for trustable & affordable equipment Description : 1. In this town 2. Seller has reputation more than 3 3. Recommended by friends or same Guild 4. Attack 80+ 5. Order by bids Wednesday, May 9, 12
SELECT b.inV FROM graph as a, graph as b WHERE a.inV=b.outV ANDa.outV=? SELECT c.inV FROM graph as a, graph as b, graph as c WHEREa.inV=b.outV AND b.inV=c.outV AND a.outV=? SELECT d.inV FROM graph as a, graph as b, graph as c, graph as d WHERE a.inV=b.outV AND b.inV=c.outV AND c.inV=d.outV AND a.outV=? SELECT e.inV FROM graph as a, graph as b, graph as c, graph as d, graph as e WHERE a.inV=b.outV AND b.inV=c.outV AND c.inV=d.outV ANDd.inV=e.outV AND a.outV=? Wednesday, May 9, 12
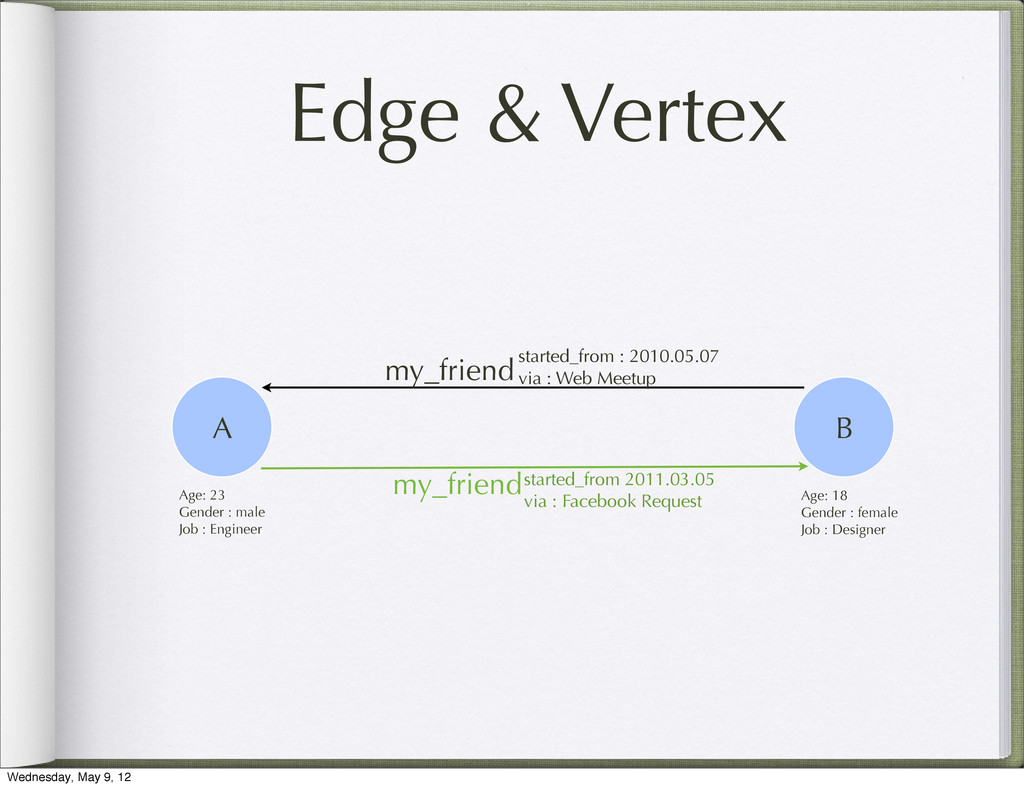
Web Meetup started_from 2011.03.05 via : Facebook Request A B Age: 23 Gender : male Job : Engineer Age: 18 Gender : female Job : Designer Wednesday, May 9, 12
Hadoop , CouchDB , MongoDB, Cassandra, Riak ... ) • Pros : Easy to scale, Proven example (Hadoop) • Cons : Map/Reduce is hard to write, and it’s not really for graph processing Wednesday, May 9, 12
v3 • Master/Slave ( Horizontal Scale is in plan ) • A(vailability) C(onsistency) I(solation) D(urability) • Various Clients & Cyper, Gremlin, Sparql Support • Written in Java, Cross Platform http://neo4j.org Wednesday, May 9, 12
file disk ) • C(onsistency) , P(artition) & Some Hack A(vailability) • Master/Slave Replication • Sponsored by VmWare !!! • Various clients & Map/Reduce with Lua • Written in ANSI C , Works in Linux, *BSD, OSX http://redis.io Wednesday, May 9, 12
• g.E => Edges • g.id => identifier of element • .out(E/V) => outgoing vertices/edges • .in(E/V) => incoming vertices/edges • .both => both vertices/edges • .filter => filter with conditions • .has => allow if has property • .hasNot => allow if has no property • .back => back to n-steps results • .or => emit if any pipes • .and => emit if all pipes • .as => names the previous steps Wednesday, May 9, 12
namespace Result Clause : what to return from query e.g. SELECT ?name ..... Query Pattern : specifying what to query in dataset e.g. WHERE { .... } Query Modifier : slicing , ordering , or any that rearranging results e.g. ORDER BY ... LIMIT ... OFFSET ... Variables : have a ‘?’ prepended e.g. ?name http://eneumann.org/talks/Sparql_tutorial.html#(1) Wednesday, May 9, 12
(Node) ID, or Index MATCH : usually after START, for Traverse purpose WHERE : Filter the traversed results RETURN : the format of return Wednesday, May 9, 12
and 2TB new data daily Yahoo - Hadoop cluster with more than 4PB data with Webmap Google - More than 20PB data with Map/Reduce everyday. Wednesday, May 9, 12
• Job - Sequence of phases & inputs • Map - Data Collection phase • Shuffle and Sort - Global Sort • Reduce - Data Collection or processing phase Wednesday, May 9, 12
• Riak - across multiple machines • CouchDB - run over all docs in single database • MongoDB - not spread across multiple machines Wednesday, May 9, 12
• Dryad - Streaming process algorithm as arbitrary dataflow graphs Designed for large scale graph algorithms Mystery Acyclic graph Vertex - developer-specified computations Edges - data channels that capture dependencies Wednesday, May 9, 12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Gremlin example g.v(21).as('I') .out('friend').as('my_friend') .out('friend').as('fof') .outE[[label:‘lives’]].inV[[name:‘Taipei’]] .outE[[label:‘likes’]].inV[[name:‘Jazz’]] http://www.youtube.com/watch?v=5wpTtEBK4-E Wednesday, May](https://files.speakerdeck.com/presentations/4faa0726a117fc002201ac7f/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Cypher Example START von=node:node_auto_index(name = 'Von') MATCH von-[:friend]->()-[:friend]->fof, fof-[:lives]->city, fof-[:likes]->interest](https://files.speakerdeck.com/presentations/4faa0726a117fc002201ac7f/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}