1 of 2, largely because Jackalope was a very young framework and still had “lots of assembly required” to make it work. So I punted the rest of the talk to YAPC::NA 2012, this was partially because I knew Jackalope wasn’t ready and hadn’t really lived enough in the real world, and partially because ...
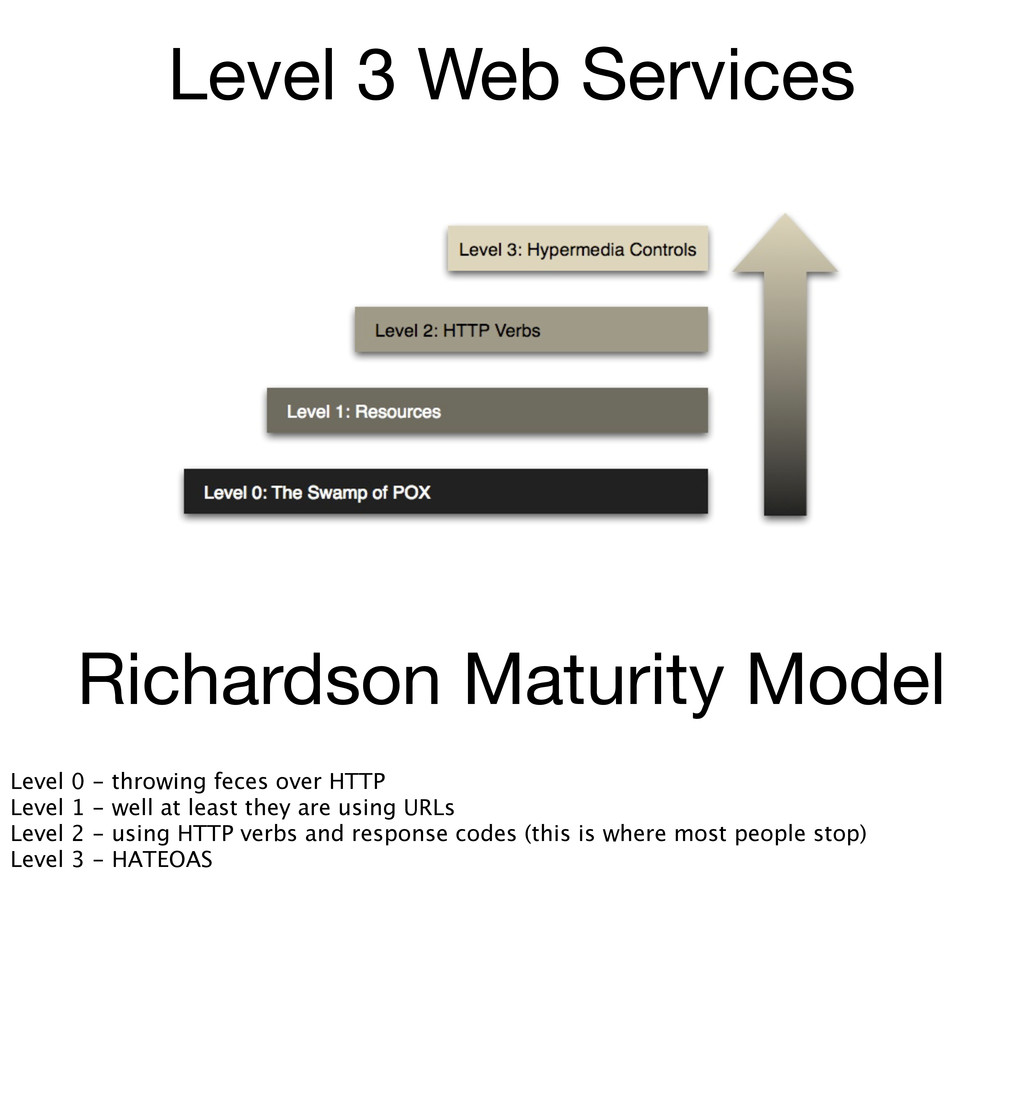
throwing feces over HTTP Level 1 - well at least they are using URLs Level 2 - using HTTP verbs and response codes (this is where most people stop) Level 3 - HATEOAS
a concept described by Roy Fielding in his thesis in which he described the REST architectural style. One key thing to keep in mind, REST is an “architectural style”, which is more akin to a design pattern, which is yet another misunderstood idea, which perhaps explains why REST is so misunderstood (trust me, I know, I misunderstood it a few times). So after spending some time on theory, I then ...
‣ ‣ ‣ “Be strict in what you emit, liberal in what you accept” There are good points to this and bad points, but the reality is that if you want people to use your API, this is probably a good philosophy to follow. Schema languages are just overhead, both computationally and conceptually, and they create a tight coupling between the client and server, by being more liberal in what you accept it is easier to evolve your service.
REST != CRUD ‣ ‣ ‣ REST is often associated with CRUD, partially because the ATOM Publishing protocol is a great example of REST, and partially cause CRUD is a simple thing to map too. Reality is that not all your web-services are CRUD and so anything that makes that assumption fails. In particular Jackalope got to the point where it insisted on CRUD and anything non-CRUD had to work around it.
REST != CRUD ‣ You can’t selectively use HTTP ‣ ‣ HTTP is hard, there is a lot of stuff to think about. But if you really are intent on using it, then you should use it all, not just a handful of status codes and a few methods. A perfect example of where Jackalope got this wrong is that it stuffed metadata into the body (the ID (should have been the Location header), the version (should have been in the ETag header) and links (should have been in the Links header)). Later on I will demonstrate this and how it made certain things just work.
REST != CRUD ‣ You can’t selectively use HTTP ‣ Front-end guys hate HATEOAS ‣ HATEOAS is a great concept, I still believe in it, but not for all cases. Writing discoverable code is a really cool idea, but fact is that a stable UI needs to be able to rely on certain things. So there has to be a balance here, which means, support both.
REST != CRUD ‣ You can’t selectively use HTTP ‣ Front-end guys hate HATEOAS ‣ Content-Type = application/json JSON is great, I love it. However, when all you emit is application/json, you are missing out. Content-types are important and content-negotiation is even more so. A lot can be said through custom content-types, including the ability to “downgrade” and deal with plain old JSON.
just for computers, but for humans too. It should be possible to explore an API with something as low-level as Curl and to be able to navigate it as a human (albiet a human who knows HTTP), and then program a computer to do the same. The key to this I believe is actually being strict about your HTTP, which gives you a common language, which is hugely important.
have long held the belief that a good architecutre has something I call a “Hack Layer” in it. This is a reasonably isolated layer in which you stuff all the bits which make no logical sense, but do make business sense (cause we all know business is not logical). So from here I started doing some research ...
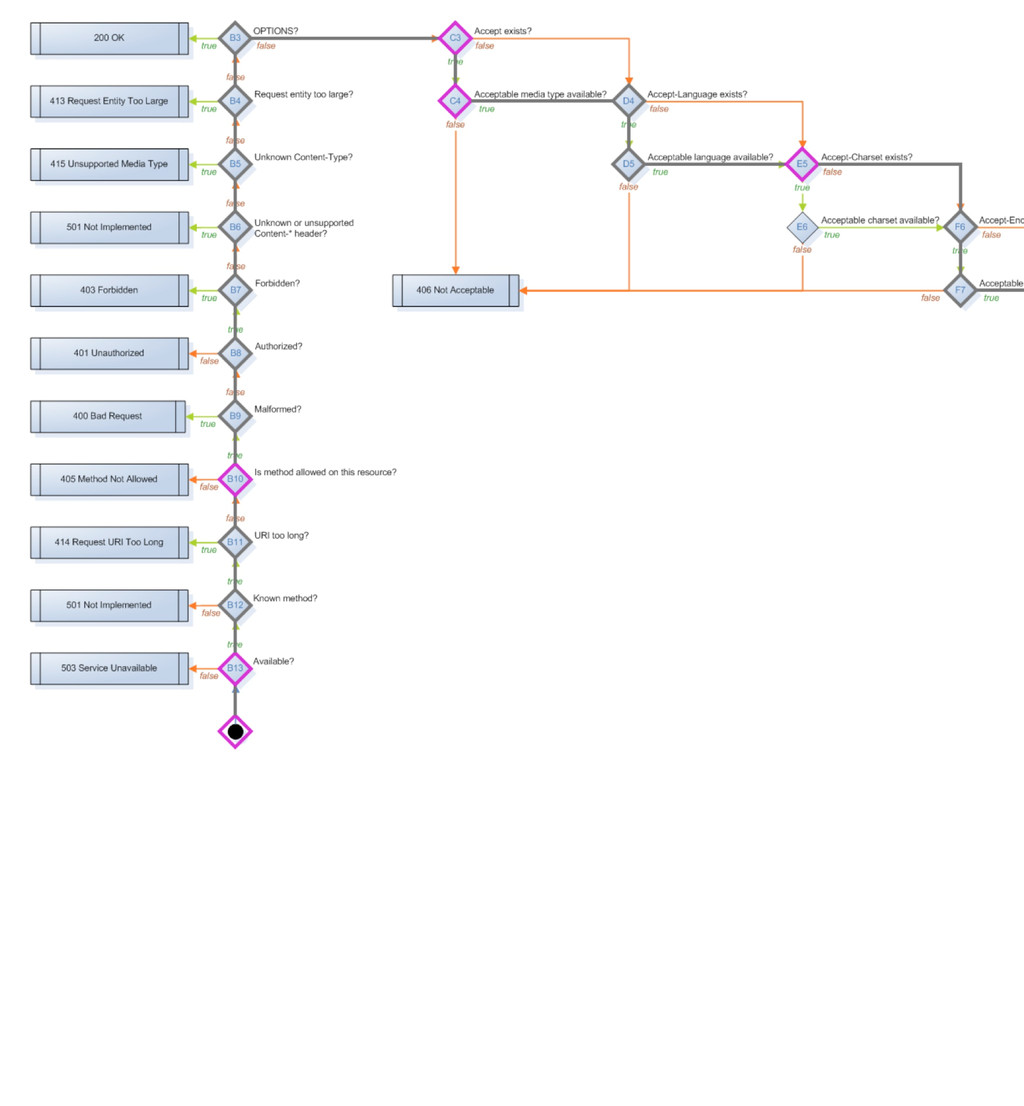
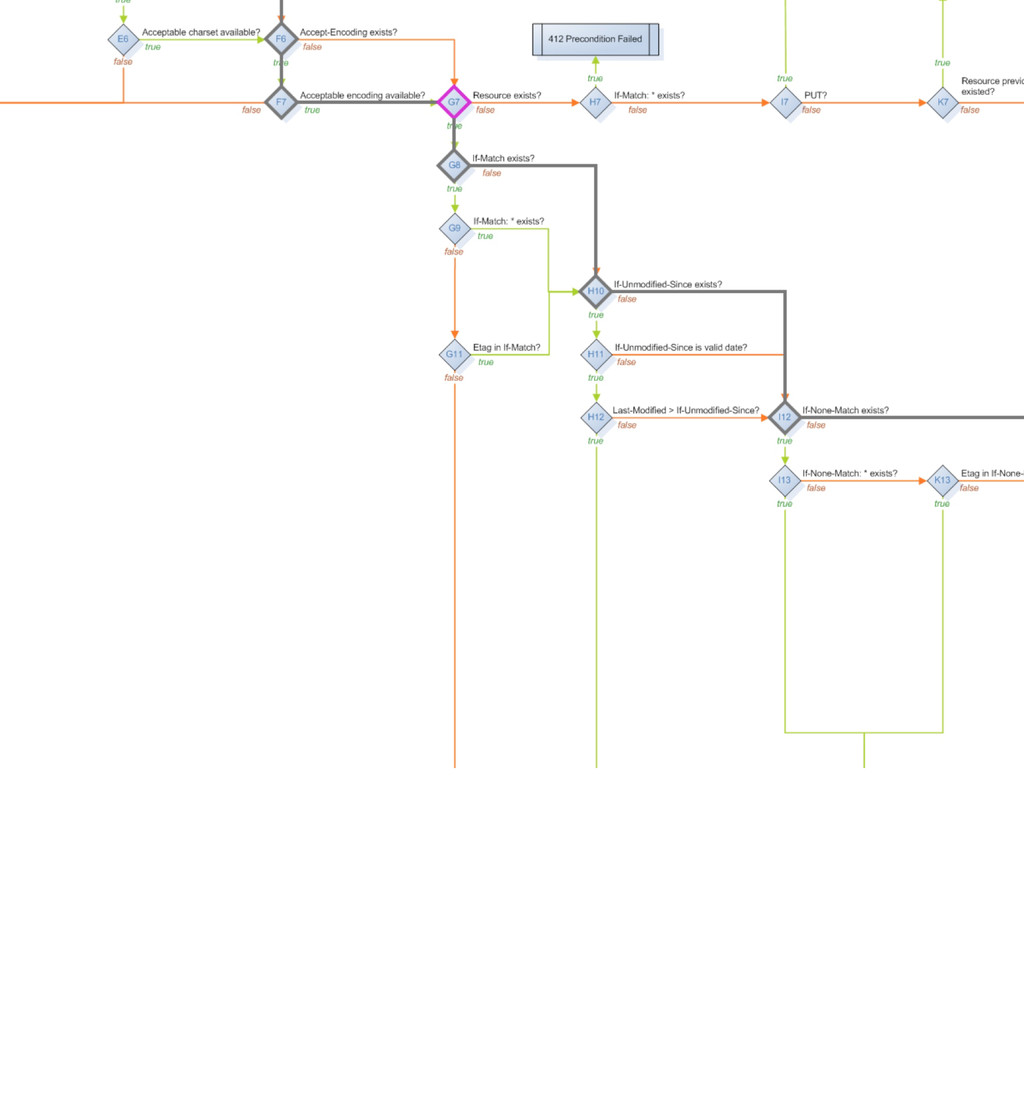
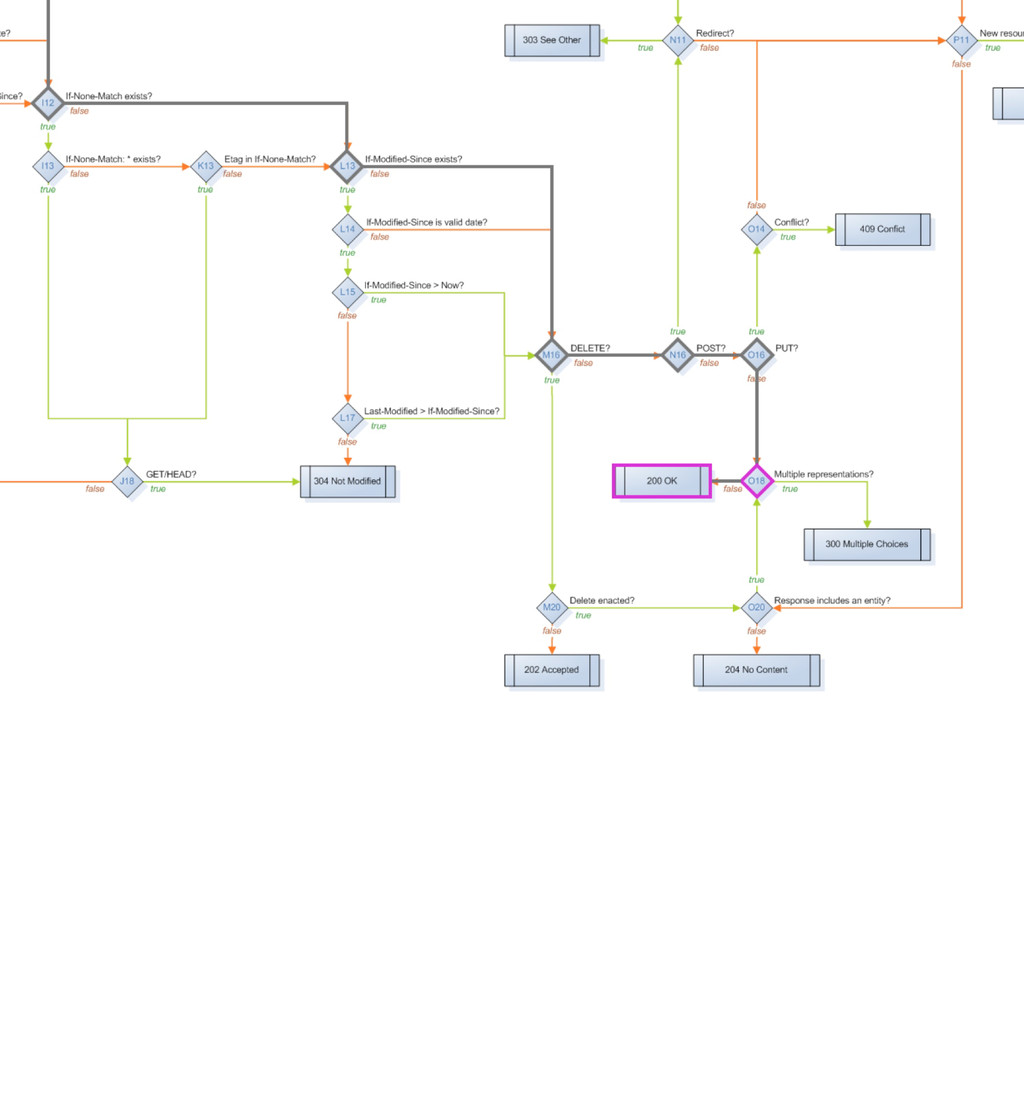
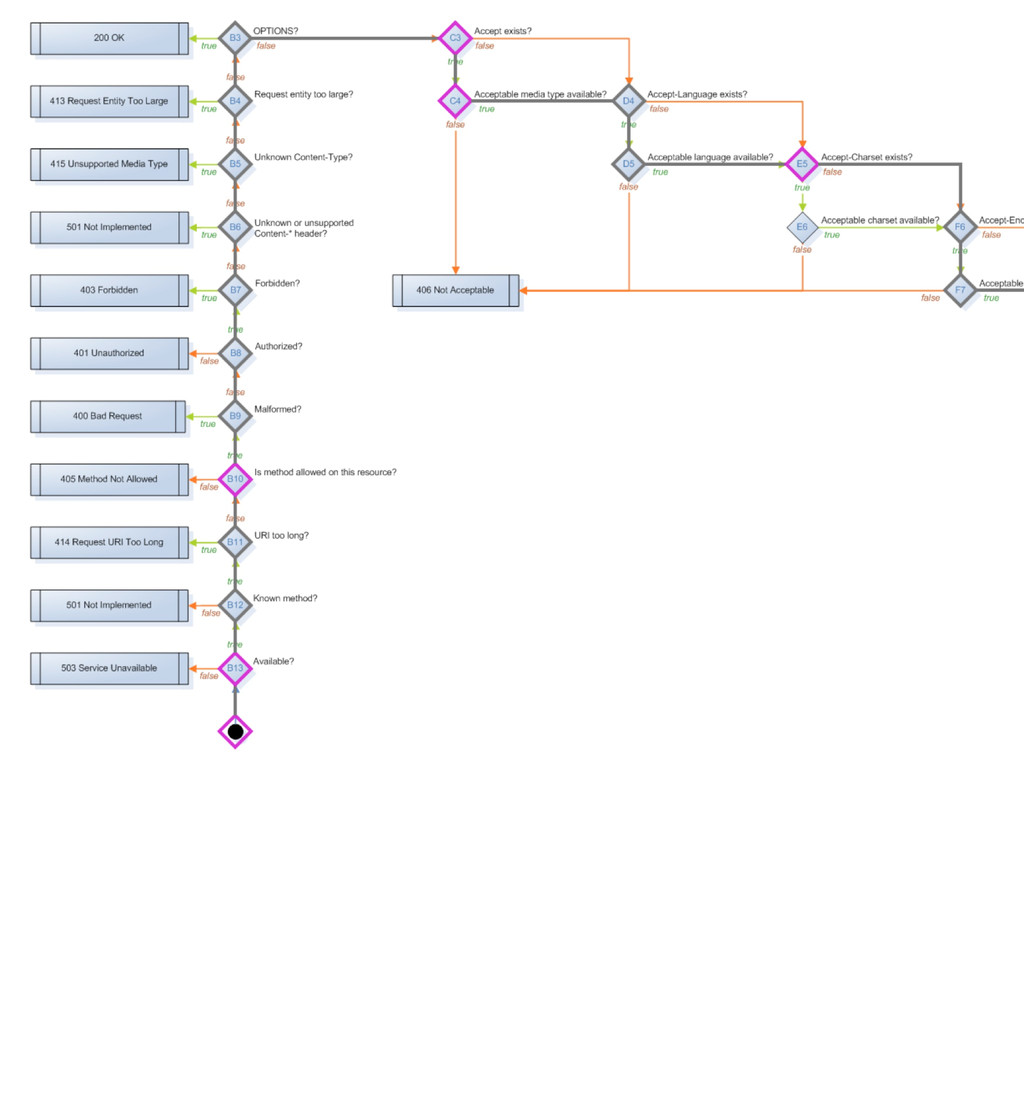
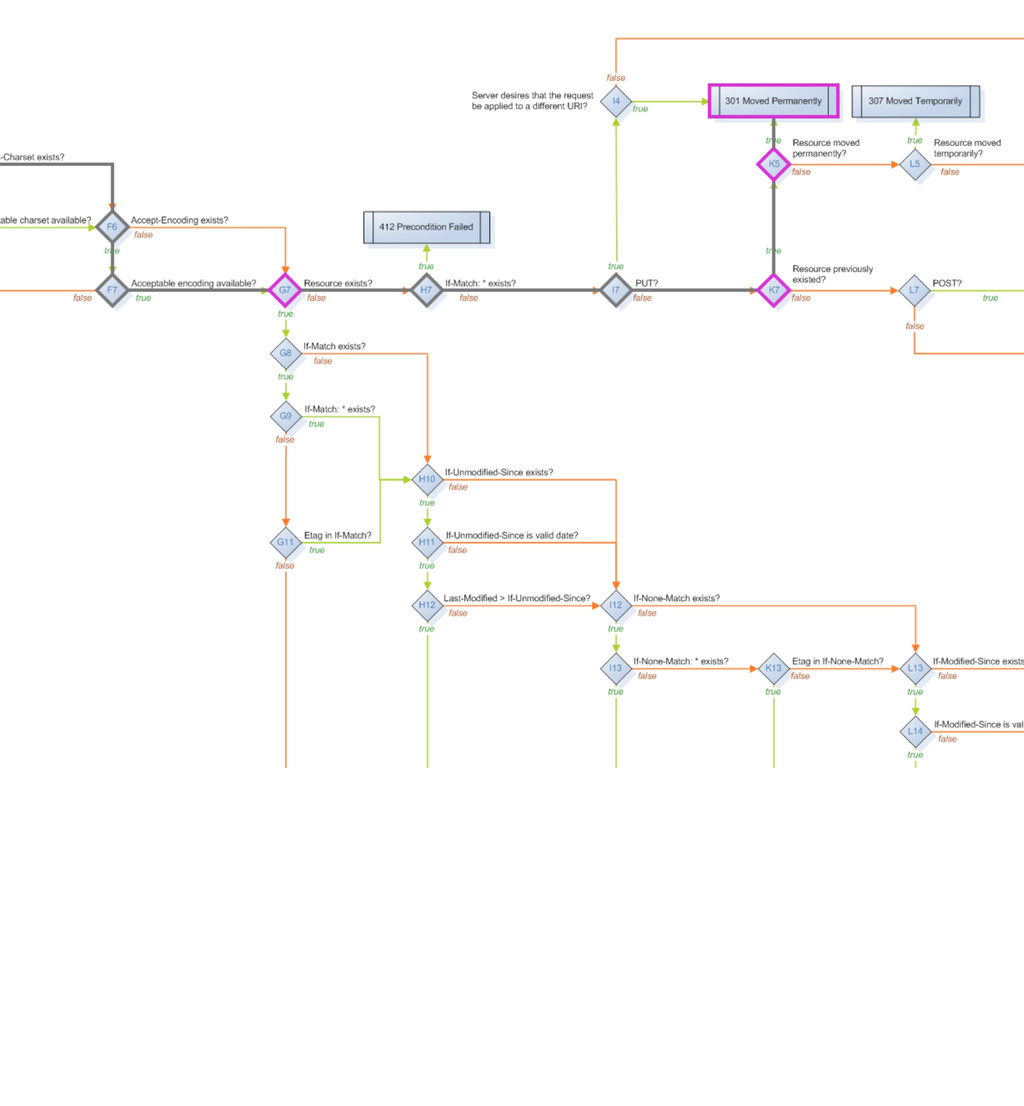
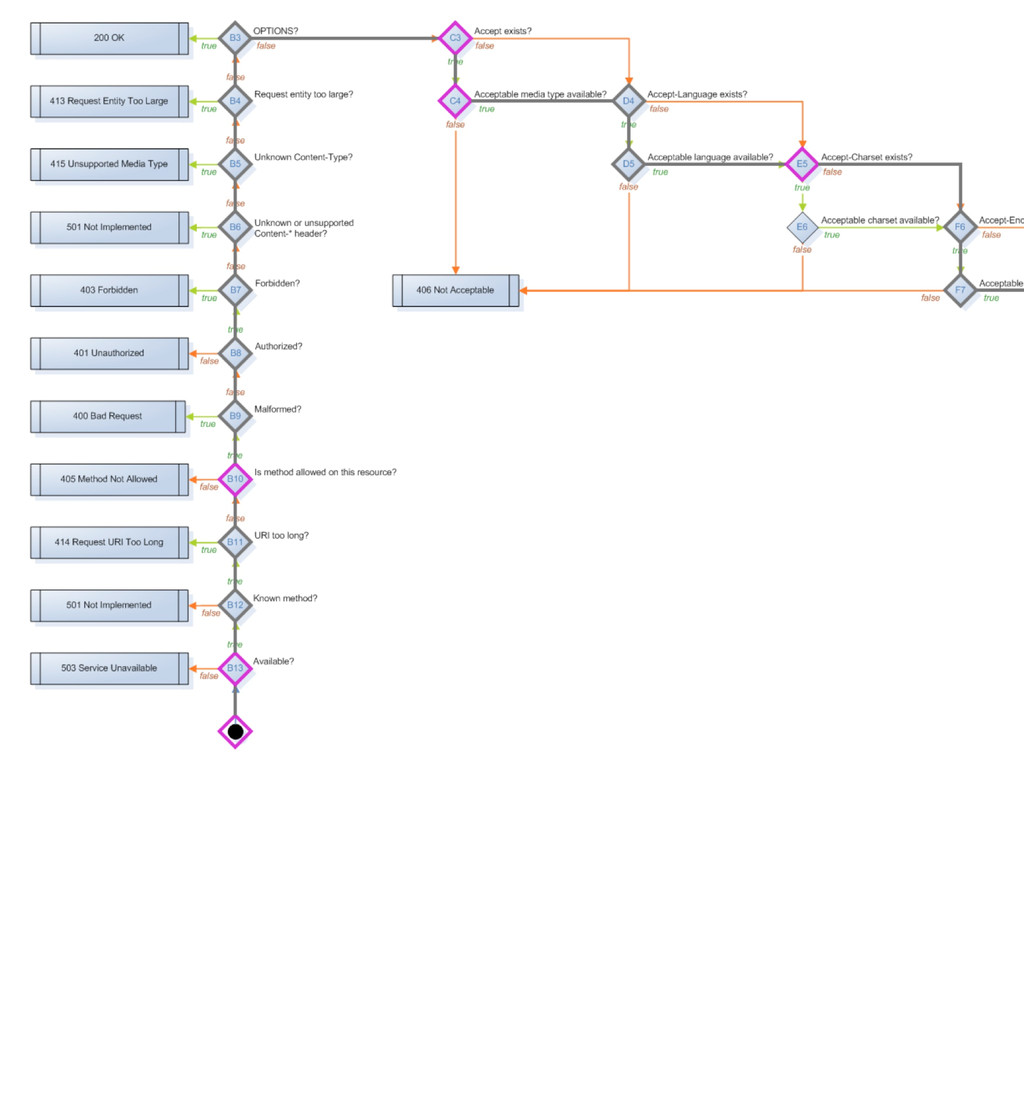
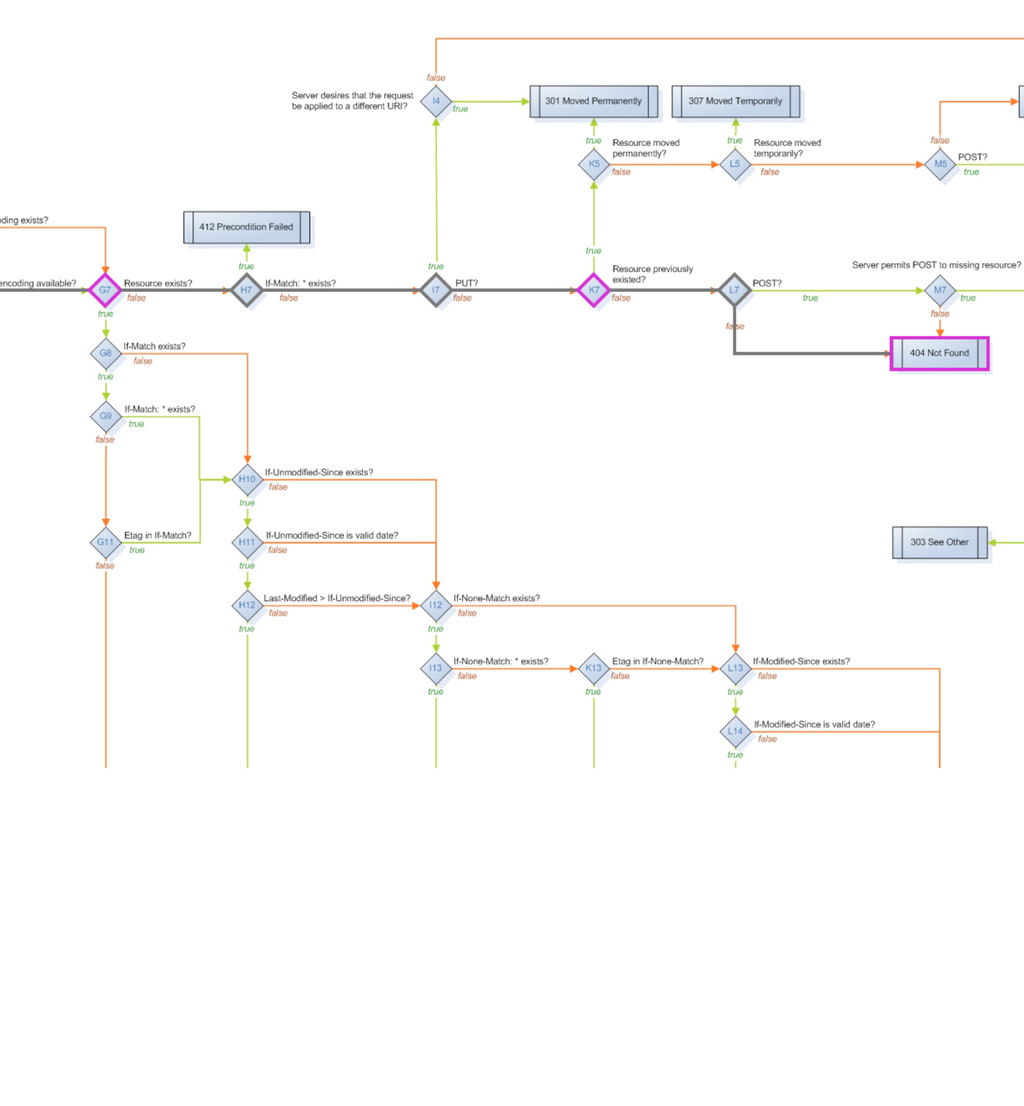
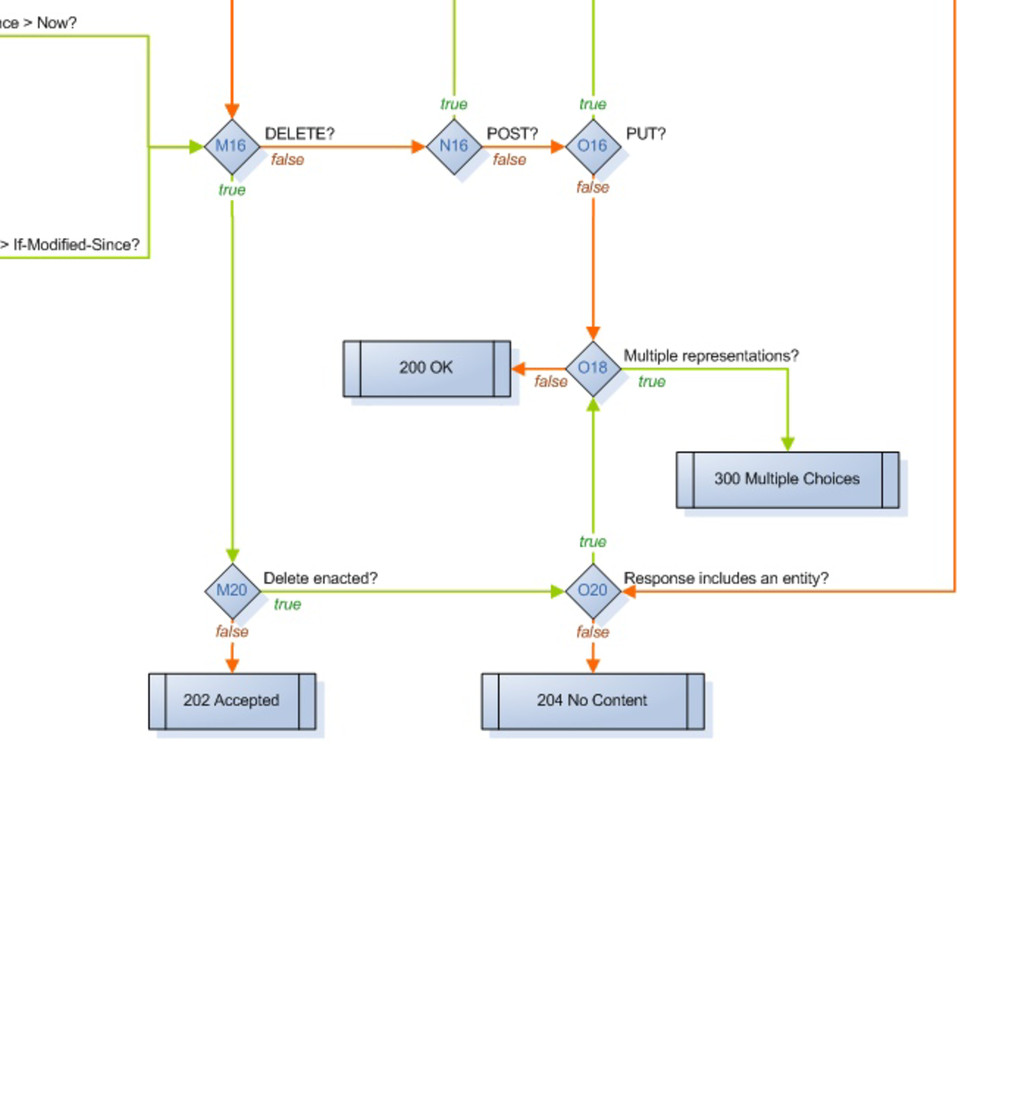
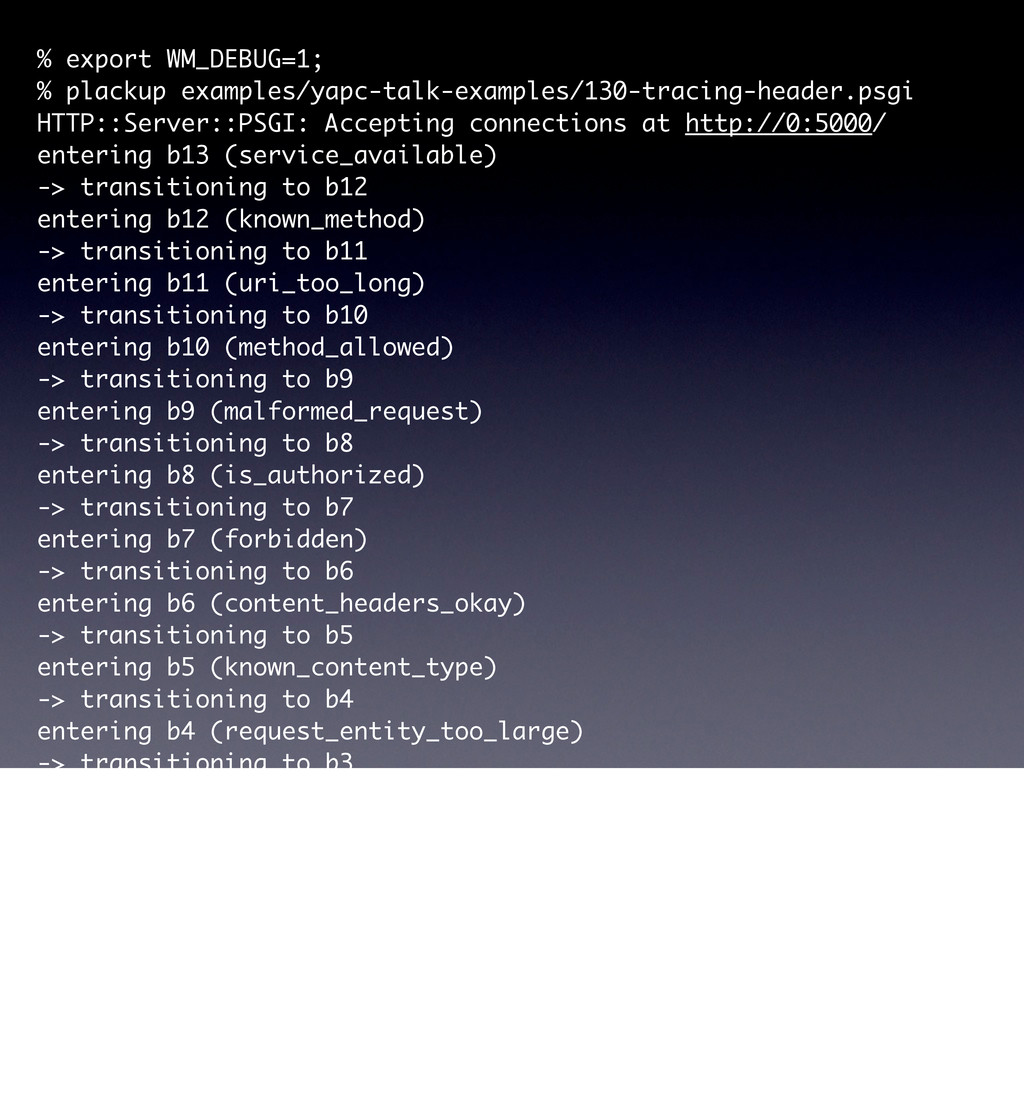
method_is_get_or_head method_is_options method_is_post method_is_put moved_permanently moved_temporarily multiple_choices multiple_representations new_resource previously_existed redirect request_entity_too_large resource_exists response_body_includes_entity service_available uri_too_long acceptable_media_type_available accept_charset_choice_available accept_charset_exists accept_encoding_choice_available accept_encoding_exists accept_header_exists accept_language_choice_available accept_language_header_exists allow_post_to_missing_resource content_headers_okay delete_enacted_immediately did_delete_complete etag_in_if_match_list etag_in_if_none_match forbidden if_match_exists if_match_exists_and_if_match_is_wildcard if_match_is_wildcard if_modified_since_exists if_modified_since_greater_than_now if_modified_since_is_valid_date if_none_match_exists if_none_match_is_wildcard if_unmodified_since_exists if_unmodified_since_is_valid_date The FSM has 57 states that basically ask 50 different possible questions that are asked of a resource, a request and a response to move it through the states machine.
delete_completed post_is_create is_conflict multiple_choices previously_existed moved_permanently moved_temporarily Informational base_uri allowed_methods known_methods charsets_provided languages_provided encodings_provided variances last_modified expires generate_etag Actions options resource_exists content_types_provided content_types_accepted delete_resource create_path process_post finish_request Web::Machine::Resource A resource has 34 methods you can override to produce functionality, I have basically grouped them into three categories here. - Predicates are (for the most part) yes/no questions which guide through the state diagram - Informational methods provide Web::Machine with information about your resource - Action methods are the places where you typically do the actual work
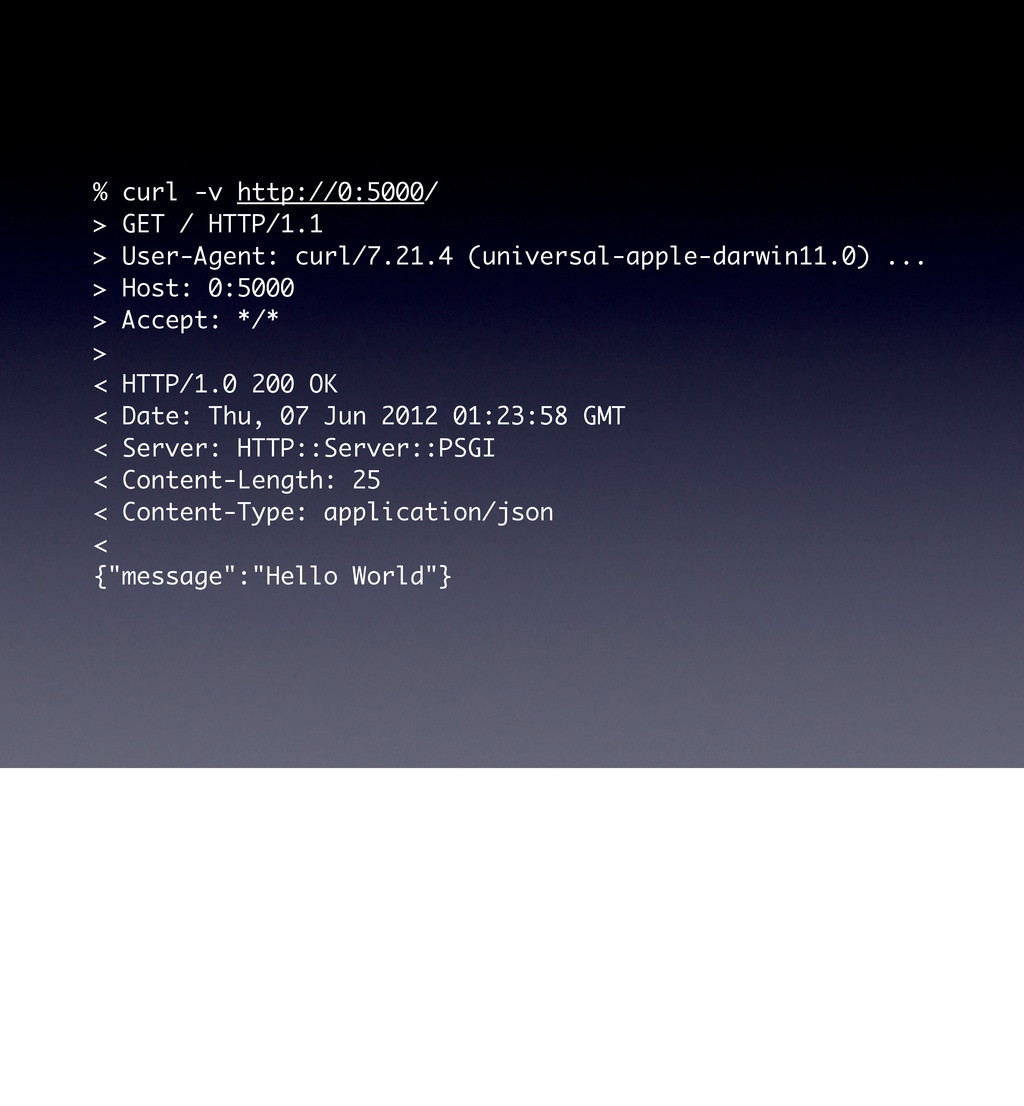
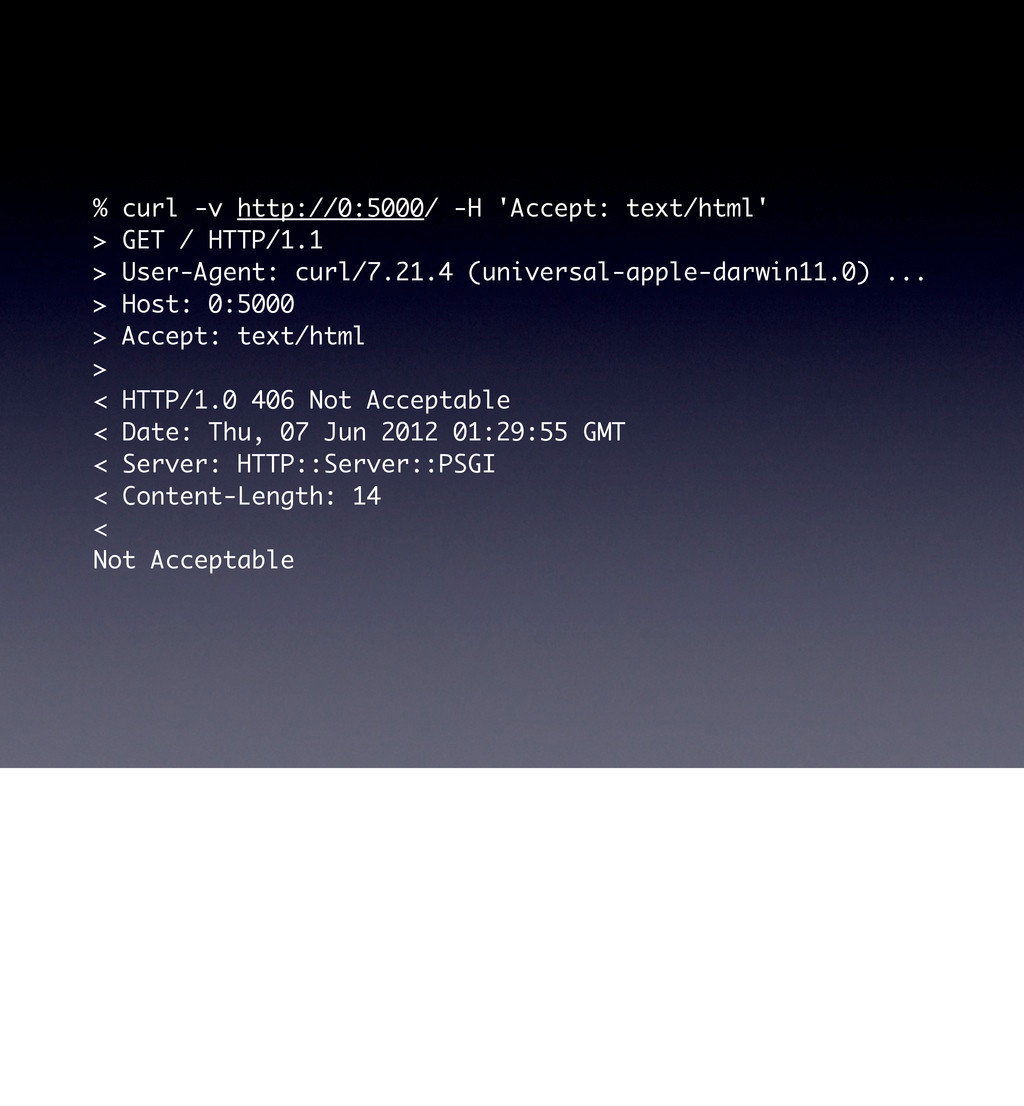
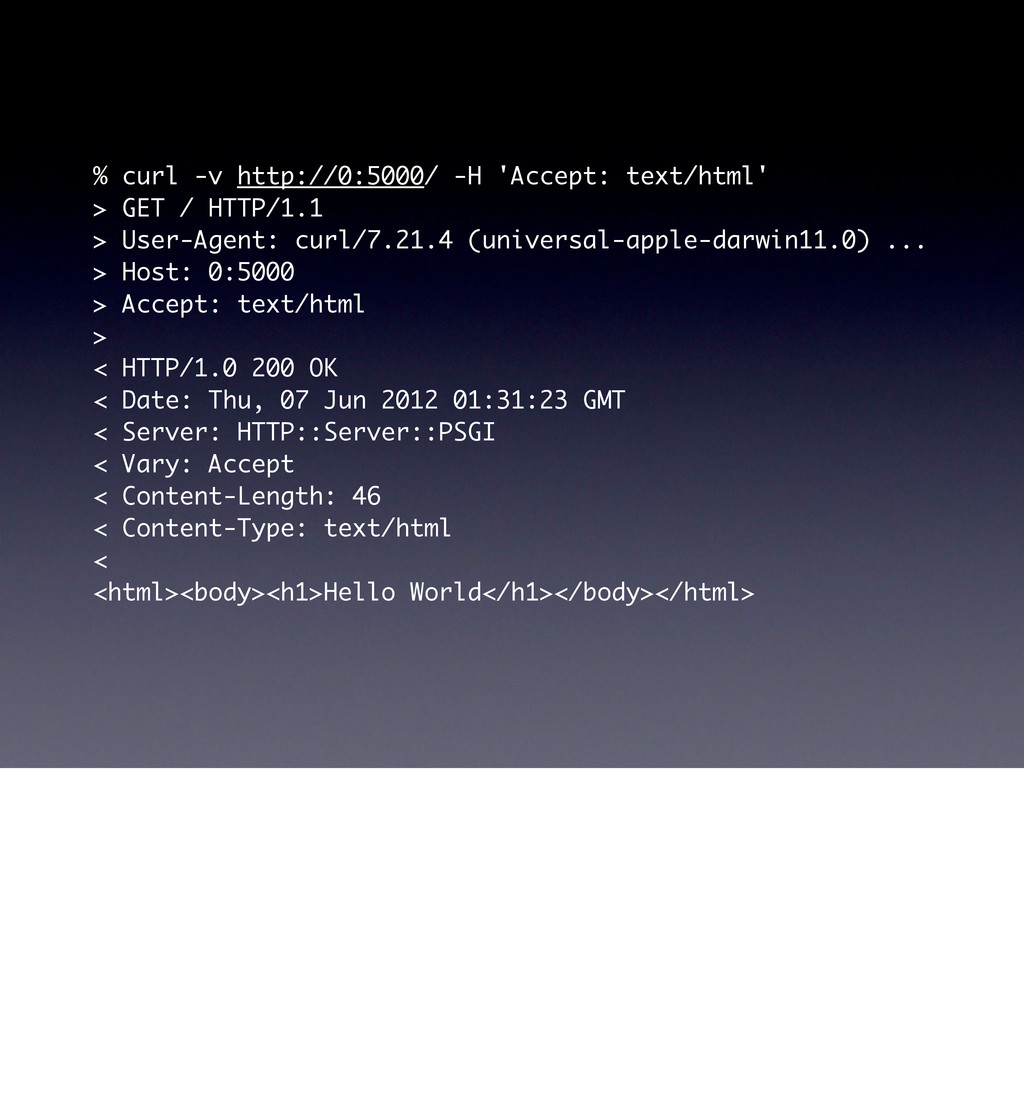
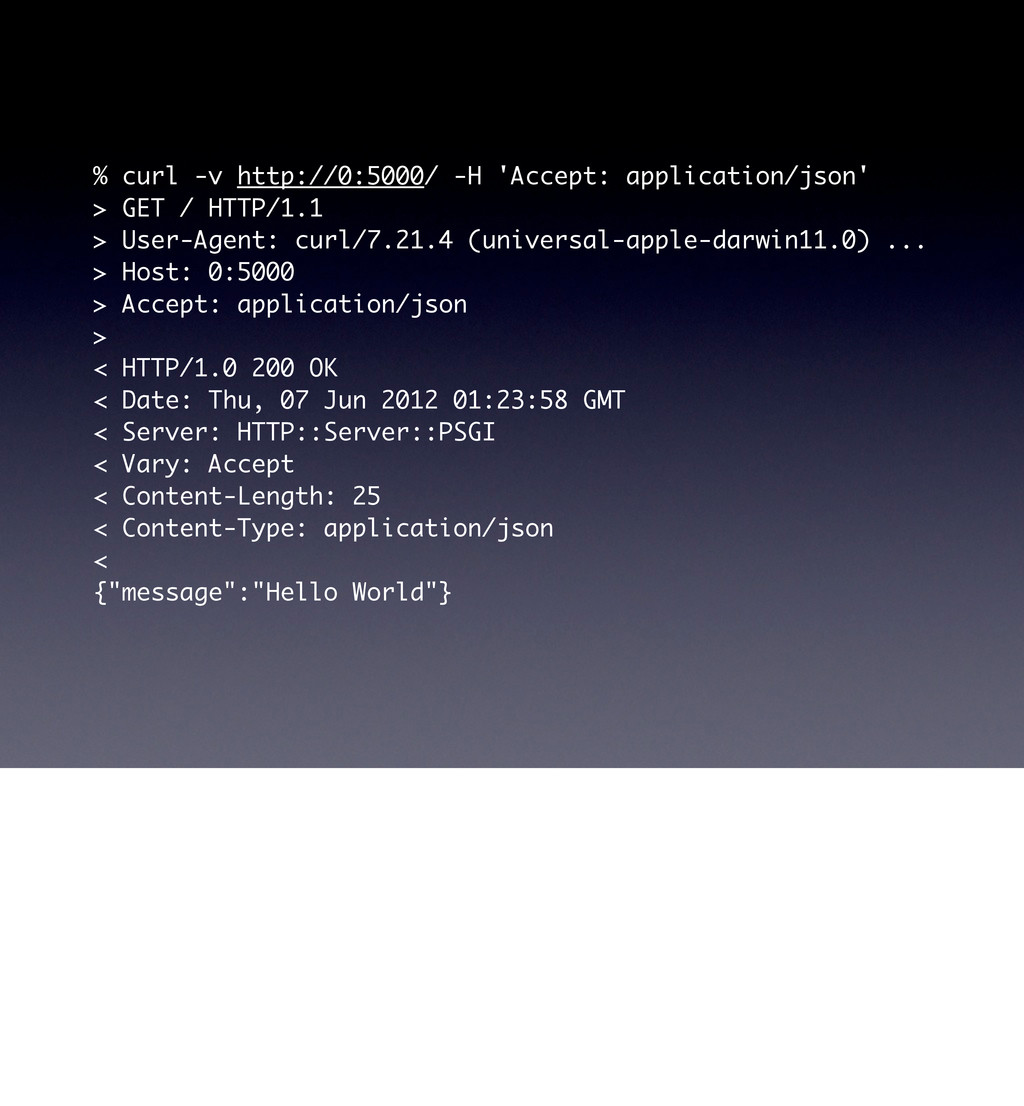
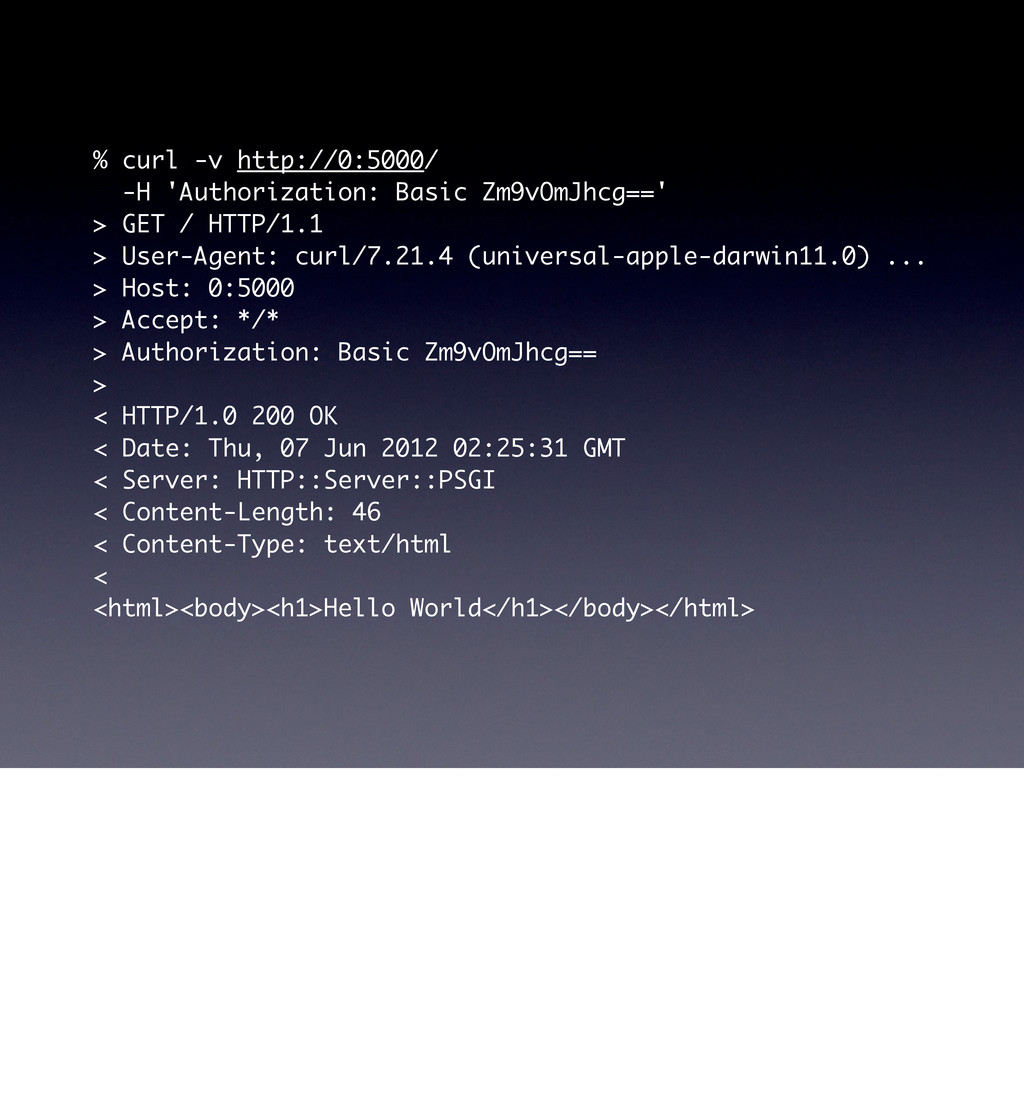
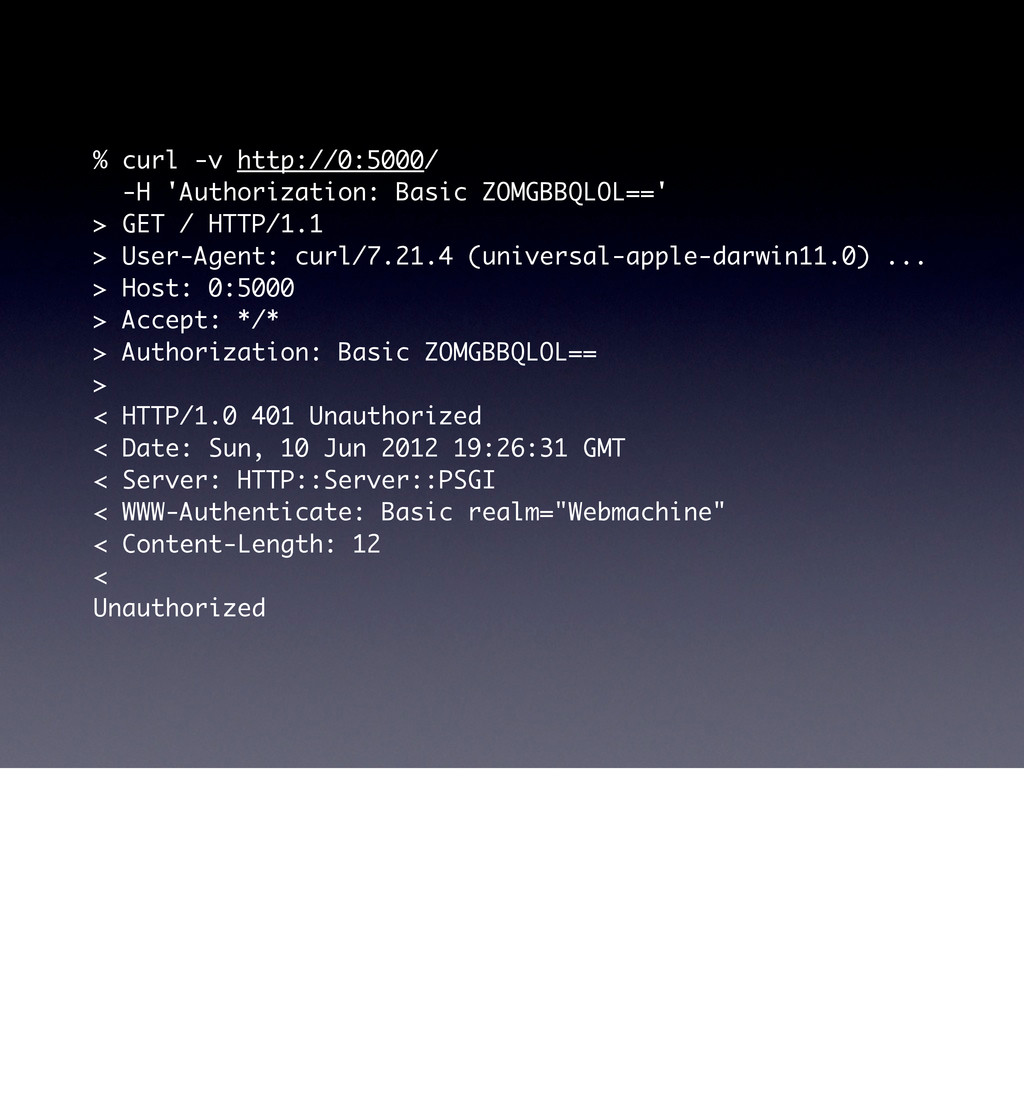
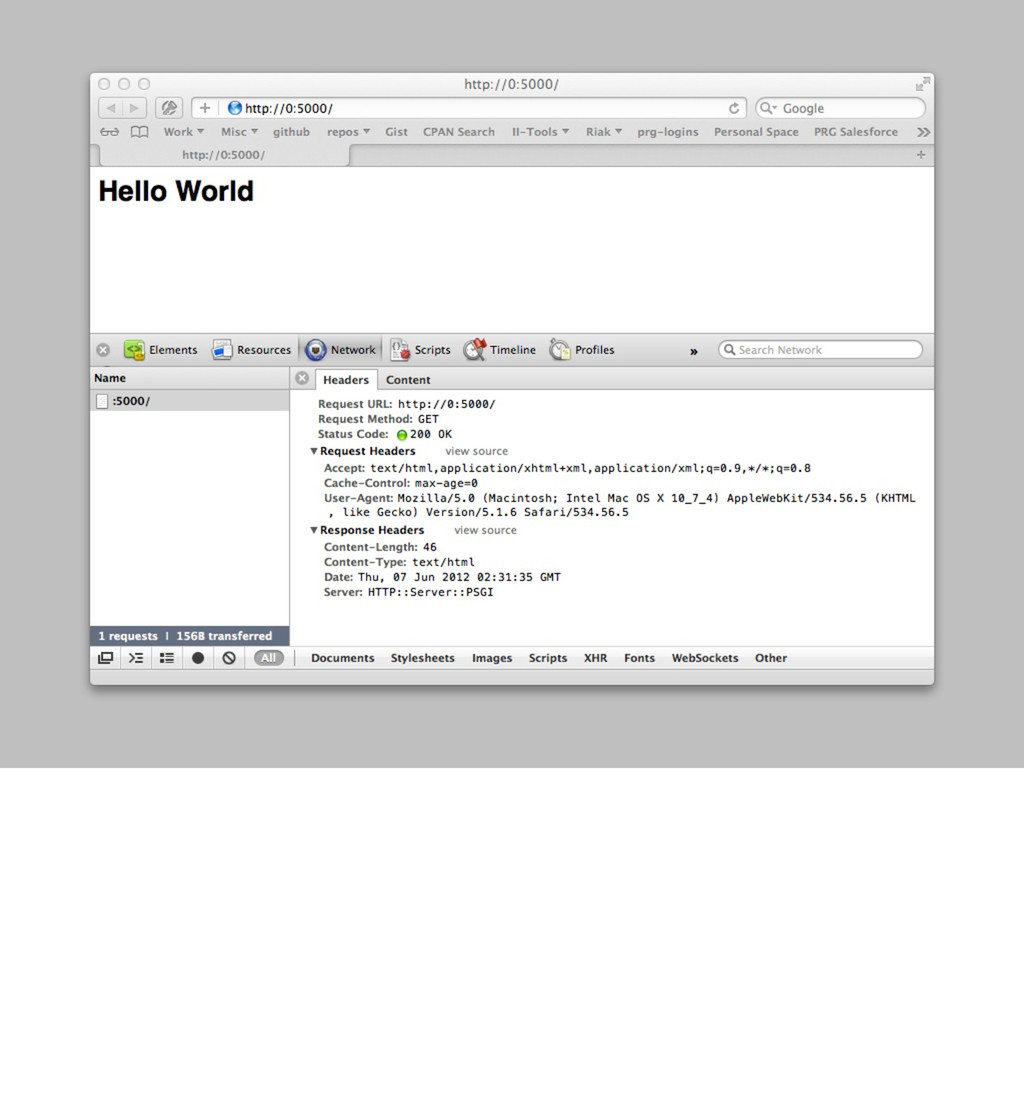
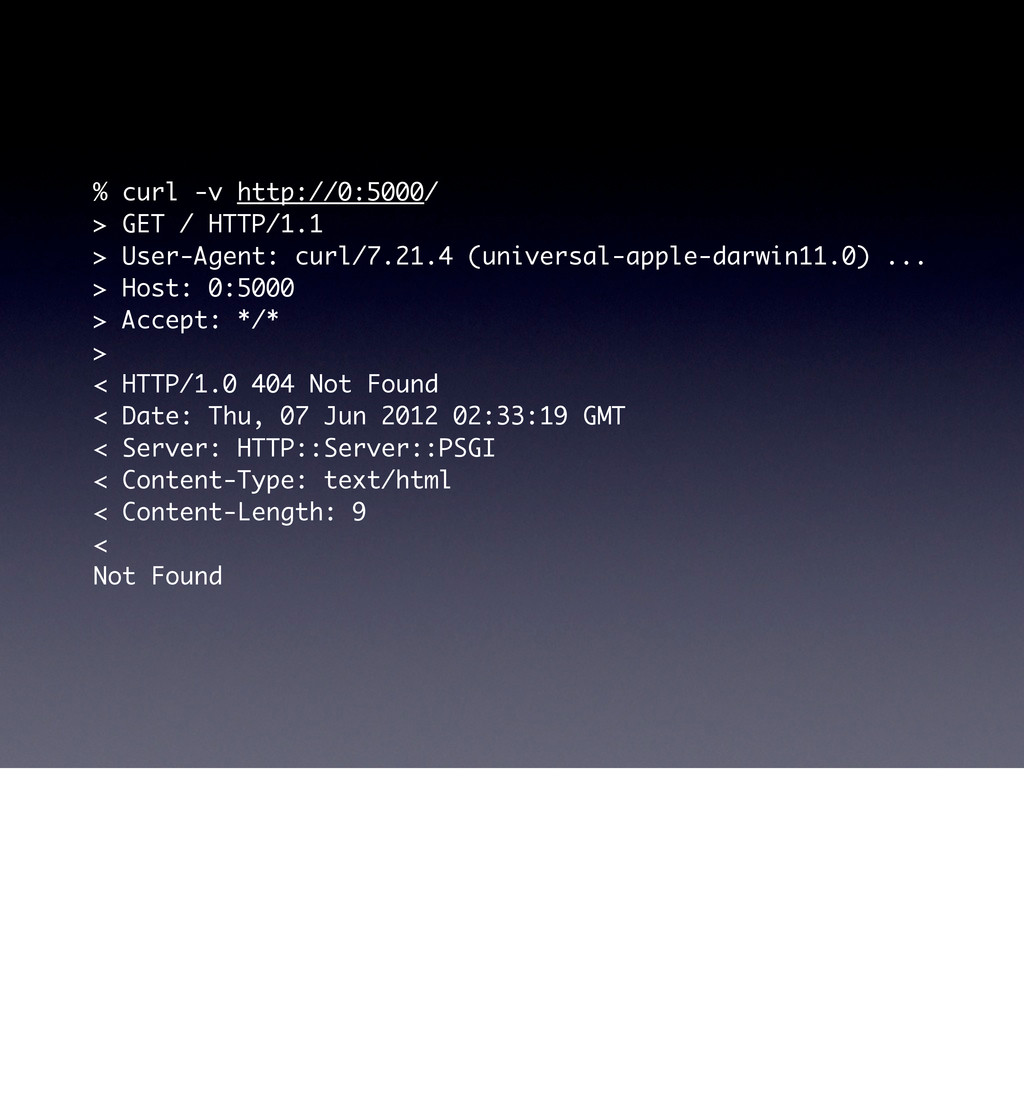
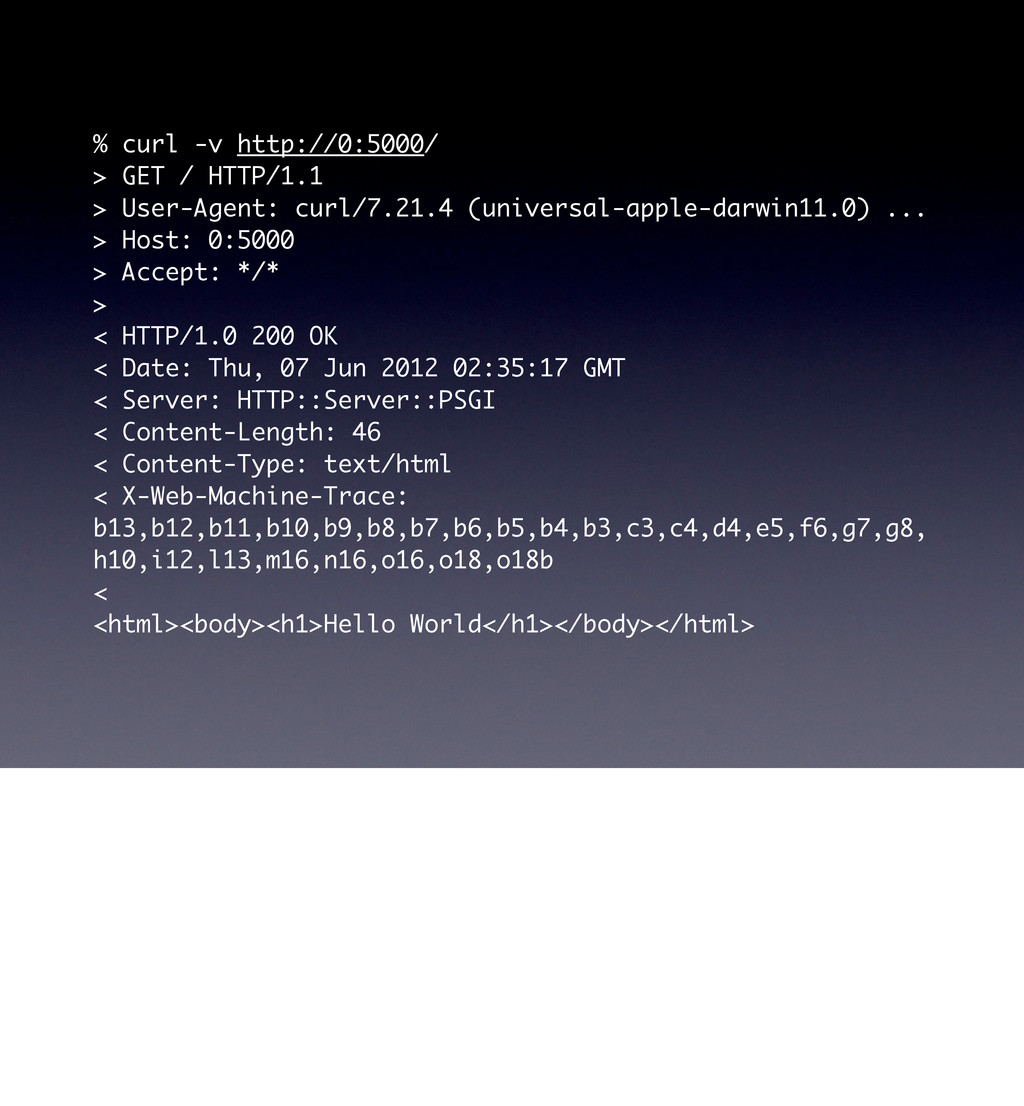
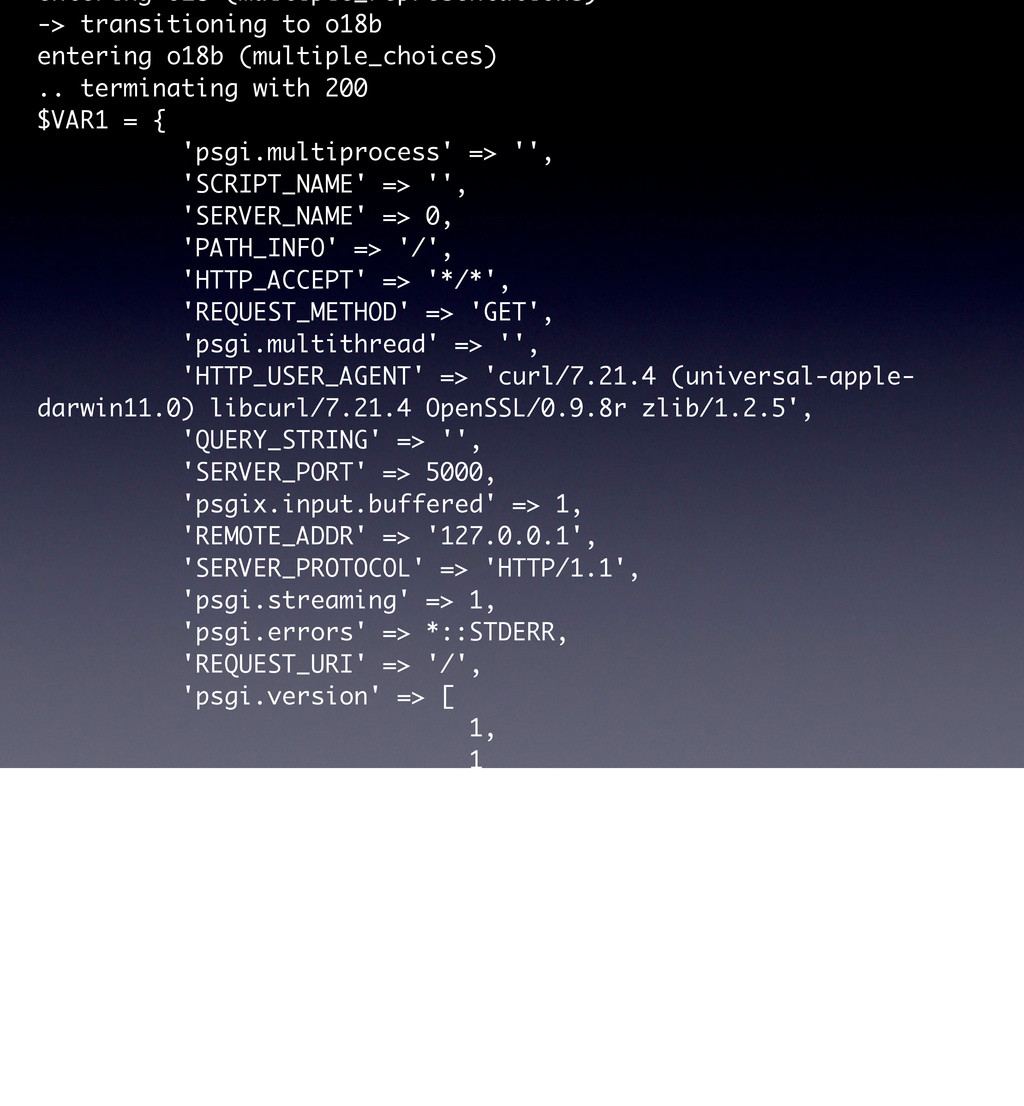
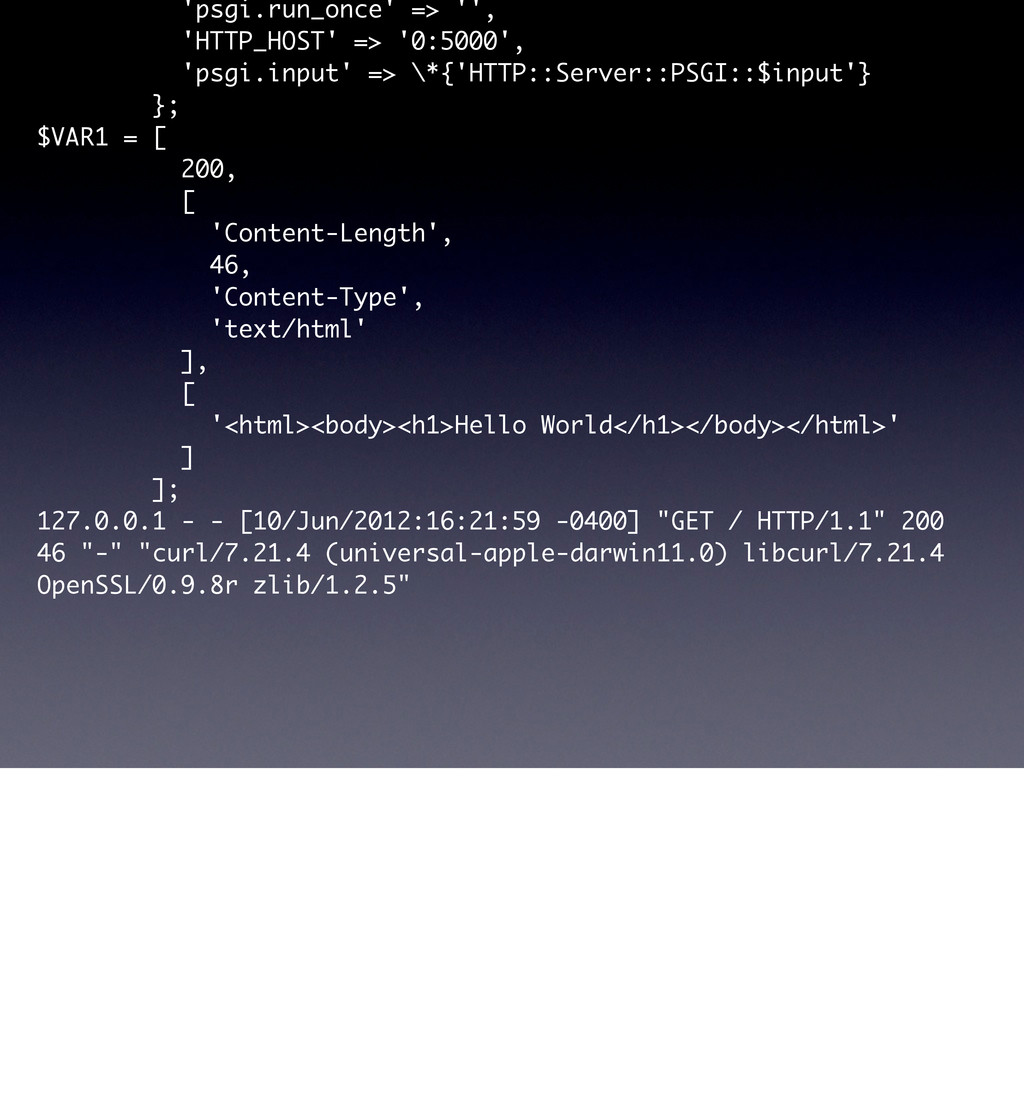
use parent 'Web::Machine::Resource'; sub content_types_provided { [ { 'application/json' => 'to_json' }, { 'text/html' => 'to_html' }, ] } sub to_json { encode_json( { message => 'Hello World' } ) } sub to_html { '<html><body><h1>Hello World</h1></body></html>' } } Web::Machine->new( resource => 'YAPC::NA::2012::Example001::Resource' )->to_app; This test shows that the order of content_types_provided is actually important if you do not specify a media-type. # JSON is the default ... curl -v http://0:5000/ # you must ask specifically for HTML curl -v http://0:5000/ -H 'Accept: text/html' # but open in a browser and you get HTML open http://0:5000/
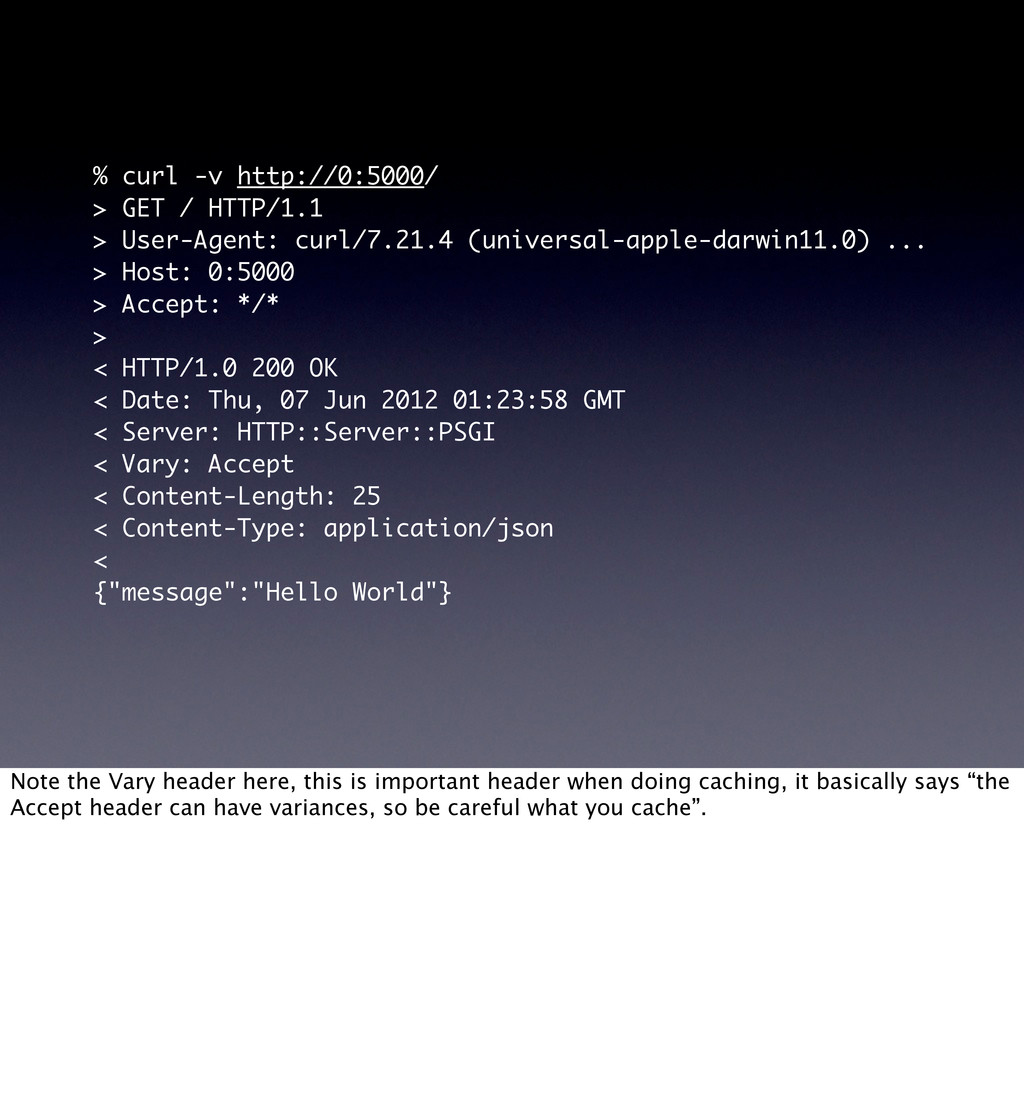
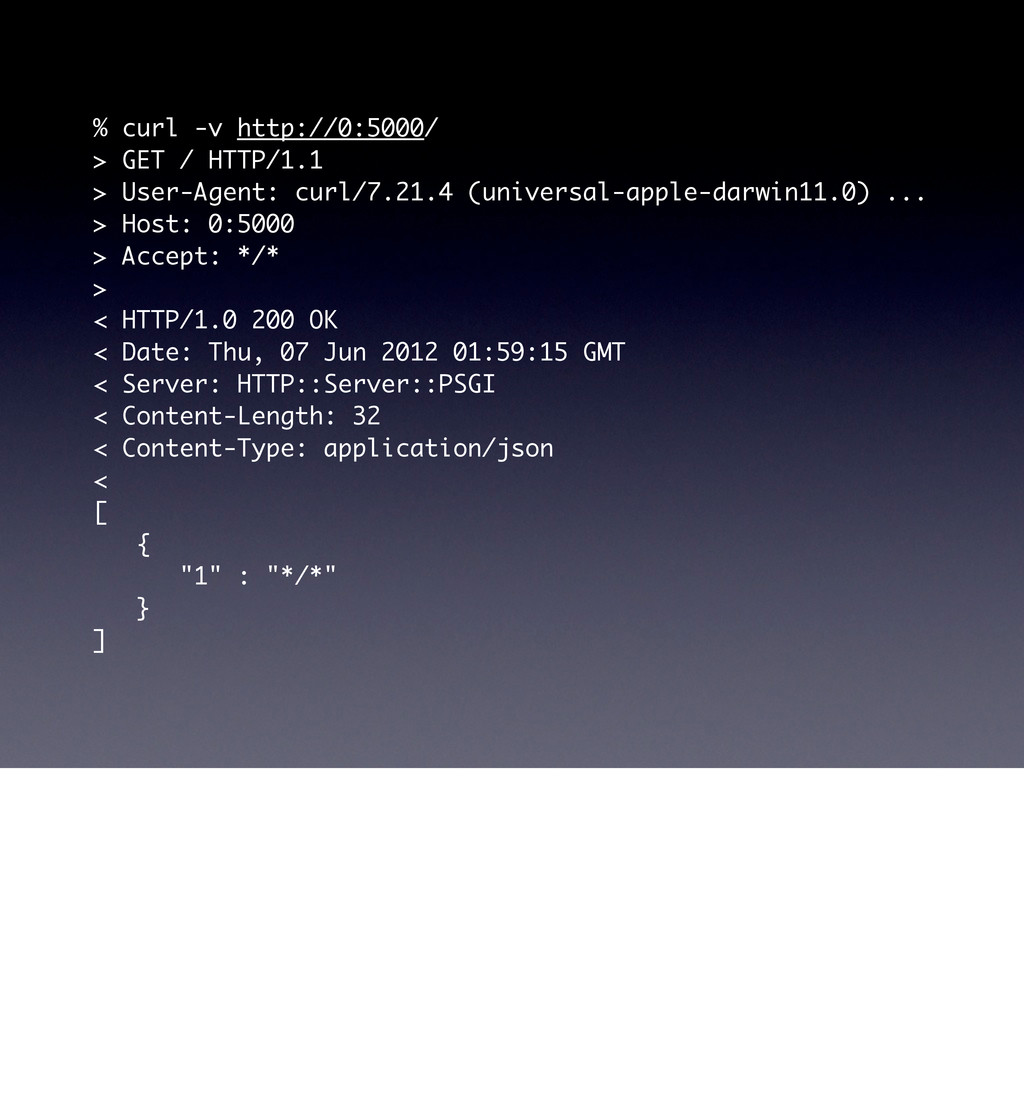
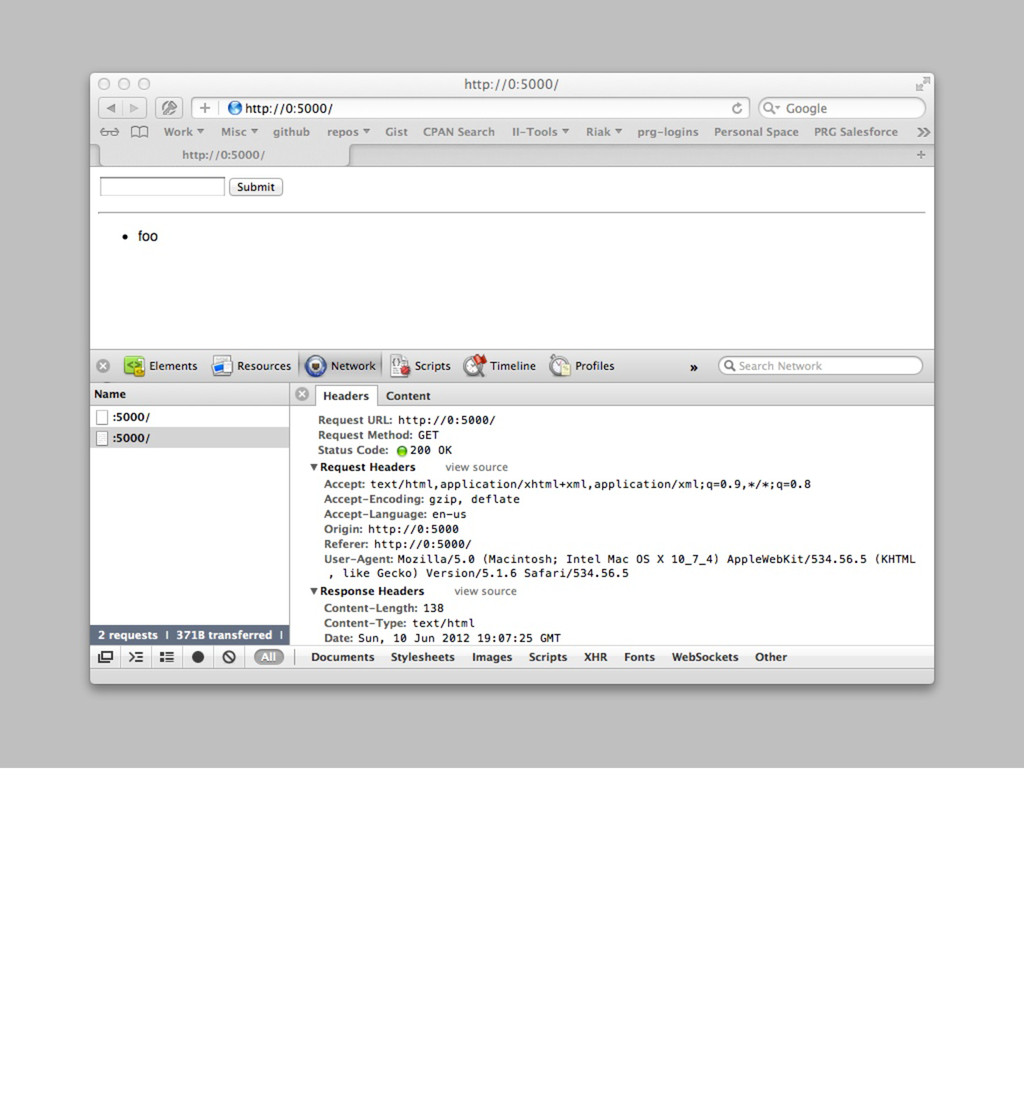
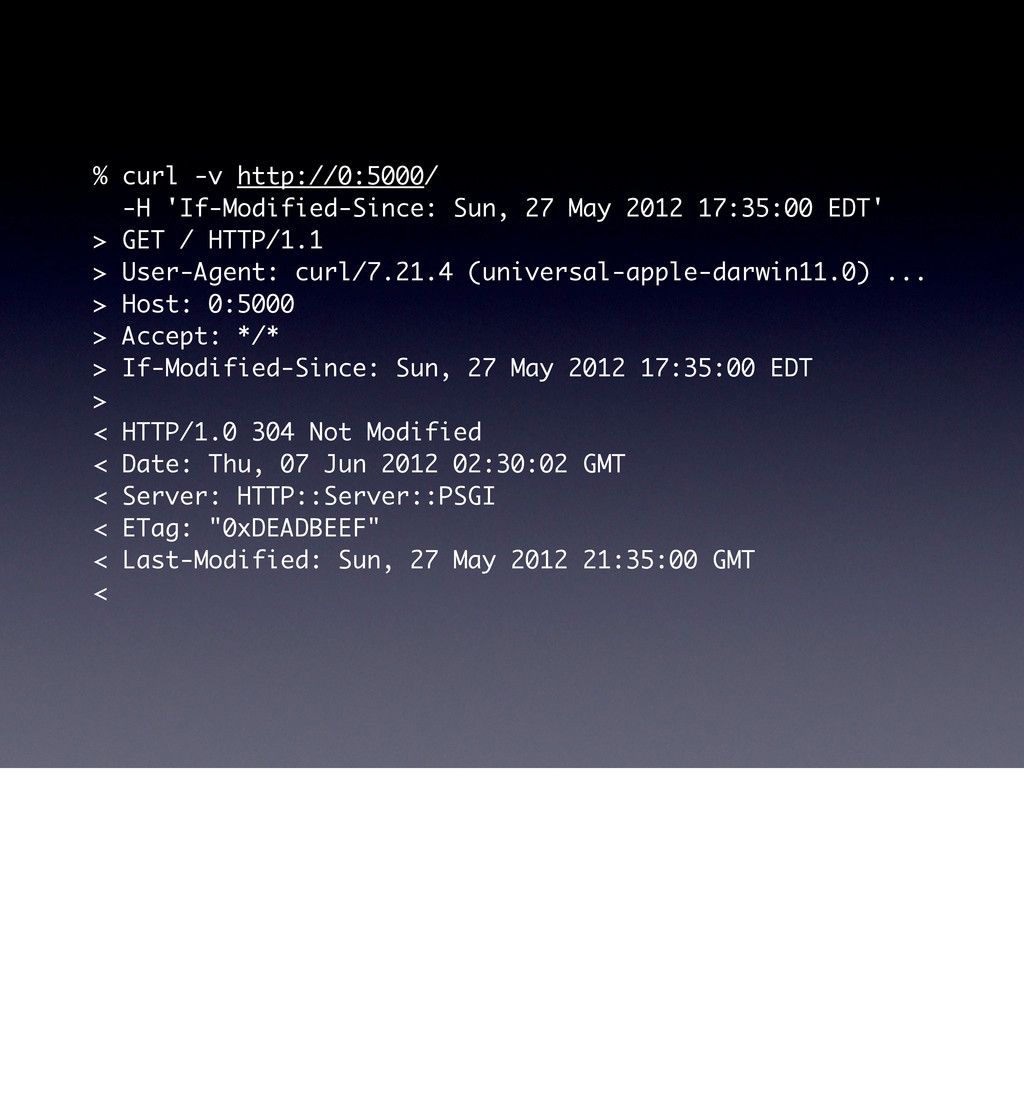
curl/7.21.4 (universal-apple-darwin11.0) ... > Host: 0:5000 > Accept: */* > < HTTP/1.0 200 OK < Date: Thu, 07 Jun 2012 01:23:58 GMT < Server: HTTP::Server::PSGI < Vary: Accept < Content-Length: 25 < Content-Type: application/json < {"message":"Hello World"} Note the Vary header here, this is important header when doing caching, it basically says “the Accept header can have variances, so be careful what you cache”.
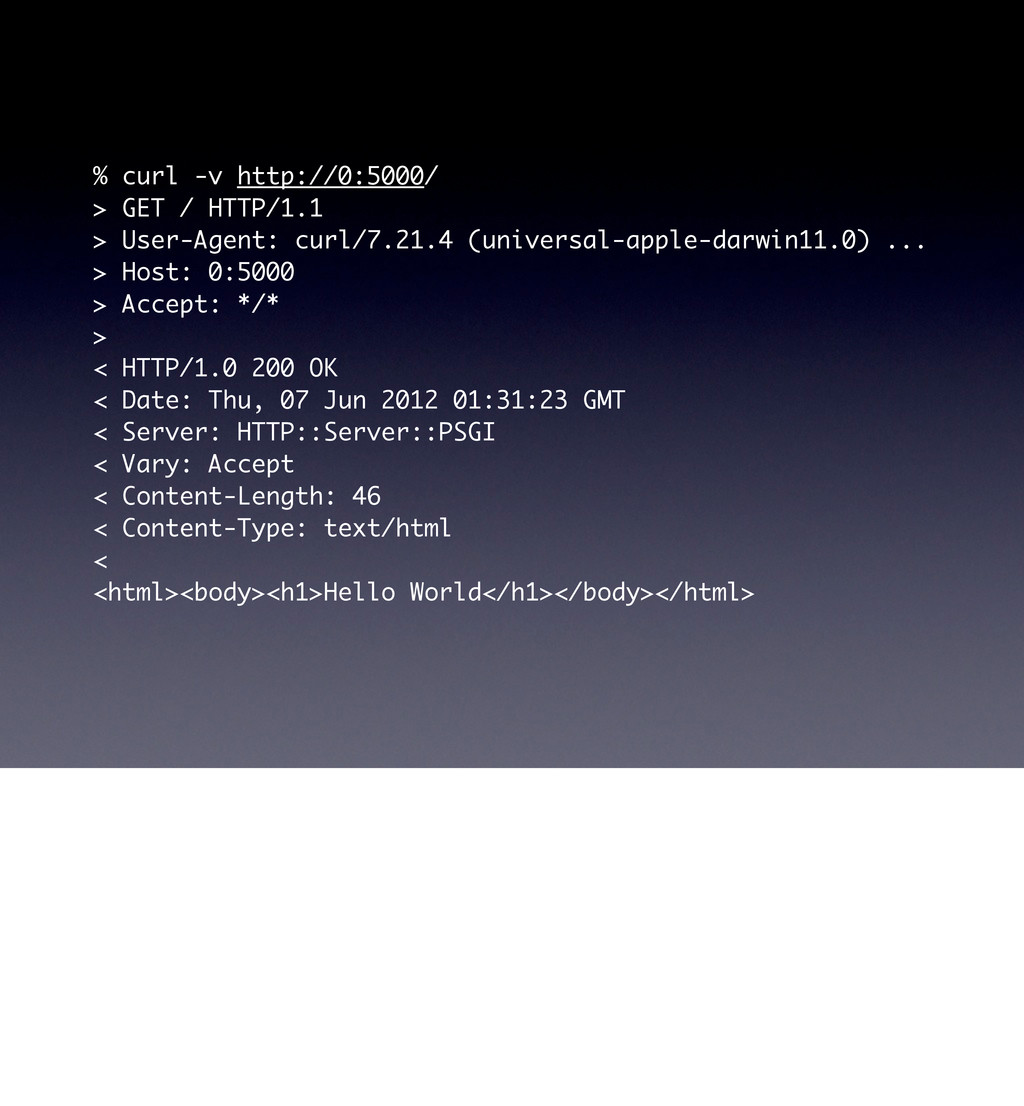
use parent 'Web::Machine::Resource'; sub content_types_provided { [ { 'text/html' => 'to_html' }, { 'application/json' => 'to_json' }, ] } sub to_json { encode_json( { message => 'Hello World' } ) } sub to_html { '<html><body><h1>Hello World</h1></body></html>' } } Web::Machine->new( resource => 'YAPC::NA::2012::Example002::Resource' )->to_app; And showing preference is just as simple as changing the order of items in content_types_provided # now HTML is the default curl -v http://0:5000/ # and you must ask specifically for JSON curl -v http://0:5000/ -H 'Accept: application/json'
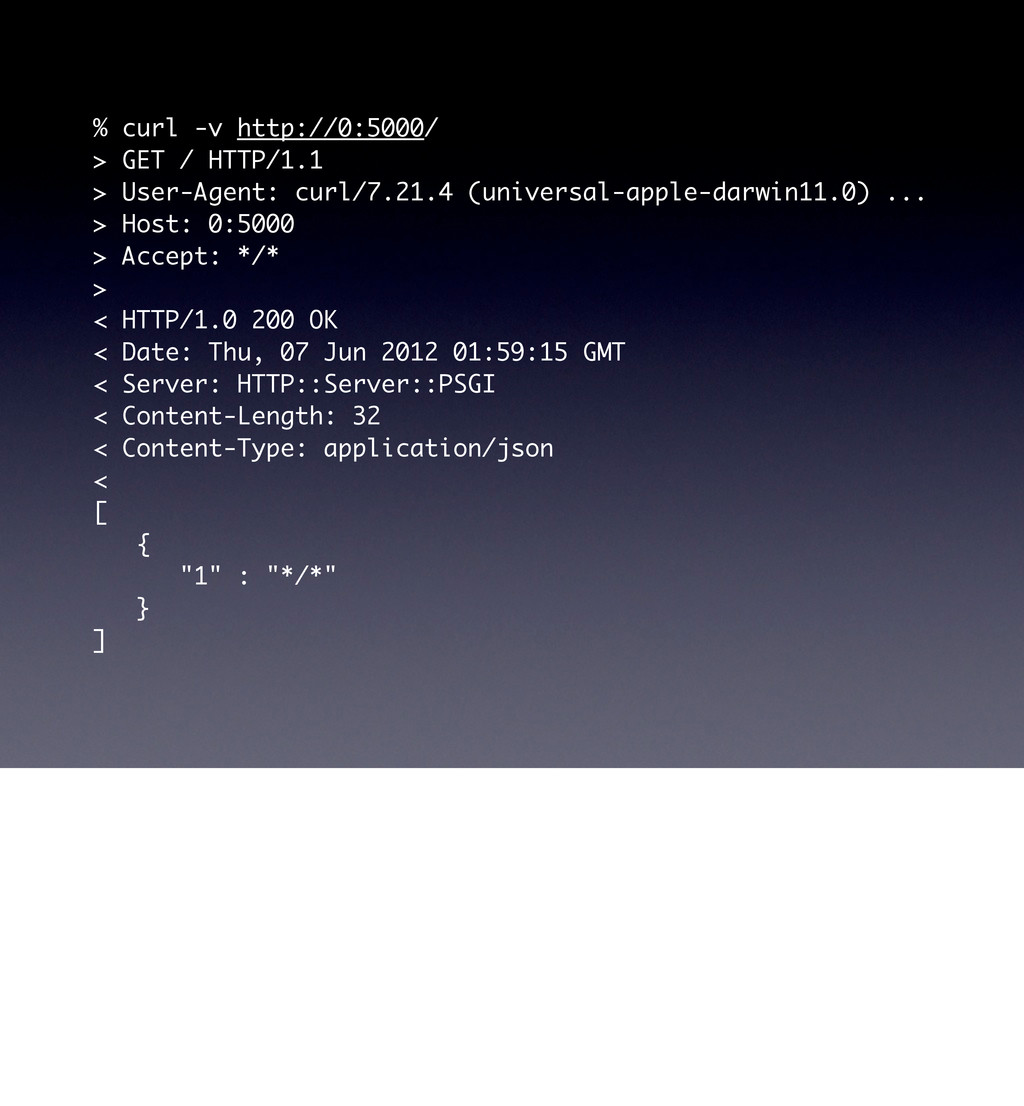
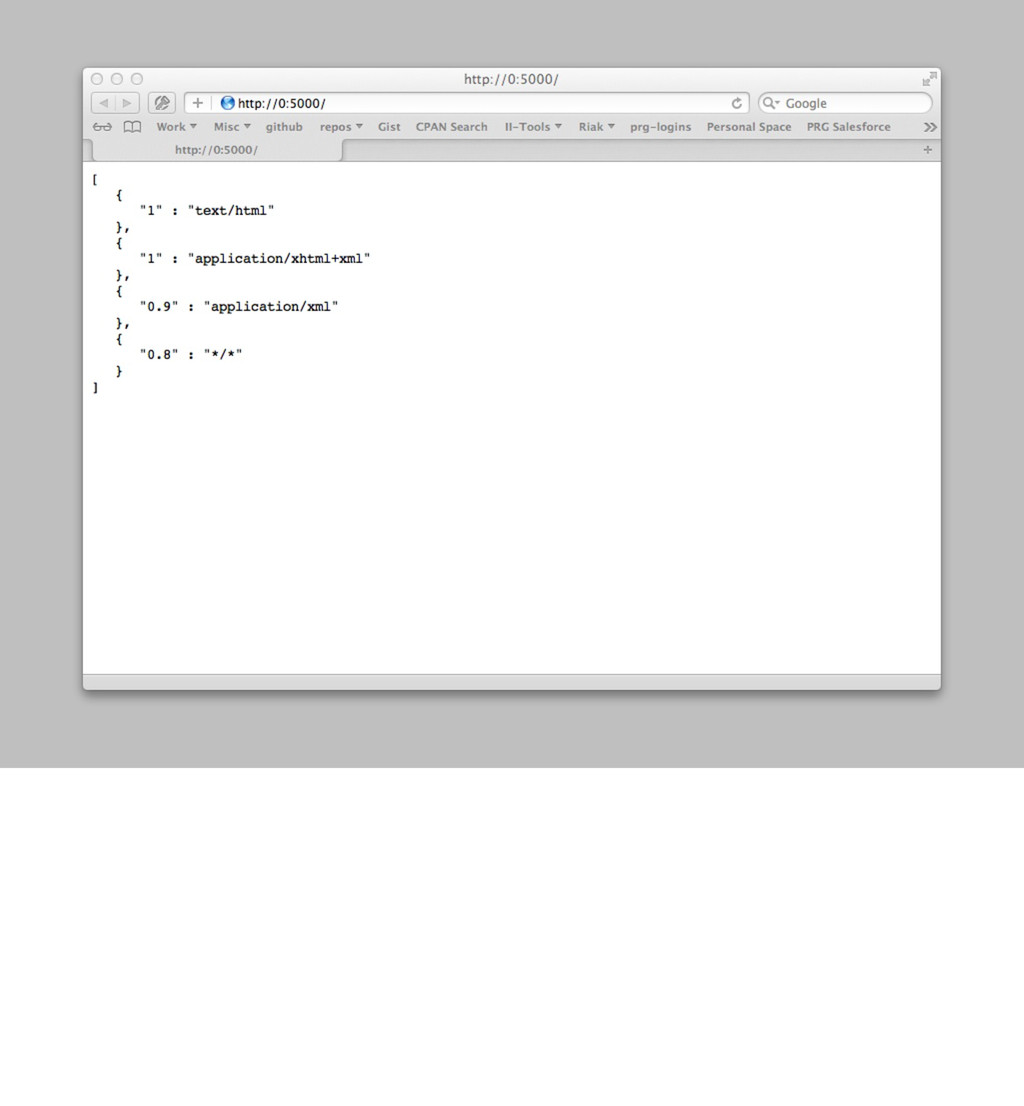
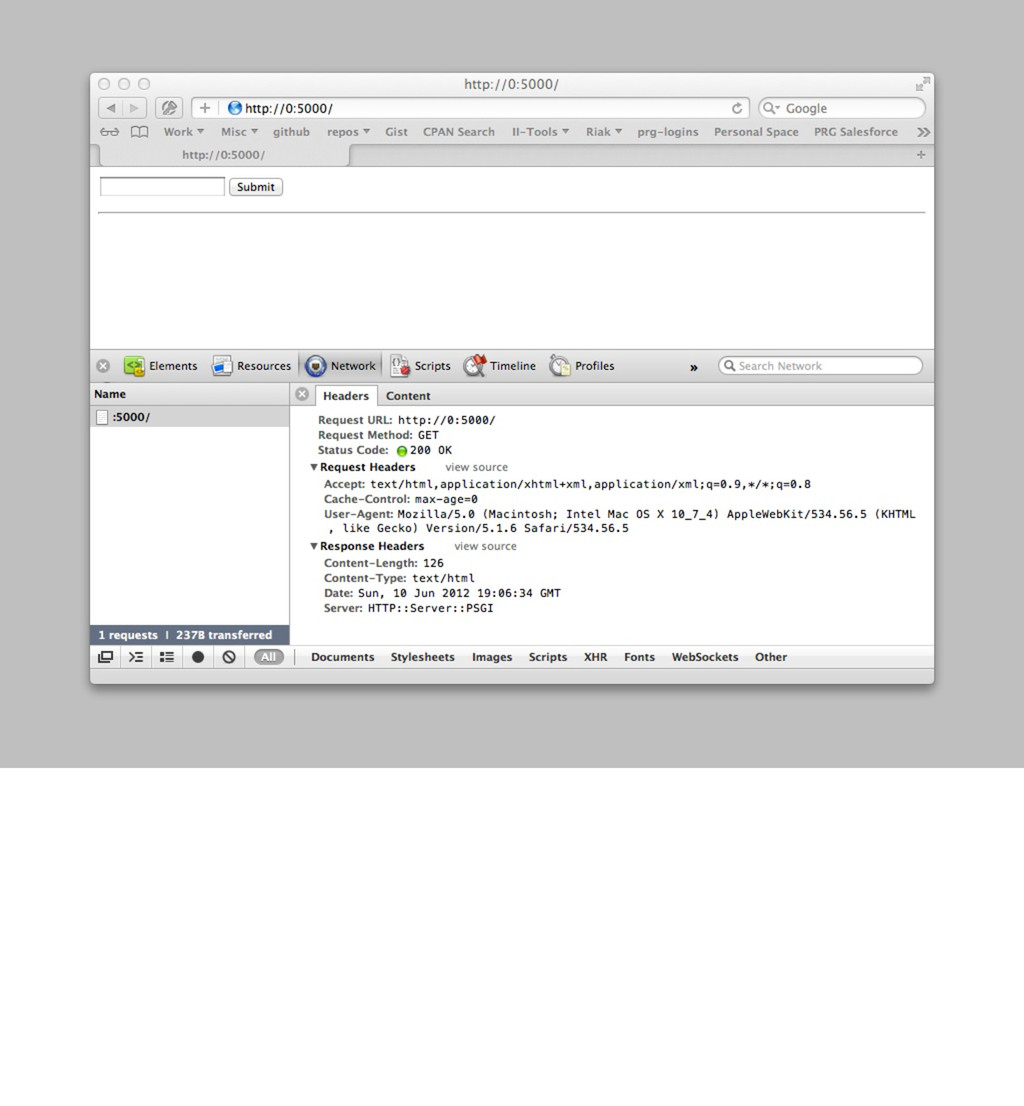
'Web::Machine::Resource'; sub content_types_provided { [{ 'application/json' => 'to_json' }] } sub to_json { my $self = shift; JSON::XS->new->pretty->encode([ map { +{ $_->[0] => $_->[1]->type } } $self->request->header('Accept')->iterable ]) } } Web::Machine->new( resource => 'YAPC::NA::2012::Example010::Resource' )->to_app; Curl by default, it accepts anything, as you can see when we run this. curl -v http://0:5000/ However, web browsers are more sophisticated creatures and have more complicated needs. open http://0:5000/ You can see that since we only provide JSON, that we end up matching the */* at the end.
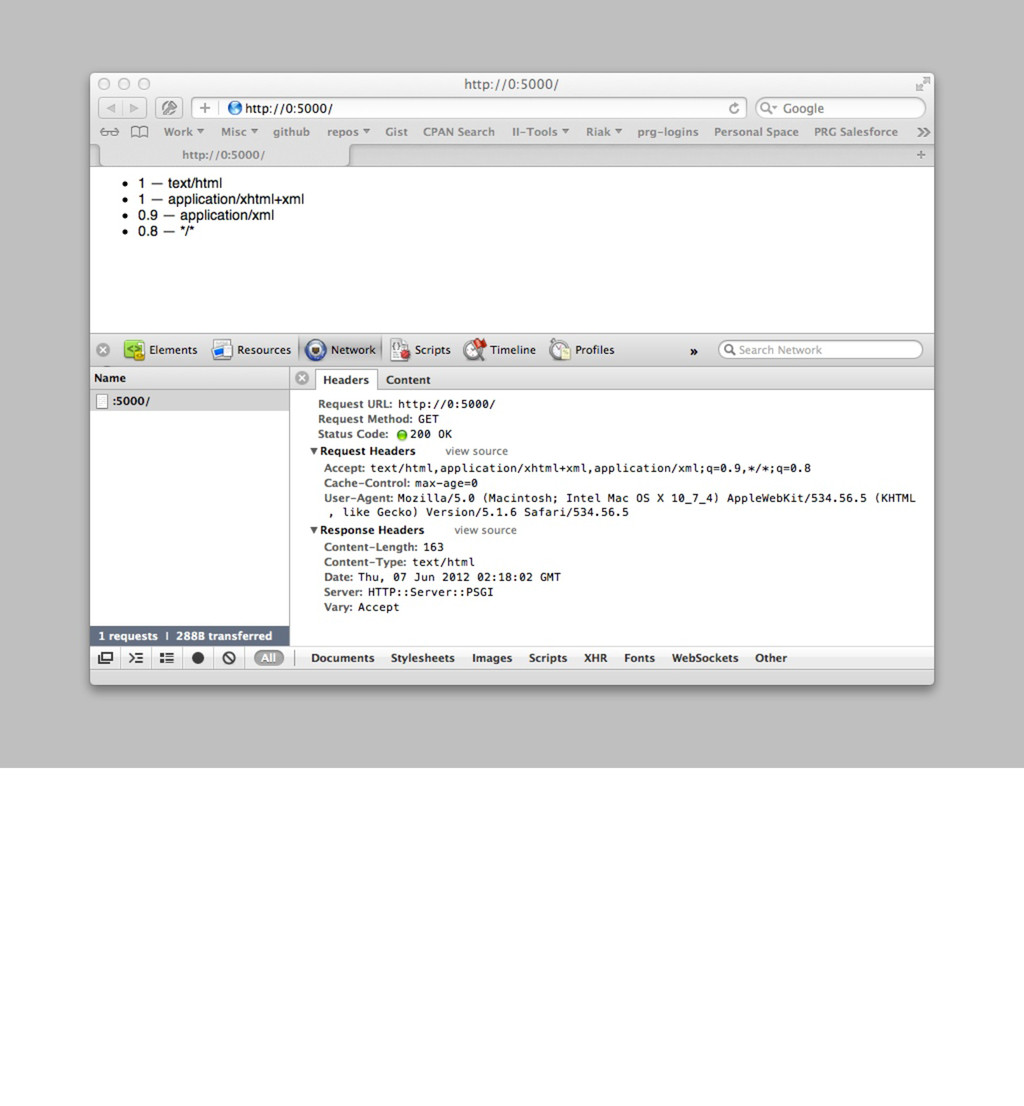
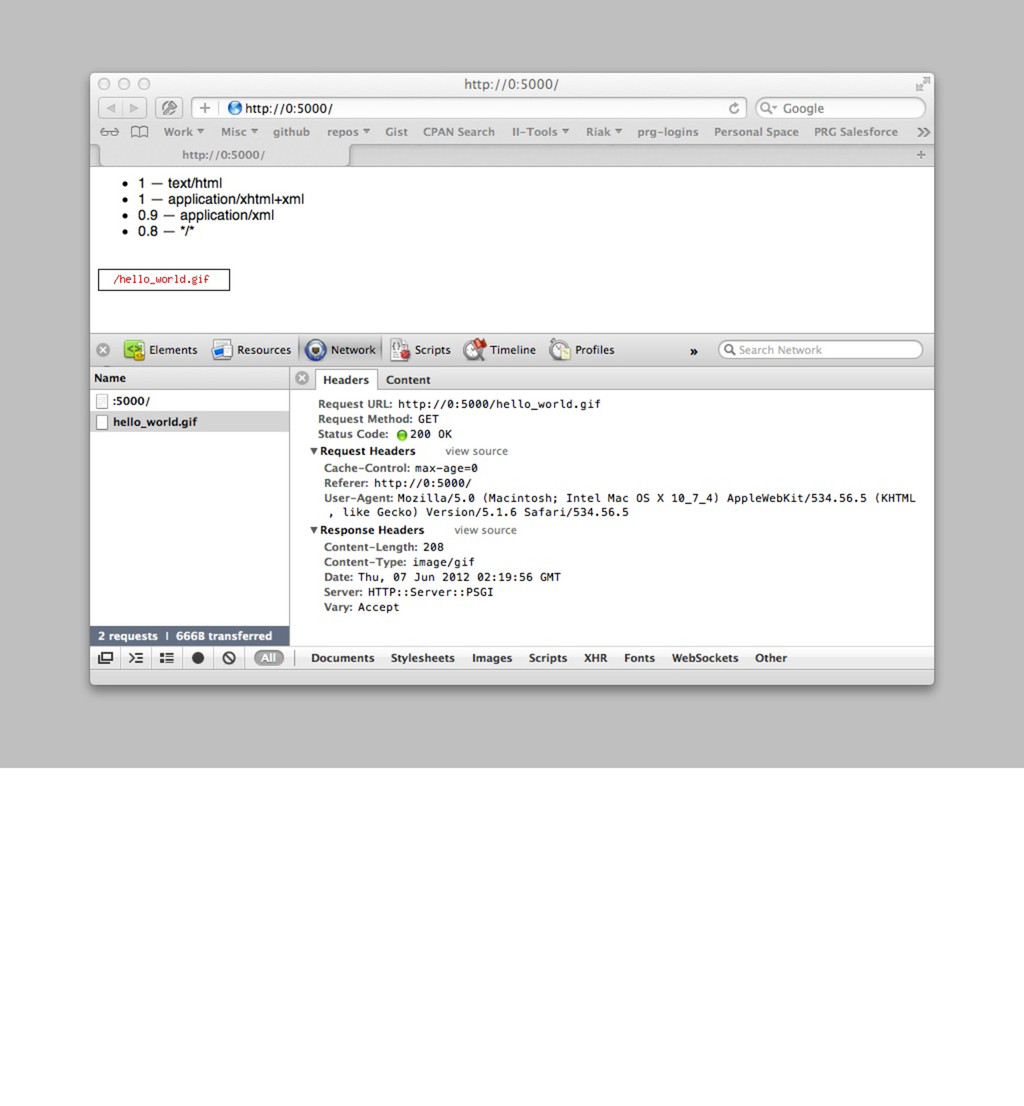
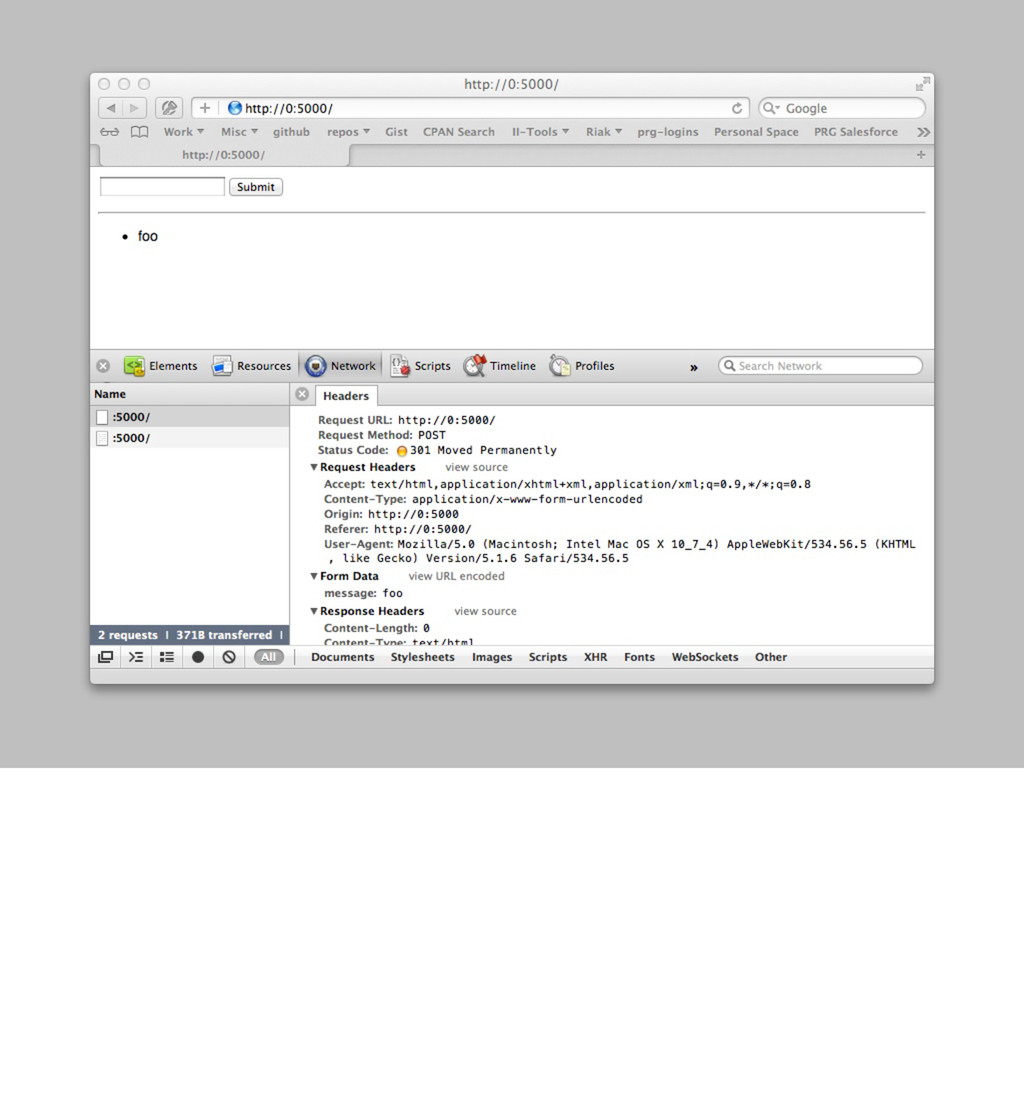
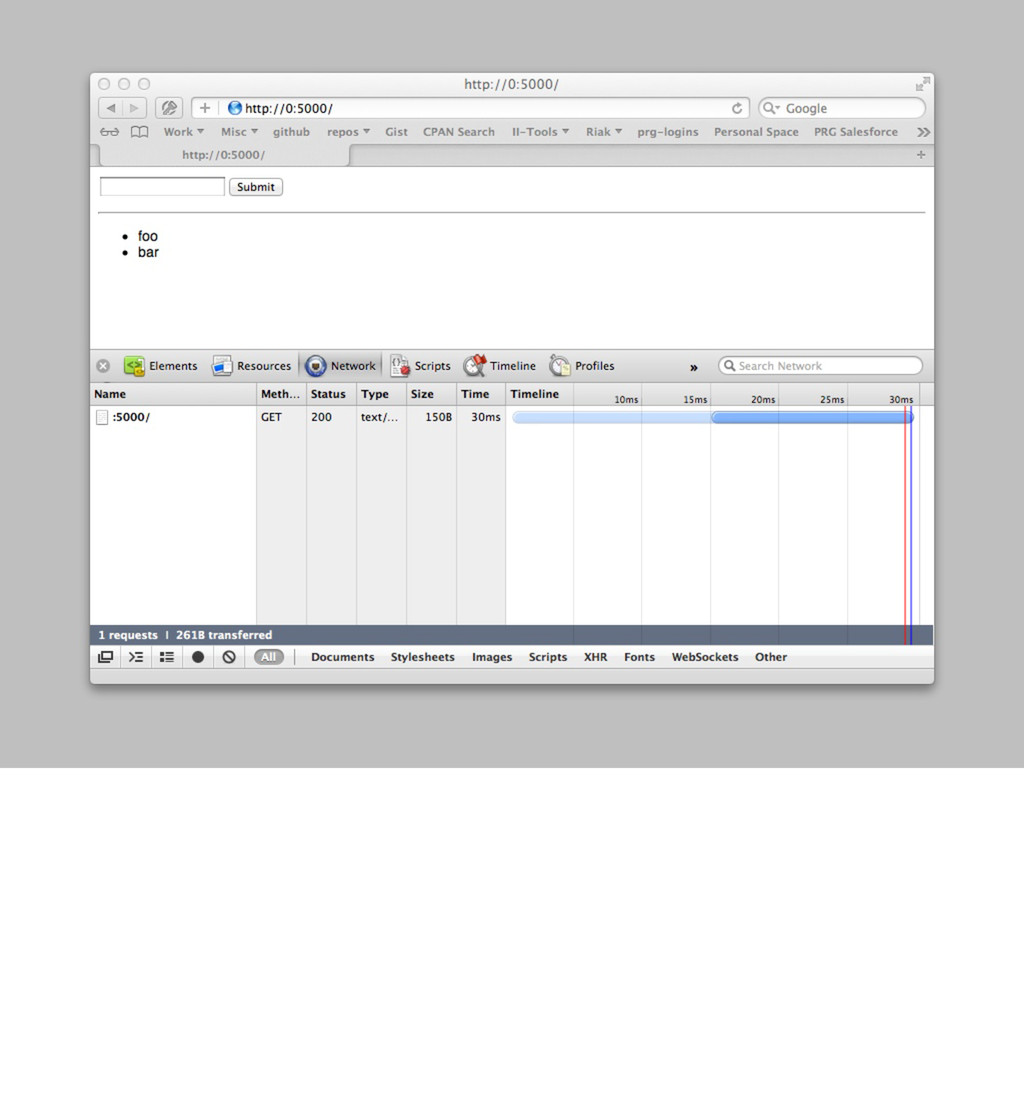
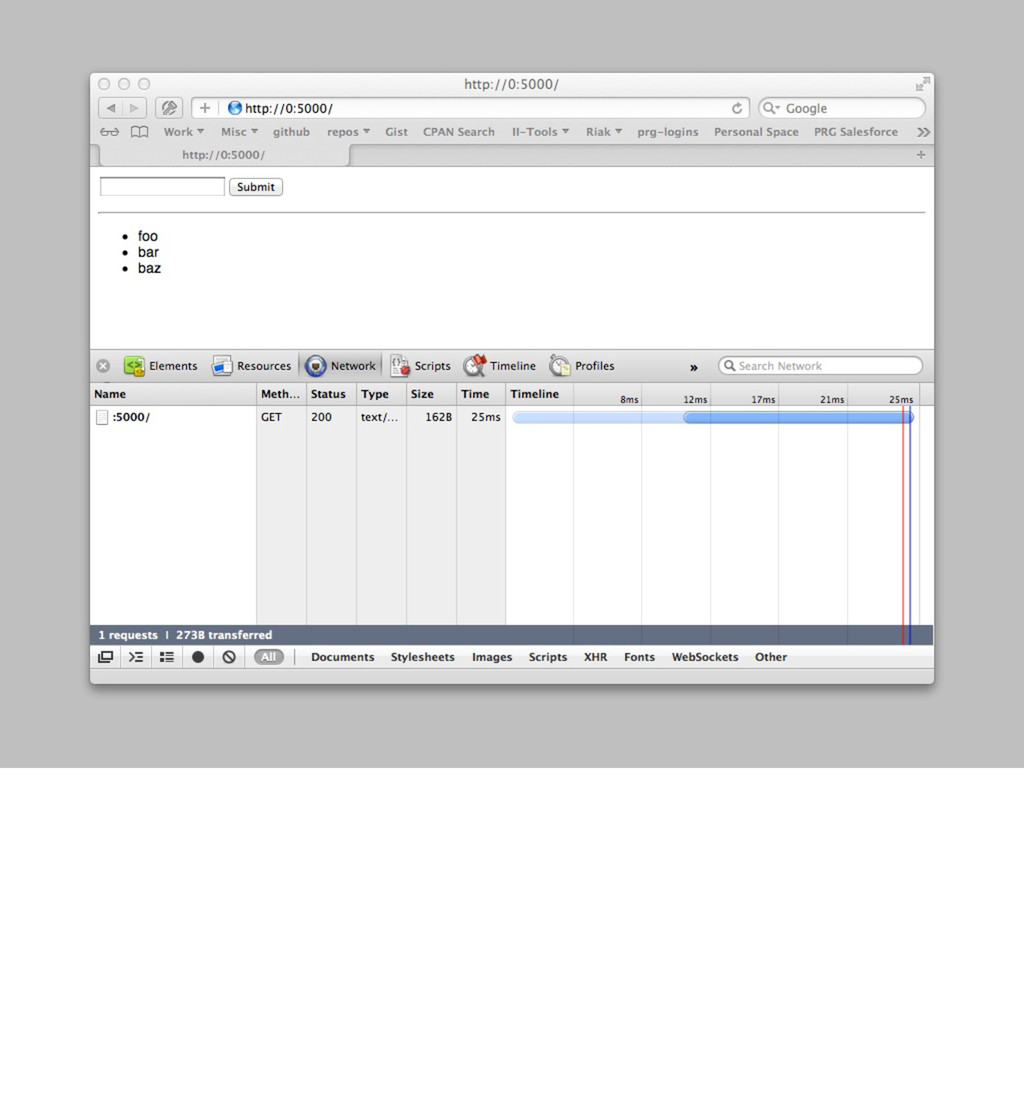
'Web::Machine::Resource'; sub content_types_provided { [ { 'application/json' => 'to_json' }, { 'text/html' => 'to_html' } ] } sub to_json { ... } sub to_html { my $self = shift; '<html><body><ul>' . (join "" => map { '<li>' . $_->[0] . ' — ' . $_->[1]->type . '</li>' } $self->request->header('Accept')->iterable) . '</ul></body></html>' } } Web::Machine->new( resource => 'YAPC::NA::2012::Example011::Resource' )->to_app; So what happens then if we provide HTML as well? open http://0:5000/ Now we prefer HTML over JSON, even though JSON is the default here. If you call curl, you get the expected JSON. curl -v http://0:5000/
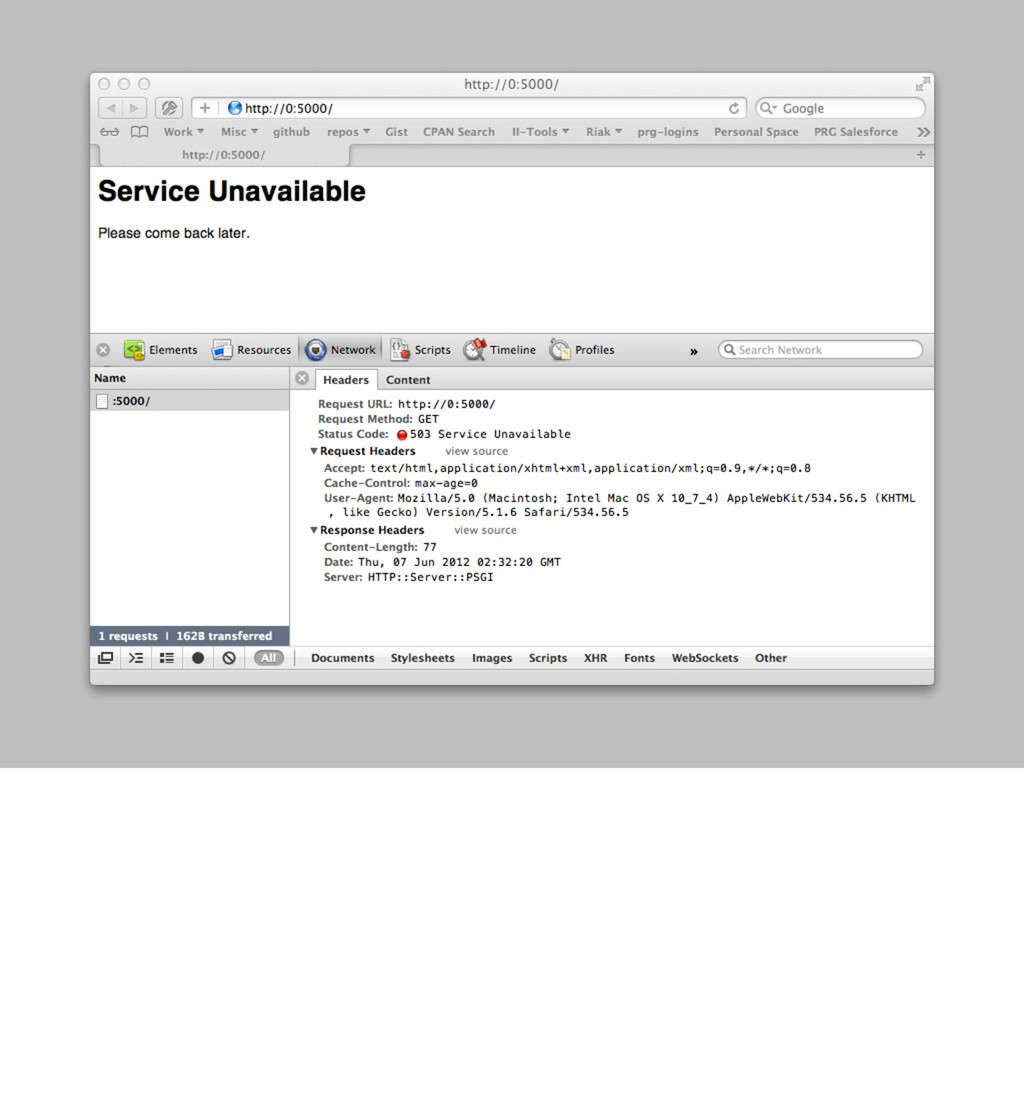
{ [ { 'text/html' => 'to_html' }, ] } sub to_html { '<html><body><h1>Hello World</h1></body></html>' } sub service_available { my $self = shift; return 1 unless -e './site_down'; $self->response->body([ '<html><body><h1>Service Unavailable</h1></body></html>' ]); 0; } } Web::Machine->new( resource => 'YAPC::NA::2012::Example110::Resource' )->to_app; This demostrates how you can easily handle situations like the site being down in a reasonably elegant way. touch site_down rm site_down
is that the web is a very messy place, it is important that your web-service can live in this world. The best way to deal with this, is to use HTTP to it’s fullest, it is the common language. This increases discoverability too, and is just an all around good idea.
not frameworks ‣ Frameworks are basically a big ball of opinion with a few bits left undone for you to complete. REST does not lend itself to this, instead I recommend using a Toolkit, meaning, a set of libraries with which you accomplish REST.
![REST from the trenches Stevan Little YAPC::NA 2012 [email protected]](https://files.speakerdeck.com/presentations/5037ed141d8148000201a6bd/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![use 5.16.0; package YAPC::NA::2012::Example000::Resource { use JSON::XS qw[ encode_json ];](https://files.speakerdeck.com/presentations/5037ed141d8148000201a6bd/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![use 5.16.0; package YAPC::NA::2012::Example001::Resource { use JSON::XS qw[ encode_json ];](https://files.speakerdeck.com/presentations/5037ed141d8148000201a6bd/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
![use 5.16.0; package YAPC::NA::2012::Example002::Resource { use JSON::XS qw[ encode_json ];](https://files.speakerdeck.com/presentations/5037ed141d8148000201a6bd/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![use 5.16.0; package YAPC::NA::2012::Example020::Resource { use Web::Machine::Util qw[ create_header ];](https://files.speakerdeck.com/presentations/5037ed141d8148000201a6bd/slide_55.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![use 5.16.0; package YAPC::NA::2012::Example032::Resource { use Web::Machine::Util qw[ create_header ];](https://files.speakerdeck.com/presentations/5037ed141d8148000201a6bd/slide_67.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![use 5.16.0; package YAPC::NA::2012::Example033::Resource { use JSON::XS qw[ encode_json ];](https://files.speakerdeck.com/presentations/5037ed141d8148000201a6bd/slide_71.jpg){kind=link}
{kind=link}
{kind=link}
![use 5.16.0; package YAPC::NA::2012::Example100::Resource { use Web::Machine::Util qw[ create_date ];](https://files.speakerdeck.com/presentations/5037ed141d8148000201a6bd/slide_74.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
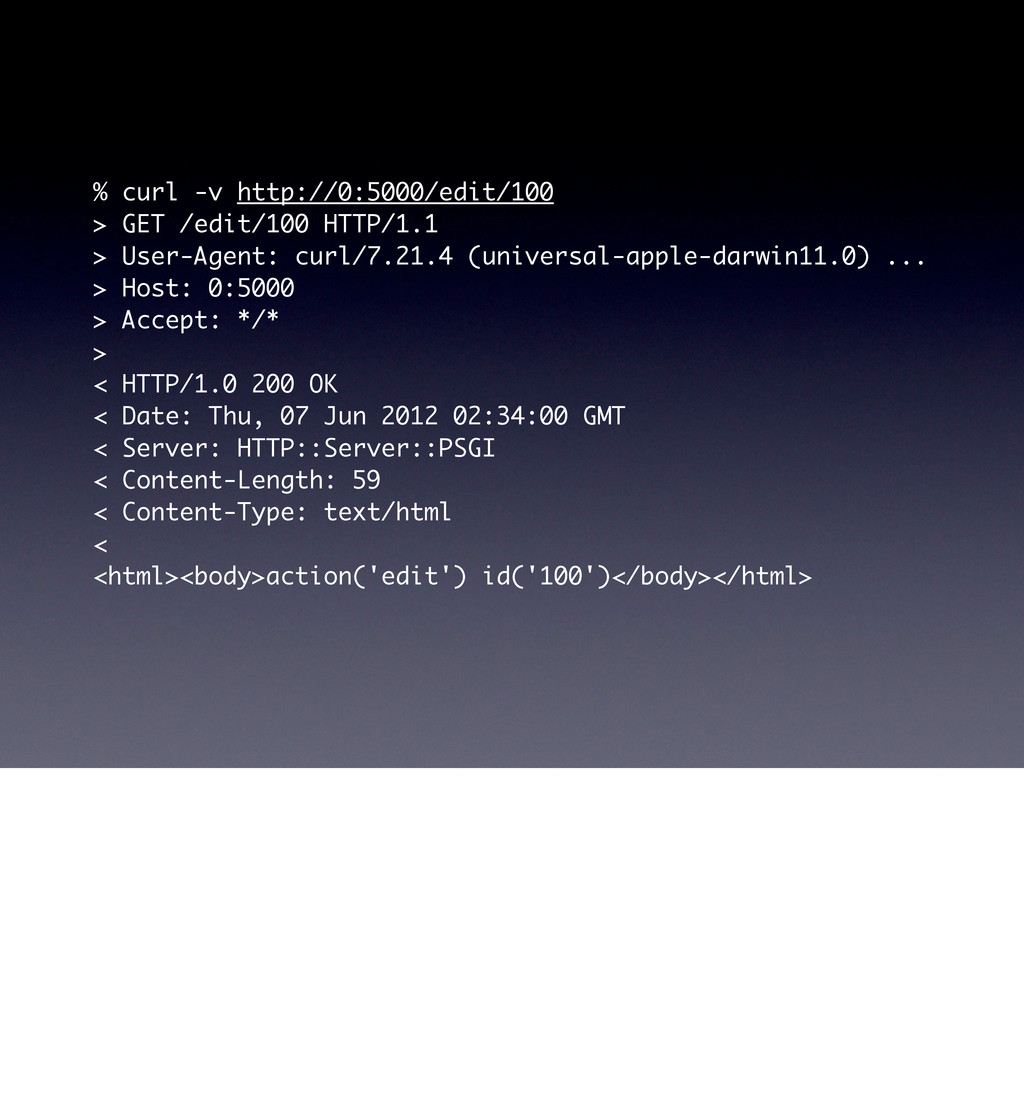
![use 5.16.0; package YAPC::NA::2012::Example120::Resource { use Web::Machine::Util qw[ bind_path ];](https://files.speakerdeck.com/presentations/5037ed141d8148000201a6bd/slide_81.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}