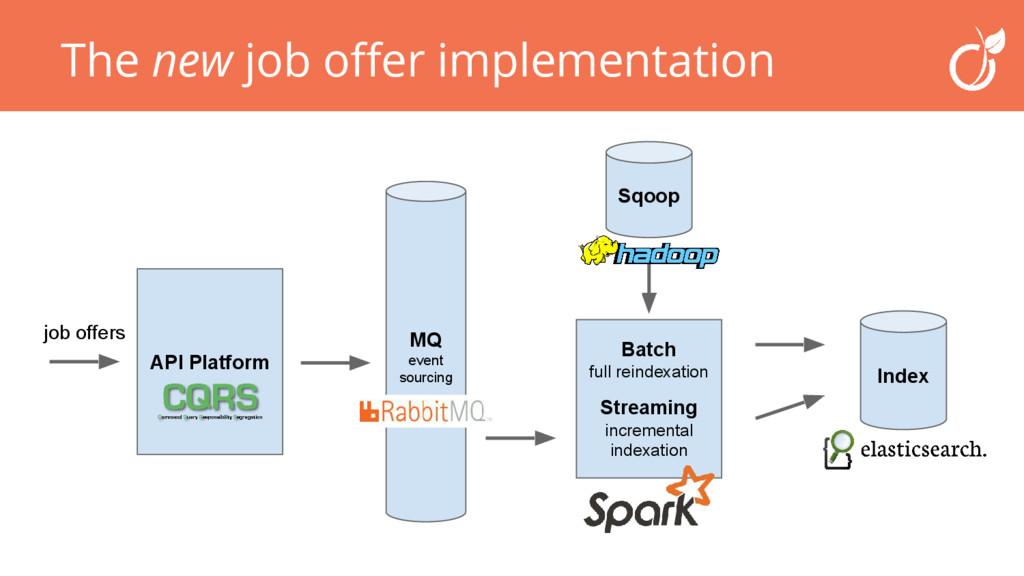
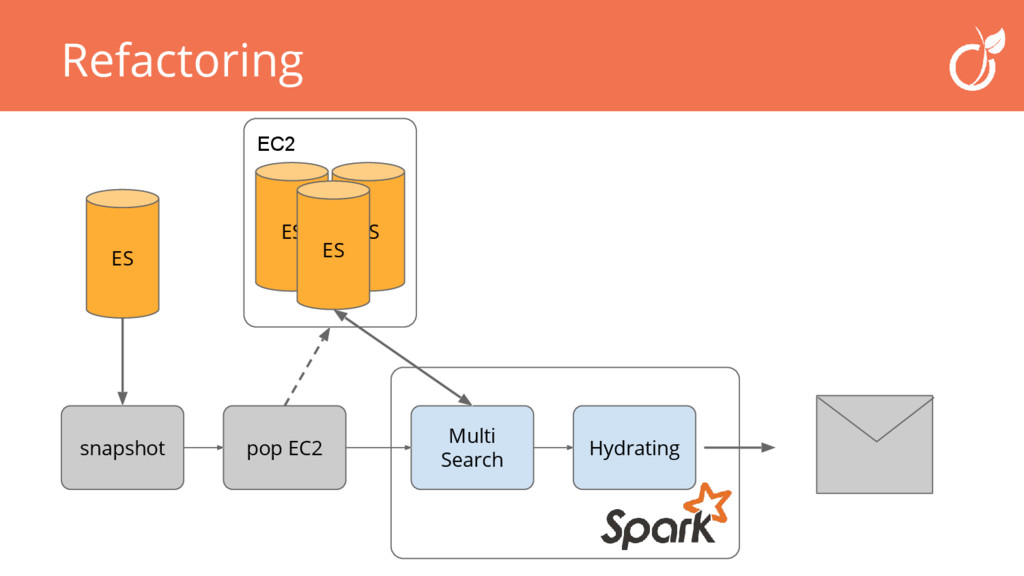
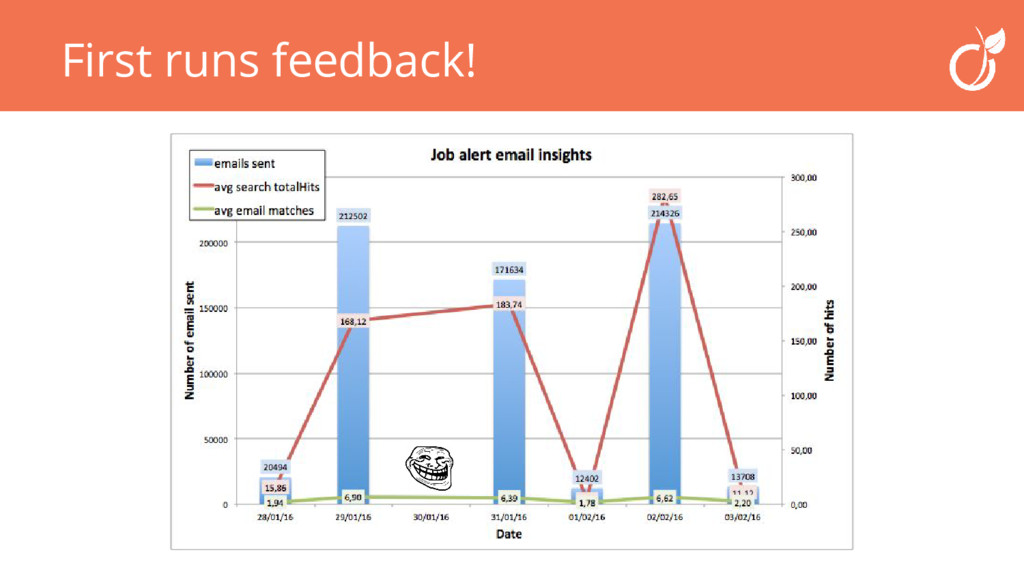
Venez découvrir comment nous avons choisi d'utiliser Spark et la percolation elasticsearch pour construire un système d'alerte d'offre d'emploi basé sur les critères de nos utilisateurs.
par Nicolas Colomer et Grégoire Nicolle, Full stack engineers @Viadeo
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}