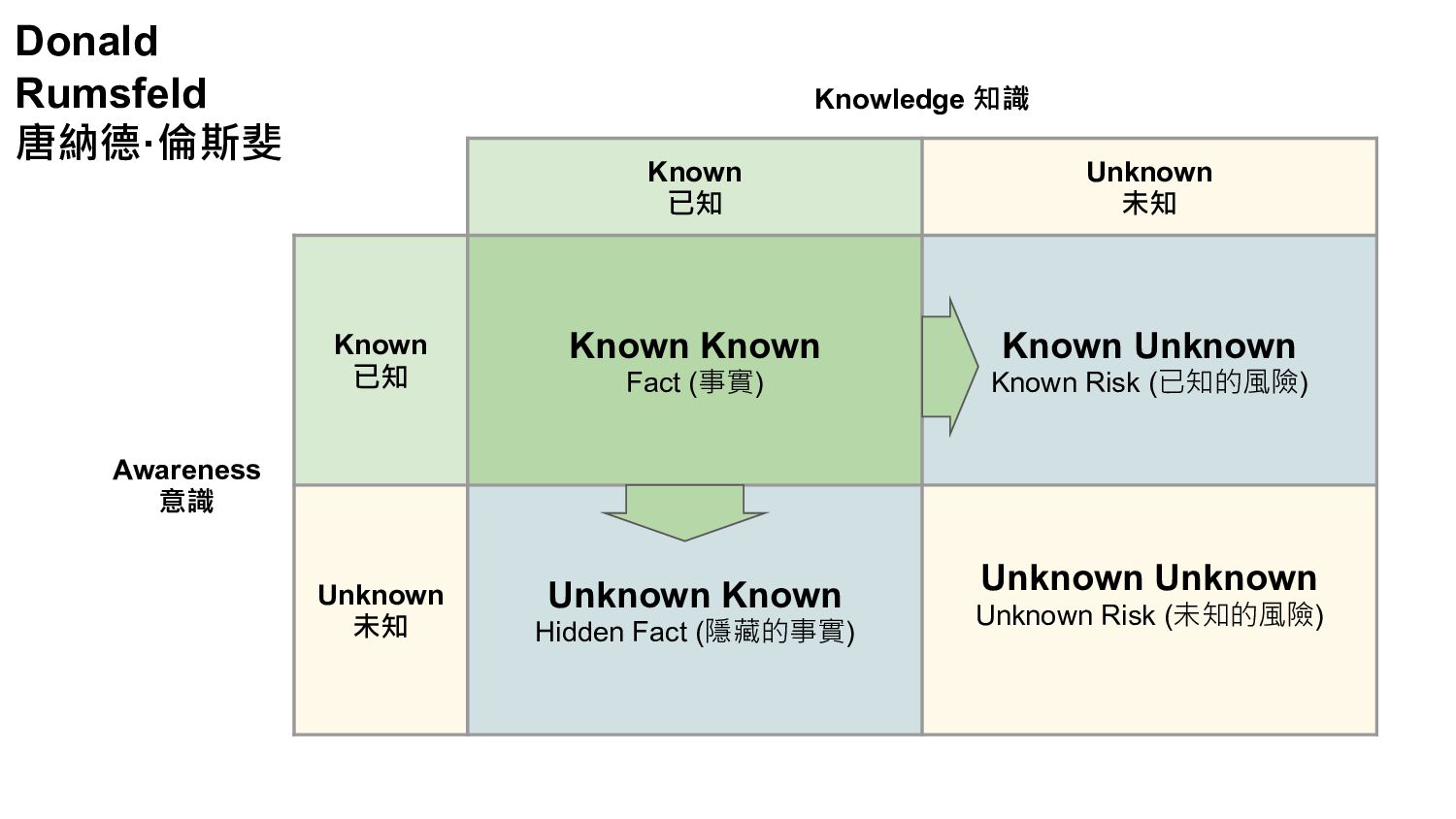
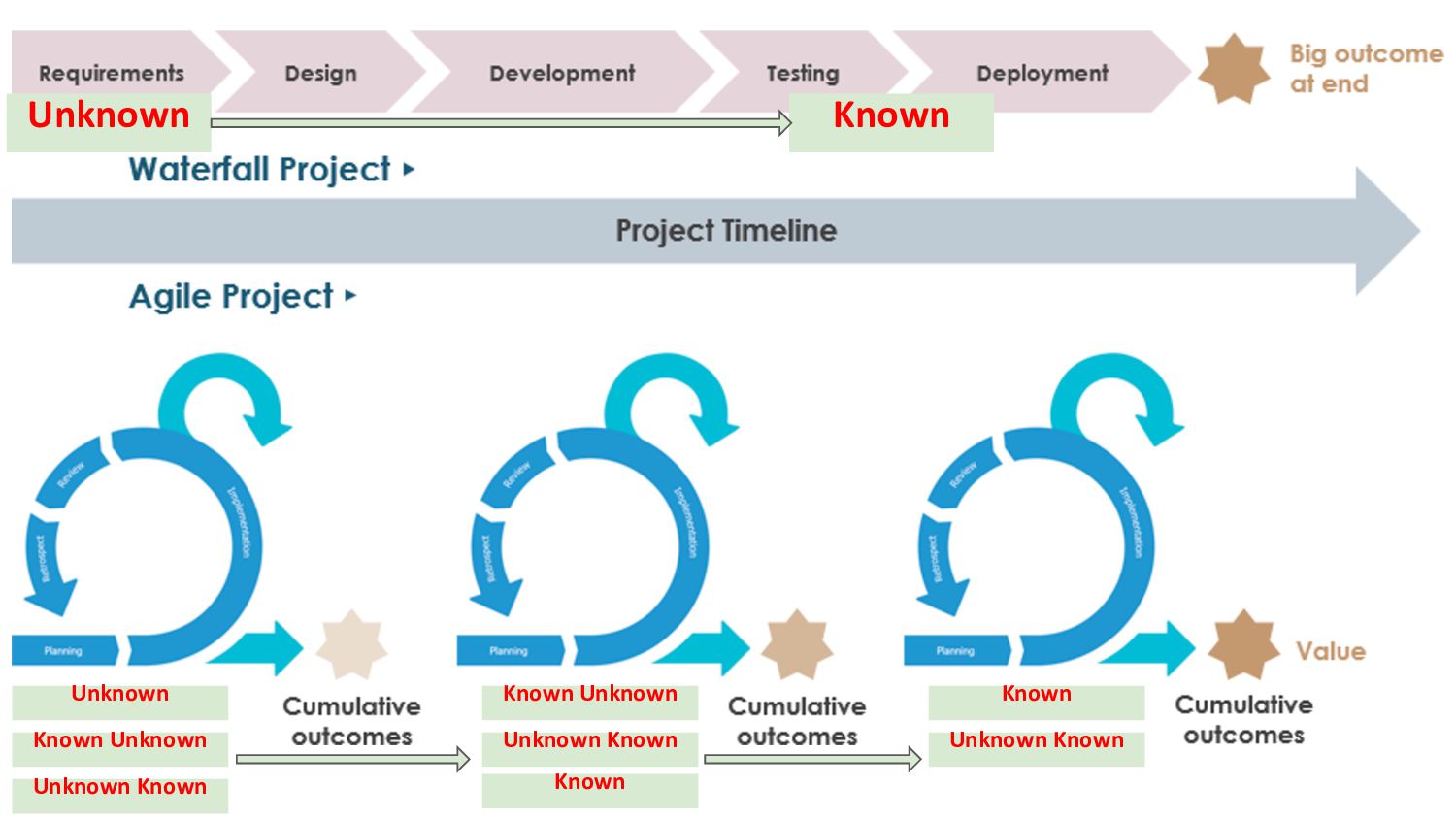
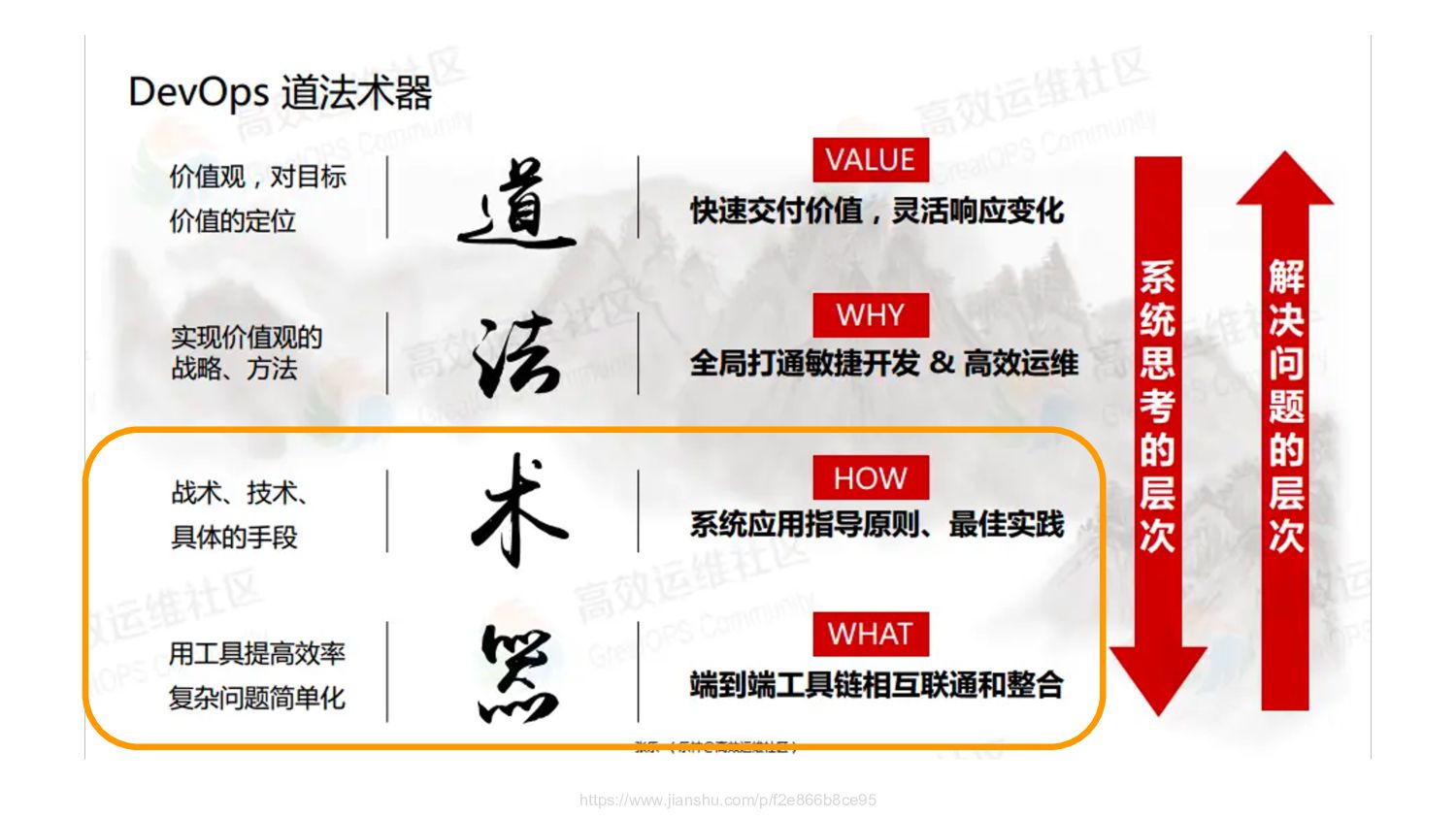
在面對不斷變化的商業需求,敏捷快速交付價值以及选代的精神已廣泛落實在 DevOps 的實踐之中,但是在使用 Elasticsearch 處理巨量日誌或資料時,一但需求改變或是有新的資料使用需求提出時,我們的應對及管理的策略為何? 如何在 Elasticsearch 來做到最佳的實踐?
工作坊將包含以下的內容:
敏捷的資料建模與管理的概念簡介
Elasticsearch Data Modeling 簡介
深入 Elasticsearch Data Modeling 的實作
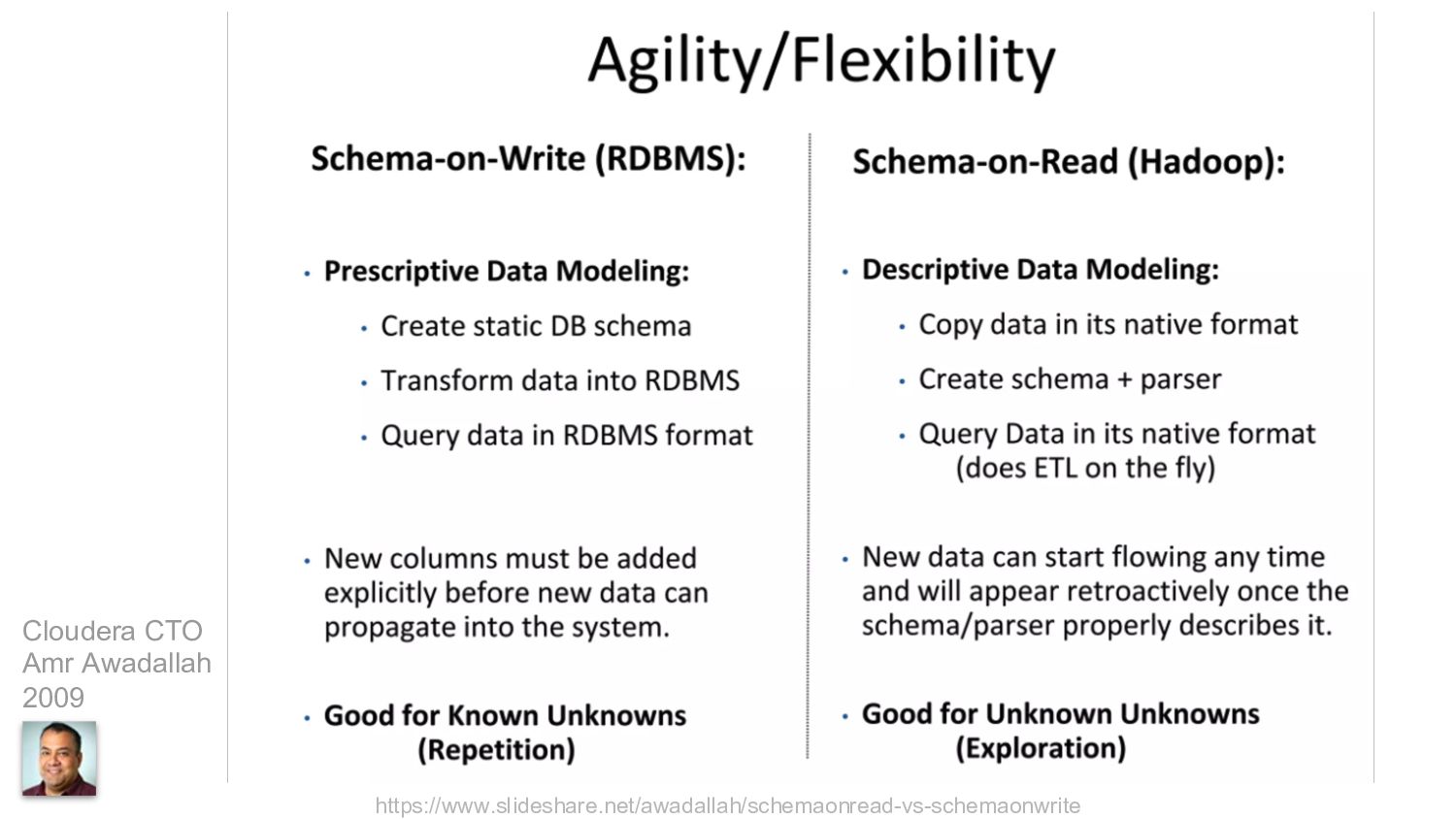
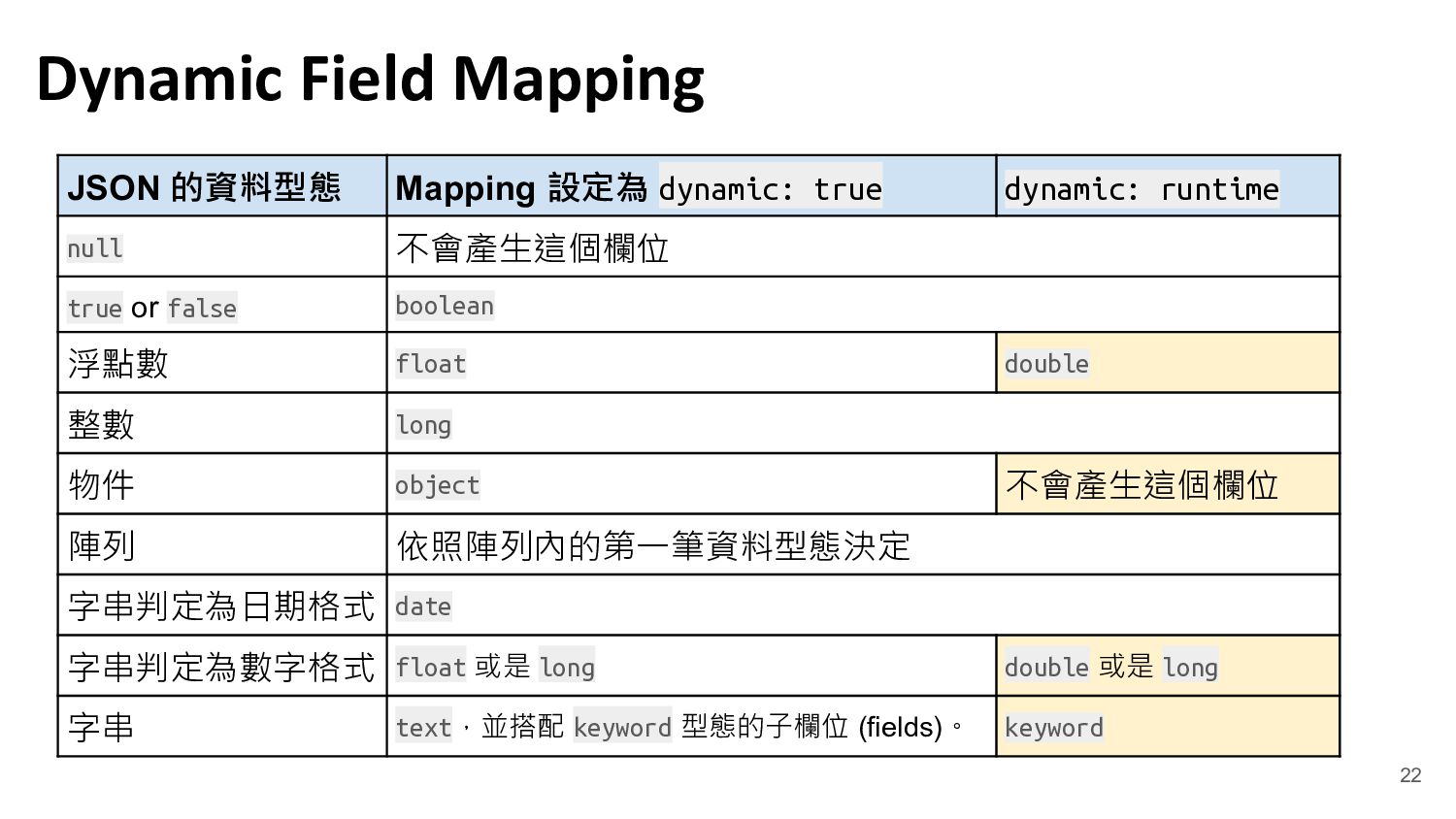
Schema on read 與 Schema on write 的差異與實現方式
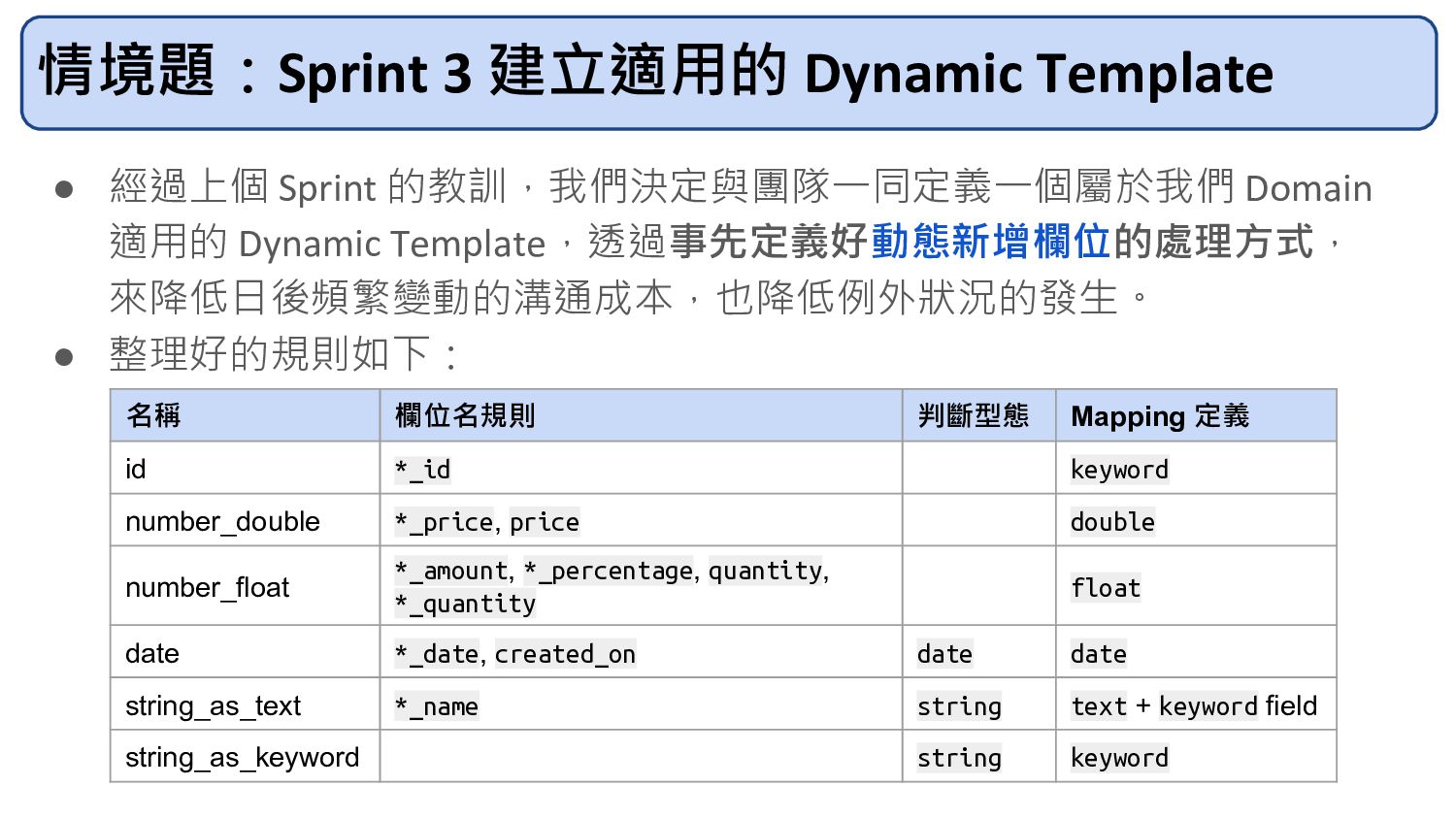
事先定義好的 Data Modeling
動態產生的 Data Modeling
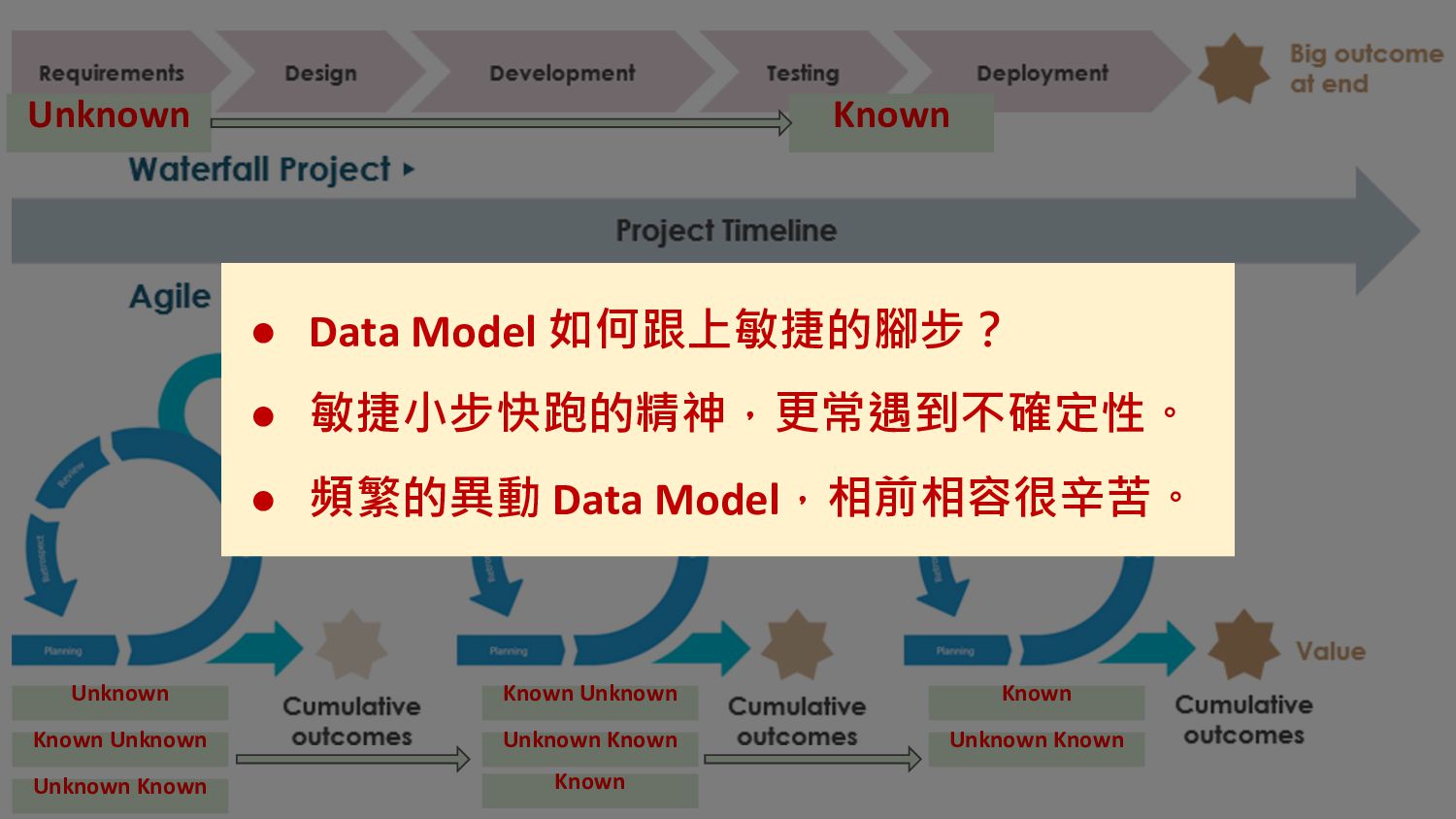
Data Model 的选代
適合已經使用過 Elasticsearch,或至少稍微了解 Elasticsearch 的聽眾。
![Copyright © 2023 一隻狗狗有限公司 Joe Wu (喬叔) [email protected] 如何在 Elasticsearch](https://files.speakerdeck.com/presentations/e1fc42a655c746258076fef4a6f70eee/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}