Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
オブザーバビリティが育むシステム理解と好奇心
Search
maru
October 26, 2025
Technology
3.9k
5
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
オブザーバビリティが育むシステム理解と好奇心
Observability Conference TOKYO 2025 in
https://o11ycon.jp/
maru
October 26, 2025
More Decks by maru
See All by maru
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
5.1k
AIネイティブな開発についてのモヤモヤを吐き出す
maruloop
0
190
SLI/SLO、「完全に理解した」から「チョットデキル」へ
maruloop
5
800
チームを巻き込みエラーと向き合う技術
maruloop
5
3.5k
yuru sre 14
maruloop
1
790
Platform and teaming and communication and...
maruloop
3
1.3k
ワークロードを処理しないプラットフォームに専念する
maruloop
0
910
When Walking like SREs
maruloop
6
1.8k
チームと成長するSRE
maruloop
2
2.2k
Other Decks in Technology
See All in Technology
_NIKKEI_Tech_Talk__勉強会は熱量では続かない___17回続いた輪読会の設計術.pdf
_awache
1
100
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
12
4.2k
穢れた技術選定について
watany
19
6.1k
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
160
Multicaで30個のミニプロジェクトをAIエージェント運用して見えてきたこと
eiei114
1
620
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1k
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
610
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
24
10k
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
390
Network Firewallやっていき!
news_it_enj
0
260
[Droidcon Orlando '26] The Android Lens: Applying Mobile Forensics to AI Performance
amanda_hinchman
1
110
「休む」重要さ
smt7174
6
1.6k
Featured
See All Featured
The Limits of Empathy - UXLibs8
cassininazir
1
530
New Earth Scene 8
popppiees
3
2.4k
Google's AI Overviews - The New Search
badams
0
1.1k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.9k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
How to make the Groovebox
asonas
2
2.3k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
620
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
660
Joys of Absence: A Defence of Solitary Play
codingconduct
1
420
Transcript
© LY Corporation © LY Corporation Public オブザーバビリティが育む 開発者のシステム理解と好奇心 LINE
ヤフー株式会社 Embedded SRE @maru in Observability Conference TOKYO 2025 1 / 53
© LY Corporation © LY Corporation Public なぜこの話をするのか ツールは整備されているのに、誰も使わない。 メトリクスもログも揃っているのに、議論が深まらない。
そんな経験、ありませんか? 今日お話しするのは、 「ツールの整備」ではなく「理解と好奇心を育てる」ためのオブザーバビリティです。 2 / 53
© LY Corporation © LY Corporation Public 自己紹介 @maru 2020:
LINE に入社(LINE スタンプ/ 着せかえ/ タブのSRE ) 2022: LYP プレミアム立ち上げSRE 2023 以降: 新サービス立ち上げSRE 常にプロダクト開発のSRE として、開発チームと綿密にやりとりしつつ SRE チームのリーダーとして、マネジメントなども。 3 / 53
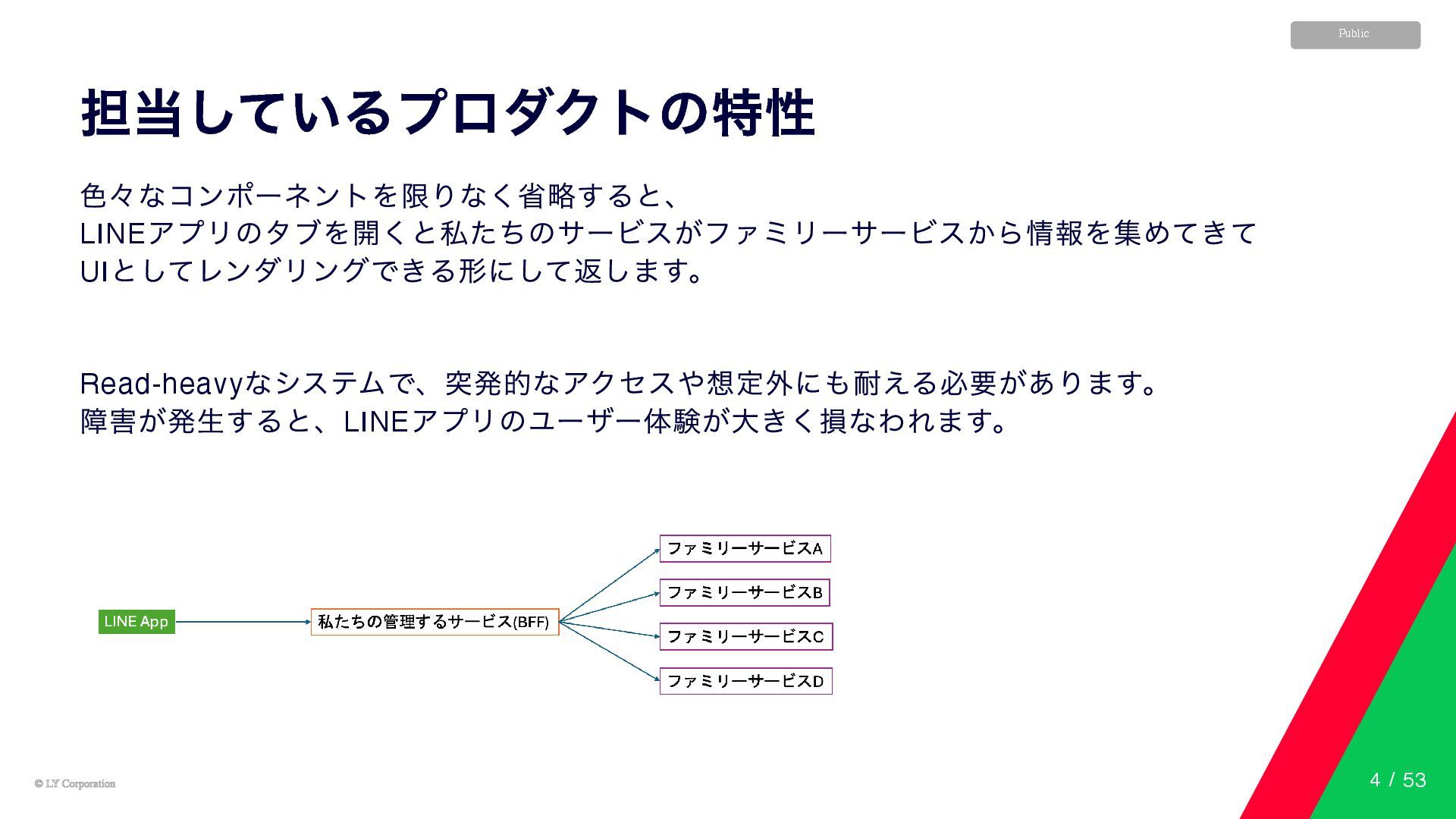
© LY Corporation © LY Corporation Public 担当しているプロダクトの特性 色々なコンポーネントを限りなく省略すると、 LINE
アプリのタブを開くと私たちのサービスがファミリーサービスから情報を集めてきて UI としてレンダリングできる形にして返します。 Read-heavy なシステムで、突発的なアクセスや想定外にも耐える必要があります。 障害が発生すると、LINE アプリのユーザー体験が大きく損なわれます。 4 / 53
© LY Corporation © LY Corporation Public オブザーバビリティツール、 本当に使われていますか? 5
/ 53
© LY Corporation © LY Corporation Public 「オブザーバビリティツール、本当に使われていますか?」 メトリクス、ログ、トレーシングを日常的にどれくらい使っていますか? 私たちはメトリクス、ログ、トレース、プロファイリング、ダンプを一通り整えました。
しかし、実際に活用されるのはリリース時や問題発生時だけでした。 6 / 53
© LY Corporation © LY Corporation Public オブザーバビリティとは? 障害を早く見つけるためのもの? 障害を早く解決するためのもの?
それとも、システムを理解するためのもの? 7 / 53
© LY Corporation © LY Corporation Public オブザーバビリティ・エンジニアリング オブザーバビリティ・エンジニアリングの説明を引用すると... モニタリングとオブザーバビリティを分けるのは、システムの状態空間
であり、さらにどのように状態空間を探索するか、どの程度の詳細さ で探索するかということです。 「状態空間」とは、システムが設計され る段階から、開発される段階、テストされる段階、( 中略) 、さまざまな 段階でシステムが示し得るすべての創発的なふるまいのことを指しま す。( 中略) オブザーバビリティがあれば、この状態空間を丹念にマッピ ングし、( 中略) システムの動作の分布をよりよく理解するために必要と される( 中略) これに対し、モニタリングは、システムの健全性を大まか に把握するためのものです。 引用: まえがき 8 / 53
© LY Corporation © LY Corporation Public オブザーバビリティとは? 障害を早く見つけるためのもの? 障害を早く解決するためのもの?
それとも、システムを理解するためのもの? 答え: システムを理解するためのもの しかし、実際に活用されていたのはリリース時や問題発生時だけでした。 9 / 53
© LY Corporation © LY Corporation Public 私たちはオブザーバビリティツールを導入して モニタリングをしていただけではないか? 10
/ 53
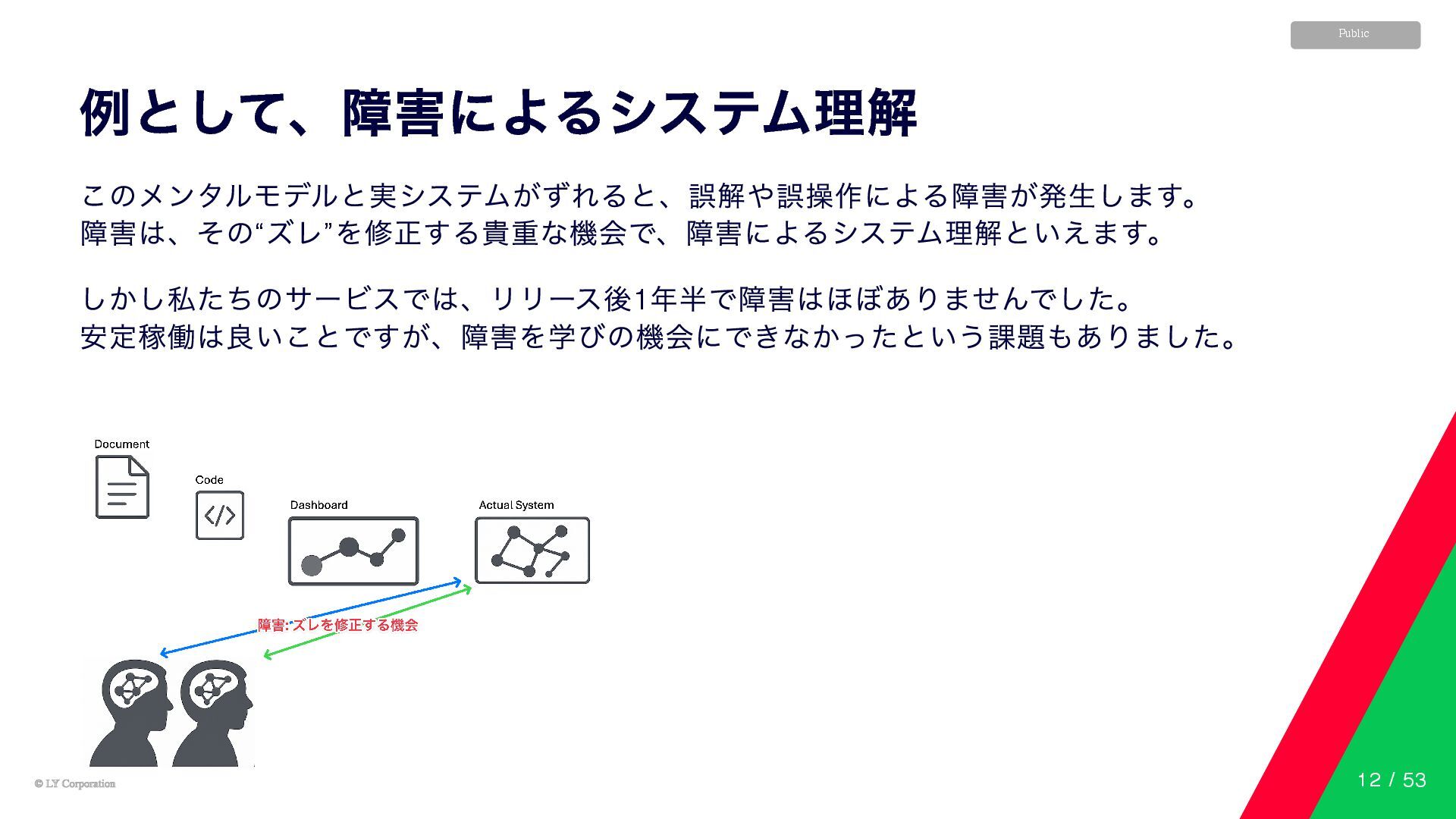
© LY Corporation © LY Corporation Public システムを理解するとは? 私たちは、実際に稼働しているシステムの中身を直接見ているわけではありません。 ドキュメントやコード、ダッシュボードを通して、その姿を頭の中に思い描いています。
これを、 システムのメンタルモデル と呼びます。 11 / 53
© LY Corporation © LY Corporation Public 例として、障害によるシステム理解 このメンタルモデルと実システムがずれると、誤解や誤操作による障害が発生します。 障害は、その“
ズレ” を修正する貴重な機会で、障害によるシステム理解といえます。 しかし私たちのサービスでは、リリース後1 年半で障害はほぼありませんでした。 安定稼働は良いことですが、障害を学びの機会にできなかったという課題もありました。 12 / 53
© LY Corporation © LY Corporation Public メンタルモデルの違い( 開発者 vs
SRE) 私はEmbedded 型のSRE として開発チームに参加し、日々一緒に開発しています。 そのなかで、次の違いに気づきました。 開発者のメンタルモデル: コードやドキュメント中心 SRE/ 運用者のメンタルモデル: ダッシュボード中心 13 / 53
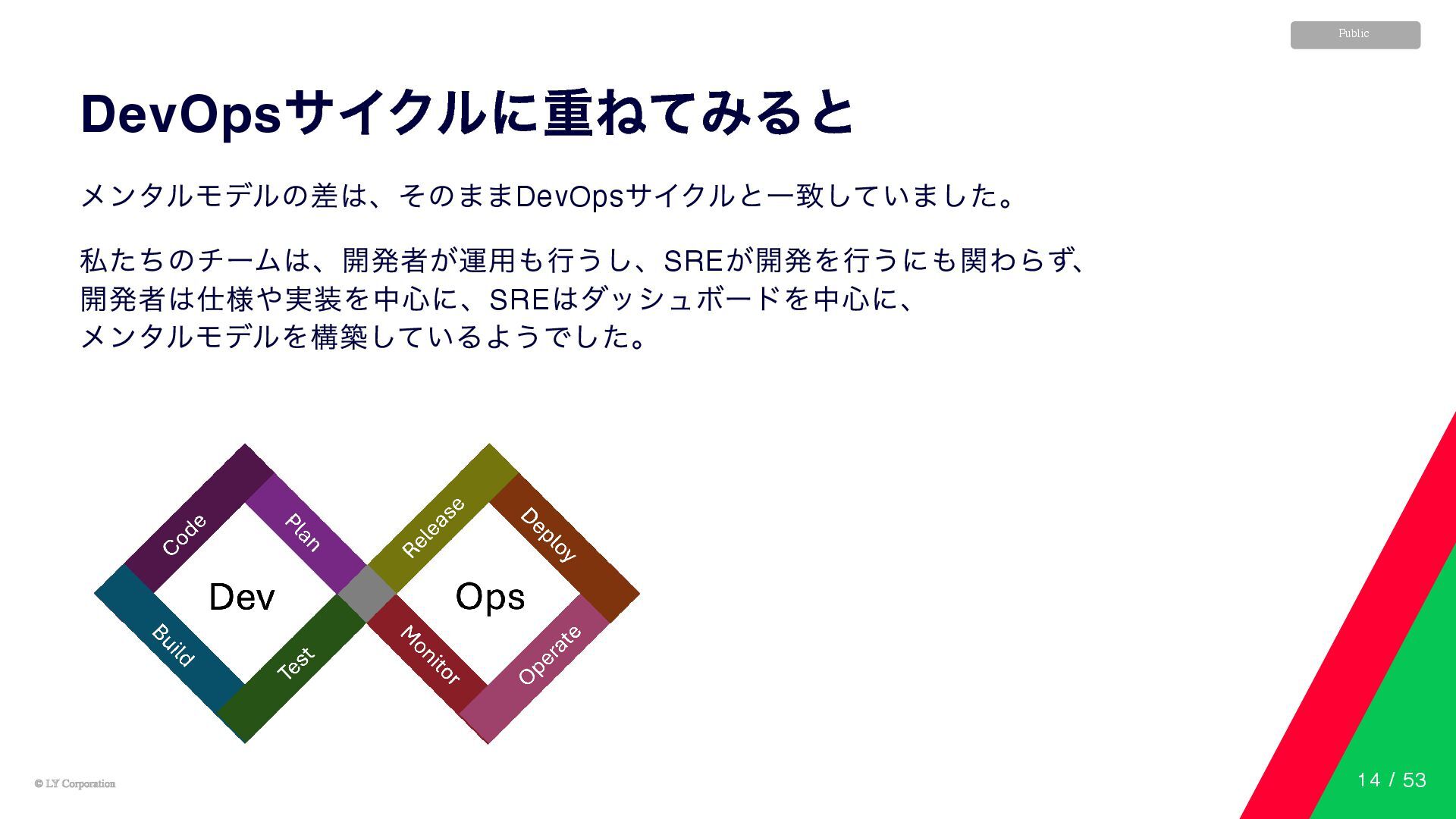
© LY Corporation © LY Corporation Public DevOps サイクルに重ねてみると メンタルモデルの差は、そのままDevOps
サイクルと一致していました。 私たちのチームは、開発者が運用も行うし、SRE が開発を行うにも関わらず、 開発者は仕様や実装を中心に、SRE はダッシュボードを中心に、 メンタルモデルを構築しているようでした。 14 / 53
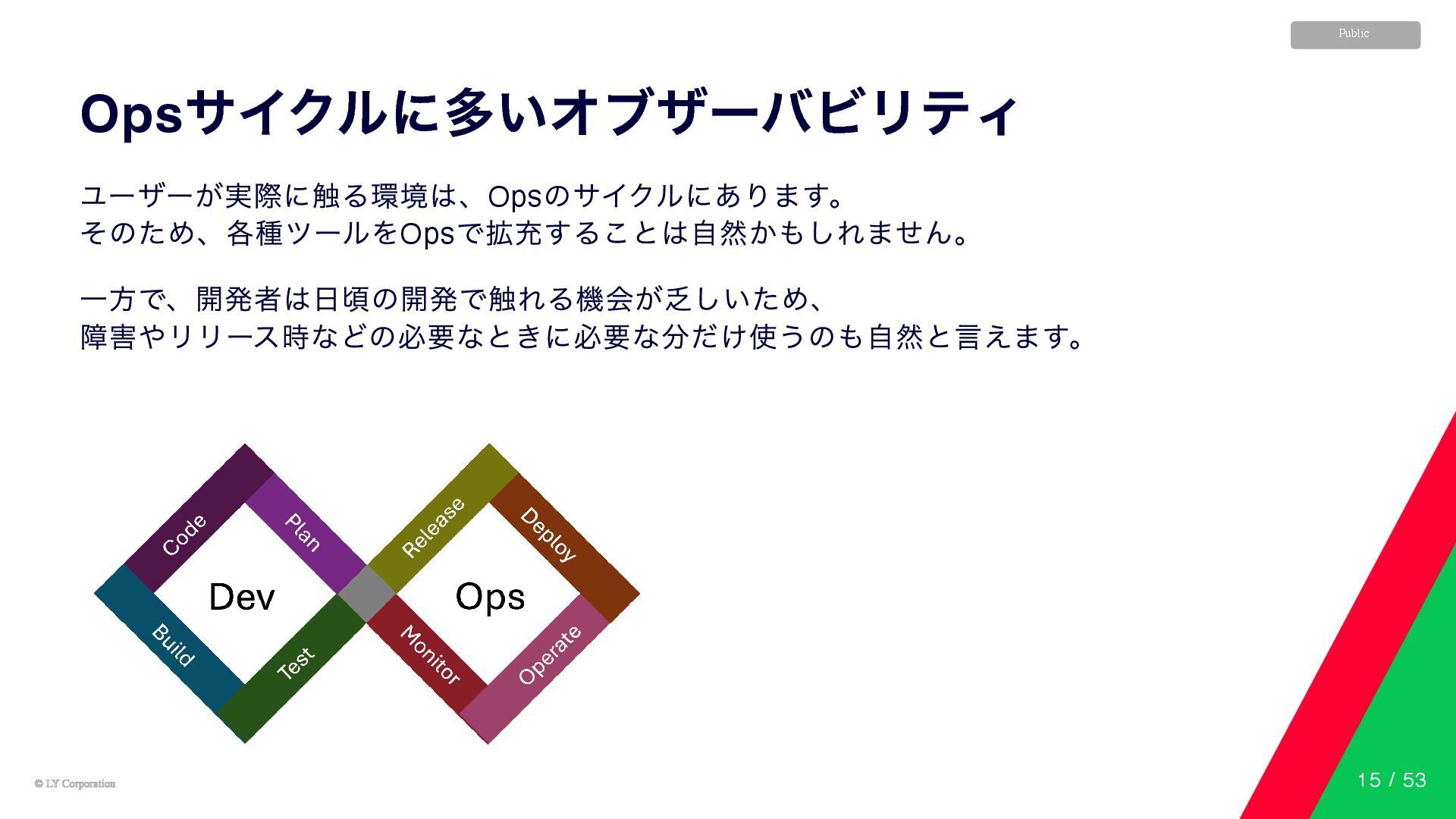
© LY Corporation © LY Corporation Public Ops サイクルに多いオブザーバビリティ ユーザーが実際に触る環境は、Ops
のサイクルにあります。 そのため、各種ツールをOps で拡充することは自然かもしれません。 一方で、開発者は日頃の開発で触れる機会が乏しいため、 障害やリリース時などの必要なときに必要な分だけ使うのも自然と言えます。 15 / 53
© LY Corporation © LY Corporation Public ここまでの整理: 私たちの課題 開発者とSRE
は、異なるメンタルモデルを持っているようです。 Ops サイクルでは、障害が実システムとメンタルモデルのズレ解消の機会になります。 障害が少ないと、そのズレの解消機会が訪れにくいです。 オブザーバビリティツールは主にOps サイクルで拡充されがちです。 その結果、開発者にとって使い慣れないツールになり、利用が避けられがちです。 オブザーバビリティツールが活用されにくく、 システム理解(メンタルモデルの構築) が難しくなっていました。 16 / 53
© LY Corporation © LY Corporation Public オブザーバビリティ・エンジニアリング オブザーバビリティ・エンジニアリングの説明を引用すると... モニタリングとオブザーバビリティを分けるのは、システムの状態空間
であり、さらにどのように状態空間を探索するか、どの程度の詳細さ で探索するかということです。 「状態空間」とは、システムが設計され る段階から、開発される段階、テストされる段階、( 中略) 、さまざまな 段階でシステムが示し得るすべての創発的なふるまいのことを指しま す。( 中略) オブザーバビリティがあれば、この状態空間を丹念にマッピ ングし、( 中略) システムの動作の分布をよりよく理解するために必要と される( 中略) これに対し、モニタリングは、システムの健全性を大まか に把握するためのものです。 引用: まえがき 17 / 53
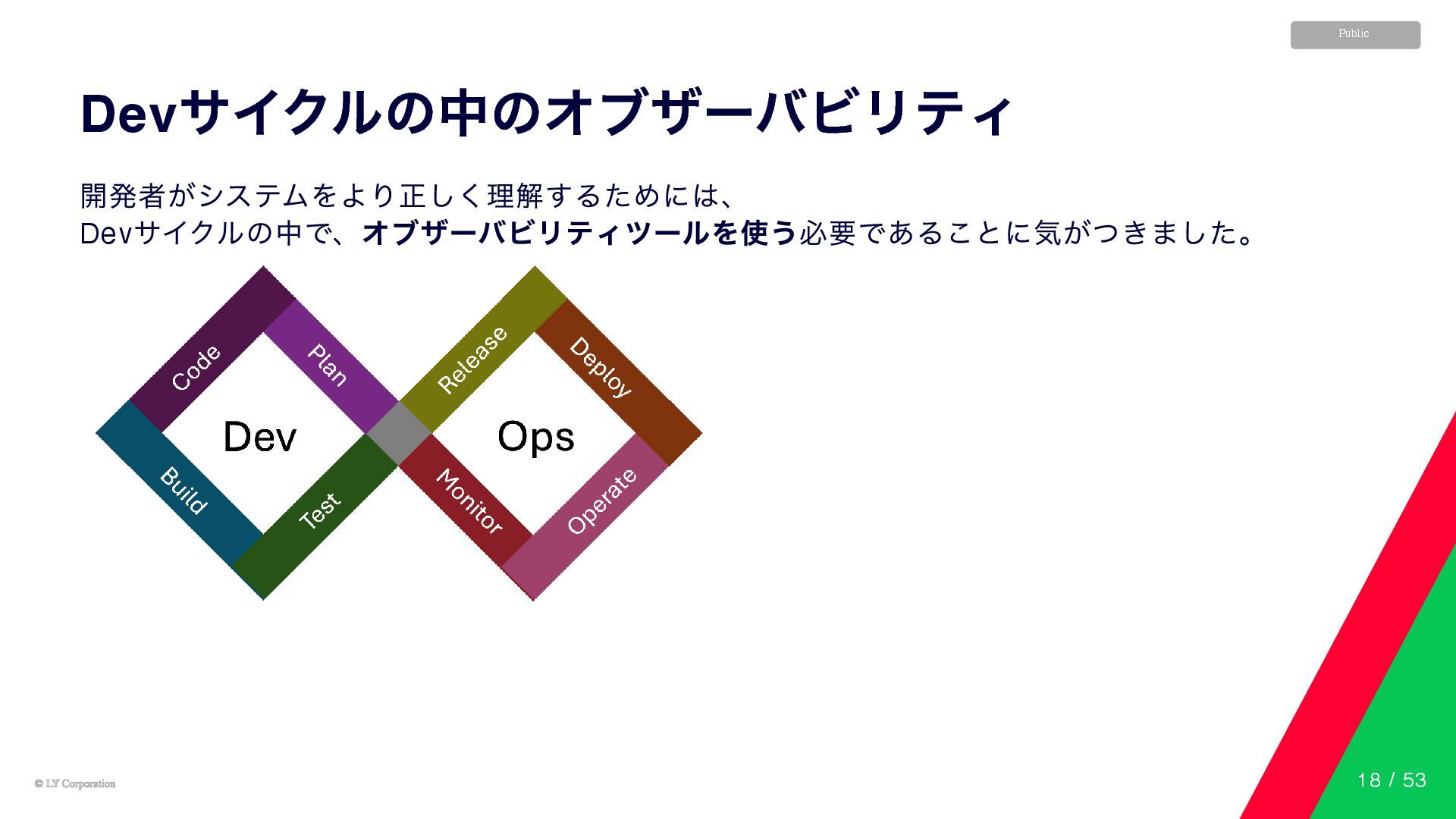
© LY Corporation © LY Corporation Public Dev サイクルの中のオブザーバビリティ 開発者がシステムをより正しく理解するためには、
Dev サイクルの中で、オブザーバビリティツールを使う必要であることに気がつきました。 18 / 53
© LY Corporation © LY Corporation Public オブザーバビリティをDev サイクルに取り込む 取り組んだこと
開発者内で自己完結する観測ループ 正確で応答速度の早いメトリクス 開発環境で問題に気づけるアラート管理 19 / 53
© LY Corporation © LY Corporation Public オブザーバビリティをDev サイクルに取り込む 取り組んだこと
開発者内で自己完結する観測ループ 正確で応答速度の早いメトリクス 開発環境で問題に気づけるアラート管理 20 / 53
© LY Corporation © LY Corporation Public 開発者内で自己完結する観測ループ 開発者がオブザーバビリティツールを活用するためには、 開発中に本番同等の観測環境と多少の負荷が必要でした。
そのため、次の2 つを整えました。 GitHub PR ごとのPreview 環境 カジュアルに実施できる 負荷試験エコシステム 21 / 53
© LY Corporation © LY Corporation Public GitHub PR ごとのPreview
環境の整備 開発者がコードをマージせずに動作を確認できる環境を自動構築しました。 (Draft 含む)PR 作成時に Kubernetes 上に namespace を自動作成 自動でアプリケーションをビルド・デプロイ LB/DNS/ メトリクス/ ログ収集まで全自動 PR クローズ時に環境を削除 → 本番と同じ観測データを、開発中にも取得できるようになりました。 22 / 53
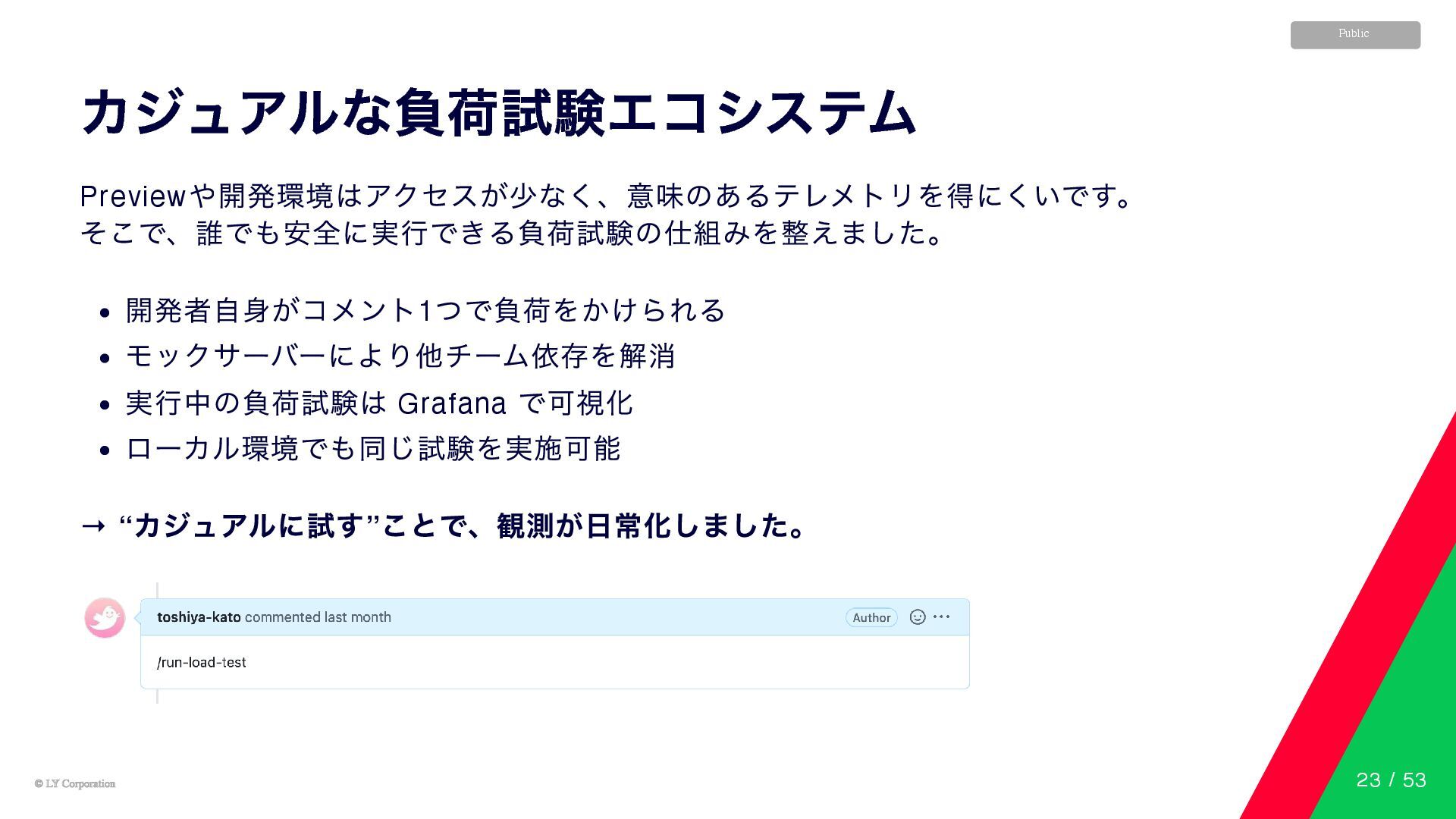
© LY Corporation © LY Corporation Public カジュアルな負荷試験エコシステム Preview や開発環境はアクセスが少なく、意味のあるテレメトリを得にくいです。
そこで、誰でも安全に実行できる負荷試験の仕組みを整えました。 開発者自身がコメント1 つで負荷をかけられる モックサーバーにより他チーム依存を解消 実行中の負荷試験は Grafana で可視化 ローカル環境でも同じ試験を実施可能 → “ カジュアルに試す” ことで、観測が日常化しました。 23 / 53
© LY Corporation © LY Corporation Public 他の課題への対応(概要) このほかにも、負荷試験を気軽にできるように複数の工夫を実施しました。 負荷試験実施時のレビューを最小限に
負荷試験シナリオとパラメータを分離し再利用性を向上 RPS やDuration の変更はパラメータファイルの編集のみ 過去と同一の負荷試験であれば、ヒストリの追加のみで実施可能 負荷生成時のコミュニケーションが不要な環境分離を実現 ローカル・Preview での並行実行、開発/ ステージングはGrafana で可視化 誰が今負荷試験をしてるか、気にする必要がなくなった → 詳細は割愛しますが、どれも「安全に・簡単に試せること」 を意識しています。 24 / 53
© LY Corporation © LY Corporation Public 開発者が負荷試験を「遊べる」ように Preview 環境と負荷試験の整備により、
「壊す・測る・直す」が安全にできるようになりました。 それでも、ツールを“ 最初に使う” ハードルは残ります。 そこで私たちは、文化として広げる工夫をしました。 25 / 53
© LY Corporation © LY Corporation Public ワークショップ形式のチューニングコンテスト パフォーマンス改善・リファクタリングも自由 負荷試験結果を共有し、議論できる場に
初心者もオブザーバビリティツールに触れるきっかけに → “ 学びの場” としてのオブザーバビリティツールに変化。 26 / 53
© LY Corporation © LY Corporation Public 草の根的な認知獲得の取り組み Slack で小さなボトルネック共有をカジュアルに繰り返しました。
「誰か挑戦してみない?」のノリでスクリーンショットを投稿。 このチャレンジの繰り返しで、API レイテンシーが 230ms → 160ms に改善しました。 27 / 53
© LY Corporation © LY Corporation Public Preview 環境と負荷試験の効果( ある1
チームの実績) 開発・ステージング環境での負荷生成回数: 150 回以上/ 月 Preview 環境での負荷生成回数: 300 回以上/ 月 定期的な自動負荷も稼働中 → ユニットテストのように、負荷試験を回す文化が定着しました。 28 / 53
© LY Corporation © LY Corporation Public オブザーバビリティをDev サイクルに取り込む 取り組んだこと
開発者内で自己完結する観測ループ 正確で応答速度の早いメトリクス 開発環境で問題に気づけるアラート管理 29 / 53
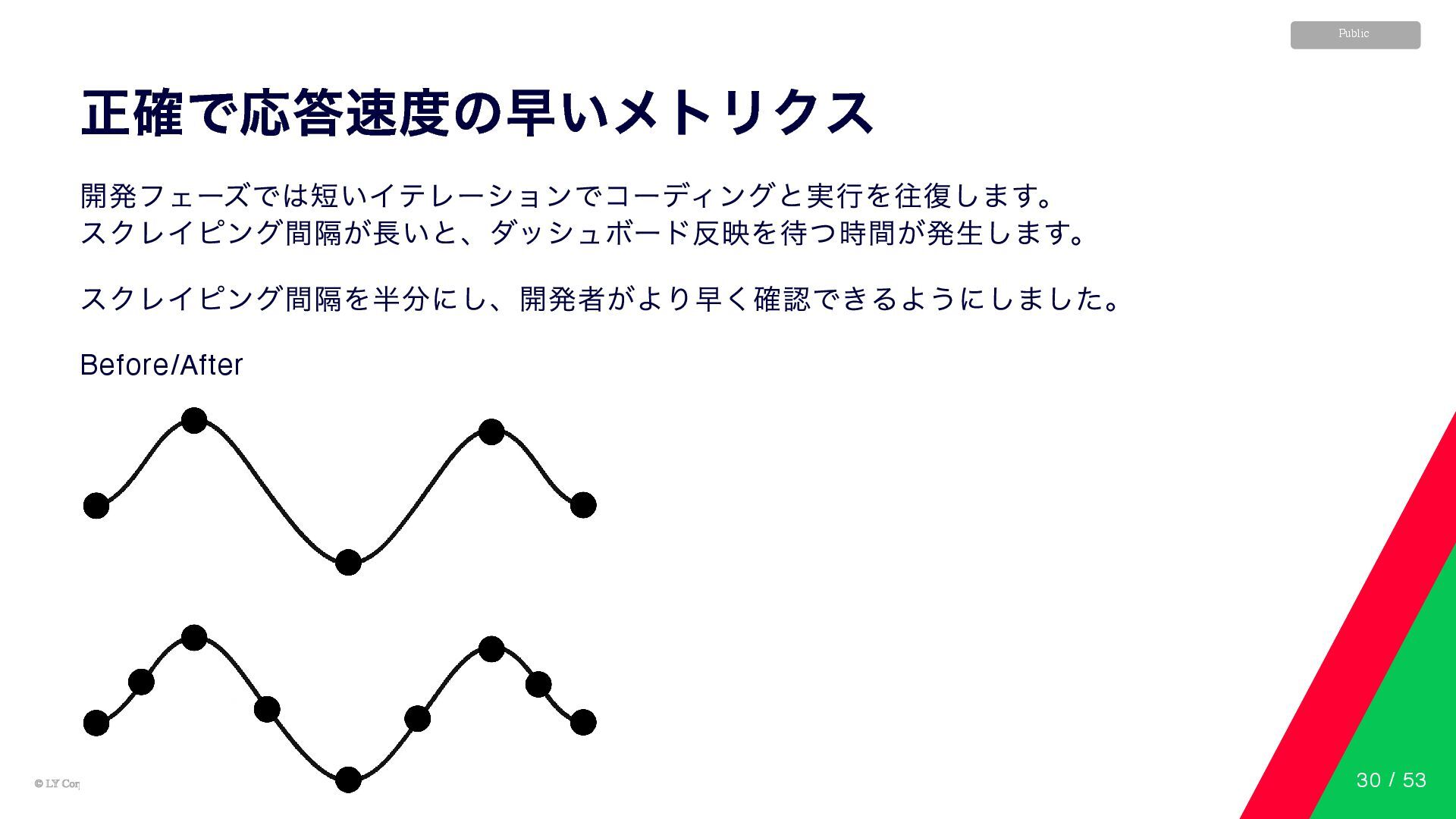
© LY Corporation © LY Corporation Public 正確で応答速度の早いメトリクス 開発フェーズでは短いイテレーションでコーディングと実行を往復します。 スクレイピング間隔が長いと、ダッシュボード反映を待つ時間が発生します。
スクレイピング間隔を半分にし、開発者がより早く確認できるようにしました。 Before/After 30 / 53
© LY Corporation © LY Corporation Public 自動ロールバックにおけるスクレイピング間隔短縮の副作用 デプロイ時に、エラー率やレイテンシーがしきい値を超えると、 デプロイツールが異常を検知して対応を行います。
明らかに異常と判断できる場合は、自動でロールバック 人による判断が必要な場合は、デプロイを一時停止し、Slack に通知 この仕組みは、スクレイピング間隔が短いほど異常検知の反応も早くなるため、 間隔の短縮によって障害対応のスピードも向上しました。 31 / 53
© LY Corporation © LY Corporation Public レイテンシーをシステム全体で正確に集計 従来はコストや応答速度の都合で、プロセスごとの分位数(99%ile など)を集計していました。
しかし、システム全体のレイテンシーとして、分位数の平均や最大は正しくありません。 そのため、今まではあくまで参考値として利用していました。 32 / 53
© LY Corporation © LY Corporation Public ヒストグラム・バケットの活用 では、単純にヒストグラム バケットで集計すればいいのかというと、実用上問題があります。
等間隔なヒストグラムでメトリクスを出力する場合、 集計してダッシュボードに表示する応答速度が犠牲になります。 私たちの場合、15 分のダッシュボードは表示できるが、30 分は表示できない状態になりました。 * 時系列データが多くなりすぎるため 33 / 53
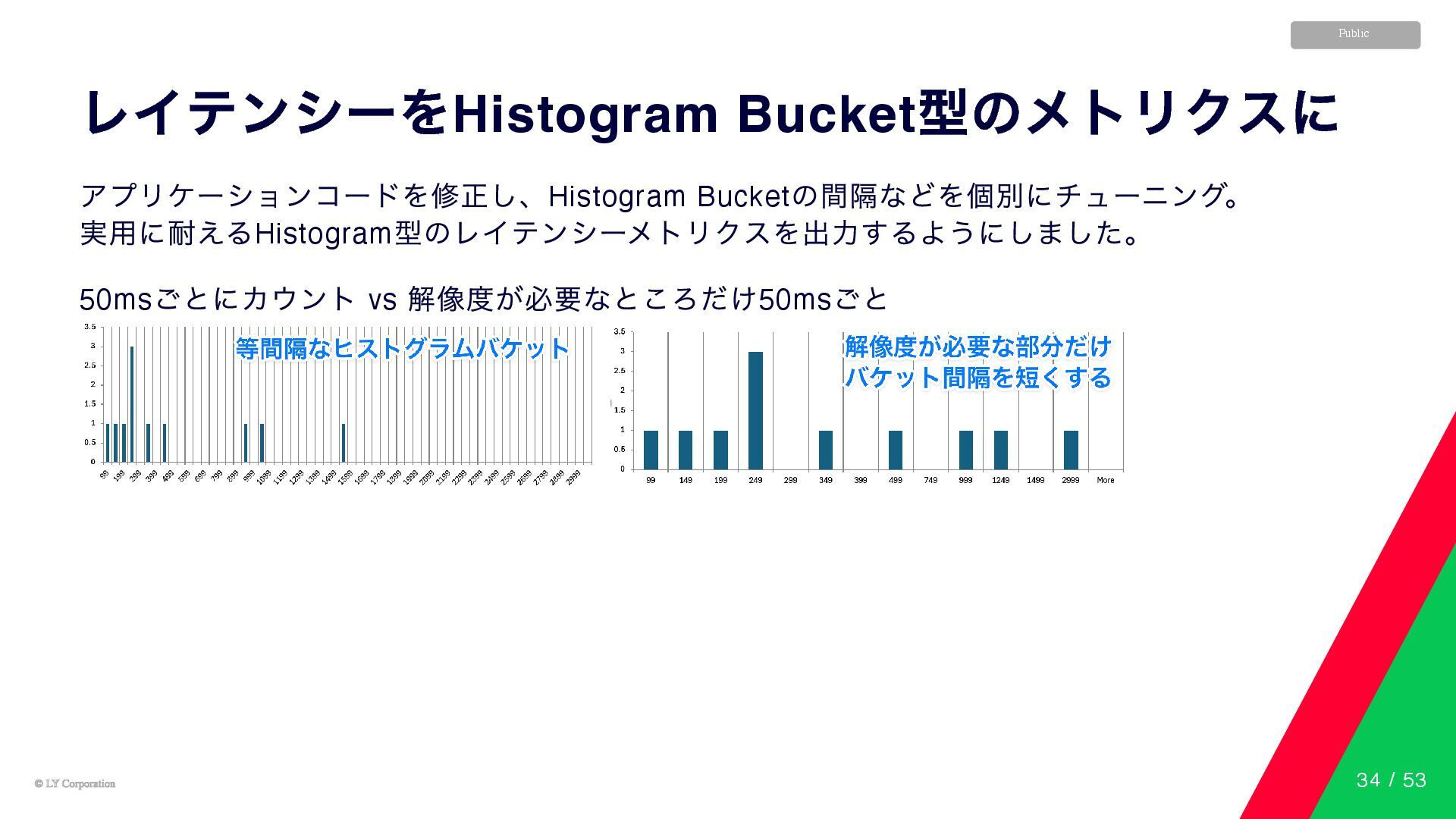
© LY Corporation © LY Corporation Public レイテンシーをHistogram Bucket 型のメトリクスに
アプリケーションコードを修正し、Histogram Bucket の間隔などを個別にチューニング。 実用に耐えるHistogram 型のレイテンシーメトリクスを出力するようにしました。 50ms ごとにカウント vs 解像度が必要なところだけ50ms ごと 34 / 53
© LY Corporation © LY Corporation Public オブザーバビリティをDev サイクルに取り込む 取り組んだこと
開発者内で自己完結する観測ループ 正確で応答速度の早いメトリクス 開発環境で問題に気づけるアラート管理 35 / 53
© LY Corporation © LY Corporation Public 開発環境で気づけるアラート管理 負荷試験により、開発環境でも定期的な負荷をかけられるようになりました。 Preview
環境により、マージ前にもメトリクスを収集・集計できます。 これにより、開発フェーズでも意味のあるアラートを設定でき、 負荷がないと気づけない問題(例: レイテンシーの悪化)にも早く気づけるようになりました。 しかし、アラートルールを開発環境などにももれなく設定することは 従来の人手によるアラート設定では難しかったです。 36 / 53
© LY Corporation © LY Corporation Public Alert rules as
Code の整備 目的 アラートを コード として一元管理し、環境差異・属人運用を解消 しきい値やラベルのみが異なるアラートを全環境に必ず設定 変更は PR レビュー と CI 検証 を通す 仕組み Terraform でアラート定義 内製の監視プラットフォーム用にTerraform Provider も開発 CI で lint / policy / 生成物チェック cloudflare/pint でPrometheus alert rule lint OPA(Policy as Code) でRunbook 紐付け等を強制 生成物(Alert YAML / しきい値)をPR 上でプレビュー 37 / 53
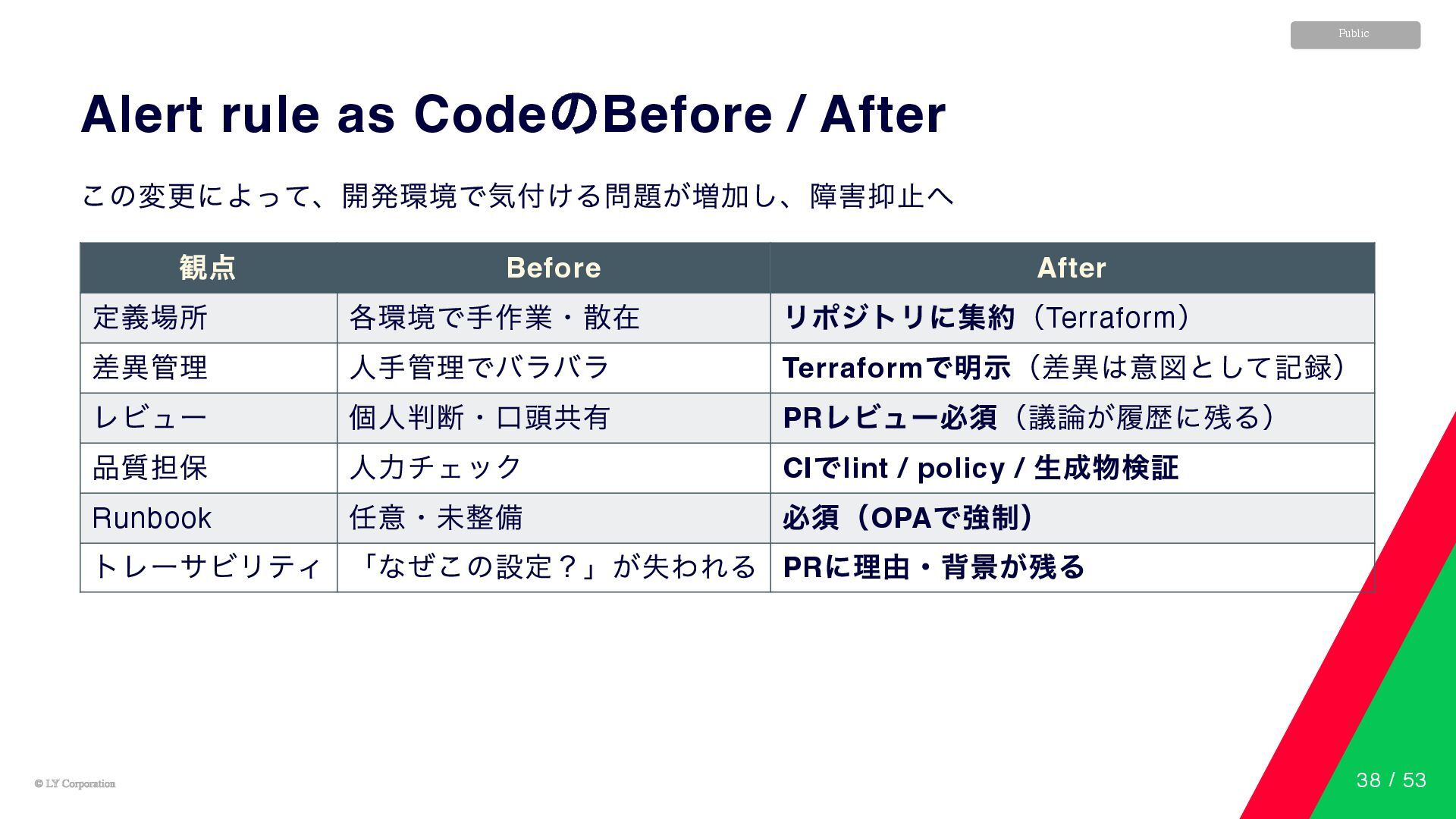
© LY Corporation © LY Corporation Public Alert rule as
Code のBefore / After この変更によって、開発環境で気付ける問題が増加し、障害抑止へ 観点 Before After 定義場所 各環境で手作業・散在 リポジトリに集約(Terraform ) 差異管理 人手管理でバラバラ Terraform で明示(差異は意図として記録) レビュー 個人判断・口頭共有 PR レビュー必須(議論が履歴に残る) 品質担保 人力チェック CI でlint / policy / 生成物検証 Runbook 任意・未整備 必須(OPA で強制) トレーサビリティ 「なぜこの設定?」が失われる PR に理由・背景が残る 38 / 53
© LY Corporation © LY Corporation Public Ops サイクルへの拡張 ここまでの改善でDev
サイクルにおけるオブザーバビリティ導入を達成できました。 次のステップは、運用全体で観測を当たり前にすることです。 Dev サイクルで観測が日常化したように、Ops でも観測を常時点灯させる状態を目指しました。 39 / 53
© LY Corporation © LY Corporation Public よりユーザー体験に近いメトリクスの収集 取り組んだこと 目的に基づくダッシュボードの整備
ユーザーのキャッシュ利用状況の収集 40 / 53
© LY Corporation © LY Corporation Public よりユーザー体験に近いメトリクスの収集 取り組んだこと 目的に基づくダッシュボードの整備
ユーザーのキャッシュ利用状況の収集 41 / 53
© LY Corporation © LY Corporation Public 目的に基づくダッシュボードの整備 従来のダッシュボードは、監視対象ごとにダッシュボードを用意していました。 アプリケーションのダッシュボード
DB のダッシュボード インフラのダッシュボード etc しかし、このダッシュボードだけでは、仮説を持って見なければ問題を発見しにくかったのです。 「XXX が原因の可能性があるから、このダッシュボードをみよう... 」 42 / 53
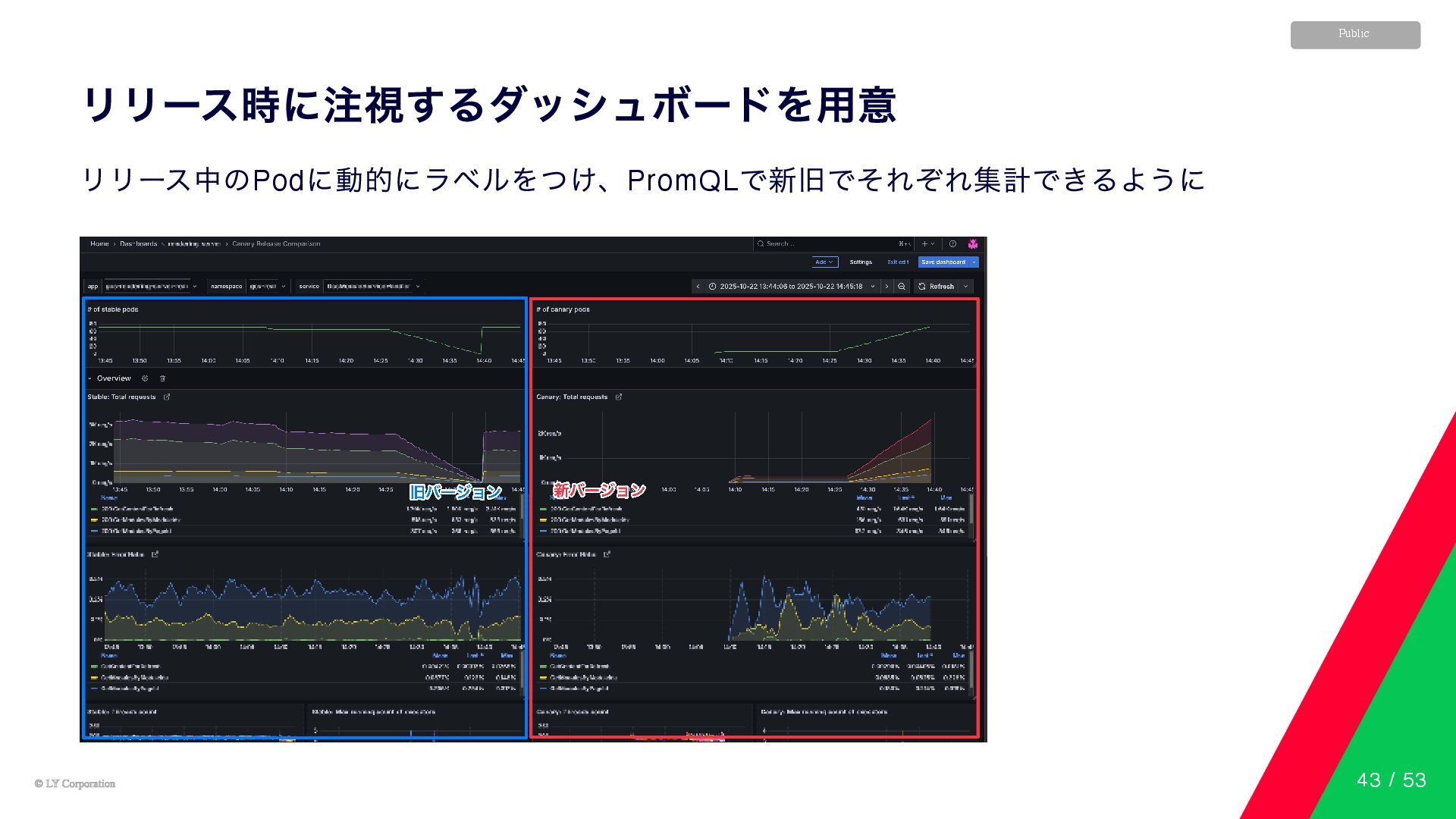
© LY Corporation © LY Corporation Public リリース時に注視するダッシュボードを用意 リリース中のPod に動的にラベルをつけ、PromQL
で新旧でそれぞれ集計できるように 43 / 53
© LY Corporation © LY Corporation Public よりユーザー体験に近いメトリクスの収集 取り組んだこと 明確な目的を持ったダッシュボードの準備
ユーザーのキャッシュ利用状況の収集 44 / 53
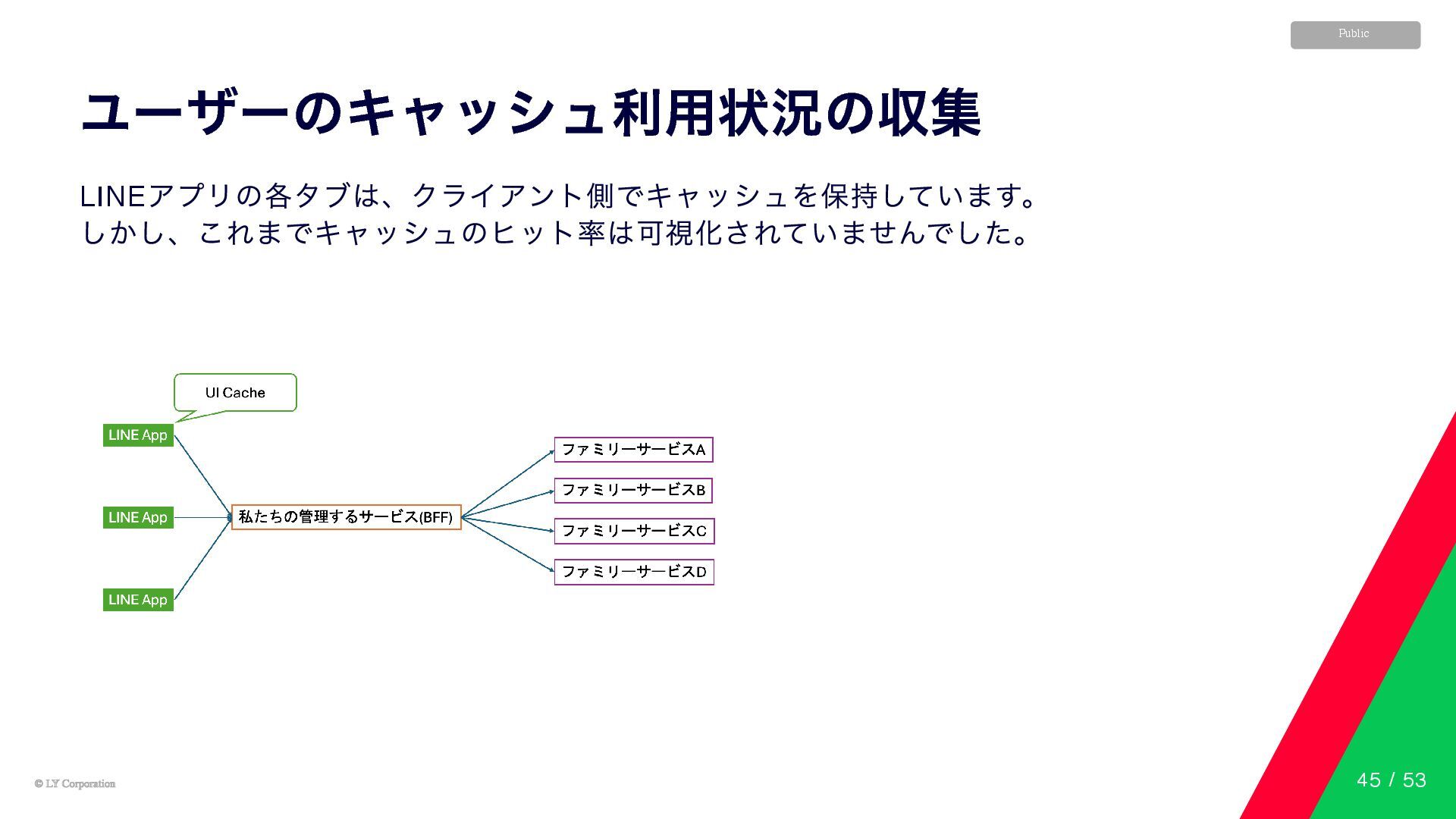
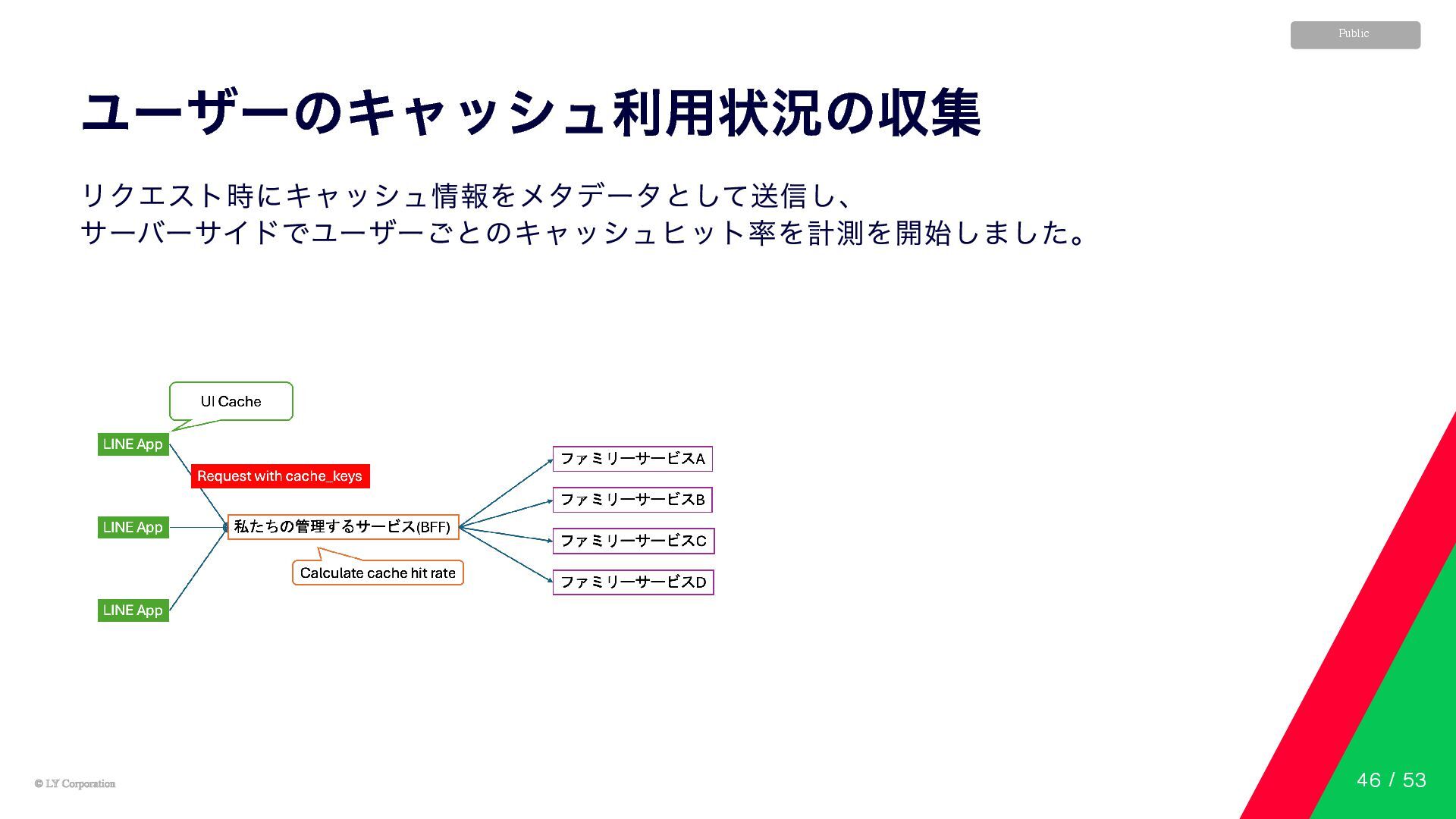
© LY Corporation © LY Corporation Public ユーザーのキャッシュ利用状況の収集 LINE アプリの各タブは、クライアント側でキャッシュを保持しています。
しかし、これまでキャッシュのヒット率は可視化されていませんでした。 45 / 53
© LY Corporation © LY Corporation Public ユーザーのキャッシュ利用状況の収集 リクエスト時にキャッシュ情報をメタデータとして送信し、 サーバーサイドでユーザーごとのキャッシュヒット率を計測を開始しました。
46 / 53
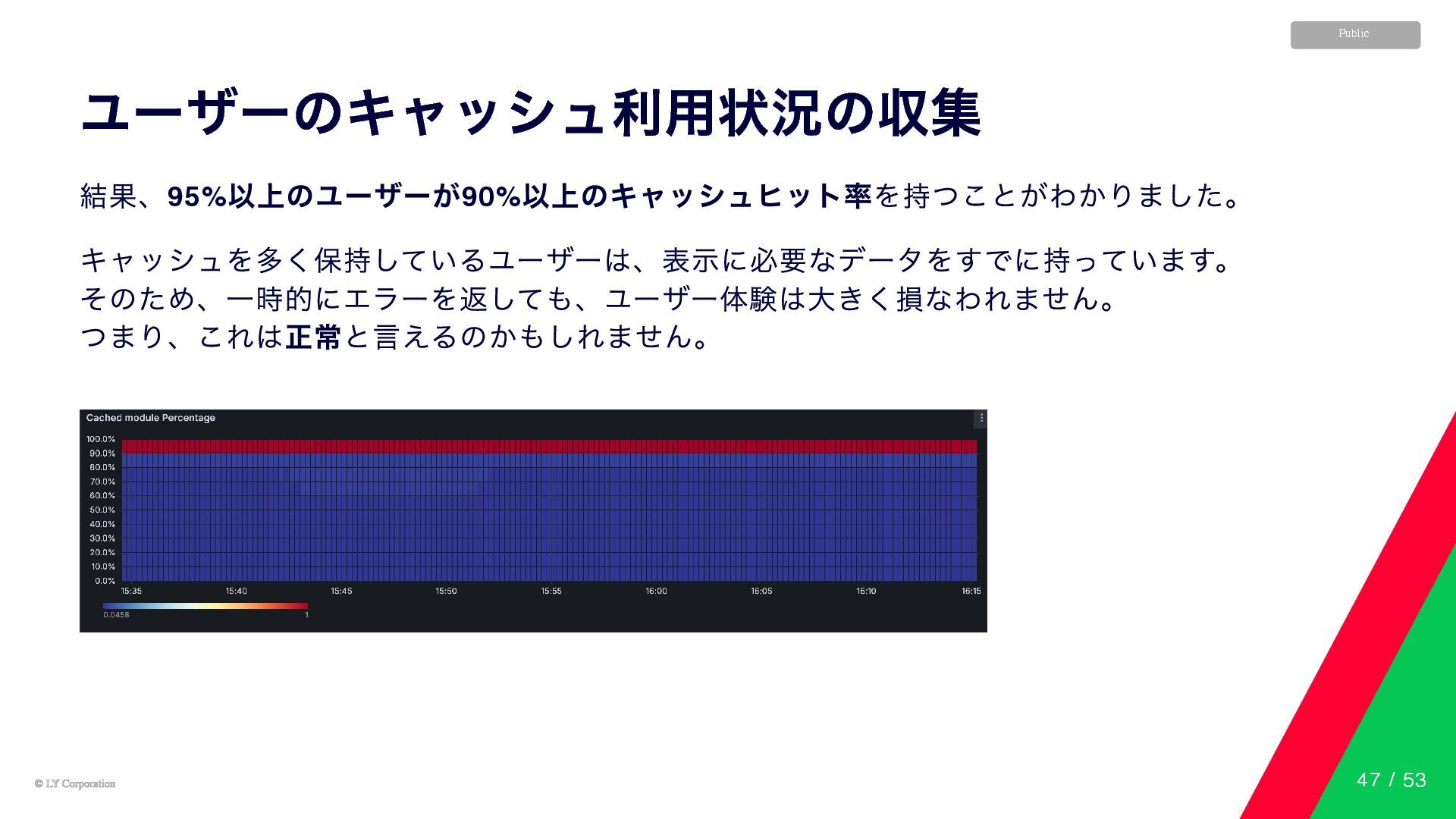
© LY Corporation © LY Corporation Public ユーザーのキャッシュ利用状況の収集 結果、95% 以上のユーザーが90%
以上のキャッシュヒット率を持つことがわかりました。 キャッシュを多く保持しているユーザーは、表示に必要なデータをすでに持っています。 そのため、一時的にエラーを返しても、ユーザー体験は大きく損なわれません。 つまり、これは正常と言えるのかもしれません。 47 / 53
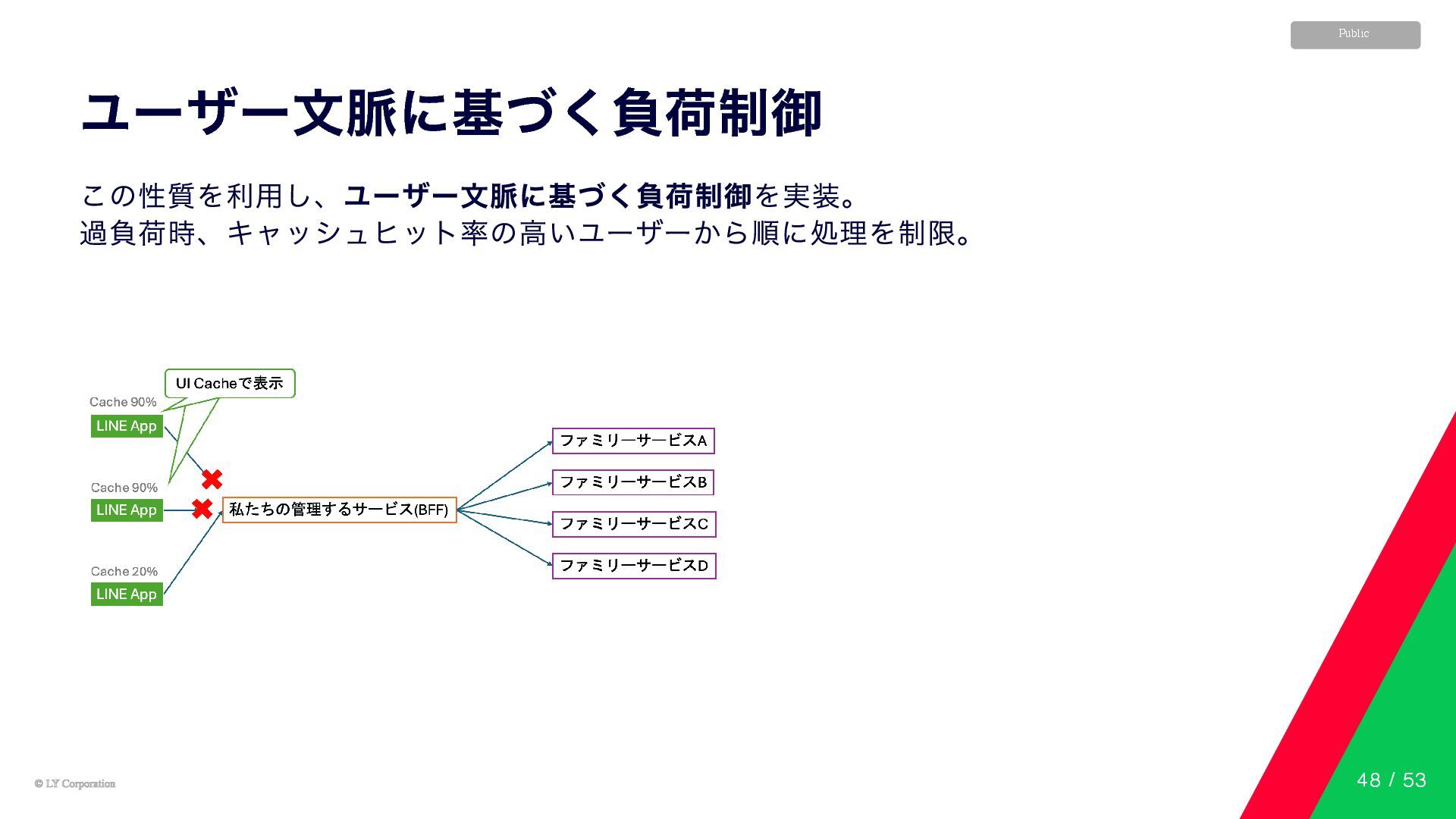
© LY Corporation © LY Corporation Public ユーザー文脈に基づく負荷制御 この性質を利用し、ユーザー文脈に基づく負荷制御を実装。 過負荷時、キャッシュヒット率の高いユーザーから順に処理を制限。
48 / 53
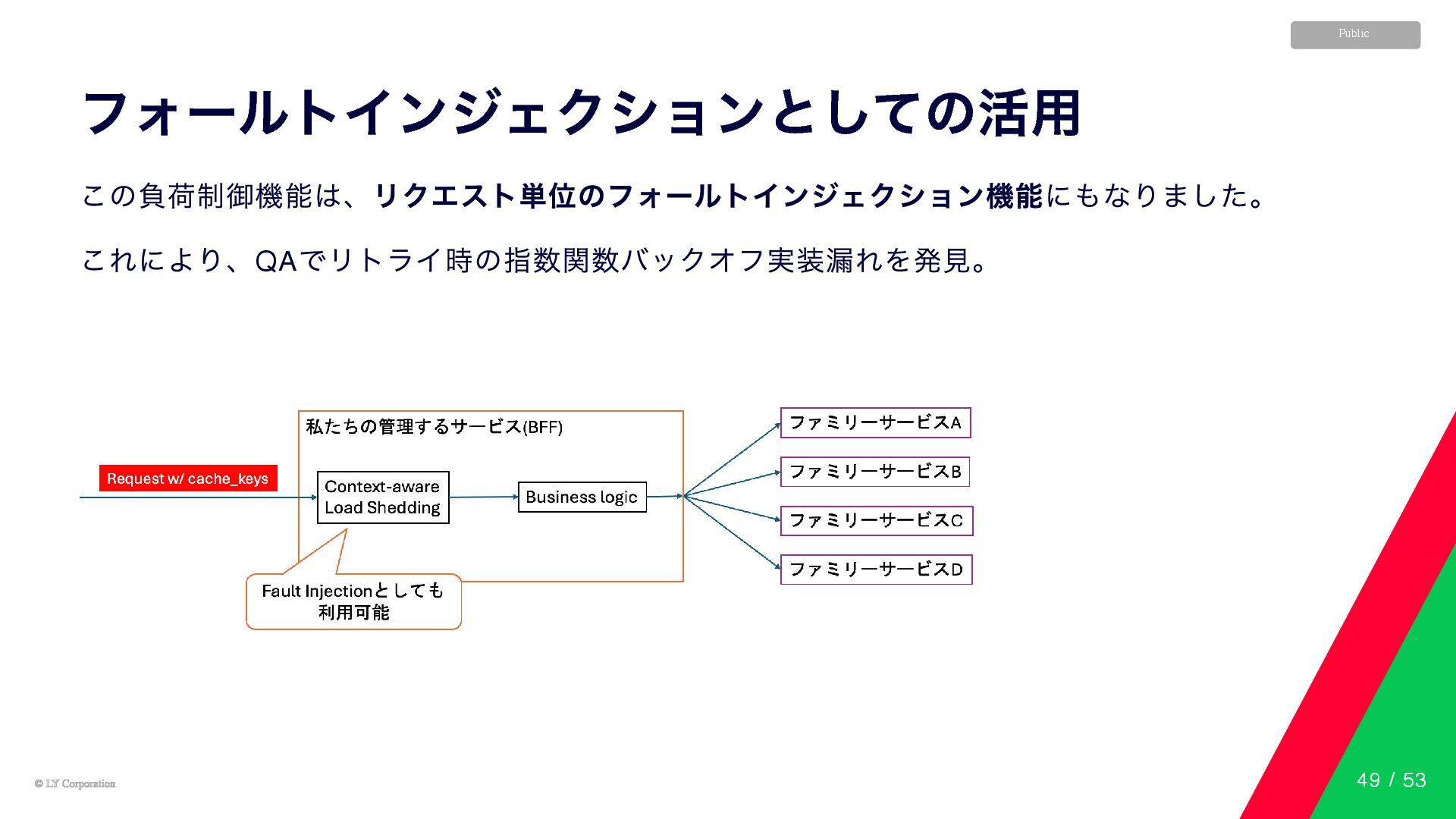
© LY Corporation © LY Corporation Public フォールトインジェクションとしての活用 この負荷制御機能は、リクエスト単位のフォールトインジェクション機能にもなりました。 これにより、QA
でリトライ時の指数関数バックオフ実装漏れを発見。 49 / 53
© LY Corporation © LY Corporation Public “ 正常” とは何か?
この負荷制御機能を導入する際に、チーム内で Graceful Degradation PJ を立ち上げました。 実際のユーザー体験というのは、正常と異常の2 値ではありません。 例えば、下記のように正常と異常はグラデーションになっています。 アプリが全く使えない 一部のコンテンツが更新されない アプリキルすると使えるけど、ときどき不安定になる 使えるけど、遅い 快適に使える このグラデーションを意図して設計するPJ を立ち上げ、その中で開発者と議論を深めています。 50 / 53
© LY Corporation © LY Corporation Public “ 正常” とは何か?
そのPJ では、過去にこのような議論や問いがありました。 エラーがあってもキャッシュで表示できるなら正常? 認証エラーはクライアントが自動リトライするから、ユーザーは気づかないのでは? SLO では、認証エラーは" 成功" にカウントしていい? リトライが1 回なら正常? 3 回なら? 期限切れの古いキャッシュは、どれくらい古いと異常? コンテンツの種類によるよね? 「何を見れば、正常と言えるのか?」 オブザーバビリティが、私たちに“ 考える問い” を与えてくれました。 “ “ 51 / 53
© LY Corporation © LY Corporation Public まとめ Dev サイクルでオブザーバビリティが活用できる環境の整備
ユーザー体験に近い観測の整備と、問いと議論 これらを通して、チームに少しずつオブザーバビリティの文化が浸透してきています。 チームの議論は増え、また、答えが明確でないものも増えましたが おそらく良い方向に向かってると思います。 リリースや障害対応のためのツールから システムの理解と好奇心を育てる文化へ “ “ 52 / 53
© LY Corporation © LY Corporation Public 会話を続けよう。 システムのことを、もっと語り合おう。 そして、観測を通じて学び続けよう。
53 / 53
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}