a system by examining its outputs. A system is considered “observable” if the current state can be estimated by only using information from outputs, namely sensor data. Splunk https://www.splunk.com/en_us/data-insider/what-is-observability.html 能力 透過檢視系統外部所揭露的資訊,能有效的衡量系統 內部運作的狀態。
to actively debug their system. Observability is based on exploring properties and patterns not defined in advance. DORA (DevOps Research and Assessment) research 工具或技術的解決方案 更主動的 debug 探索沒有事先定義好的特性與模式 https://cloud.google.com/architecture/devops/devops-measurement-monitoring-and-observability
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
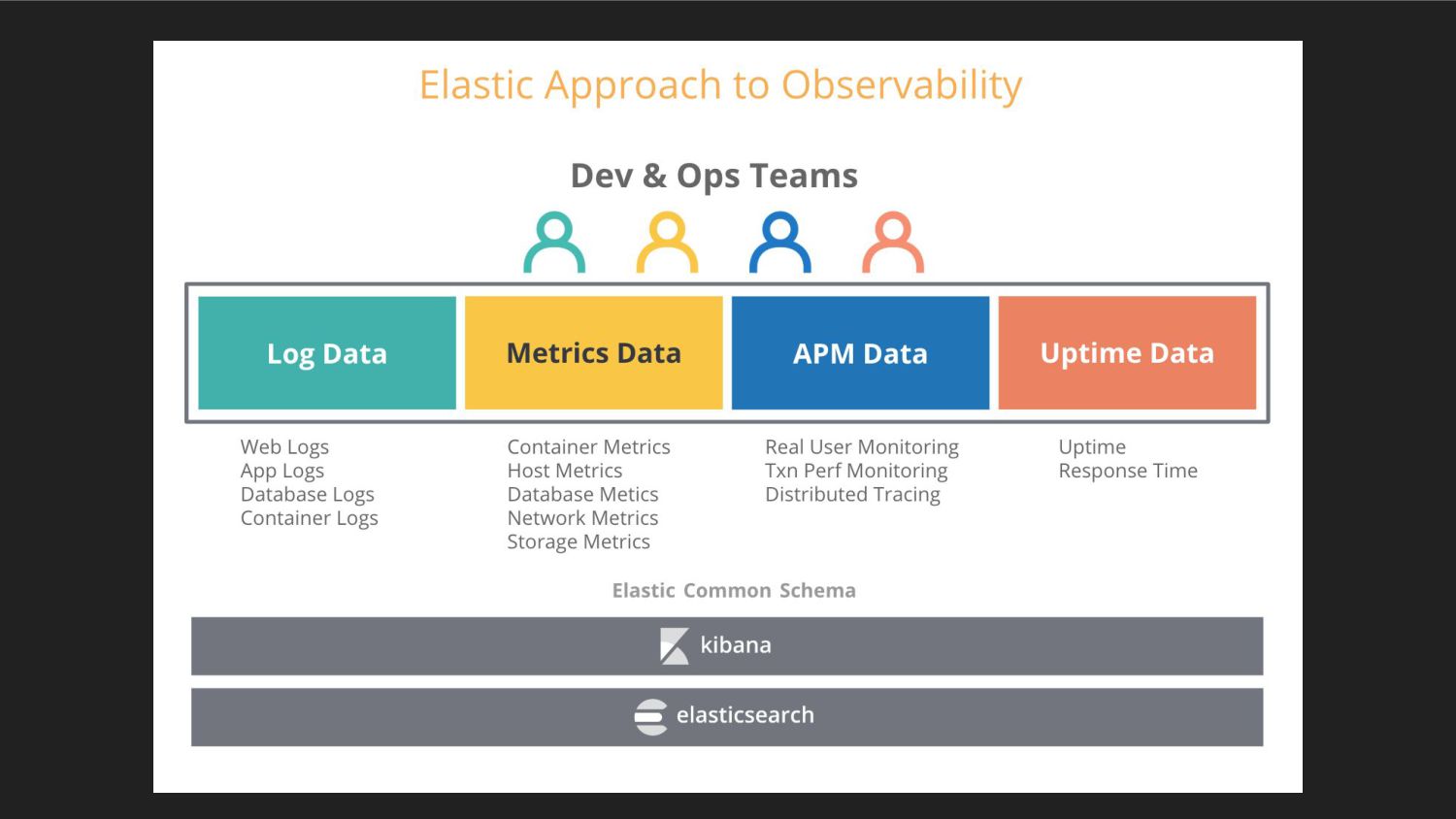{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Elastic Common Schema (ECS) • 是一個 Open Source 的規範[1] ◦](https://files.speakerdeck.com/presentations/b5e2ed3d2b244c76a94face4fc5a4ded/slide_20.jpg){kind=link}
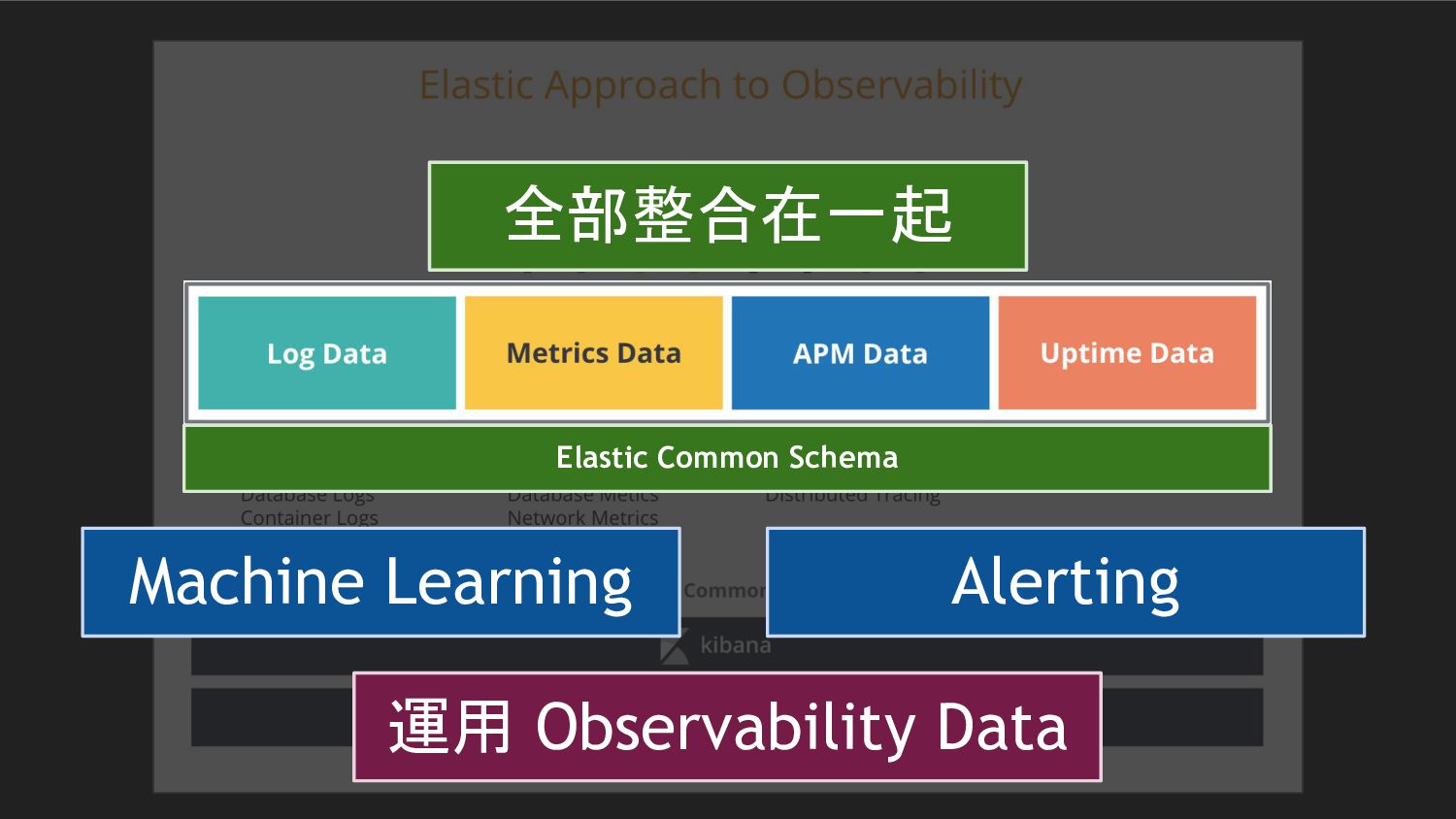{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
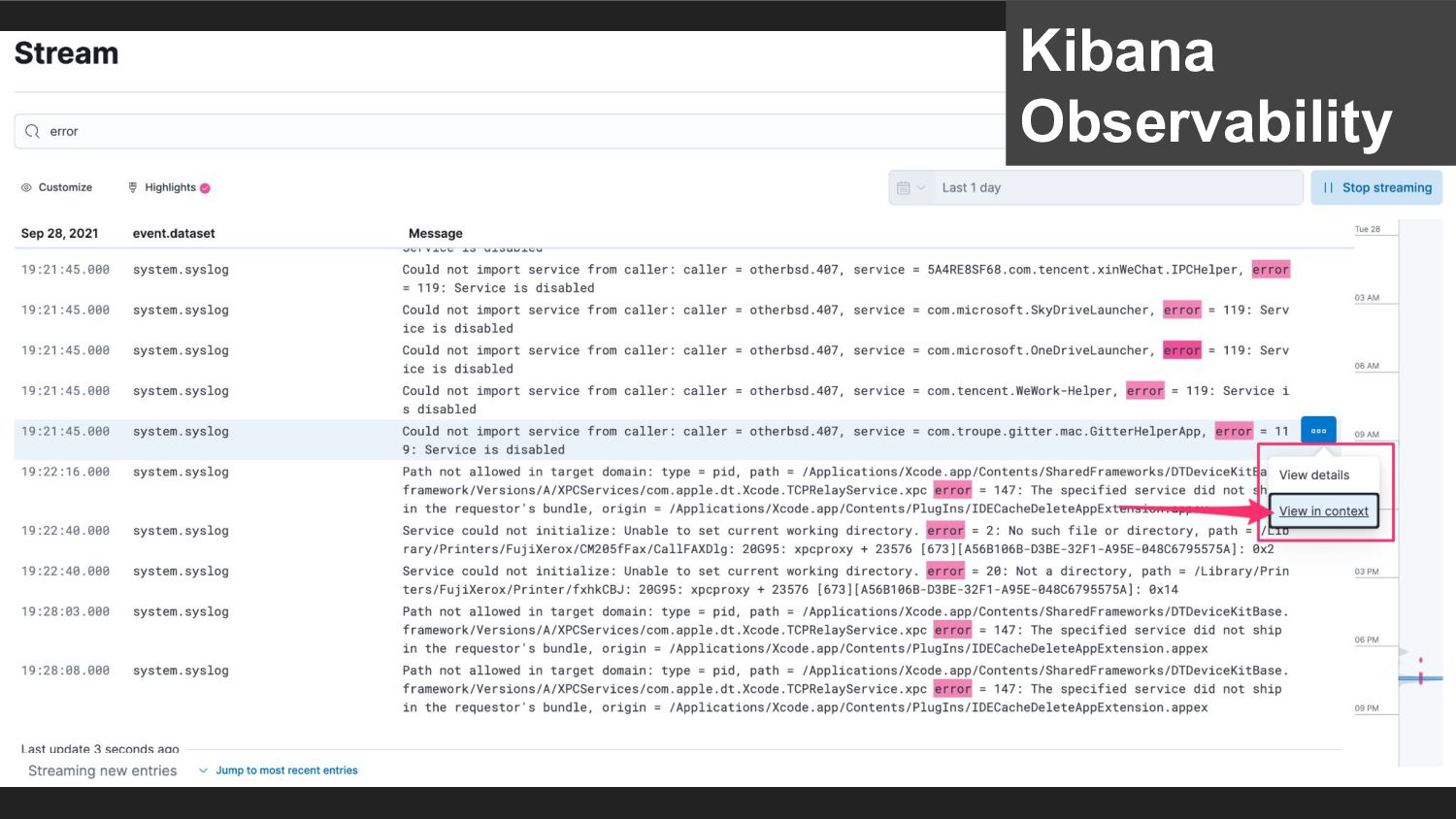{kind=link}
{kind=link}
{kind=link}
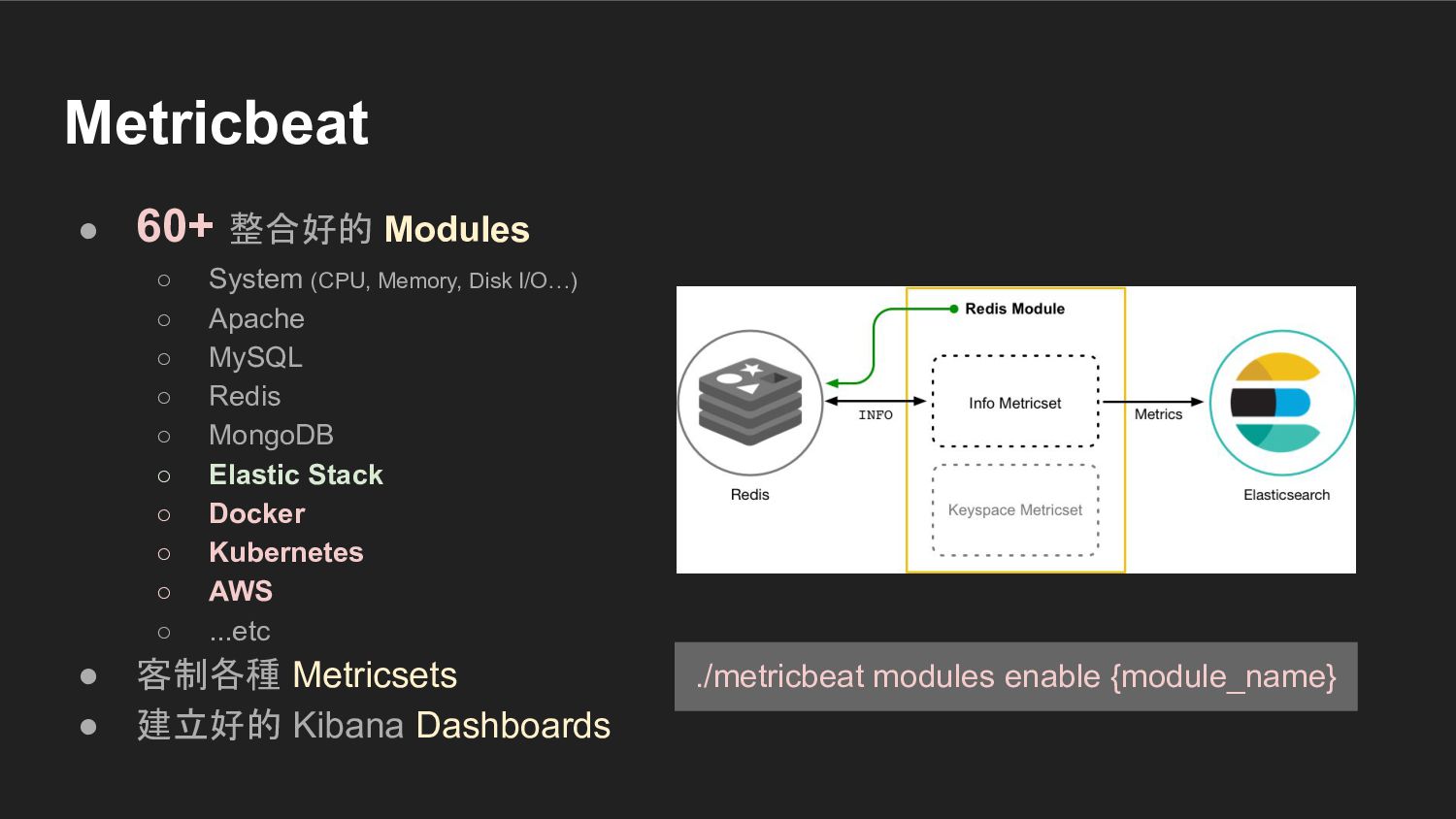{kind=link}
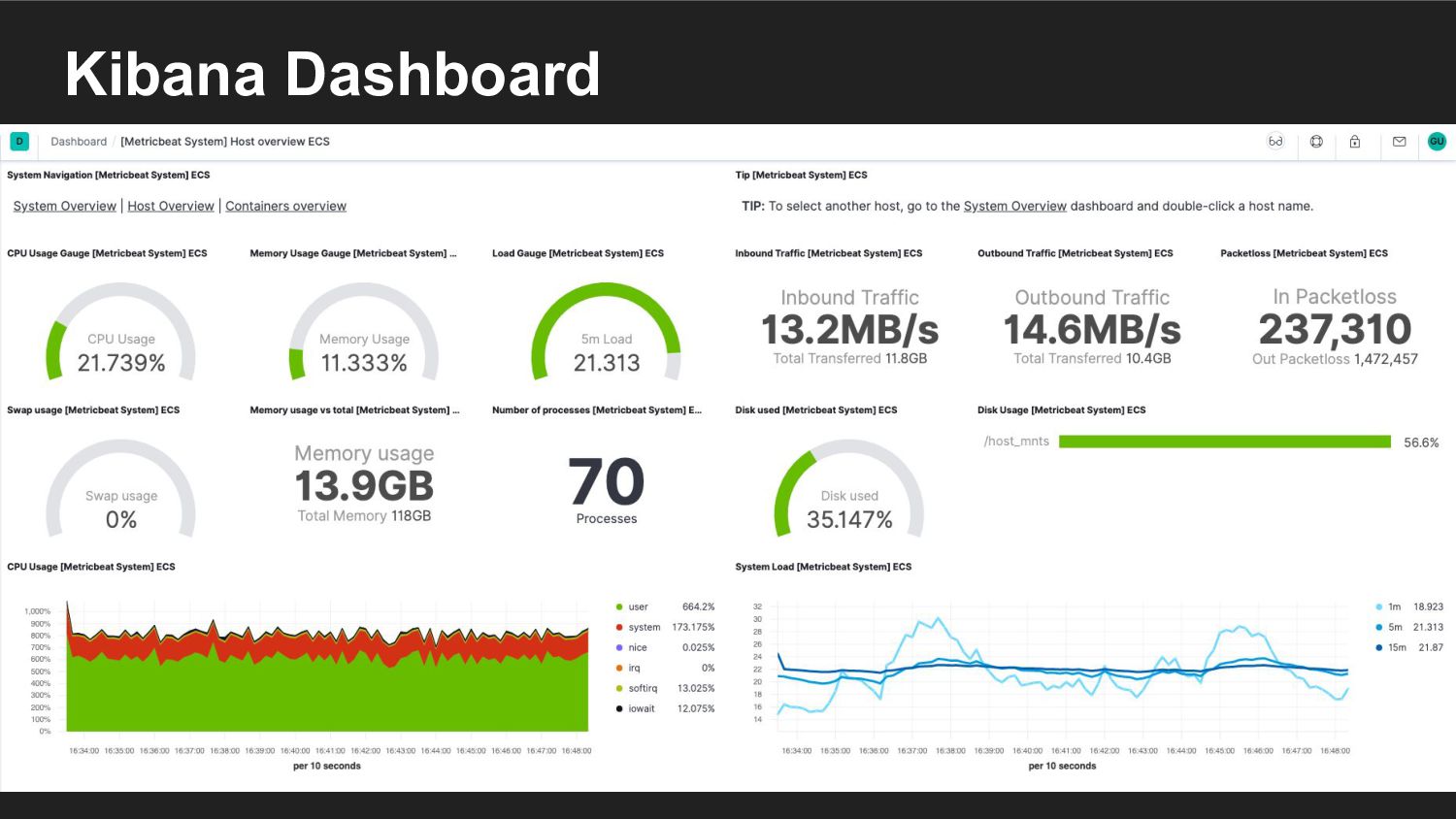{kind=link}
{kind=link}
{kind=link}
{kind=link}
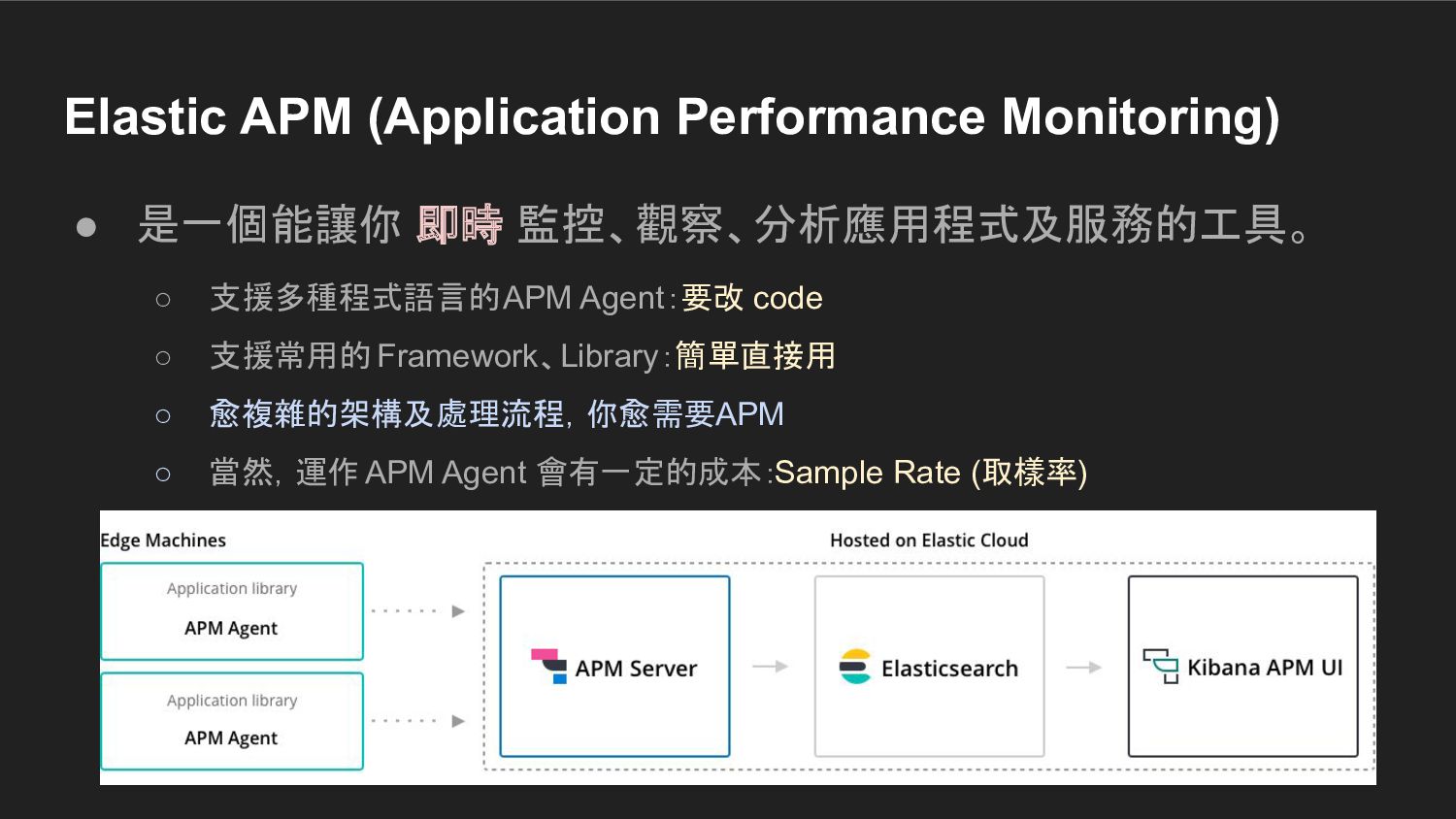{kind=link}
{kind=link}
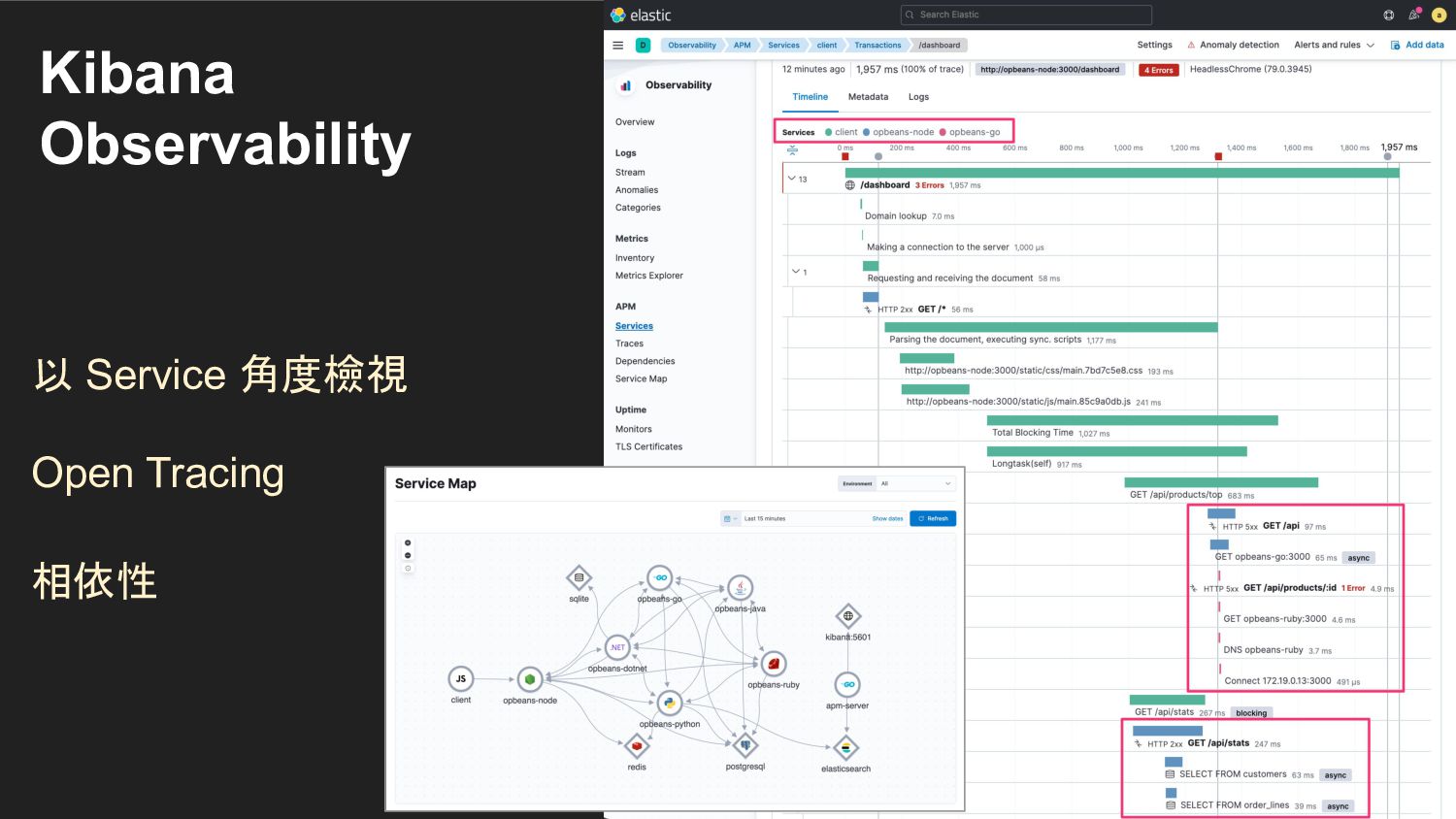{kind=link}
{kind=link}
{kind=link}
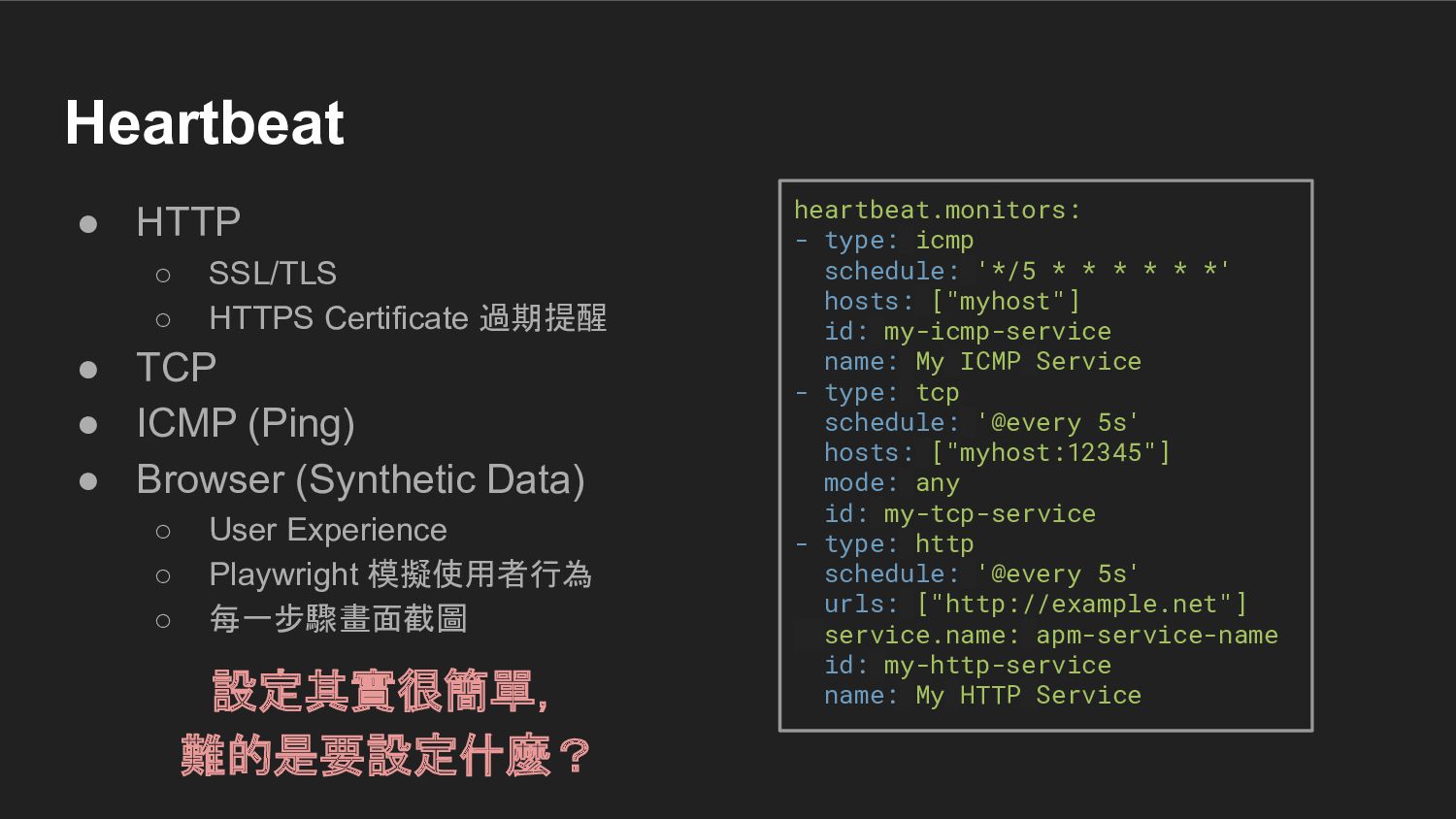{kind=link}
{kind=link}
{kind=link}
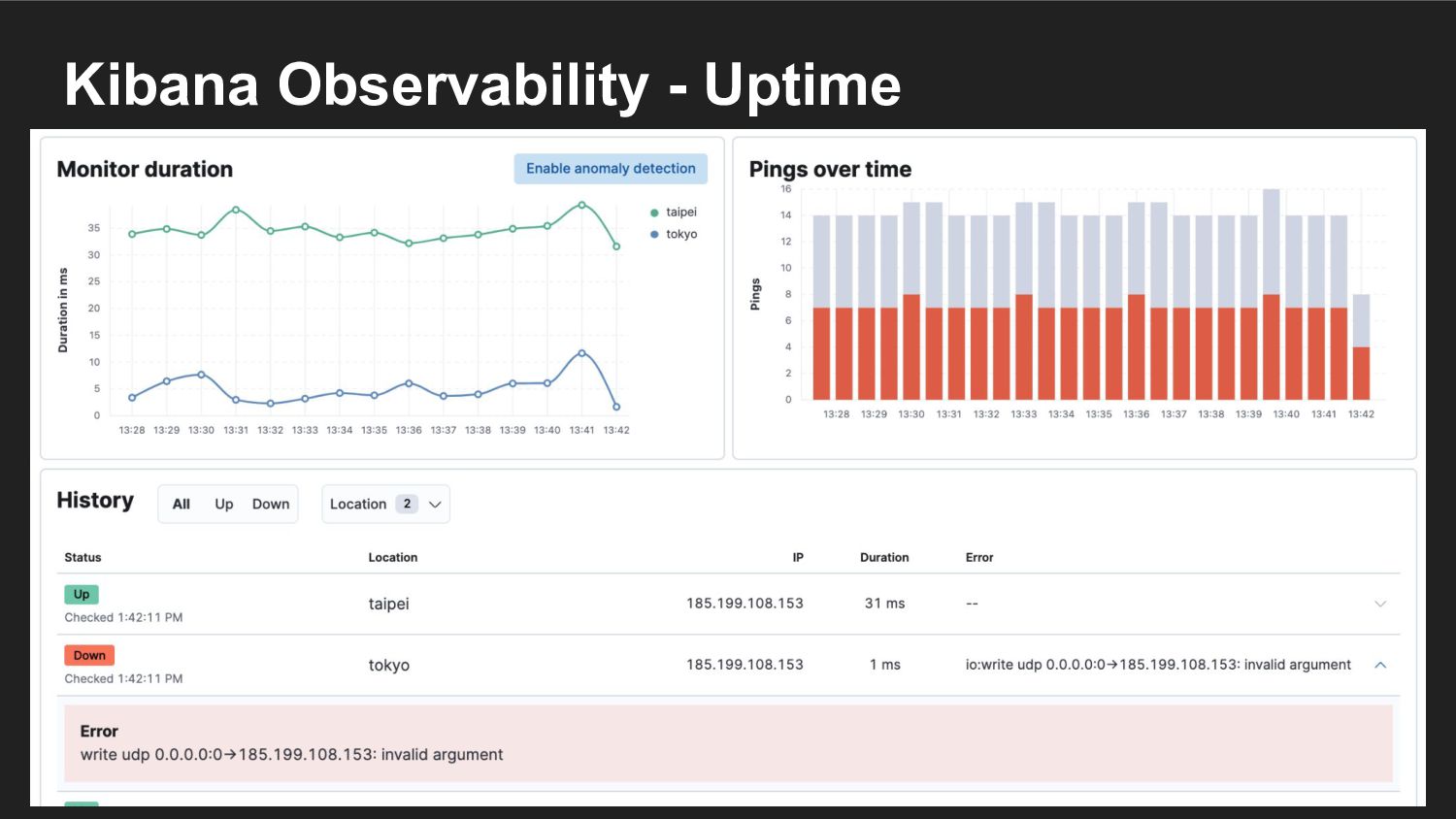{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
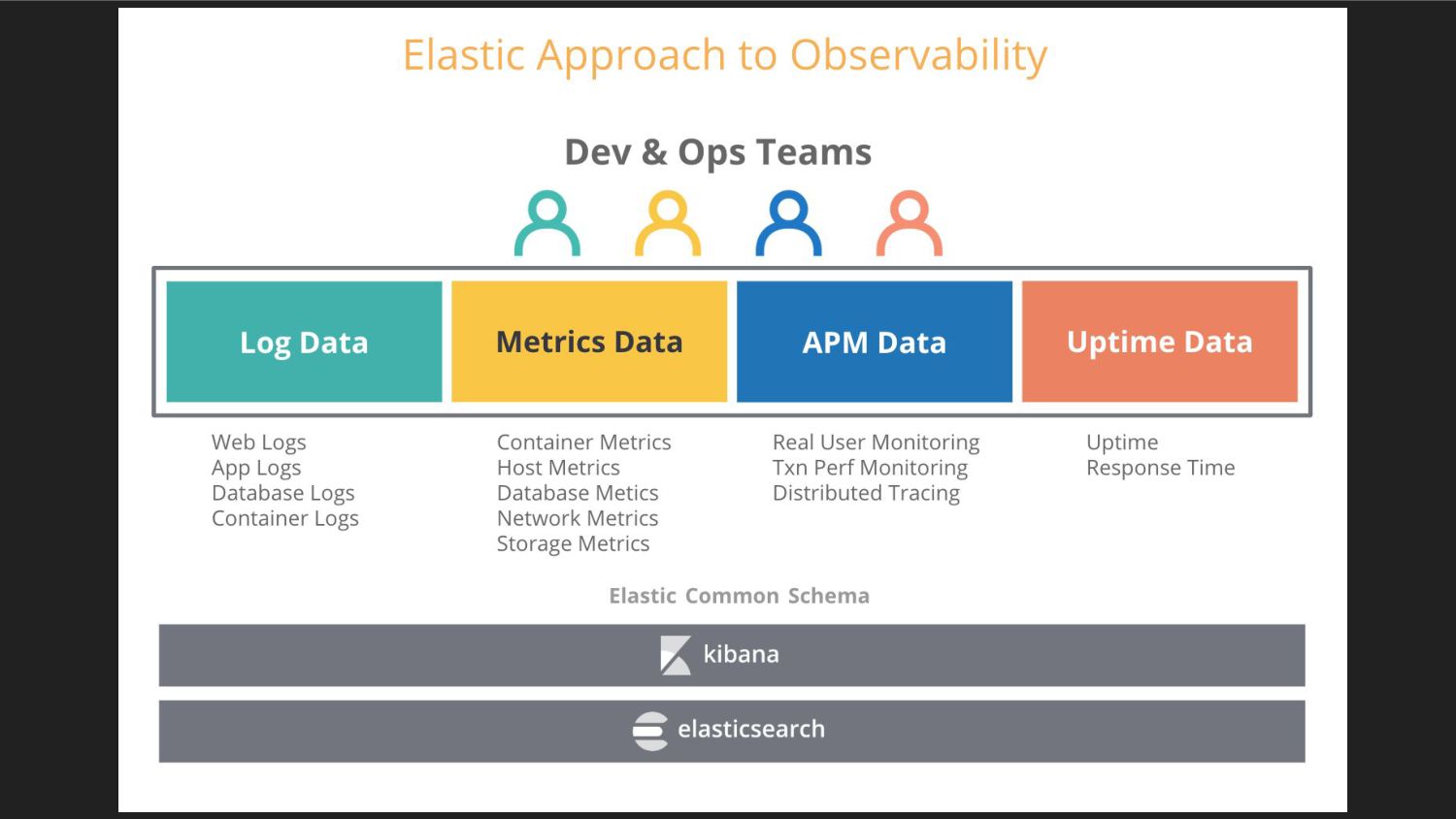{kind=link}
{kind=link}
{kind=link}
{kind=link}