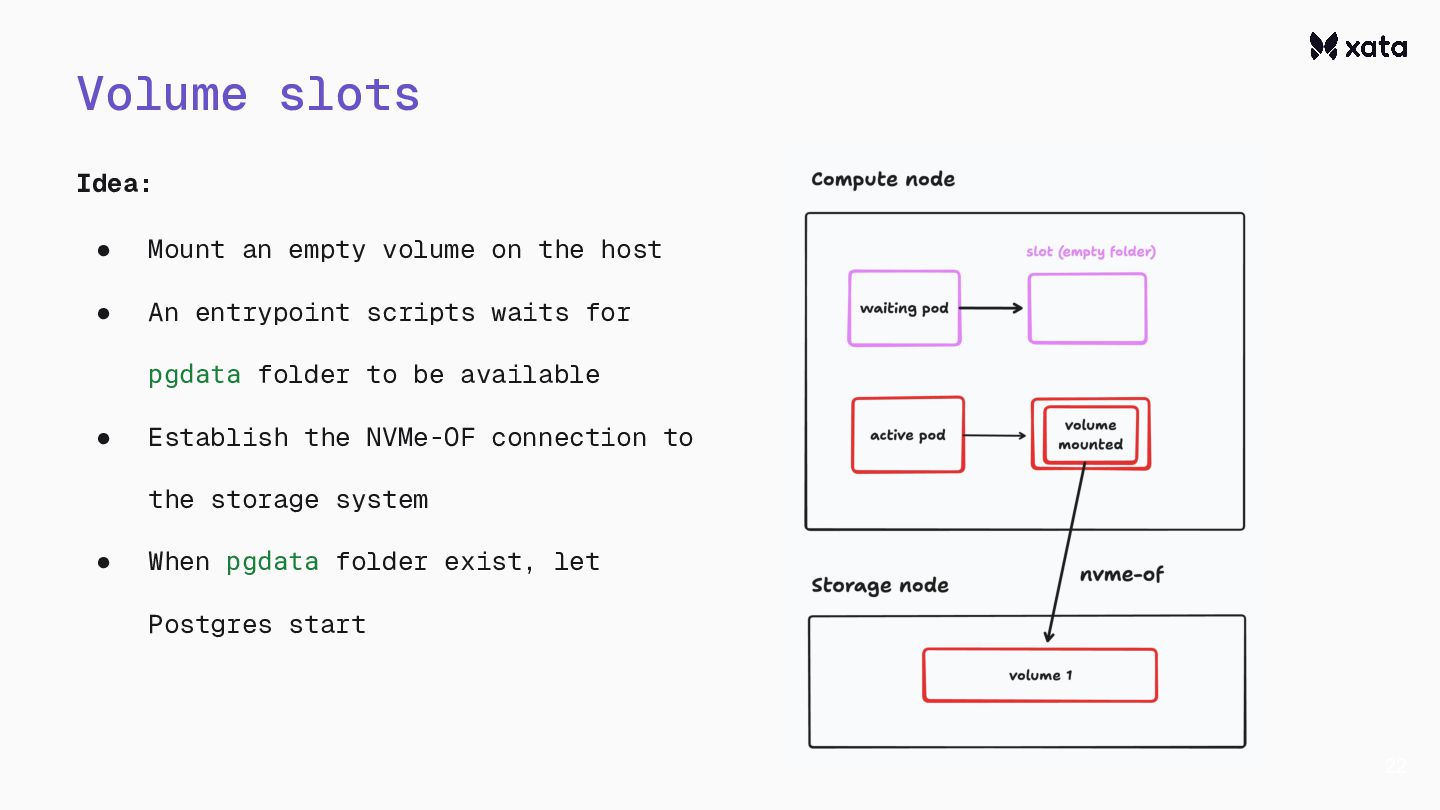{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}