done for equal sized particles by decomposing the RPY tensor into 4 calls to the harmonic FMM, the one which computes electrostatic potential and it’s gradient. This sum is seperated as two sums, one for neighbouring particles and one for far away particles. um i = um i,loc + um i,far After simplifications, the final expression is um i,far = C1 Pm far (vi , 0, 0) - C1 3 j=1 xm j Fm i,far (vj , 0, 0) + Fm i,far (C1 (x.v), C2 , v) Vipul Harsh (India) Georgia Tech. Symposium 8thMay, 2014 11 / 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
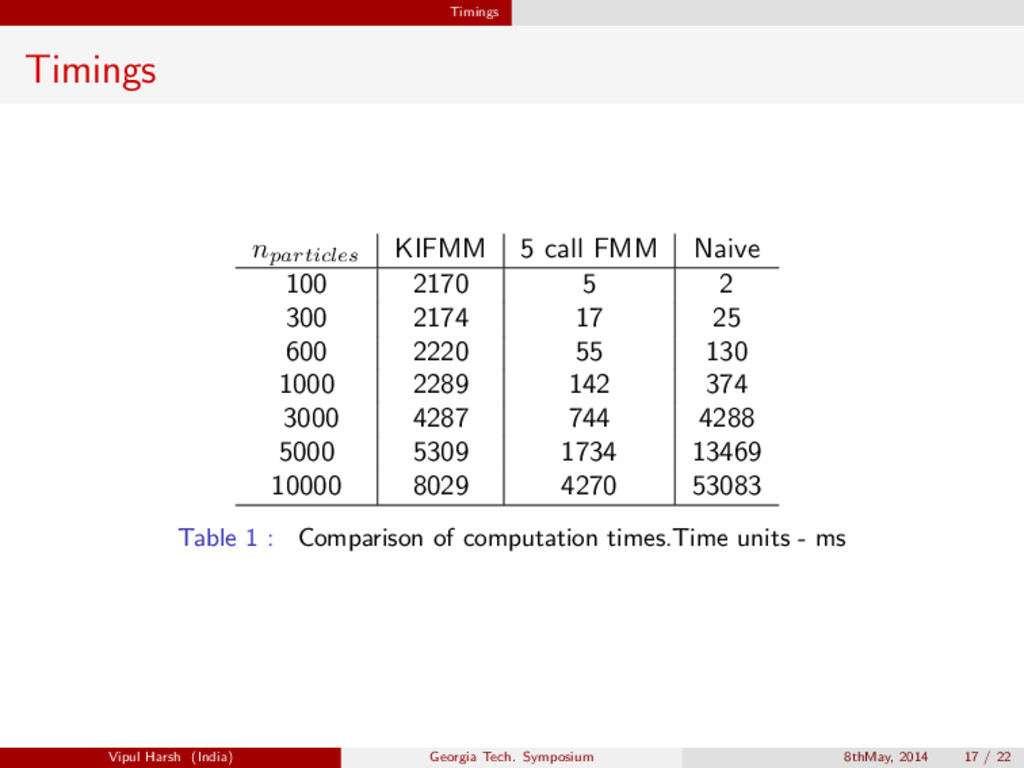{kind=link}
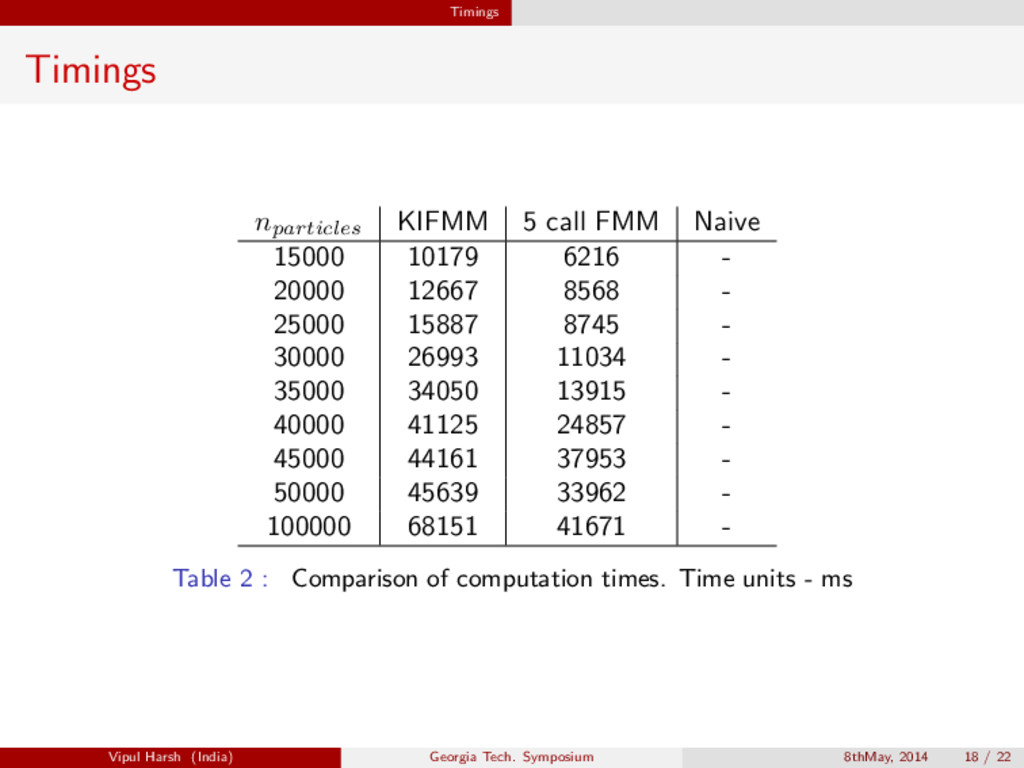{kind=link}
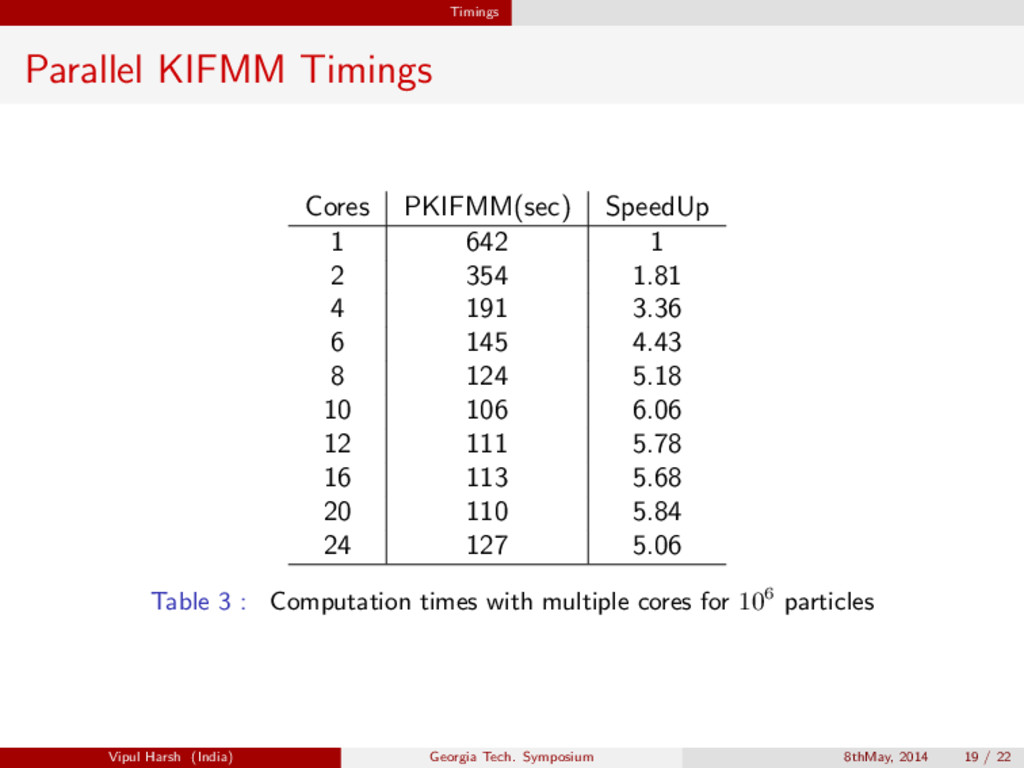{kind=link}
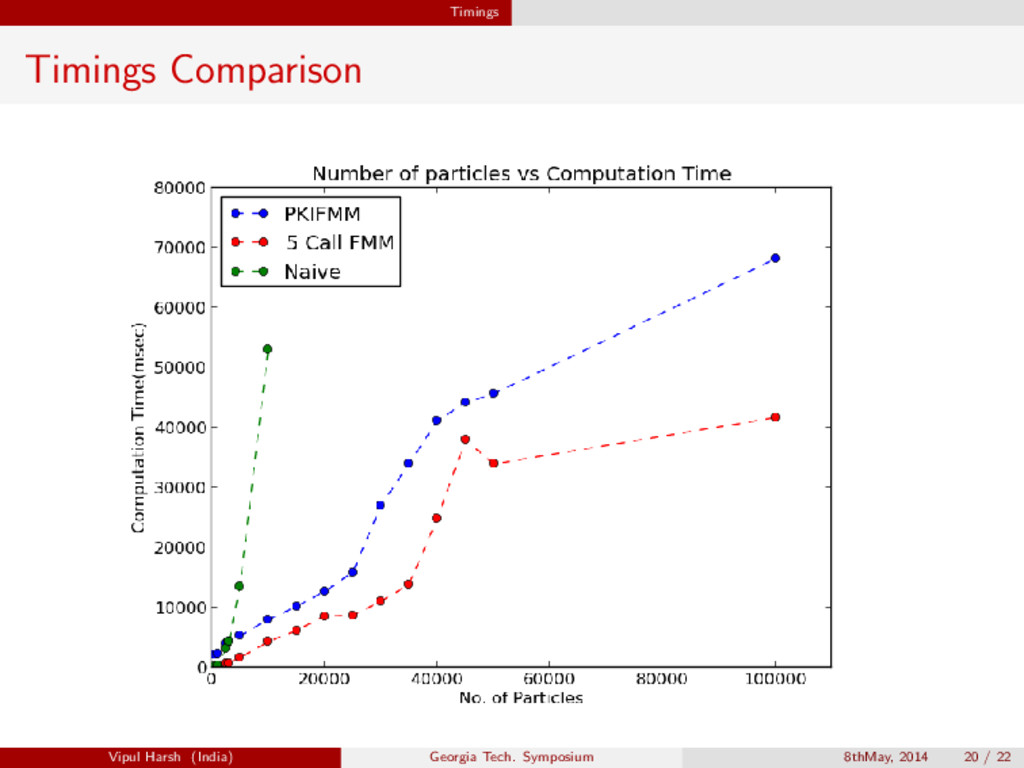{kind=link}
{kind=link}
{kind=link}