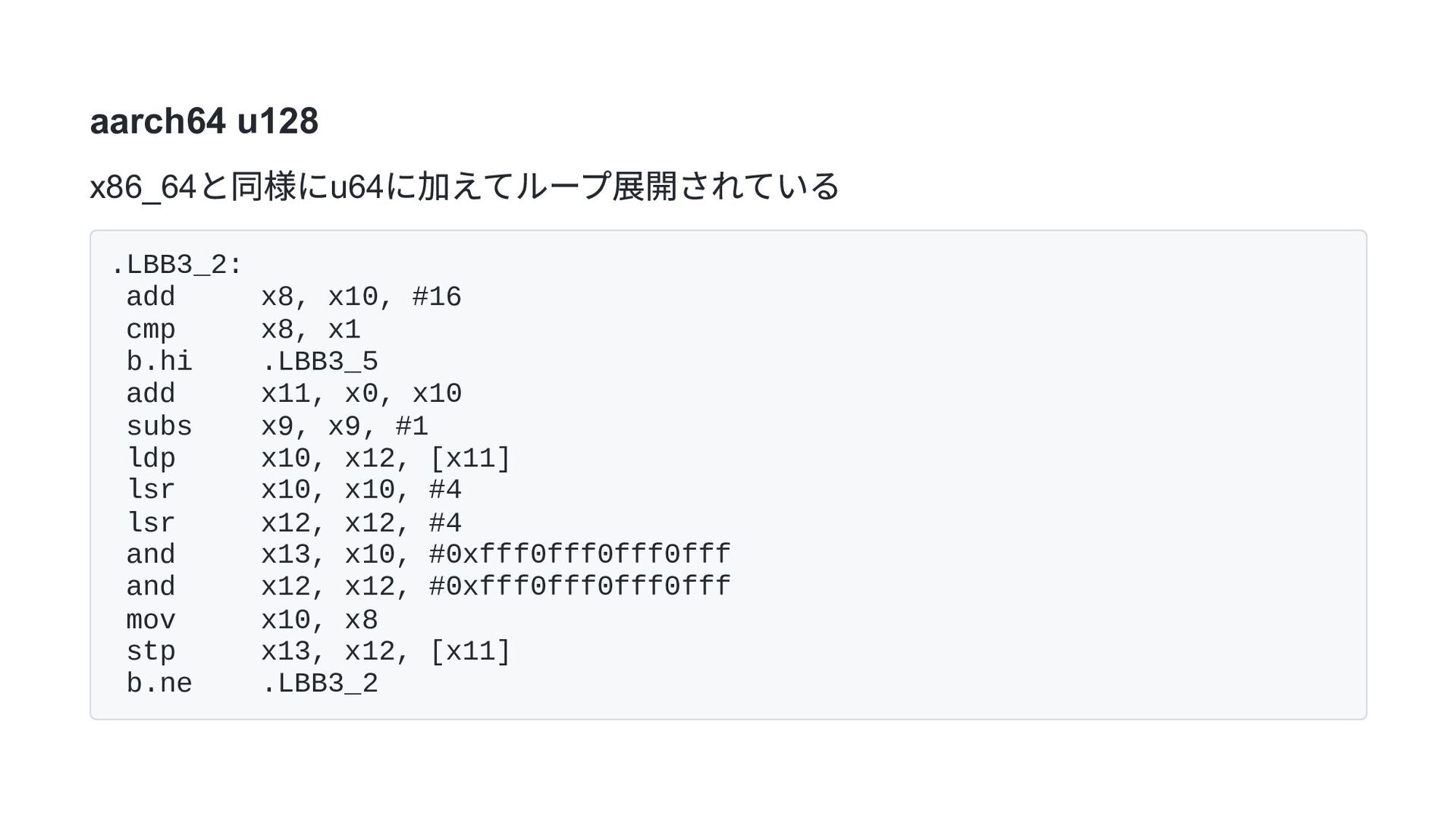
{ for i in 0..buf.len() / 16 { let i: usize = i * 16; let mut a = LittleEndian::read_u128(&buf[i..i + 16]); a = (a & 0xfff0fff0fff0fff0fff0fff0fff0fff0) >> 4; LittleEndian::write_u128(&mut buf[i..i + 16], a); } }
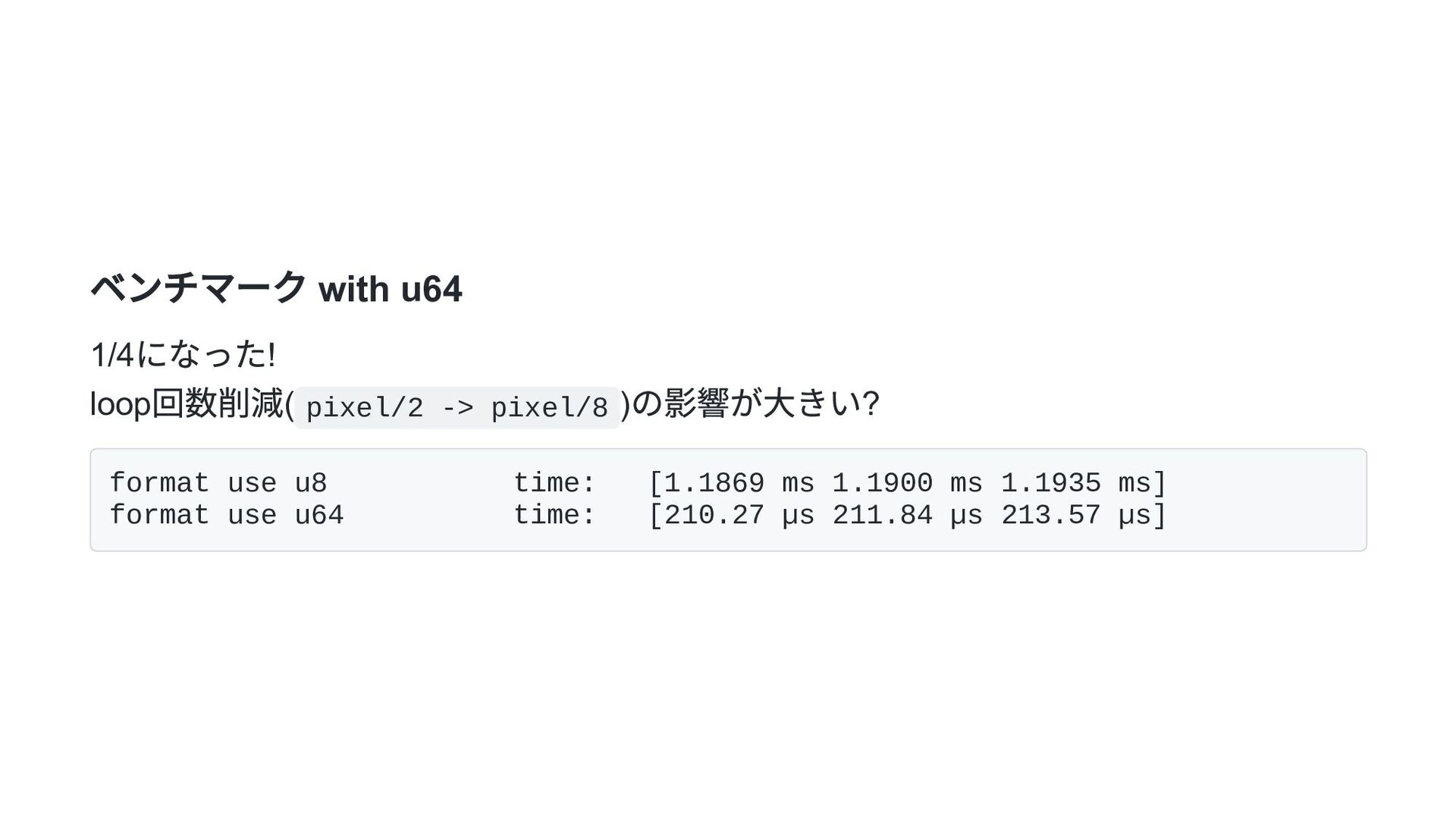
use u8 time: [1.1869 ms 1.1900 ms 1.1935 ms] format use u16 time: [706.00 µs 710.77 µs 716.34 µs] format use u64 time: [210.27 µs 211.84 µs 213.57 µs] format use u128 time: [159.99 µs 164.70 µs 169.74 µs]
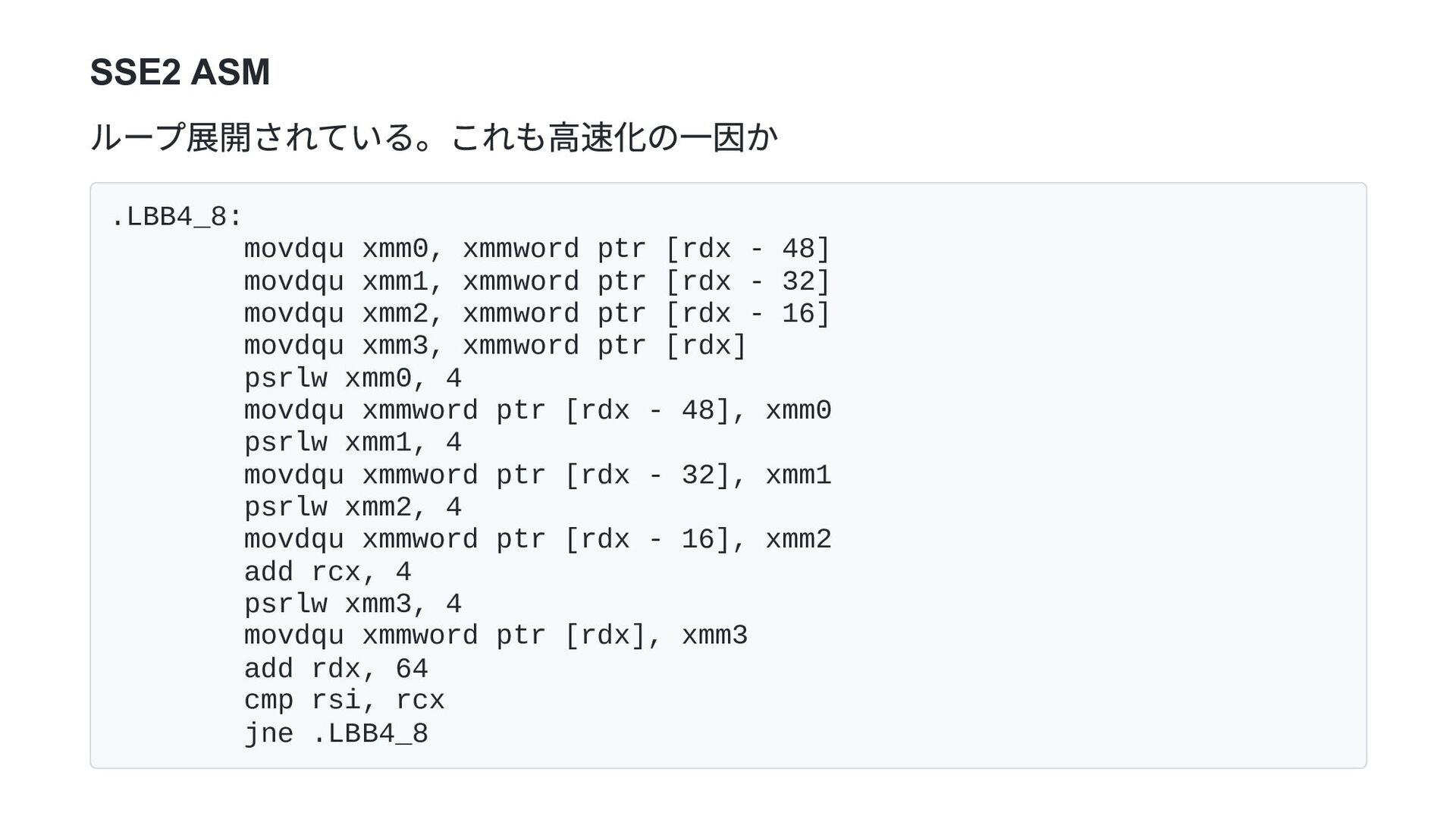
u8 time: [1.1869 ms 1.1900 ms 1.1935 ms] format use u16 time: [706.00 µs 710.77 µs 716.34 µs] format use u64 time: [210.27 µs 211.84 µs 213.57 µs] format use u128 time: [159.99 µs 164.70 µs 169.74 µs] format use 128 SSE2 time: [95.795 µs 97.490 µs 99.380 µs] format use 256 AVX2 time: [92.268 µs 92.971 µs 93.704 µs]
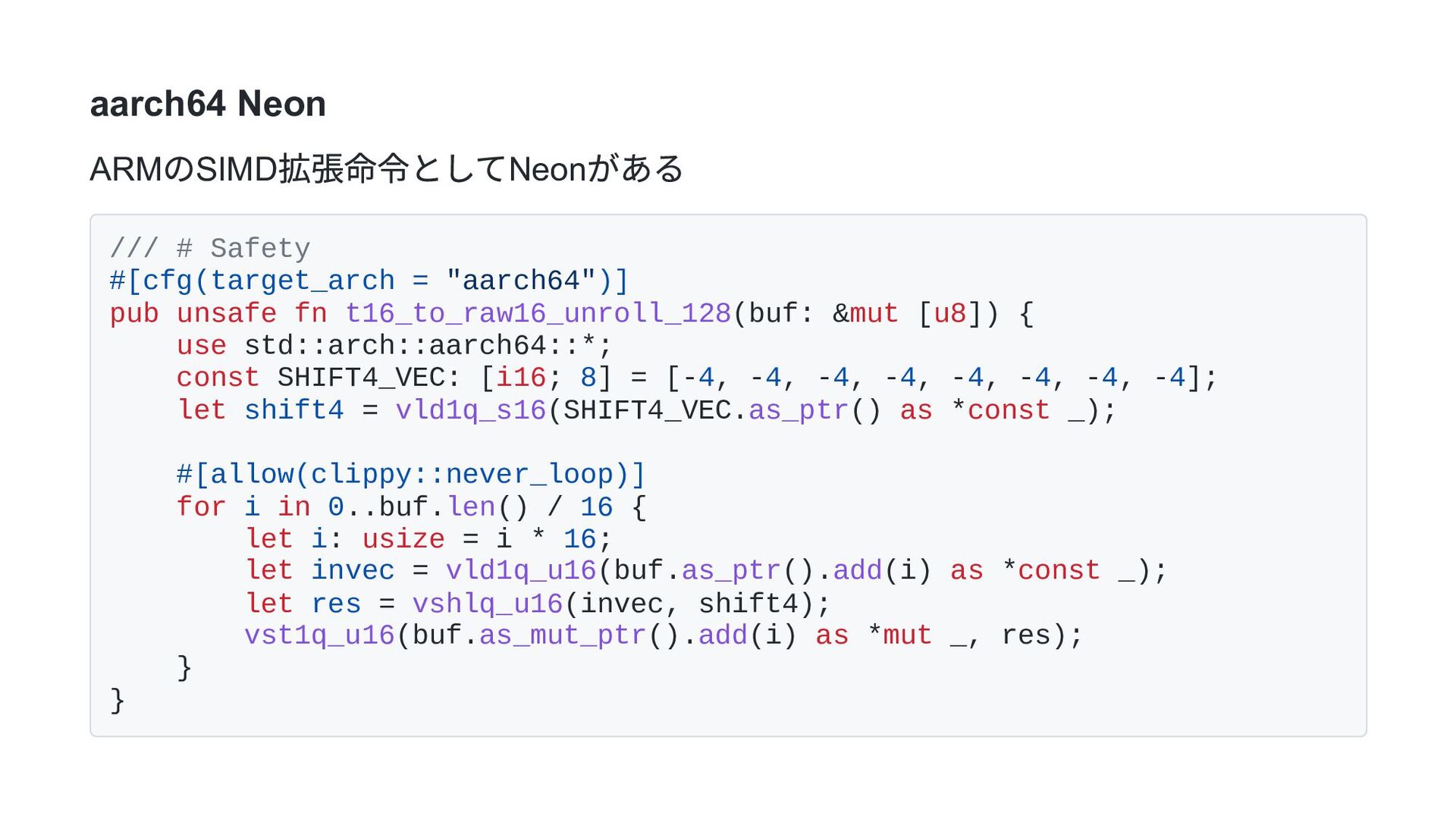
= "aarch64")] pub unsafe fn t16_to_raw16_unroll_128(buf: &mut [u8]) { use std::arch::aarch64::*; const SHIFT4_VEC: [i16; 8] = [-4, -4, -4, -4, -4, -4, -4, -4]; let shift4 = vld1q_s16(SHIFT4_VEC.as_ptr() as *const _); #[allow(clippy::never_loop)] for i in 0..buf.len() / 16 { let i: usize = i * 16; let invec = vld1q_u16(buf.as_ptr().add(i) as *const _); let res = vshlq_u16(invec, shift4); vst1q_u16(buf.as_mut_ptr().add(i) as *mut _, res); } }
u8 time: [2.6863 ms 2.6927 ms 2.7000 ms] format use u16 time: [1.3942 ms 1.3950 ms 1.3964 ms] format use u64 time: [399.52 µs 402.12 µs 404.56 µs] format use u128 time: [280.36 µs 280.38 µs 280.41 µs] format use 128 neon time: [144.28 µs 144.79 µs 145.35 µs] クロックが遅いためかu8 では2.7ms もかかる u128 で1/10 になっている SIMD を使うとx86 の処理時間に肉薄する
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
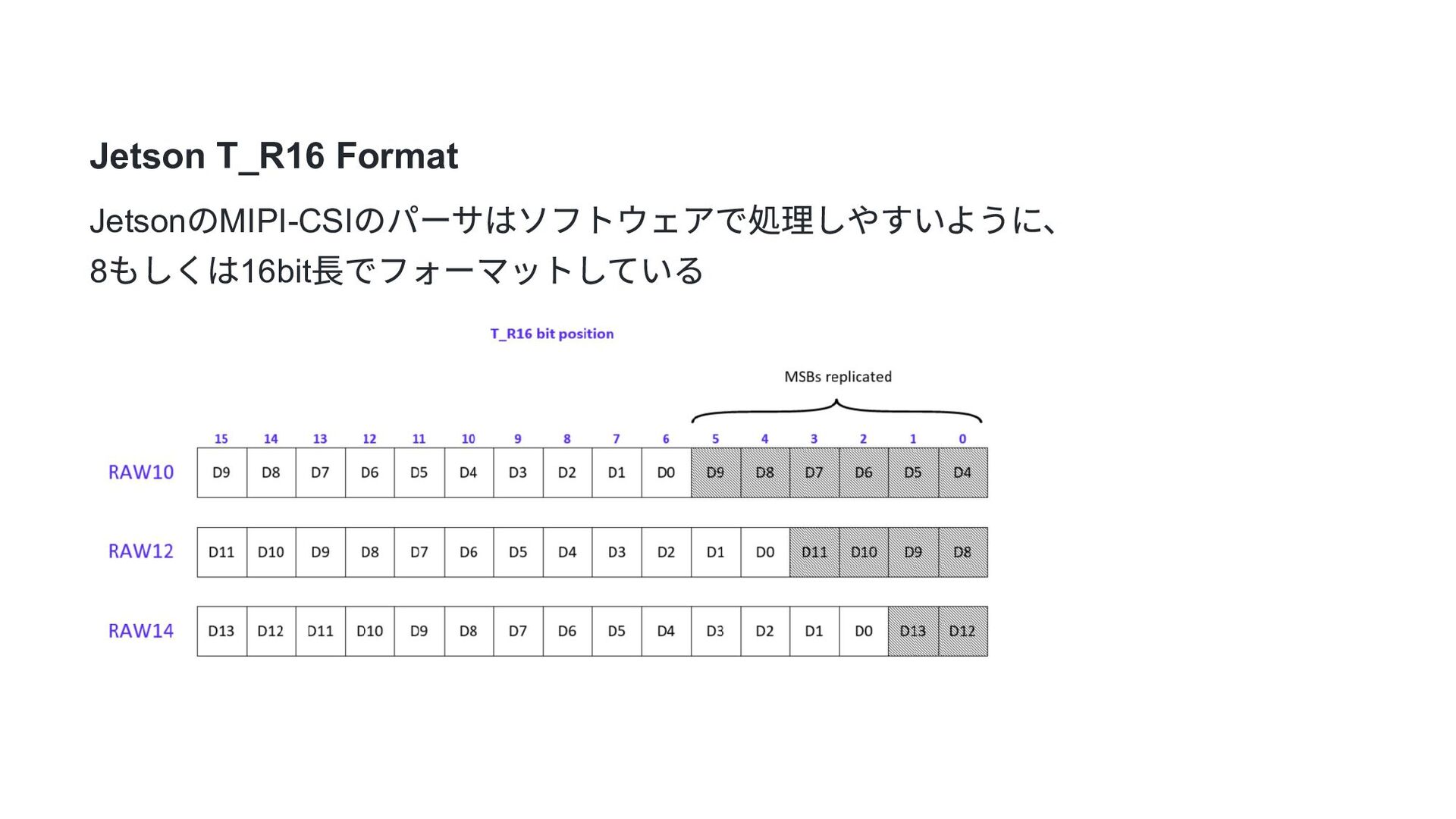{kind=link}
{kind=link}
![ナイーブな実装 u8 単位でシフトして上書きする pub fn t16_to_raw16_u8(buf: &mut [u8]) { for](https://files.speakerdeck.com/presentations/5c2eb701f1f4425c8b079b1637a8206b/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![u8 アセンブリ .LBB6_2: lea rcx, [rax - 1] cmp rcx,](https://files.speakerdeck.com/presentations/5c2eb701f1f4425c8b079b1637a8206b/slide_14.jpg){kind=link}
{kind=link}
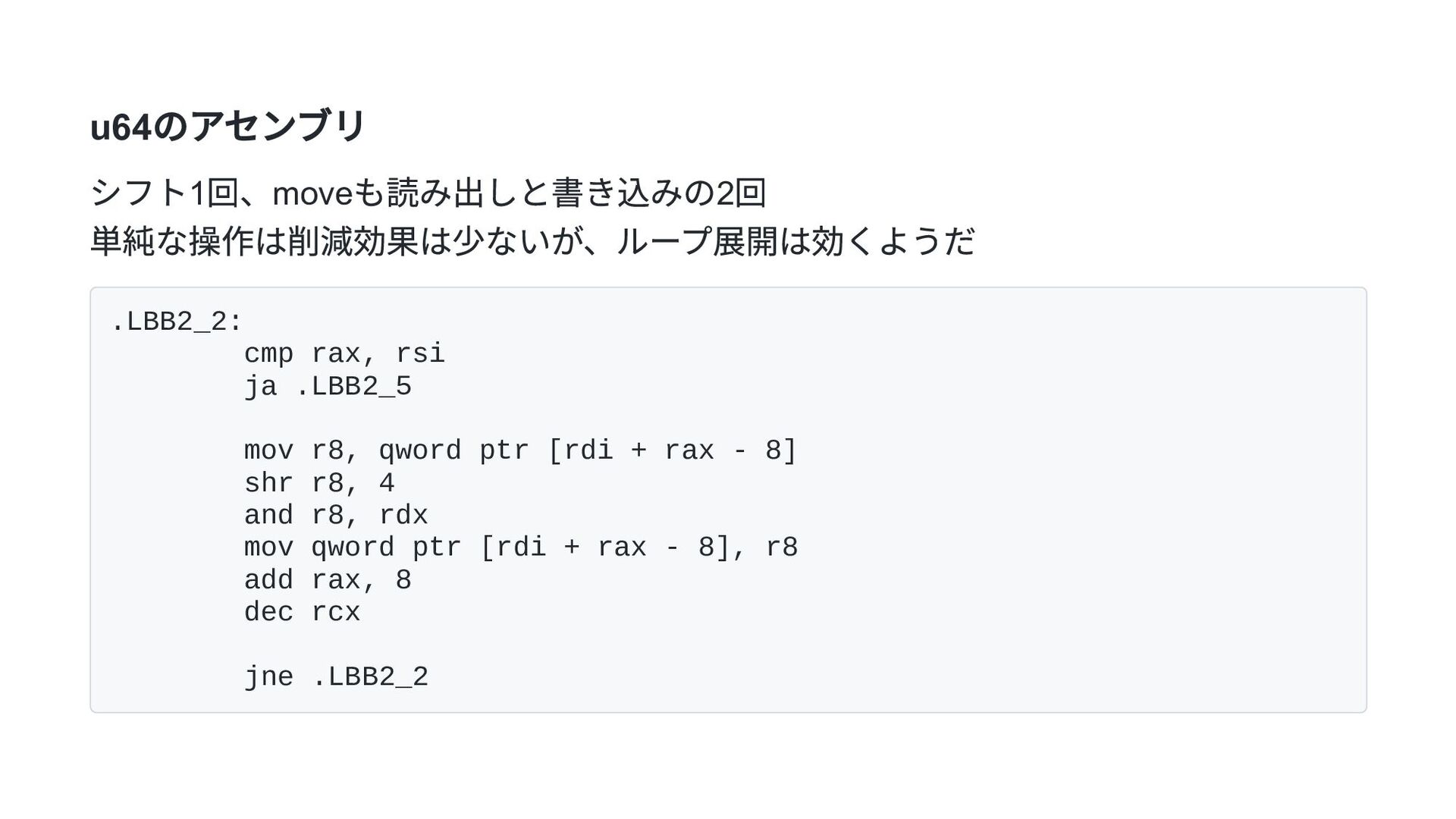
![u64 実装 pub fn t16_to_raw16_u64(buf: &mut [u8]) { for i](https://files.speakerdeck.com/presentations/5c2eb701f1f4425c8b079b1637a8206b/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
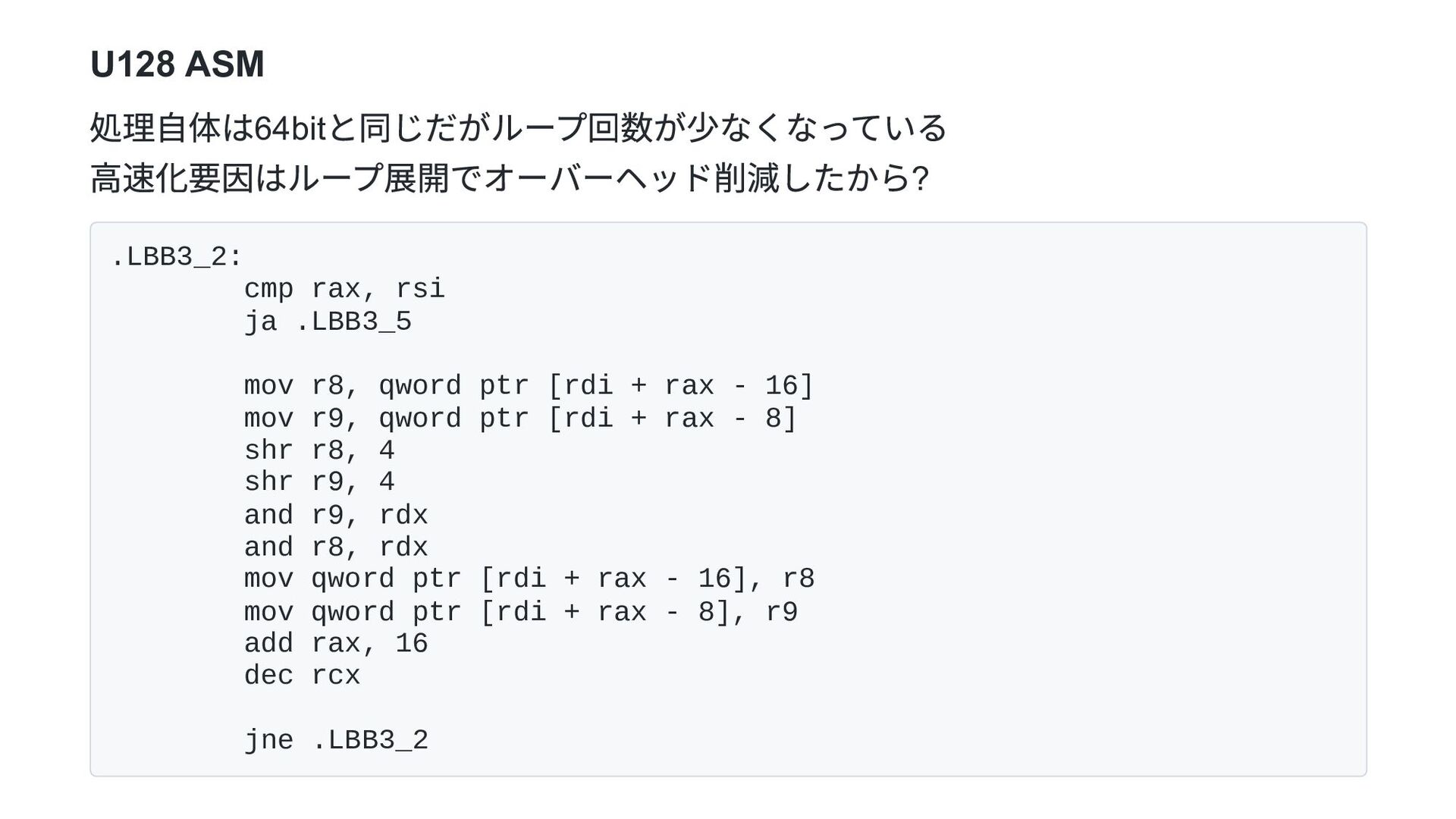
![u128 Rust にはu128 がプリミティブとして用意されている。 これはどうなる? pub fn t16_to_raw16_u128(buf: &mut [u8])](https://files.speakerdeck.com/presentations/5c2eb701f1f4425c8b079b1637a8206b/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![SSE2 /// # Safety #[target_feature(enable = "sse2")] #[cfg(any(target_arch = "x86",](https://files.speakerdeck.com/presentations/5c2eb701f1f4425c8b079b1637a8206b/slide_23.jpg){kind=link}
![AVX2 /// # Safety #[target_feature(enable = "avx2")] #[cfg(any(target_arch = "x86",](https://files.speakerdeck.com/presentations/5c2eb701f1f4425c8b079b1637a8206b/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}