Neural networks and deep learning have seen a spectacular advance during the last few years and represent now the state of the art in tasks such as image recognition, automated translations and natural language processing. Unfortunately, most of the high performance deep learning implementations are single-node only, not being therefore particularly scalable.
During this talk, we will demonstrate how Apache Spark, the fast and general engine for large-scale data processing, can be used to train artificial neural networks, thus allowing to achieve high performance and parallel computing at the same time.
Presented at Scala Italy 2016 with Emanuele Bezzi
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
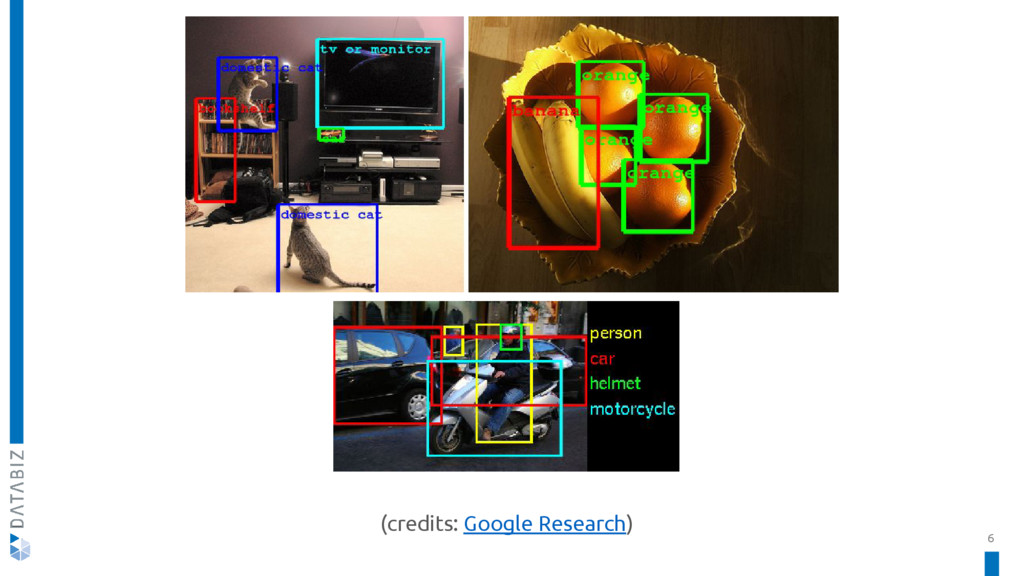{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
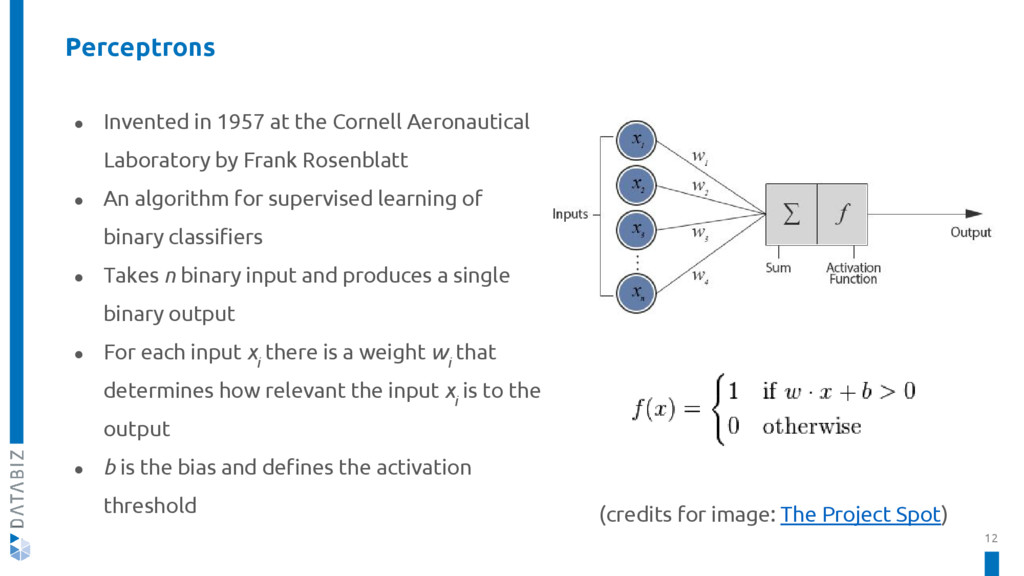{kind=link}
{kind=link}
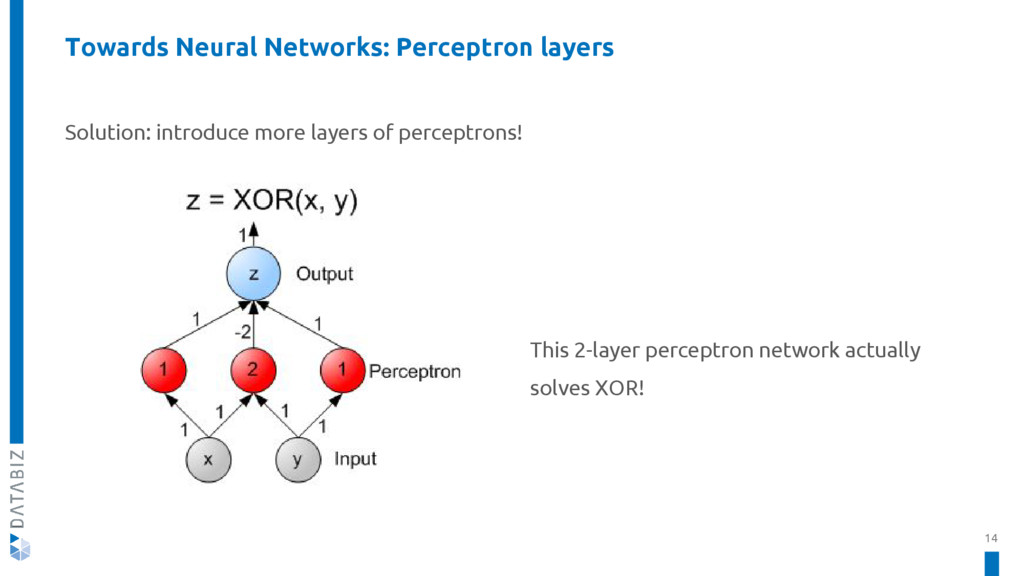{kind=link}
{kind=link}
{kind=link}
{kind=link}
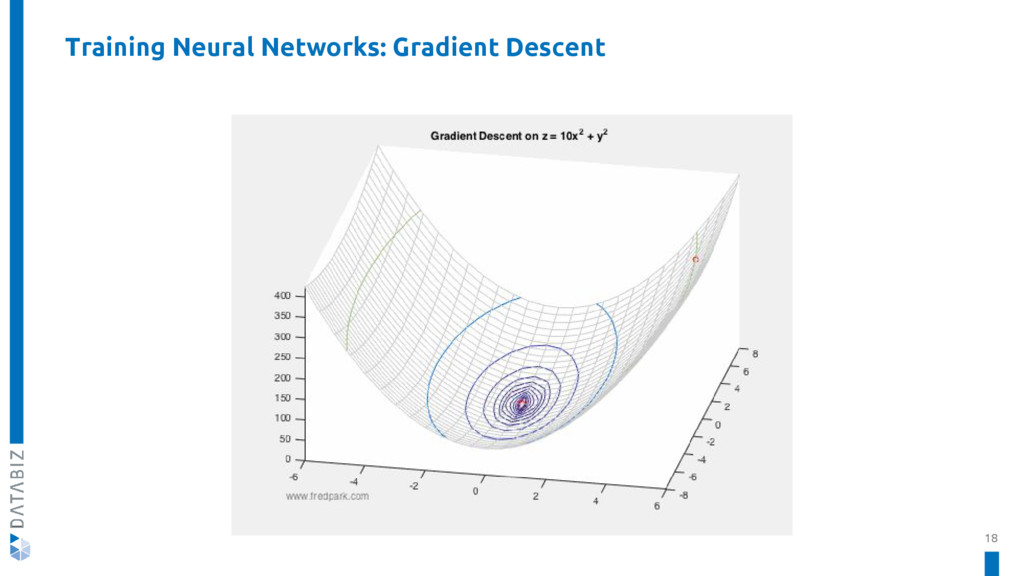{kind=link}
{kind=link}
{kind=link}
{kind=link}
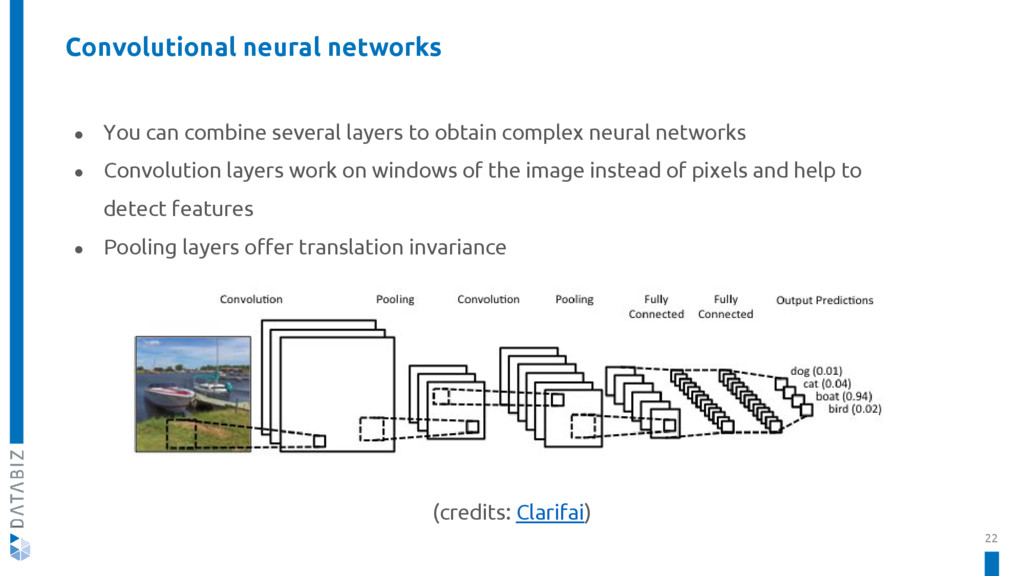{kind=link}
{kind=link}
{kind=link}
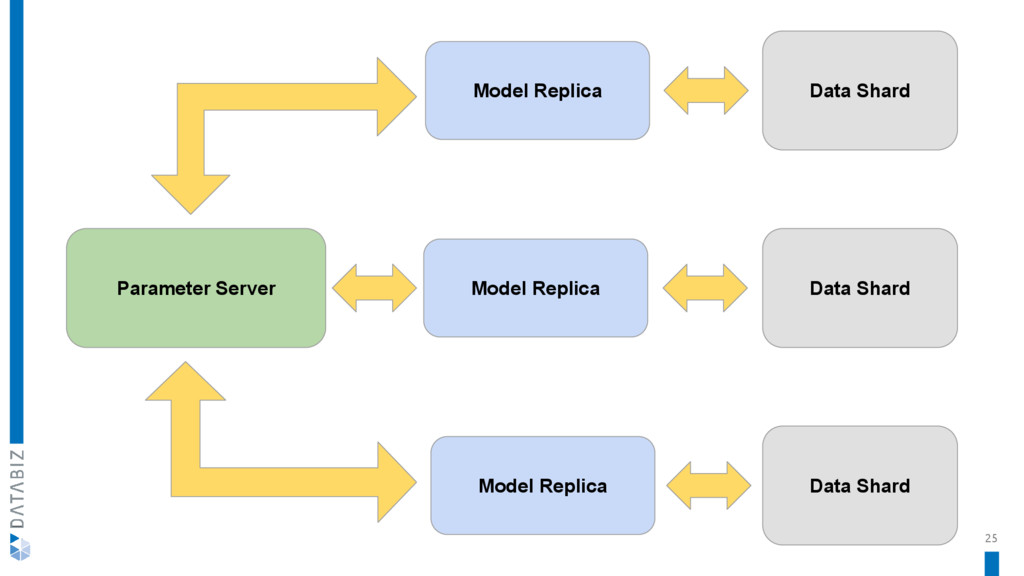{kind=link}
{kind=link}
{kind=link}
{kind=link}
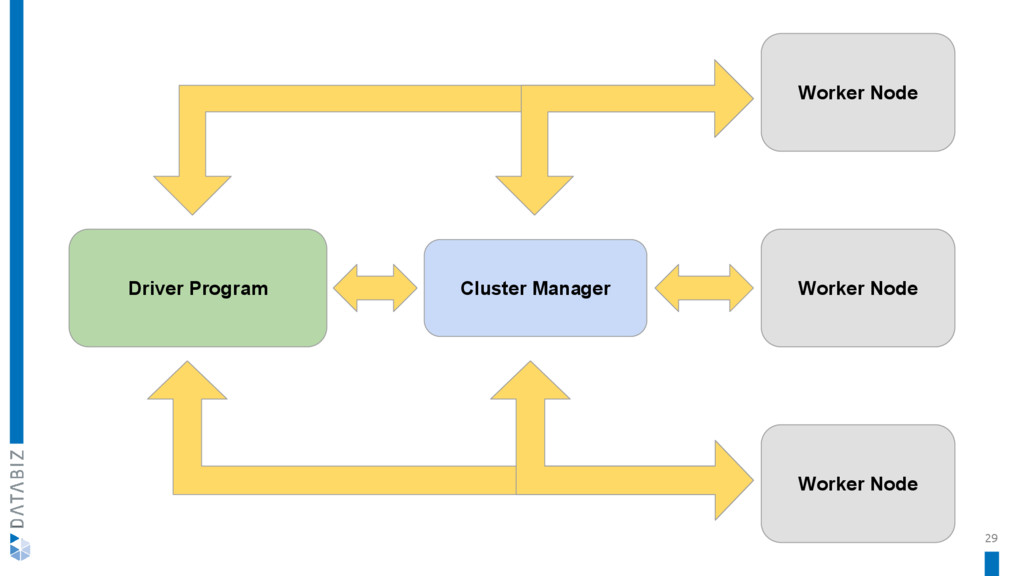{kind=link}
{kind=link}
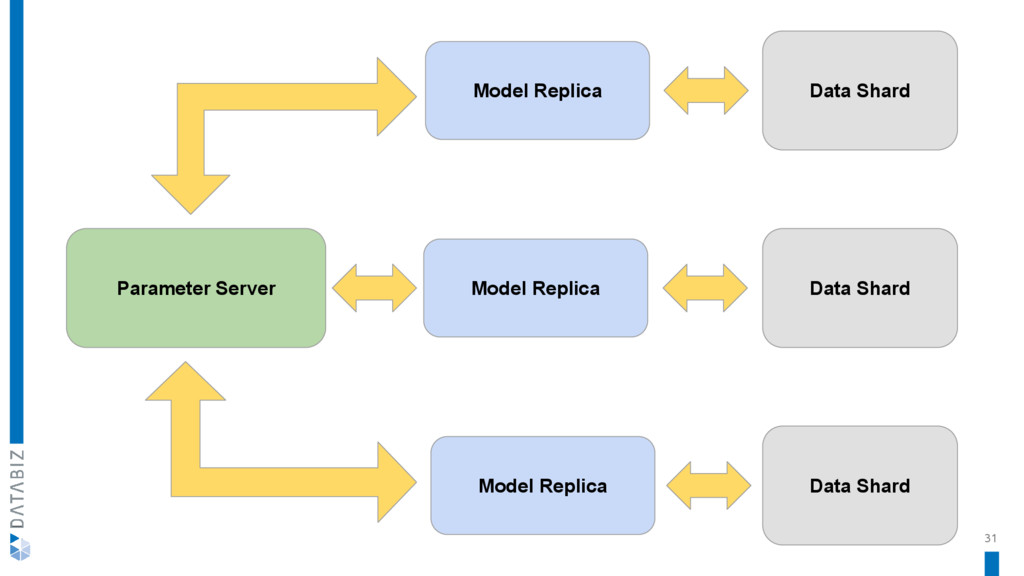{kind=link}
{kind=link}
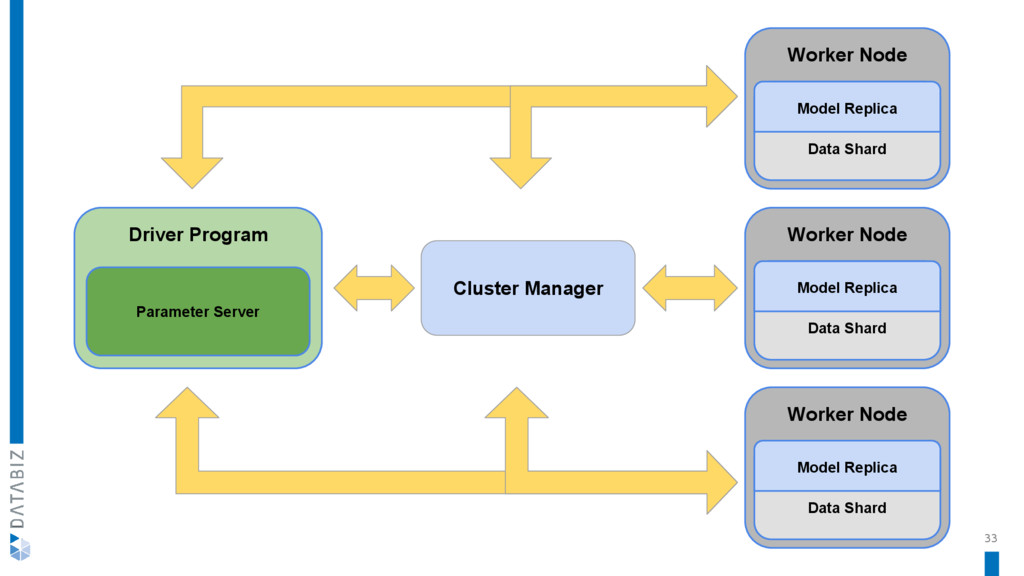{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
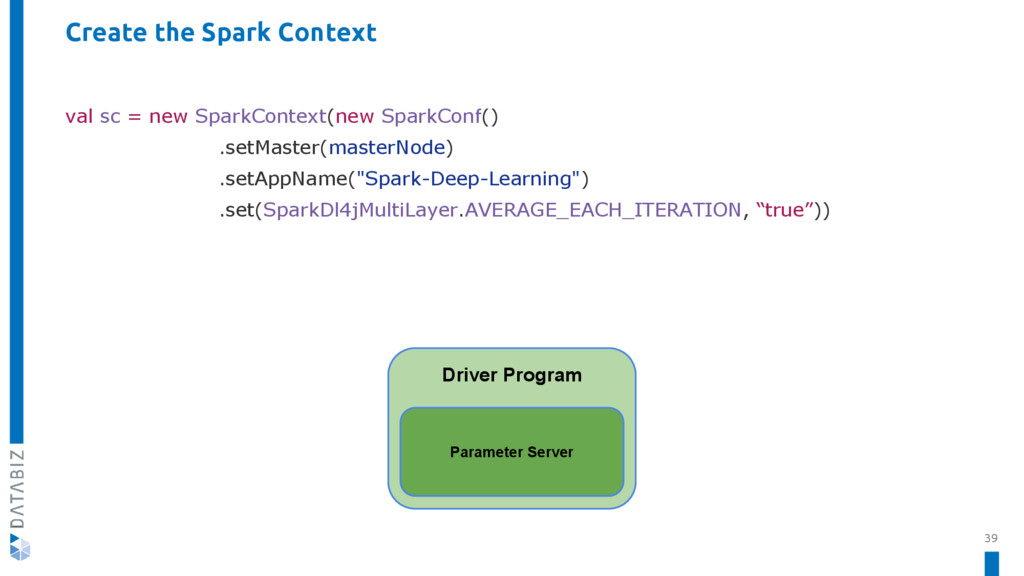{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}