Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
エンジニアは生成AIと どのように向き合うべきか? ことばの意味という観点から
Search
Hitomi Yanaka
May 29, 2026
Technology
420
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
エンジニアは生成AIと どのように向き合うべきか? ことばの意味という観点から
Qiita Conference 2026
https://qiita.com/official-campaigns/conference/2026
Hitomi Yanaka
May 29, 2026
More Decks by Hitomi Yanaka
See All by Hitomi Yanaka
ことばの意味を計算するしくみ
verypluming
11
4.1k
この先生きのこるには
verypluming
4
6.2k
Compositional Evaluation on Japanese Textual Entailment and Similarity (JSICK:構成的推論・類似度データセットSICK日本語版の紹介)
verypluming
2
1.3k
東京大学深層学習(Deep Learning基礎講座2022)深層学習と自然言語処理
verypluming
53
49k
JaNLI: 日本語の言語現象に基づく敵対的推論データセット
verypluming
0
590
Other Decks in Technology
See All in Technology
41歳でAWSが好きすぎてITエンジニアになったおっさんの話
yama3133
1
790
AI エージェント時代のデジタルアイデンティティ
fujie
0
800
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
380
害獣害虫を自動判別! ペストコントロール支援ビジネス成功のヒント【SORACOM Discovery 2026】
soracom
PRO
0
110
脱Jenkins、インターン生が挑んだCIツールGitHubActions移行
mixi_engineers
PRO
1
210
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1.4k
Jitera Company Deck
jitera
0
640
【5分でわかる】セーフィー エンジニア向け会社紹介
safie_recruit
0
53k
データベース研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
570
現場との対話から始める “作る前に問い直す”業務改善
mochico50
2
330
データエンジニアリングとドメイン駆動設計
masuda220
PRO
15
2.7k
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
30
17k
Featured
See All Featured
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.7k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
420
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
640
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
180
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
1k
How to Ace a Technical Interview
jacobian
281
24k
YesSQL, Process and Tooling at Scale
rocio
174
15k
The SEO identity crisis: Don't let AI make you average
varn
0
520
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
810
Abbi's Birthday
coloredviolet
3
8.8k
Agile that works and the tools we love
rasmusluckow
331
22k
Transcript
エンジニアは生成AIと どのように向き合うべきか? ことばの意味という観点から 東京大学 理化学研究所 谷中 瞳 http://hitomiyanaka.strikingly.com/
[email protected]
X: @verypluming Qiita
Conference 2026 1
自己紹介 東京大学大学院 情報理工学系研究科 コンピュータ科学専攻 谷中研究室 准教授(卓越研究員) 理化学研究所 革新知能統合研究センター 説明可能AIチーム チームディレクター 研究分野:自然言語処理、計算言語学 経歴 2018-2021 理化学研究所革新知能統合研究センター 特別研究員
2015-2018 東京大学大学院工学系研究科システム創成学専攻 博士(工学) 2
宣伝:「ことばの意味を計算するしくみ」 ・ことばの意味を形式的にとらえる 計算言語学 ・ことばの意味を統計的にとらえる 自然言語処理 ことばの意味を計算する2つの アプローチの可能性と課題を整理 2026年ITエンジニア本大賞技術書部門受賞! https://x.gd/Y13JK 3
生成AIを活用した開発業務の効率化が急速に普及 代表例(ごくごく一部) • コーディング支援 ◦ GitHub Copilot、Claude Code、Gemini CLI、Codex CLIなど
• テキスト生成 ◦ チャットボット、文書校正、機械翻訳、情報検索など • 画像生成 ◦ デザインプロトタイプ作成、コンテンツ制作支援など 4
生成AIを活用した開発業務の効率化が急速に普及 代表例(ごくごく一部) • コーディング支援 ◦ GitHub Copilot、Claude Code、Gemini CLI、Codex CLIなど
• テキスト生成←今日はこちらを中心に話します ◦ チャットボット、文書校正、機械翻訳、情報検索など • 画像生成 ◦ デザインプロトタイプ作成、コンテンツ制作支援など 5
LLM:テキスト生成に特化した生成AI 2023年頃からChatGPTをはじめとして、大量のテキストと深層学習を用いて 統計的にことばを学習する大規模言語モデル(LLM) が急速に発展 6 図は[Minaee+2024]から引用
本日は、以下の順に紹介します 1. LLMの基本的なしくみ 2. LLMのしくみからわかる課題 3. LLMの課題を踏まえた活用方法 4. 今後、LLMとどのように向き合うと良いか 7
LLMはそもそもどのようにことばの意味を捉えている? LLMは語の分布に基づいてことばの意味を捉えている(分布意味論 ) 語の意味は周囲の語(文脈)から形成されるという分布仮説に基づいて、語の 意味をベクトルで記述 天気という語は今日という語と同時に出現しやすい: 語の意味をその語の周囲に現れる語の出現頻度に基づいて表す 今日の天気は晴れである。 今日の1時間ごとの天気、気温、降水量を掲載します。 あなたが知りたい天気予報をお伝えします。
今日は天気が良いので布団を干した。 8
どうやって単語の意味を表す?(1):one-hotベクトル 文を一定の区切り(トークン)で分割し、各トークンにID(次元)を振り、one-hot ベクトル(局所表現)にする 今日(1,0,0,0,0,0,0) 今日 (1,0,0,0,0,0,0) は (0,1,0,0,0,0,0) は (0,1,0,0,0,0,0)
晴れ(0,0,1,0,0,0,0) 休み (0,0,0,0,0,1,0) て (0,0,0,1,0,0,0) だ (0,0,0,0,0,0,1) いる (0,0,0,0,1,0,0) 今日 は 晴れ て いる 1 2 3 4 5 今日 は 休み だ 1 2 6 7 9 トークン ID ※トークンの区切り方は複数通り考えられることに注意 (例:「て いる」と「ている」)モデルによって異なる
どうやって単語の意味を表す?(2):単語の分散表現 局所表現は非常に高次元になり計算効率が悪いので、分散表現にする:単語 埋め込みベクトルhをone-hotベクトルxに変換⾏列Wをかけて得る h=Wx - Wは埋め込み行列、コーパス(テキストの集合)から学習 - xの次元はコーパス中のトークン数 - hの次元は埋め込みたい数(ハイパーパラメータ)
- 例)Llama3.1-8B-Instructの埋め込み次元数は4096 10
単語の意味から文の意味を計算する:言語モデル トークン系列w 1 , w 2 ,…,w i-1 の次に続くトークンw i
の 出現確率(確からしさ)P(w 1 , w 2 ,…,w i )を計算するモデル P(今日,の,天気,は,GPT)=0.0000003 P(今日,の,天気,は,パンダ)=0.0000007 P(今日,の,天気,は,晴れ)=0.0000127 出現確率が高い文を自然な文として生成するように学習 →今日,の,天気,は,晴れ 11
大規模言語モデルの根幹にあるモデル:Transformer [Vaswani+2017] 12 Encoder Attentionに基づくEncoder-Decoder (系列変換)モデル • Attention : 入力系列の重要な情報(どの単語に注目するか)
を用いるしくみ マルチヘッドで並列処理可能、LLMの誕生へ • Encoder-Decoder : 入力系列を1つの埋め込みベクトルに変換する Encoderモデルと、 Encoderのベクトルを受け取り1トークンずつ生成 するDecoderモデルから構成 Decoder
GPT (Generative Pre-trained Transformer) [Radford+2018] 元祖・大規模なコーパスによる事前学習に基づく大規模言語モデル TransformerのDecoder部分を用い、トークン列の次に続くトークンの確率を計 算:Transformerがことばの深い再帰、局所曖昧性、長距離依存関係にある程 度頑健になったので、高性能で確率を計算できる 13
図は[Devlin+2019]から引用
GPT-3:現在のChatGPTの前身[Brown+2020] • OpenAIが開発したLLM • 基本構成はGPTと同じだが、事前学習に用いるデータサイズやパラメータ 数が桁違いに大きい ◦ 570GBのテキストデータで事前学習、パラメータ数は175B ◦ LLMの性能は基本的には計算資源・データサイズ・パラメータ数が多いほど良
い[Kaplan+2020] • GPT-3以降のLLMは、タスクの説明と少数の正解例をプロンプト として入 力に含めれば、ある程度タスクに適応できる(文脈内学習) • 現在のLLMは事前学習に加えて指示チューニング(プロンプト遵守率を高 める追加学習)、思考過程の生成を促す追加学習なども実施 14
LLMの課題1:分布仮説に起因する問題 否定、量化、数量、時制、比較、代名詞など、文法が関わる意味は、 分布仮説に従うとは限らない 15 機械翻訳の例 日本語:私は泳げなくないわけではない 英語:Not that I can't
swim. 複雑な構文になると、入力の認識や出力の生成を誤ることがある 「喫煙席のないカフェ」で 検索したのに、喫煙席のある カフェばかり出てくる… 情報検索の例
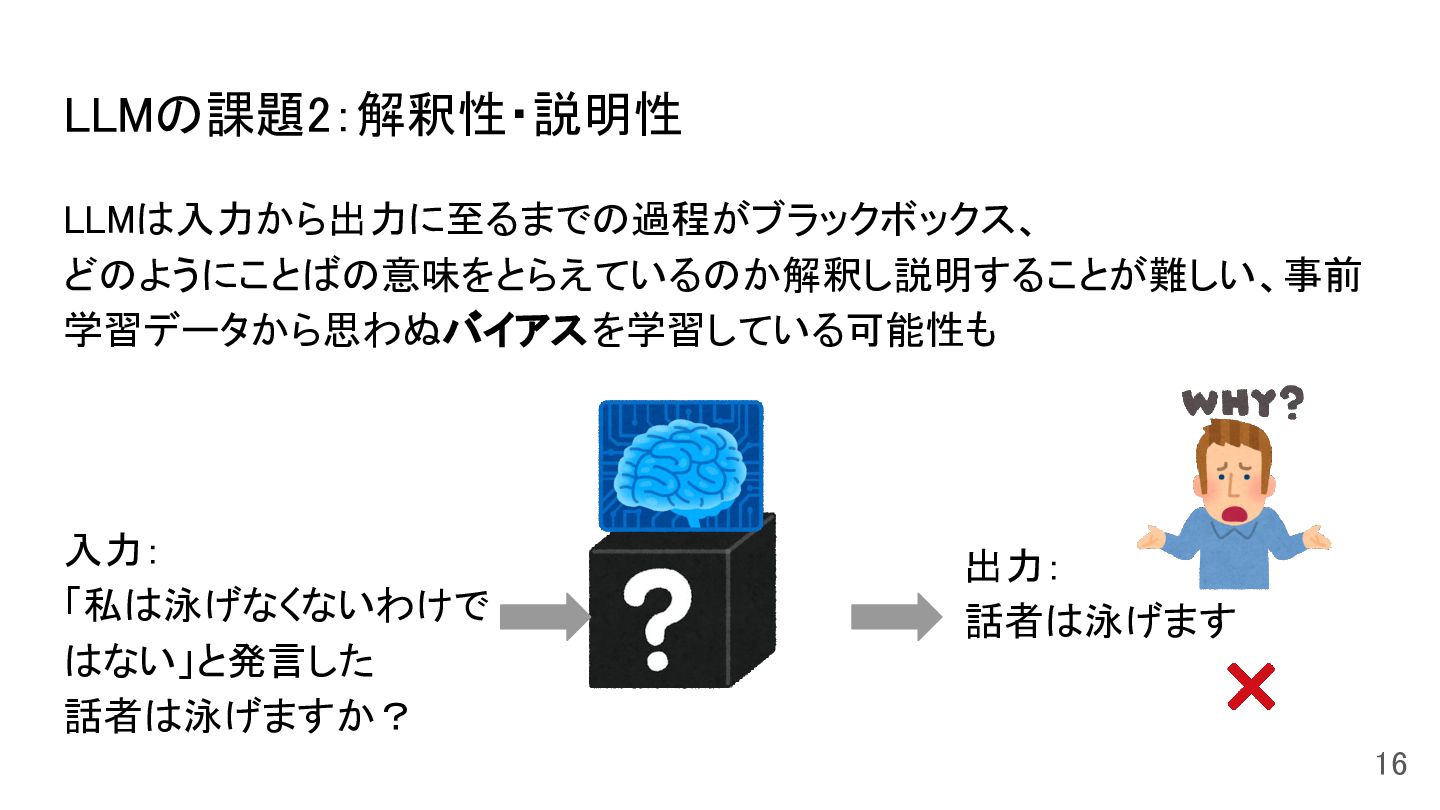
LLMの課題2:解釈性・説明性 LLMは入力から出力に至るまでの過程がブラックボックス、 どのようにことばの意味をとらえているのか解釈し説明することが難しい、事前 学習データから思わぬバイアスを学習している可能性も 16 入力: 「私は泳げなくないわけで はない」と発言した 話者は泳げますか? 出力:
話者は泳げます
LLMの課題をふまえたLLMの活用方法(1)プロンプト • LLMにどういうタスクをやってもらいたいのか、 単純な語・構文・構造で、曖昧さを残さずに、具体的に書こう ◦ 複数の意味を持つ語、否定、指示語の多用など、複雑な構文になると ハルシネーション(幻覚)を起こしやすい[Watson+2026] ◦ 悪い例:あのスピードについて教えて 「あの」は何を指す?「スピード」は映画?トランプのゲーム?
◦ タイポや無駄な空白も、性能に影響を与える[Romanou+2026] ◦ プロンプト最適化を使用する場合も、結局初期のプロンプト設定が重要 • LLMの学習データの多くは英語である ことを考慮しよう ◦ LLM内部では英語で思考しているという研究も[Zhong+2024] ◦ 日本語ではなく英語で聞いた方が正しい場合もある(ただし、複数言語が混在 するコードスイッチングクエリは悪化する場合もある[Zeng+2026]) 17
LLMの課題をふまえたLLMの活用方法(2)タスク設定 • なるべく単純なタスク設定にしよう ◦ 人間が解けないタスクは、基本的にはLLMも解けない ◦ 1つのプロンプトで複数のタスクを聞かない(エージェントを分ける) • タスク設定やプロンプトが適切か、テストデータで確認 しよう
◦ 実際に頻出するデータと、例外的なデータの両方でテスト ◦ 適切なfew-shot example、参考URLなどエビデンスを与えると効果的 • タスクの背景、ロール、ペルソナをシステムプロンプト で明確に ◦ 例:あなたは社内チャットボットを開発しているエンジニアです ◦ ただし、複数の背景を与えると、部分的にしか考慮してくれない場合も • タスクに合った出力形式を指定しよう ◦ 長い文字数の遵守は苦手 例:2000字でLLMとは何か説明して 18
LLMの課題をふまえたLLMの活用方法(3)人間のチェック • LLMのバイアスやハルシネーションの問題は原理的に避けられない。プロ ンプトインジェクションや情報漏洩などの安全性の問題も ◦ プロンプトインジェクション:悪意のあるプロンプトを入力してシステムプロンプト を引き出すなどの不正な挙動を誘発する攻撃 • RAG (Retrieval-Augmented
Generation) による事実照合やガードレール モデルなど、データや用途に合わせて技術を使い分けよう ◦ 大規模データの高速な照合はベクトル検索型RAG、流動データの照合はエー ジェント型RAG、入力のフィルタリングはガードレールモデル • 人間ーモデル間の効率的なチェック体制( human-in-the-roop) を考えるこ とも重要 ◦ ハーネスエンジニアリング 19
今後、LLMとどのように向き合うと良いか 20 • LLMは様々な業務の効率化に活用できるようになったが、どういうタスクを 解いてもらいたいのかをことばで正確にLLMに伝える力が求められている • LLMと向き合う力は、PM力とも少し近い? ◦ 役割・仕事内容・制約を正確にわかりやすく伝える ◦
仕事内容が問題ないか効率的に人手でチェックするしくみを考える ◦ ただし、図でLLMに意図を伝えることは(現状)難しい。 また、人に意図を伝える場合は表情や感情など、非合理な部分も大切 といった違いがあることにも注意 • LLMを効果的に活用して、効率的に業務を進めよう ご清聴ありがとうございました!
![エンジニアは生成AIと どのように向き合うべきか? ことばの意味という観点から 東京大学 理化学研究所 谷中 瞳 http://hitomiyanaka.strikingly.com/ [email protected] X: @verypluming Qiita](https://files.speakerdeck.com/presentations/c9a2094dd09d4a32ac496a3654c4bec4/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![LLM:テキスト生成に特化した生成AI 2023年頃からChatGPTをはじめとして、大量のテキストと深層学習を用いて 統計的にことばを学習する大規模言語モデル(LLM) が急速に発展 6 図は[Minaee+2024]から引用](https://files.speakerdeck.com/presentations/c9a2094dd09d4a32ac496a3654c4bec4/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![大規模言語モデルの根幹にあるモデル:Transformer [Vaswani+2017] 12 Encoder Attentionに基づくEncoder-Decoder (系列変換)モデル • Attention : 入力系列の重要な情報(どの単語に注目するか)](https://files.speakerdeck.com/presentations/c9a2094dd09d4a32ac496a3654c4bec4/slide_11.jpg){kind=link}
![GPT (Generative Pre-trained Transformer) [Radford+2018] 元祖・大規模なコーパスによる事前学習に基づく大規模言語モデル TransformerのDecoder部分を用い、トークン列の次に続くトークンの確率を計 算:Transformerがことばの深い再帰、局所曖昧性、長距離依存関係にある程 度頑健になったので、高性能で確率を計算できる 13](https://files.speakerdeck.com/presentations/c9a2094dd09d4a32ac496a3654c4bec4/slide_12.jpg){kind=link}
![GPT-3:現在のChatGPTの前身[Brown+2020] • OpenAIが開発したLLM • 基本構成はGPTと同じだが、事前学習に用いるデータサイズやパラメータ 数が桁違いに大きい ◦ 570GBのテキストデータで事前学習、パラメータ数は175B ◦ LLMの性能は基本的には計算資源・データサイズ・パラメータ数が多いほど良](https://files.speakerdeck.com/presentations/c9a2094dd09d4a32ac496a3654c4bec4/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
![LLMの課題をふまえたLLMの活用方法(1)プロンプト • LLMにどういうタスクをやってもらいたいのか、 単純な語・構文・構造で、曖昧さを残さずに、具体的に書こう ◦ 複数の意味を持つ語、否定、指示語の多用など、複雑な構文になると ハルシネーション(幻覚)を起こしやすい[Watson+2026] ◦ 悪い例:あのスピードについて教えて 「あの」は何を指す?「スピード」は映画?トランプのゲーム?](https://files.speakerdeck.com/presentations/c9a2094dd09d4a32ac496a3654c4bec4/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}