is what happens when you ask a software engineer to design an operation team.” Google - Site Reliability Engineering Ref: Betsy Beyer et al., “Site Reliability Engineering - HOW GOOGLE RUNS PRODUCTION SYSTEMS -,” 2016. • ソフトウェアエンジニアに運用チームの設計を依頼し たときにできあがるもの • SREチームは単なるインフラチームでも 運用チームでもない
culture, make a future SREという文化を組織に浸透させる。文化が強固に根付いた組織が日経の未来を形づくる。 Vision Think with us, act for yourself サービスチームと共に信頼性について考え、サービスチームが実行していくこと Value confidence, safe and relief, better experience, happiness
• SLOを可視化して、定期的にレポート ◦ 社内におけるSLI/SLOに対する意識付けを習慣化 • The Home Depot で実践されていた VALET Platform のコンセプト※1を参考 ※1: “SLO Engineering Case Studies,” https://sre.google/workbook/slo-engineering-case-studies/
future SREという文化を組織に浸透させる。文化が強固に根付いた組織が日経の未来を形づくる。 Vision Think with us, act for yourself サービスチームと共に信頼性について考え、サービスチームが実行していくこと Value confidence, safe and relief, better experience, happiness
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
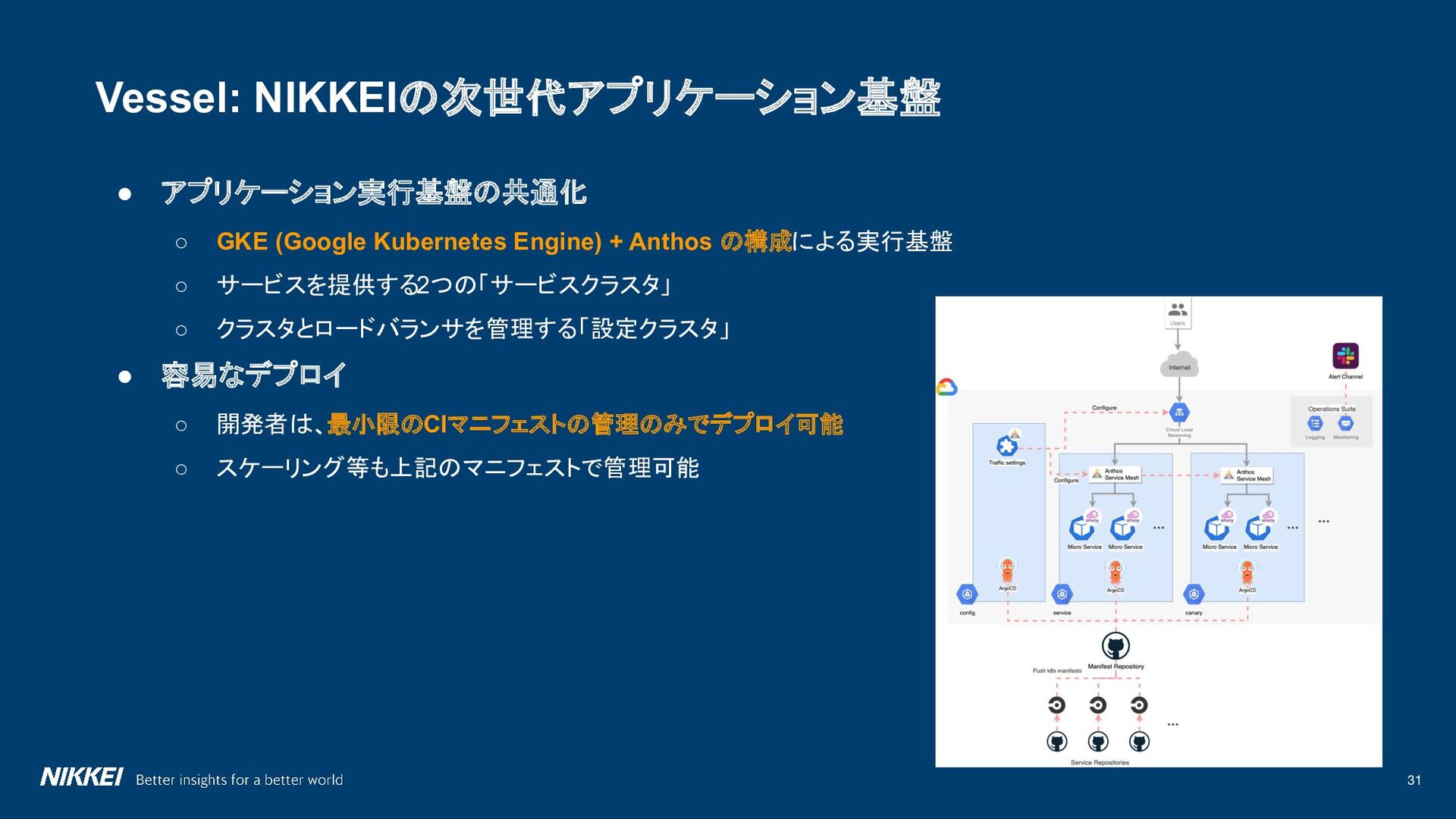{kind=link}
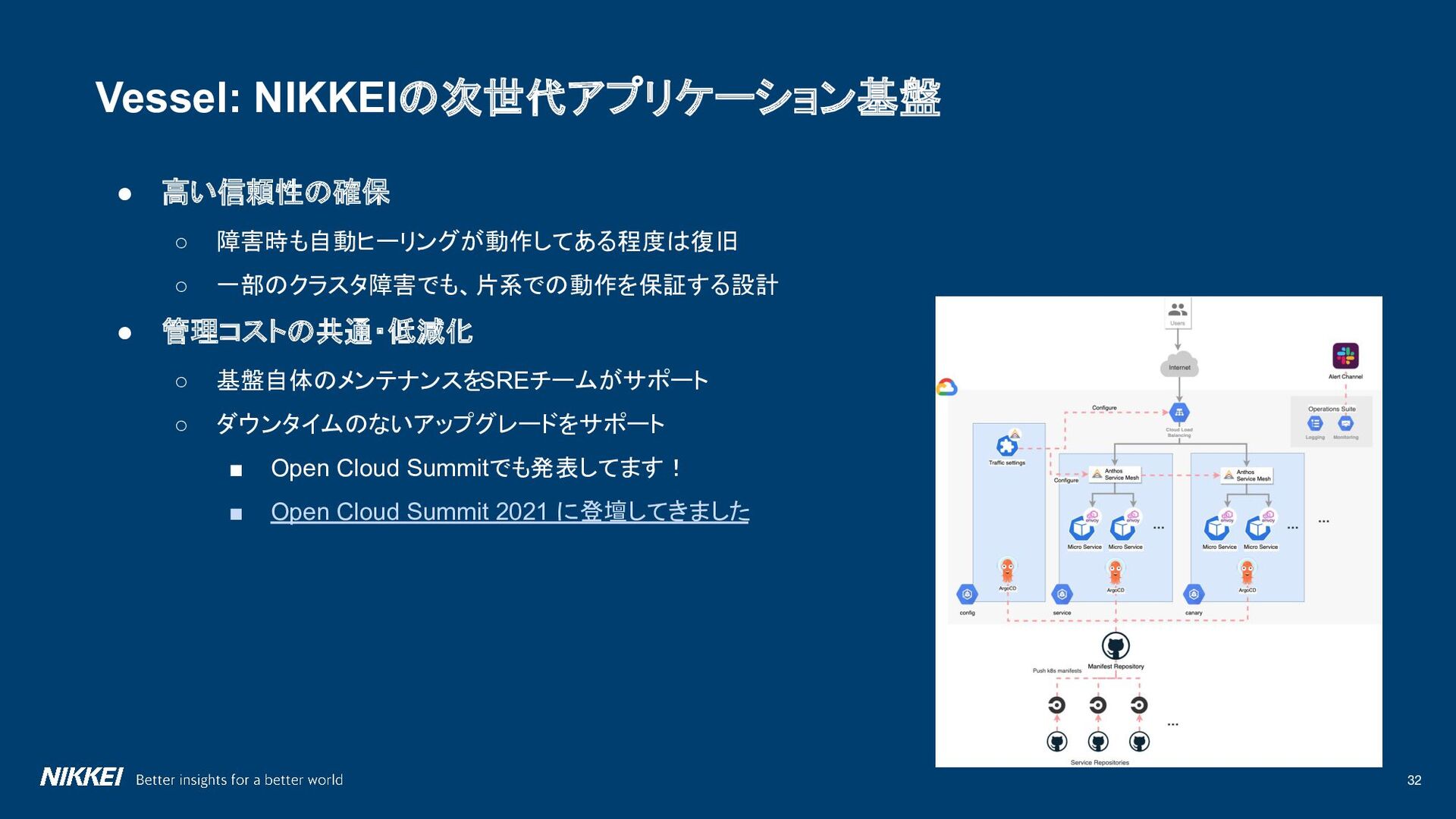{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
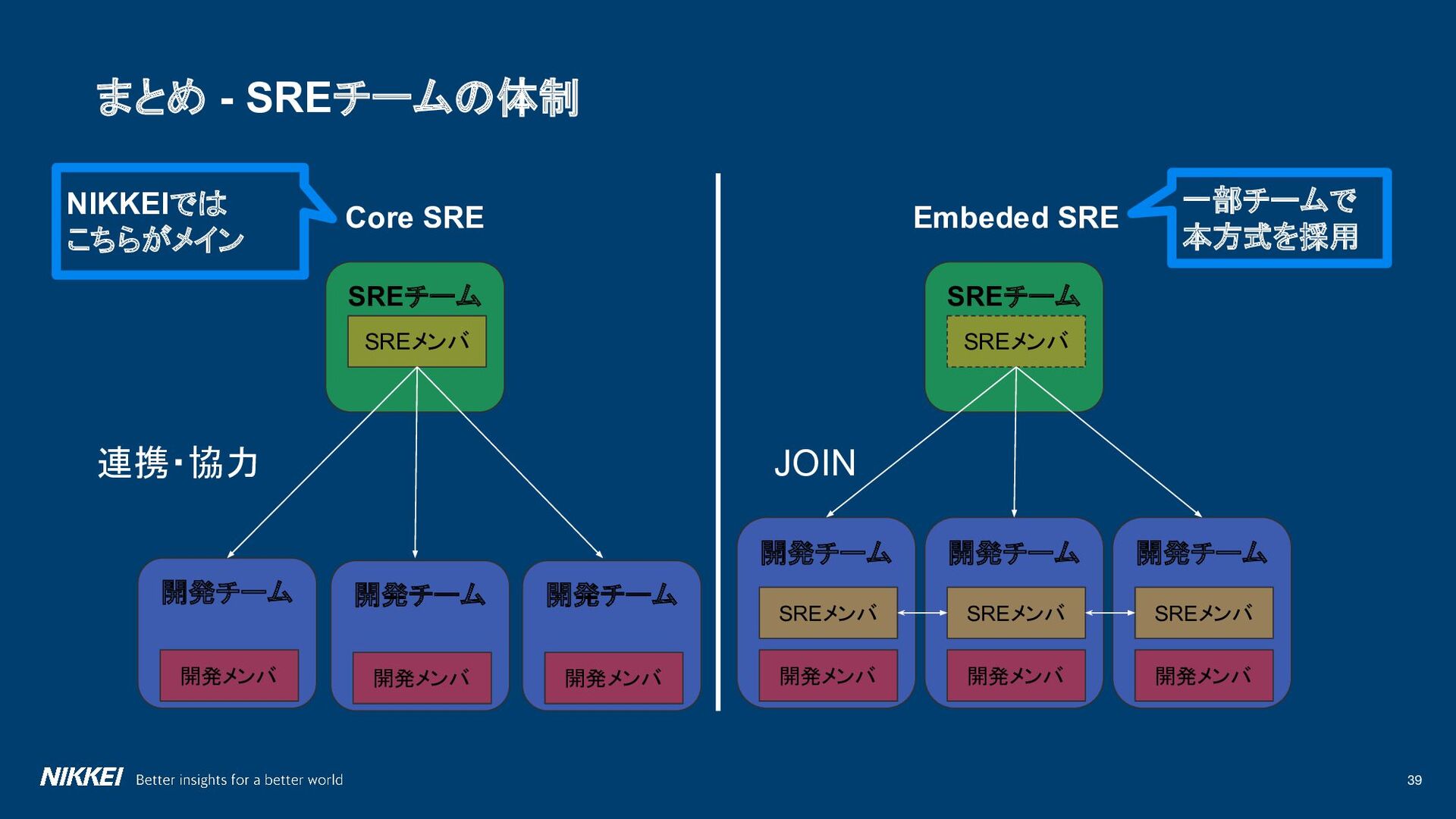{kind=link}
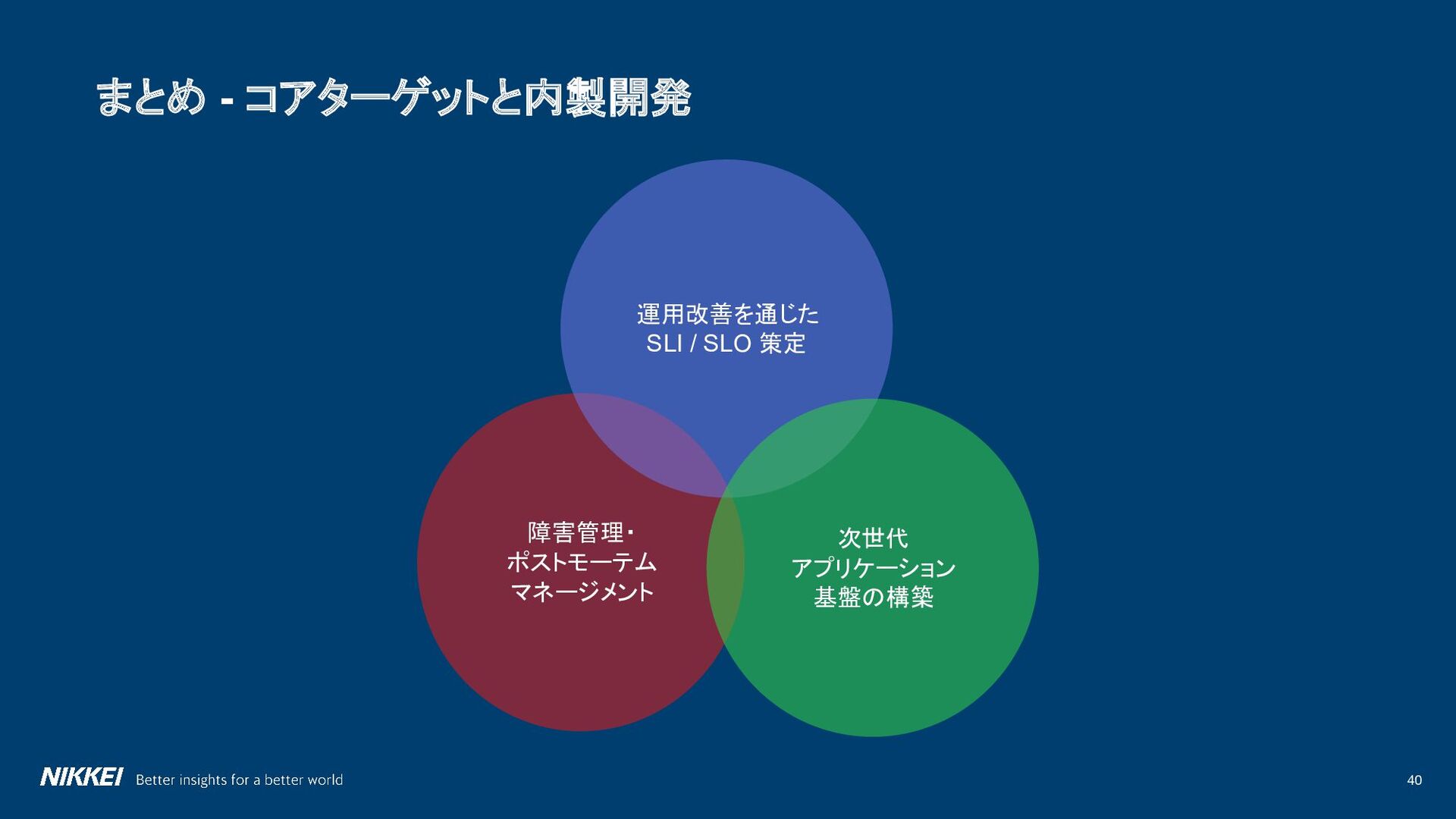{kind=link}
{kind=link}
{kind=link}