The slides I used at the KNIME Italy Meetup in Milan ("KNIME Italy MeetUp goes Big Data on Apache Spark") .
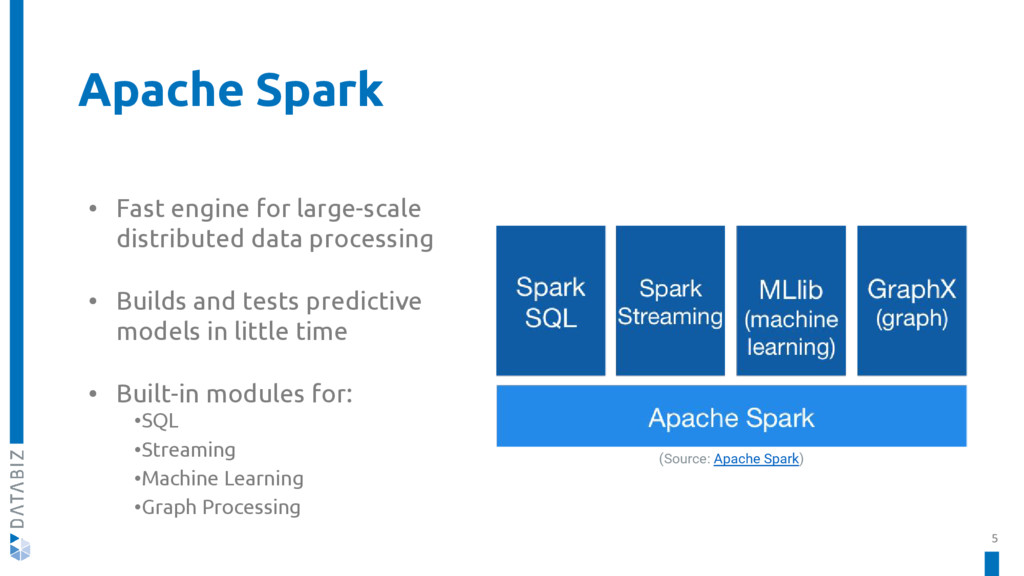
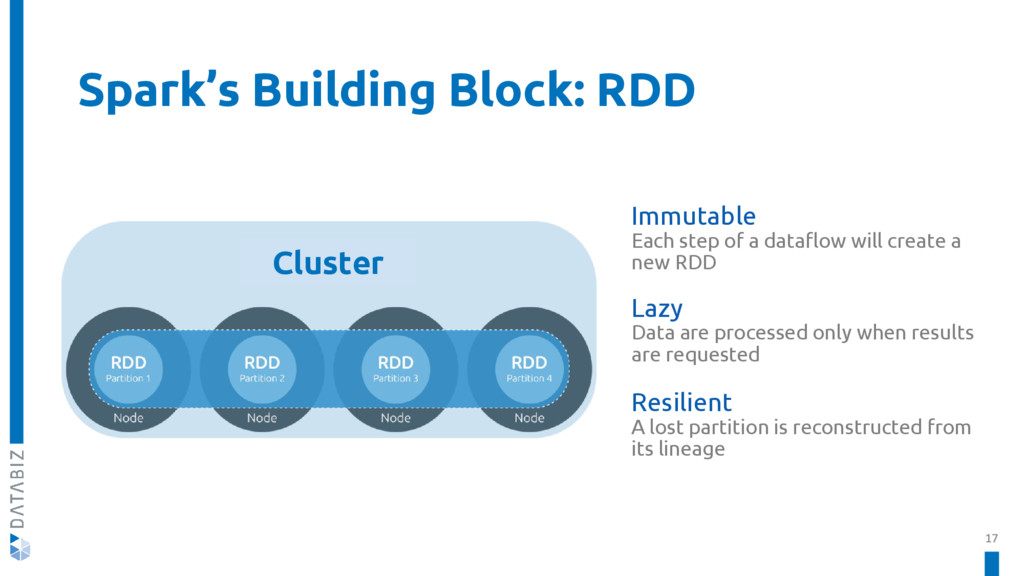
Apache Spark is a fast and general engine for large-scale data processing. It allows you to build and test predictive models in little time, and comes with built-in modules for: SQL, Streaming, Machine Learning, Graph Processing.
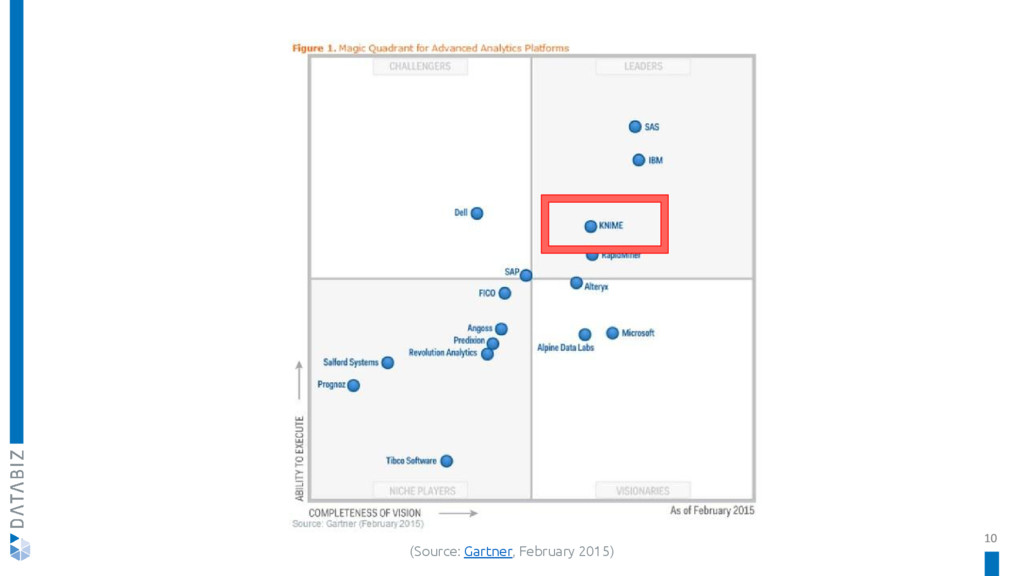
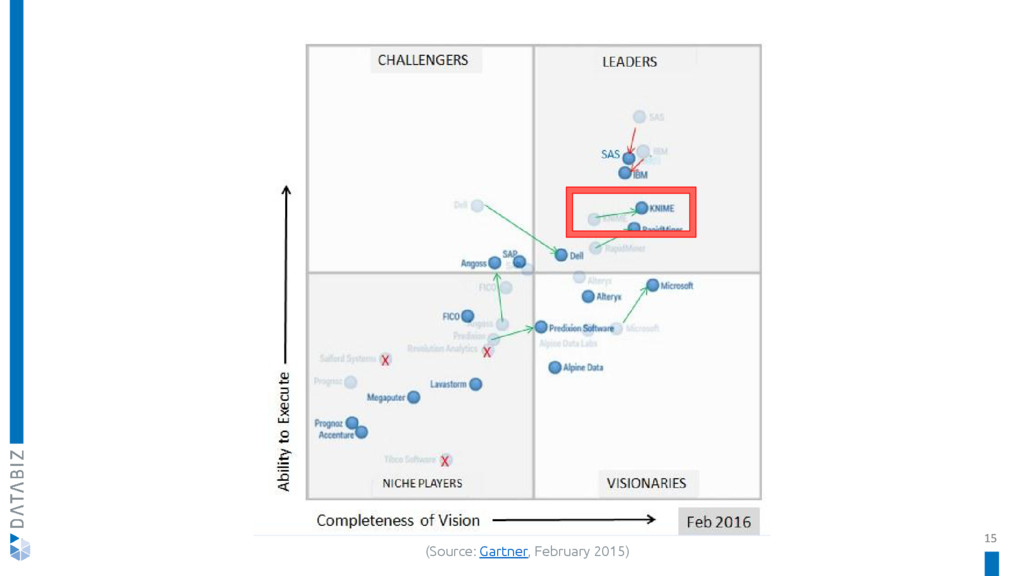
KNIME, the Konstanz Information Miner, is an open source data analytics, reporting and integration platform, integrating various components for machine learning and data mining through its modular data pipelining concept. Its graphical user interface allows assembly of nodes for data preprocessing, modeling, data analysis and visualization.
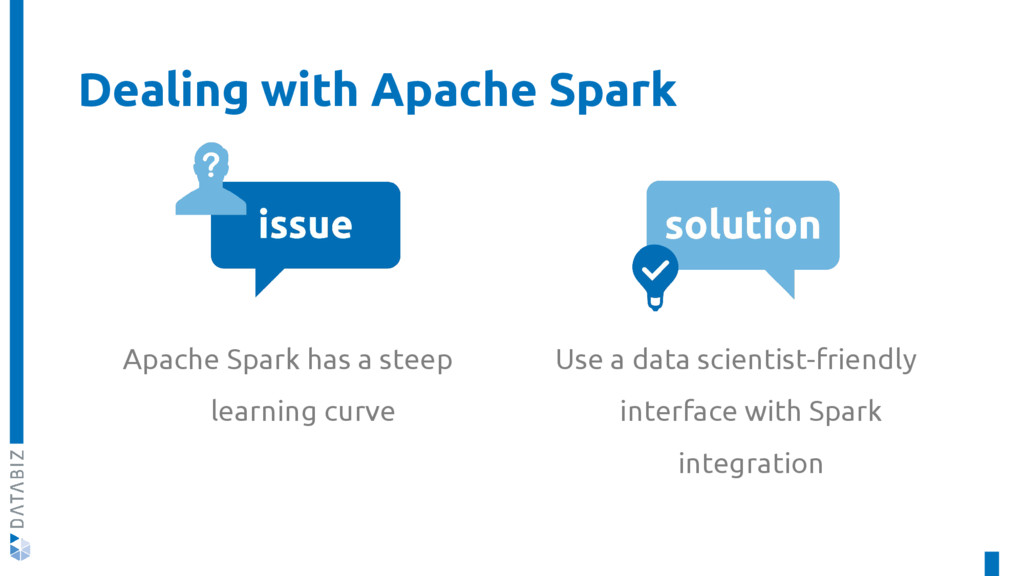
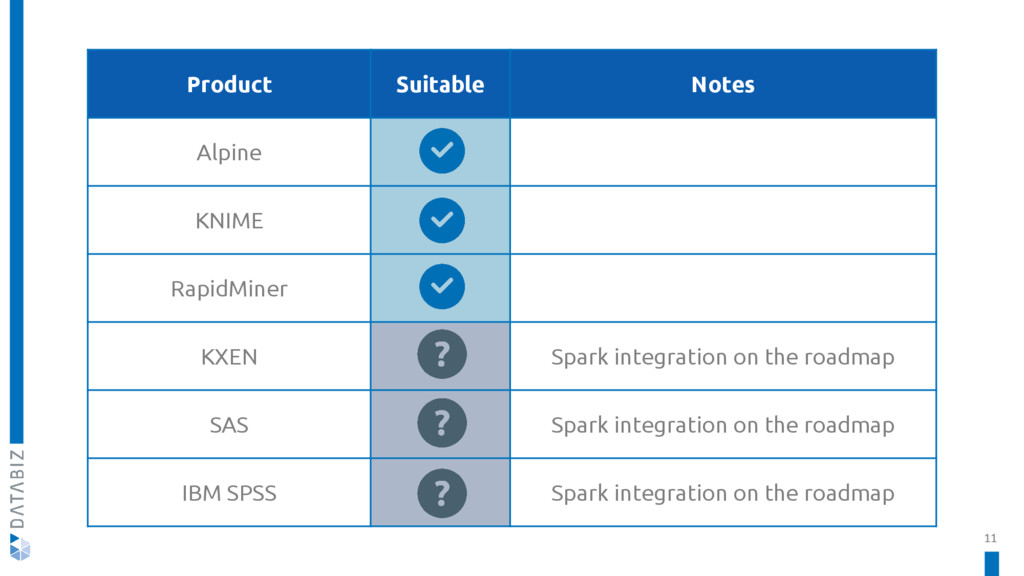
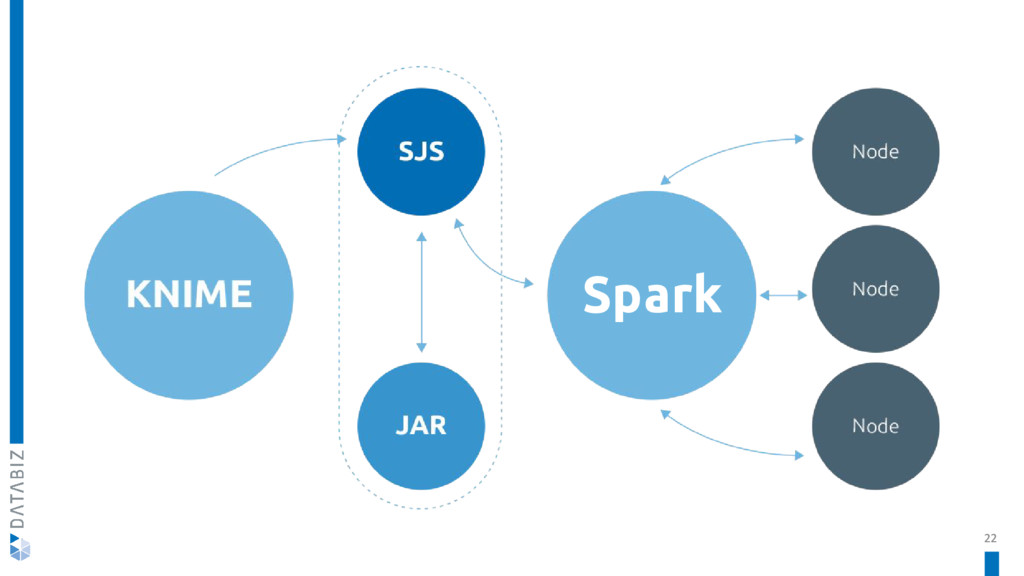
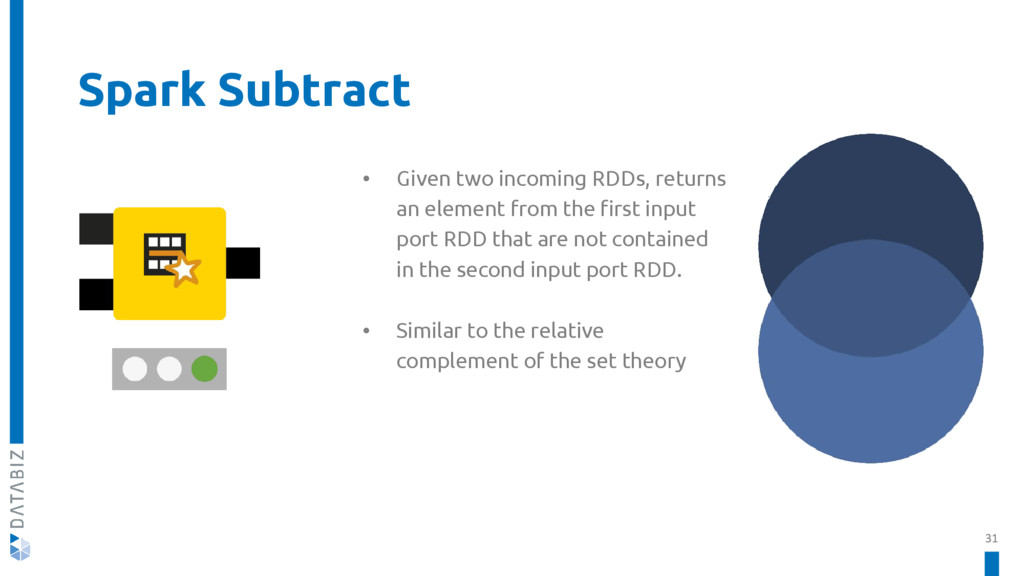
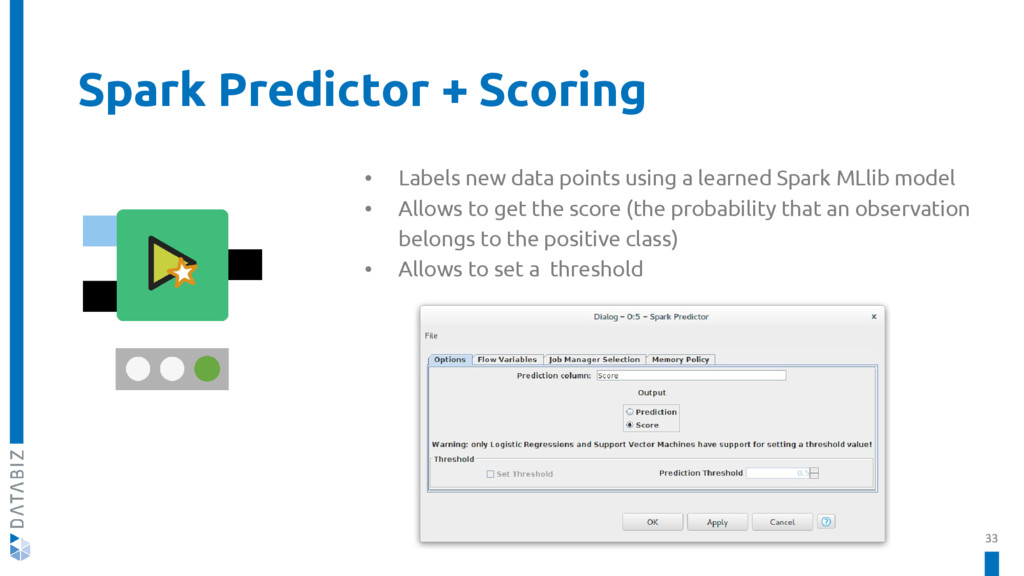
KNIME Spark Executor is a set of nodes used to create and execute Apache Spark applications with the familiar KNIME Analytics Platform.
In this talk, we will delve deeper into the architecture of the KNIME Spark Executor, understanding how it makes KNIME interact with Spark, and we will see which new nodes Databiz developed for it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Hey, We Are Hiring! Send Us Your CV! [email protected]](https://files.speakerdeck.com/presentations/137db837ea894a349cab805d5a8210ba/slide_46.jpg){kind=link}
![Hey, We Are Hiring! Send Us Your CV! [email protected]](https://files.speakerdeck.com/presentations/137db837ea894a349cab805d5a8210ba/slide_47.jpg){kind=link}