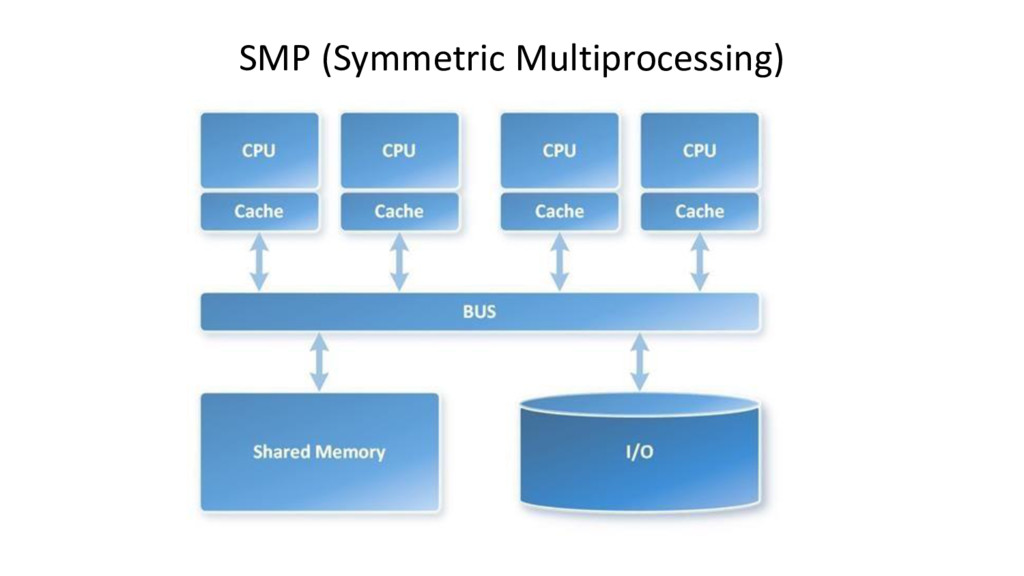
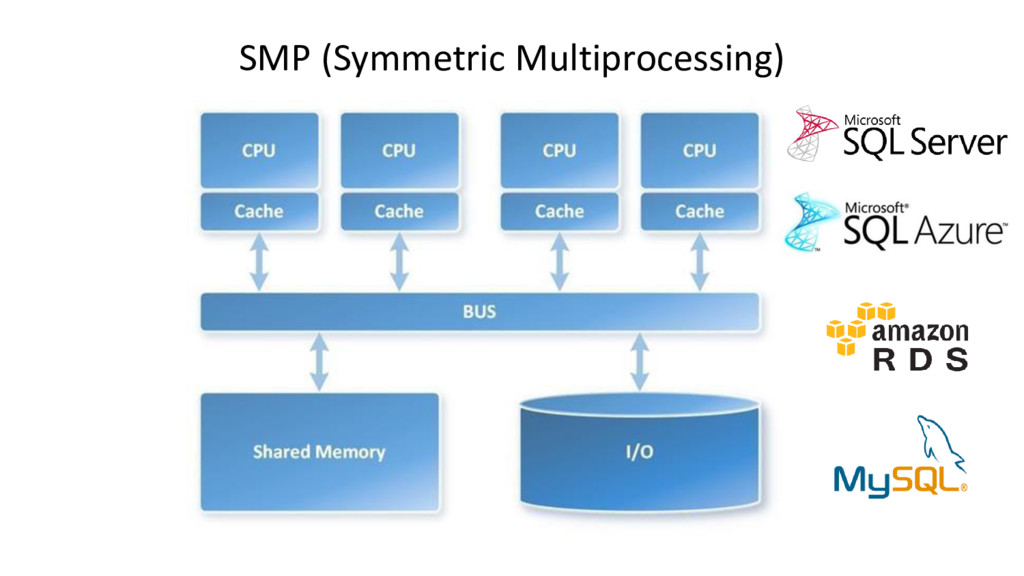
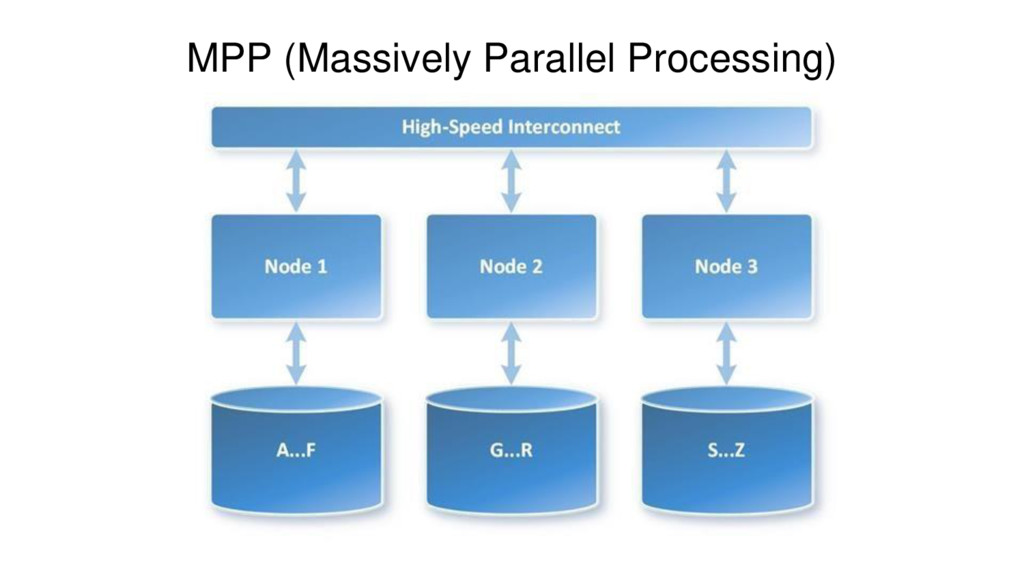
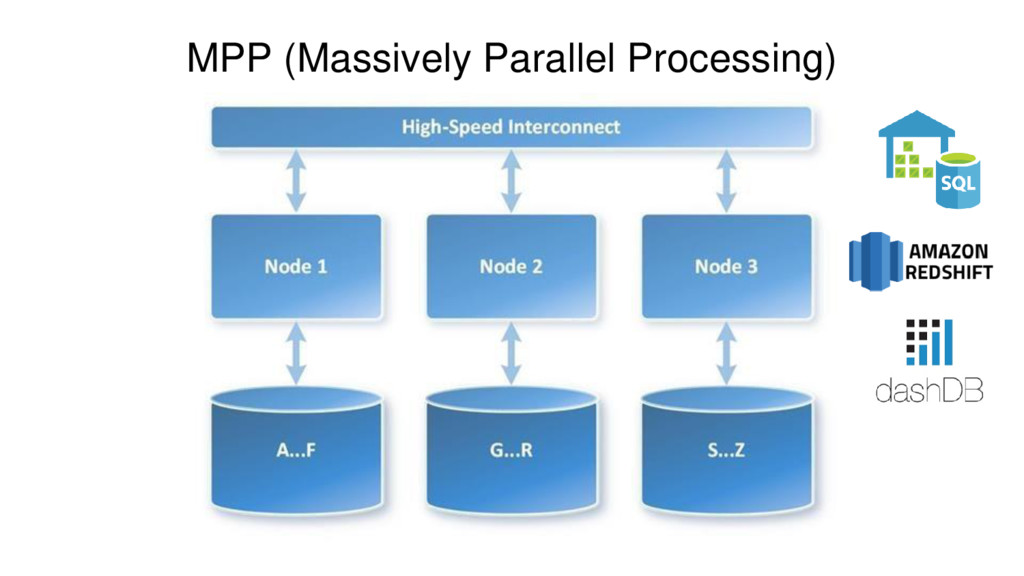
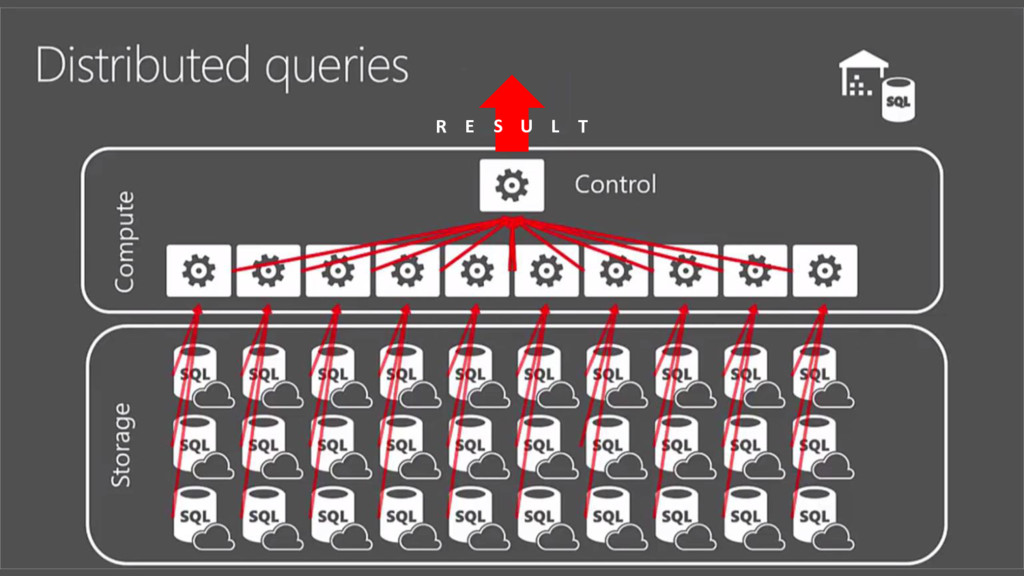
Azure SQL Data Warehouse is a massively parallel processing (MPP) cloud-based, scale-out, relational database, built on SQL Server. Behind the scenes, SQL Data Warehouse spreads your data across many shared storages and processing units. It gives a possibility to grow and shrink compute and storage independently, pause and resume to pay only for what you use.
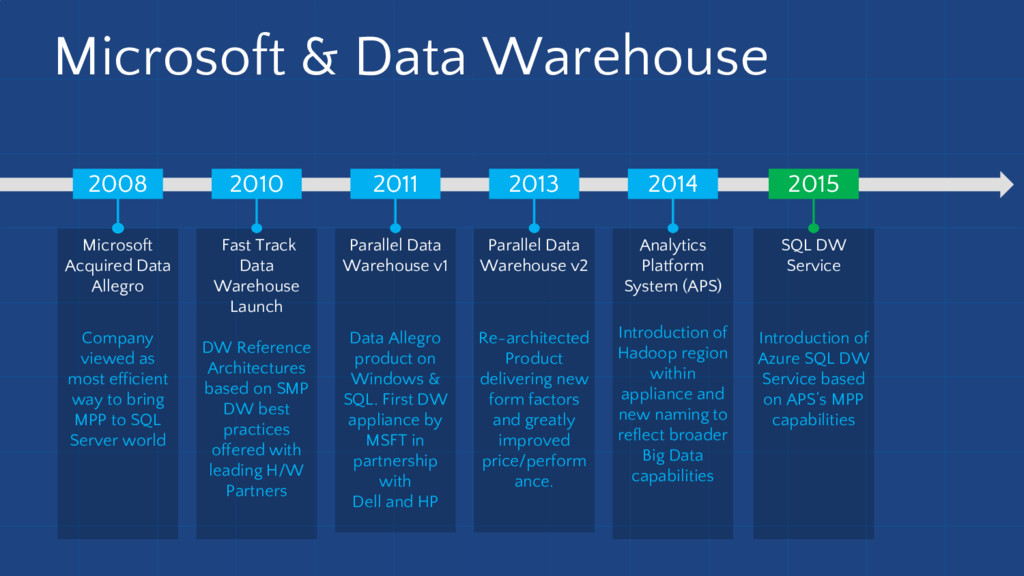
A few months ago, we started exploring Azure Data Warehouse, and now we are successfully using it in production. I would like to share our first lessons learned.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
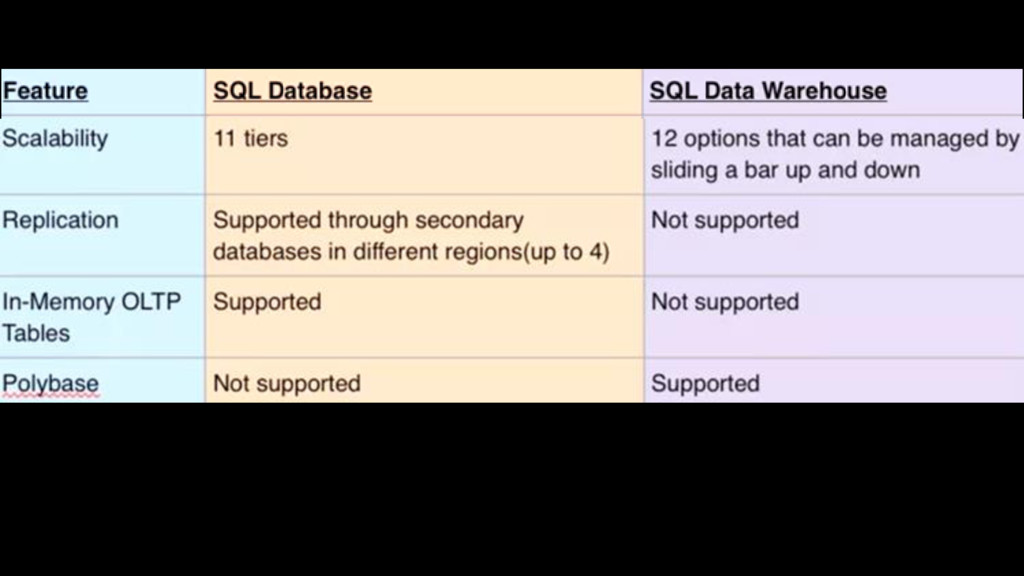{kind=link}
{kind=link}
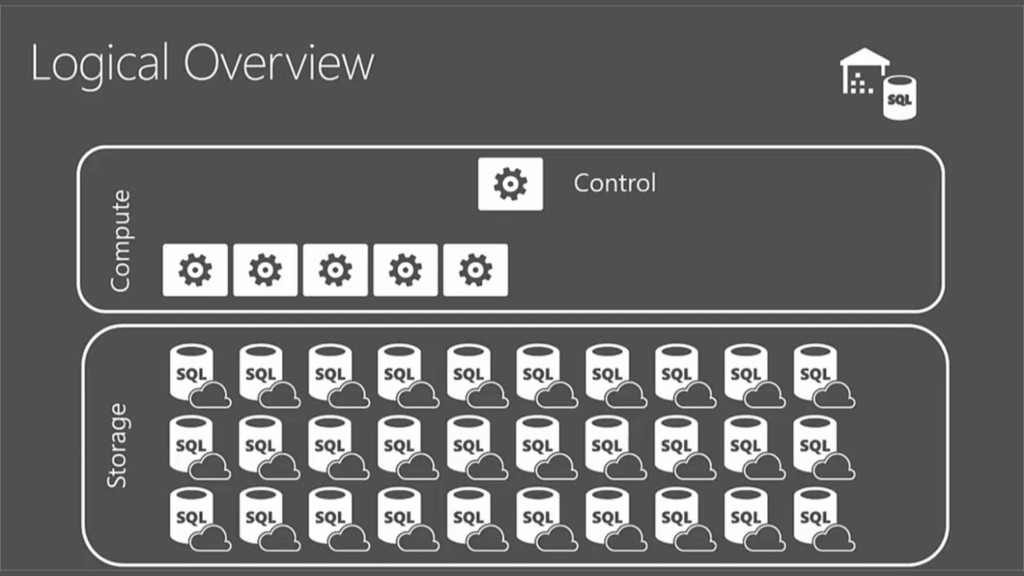{kind=link}
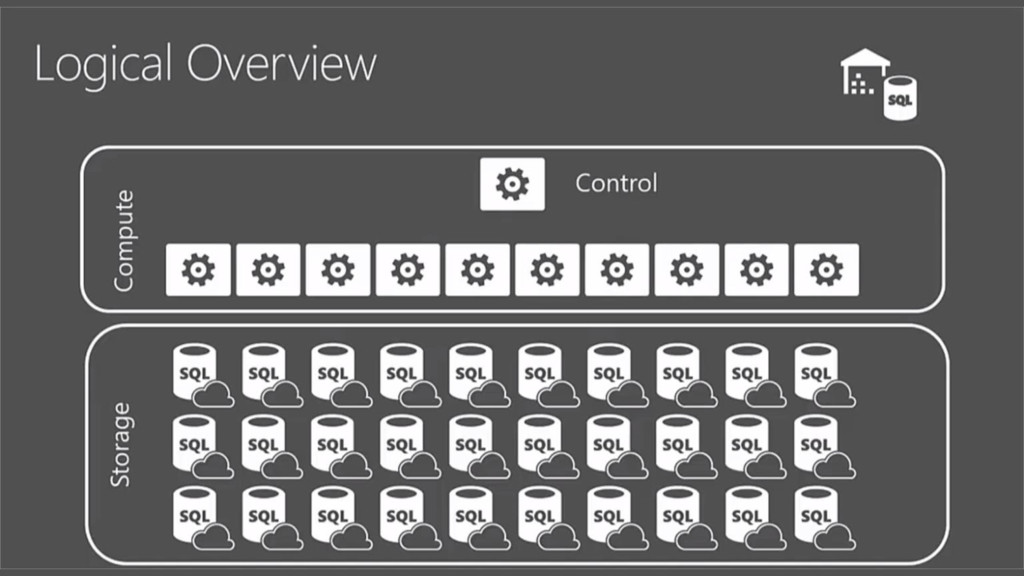{kind=link}
{kind=link}
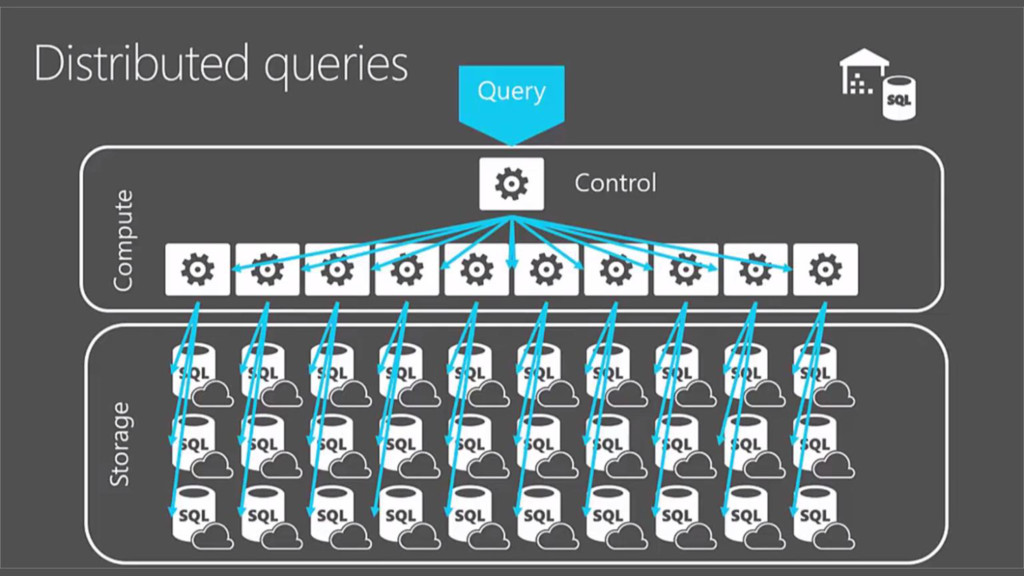{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CREATE TABLE [dbo].[Students] ( [StudentId] INT NOT NULL [Name] VARCHAR(50)](https://files.speakerdeck.com/presentations/56b4b290cd894c5dae1277bb033e7972/slide_35.jpg){kind=link}
{kind=link}
![CREATE TABLE [dbo].[Students] ( [StudentId] INT NOT NULL [Name] VARCHAR(50)](https://files.speakerdeck.com/presentations/56b4b290cd894c5dae1277bb033e7972/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
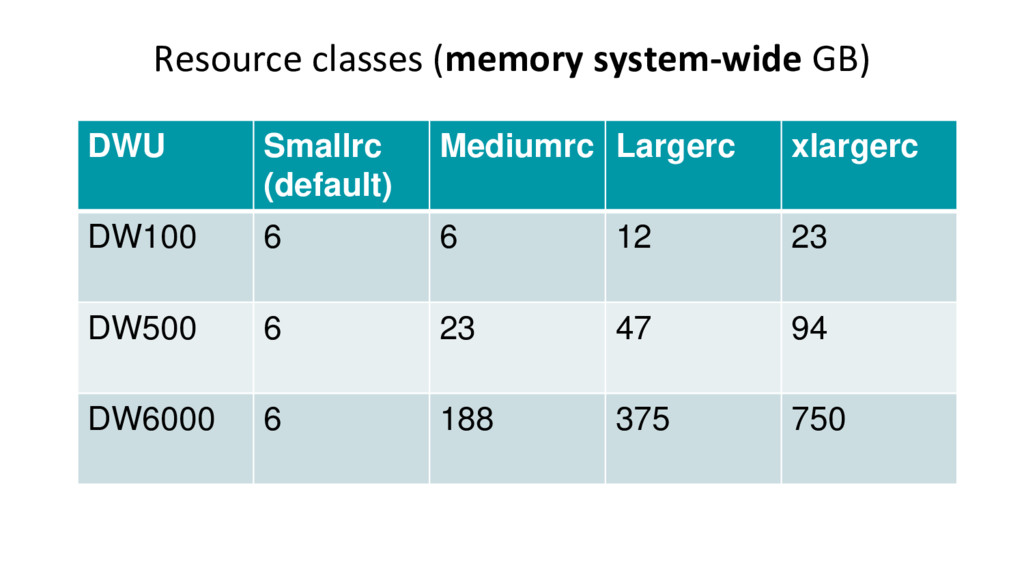{kind=link}
{kind=link}
![CREATE TABLE [dbo].[Students] ( [StudentId] INT NOT NULL [Name] VARCHAR(50)](https://files.speakerdeck.com/presentations/56b4b290cd894c5dae1277bb033e7972/slide_43.jpg){kind=link}
{kind=link}
![CREATE TABLE [dbo].[Students] ( [StudentId] INT NOT NULL [Name] VARCHAR(50)](https://files.speakerdeck.com/presentations/56b4b290cd894c5dae1277bb033e7972/slide_45.jpg){kind=link}
{kind=link}
![CREATE TABLE [dbo].[Students] ( [StudentId] INT NOT NULL [Name] VARCHAR(50)](https://files.speakerdeck.com/presentations/56b4b290cd894c5dae1277bb033e7972/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
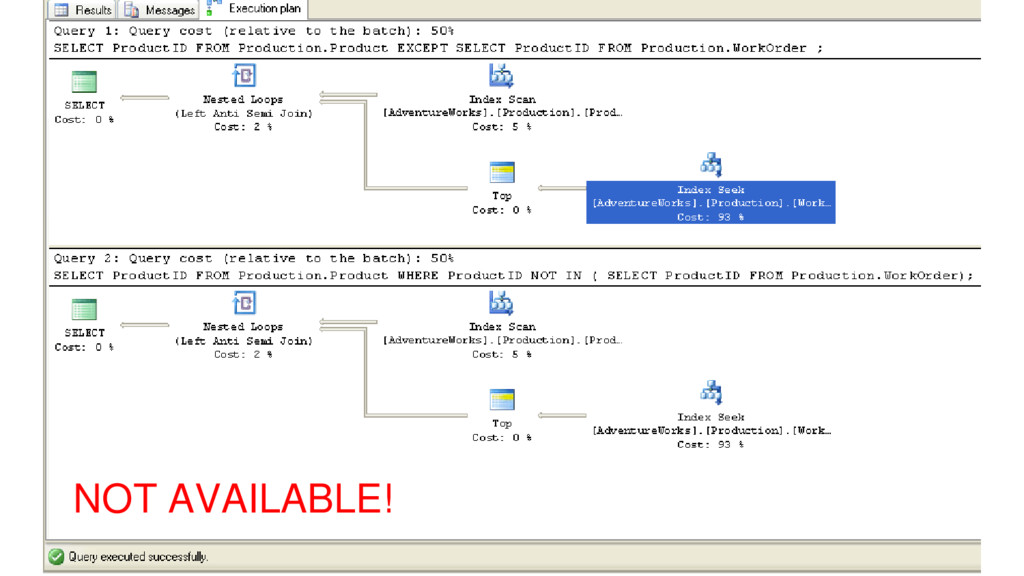{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
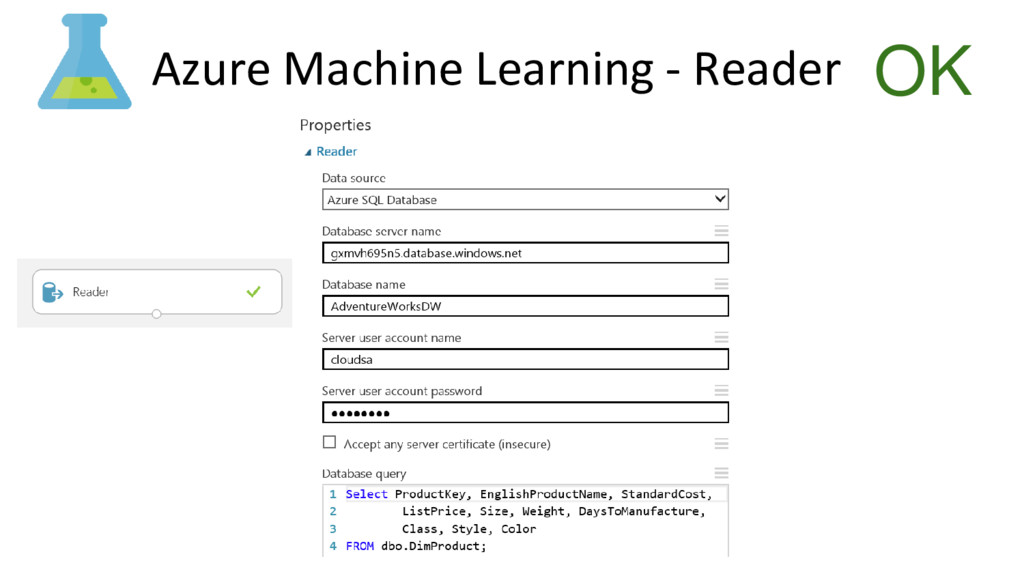{kind=link}
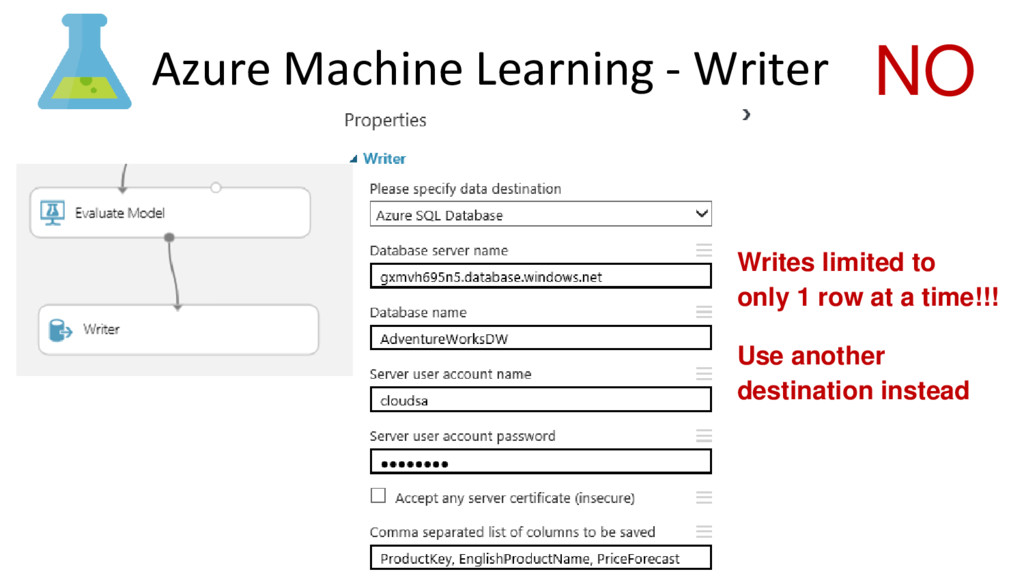{kind=link}
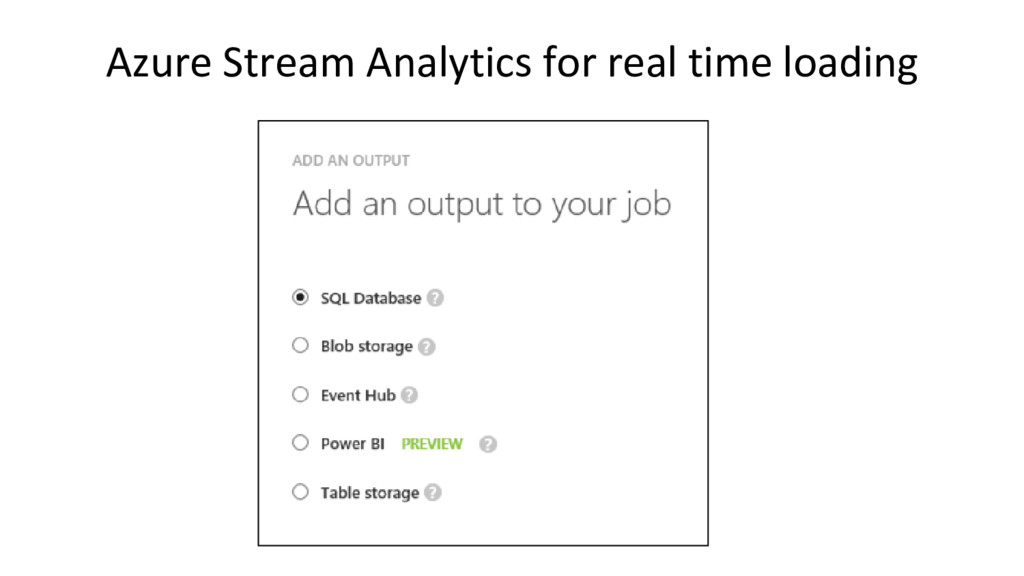{kind=link}
{kind=link}
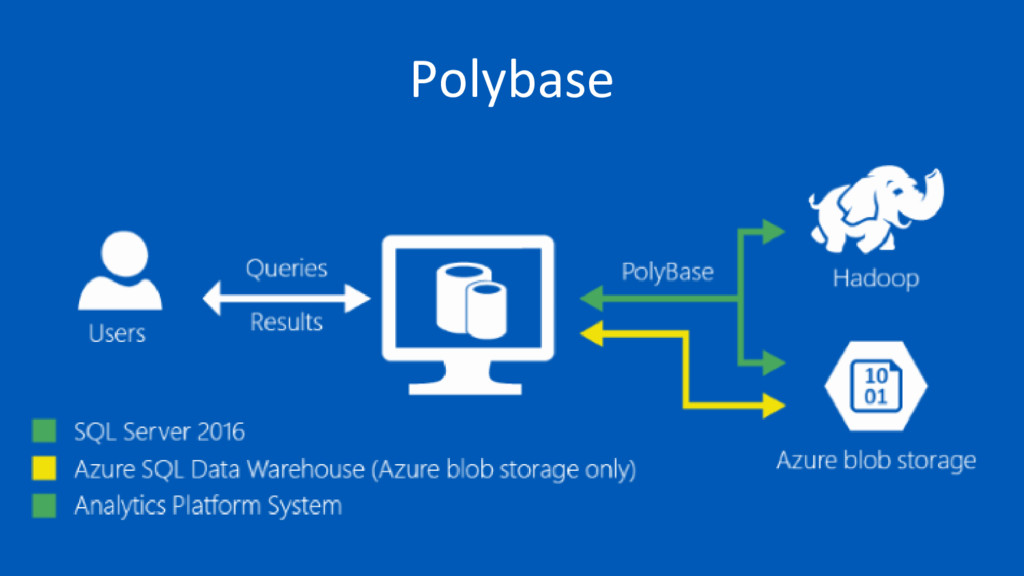{kind=link}
{kind=link}
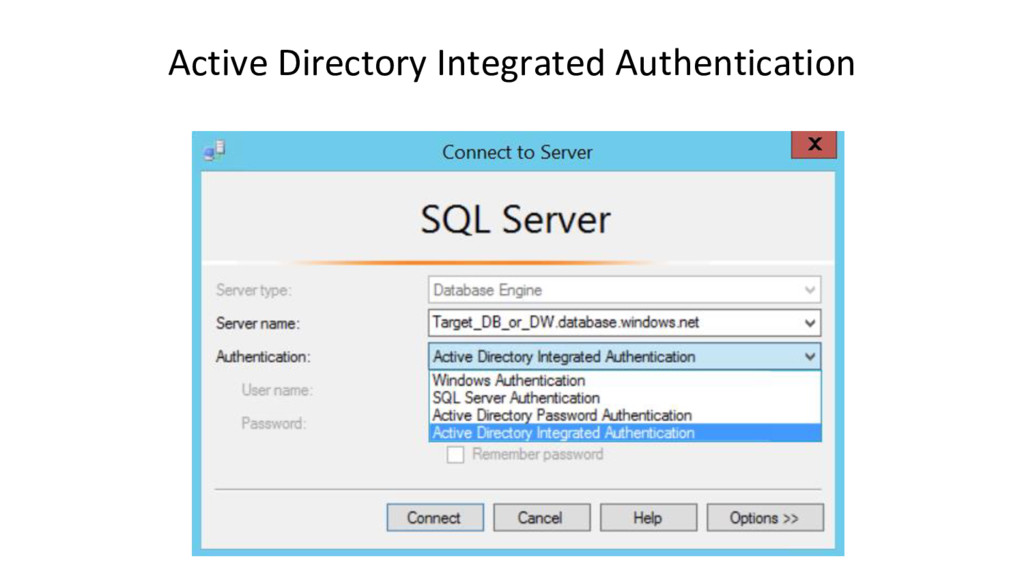{kind=link}
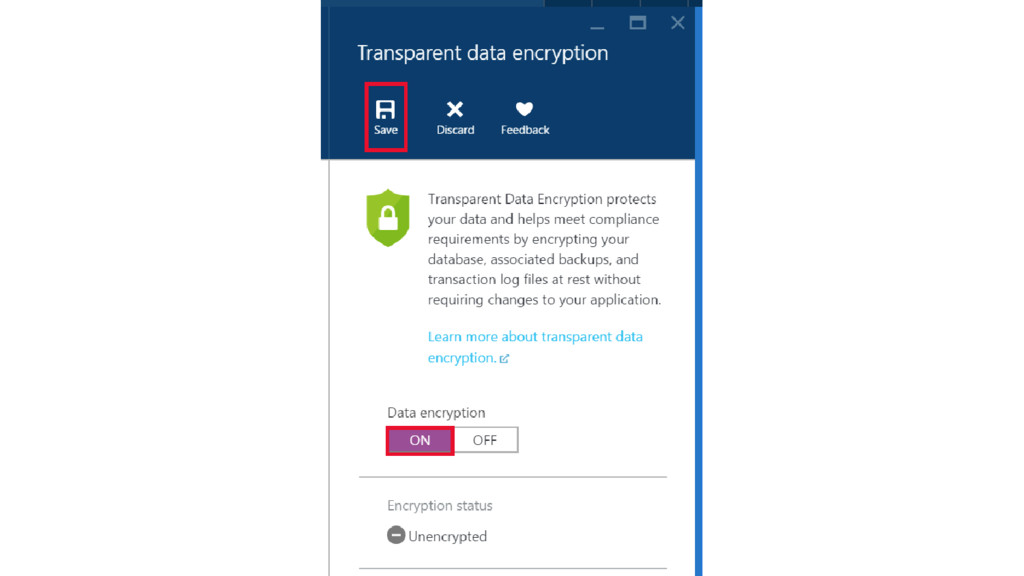{kind=link}
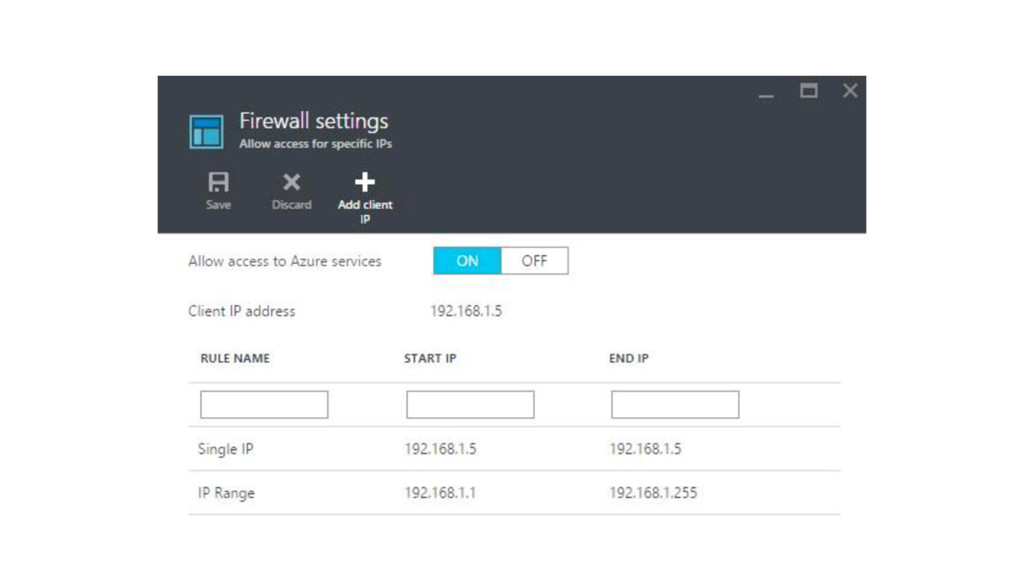{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}